Archiving and Purging
This functionality is not available in every product.
The term archiving describes the process of moving selected data from production to an archive environment while maintaining the referential integrity of the overall application.
The term purging describes the process of deleting data from production without storing the data in another environment. Similar to archiving, the purge process must not affect the referential integrity of the application.
The Archiving Engine refers to the tools and infrastructure that are required for archiving and purging production data. The concepts for archiving and purging are very similar, except that purged production data is not transferred to an archive database.
Technical Chapter! The concepts described chapter do not relate to normal business process. If you are not responsible for managing product databases, skip this chapter.
Contents
The Big Picture of Archiving and Purging
Developing Archive and Purge Procedures
Sample Archive and Purge DB Processes
As time passes, the amount of data stored in the production database grows. Some tables can become very large and retain seldom-accessed data in the production database. Extremely large volumes of data may impede system performance.
In order to reduce the amount of raw data stored in the production database, a subset of records in the production database can be moved to an archive database, or a purged from the system.
Archiving and purging keeps the volume of data in the production database at a manageable level without compromising the system’s ability to perform normal operations.
Production Environment. This document makes many references to the production environment. It is quite possible to archive and purge non-production data, but for the sake of clarity, this document refers to "production" in place of any source environment for archive or purge.
Warning! There are currently no sample processes for restoring archived data. Please make sure you are very familiar with the Archive Engine and sample archive procedures before attempting to archive production data.
Contents
Maintaining Normal System Operation
Metadata and Archive/Purge Procedures
Storing Archived Data
When you archive, you move data out of the production environment's database to an alternate Framework environment's database. You can still view archived data along with production data in the alternate environment.
Archive Environment Registration
Database Users and Database Relationships
Multi-Environment Application
Think of the product as an application that is not bound to a single database instance. To understand ConfigLab concepts, you must think of the product as a collection of environments. An environment is an installed version of the product database, application server and web server.
There is only one environment in the application whose database contains production data. Let’s call this the production environment. Other environments exist to support the production environment in various ways. There is no logical limit to the number of supporting environments that may exist within the application.
Environment Roles
The environments supporting production are categorized into environment roles based on their function.
An Archive environment is a repository for data that is removed from production.
ConfigLab, Compare Source, and Sync Target environment roles are discussed in Configuration Lab.
The following illustration depicts a production environment with multiple supporting environments:
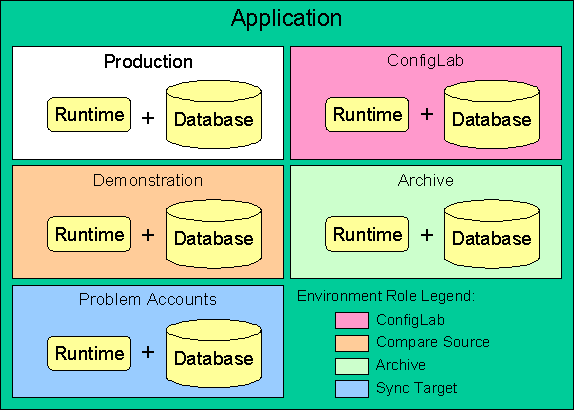
Production With Multiple Supporting Environments
Archive Environment Registration
Archive environments must be registered before they can be utilized. Registering an archive environment involves running an environment registration utility, specifying information about both production and the archive environment being registered. Your implementation's database administrator must execute the registration utility as the utility performs functions on the database that require administrative access.
When using Oracle as your database, you have the choice of configuring the archive database to be in the same Oracle instance (recommended) or a separate Oracle instance. For other databases, separate database instances are required.
The following summarizes the functions performed by the registration utility:
· Adds an environment reference in the production environment specifying the target environment’s role (in this case Archive), the target environment's universal environment ID, as well as a prefix character used for creating synonyms described below.
· Creates synonyms in the production environment database that reference tables in the target environment database over a database relationship. Refer to Database Users and Database Relationships below. These synonyms are prefixed with the environment reference's name prefix that is used in place of the “C” in a normal table name. For example, assuming the environment reference's name prefix is A, the CI_BILL table in the target environment database is referenced via the AI_BILL synonym in the production environment database.
· If the archive database is configured as a separate database instance, the utility also creates super views in the archive environment’s database that is being registered. Each super view is a database view defined as a union of a given archive environment database table and its corresponding production environment database table (over another database relationship). Refer to Database Users and Database Relationships below.
Note that registering a supporting environment is a one-time operation. Once the environment is registered, it maintains its role until it is deregistered. Note also that if the system is upgraded or if a single fix is applied, you must reregister all supporting environments.
For more information on registering environments, refer to How To Register an Archive Environment. For more information on viewing environment references created by the registration utility, refer to Defining Environment Reference Options.
Warning! While it is possible to register multiple archive environments within the application, it is not recommended. Spreading archived financial data across multiple databases may cause financial balances to display inaccurately when viewed within an archive environment.
Deregistering an Environment
If you no longer want use a given environment for archive processing, you should deregister it using the registration utility. Deregistering an environment removes the remote table synonyms that were added when the environment was registered and it changes the environment reference status to inactive.
For more information on deregistering environments, refer to How To Register an Archive Environment.
Reregistering an Environment
If you had previously deregistered an environment reference and you wish to make that environment available for archive processing again, you must reregister it using the registration utility. You must also reregister an environment after upgrading or applying a single fix. Reregistering an environment updates the environment reference status to active if it was previously inactive and it creates/drops/updates the remote table synonyms.
For more information on reregistering environments, refer to How To Register an Archive Environment.
Database Users and Database Relationships
When an environment is installed initially, a database user is defined as the owner of all the application database schema objects. We'll call this database user CISADM. To use the archive engine, two additional database users are necessary for each environment's database:
· Database user with read/write access to the application database schema. We'll call this database user CISUSER.
· This database user is installed automatically when the system is installed in an Oracle database.
· The application server(s) used to access the production environment should be configured to access the production database as the CISUSER database user. This is the default in an Oracle installation. For DB2, this is a manual operation that must be performed manually following installation and prior to environment registration.
· Database user with read-only access to the application database schema. We'll call this database userCISREAD.
· Note that this database user is installed automatically when the system is installed in an Oracle database.
· The application server(s) used to access the archive environment should be configured to access the archive database as the CISREAD database user.
Prior to registering an Archive environment, the following database relationships must be configured by your implementation's database administrator to match the diagram below:
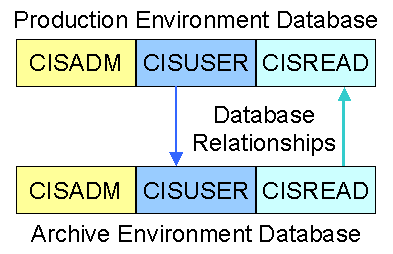
Same Oracle Instance. If you configured your archiving environment to be in the same Oracle instance as your production environment then you don't need to configure a database link.
Notice that the database relationship originating from the production environment's CISUSER database schema references the CISUSER schema in the archive environment’s database. A database relationship originating from the archive environment’s CISREAD database schema references the CISREAD schema in the production environment’s database.
Archive database processes that are run from the production environment move data into a given archive environment. When the process populates tables in an archive environment’s database, the CISUSER to CISUSER database relationship is used.
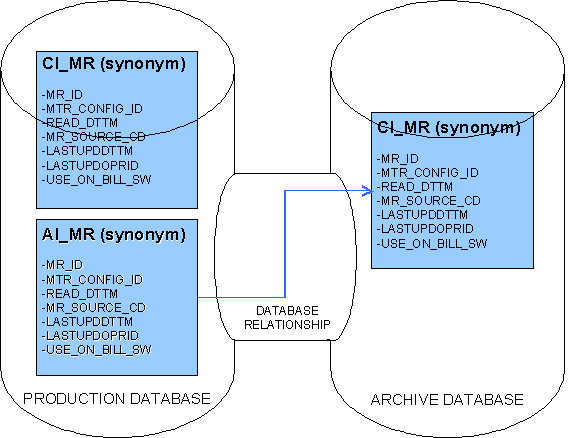
So that archived data may be viewed along with production data in an archive environment, the registration script creates super views of application tables by defining a union of the production database tables with a given archive environment’s corresponding database tables. These super views replace the "CI_" synonyms normally defined under the CISREAD schema in the archive environment. When a user logs onto an archive environment and maneuvers around the system, the data presented is from the super views. To accomplish this, synonyms from CISUSER in the archive environment database tables are unioned with the CISREAD production database synonyms over the CISREAD to CISREAD database relationship. The super views are read only, of course.
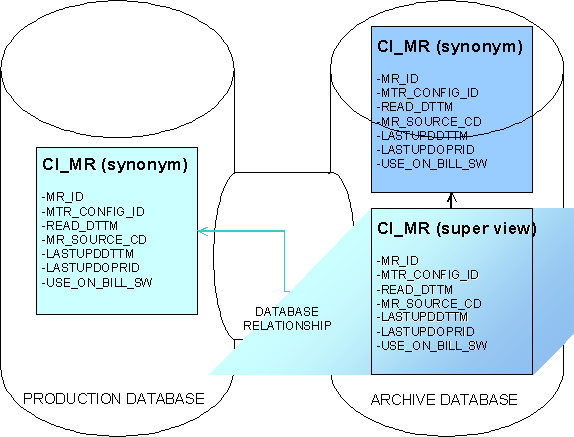
As mentioned previously, most entities in a given archive database are accessed using a super view when accessing an archive environment’s data under its CISREAD schema. This implies that an application server and web server must be installed and configured to reference the CISREAD schema, not the CISUSER schema. Refer to Managing Archive Environments for more information.
Within the CISREAD schema, certain tables are not presented from super views:
· System tables. These tables are only maintained in the production environment’s database. When an archive environment is registered, views in the archive environment database’s CISREAD schema are created that access system table entities solely from the production environment database's CISREAD schema. System tables are special configuration tables used to store data that support the application. Metadata and security tables fall into this category.
Refer to Defining Table Options for information on identifying system tables.
· Access modes. There is a security table that contains a given user group's allowable actions for a given application service. The archive environment CISREAD schema’s super view restricts user group access modes to those that do not modify data.
Refer to Defining User Groups for more information on specifying access modes to application services for user groups.
Archiving Data Using Flat Files. As an alternative to archiving data using the database relationships described above, you can move your archive data to flat files and then subsequently import these flat files into your archive environment. For some environments, bypassing the database relationships for the archive step may provide better performance. Refer to Step 4: Move or Delete Production Data for more information about the background process that archives data to flat files.
Maintaining Data Integrity
Referential integrity of the production database must be maintained after archiving or purging. Imagine if bill records were purged and bill segment records were not. Some bill segment records would reference non-existent bill records in the production database. To effectively archive or purge production data without causing system problems, it is important to understand the system’s data model.
Archiving or purging production data requires analysis of table dependencies. When choosing data to archive, a primary production maintenance object is selected. All of the table relationships related to the maintenance object must be analyzed. Rules for handling different table relationships during archiving or purging are necessary.
Contents
Inter-Database Foreign Key References
Identifying Relationships
Often parent-child relationships exist between tables. To avoid repeating groups of data stored on one table, a child table is used to store the repeating information. Records on a child table cannot exist without a related parent record. Child tables have identifying relationships with parent tables.
Records on a parent table should be archived or purged along with related records on all child tables. This ensures that child records are not orphaned. This axiom is recursive, as child tables may have child tables of their own.
Suppose that you want to archive meter read data. For each CI_MR (meter read) record that is archived, the related child records in CI_REG_READ (register reading) and CI_MR_REM (meter read remark) tables should also be archived. The following illustrates how register reading records and meter read remark records are related to a parent meter read record.

Non-Identifying Relationships
Parent-child is not the only way tables may be related. To minimize database storage requirements, attributes related to a specific entity exist on a single table. Generally tables do not redundantly store data that already exists on another table. Instead, a reference to the table is used. These tables have non-identifying relationships.
Consider a field activity step for reading a meter. The field activity step table does not store the date and time the meter was read, as this information is kept on the meter read table. The field activity step merely contains a reference to the meter read.

Special consideration must be taken to manage non-identifying relationships during the archiving or purging of production data. Most of the time, the best solution is to use non-identifying relationships as exclusion criteria, but there are exceptions where it is acceptable to allow foreign key references to archived data.
Let’s take a look at this from an archive and purge perspective separately:
· Archive processes.
When data is archived, it is moved from the production environment’s database to an archive environment’s database. Since the data still exists within the application, references to data moved from production to archive may still be considered valid. The system takes special measures when presenting archived foreign key references. This is considered an inter-database foreign key.
While references to foreign keys outside of the environment’s database are sometimes valid, it is still good practice to minimize their occurrences. If you examine the sample archive processes, you will notice that care has been taken to reduce the number of foreign keys that reference archived data.
· Purge processes.
Dangling foreign key references to deleted records must not be left after a purge process has been executed. After a purge, the data does not exist in any environment, so any reference to the data is invalid.
Inter-Database Foreign Key References
When a system-generated key value is assigned to a record, the system also stores the key value in a key table that corresponds to the record's database table (see Defining Table Options). Key tables store the universal environment identifier along with the key values.
When data is moved from production to archive, the archived records' related key table records are not deleted from the production database. The key table records are instead updated with the universal environment identifier of the target archive environment. This prevents the system from re-using an archived key value. For example, since field activity steps are allowed to reference archived meter reads, the key values of the archived meter reads cannot be assigned to new meter reads.
Imagine. What would happen if archived key values were re-used? New records added to production might be unwittingly linked to records that were simply preserving their link to archived records.
If the production system encounters a foreign key reference to a record that is not in the current environment's database, it will look up the key value on the record's associated key table to see if the underlying data has been archived. The existence of the key value on the key table satisfies application level referential integrity, because the key of the archived data is still present in the production database. Even though the key is displayed, the description of the object is blank, and any go-to functionality that is normally associated with the key is disabled.
Archive Process Order
To minimize the number of inter-database foreign key references, it is desirable to archive sets of production data in a specific order. Suppose that you wanted to archive meter read data. The CI_BSEG_READ (bill segment read detail) table contains non-identifying relationships to the CI_MR (meter read) table. Almost every meter read record is referenced on a bill segment read detail record.
Using the sample process for archiving meter reads alone would result in very few meter reads being archived because the sample meter read archiving processes would not allow dangling intra-database foreign key references from bill segment read to register reading. Performing a bill archive prior to performing a meter read archive alleviates this problem.
Cannot Archive Most Meter Reads
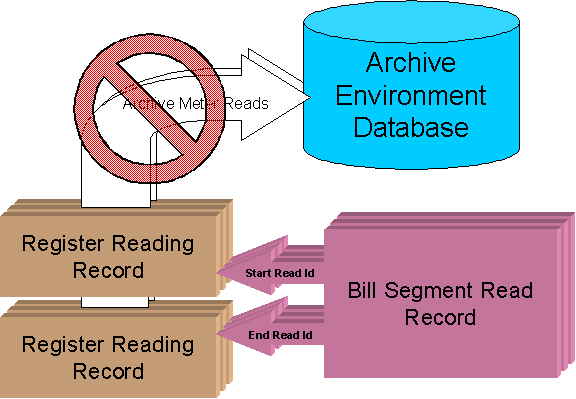
Bill Segment Reads Reference Register Readings
Archive Bills First
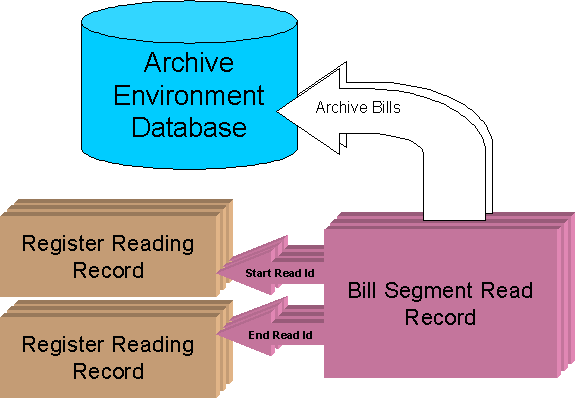
Archive Bills First To Remove References
Now Archive Meter Reads
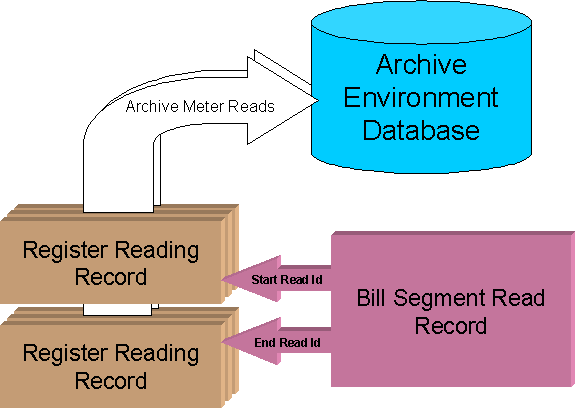
Bill Archive Removed References
Maintaining Normal System Operation
In addition to maintaining referential integrity of the production database, the archiving or purging processes must ensure that critical data is not archived or purged along with non-critical data stored on the same tables. It is important to understand system functionality and business processes to determine impact of archiving or purging production data.
Contents
Age of Data
Generally age is a factor in determining which production data to archive or purge. It makes sense to archive or purge older data that is accessed less often than recently added data. When a set of production data is chosen for archive or purge, consider how much of the data is still relevant to maintain normal operations.
Status Of Data
Many tables include a status field or state-identifying switch. These fields are used to track the state transition of a system entity. The system often keys processing or validation off of these status fields. Usually records are added in an initial state, and over time the state changes, eventually reaching some final status. Think of a service agreement moving from Pending Start to Active to Pending Stop to Stopped to Closed. Records that store data related to system entities controlled by state should generally not be archived or purged unless the system entity is in a final status.
Keys and Relationships
Archiving configuration data that is based on user-defined keys can be problematic. Since configuration tables' keys are user-defined (not system-generated), they do not have associated key tables. This means that if you archive configuration data, the system does not validate that the key has been used once it has been moved to an archive environment's database.
Remember that one of the features of an archive environment is that it provides you the ability to use the application to view both production and archived data at the same time. By logging into an archive environment whose application server points to the CISREAD schema, the data is presented from super views of both production and archive. If data related to a user-defined key were re-used in production, the super view in archive would contain two records with the same key value, and the effect on the archive environment would be unpredictable. You should consider carefully whether you want to archive data based on user-defined keys.
For more information on how data based on system-generated keys vs. data based on user-defined keys is handled during an archive, refer to Step 4: Move or Delete Production Data.
Warning! It is possible to contort the archive and purge processes to introduce problems for the super views in an archive environment. Let's say that you archived bills with bill calculation headers that referenced a rate version, then you purged that rate version from production. The archive environment would not have access to the rate version needed to view those archived bills.
Aggregate Summaries
Archiving or purging records from a production data table could affect balances and quantities that are calculated from details. There are various ways to handle these situations, and each situation must be treated individually.
There are very few cases where calculated or stored aggregate summaries exist in the system. The sample archive procedures deal with the most complex instances of aggregate summaries that exist in the system, which are those that deal with financial data.
There are different ways of dealing with aggregate summaries, and they may be used in combination:
· Add a detail record that is representative of a summary of archived or purged detail records.
· Use criteria algorithms to ensure that the removed detail records do not affect normal system operation. For example, if you archive credit rating history, only archive expired credit rating details so that the overall credit rating and cash-only point balances remain the same after an archive or purge.
· Change system functionality to alert users when an aggregate summary has been altered due to a purge or archive. Note that this option should not be necessary.
For more information on how the sample archive procedures deal with aggregate summaries, refer to the processing algorithms associated with the Sample Archive and Purge DB Processes.
Metadata and Archive/Purge Procedures
You configure archive and purge processes using metadata. It is important to understand the following metadata objects in order to configure an archive or purge process.
· Table. Defines fields and constraints associated with a table.
· Constraint. Defines relationships between tables.
· Maintenance Object. Defines tables maintained by page maintenance application service.
· Database Process. Defines a group of maintenance objects that are archived/purged together.
Contents
Table Constraints Define Relationships
Maintenance Objects Group Tables
Database Processes Group Maintenance Objects For A Purpose
DB Process Instructions Drive The Process
Table Constraints Define Relationships
Tables are the metadata that correspond to database tables where records of data are stored in the application. The relationships between tables within the application are defined using constraints.
Unless your implementation has defined custom tables, you are not required to configure tables and constraints used in archiving and purging. All of the table and constraint metadata is populated when the system is installed. The information on tables and constraints is provided as background to make the archiving and purging functions easier to understand.
Constraints are examined during an archive or purge process to ensure that referential integrity is maintained. Intra-database foreign key references are not allowed to "dangle" after any purge or after data based on non-system-generated keys is archived.
Referential Integrity. The constraints examined by purge and archive processes are the same constraints examined by the online system when a delete action is performed.
Below is an illustration of a foreign key constraint defined on the CI_BSEG_READ table. This represents one of the bill segment read detail’s foreign keys that references a register reading’s primary key:
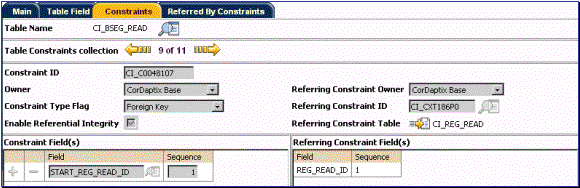
Foreign Key Constraint Example
Refer to Defining Table Options for more information on viewing a table’s constraints.
Maintenance Objects Group Tables
A maintenance object represents a primary table and child tables that are maintained as a logical unit. Each maintenance object has a page maintenance application service (runtime program) responsible for manipulating and validating the primary record and related child records defined in its tables. When records related to a maintenance object are archived or purged, records in the primary table and related child tables are automatically archived/purged at the same time. The system examines the constraints defined on the maintenance object's tables to ensure this is done.
Unless your implementation has defined custom tables, you are not required to configure maintenance objects used in archiving and purging. All of the maintenance objects are populated when the system is installed. The information on maintenance objects is provided as background to make the archiving and purging functions easier to understand.
For example, the bill segment page is responsible for maintaining a CI_BSEG record along with its related CI_BSEG_READ records, CI_BSEG_CALC records, CI_BSEG_CALC_LN records, etc. Below is an illustration of the BILL SEG maintenance object. Notice that the tables are defined with roles of either Primary or Child. Also note that the constraint representing the parent-child relationship is also defined for each table.
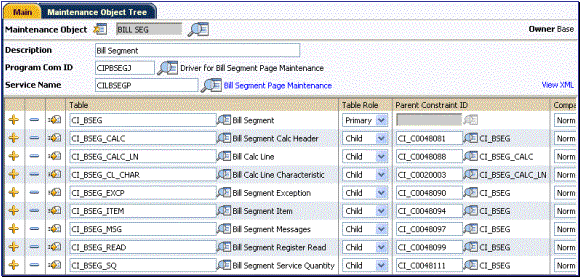
Maintenance Object Example
Refer to Defining Maintenance Object Options for more information on viewing maintenance objects.
Database Processes Group Maintenance Objects For A Purpose
More than one maintenance object may be involved in an archive or purge task. A maintenance object only specifies the child tables that are maintained as part of a page maintenance application service. Therefore, multiple maintenance objects may need to be archived or purged together to ensure that records in all parent-child relationships are archived or purged at the same time.
A database process (DB process) allows you to specify a group of maintenance objects that are processed together for a purpose. In addition, you specify the parent-child constraints that link child maintenance object tables with their parent maintenance object tables within the DB process.
The DB process type specifies the purpose. The DB process types used with the Archive Engine are Archive and Purge:
· An Archive DB process is used to move production data to an Archive environment.
· A Purge DB process is used to delete production data.
For Archive and Purge DB processes, one maintenance object acts as the Primary in the collection of DB process instructions.
Let’s say our DB process purpose is archiving bills that were more than four years old. Not only do you need to archive records in tables defined under the BILL maintenance object, you also need to archive the related records in tables defined under the BILL SEG maintenance object and the FT maintenance object. Note the linkage constraints specified for BILL SEG and FT.
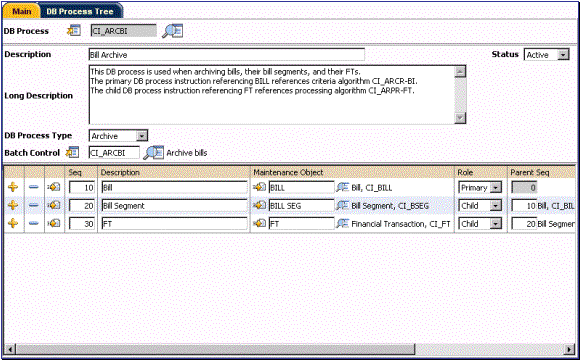
DB Process Example (left side of grid)
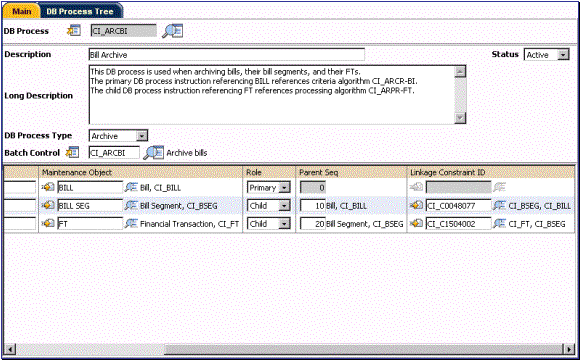
DB Process Example (right side of grid)
Refer to Defining Database Process Options for more information on setting up database processes.
DB Process Instructions Drive The Process
Each maintenance object specified for a DB process represents a DB process instruction. DB processes instructions used for archive and purge are the metadata that background processes use to build the subset of production data eligible for archive or purge (see archive root objects). DB process instructions specify exclusion criteria or extra processing that is done when an archive or purge procedure is performed.
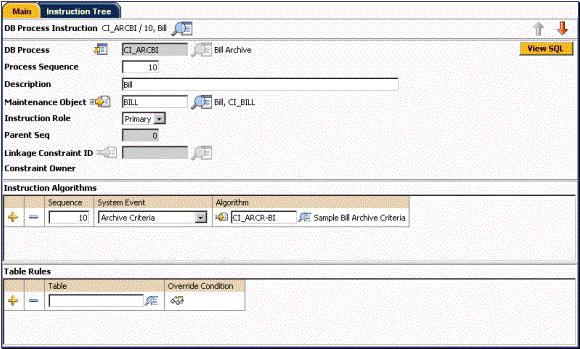
DB Process Instruction Example
Refer to Defining Database Process Instruction Options for more information on setting up DB process instructions.
Contents
Criteria Algorithms Exclude Records
Table Rules Also Exclude Records
Processing Algorithms Perform Extra Processing
Criteria Algorithms Exclude Records
During an archive or purge procedure, background processes are executed to build the subset of production data to be archived or purged. We’ll call this set of background processes the Archive Engine. When the Archive Engine runs, criteria algorithms specified on DB process instructions are executed. Criteria algorithms are supplied with the primary key value of a maintenance object’s primary table. These algorithms simply return a Yes or No value depending on program logic that determines whether the object may be archived or purged. These algorithms are usually defined on a Primary DB process instruction, but there is no restriction. When criteria algorithms specified on Child DB process instructions return a No (do not archive/purge), none of the records associated with the Primary DB process instruction nor any of its children are archived or purged.
The following illustrates an instruction algorithm specified on the Primary DB process instruction for an “Archive Bill” DB process.

Archive Criteria Algorithm Example
Refer to Defining Database Process Instruction Options for more information on setting up DB process instruction algorithms.
The instruction algorithm’s program logic performs queries based on the primary key values of records on the CI_BILL table, and returns No (do not archive/purge) if any of the following conditions are met:
Age and State
· Bill is less than n days old (n is specified as an algorithm parameter).
· Bill is not complete.
· FTs linked to the bill are not frozen
· FTs linked to the bill are not redundant
· FTs for the bill’s bill segments are linked to an unbalanced match event.
Relationships
· Pay segment FTs or adjustment FTs are linked to the bill.
· Auto pay clearing staging records exist for the bill.
· Statements exist for the bill.
Table Rules Also Exclude Records
Another way to exclude records from being archived or purged is to set up table rules on a DB process instruction. A table rule’s override condition is incorporated into the WHERE clause in the SQL statement that builds the subset of production data for archive or purge when the Archive Engine runs. Table rules may be specified on any DB process instruction for any table within that DB process instruction, but are generally specified only on a Primary DB process instruction’s Primary table.
The following illustrates a table rule specified on the Primary DB process instruction for an “Archive Bill” DB process. Specifying this table rule prevents the Archive Engine from archiving any bills for account 2846738204:
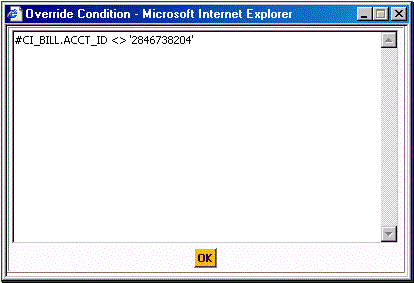
Table Rule Override Condition Example
Warning! Table rules are usually not used with archive or purge DB processes. Specifying additional WHERE clauses may introduce inefficient data access. Only consider using a table rule if an index supports the WHERE clause.
Inner Joins. If you specify a table rule on a Child table within the DB process instruction, that table is joined with its recursive parent tables in the resulting SQL. Use the SQL viewer to make sure that the resulting SQL is really what you want.
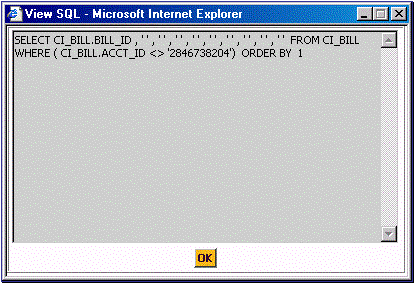
DB Process Instruction - View SQL
Refer to Defining Database Process Instruction Options for more information on setting up DB process instruction table rules.
Processing Algorithms Perform Extra Processing
As their names imply, Archive Processing and Purge Processing algorithms perform extra processing based on program logic. These algorithms are used to resolve aggregate summaries, and may also be used in some cases to set special archive attributes on records where unresolved non-identifying relationships result from archiving data. As with criteria algorithms, the Archive Engine supplies processing algorithms with the primary key value of a maintenance object’s primary table when archive or purge background processes are executed.
The following illustrates an archive processing algorithm specified on a Child DB process instruction for an “Archive Bill” DB process. In this case, when an FT is archived, the algorithm’s program logic:
· Updates the SA’s archive adjustment.
· Updates balance control.
· If the FT is linked to a bill, sets bill’s archive flag to Y.
· If the FT is linked to a match event, sets the match event’s archive flag to Y.

Archive Processing Algorithm Example
Refer to Defining Database Process Instruction Options for more information on setting up DB process instruction algorithms.
The archive engine is a conceptual metaphor that represents the framework used to archive or purge production data. We can think of the archive engine as a set of generic programs designed to move or delete any data from production.
Contents
Lifecycle of an Archive Root Object
Archive and Purge Procedures
An archive or purge procedure is a set of processes used to accomplish an archive or purge task. An archive or purge procedure consists of a set of four background processes that are executed in a specific order. Each background process is submitted separately, and has a specific function. An Archive or Purge DB process specifies a batch control that relates to the first background process that is executed. This is not to say that a different program is required for each Archive or Purge DB process, as there is one generic program that performs the first step of any archive or purge procedure.
For example:
· The CI_ARCBI (“Archive Bill”) DB process may specify a batch control called CI_ARCBI (“Step 1 of Archive Bills”). The program associated with the CI_ARCBI batch control is CIPYCPRB.
· The CI_ARCPY (“Archive Pay Event”) DB process may specify a batch control called CI_ARCPY (“Step 1 of Archive Pay Events”), and the program associated with the CI_ARCPY batch control is also CIPYCPRB.
Batch Controls. The batch controls used for background processes submitted for Step1: Create Primary Archive Root Objects are typically named the same as an archive or purge DB process.
The subsequent background processes are also generic programs that perform functions related to a step in any archive or purge task. The same programs are executed for Step 2, Step 3 and Step 4 regardless of the archive or purge DB process. While this concept is confusing, it may become clearer as we look at what each step does.
Separating Procedures. You may prefer to set up separate batch controls for steps 2, 3, and 4 for each Archive or Purge DB process. While there is slightly more configuration involved, it may be worthwhile in terms of maintaining clear separation of your archive and purge procedures; for example, you may want to keep steps 2, 3, and 4 of an “Archive Bills” archive procedure separate from steps 2, 3, and 4 of an “Archive Pay Events” archive procedure.
The following steps are performed for any archive or purge procedure. Remember that each step in an archive or purge procedure is a separately submitted batch process:
· Create Primary Archive Root Objects
· Build Child Archive Root Objects for Primary Archive Roots
· Check Recursive Integrity
· Move or Delete Production Data
For more information on submitting batch processes, refer to Online Batch Submission.
Contents
Step 1 - Create Primary Archive Root Objects
Step 2 - Build Child Archive Root Objects for Primary Archive Root Objects
Step 3 - Recursive Integrity Check
Step 4 - Move or Delete Production Data
ArcSetup Preprocessing
A utility called ArcSetup is provided to maximize performance. Run this as a pre-archive task with action type B. This utility generates the DDL for the tables that are associated with archive DB Processes resulting in the scripts Gen_Index.sql and Enable_Pkey.sql. It then drops indexes and disables primary key constraints for tables associated with archive DB processes.
Step 1 - Create Primary Archive Root Objects
When you submit the first step in an archive or purge procedure, the program attempts to build and store archive root objects. Archive root objects drive the subsequent steps in an archive or purge procedure. Archive root objects represent the subset of production data to be archived or purged. Archive root objects are transient, as they only exist during an archive or purge procedure. Archive root objects reference the primary key value of the Primary table of the maintenance object specified on a DB process instruction.
This step creates archive root objects for the maintenance object specified on the DB process’ Primary DB process instruction. We’ll call these Primary archive root objects.
Remember:
· A DB process specifies the batch control used to submit the “first step” in an archive or purge procedure.
· A DB process’ Primary DB process instruction specifies a maintenance object
· A maintenance object specifies its Primary table.
· A table specifies its Primary key constraint.
Test Mode. You can specify a parameter on the batch control that prevents this background process from actually creating archive root objects. When executed in test mode, this step writes information about the archive root objects to a trace file.
Apply Table Rules
The program applies table rules related to the Primary DB process instruction (table rules related to Child DB process instructions are applied later). A table rule’s override instruction (WHERE clause) prevents archive root objects from being created unless the data meets the condition.
Refer to Table Rules Also Exclude Records for more information on setting up table rules.
Execute Criteria Algorithms
As Primary archive root objects are being created, the program executes criteria algorithms specified on the Primary DB process instruction. The program passes the primary key values of the Primary table data of potential Primary archive root objects to the criteria algorithms. If a criteria algorithm returns a false (do not archive/purge), the program does not create an archive root object for the data.
Refer to Criteria Algorithms Exclude Records for more information on setting up criteria algorithms.
Create Archive Root Instructions For Archive Root Objects
For each archive root object stored by this step, the program stores an archive root instruction that links the archive root object and its DB process instruction. An archive root instruction references the archive root object that caused it to be stored and that archive root object’s Primary archive root object. At this time, the program is creating root instructions for the Primary DB process instruction; so a root instruction’s Primary root object reference and Child root object reference are the same archive root object. When we examine how the program creates Child archive root objects, it becomes clear that archive root instructions provide a cross-reference of Primary and Child archive root objects that are processed together as a group.
Step 2 - Build Child Archive Root Objects for Primary Archive Root Objects
The next step in an archiving procedure creates Child archive root objects for data related to Primary archive root objects with an initial status (archive root objects are added as initial in Step 1: Create Primary Archive Root Objects). Note that this background process processes archive root objects related to the specified Archive or Purge DB process. You specify the DB process as a parameter on the batch control.
For each Primary archive root object, the program creates Child archive root objects for data related to Child DB process instructions linked to the Archive or Purge DB process. As with the Primary archive root objects built in the previous step, Child archive root objects reference the primary key value of the Primary table of the maintenance object specified on the Child DB process instruction.
Apply Table Rules
It would be unusual to include a table rule on a Child DB process instruction. If they are specified on any of the Child DB process instructions, they prevent archive root objects from being created for the data related to Child DB process instructions unless the data meets the conditions specified on a table rule's override instruction (WHERE clause). This is unusual because you would most likely create dangling foreign key references by specifying table rules at this level. It may be better to try and prevent the applicable Primary archive root objects from being created in the first place.
Refer to Table Rules Also Exclude Records for more information on setting up table rules.
Execute Criteria Algorithms
At this time, the program executes criteria algorithms related to the Child DB process instructions. As in the previous step, these criteria algorithms prevent archive root objects from being created. The difference is that if a criteria algorithm specified on a Child DB process instruction returns false (do not archive/purge), the program deletes all of the root objects related to the Primary archive root object. This is a fundamental difference between criteria algorithms and table rules specified at this level. Since the archive root objects are deleted, they will not be subject to further processing in subsequent steps. Again, criteria algorithms are generally specified on Primary DB process instructions.
Refer to Criteria Algorithms Exclude Records for more information on setting up criteria algorithms.
Create Archive Root Instructions For Archive Root Objects
For each Child archive root object, the program stores an archive root instruction that links the archive root object and its DB process instruction. The root instruction references the archive root object that caused it to be stored and that archive root object’s Primary root object. Once the program processes all of the child archive root objects, the archive root instructions provide a cross-reference of Primary and Child archive root objects that are processed together by subsequent steps.
Step 3 - Recursive Integrity Check
This step in an archiving procedure performs a recursive integrity check onPrimary archive root objects with a pending status (archive root objects were updated to pending in Step 2: Build Child Archive Root Objects). Again, this background process processes archive root objects related to the specified Archive or Purge DB process. You specify the DB process as a parameter on the batch control.
If any foreign key constraint specified on a table related to any of the maintenance objects associated with a given Primary archive root object or its children references the same table that the foreign key constraint is defined, the program performs a recursive integrity check.
If only one side of a recursive relationship is slated for archive or purge, the program deletes all of the archive root objects related to the root object in question (from the Primary root object down). In other words, this is an invalid condition and deleting the archive root objects prevents the corresponding data from being archived or purged by the last step.
If both sides of a recursive relationship are slated for archive or purge, the program updates the Primary archive root object references on all archive root instructions involved in the recursive relationship to match the current archive root object instruction’s Primary archive root object. In other words, the archive root object cross-reference (archive root instruction) is updated so that all of the archive root objects involved in a recursive relationship are archived or purged together.
This is best explained by example:
Suppose that a DB process’ purpose is to archive adjustments that are more than four years old.
· Step 1 of the archive procedure creates applicable Primary archive root objects linked to the ADJ maintenance object’s Primary table’s primary key values (primary keys of the CI_ADJ table).
· Step 2 propagates Child archive root objects (i.e. archive root objects for the FT maintenance object).
· Step 3 examines the production data related to the archive root objects and makes sure that for any CI_ADJ record slated for archive, the corresponding CI_ADJ record specified by foreign key (XFER_ADJ_ID) is also slated for archive.
· If the corresponding CI_ADJ record is not slated for archive, all of the archive root objects and archive root instructions related to the Primary archive root object are deleted.
· Otherwise, the program updates all of the archive root instruction’s related to the archive root object being processed, setting their Primary archive root object references to match the Primary archive root object reference specified on the current root object instruction. This way, all of the archive root instructions reference the same Primary archive root object and are processed together in Step 4: Move or Delete Production Data.
Rarely performed. There are very few cases where recursive relationships exist in the system.
Step 4 - Move or Delete Production Data
The last step is the one that actually moves the production data into an archive environment, copies it to a flat file, or deletes it (in the case of purge). For step 4, you can select from two background processes: one that moves data to a target archive environment or one that calls an algorithm that moves the data to a flat file. If you archive to flat files, you can subsequently import the files into the archive environment using a database tool. The flat file method may provide better performance in some environments.
Contents
Archiving Data Directly to a Target Environment or Purging
Archiving Data Directly to a Target Environment or Purging
The AR-DCDT background process loops through the archive root instructions related to approved archive root objects (they were set to approved in Step 3: Recursive Integrity Check). The processing order is by Primary archive root object reference, from the lowest level Child archive root objects up to the Primary archive root object. The program issues a commit after each Primary archive root instruction has been processed. If a validation error occurs while processing an archive root instruction, the program deletes all of the archive root objects whose root instructions reference the same Primary archive root object.
This background process processes archive root objects related to the specified Archive or Purge DB process. You specify the DB process as a parameter on the batch control.
Execute Processing Algorithms
If there are processing algorithms associated with the archive root instruction being processed, both programs execute them before the data is deleted. These algorithms resolve foreign key references on production data that reference the subset of data to be archived. They may also resolve aggregate summaries (e.g. updating a summary adjustment to maintain a service agreement balance).
Delete Production Data and Root Object
Both programs handle the deletion of production data. Purge DB processes are handled differently than Archive DB processes.
For a purge:
· The program calls the driver specified on the archive root object’s maintenance object to validate intra-database foreign key references.
· If the archive root object's underlying data is not referenced by other data in the environment, the program deletes the underlying production data.
· The program deletes the archive root object and archive root instruction.
For an archive:
· The archive root object's underlying production data is copied to the archive environment’s database using the archive environment's synonym prefix and the archive root object's underlying production data is deleted.
· For each table in the archive root object's maintenance object hierarchy that has a key table, the program updates the key value record related to the archived record with the universal environment identifier of the supporting archive environment. Refer to Inter-Database Foreign Key References.
· The program deletes the archive root object and archive root instruction.
Archiving Data to Flat Files
The AR-DCDTF background process calls an algorithm that copies the data to a flat file then deletes it from the product environment. This background process selects the archive root instructions related to approved archive root objects (they were set to approved in Step 3: Recursive Integrity Check), groups them by their Primary root object, and calls the Archive Copy Data algorithm specified on the DB process instruction.
The algorithm copies the records to the path and file specified as parameters to the algorithm. We have provided sample algorithms for archiving meter read data to a file. If you want to use AR-DCDTF for other archive jobs, you must develop your own algorithms using ARCD-MR as an example. If a validation or other error occurs while writing to the flat file, the program stops execution. You must manually delete the flat files and restart the background process.
This background process processes archive root objects related to the specified Archive & Copy to File DB process. You specify the DB process as a parameter on the batch control.
Execute Processing Algorithms and Delete Production Data and Root Objects
After the flat files are written, the background process performs the following steps:
· For each table in the archive root object's maintenance object hierarchy that has a key table, the program updates the key value record related to the archived record with the universal environment identifier of the supporting archive environment. This is the archive environment into which you should subsequently load the flat files. Refer to Inter-Database Foreign Key References.
· If there are processing algorithms associated with the archive root instruction being processed, both programs execute them before the data is deleted. These algorithms resolve foreign key references on production data that reference the subset of data to be archived. They may also resolve aggregate summaries (e.g. updating a summary adjustment to maintain a service agreement balance).
· The program deletes the archive root objects and archive root instructions for the DB process.
ArcSetup Post Processing
Run the ArcSetup utility as a post-archive task with action type A. This utility
· Drops the synonyms in the schema with read only privileges to the application schema (for example the ARCREAD schema) for the tables that are associated with the archive DB processes
· Generates super views in the schema with read only privileges to the application schema (for example the ARCREAD schema) for the tables that are associated with DB Process in the schema with read only privileges to the application schema
· Logs on to SQLPLus as the application schema owner and execute scripts: Gen_Index.sql, Enable_Pkey.sql
Lifecycle of an Archive Root Object
This diagram shows the state transition for an archive root object. Note that archive root objects only persist during the execution of an archive procedure.
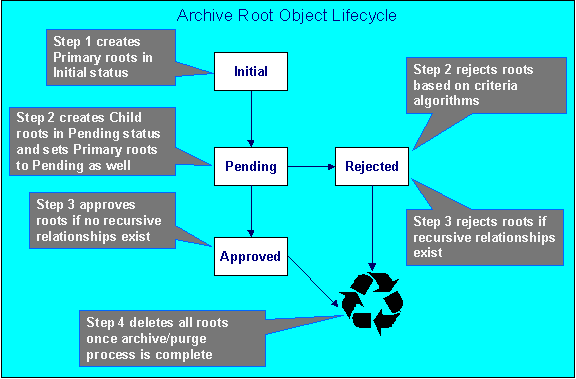
Archive Root Lifecycle
The topics in this section describe how to design and develop new archive and purge procedures.
Warning! Designing and developing new archiving procedures requires thought. Become familiar with the sample archiving procedures before attempting to develop your own.
Contents
Design and Develop Criteria Algorithms and Table Rules
Design and Develop Processing Algorithms
Design and Develop Archive Copy Processing Algorithms
Configure Metadata
When designing an archive or purge procedure, choose a primary maintenance object to archive. If you have added custom tables and maintenance objects, make sure they have been configured with all relevant constraints. When configuring DB processes, remember that parent records should be archived or purged with all of their children even when they cross maintenance object boundaries. Constraints linking maintenance objects are very important.
Refer to Database Processes Group Maintenance Objects for more information on setting up DB processes for archive or purge.
Design and Develop Criteria Algorithms and Table Rules
Since you want to process only a subset of production data, you need to determine exclusion criteria and put the logic into criteria algorithms or table rules. Remember the general rules for determining subsets of data to archive or purge:
· Archive or purge older data.
· Archive or purge data in its final status.
· Archive data based on system-generated keys.
· Minimize intra-database dangling foreign key references.
· Be careful when purging configuration data.
Even though during a purge foreign key checking is performed in Step 4: Move or Delete Production Data, you may consider reducing the number of eligible Primary archive root objects created by Step 1: Create Primary Archive Root Objects with criteria algorithms to reduce overall processing time.
For ideas on how to avoid creating extraneous Primary archive root objects during an archive or purge, refer to Sample Archive and Purge DB Processes.
Design and Develop Processing Algorithms
If any of the tables are involved in an aggregate summary, you may need to write a processing algorithm that inserts summary records to represent the deleted detail records. The logic for these programs depends heavily on the type of aggregate summary. Often you can avoid these situations by limiting the set of archived or purged data.
For example, if you were to choose to archive credit rating history records, use a criteria algorithm that returns false if the credit rating history is not expired. Since expired credit rating history records do not contribute to the aggregate summary, it is not necessary to develop a processing algorithm.
For examples of archive processing algorithms, refer to Sample Archive and Purge DB Processes.
Design and Develop Archive Copy Processing Algorithms
If you are archiving production data to flat files, you need to write the archive copy data algorithms that writes the archived data to flat files. If you intend to reload the flat files into an archive environment, your algorithms should be written to structure the flat files so that they can be easily imported using your DB tools.
This section describes the archive and purge DB processes that exist in the demonstration database. We have provided sample Archive and Purge DB processes for the most complex high-volume transaction data. It may be useful to copy these DB processes from the demonstration database. Refer to How To Copy Samples From The Demonstration Database.
Because of the logic in the criteria algorithms used to minimize the number of inter-database foreign key references, sample archive procedures should be performed in the order they appear in this document.
For more information on the execution order of sample archive processes, open the help index and navigate to the index entry labeled background processes / system processes - archive and purge.
Contents
How To Register an Archive Environment
Performance Tuning Tips For Archive
How To Copy Samples From The Demonstration Database
How To Register an Archive Environment
A database administrator must execute the environment registration utility, as administrative access is required. This utility is also used to deregister and reregister environments.
EnvSetup Registration Script
The EnvSetup registration script provides two options for archiving.
Production and Archive Environments on separate Oracle Instances
Production and Archive on the same Oracle Instance:
Production and Archive Environments on separate Oracle Instances
Prior to Oracle Utilities Customer Care and Billing V210, super views were created for most of the application objects in a given archiving database under the CISREAD archive schema. These super views are a union view of production data and archived data. In Oracle Utilities Customer Care and Billing V230, the registration scripts initially creates synonyms for all application objects in the archive database pointing to the production schema using a CISREAD to CISREAD relationship. The super views are created only for archived database tables via the ArcSetup script. There is no other change in configuration for registration using this option.
Production and Archive on the same Oracle Instance:
In Oracle Utilities Customer Care and Billing V230, the support for archiving has been extended to allow for two schemas within the same Oracle instance. Since both Production and Archive schema’s data is being processed within the same Oracle instance, the configuration eliminates data processing over database link and improves performance for the archiving process. The following diagram illustrates the relationship between Production and Archive schemas.
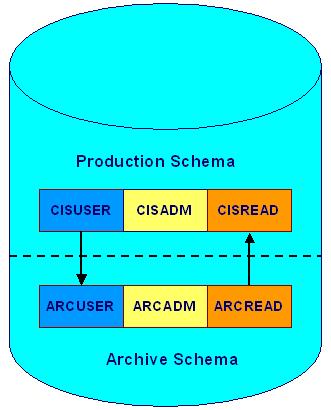
Production and archive on the same Oracle instance
Notice that the database relationship originating from the production CISUSER schema references the ARCUSER schema in the archive schema. A database relationship originating from the archive ARCREAD schema references the CISREAD in the production schema. Archive database processes that are run from the production environment move data into a given archive environment. When the process populates tables in an archive schema, the CISUSER to ARCUSER database relationship is used. So that archived data may be viewed along with production data in an archive environment, the ArcSetup script creates super views of archived tables by defining a union of the production database tables with a given archive environment’s corresponding database tables. These super views replace the "CI_" synonyms normally defined under the ARCREAD schema in the archive environment. When a user logs on to an archive environment and navigaytes around the system, the data presented is from the super views. To accomplish this, synonyms from ARCUSER in the archive environment database tables are unioned with the CISREAD production database synonyms over the ARCREAD to CISREAD database relationship. The super views are created only for the tables that are archived and ofcourse, they are read only.
Since most application objects in a given archiving schema access an archive environment’s data under its ARCREAD schema. This implies that an application server and web server must be installed and configured to reference the ARCREAD schema, not the ARCUSER schema. In order to move the data from production schema into archive schema and to view archived data along with production data, the registration utility generates required security grants for CISUSER and ARCREAD users.Oracle (EnvSetup)
The registration utility may be executed from any workstation configured to connect to both the production environment database and the supporting environment database.
In this example, we describe how to register an Archive environment. We'll call the production environment database "CCBPROD" and the Archive environment database "CCBARCH".
You may specify the following parameters on the command line. If parameters are not supplied, the registration utility prompts for them:
· Information about the production environment database:
· Name of the database
· System database user password
· Application schema owner database user
· Database user with read-write privileges to the application schema
· Database user with read-only privileges to the application schema
-r CCBPROD,{system password},CISADM,CISUSER,CISREAD
· Information about the supporting environment database:
· Name of the database
· System database user password
· Application schema owner database user
· Database user with read-write privileges to the application schema
· Database user with read-only privileges to the application schema
-s CCBARCH,{system password},CISADM,CISUSER,CISREAD
· Action:
· I-Install (register), U-Reconfigure (reregister), D-Uninstall (deregister)
-a I
· Environment type of the supporting environment:
· CMPS-Compare Source, SYNT-Sync Target, CLAB-ConfigLab, ARCH-Archive
-t ARCH
· Environment reference code:
· The environment reference used to retrieve information about the supporting environment from the production environment.
-e PROD-ARCHIVE
· Name prefix:
· The prefix character used to reference database tables in the supporting environment from the production environment. Note that this character must not be C, S, or a name prefix used by an existing supporting environment.
-n A
· Environment description:
· Description of the environment reference.
-d Production Archive Environment
· Source database link name:
· Name of the database link from the production database to the supporting environment database.
-x CCBPRODCISUSER-CCBARCHCISUSER
· Target database link name:
· Name of the database link from the supporting environment database to the production database. Not specified for Compare Source or Sync Target environments.
-y CCBARCHCISREAD-CCBPRODCISREAD
· Oracle character set:
· The Oracle character set specified for the production database.
-c {Oracle character set}
· Apply changes to the databases:
· Specify this parameter to apply the changes directly instead of writing them to a log file.
-u
· Log file name:
· Specify the name of the log file if the parameter above was not specified.
-l {log file name}
}
ArcSetup
The ArcSetup utility is provided to configure pre-archive and post-archive tasks for an archive environment.
Pre-Archive Tasks
The utility performs the following tasks if the action type is “B”:
· Generates the DDL for the tables that are associated with DB Process
· Gen_Index.sql
· Enable_Pkey.sql
· Drops the indexes and disables any primary key constraints for the tables that are associated with DB Process.
Post-Archive Tasks
The utility performs the following tasks if the action type is “A”:
· Drops the synonyms for the tables that are associated with the DB Process in the schema with read only privileges to the application schema
· Generates super views for the tables that are associated with the DB Process in the schema with read only privileges to the application schema
· Logs on to SQLPlus as the application schema owner and executes scripts: Gen_Index.sql, Enable_Pkey.sql
Executing ArcSetup
The utility may be executed from any workstation configured to connect to both the production environment database and the archiving environment database.
In this example, we describe how to setup an Archive environment. We'll call the production environment database "CCBPROD" and the Archive environment database "CCBARCH".
· Information about production database:
· Name of Archiving Database
· System Database user password
· Application schema owner database user
· Database user with read only privileges to the application schema
-d CCBPROD,manager,CISADM,CISREAD
· Action:
· A-After Archived, B-Before Archiving
-a B
· DB Process Name:
-p CIARC_BI
· Log file name:
· This is an optional parameter if not specified the log file will be generated with ArcSetup.log
-l {log file Name}
Performance Tuning Tips For Archive
· Generate database statistics prior to running the archive DB process
· Execute ArcSetup to drop the indexes for the table that are being archived by the DB process
· After moving the data from production to archive, generate the database statistics in both Production and Archive environments
· If the Production and Archive schemas are setup in the same Oracle Instance, extra care needs to be taken for configuring the instance parameters, SGA, distributing data files across multiple disks/disk controllers. Also, archive jobs are resource intensive and need to be scheduled during off production hours
· Database activities need to be monitored for archival job #3; performance can be improved if the recursive reference indexes would be created for the duration of archiving run on production tables. Execute the following SQL in order to retrieve the list of tables/columns for the DB process. Please note that any custom indexes can only be useful for archiving jobs, they can be overheads for non-archiving jobs
SELECT DISTINCT DI.MAINT_OBJ_CD,
MO.TBL_NAME,
CF.CONST_ID,
CF.SEQ_NUM,
CF.FLD_NAME
FROM CI_DB_INSTR DI,
CI_MD_MO_TBL MO,
CI_MD_CONST CO,
CI_MD_CONST_FLD CF
WHERE DI.DB_PROC_CD = <input DB Process Code>
AND MO.MAINT_OBJ_CD = DI.MAINT_OBJ_CD
AND CO.TBL_NAME = MO.TBL_NAME
AND CO.REF_CONST_ID IN (SELECT C2.CONST_ID
FROM CI_MD_CONST C2
WHERE C2.TBL_NAME = CO.TBL_NAME)
AND CO.CONST_ID = CF.CONST_ID
AND CO.CONST_ID NOT IN (SELECT MDT.PRNT_CONST_ID FROM CI_MD_MO_TBL MDT WHERE MDT.MAINT_OBJ_CD = MO.MAINT_OBJ_CD)
AND CO.CONST_ID NOT IN (SELECT DPP.LNKG_CONST_ID FROM CI_DB_INSTR DPP WHERE DPP.DB_PROC_CD = DI.DB_PROC_CD)
ORDER BY 1,2,3
How To Copy Samples From The Demonstration Database
Warning! If you are not familiar with the concepts described in the ConfigLab chapter, this section will be difficult to understand. Specifically, you need to understand how a Compare DB process is used to copy objects between two databases. Please take the time to familiarize yourself with this concept before attempting to copy the sample Archive and Purge DB processes from the demonstration database.
The demonstration database contains several sample Archive and Purge DB processes. The topics in this section describe how to copy the sample Archive and Purge DB processes from the demonstration database to the production environment. The following assumes that the demonstration environment has been registered as a Compare Source supporting environment in your production environment.
Contents
If You Work In A Non-English Language
Set Up A DB Process To Perform The Copy
Set Up Archive Adjustment Type
If You Work In A Non-English Language
The demonstration database is installed in English only. If you work in a non-English language, you must execute the NEWLANG background process on the demonstration database before using it as a Compare Source supporting environment. If you work in a supported language, you should apply the language package to the demonstration database as well.
If you don’t execute NEWLANG on the demonstration database, any objects copied from the demonstration database will not have language rows for the language in which you work and therefore you won’t be able to see the information in the target environment.
Set Up A DB Process To Perform The Copy
You need to configure a DB process in your target environment that copies the sample archive and purge DB processes from the demonstration environment. This is confusing because you are configuring a DB process in one environment that copies DB processes from another.
First, set up batch controls to “copy sample archive/purge processes”. Our suggestion is to duplicate the CL-COPDB batch control, as this is a system installed batch control that has the correct program name and batch parameters used to compare data between two environments. Make sure to populate the environment reference batch parameter with the environment reference of the demonstration environment.
Next, set up a DB process to “copy sample archive/purge processes”. Our suggestion is to duplicate the CL-COPDB DB process, as this is a system installed DB process configured to copy other DB processes. For clarity make the name of the duplicated DB process match the name of the duplicated batch control. Also, make sure you change the override condition table rules on the Primary DB process instruction:
· Process Sequence: 10
· Maintenance Object: DB PROCESS (DB Process, CI_DB_PROC)
· Instruction Role: Primary
· Table rules:
· Table: CI_DB_PROC
· Override Condition: #CI_DB_PROC.DB_PROC_CD LIKE ‘CI_ARC%’ OR #CI_DB_PROC.DB_PROC_CD LIKE ‘CI_PUR%’
This assumes that you want to copy all of the DB processes prefixed with CI_ARC or CI_PUR to your target environment. You may replace the table rule’s override instruction with a WHERE clause defining any desired DB processes you want to copy from the demonstration database.
Run The Background Processes
When the background process that you set up by duplicating CL-COPDB batch control runs, it highlights differences between the “copy archive/purge process” DB processes in the demonstration environment database and your target environment database.
The first time you run this process, it creates root objects in your target environment database to indicate the copied DB processes will be added. You can use the Difference Query to review these root objects and approve or reject them.
Automatic approval. When you submit the background process, you can indicate that all root objects should be marked as approved (thus saving yourself the step of manually approving them using Difference Query).
Next duplicate the CL-APPCH batch control, as this is a system installed batch control that has the correct program name and batch parameters used to apply the changes of approved root objects created by the first batch process. Populate the identifier of the Compare DB process in the appropriate batch parameter.
After you’ve approved the root objects, submit the background process associated with the duplicated CL-APPCH DB process to add the DB processes to your target environment.
Set Up Archive Adjustment Type
Since the financial archive processes must maintain aggregate summaries, an archive adjustment type is necessary. The sample archive processes reference the processing algorithm CI_ARPR-FT. This algorithm references adjustment type ARCADJ. Before executing an archive process for financial entities using the sample Archive DB processes, add the ARCADJ adjustment type:
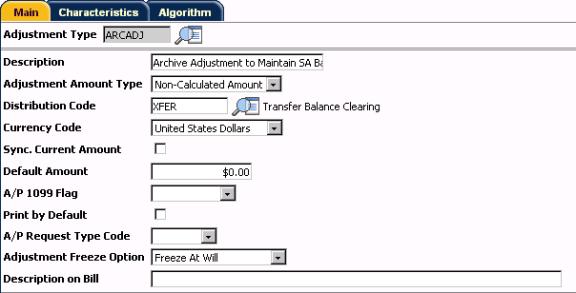
Archive Adjustment Type - Main

Archive Adjustment Type - Algorithm
Distribution Code. Since the archive adjustment has no general ledger impact, the distribution code may be any valid distribution code.
Financial Algorithm. Although the chosen algorithm specifies Payoff Amt = 0, an archive adjustment itself may indeed have a payoff amount when calculated.
Remember that the Archive Engine may be used to archive or purge data in environments other than production. While archiving from environments other than production may not make sense, purging from an archive environment has merit. Over time, the amount of data kept in an archive environment has the potential to mount. This is especially true if you archive fast growing tables on a regular basis.
Purging data from an archive environment is not really any different from purging from the production environment. In order to purge from an archive environment, you need to log into it under the CISUSR schema. This means a web server and application server must process data against this schema. This is not the same application server that processes data against the CISREAD schema, where view-only data is presented from the super views.
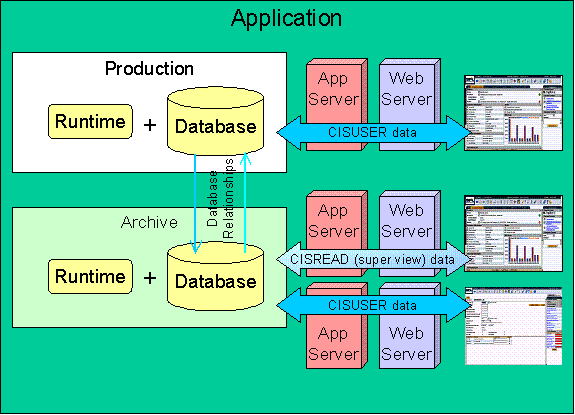
Accessing Environments
Once logged into the archive environment under the CISUSR schema, you execute a purge procedure to purge a subset of the archived data. You need to set up DB processes within the archive environment for purging the archived data.
Refer to Metadata and Archive Purge Procedures for information on configuring DB processes for archive and purge.
Example - Purge From an Archive Environment
Let's say that for the last five years, you have archived pay event data that is two years old or older to an archive environment. Now you want to implement a purge of the pay event data in the archive environment that is four years old or older.
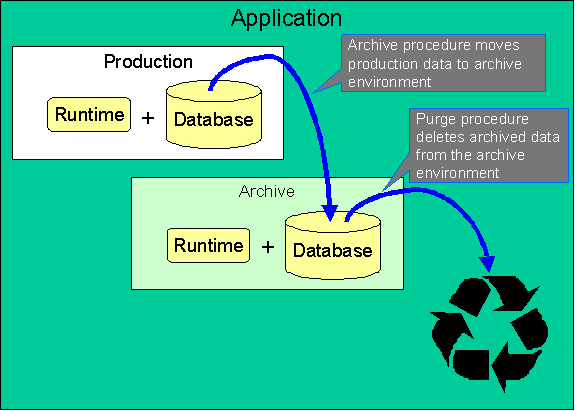
Purging from an Archive Environment
To perform the purge, you need to set up a batch control and a Purge DB process in the archive environment. The Purge DB process instructions for the pay event purge would look like this:
|
Proc Seq |
Maintenance Object |
Parent Seq |
Constraint |
Parent MO Table (from Constraint) |
|
10 |
Pay Event |
- |
- |
- |
|
20 |
Payment |
10 Pay Event |
Pay Event Id |
CI_PAY_EVENT |
|
30 |
FT |
20 Payment |
Sibling ID |
CI_PAY_SEG |
PAY EVENT Maintenance Object Instruction Algorithm:
· Sequence: 10
· System Event: Purge Criteria
· Algorithm: An algorithm whose program logic returns false if the pay event is four years old or less. Alternatively, a table rule may be used.
FT Maintenance Object Instruction Algorithm:
· Sequence: 10
· System Event: Purge Processing
· Algorithm: (an algorithm of type PRPR-FT, this algorithm would have the "Modify Balance Control" parameter set to N)