Data Quality Management
This chapter describes administering Data Quality Management (DQM), including setting up word replacements, defining attributes and transformations, defining match rules, maintaining the staged schema, maintaining the Merge Dictionary, and diagnosing DQM setup.
This chapter covers the following topics:
- Data Quality Management Overview
- Administering Data Quality Management
- Word Replacements
- Attributes for DQM
- Transformations Overview
- Defining Attributes and Transformations
- Match Rules Overview
- Defining Single Match Rules
- Defining Match Rule Sets
- DQM Compile All Rules Program
- Quality Adjusted Search Results
- Viewing Match Rules
- Staged Schema
- Merge Dictionary Overview
- Creating Custom Merge Master Party Defaulting Method
- Automerge
- DQM Diagnostic Reports
Data Quality Management Overview
Oracle Trading Community Architecture Data Quality Management (DQM) is a set of tools and features that provide powerful searching and matching functionality for search, duplicate identification, duplicate prevention, and other data management features. With a sophisticated matching mechanism, DQM can determine records that match specified search criteria, or records that are potential duplicates of another record.
TCA and other Oracle applications integrate Data Quality Management functionality for various purposes, including:
-
Searches for parties, addresses, contacts, and contact points in the TCA Registry.
-
Prevention of duplicate entry into the Registry when records are created or updated.
-
Identifying possible duplicates that currently exist in the Registry.
For the purposes of matching records, DQM takes into account that records can contain typographical errors, spelling errors, or incomplete data. DQM copies the data into staged tables separate from the TCA Registry, and transforms and standardizes the staged records. With fuzzy searches through the transformed data in the staged tables, a set of possible matches in the TCA Registry is established.
For resolving duplicates, DQM also lets you define a repository of the entities and procedures that are processed when parties are merged. DQM also provides an Automerge feature to automatically merge records that exceed a specified threshold.
Note: If you have information from source systems in the TCA Registry, DQM uses the Single Source of Truth record for each party. See: Single Source of Truth Overview.
Related Topics
Data Quality Management Examples
Data Quality Management Process
Administering Data Quality Management
Major Features
Data Quality Management provides various features that work together as a powerful and flexible data transformation and matching tool. These features are integrated with TCA and can be used by any Oracle E-Business Suite application to search and identify duplicates.
Attribute Search in Entities
DQM uses attributes in these four entities, which are a subset of the TCA Registry, to search and identify matches:
-
Party
-
Address
-
Contact
-
Contact Point
Most of the attributes correspond to a table column in the TCA Registry tables. For example, party name is an attribute of the party entity, and the value for this attribute is obtained from the HZ_PARTIES table. The party name can be one attribute that you use to evaluate if two parties are duplicates or matches, for example John Smith and Jon Smith.
You can add custom attributes if the predefined attributes do not meet your needs. These custom attributes, along with special seeded logical attributes, do not correspond to a TCA Registry column.
See: Attributes for DQM.
Predefined and Customizable Search and Match Functionality
You can use predefined transformations and match rules to search and identify matching records. Transformations transform party, address, contact, and contact point attribute values into standardized representations for high quality matching. In addition to the seeded transformations, DQM provides seeded word replacement lists in American English that transformations can optionally call upon. Match rules determine and evaluate the results of the matching process.
You can define and implement custom transformations to optimize the match rules for your environment and application. You can also set up your match rules to meet your business needs.
Transformations and Word Replacements
Transformations transform data into representations that are more similar for matching purposes. For example, transformations can replace double letters with only one of the letters, as well as remove nonalphanumeric characters and vowels. A transformation that removes vowels would change, for example, both values for an address attribute, 123 Main Rd and 123 Mane Road, into 123 MN RD. This transformation allows the two attributes to be determined a match, minimizing the effects of potential spelling errors, such as Mane, and data entry inconsistencies, such as Rd versus Road.
Transformations use word replacement lists which create synonyms that are treated as equivalents for searching and matching. You can use word replacements to standardize certain portions of your party data to minimize the effect of data entry inconsistencies on searches. For example, a word replacement transformation can replace California, Calif, and ca with CA.
See: Word Replacements and Transformations Overview.
Match rules determine whether two parties should be identified as a match or potential duplicate. DQM match rules can be applied, for example, when you:
-
Search for TCA Registry information using search interfaces.
-
Run a duplicate identification process.
-
Enter or update party information through user interfaces, import interfaces, or APIs, for duplicate prevention.
Match rules support score-based matching and consist of two parts, acquisition and scoring criteria. Acquisition provides an initial set of possible matches, and scoring assigns scores to attributes to further filter matches and rank the results.
When you define match rules, you can specify which attributes are important for matching and configure how the attributes should be evaluated. For example, you can define a match rule so that only records with the same transformed party name and party number attribute values are considered matches. You can also determine how matching or similar attributes are scored to produce a total score that you can use to evaluate a record. To each attribute that you use in a match rule, you also assign transformations.
See: Match Rules Overview.
Staged Schema
The staged schema is a mirror of a portion of the TCA Registry and contains data that transformations have cleansed and standardized. Matches are determined by comparing an input record against the transformed records in the staged schema, which is separate from the TCA Registry. The Registry itself is not transformed or searched at any time. The staged schema is shared across all Oracle E-Business Suite applications.
Searches through the staged schema are actually searches against the interMedia or B-Tree indexes that index the schema and speed up the search process. During the acquisition phase of matching, the indexes quickly limit the number of parties to evaluate for scoring.
You can run programs in DQM to generate or update the staged schema and the indexes. For accurate searches, the staged schema can be automatically synchronized with the TCA Registry when records in the Registry are created or updated through user interfaces or TCA import.
See: Staged Schema.
Merge Dictionary
The Merge Dictionary contains the entities and procedures that are processed during party merges. You define how duplicate parties are to be merged and in what order. See: Merge Dictionary Overview.
Automerge
Automerge is a process that can be implemented as part of duplicate identification. Based on the setup, Automerge automatically merges records that exceed a specified threshold. See: Automerge.
Duplicate records can be identified when a Create or a Save Web service (create operation) is invoked. Automerge is run based on the criteria specified in the match rule
Data quality is enabled based on the profile HZ: Enable DQM for Integration. When a Create or Save Web service (create operation) is invoked,
-
If data quality is enabled, then duplicate identification is based on the Match Threshold and the Automerge Threshold values specified in the match rule.
-
When an organization or person (party) is created in Customer Data Hub, the parties are merged based on the following criteria:
-
If the match score is less than the Match Threshold value, then the newly created party is retained.
-
If the match score is more than or equal to the Match Threshold value, but less than the Automerge Threshold value, then a merge request is created to merge an existing party and the newly created party.
-
If the match score is more than or equal to the Automerge Threshold value, then the existing party and the new party are automatically merged.
-
Globalization
Various features support using DQM in different countries and languages, including:
-
Nondelimited word replacements for languages in which words are not defined as consecutive characters separated by spaces.
-
Word replacements that occur only if specific conditions are met. For example, the word is replaced only if it occurs at the beginning or end of the string.
-
Seeded transformations that support data from most Latin-based languages.
-
Match rule sets that contain multiple match rules, with conditions to determine which rule is used, for example conditions based on the Country attribute.
Related Topics
Data Quality Management Overview
Data Quality Management Examples
These examples illustrate using Data Quality Management to identify existing duplicates, search for parties, or prevent duplicate entries.
For a party called International Party Duplicates, the party name could have been entered in different ways, such as International Party Duplicates, Inc. or IPD.
You use a transformation to remove all nonalphanumeric characters and terms such as Corp and Inc, and then normalize party names into three-letter acronyms in the staged schema. Define match rules and search for duplicates.
As a result, the entries in this table are displayed as possible duplicates:
| Original Value | Transformed Value in Staged Schema |
|---|---|
| IPD | IPD |
| I.P.D. | IPD |
| IPD Corp. | IPD |
| Intl Party Duplicates | IPD |
| International Party Duplicates | IPD |
| International Party Duplicates, Inc. | IPD |
Searching for Parties
An Oracle application has implemented DQM to create a search interface that you enter search criteria in. Transformations were created, including one that uses the DQM PL/SQL function Soundex, and the results were populated into the staged schema.
You want to search for parties of type Person with the last name Smyth who are located in California. The last name could have been misspelled and entered in different ways, such as Smith or Smythe. You enter Smyth and California in the search interface, and the Oracle application applies a match rule that includes a filter for the state of California and searches through the staged schema for search results.
This table shows the original entries in your TCA Registry.
| Name | Location |
|---|---|
| Smith, James | Redwood Shores, California |
| Smith, Virginia | Seattle, Washington |
| Smyth, Edward | Los Angeles, California |
| Smyth, Helen | New York City, New York |
| Smythe, Joseph | Los Angeles, California |
This table shows the Soundex representation for these names:
| Name | Soundex Representation |
|---|---|
| Smith | S260 |
| Smyth | S260 |
| Smythe | S260 |
The search finds the entries in this table as possible matches:
| Name | Location |
|---|---|
| Smith, James | Redwood Shores, California |
| Smyth, Edward | Los Angeles, California |
| Smythe, Joseph | Los Angeles, California |
Preventing Duplicate Entries
DQM was implemented to enforce the policy that no duplicates are allowed for matches on the combination of cleansed party name and address. Transformations were defined that remove all vowels and double letters, and a match rule was also defined that best expresses the policy.
As a result, you avoid populating the duplicate entries in the TCA Registry, shown in this table, because their transformed records are identical:
| Original Record | Transformed Record |
|---|---|
| Allison Byrne, 123 S. Main Str. 11111 | ALSN BRN, 123 MAIN, 11111 |
| Alisen Burn, 123 South Main Street, 11111 | ALSN BRN, 123 MAIN, 11111 |
Related Topics
Data Quality Management Overview
Data Quality Management Process
This diagram illustrates how the different features of Data Quality Management work together to find matches and duplicates.
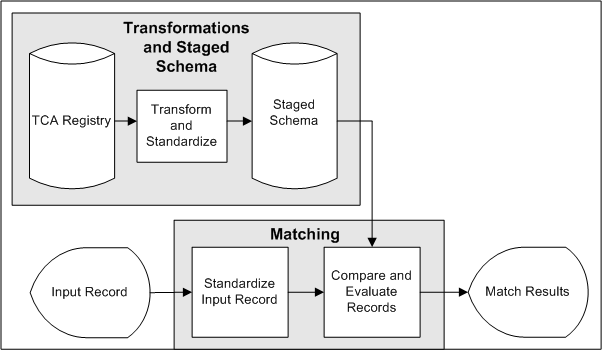
-
The TCA Registry contains party information that could have been entered with typographical errors, spelling errors, and aliases.
-
You run the DQM Staging program to transform and standardize the attribute values, such as party name and number, in a copy of the Registry, the staged schema. The attributes to include in the schema, as well as the transformations to use on each attribute, are defined in the Define Attributes and Transformations page.
-
The staged schema stores the transformed attribute values, separate from the original Registry.
-
Input records come in when you enter or search for party information, or run a duplicate identification process.
-
The transformations in a match rule transform the attribute values in the input record.
-
The same match rule is applied to compare the transformed input record attributes against the attributes in the staged schema.
-
Based on how the attributes match up, potential matches from the staged schema are identified for the input record. If the match rule contains scoring criteria, the selected records from the staged schema are also scored.
Bulk Duplicate Identification
Bulk duplicate identification is a particular DQM process to identify duplicates for a large number of records within the TCA Registry. The process involves:
-
B-Tree indexes in the staged schema.
-
Match rules with the Bulk Duplicate Identification purpose, which include acquisition attributes and transformations that are defined for bulk duplicate identification.
Instead of comparing against the staged schema one at a time for each input record, as with simple duplicate identification, bulk duplicate identification compares the whole set of input records at once through a join procedure in the staged schema.
This diagram illustrates the bulk duplicate identification process:
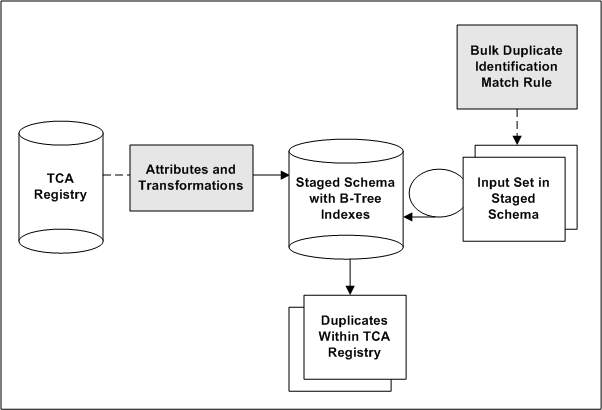
-
TCA Registry attributes are transformed for the staged schema. The attributes to include in the schema, as well as the transformations to use on each attribute, are defined in the Define Attributes and Transformations page.
Also defined are the attribute and transformation combinations to be used for bulk duplicate identification. The staged schema includes B-Tree indexes only for the transformed attributes marked for bulk duplicate identification.
-
A duplicate identification process is started, either for a subset of records in the TCA Registry or for the entire Registry. The transformed version of that set of input records is already represented in the staged schema.
-
A match rule with the Bulk Duplicate Identification purpose is applied, and the input set within the staged schema is joined with the staged schema.
Each record in the input set is simultaneously compared against all other records in the same staged table using only B-Tree indexes.
-
Based on how the attributes match up, potential duplicates from the staged schema are identified. If the match rule contains scoring criteria, the selected records from the staged schema are also scored.
Related Topics
Data Quality Management Overview
Administering Data Quality Management
To utilize and implement Data Quality Management (DQM) functionality, you must set up and administer the DQM tools. These tools are integrated with TCA and can be used by any Oracle Applications E-Business Suite application to search the TCA Registry and identify or prevent duplicates.
To administer Data Quality Management:
-
Review information about the current DQM setup. See: DQM Administration Overview Page.
-
Note: To set the HZ: Merge Master Party Defaulting profile option to User Hook, you must create a custom user hook. See: Creating Custom Merge Master Party Defaulting Method.
-
At any time, you can run Diagnostic reports to get comprehensive details about the current DQM setup. See: DQM Diagnostic Reports.
Related Topics
Data Quality Management Overview
Introduction to Administration
DQM Administration Overview Page
The DQM Administration Overview page provides basic information about the current Data Quality Management setup. For each possibly displayed informational message, these tables tell you where to go for more details.
| Informational Message | See |
|---|---|
| One or more TCA records failed to synchronize. Run the DQM Setup - Detailed diagnostic report for more information. | DQM Diagnostic Reports |
| TCA data has not been staged. Set up attributes, transformations, and word replacement lists, and run the DQM Staging Program with the Stage All Data staging command. | |
| The DQM synchronization method is set to: <method>. | DQM Synchronization Method |
| Informational Message | See |
|---|---|
| The transformations <transformation names> have been added to this attribute: <attribute name>. | Defining Attributes and Transformations |
| Values were added or removed for these word replacement lists: <word list name>. | Creating and Updating Word Replacement Lists |
Related Topics
Administering Data Quality Management
Word Replacements
With word replacement, you can identify words that act like synonyms of other words for the purpose of searching and matching. Transformations can use word replacements.
Word replacement is a particularly useful technique for standardizing certain portions of your party information to minimize the effect of data entry inconsistencies on searches. You can use these word replacements in the development of transformations. In the PL/SQL functions used in transformations, code can be written to call a word replacement list.
Word replacement lists contain word pairs, each pair with an original and replacement word. The replacement word is used when the original word is identified and any specified conditions are met. Aside from using seeded conditions, you can also create your own conditions. See Creating Custom Word Replacement Conditions.
For example, this table displays possible original words for a replacement word in a word list for a specified language.
| Word List Name | Language | Original Word | Replacement Word |
|---|---|---|---|
| Person Name | American English | Bob | Robert |
| Person Name | American English | Rob | Robert |
| Person Name | American English | Robbie | Robert |
| Person Name | American English | Roberto | Robert |
| Person Name | American English | Bobby | Robert |
When you enter Rob as the value for a first name attribute of a search, the search returns records in which the first name attribute matches to the replacement word for Rob. The result of your search would return records containing Bob, Robbie, Roberto, Bobby, and Robert as well as Rob.
Seeded and Custom Word Replacement Pairs
DQM provides word replacement lists containing over 3,000 word replacement pairs in American English. The included word lists are:
-
ADDRESS_DICTIONARY
-
DOMAIN_NAME_DICTIONARY (used for e-mail and URLs)
-
EXPANDED_PERSON_NAME_DICTIONARY
-
KEY MODIFIERS
-
ORGANIZATION_NAME_DICTIONARY
-
PERSON_NAME_DICTIONARY
-
US_STATE_DICTIONARY
See: Seeded Word Replacement Lists, Oracle Trading Community Architecture Reference Guide.
You can add to the lists of seeded word replacement pairs in American English or create lists in any other languages supported by Oracle Applications.
Administering Word Replacements
This table describes some terms in the pages used for this procedure.
| Term | Description |
|---|---|
| Identification Method | The method that the original word in a word pair is identified by:
|
| Data Source | Source of the word list, for example Seeded for seeded lists. |
To administer word replacement lists, you can:
-
Create, update, or copy word lists. See: Creating and Updating Word Replacement Lists.
-
Delete word lists only if they are not seeded.
Related Topics
Data Quality Management Overview
Creating and Updating Word Replacement Lists
Although DQM provides over 3,000 word replacement pairs in American English, you can modify the provided lists or create lists of word replacement pairs with words that users often enter with errors or as shortcuts.
The fuzzy key generation program uses only the following 3 word lists for fuzzy search
-
ADDRESS_DICTIONARY – for address
-
ORGANIZATION_NAME_DICTIONARY – for organization
-
PERSON_NAME_DICTIONARY – for person
You cannot create your own replacement list, but must update any of the applicable lists listed above, for fuzzy search.
Important: A new word list is not used until you create custom transformations that use the list. See: Creating Custom Transformations.
Procedure to Select the Word Identification Method
When you create or copy a word list, you must specify the word identification method. You cannot change the method when you update a list.
Note: The Nondelimited method is usually used for relevant non-English languages, such as Japanese, that are based on characters, not words separated by spaces.
John is the original word, Jonathan is the replacement word, and the attribute value is John Johnson. If the word replacement with the Delimited method is applied, then the attribute value becomes Jonathan Johnson, because only John surrounded by spaces is replaced. If with Nondelimited, then the value becomes Jonathan Jonathanson, because John is replaced no matter where it appears.
Procedure to Enter Word List Information
This table describes some terms in the pages used for this procedure.
| Term | Description |
|---|---|
| Condition | Criterion that must be met for the word replacement to occur. Conditions are particularly useful for country-specific word replacements. For example, in the UK, LTD or Limited is a common organization name suffix. You can specify to replace either word with a blank space only if it appears at the end of a string. |
-
Enter a unique word list name, and optionally define the source of the list, for example to identify a list that you created or obtained from a third party. When you update an existing list, you can change the name and source, but not the language.
-
Define word replacement pairs.
-
No matter which word identification method is selected, do not enter original words with spaces.
-
For original and replacement words, you can enter not only whole words, but also abbreviations, word fragments, and numeric characters. For example, you can create a word replacement pair by entering 1 as the original word and one as the replacement word. If a user enters 1 to perform a search, then one is used to search your party information.
-
Replacement words do not have to be unique and can be left blank. You cannot, however, use the same word as both an original and replacement word in the same word list. For example, you cannot have Street to be replaced by St. in a word pair, and also St. to be replaced by Saint in another word pair.
You can create several word replacement pairs that have different unique original words with the same replacement word. This table shows an example:
Original Word Replacement Word Bob Robert Rob Robert Robbie Robert Roberto Robert Bobby Robert
-
-
For any word pair, optionally enter a condition.
You can use the same original word multiple times in a list only if the replacement words and conditions are different. For example, you can enter St. twice as an original word to be replaced by the replacement words Street and Saint, with a condition for each case.
Important: If you use original words multiple times, the conditions are applied in the order defined, and a word is replaced according to the first condition that is met. For example, if the St. and Street word pair is defined first, and that condition is met, then the word replacement occurs. The condition for the St. and Saint word pair is skipped.
-
You must enter a value after the condition if the field is not disabled. If multiple values are possible, for example for the seeded If Country Equals condition, separate each value by a comma.
-
After you add or modify word replacement pairs, run the DQM Staging program to update the staged schema to include the new or revised word replacement pairs. In the Original Word column, Staging Required indicates the word pairs that still need to be staged.
For any record that you add to or update in the TCA Registry, the word replacement pairs become immediately effective after the DQM Staging program finishes. See: DQM Staging Program.
Related Topics
Word Replacements Tips
When you create and use word replacements, consider these issues:
-
Avoid recursive word replacement pairs that can generate inconclusive results.
For example, you need to create word replacements for common variations of a name such as Caroline, Carolyn, Carolan, Carole, and Carol.
This table shows an example of effective word replacement pairings of original and replacement words.
Effective Word Replacement Pairs Original Word Replacement Word Caroline Carol Carolyn Carol Carolan Carol Carole Carol This table shows an example of ineffective word pairings using recursive word replacement.
Ineffective Word Replacement Pairs Original Word Replacement Word Caroline Carolyn Carolyn Carolan Carolan Carole Carole Carol -
Create word replacement pairs consistent with the type of party information in the word lists for person names, addresses, organization names, or states. For example, if you apply a word replacement pair for a person name to an organization name, Jonathan Deere might be used as a replacement for the company name, John Deere.
-
Create a limited number of word replacement pairs between person names and organization names.
Because some organizations are named after people, a limited number of common word replacements of person names to organization names can be appropriate. For example, your organization has regular contact with a group of professional firms such as accountants and lawyers. You can create word replacement pairs specifically for these organizations that would match person names to organization names. Word replacement pairs between different types of party information should be limited to reduce inappropriate matches.
-
Create a limited number of word replacement pairs between address-related words and organization names.
Because some organizations are named after geographical locations, a limited number of word replacements of address elements to organization names can be appropriate. For example, your organization has regular contact with the Main Street Cafe. You can create a word replacement pair specifically for this organization that would match an address element to the organization name. Word replacement pairs between different types of party information should be limited to reduce inappropriate matches.
-
Consider replacing the original word, or symbol, & with the replacement word and.
Several of the seeded transformations remove symbols such as &, that are not alphanumeric characters. If some form of conjunction is important to your searches, you should replace & with and. You can also avoid or customize the seeded transformations that remove &.
-
Consider mapping generic address-related words such as street, avenue, and so on to a blank Replacement Word field.
People often know the proper name for an address but might not know the generic portion of the address. For example, you can broaden the search criteria so that both Market Street and Market Avenue are included in the search results as possible matches. By mapping the words street and avenue to a blank Word Replacement field, you would broaden the possible matches.
See: Seeded Word Replacement Lists, Oracle Trading Community Architecture Reference Guide.
Creating Custom Word Replacement Conditions
Create custom conditions to use with word replacement pairs. You have a lot of flexibility, so make sure that the conditions you create make sense and work correctly.
Each condition includes a defined function and possible user-defined values. For example, the user must specify at least one value, such as Argentina, when defining a word pair with the seeded If Country Equals condition. If the record being evaluated has Argentina as the Country attribute, then the word replacement occurs.
On the other hand, the seeded End of String condition and does not require a user-defined value. If the original word is at the end of a string and the replacement word does not cause the entire string to be null, then the word replacement occurs.
Procedure
-
Write a custom function with this signature:
FUNCTION <custom function>( p_input_str IN VARCHAR2, p_token_str IN VARCHAR2, p_condition_id IN NUMBER, p_condition_val IN VARCHAR2) RETURN BOOLEAN;The tca_eval_condition_rec function is used for all seeded conditions. Instead of defining a new function, you can use the seeded one and write custom code in the if/elseif block for the condition_id, as shown in this example:
IS BEGIN if condition_id = 1 get_gbl_condition_rec_value( ‘PARTY_SITES’, ‘COUNTRY’ ) = ‘US’ do this and return true/false ; elsif condition_id = 2 get_gbl_condition_rec_value( ‘PARTY_SITES’, ‘ZIPCODE’ ) = ‘xxxxxx’ do this and return true/false ; else return true ; END ; -
Insert a new row in the HZ_WORD_RPL_CONDS_B table and populate the columns.
-
CONDITION_FUNCTION: The custom function that you define for the condition.
-
CONDITION_VAL_FORMAT: How many user-defined values the condition can take. This table provides examples of how the possible column values are used.
CONDITION_VAL_FORMAT Value Condition Reason None Start of String Condition does not apply to specific values Single Party Type Equals Condition requires only one party type value Multiple In Country Condition requires at least one country value Note: It is possible to implement a condition that applies to multiple attributes, for example a Party Type Equals and In Country condition. Single attribute conditions, however, are recommended.
-
Related Topics
Attributes for DQM
Attributes make up the four entities used in DQM: Party, Address, Contact, and Contact Point. Each attribute in the entities is derived from a specific column in one of the TCA Registry tables. These four entities make up the staged schema.
For example, the Party entity in DQM is named HZ_STAGED_PARTIES and contains attributes from the TCA Registry tables:
-
HZ_PARTIES
-
HZ_ORGANIZATION_PROFILES
-
HZ_PERSON_PROFILES
Examples of attributes in the Party entity include:
-
PARTY_NUMBER from HZ_PARTIES
-
DUNS_NUMBER from HZ_ORGANIZATION_PROFILES
-
MARITAL_STATUS from HZ_PERSON_PROFILES
Attributes in the staged schema contain values from the TCA Registry tables that have been transformed into representations that are more alike for the purposes of matching. Attributes, therefore, are used to search for possible matches between an input record and the TCA Registry data.
If needed, you can use up to 30 CUSTOM_ATTRIBUTE columns in each entity to store additional attributes. See: Creating Custom Attributes and Seeded Attributes, Oracle Trading Community Architecture Reference Guide.
Related Topics
Defining Attributes and Transformations
Data Quality Management Overview
Transformations Overview
Your raw party information can include typographical errors, spelling errors, inconsistent formats, and abbreviations due to input errors. For this reason, searches performed on raw values often are inconclusive or miss potential matches.
Transformations transform attribute values in the staged schema so that the values are more similar and useful for the purpose of matching records. Transformations neutralize the effects of data errors on your searches. For example, a transformation that removes all of the double letters in a party name transforms a name such as Allied Freight into Alied Freight. This transformation makes it easier to match to a party if a typographical error, such as a missing double letter, exists.
After your raw data has been transformed and populated into the staged schema, match rules can use the transformed data to score each record to determine if the record is considered alike enough to be a match to an input value.
DQM includes several standard, or seeded, transformations. You can also develop your own transformations.
Seeded Transformations
DQM provides several predefined transformations, such as Cleanse and Exact. The Exact transformation accomodates various characters in non-English languages. See: Seeded Transformations, Oracle Trading Community Architecture Reference Guide.
For example, the Cleanse transformation performs these actions:
-
Capitalizes all letters.
Zannardi-Montoya is transformed to ZANNARDI-MONTOYA.
-
Removes nonalphanumeric characters.
ZANNARDI-MONTOYA is transformed to ZANNARDI MONTOYA.
-
Reduces any white space to one space.
-
Removes double letters, retaining only one of the double letters.
ZANNARDI MONTOYA is transformed to ZANARDI MONTOYA.
-
Removes vowels except initial vowels.
ZANARDI MONTOYA is transformed to ZNRD MNTY.
The final result from the Cleanse transformation is ZNRD MNTY. This result would be populated into the staged schema.
All seeded transformations are available in packages. Not all seeded transformations are automatically populated into the staged schema. During the installation of DQM, you can decide if you want to use all of the available transformations.
To ensure that a seeded transformation is populated into the staged schema, you must define the transformation and then run the DQM Staging program. See: Defining Attributes and Transformations and DQM Staging Program.
Related Topics
Defining Attributes and Transformations
Creating Custom Transformations
Data Quality Management Overview
Defining Attributes and Transformations
Specify the attributes to use for matching, and assign transformations to each attribute. Only active attribute and transformation combinations that you define in the Define Attributes and Transformations page can be used in the staged schema and in match rules.
You define attributes and transformations for each entity used in DQM: Party, Address, Contact, Contact Point. Attributes are transformed by their assigned transformations in the staged schema.
For address, contact, and contact point attributes, you can optionally denormalize the attribute to the party level. The transformed value would be stored in the HZ_STAGED_PARTIES table instead of the staging table for the entity. You should denormalize only attributes that have a limited number of possible values, such as the Country attribute. Denormalization improve performance, but you cannot denormalize all attributes.
Procedure
This table describes some terms in the pages used for this procedure.
| Term | Description |
|---|---|
| Uniqueness | The uniqueness of an attribute value with respect to other attributes for identifying an entity. For example, for an address, the Postal Code attribute provides a more unique value, across records, than the State attribute. This uniqueness information is used for DQM searches. |
| Bulk Acquisition | Option indicating that the attribute and transformation combination can be used in acquisition for match rules with the Bulk Duplicate Identification purpose. The attribute value, as transformed by the transformation, would be indexed with B-Tree indexes, which are used only for bulk duplicate identification. See: Bulk Duplicate Identification. |
-
Select an attribute name and enter a user-defined name. Search interfaces that use DQM generally display the user-defined names, not the attribute names, as the search criteria.
If you are defining one of the 30 custom attributes, enter the name of the custom PL/SQL procedure that DQM uses to obtain the custom attribute. See: Creating Custom Attributes.
-
Indicate the uniqueness of the attribute with respect to other attributes for the entity.
-
To view or update the transformations assigned to an attribute, click Transformation Details for the appropriate attribute to display the transformations below.
Note: You cannot remove attributes that are seeded for the entity or used in seeded match rules.
-
To assign a seeded transformation, just enter the transformation name. For custom transformations, you must also enter a description as well as the PL/SQL function that is called to transform the attribute values and to return a formatted result. See: Creating Custom Transformations.
-
Default: Specify if the transformation is also selected by default when the corresponding attribute is selected to be used in a new match rule. See: Assigning Scores, Transformations, and Thresholds.
-
Bulk Acquisition: Specify if the attribute and transformation combination can be used in acquisition for match rules with the Bulk Duplicate Identification purpose.
Note: For performance reasons, select this option only when necessary.
You cannot deselect Bulk Acquisition for transformations that are used, for acquisition, in seeded match rules of Bulk Duplicate Identification purpose.
-
Active: To use the transformation, you must activate the transformation for the selected attribute.
You cannot inactivate seeded transformations if they are used in seeded match rules. You can, however, activate inactive transformations to use in custom match rules.
Note: You cannot remove transformations that are seeded for the attribute or used in seeded match rules.
-
Use Up and Down to order the transformations. For example, the CLEANSE transformation alters the original attribute value more than EXACT does. You would order EXACT before CLEANSE because the transformed value is closer to the original and provides a more precise match.
If multiple transactions have Default selected, then this order is reflected when the corresponding attribute is selected for new match rules with the Search purpose.
-
Before you can use new or updated attributes and transformations, you must generate or update your staged schema. See: DQM Staging Program.
Related Topics
Attribute and Transformation Tips
Creating Custom Attributes
You can define custom attributes for the entities used in DQM: Party, Address, Contact, and Contact Point. Up to 30 custom attributes are available in each entity.
Note: Before creating new attributes, verify that none of the seeded attributes satisfy your needs. Many seeded attributes are inactive, so be sure to check the list of inactive attributes before creating custom attributes.
Procedure
-
Write a custom procedure that obtains the custom attribute.
When a CUSTOM_ATTRIBUTE column needs information about a party, address, contact, or contact point, DQM calls a procedure with this signature:
FUNCTION <custom_attribute_proc> p_record_id IN NUMBER, p_entity_name IN VARCHAR2, p_attrib_name IN VARCHAR2, p_context IN VARCHAR2) RETURN VARCHAR2;-
p_record_id: The p_record_id value in the signature is the primary key of the table where the CUSTOM_ATTRIBUTE_PROCEDURE is defined.
This table displays the appropriate p_record_id value for each entity attribute.
Entity Attribute p_record_id Party PARTY_ID Address PARTY_SITE_ID Contact ORG_CONTACT_ID Contact Point ORG_CONTACT_POINT_ID -
p_context: The p_context value, STAGE or SEARCH, indicates whether the attribute is to be used in the context of staging or searches.
-
-
Define the custom attribute using one of the available CUSTOM ATTRIBUTE values. Enter your custom PL/SQL procedure and define transformations for the attribute. See: Defining Attributes and Transformations.
Note: If you do not plan to transform the party information for a custom attribute, then use an Exact transformation.
Related Topics
Creating Custom Transformations
You can create transforms to transform any of the TCA Registry attributes in the entities used in DQM: Party, Address, Contact, and Contact Point.
Procedure
-
Create a PL/SQL function for transforming a TCA table column.
Create the transformation in the APPS schema as a PL/SQL function that conforms to the following standard signature:
FUNCTION <transformation_function_name> p_original_value IN <ATTRIBUTE_DATATYPE> p_language IN VARCHAR2, p_attribute_name IN VARCHAR2, p_entity_name IN VARCHAR2, p_context IN VARCHAR2 DEFAULT NULL) RETURN VARCHAR2;-
p_original_value: The data type of the parameter p_original_value depends on the data type of the attribute that the parameter is transforming. The return value, however, must be VARCHAR2.
This table shows an example of p_original_value data types for different attributes.
Attribute Name Attribute Code Data Type of p_original_value Party Name PARTY_NAME VARCHAR2 Person Name PERSON_NAME VARCHAR2 Last Update Date LAST_UPDATE_DATE DATE Date of Birth DATE_OF_BIRTH DATE -
p_language: You must include this parameter, but cannot use it.
-
p_context_value: The p_context value, STAGE or SEARCH, indicates whether the transformation is to be used in the context of staging or searches.
You can use any PL/SQL procedure that adheres to the above signature as a transformation.
-
-
Assign your custom PL/SQL function to a transformation. To use the transformation, you must also assign the transformation to at least one attribute. See: Defining Attributes and Transformations.
Related Topics
Attribute and Transformation Tips
When you create and use transformations, consider these issues:
-
Design and create as many attributes and transformations as possible before populating or updating the staged schema.
After defining any new transformations for any attribute, you must run the DQM Staging program to generate or update the staged schema. Processing the staged schema can require significant computing resources and time. If you are uncertain about initially adding a transformation or an attribute with the initial group of transformations and attributes, the best strategy is to add the transformation.
-
Do not transform lookups. Lookups have a predetermined or known set of values, so you cannot transform them.
-
Remember that word replacements are called within a transformation.
-
Consider the possibility that your party information might contain compound names that were entered with the modifier following a comma.
For example, The New Datsonville could have been entered into your party information as Datsonville, The New. You can create a transformation that reverses the text before and after the comma in any city name.
-
If the Domain attribute has only domain values, use the Core Domain Extraction transformation. If the attribute has e-mail addresses, use either the Core Domain Extraction or Full Domain extraction transformation.
You can modify or add codes to the:
-
E-Mail Domain Suffixes (HZ_DOMAIN_SUFFIX_LIST) lookup type, which the Core Domain Extraction transformation uses to identify core domains.
-
ISP E-Mail Domains (HZ_DOMAIN_ISP_LIST) lookup type, which both transformations use to remove ISP e-mail domains from the matching process.
The transformation compares against the code, not lookup meaning or description.
See: Defining Receivables Lookups, Oracle Receivables Implementation Guide.
Important: Before you can use new or updated lookups, you must generate or update your staged schema. See: DQM Staging Program.
-
Match Rules Overview
Match rules determine whether two records should be identified as a match. A match rule has one of these purposes:
-
Search: Mainly for search user interfaces, but also for duplicate prevention. These match rules support matching by evaluating a series of criteria, with the ones yielding the most precise matches first, to return search results with corresponding match percentage.
-
Bulk Duplicate Identification: For identifying duplicates for a large number of records at one time, using simple logic for fast processing.
-
Expanded Duplicate Identification: For identifying or preventing duplicates, using more precise and complex logic than Bulk Duplicate Identification.
-
Integration Services: For identifying duplicates when creating customers using the Create or Save (create operation) Web services.
Match rules with Bulk or Expanded Duplicate Identification purpose support score-based matching and consist of two parts, acquisition and scoring. Acquisition provides an initial set of possible matches, and scoring assigns scores to attributes to further filter matches and rank the results.
A match rule can be of type:
-
Single: Contains a single match rule.
-
Set: Contains multiple match rules and conditions to determine which rule in the set to use. All rules in a set have the same purpose, either Search or Expanded Duplicate Identification.
Match rule sets are particularly useful for country-specific processes or entities. For example, countries use different address attributes. You can define a set that has match rules with different address attributes. The conditions would determine which match rule to use, based on the country attribute.
Administering Match Rules
-
Creating, Updating, or Copying Match Rules: Aside from letting you create new custom match rules, DQM provides seeded match rules. See: Seeded Match Rules, Oracle Trading Community Architecture Reference Guide.
You can copy and update match rules to meet your specific requirements, or to test variations of an existing custom match rule before you improve or modify the original rule.
See: Defining Single Match Rules and Defining Match Rule Sets.
-
Compiling Match Rules: After you initially install DQM, you must compile all the seeded match rules before you can use them, even if just to use them for copying. You also need to compile match rules that you create, update, or copy.
-
Compiled: PL/SQL code for the match rule has been generated. The match rule is locked against changes, but available for use. The lock ensures that the match rule and its compiled PL/SQL code are always synchronized.
-
Uncompiled: Match rule is previously saved, but now unlocked. An uncompiled match rule cannot be used until it is compiled.
You can use the Match Rules page to compile individual or all match rules, or run the DQM Compile All Rules program to compile all rules. See: DQM Compile All Rules Program.
Tip: Compile match rules outside of your organization's operational business hours, or at times when no DQM logic is used. Match rules cannot be compiled when DQM is being used for any process, for example to search for records or identify duplicates.
Before you can compile any match rule, make sure that the staged schema is generated, or run the DQM Staging program. See: DQM Staging Program.
Note: You cannot change a match rule's purpose after the match rule has been compiled at least once.
-
-
Viewing Match Rules: Click the match rule name to view the match rule definition. See: Viewing Match Rules.
-
Deleting Match Rules: Use the Match Rules page to delete any compiled, custom match rules. Before deleting a match rule, you should make sure that it is not used anywhere. If the rule is in use, replace it with another match rule or consider the consequences of deleting the rule.
Related Topics
Data Quality Management Overview
The Matching Process
The matching process depends on the purpose of the involved match rule. See:
Related Topics
Search Matching Process
This diagram describes the DQM matching process involving match rules with the Search purpose.
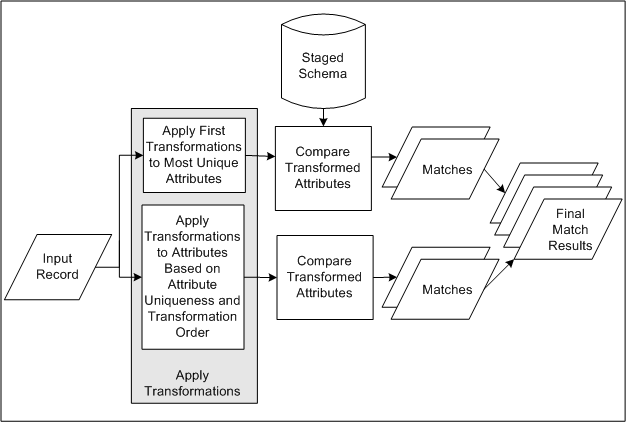
-
The staged schema stores the transformed TCA Registry attribute values for comparison in the matching process. The included attributes and the transformations applied to each are defined in the Define Attributes and Transformations page.
-
Input records come in when you enter party information or search criteria.
-
The attributes in the match rule assigned the highest level of uniqueness, as defined in the Define Attributes and Transformations page, are transformed by the transformations ordered first in the match rule based on match precision. This combination represents criteria for the most exact matches.
For example, the Address 1 attribute provides a more unique value, across records, than the City attribute. The EXACT transformation, which modifies values less than the CLEANSE transformation, would provide more precise matches based on the transformed values. So Address 1, defined as the most unique attribute for the Address element, is first transformed by EXACT.
-
The attribute values in the input record that are transformed by the transformations in the match rule are compared against the attribute values in the staged schema to determine matches.
Note: In order for an attribute to be shown to the user during search, the attribute must be set for acquisition or both scoring and acquisition. It should not be set at scoring only as the attributes will not be displayed on the UI.
-
For each entity, steps 3 through 4 are repeated in sequence of attribute uniqueness and transformation order.
-
When a maximum number of matches is reached, the match results are returned. Search results from the first sequence, with the most exact criteria, would have the highest match percentages.
Related Topics
Expanded Duplicate Identification Matching Process
This diagram describes the DQM matching process involving match rules with the Expanded Duplicate Identification purpose.
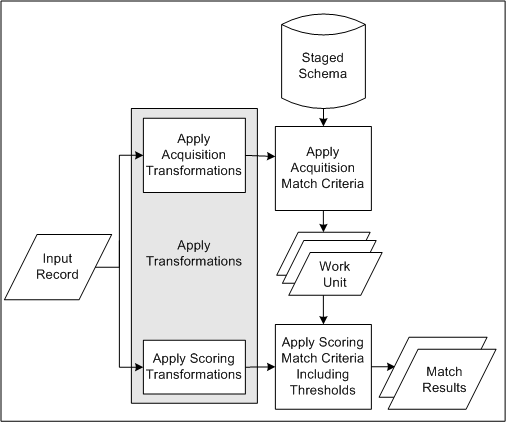
-
The staged schema stores the transformed TCA Registry attribute values for comparison in the matching process. The included attributes and the transformations applied to each are defined in the Define Attributes and Transformations page.
-
Input records come in when you enter party information, or run a duplicate identification process.
-
Transformations from the acquisition and scoring phases of the match rule transform the input record, one entity at a time, for the attributes defined in the match rule.
-
The attribute values in the input record that are transformed by the acquisition transformations in the match rule are compared against the attribute values in the staged schema.
Matched acquisition attribute values determine the most relevant subset of records from the staged schema to form the work unit.
-
The work unit consists of all records from the staged schema with attribute values that match the transformed acquisition attribute values of the input record.
The work unit saves you time and resources because this relevant subset of records, not the entire staged schema, can be compared against the input record for scoring.
-
The attribute values in the input record that are transformed by the scoring transformations in the match rule are compared against the attribute values in the work unit. Based on the match rule, a score is calculated for each record in the work unit.
-
Steps 3 through 6 are repeated for each entity.
-
Scores from all entities are added together for each record.
-
The score of each work unit record is compared against the match and Automerge thresholds defined in the match rule.
-
Records with scores that reach the match threshold are selected as matches for the input record.
-
Records with scores that also reach the Automerge threshold are automatically merged if Automerge is implemented and the match rule is designated for use with Automerge.
-
Related Topics
Bulk Duplicate Identification Matching Process
This diagram describes the bulk duplicate identification process, involving match rules with the Bulk Duplicate Identification purpose.
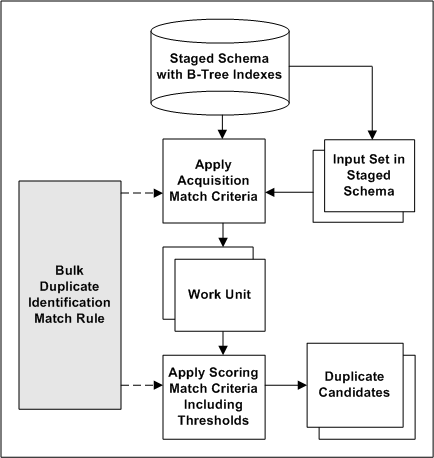
-
The staged schema stores the transformed TCA Registry attribute values for comparison in the matching process. The included attributes and the transformations applied to each are defined in the Define Attributes and Transformations page.
Also defined are the attribute and transformation combinations to be used for bulk duplicate identification. The staged schema includes B-Tree indexes only for the transformed attributes marked for bulk duplicate identification.
-
A duplicate identification process is started, either for a subset of records in the TCA Registry or for the entire Registry. The transformed version of that set of input records is already represented in the staged schema.
-
With the Bulk Duplicate Identification purpose, the match rule specified for the duplicate identification is applied to the staged schema, which is joined with the input set for bulk comparison.
-
Using the acquisition criteria in the match rule, each record in the input set is compared to all other records in the same staged table.
For example, an acquisition criterion is the D-U-N-S Number attribute with the Exact transformation. All D-U-N-S Numbers, as transformed by the Exact transformation, would be compared against one another.
-
Matched acquisition attribute values determine the most relevant subset of records from the staged schema to form the work unit.
-
Using the scoring criteria in the match rule, each record in the work unit is compared to all other work unit records in the same staged table.
-
A score is calculated for each record in the work unit, and scores for all entities are added together for determining duplicate parties.
-
-
The score of each work unit record is compared against the match and automatic merge thresholds defined in the match rule.
-
Records with scores above the match threshold are selected as potential duplicates.
-
Records with scores that also exceed the Automerge threshold are automatically merged, if Automerge is implemented and the match rule is designated for use with Automerge.
-
Related Topics
Bulk Duplicate Identification.
Integration Services Duplicate Identification Matching Process
This diagram describes the duplicate identification process, involving match rules with the Integration Services purpose.
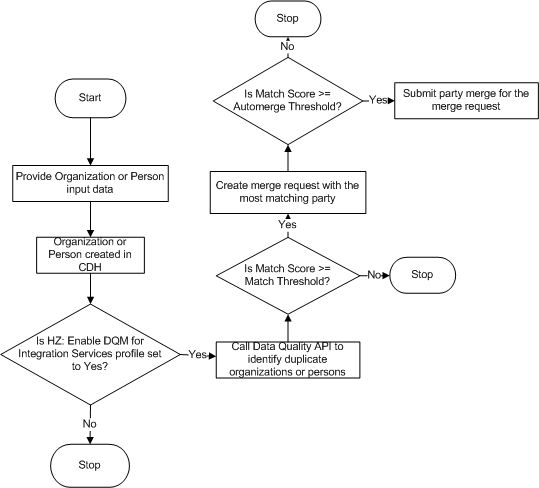
-
When a person or organization is created in Customer Data Hub, the duplicate identification process checks if HZ: Enable DQM for Integration Services profile option is set to Yes.
-
If data quality is enabled, the DQM Organization/Person Search API uses the following logic to identify if the new organization or person:
-
If the match score is less than the Match Threshold value then the new organization or person is retained.
-
If the match score is more than or equal to the Match Threshold value but less than the Automerge Threshold value, then a merge request is created to merge the existing organization or person and the new organization or person.
-
If the match score is more than or equal to the Automerge Threshold value then an Automerge request is created to merge the existing organization or person and the new organization or person.
-
-
If more than one existing organization or person is retrieved as a potential match for the new organization or person, then the matching process is executed for the record with the highest match score. This rules applies to both, the Automerge and Create Merge request processes.
-
If more than one existing organization or person is retrieved as a potential match for the new organization or person, and all records have the same high match score, then the matching process is executed for the record with the most recent last update date. This rules applies to both, the Automerge and Create Merge request processes.
Defining Single Match Rules
You define a match rule when you create a custom rule, update an existing custom rule, or copy an existing seeded or custom rule. You cannot update a seeded match rule.
When you define match rules, you can specify which attributes are important for matching and configure how the attributes should be evaluated. For each attribute that you use in a match rule, you also assign one or more transformations.
For example, you can define a match rule so that only records with the same transformed party name and party number attribute values are considered matches. You can also determine how matching or similar attributes are evaluated to provide meaningful search results or duplicate candidates.
For your business needs, you do not need to use all of the functions of match rules with the Expanded Duplicate Identification, Bulk Duplicate Identification, or the Integration Services purpose.
-
For the simplest type of matching, use only acquisition.
-
For ranking your results, use scoring.
-
For filtering results based on the scores, use thresholds.
Procedure
-
Enter the basic information for the match rule. See: Entering Match Rule Details.
-
Select attributes for the match rule. See: Selecting Attributes and Defining Usage.
-
(Match rules with Bulk Duplicate Identification and Expanded Duplicate Identification purpose only) Define the usage of the attributes. See: Selecting Attributes and Defining Usage.
-
Assign transformations. For match rules with Bulk Duplicate Identification, Expanded Duplicate Identification, and Integration Services purpose only, also define scores and thresholds. Submit the match rule. See: Assigning Scores, Transformations, and Thresholds.
-
Compile the match rule. See: Compiling Match Rules.
Related Topics
Entering Match Rule Details
Note: The match rule purpose that you select determines various aspects of defining the match rule, for this as well as subsequent procedures.
Procedure
-
Enter the basic information for the match rule, including its name and purpose.
Note: You cannot change a match rule's purpose after the match rule has been saved.
-
For match rules with Expanded Duplicate Identification, Bulk Duplicate Identification, or Integration Services purpose, specify for the search operator if a record must match any or all acquisition attributes to be considered a match.
Even if you select Match Any, a record still must match all acquisition attributes within the same entity, except Party. For example, for acquisition, you have only the Party Name and D-U-N-S Number attributes from the Party entity, and City and State from the Address entity. If a record matches only D-U-N-S Number, it is considered a match. If it matches only State, it is not considered a match. Because City is also from the Address entity, the record would need to match both City and State.
-
For match rules with Expanded Duplicate Identification, Bulk Duplicate Identification, or Integration Services purpose, indicate if the Allow Automerge check box must be selected. See: Automerge.
Caution: You cannot undo automatic merges. For Automerge, use only match rules that provide exact matches.
-
For match rules with Search purpose, indicate if the match rule can be used to identify existing records that are possible duplicates of a new record, to prevent duplicates from being saved.
Related Topics
Selecting Attributes and Defining Usage
After you have entered basic details for the match rule you are creating, you select attributes to include in the match rule and, for match rules with Expanded Duplicate Identification or Bulk Duplicate Identification purpose, define the usage of each attribute.
After this procedure, assign transformations and, for match rules with Expanded Duplicate Identification or Bulk Duplicate Identification purpose, optionally scores and thresholds. See: Assigning Scores, Transformations, and Thresholds.
Procedure
Select attributes, from the Party, Address, Contact, and Contact Point entities, that help you obtain all relevant matches. For example, if you want to find records that have matching names, include the Party Name attribute in the match rule.
Note: Only defined attributes are available for you to select. See: Defining Attributes and Transformations.
If this match rule has the Bulk Duplicate Identification purpose, and you plan to use this rule for bulk import, then do not select user-defined custom attributes. See: Bulk Import Overview, Oracle Trading Community Architecture User Guide.
If you are defining a match rule with the Search purpose, the selected attributes determine the search criteria that appear in the user interface. The actual prompt that appears for each criterion is the user defined name. See: Defining Attributes and Transformations.
(Bulk Duplicate Identification, Expanded Duplicate Identification or Integration Services only) Define the usage of the selected attributes in the match rule..
-
Acquisition: Used for comparing an input record to the records in the staged schema, to obtain an initial set of matched records.
If you specify more than one acquisition attribute in the match rule, the search operator that you defined for the match rule determines whether all or any attribute must match to determine if the input record is a match to a record in the staged schema. See: Defining Single Match Rules.
Do not be too restrictive with your acquisition if you want fairly loose matches. For example, if you use the Address, City, and State attributes for acquisition, with the Match All search operator, then a record must have the same combination of address, city, and state to match. If you use just City and State, however, you will have more potential matches, and can still use address as a match criterion by including Address as a scoring attribute.
The initial set of matched records obtained by acquisition is called the work unit. A work unit includes all records with acquisition attribute values, transformed using the transformations, that match attribute values of the input record. The work unit can be the final set of matches or used for scoring.
If you only want to consider this initial set of matched records, you do not have to define scoring attributes and specify thresholds or scores. You would have a match rule that requires that a record matches any or all acquisition attributes you have selected.
-
Filter: Used in acquisition so that the attribute must be a match in the work unit. The search engine groups filter attributes of the same entity under a match-all condition, even the Party entity.
Note: If the attribute's type is Lookup, then the DQM search engine defaults that attribute as a filter because the values of the attribute are usually not unique across records.
For example, this table displays a set of acquisition attributes:
Attribute Name Entity Type Filter Default as Filter Party Name Party Yes No D-U-N-S Number Party Yes No CEO Name Party No No Address 1 Address No No Country Address Lookup Yes Yes Phone Number Contact Point No No If the match rule's search operator is Match Any, then all of the returned records will match either of the following criteria:
-
Party Name and D-U-N-S Number
-
Address 1 and Country
Even though the search operator is Match Any, and Address 1 is not a filter, all acquisition attributes within the same entity, other than Party, must be a match. In this case, because they are filters within the same entity, party attributes Party Name and D-U-N-S Number both also must match. See: Defining Single Match Rules.
Note: Attributes used as filters are only used in acquisition, not scoring, because all records must contain these filter attributes.
-
-
Scoring: Used to score the records in the work unit. With the scoring component of a match rule, records that do not exactly match the values of the acquisition attributes values can still be considered a match.
Note: Scoring attributes do not have to be the same as the acquisition attributes, and you can use more attributes for scoring. For best results with match rules with the Search purpose, however, use the same attributes for both acquisition and scoring.
You must have acquisition attributes from each entity that has scoring attributes in the same match rule. For example, if you have scoring attributes from the Party and Contact Point entities, you must also have acquisition attributes from those two entities, even if not the exact same attributes.
-
Related Topics
Assigning Scores, Transformations, and Thresholds
After you have selected attributes for the match rule and defined their usage, assign transformations for each attribute. For match rules with Bulk Duplicate Identification or Expanded Duplicate Identification purpose, you also define the scores and weights used to calculate the match score for each record in the work unit. The match score for the entire record is the sum of the actual weighted attribute scores. This match score is the value that is compared to the match rule thresholds to evaluate the record in the work unit.
Procedure for Match Rules with Search Purpose
-
To specify the order in which attributes appear as search criteria, assign a number to every attribute. Use positive integers greater than 0. The numbering does not have to be gapless.
For example, if you have four attributes, the first row of displayed search criteria contains attribute 1 and 2, from left to right. The second row contains attribute 3 and 4, from left to right. All attributes without an assigned number are displayed last.
-
Assign at least one transformation for each attribute. You can choose more than one transformation for each of the attributes in the match rule.
Tip: Use the fewest transformations possible in your match rule. Using more transformations than necessary could affect the time required for staging and the performance of your search.
Transformations that appear by default were selected to do so, in the specified order, on the Define Attributes and Transformations page. See: Defining Attributes and Transformations.
-
Use Up and Down to order the transformations. For example, the CLEANSE transformation alters the original attribute value more than EXACT does. You would order EXACT before CLEANSE because the transformed value is closer to the original and provides a more precise match.
This order determines how the search is processed. See: Search Matching Process.
-
You can save the match rule definition and compile it later. A new or updated match rule cannot be used until it is compiled. See: Compiling Match Rules.
Procedure for Match Rules with Bulk Duplicate Identification or Expanded Duplicate Identification Purpose
This table describes some terms in the pages used for this procedure.
-
Rank your scoring attributes in order of importance by assigning scores in the form of integers. Assign the highest score to the attribute that you consider the most important for a match.
-
Assign at least one transformation for each acquisition, filter, and scoring attribute. DQM applies the selected transformations to that attribute before the input record is compared to the record in the work unit. You can choose more than one transformation for each of the attributes in the match rule.
Tip: Use the fewest transformations possible in your match rule. Using more transformations than necessary could affect the time required for staging and the performance of your search.
If the match rule has the Bulk Duplicate Identification purpose, then only transformations marked for Bulk Acquisition on that page are available for the corresponding attribute. See: Defining Attributes and Transformations.
-
For scoring attributes, optionally assign weights and, available through personalization, similarity matching. You also specify if the attribute and transformation combination is used in acquisition or scoring processes when the match rule runs.
-
Weight: Assign percentage weights to the transformations depending on how similar the transformed value of the attribute would be to the original values of the attribute. For example, you should assign more weight to the Exact transformation than to the Cleanse transformation because Exact makes fewer changes to the original data.
-
Similarity: The Similarity matching option does not require an exact match, letting you create fuzzier matches by applying the similarity algorithm to transformed attribute values. The similarity algorithm compensates for unanticipated errors that the transformations do not catch.
If the computed percentage is greater than or equal to the similarity percentage that you define in the match rule, the attribute is considered a match. If you select the Similarity option, you must enter this similarity percentage.
Note: The Similarity option requires additional computing resources and time.
-
-
Note: Make sure that:
-
You do not set any thresholds too low. Low thresholds might let combinations of attributes pass as matches that are not significant.
-
Each threshold is less than the sum of the possible scores of all attributes.
-
Match Threshold: To compute what you should enter, determine the minimum set of attributes required for a match. The total of the attribute scores of this minimum set is the maximum value of the match threshold.
-
Automerge Threshold: You can enter this threshold only if the match rule is allowed for Automerge. See: Defining Single Match Rules.
To compute the Automerge threshold, determine the minimum set of attributes required for considering two parties for merge. The total of the attribute scores of this minimum set is the maximum value for the Automerge threshold.
The automatic merge threshold must be more than or equal to the match threshold.
Caution: You cannot unmerge records that are automatically merged. Set the automatic merge threshold high enough to prevent merging records that are not definite duplicates.
-
-
You can save the match rule definition and compile it later. A new or updated match rule cannot be used until it is compiled. See: Compiling Match Rules.
Related Topics
Match Rule Example
This section provides an example of how you can develop a match rule. This example focuses on the scoring and threshold components, detailing the thought process you might take to create an effective match rule.
Preparing for the Match Rule
-
Create a list of all of the attributes that should match between two matching records. This list should include attributes that are really important as well as attributes that are just good to have as matches.
For this example, this table shows the following list of attributes:
Attribute Name Entity Type Party Name Party Phone Number Contact Point Address1 Address Country Address Lookup Postal Code Address Contact Last Name Address -
Rank the order of importance of the attributes, as shown in this table:
Rank Attribute Name Entity Type 1 Party Name Party 2 Phone Number Contact Point 3 Contact Last Name Contact 4 Address1 Address 5 Country Address Lookup 6 Postal Code Address This ranking indicates that the attribute score you assign to party name is the highest and the scores are lower or stay the same as you go down the ranking.
-
Identify the minimum sets of attributes you require to match for records to be considered matches, for example:
-
Only the party name
-
Only the phone number
This requirement indicates that your acquisition attributes should at least include party name and phone number and that you should select the Match Any search operator.
-
-
Identify the sets of attributes that by themselves are not good enough to indicate that you have matching records, but which, if they were close enough matches, might give additional credence to a match on the minimum set of party name and phone number.
-
Only address
-
Only country
-
Only postal code
-
Only address and country
-
Only address and postal code
-
Only country and postal code
-
Only contact last name
This selection determines the attributes that you need to include as scoring attributes.
-
Selecting Attributes and Assigning Scores
-
You should select the Match Any search operator because you have two sets in step 3 of Preparing for the Match Rule.
-
Choose attributes from step 1 of Preparing for the Match Rule that would get you all of the possible matches. You must include the attributes from step 3 of Preparing for the Match Rule. For this example, you select:
-
Party Name
-
Phone Number
-
Contact Last Name
-
-
Select attributes from step 1 of Preparing for the Match Rule that you want to use to score the records. You must include the attributes from step 4 of Preparing for the Match Rule.
This table shows the scoring attributes.
Attribute Name Entity Type Party Name Party Phone Number Contact Point Address1 Address Country Address Lookup Postal Code Address Contact Last Name Contact -
Assign scores to the scoring attributes following the ranking in step 2 of Preparing for the Match Rule. The most important attributes receive the highest scores. For this example, the score assignments should reflect the following:
-
Matches on party name provide the best match results, so you assign the highest score to party name.
-
Matches on a phone number might be the second best matching criterion, so you assign the next highest score to phone number.
-
Combinations of the address components and contact last name are the third best, so you assign scores by relative importance.
-
The contact last name attribute is estimated to have about the same value as the address1 attribute.
For this example, the scores in this table are assigned to the scoring attributes.
Scoring Attributes Scores Party Name 40 Phone Number 30 Address1 15 Country 10 Postal Code 10 Contact Last Name 15 The total score for the attributes in this table is 120.
-
Setting the Match Threshold
-
Obtain minimum sets from step 3 of Preparing for the Match Rule and total attribute scores from step 4 of Selecting Attributes and Assigning Scores.
-
For Party Name the total attribute score is 40.
-
For Phone Number the total attribute score is 30.
-
-
Set your match threshold based on the lower score of the two minimum sets, in this example, 30.
With the match threshold at 30, you can interpret scoring as follows:
-
If only the phone number is a match, the record is a match because the score equals the match threshold of 30.
-
If only the party name is a match, then the record is a match because the score exceeds the match threshold of 30.
-
If the country, postal code, and contact last name are a match, then the record is a match because the attributes' combined score of 35 exceeds the match threshold of 30.
-
If the address1, country, and postal code are a match, then the record is a match because the attributes' combined score is 35, which exceeds the match threshold of 30.
With the match threshold at 30, this table shows results of possible matches:
| Possible Matches | Cumulative Score | Match |
|---|---|---|
| Party Name | 40 | Yes |
| Phone Number | 30 | Yes |
| County, Postal Code, and Contact Last Name | 35 | Yes |
| Address1, Country, and Postal Code | 35 | Yes |
| Party Name and Phone Number | 70 | Yes |
| Phone Number and Country | 40 | Yes |
| Address1 and Country | 25 | No |
| Country and Postal Code | 20 | No |
| Party Name, Address1, and Contact Last Name | 70 | Yes |
Considering the Impact of Transformations on Your Thresholds
If you have transformation weights other than 100%, then you might need to tune your threshold. With weights other than 100%, the total score for the record can be lower than the match threshold that you assigned. The total score is the sum of attribute scores that are multiplied by the weight.
For example, a minimum set of attributes required for match consists of party name. The following table shows the transformations and weights assigned to the Party Name attribute, as well as the weighted attribute scores calculated for each transformation.
Party Name Attribute with Attribute Score 40
| Transformation | Weight % | Weighted Attribute Score Calculation |
|---|---|---|
| Exact | 100 | 100% * 40 = 40 |
| Reverse | 80 | 80% * 40 = 32 |
| Cleanse | 50 | 50% * 40 = 20 |
Depending on the transformations, a matching party name can have a weighted attribute score below 40. With a weighted score of 20, for example, this minimum set might not exceed the match threshold of 30. If you want all possible matches that originate from any of the transformations, you might want to adjust some of your values.
You have three options:
-
Decrease the match threshold to the lowest possible weighted attribute score. Performing this option might affect the scores of other attributes and thresholds.
-
Increase the weight of the transformations so that the lowest possible weighted attribute score exceeds the match threshold. This option might not always be possible because weights must be less than or equal to 100.
-
Increase the attribute score so that the lowest possible weighted attribute score exceeds the match threshold.
For example, you can increase the Party Name attribute score to 60 and the Cleanse transformation weight to 70%. This table shows the adjusted assignments with each possible weighted attribute score exceeding the match threshold of 30.
Party Name Attribute with Attribute Score 60
| Transformation | Weight % | Weighted Attribute Score |
|---|---|---|
| Exact | 100 | 60 |
| Reverse | 80 | 48 |
| Cleanse | 70 | 42 |
Defining Match Rule Sets
You define a match rule set when you create a set, as well as update or copy an existing set.
Procedure
-
Enter the basic information for the match rule set, including its name and the purpose of all match rules in the set. The Bulk Duplicate Identification purpose is not used in match rule sets because bulk duplicate identification processes in bulk. For match rule sets to function effectively, the records must be processed row by row.
Note: After a set is first created and compiled, you cannot change the purpose when you later update or copy the match rule set.
-
Specify a fallback match rule, at least one match rule to include in the set, and the conditions under which to use each match rule. All combinations of the condition components must be unique.
Note: If a match rule set with Search purpose is used to render search UI, then the superset of all attributes in the set is the displayed search criteria.
For example, to run a match rule for Australian addresses, you define the condition as:
-
Entity: Address
-
Attribute: Country
-
Operation: Equals
-
Value: Australia
Note: The value is not case sensitive.
-
-
Define the order in which the match rule set conditions are evaluated. The first condition to be met determines which match rule runs.
You can save the match rule set definition and compile it later. A new or updated match rule set cannot be used until it is compiled. See: Compiling Match Rules.
Related Topics
DQM Compile All Rules Program
Use the DQM Compile All Rules program when you initially install DQM to compile the seeded match rules provided by TCA. You can also use this program to compile all of the match rules that you create or update.
You can compile selected match rules in the Match Rules page, while this program always compiles all rules. The program attempts to compile all match rules even if certain match rules fail to compile. Match rules that are already compiled remain compiled, and match rules that can be successfully compiled are compiled. Match rules that fail to compile are left uncompiled.
You can see the compile status of each match rule in the Match Rules page.
Prerequisites
Before you can compile your match rules, you must run the DQM Staging program. For more information, see: DQM Staging Program.
Related Topics
Quality Adjusted Search Results
The Quality Adjusted Search Results feature takes a record's match percentage, as determined by a match rule, and adjusts it based on what you define as quality. This feature applies only to searches, or matching processes using match rules of type Search, and only to records with scores that reach the match rule's match threshold percentage value. You get search results that are based on both similarity to search criteria and quality, sorted by the quality adjusted match percentage.
If the HZ: Enable Quality Weighting for DQM Match Scores profile option is set to Yes, then DQM applies two user hook procedures to search results that reach the match threshold. The first procedure determines the quality weighting, or the percentage of the final adjusted match percentage that should be based on quality. The second determines the quality score, which represents the user-defined quality of a record, with 100 as the highest possible.
To set up, you must:
-
Set the HZ: Enable Quality Weighting for DQM Match Scores profile option to Yes. See: DQM Deployment Category.
-
Create two user hook procedures for determining quality weighting and quality scores. See: Creating Logic for Quality Adjusted Search Results.
This table shows the records that a match rule has identified as search results, with the match percentages that the match rule has calculated.
| Record | Match Percentage |
|---|---|
| A | 70% |
| B | 67% |
| C | 65% |
| D | 62% |
The first user hook procedure determines that the quality weighting is 20%, and the second procedure calculates the quality scores as shown in this table.
| Record | Match Percentage | Quality Score |
|---|---|---|
| A | 70% | 50 |
| B | 67% | 20 |
| C | 65% | 60 |
| D | 62% | 80 |
If 20% of the final adjusted match percentage is from the quality score, then 80% is from the original match percentage. The match percentage must be adjusted to be out of 80%, not 100%. This adjustment, for the weighted match percentage, is calculated as:
Weighted Match Percentage = Match Percentage * (100 - Quality Weighting) / 100
The quality score must also be adjusted based on the quality weighting of 20%. The weighted quality percentage is calculated as:
Weighted Quality Percentage = Quality Score * Quality Weighting / 100
This table shows the weighted match percentages and weighted quality percentages, with quality weighting of 20%.
| Record | Match Percentage | Weighted Match Percentage | Quality Score | Weighted Quality Percentage |
|---|---|---|---|---|
| A | 70% | 56% | 50 | 10% |
| B | 67% | 53.6% | 20 | 4% |
| C | 65% | 52% | 60 | 12% |
| D | 62% | 49.6% | 80 | 16% |
The final quality adjusted match percentage is calculated by adding the weighted match percentage and the weighted quality percentage. This table shows the search results, sorted by the quality adjusted percentages.
| Record | Weighted Match Percentage | Weighted Quality Percentage | Quality Adjusted Match Percentage |
|---|---|---|---|
| A | 56% | 10% | 66% |
| D | 49.6% | 16% | 65.6% |
| C | 52% | 12% | 64% |
| B | 53.6% | 4% | 57.6% |
Note how the order of the records have changed when quality is taken into account.
Creating Logic for Quality Adjusted Search Results
For the logic to use in calculating quality adjusted search results, you must write two user hook procedures for the HZ_DQM_QUALITY_UH_PKG package: get_quality_weighting and get_quality_score. These procedures let you implement the logic to use, according to your organization's needs and definitions of quality.
The template code for the HZ_DQM_QUALITY_UH_PKG package is present in the file $AR_TOP/patch/115/sql/ARHDQUHB.pls, which has dummy implementations for the user hook procedures. Copy this file and provide actual implementations for the quality weighting and scoring procedures.
get_quality_weighting
-
Input: The ID of the match rule used for the search
-
Output: A number that represents the quality weighting for calculating the quality adjusted match percentage, based on the input match rule
In the get_quality_weighting procedure, include all the possible search match rules that are used for quality adjusted search results. You can assign different quality weighting to the match rules.
FUNCTION get_quality_weighting(p_match_rule_id IN NUMBER)
RETURN NUMBER IS
l_quality_weighting NUMBER := 0;
BEGIN
IF (p_match_rule_id = 8) THEN
l_quality_weighting := 20;
ELSIF (p_match_rule_id = 10) THEN
l_quality_weighting := 25;
END IF;
RETURN l_quality_weighting;
EXCEPTION
WHEN OTHERS THEN
RAISE;
END get_quality_weighting;
For example, a search is run using the match rule with the ID of 10. The get_quality_weighting procedure would determine that 25% of the quality adjusted match percentage is based on the quality score. The remaining 75% is based on the original match percentage.
get_quality_score
-
Input: An entire record, including all the column values from the HZ_PARTIES table, and the ID of the match rule used for the search
-
Output: A number that represents the quality score for the input record, indicating its quality level, with 100 as the highest
In the get_quality_score procedure, include all the possible search match rules that are used for quality adjusted search results. The logic in this procedure can be as simple or complex as you need. You can base the logic only on record values passed to the procedure, for example the certification level or whether a DUNS Number exists or not. For a more complex approach, you can instead take the passed values and use them to join to any number of tables to determine quality, or to call other procedures, APIs, programs, and so on.
Caution: The more complex the procedure, the more the performance might be negatively affected.
FUNCTION get_quality_score(p_match_rule_id IN NUMBER, p_hz_party_rec IN HZ_PARTIES%ROWTYPE)
RETURN NUMBER IS
l_quality_score NUMBER := 0;
BEGIN
IF (p_match_rule_id = 8) THEN
IF p_hz_party_rec.duns_number IS NOT NULL THEN
l_quality_score := 50;
END IF;
ELSIF (p_match_rule_id = 10) THEN
IF p_hz_party_rec.duns_number IS NOT NULL THEN
l_quality_score := 35;
END IF;
END IF;
RETURN l_quality_score;
EXCEPTION
WHEN OTHERS THEN
RAISE;
END get_quality_score;
For example, a search is run using the match rule with the ID of 10, and the record that is evaluated has a DUNS Number. The get_quality_score procedure would assign this record a score of 75.
Related Topics
Quality Adjusted Search Results
Viewing Match Rules
View the details of match rules of type Single or Set.
-
-
Match Rule Definition: The match rule details entered in the first step of defining a match rule. See: Entering Match Rule Details.
-
Attributes and Transformations (match rules with Search purpose) or Attributes, Transformations, and Scores (match rules with Expanded Duplicate Identification and Bulk Duplicate Identification purpose):
-
The attributes selected for the match rule. See: Selecting Attributes and Defining Usage.
-
The transformations defined for each attribute. See: Assigning Scores, Transformations, and Thresholds.
-
The thresholds defined for the match rule, if any. See: Assigning Scores, Transformations, and Thresholds.
-
-
Set: The details entered for defining a match rule set. See: Defining Match Rule Sets.
Related Topics
Staged Schema
The staged schema is a separate set of database tables with a portion of the data from the TCA Registry that transformations have standardized for improved matching. During matching, the input record is compared against the records in the staged schema instead of the original Registry. To enable efficient searches, the staged schema is indexed using Oracle interMedia and B-Tree indexes. DQM searches against the indexes to take advantage of high performance capabilities in searching through large quantities of data.
Staged Schema Features
Each table in the staged schema contains attribute values for each entity: Party, Address, Contact, and Contact Point, and can include up to 30 custom attributes. In the Define Attributes and Transformations page, you define the attributes that you want in the staged schema as well as the transformations to apply to each attribute value. See: Defining Attributes and Transformations.
For example, for the Party entity, you can include the party name attribute and specify two transformations to transform the party names. Each attribute, in essence, corresponds to a column in a TCA Registry table that stores the attribute value, and the staged schema contains the transformed version of those values.
See: Seeded Attributes, Oracle Trading Community Architecture Reference Guide.
This table shows the mapping of the TCA Registry to the staged schema. The staged schema table that is used depends on the program you run to stage data. See: Administering the Staged Schema.
Administering the Staged Schema
Data Quality Management lets you:
-
Create and update the staged schema. See: DQM Staging Program.
-
Synchronize the staged schema with the TCA Registry. See: DQM Synchronization Method.
interMedia Indexes
interMedia indexes speed up the acquisition phase of the matching process by quickly limiting the number of parties to evaluate for scoring. interMedia indexes are built using inverted indexes, a structure that differs from normal indexes. DQM provides four interMedia indexes, one for each entity.
You can:
-
Create and update interMedia indexes. See: DQM Staging Program.
-
Optimize interMedia indexes. See: DQM Index Optimization Program.
-
Synchronize interMedia indexes with TCA Registry data. See: DQM Synchronization Method.
B-Tree Indexes
B-Tree indexes are created in the staged schema only for attributes that were transformed for bulk duplicate identification. These indexes provide increased performance over interMedia indexes, and are used only for matching processes that involve match rules with the Bulk Duplicate Identification purpose. See: Bulk Duplicate Identification.
You can:
-
Create and update B-Tree indexes. See: DQM Staging Program.
-
Synchronize B-Tree indexes with TCA Registry data. See: DQM Synchronization Method.
Related Topics
Data Quality Management Overview
DQM Staging Program
Use the DQM Staging program to create the staged schema, B-Tree, and interMedia indexes. This program applies transformations to a portion of the data contained in the TCA Registry and generates a separate schema with the transformed and standardized data.
When you specify in the Staging Command parameter to create indexes, the DQM Index Creation program automatically runs to generate interMedia and B-Tree indexes for the staged schema. Invoke the DQM Index Creation program not just to create indexes for the first time, but also to reindex the entire staged schema whenever necessary.
Tip: You can use the HZ: DQM Index Creation Memory profile option to override the default amount of memory that is allocated for creating interMedia indexes. See: Profile Options and Profile Option Categories.
The time that the program takes to create the staged schema depends on the size of your database and the number of attributes and transformations that you defined. To decrease the amount of time, you can specify how many parallel workers to use when you run the DQM Staging program. Workers are processes that run at the same time to complete a task that would otherwise take longer with a single process. The DQM Staging program invokes the DQM Stage Worker, which spins off parallel workers for staging the data.
Aside from creating the entire staged schema and the interMedia indexes, you can also run the DQM Staging program to:
-
Stage data using only new transformations
-
Generate only mapping procedures, which map attributes to the source columns of the attribute values
-
Regenerate only missing or invalid interMedia indexes
-
Estimate the table disk space needed to stage all data and create indexes
You should estimate the disk space first before actually staging data. The report output displays, in megabytes, the space required to stage each entity and create all indexes, as well as the total for all entities and indexes.
Note: Run the DQM Staging program every time that you add or modify attributes or transformations. See: Defining Attributes and Transformations.
Prerequisites
Before you submit the DQM Staging program, you must define attributes and transformations. See: Defining Attributes and Transformations.
Program Parameters
-
Number of Parallel Staging Workers: Enter the number of parallel staging workers, between one and ten, that you want to use to create the staged schema, or leave the parameter blank. The DQM Stage Worker runs with one worker if you leave the parameter blank.
-
Staging Command: Enter what you want the program to accomplish. This table shows the options.
Staging Command Description CREATE_INDEXES Create Indexes: To invoke the DQM Index Creation program to generate indexes for the staged schema. CREATE_MISSING_INVALID_INDEXES Recreate Missing and Invalid DQM Indexes: To invoke the DQM Index Creation program to regenerate missing or invalid indexes ESTIMATE_SIZE Estimate Disk Size for Staging: To estimate the disk space required to stage all data and create indexes. GENERATE_MAP_PROC Generate mapping procedures: To generate only mapping procedures. STAGE_ALL_DATA Stage all data, create indexes, and generate map procedures: To stage all data, create indexes, and generate mapping procedures. STAGE_NEW_TRANSFORMATIONS Stage new transformations: To stage data using only new or modified transformations. STAGE_NEW_TRANSFORMATIONS_NO_INDEXING Stage new transformations with no indexing: To stage data using only new or modified transformations without rebuilding indexes. -
Continue previous execution: Enter Yes to continue running a previous DQM Staging program that did not finish. Enter No to run a new DQM Staging program.
-
Index Creation Tablespace: Enter the table space where the interMedia indexes are to be created in.
-
Index Creation: Enter PARALLEL to generate multiple indexes at the same time, based on the number of parallel workers that you specified. Enter SERIAL to create indexes one after another, even if you specified parallel workers.
Related Topics
DQM Index Optimization Program
Use the DQM Index Optimization program to optimize interMedia indexes. You can schedule this program to run on a periodic basis. In general, you can run the DQM Index Optimization program less frequently than the DQM Synchronization program. The DQM Index Optimization program improves the performance of interMedia searches, which gradually degrades over time. You should run this program once in a while, but frequent optimization is not mandatory.
The DQM Synchronization program, however, synchronizes data between the TCA Registry and the staged schema, so you should run this program as often as possible to keep the search results accurate. See: DQM Synchronization Program.
Prerequisites
Before you submit the DQM Index Optimization program, you must make sure that both the staged schema and interMedia indexes exist.
Related Topics
DQM Synchronization Method
Select either the Automatic or Batch synchronization method, or Disable for no synchronization between the staged schema and the TCA Registry. Synchronization ensures that any new or updated data in the TCA Registry is reflected in the staged schema, and interMedia and B-Tree indexes.
-
Automatic: When data is inserted or updated in the TCA Registry through:
-
User interfaces or APIs, the staged schema is immediately synchronized.
-
Bulk Import or Customer Interface, the staged schema is synchronized in a controlled manner, given the potentially large volume of records. A queue is created, and a maximum of 100 records are synchronized at one time.
See: Bulk Import Overview, Oracle Trading Community Architecture User Guide or Customer Interface, Oracle Trading Community Architecture User Guide.
Optionally enable search on records with interMedia indexes that are not yet synchronized.
Caution: Enabling this option can cause decrease in search performance.
-
-
Batch: Schedule the DQM Synchronization program to periodically run. See: DQM Synchronization Program.
Related Topics
DQM Synchronization Program
Use the DQM Synchronization program to synchronize an existing staged schema with the TCA Registry. The program:
-
Includes Registry records of any source, updated and created through user interfaces, APIS, or batch loading.
-
Updates interMedia and B-Tree indexes after updating the staged schema.
You can schedule the DQM Synchronization program to be run on a periodic basis. The frequency that you want to submit this program with depends on:
-
How often the information in the TCA Registry usually changes
-
How often you search against the TCA Registry
-
How much processing power you have
If you run the program frequently, the data in the staged schema and indexes are sooner updated for your searches. The interMedia indexes, however become less optimal and slower to use. To optimize the interMedia indexes, see: DQM Index Optimization Program.
Prerequisites
-
Select Batch as the synchronization method if you are scheduling the program to periodically run. See: DQM Synchronization Method.
-
Make sure that both the staged schema and indexes exist.
Program Parameter
Number of Workers: Enter the number of parallel workers, between one and ten, that you want to use to synchronize the staged schema, or leave the parameter blank. The synchronization runs with one worker if you leave the parameter blank.
Related Topics
Merge Dictionary Overview
The Merge Dictionary stores the entities and procedures that must be processed to merge party entities for any Oracle application. During the merge process, each procedure sequentially executes for the entities defined in the Dictionary. Merge programs use the information in the Merge Dictionary to recognize which entities to merge, and they recognize the foreign keys and procedures without the need to recompile or regenerate the application code.
Each Oracle application maintains its own tables to store the information required to complete its business functions. During a merge process, all registered applications must be able to access the data for the appropriate entity that is related to the TCA Registry. If a merge procedure attempts to access a deleted party, the transaction, attributes, and other information for the party cannot be merged.
To maintain how Oracle applications are affected by the merge process, you register the entities, for example Accounts, Organization Contacts, and Party Sites, foreign keys, and procedures for specific Oracle applications in the Merge Dictionary. See: Maintaining the Merge Dictionary.
For example, if your company enters into a service contract with one of the parties in your Registry, you would use Oracle Receivables to send invoices and statements to that party and Oracle Service to administer that service contract. If that party is acquired by another party, is identified as a duplicate of another party, or has sites that must be consolidated, you must merge those parties or party sites. This party merge affects customer accounts and attributes of the parties in Oracle Receivables, Oracle Service, and other Oracle Applications.
The registration specifies the names of the procedures required to merge the entities that interact with the party entities. These entities can be identified using the foreign key attributes that they contain. If any entity contains an attribute that is a foreign key to any of the TCA entities, these entities should be part of the Merge Dictionary and a procedure should be created to handle the records in this entity during the merge process.
Some Oracle Applications, along with their party entities, are automatically registered at installation. If you have installed any of these applications, when you perform a merge, the entities associated with the parties in these applications are merged as well. See: Party and Account Merge Impact, Oracle Trading Community Architecture Reference Guide.
Related Topics
Data Quality Management Overview
Maintaining the Merge Dictionary
With the Merge Dictionary, you determine the sequence of entities to merge, as well as view, update, and add seeded or custom entities.
You add entities as a child of another entity. The parent entity is merged before the child, and the foreign key of the child points to the parent.
You can delete custom entities from the Merge Dictionary. The data from deleted entities will not be merged during any merge process, and all child entities under the deleted entity will also be deleted.
See: Customizing the Merge Dictionary.
Prerequisites
Before you add any Oracle application to the Merge Dictionary, you must:
-
Identify any entities that have foreign keys in the TCA Registry.
-
Create merge procedures by identifying the foreign keys for those entities.
Entity Details
This table describes the details of the entity that you are viewing, updating, or adding. What you can update depends on whether the entity is seeded or custom.
| Detail | Description |
|---|---|
| Entity | The name of the table that has a foreign key to the HZ_PARTIES table or a related table such as HZ_PARTY_SITES or HZ_CONTACT_POINTS. |
| Application | The Oracle application affected by the merge process. |
| Sequence | The order in which the entity is to be processed during a merge. |
| Parent Entity | The name of the table that the foreign key of the entity refers to. |
| Primary Key | The name of the primary key column for the entity. |
| Foreign Key | The name of the foreign key column which links the entity to its parent entity. |
| Description | A description of the entity, for example Party for HZ_PARTIES. |
| Description Columns | The name of the columns used to generate a description for the record, for example, PARTY_NAME for the HZ_PARTIES table. You can alternatively enter a complex concatenation or decode expression. The description columns are used in reports and logs. |
| Procedure Name | The name of the merge procedure, which must conform to the standard merge procedure signature. |
| Merge Records in Bulk | Whether or not the merge procedure is called once for every record or for all records in the table that references the merged party. If records are merged in bulk, you cannot assign child entities to this entity. |
| Additional Query Clause | A SQL clause that is used to specify additional filtering conditions for joining the table to the related parent entity. |
| Batch Merge Routine | Whether or not the merge procedure is a routine that should be processed in batch, for performance reasons. Generally, you should use this option if the table that this merge routine is created for has multiple foreign key references to TCA. This option lets you create one batch routine instead of a number of regular routines for each foreign key. |
Customizing the Merge Dictionary
You can customize the Merge Dictionary by including your own custom entities as part of the merge process, so that custom entities can be merged using standard merge rules or custom rules. You must develop the code to customize the merge procedures used by your custom applications and entities. Your custom merge procedure should:
-
Perform any required validations before you run the merge process.
-
Meet the processing requirements of your range of business activities.
-
Conform to the standard merge procedure signature. This table shows the parameters.
Parameter Usage Data Type Description p_entity_name IN VARCHAR2 Name of the entity being merged. p_from_id IN NUMBER Primary key ID of the merge-from record. p_to_id IN / OUT NUMBER -
IN: Primary key ID of the merge-to record.
-
OUT: Primary key ID of the merge-to record if the record is identified as part of the duplicate check.
p_from_fk_id IN NUMBER Foreign key ID of the merge-from record. p_to_fk_id IN NUMBER Foreign key ID of the merge-to record. p_parent_entitiy_name IN VARCHAR2 Name of the parent entity. p_batch_id IN NUMBER Batch ID. p_batch_party_id IN NUMBER ID that uniquely identifies the batch and party record being merged. Use this ID to reference batch information. x_return_status IN / OUT VARCHAR2 Status of the call. Returned values are: -
FND_API.G_RET_STS_SUCCESS: Success
-
FND_API.G_RET_STS_ERROR: Expected Error
-
FND_API.G_RET_UNEXP_ERROR: Unexpected Error
-
If the relationship between the parent and child entities involve more than one foreign key or is complex, you can enter an additional join condition in the merge procedure.
For example, the HZ_CONTACT_POINTS table can be associated with either a party or party sites based on the value of the owner_table_name. To associate HZ_CONTACT_POINTS with:
-
The HZ_PARTIES table
-
Enter the join condition as hz_contact_points.owner_table_name = HZ_PARTIES.
-
Define the foreign key as owner_table_id.
-
-
The HZ_PARTY_SITE table
-
Enter the join condition as hz_contact_points.owner_table_name = HZ_PARTY_SITE.
-
Define the foreign key as owner_table_id.
-
Related Topics
Creating Custom Merge Master Party Defaulting Method
The merge master party is the party in a duplicate set that remains in the TCA Registry after a merge. The HZ: Merge Master Party Defaulting profile option setting determines the method to use for defaulting the master for each duplicate set. You can define a custom user hook and set the profile option to User Hook to use your method. See: DQM Deployment Category.
Parameters
The parameters for the custom user hook are:
-
Input
p_dup_set_id (duplicate set identifier)
-
Output
-
x_master_party_id
-
x_master_party_name
-
x_return_status
-
x_msg_count
-
x_msg_data
-
User Hook Example
/* Use OSO party as master party, if it doesn't exist, use any party id
in the dup set*/
procedure default_master_user_hook(
p_dup_set_id IN NUMBER,
x_master_party_id OUT NOCOPY NUMBER,
x_master_party_name OUT NOCOPY VARCHAR2,
x_return_status OUT NOCOPY VARCHAR2,
x_msg_count OUT NOCOPY NUMBER,
x_msg_data OUT NOCOPY VARCHAR2 ) is
cursor get_OSOPartyId_csr is
SELECT PP.PARTY_ID, PP.PARTY_NAME
FROM HZ_PARTIES PP,HZ_DUP_SETS DS, HZ_DUP_SET_PARTIES DSP,
HZ_DUP_BATCH DB
WHERE PP.PARTY_ID =DSP.DUP_PARTY_ID
AND DB.DUP_BATCH_ID = DS.DUP_BATCH_ID
AND DS.DUP_SET_ID = DSP.DUP_SET_ID
AND DSP.DUP_SET_ID= p_dup_set_id
AND PP.CREATED_BY_MODULE = 'OSO_CUSTOMER'
AND NVL(DSP.MERGE_FLAG,'Y') <> 'N'
AND ROWNUM = 1;
cursor get_RandomPartyId_csr is
SELECT PP.PARTY_ID, PP.PARTY_NAME
FROM HZ_PARTIES PP,HZ_DUP_SETS DS, HZ_DUP_SET_PARTIES DSP,
HZ_DUP_BATCH DB
WHERE PP.PARTY_ID =DSP.DUP_PARTY_ID
AND DB.DUP_BATCH_ID = DS.DUP_BATCH_ID
AND DS.DUP_SET_ID = DSP.DUP_SET_ID
AND DSP.DUP_SET_ID= p_dup_set_id
AND NVL(DSP.MERGE_FLAG,'Y') <> 'N'
AND ROWNUM = 1;
begin
-- Initialize return status to SUCCESS
x_return_status := FND_API.G_RET_STS_SUCCESS;
open get_OSOPartyId_csr;
fetch get_OSOPartyId_csr into x_master_party_id,x_master_party_name;
close get_OSOPartyId_csr;
if x_master_party_id is null /* OSO party doesn't exist */
then
open get_RandomPartyId_csr;
fetch get_RandomPartyId_csr into
x_master_party_id,x_master_party_name;
close get_RandomPartyId_csr;
end if;
EXCEPTION
WHEN OTHERS THEN
x_return_status := FND_API.G_RET_STS_UNEXP_ERROR;
FND_MESSAGE.SET_NAME('AR', 'HZ_API_OTHERS_EXCEP');
FND_MESSAGE.SET_TOKEN('ERROR' ,SQLERRM);
FND_MSG_PUB.ADD;
FND_MSG_PUB.Count_And_Get(
p_encoded => FND_API.G_FALSE,
p_count => x_msg_count,
p_data => x_msg_data);
end;
Related Topics
Data Quality Management Overview
Automerge
Automerge automatically merges records that exceed a specified threshold during duplicate identification. The Automerge program only runs if the match rule specified for the duplicate identification process is designated for Automerge.
Note: Automerge is always implemented as part of a duplicate identification process. You can manually run Automerge only to resubmit an automatic run that resulted in error.
The Automerge program evaluates records against the match and automatic merge thresholds set in that match rule. The program:
-
Automatically merges records that meet or exceed the automatic merge threshold.
-
Creates a System Duplicate Identification (SDI) batch containing records that exceed the match threshold but not the automatic merge threshold. The SDI batch is available in Oracle Customer Data Librarian for merge consideration.
If a party is to be automatically merged, but already exists in a merge request in Oracle Customer Data Librarian, then an error is recorded in the Automerge log, and that party is not merged with its duplicates. The program continues and merges other parties that do not incur errors. See: De-Duplication Overview, Oracle Customer Data Librarian User Guide.
Rules for Automerge
In each duplicate set, two or more duplicate candidates are automatically merged into one merge master record. You can control aspects of the merge through profile options.
-
The HZ: Merge Master Party Defaulting profile option setting determines which party in each duplicate set is the master.
-
The HZ: Default Profile Attributes for Merge Mapping and HZ: Default Secondary Profile Attributes for Merge Mapping profile option settings determine which party profile attributes remain after the merge.
-
The HZ: Use DQM Suggested Groupings for Automerge profile option determines if addresses and relationships are merged based on DQM suggestions, or are just transferred from duplicate candidates to the master.
See: DQM Deployment Category.
Other rules of Automerge are:
-
For attributes other than party profile attributes, if the master already has a value, then that value survives the merge. If not, then the value is transferred from the duplicate candidate with the latest creation date and an attribute value.
-
For relationships, If the subject party Registry ID for the merge master and duplicate candidates are the same, and the relationship type is the same, then Automerge merges the relationship records. See: Relationships Overview, Oracle Trading Community Architecture User Guide.
-
If the party sites for the merge master and duplicate candidates have the same location ID, then the party sites are merged instead of transferred.
-
All transactions and accounts are transferred from the duplicate candidates to the merge master.
Program Parameters
Run this program from Standard Request Submission only to resubmit an Automerge that resulted in error.
-
Batch: Enter the batch number to rerun Automerge for. Only previously failed batches are available.
-
Number of Workers: Enter the number of workers for the process. The recommended number is four, and the maximum number is ten.
Related Topics
Data Quality Management Overview
DQM Diagnostic Reports
Use DQM diagnostic reports to evaluate your DQM setup and understand how and why DQM processes are working as they are. You create a report to generate a report output that provides details of your DQM setup at the time of report submission. You can resubmit a report to regenerate the output using the same report parameters, but also to capture DQM setup details at a different time.
Note: The output from a resubmitted report replaces the previous output. To avoid this override, create a new report instead.
There are two types of DQM diagnostic reports:
-
DQM Setup - Basic
-
DQM Setup - Detailed
The DQM Setup - Detailed report provides all the information that the DQM Setup - Basic report does, plus additional details.
-
General DQM Staging Information. See: Staged Schema.
-
DQM Staging Program Results. See: DQM Staging Program.
-
Index Statistics. See: interMedia Indexes and B-Tree Indexes.
-
Synchronization Status. See: DQM Synchronization Method.
-
Match Rules (DQM Setup - Detailed only). See: Match Rules Overview.
-
Attributes and Transformations (DQM Setup - Detailed only). See: Defining Attributes and Transformations.
-
DQM Related Profile Options (DQM Setup - Detailed only). See: DQM Deployment Category, DQM Fuzzy Key Generation Category, and Data Librarian Import Setup Category, Oracle Customer Data Librarian Implementation Guide.
DQM : Generate XML Data for the Diagnostic Reports
The DQM : Generate XML Data for the Diagnostic Reports program runs when you create a DQM diagnostic report from the DQM Diagnostics page. You can also run this program from Standard Request Submission to resubmit a previously run report, exactly the same as resubmitting from the DQM Diagnostics page. See: DQM Diagnostic Reports.
Program Parameter
Select the name of the DQM diagnostic report to resubmit.
Related Topics