Optimizing Audience Lists with Predictive Analytics
This chapter covers the following topics:
- Overview of Predictive Analytics
- Understanding and Building Predictive Models
- Evaluating Model Build Results
- Improving Model Results
- Building a Model
- Understanding Scoring Runs Generation
Overview of Predictive Analytics
Predictive analytics is a process used to discover strong, meaningful patterns and relationships in large amounts of data. These patterns and relationships are used to more accurately predict and analyze the behavior of customers and prospects.
For example, you can use the Oracle Data Mining functionality within Oracle Marketing to predict customer behavior for a variety of purposes, such as identifying which customers are most likely to:
-
Respond to your marketing campaign
-
End their relationship with your organization
-
Purchase a particular product
-
Be profitable to you
Effective predictive analytics enables you to make better business decisions. You can more effectively apply your marketing budget by targeting only the strongest prospects, thereby driving up margin.
The predictive analytics process consists of the following general steps and concepts:
-
Building a model
A model is a set of rules that can be used to predict the value of a specific customer attribute based on the known values of other attributes.
Building a model involves using data mining algorithms to create a set of rules based on the training data it is supplied. The training data is historical information about existing customers. This information consists of the known values for customer attributes such as direct mail responder, income, age, gender, and so on.
Oracle Marketing provides seeded model types (three response, one loyalty/retention, one product affinity, and one customer profitability models) to help automate the data mining process. Custom model types that predict any customer behavior can also be implemented.
-
Evaluating model results
Three reports are generated automatically when a model is built: Lift Chart, Performance Matrix, and Attribute Importance. By evaluating this information, you can determine the accuracy of the model and make adjustments to the training data that will improve the performance and predictive power of the model.
-
Scoring a target population
The process of scoring is also referred to as executing a scoring run. During a scoring run, a model is used to predict the future behavior of a target population. The score assigned to each customer record in the target population indicates the likelihood that this customer will exhibit a particular behavior. For example, customer A may be scored with a 90% probability of responding to a particular e-mail campaign.
-
Viewing the scoring run results and generating a list
The scoring run results are presented as a continuous range of 10 segments. Each segment has an associated percentage range (for example, 80–89.99%). The percentage indicates the likelihood that the customers within a particular range will exhibit the target behavior.
From the scoring run results page, you can generate lists of customer records. The breakdown into segments allows you to narrow your target population and select only the customers who exhibit the desired behavior.
Each of the steps above is described in more detail in the following sections.
Understanding and Building Predictive Models
The process of building a model consists of the following steps:
-
Creating the model by selecting a
The target comprises a target field and a data source. The data source is implied through the model type and target field association.
Related Topics
About Model Types
Oracle Marketing models are predictive models used to predict future customer behavior. They are built using the Naive Bayes algorithm, which can predict binary or multi-class outcomes. Currently in Oracle Marketing, this algorithm is used to predict the binary outcomes of a target field.
For example, you might want to predict which customers are likely to respond to a direct marketing campaign. The possible values for the target field would be yes or no.
The following model types are seeded in the application and are designed to automate the model building process.
-
Response models
-
E-mail
-
Direct Mail
-
Telemarketing
-
-
Loyalty/Retention model
-
Product Affinity model
-
Customer Profitability model
-
Custom model
A description of each model type is provided in the following table.
Model Types Model Type Description Response Use these three model types (e-mail, telemarketing, and direct mail campaigns) to predict which customers and prospects are most likely to respond to the corresponding marketing activity. Loyalty/Retention Use this model to predict which customers are likely to end their relationship with your organization. Product Affinity model Use this model to predict the likelihood of a customer purchasing a particular product or products from a particular product category. This model analyses a customer’s past purchasing patterns for a product or product category and predicts the customer’s affinity for a product or product category. After building this model for a specific product or product category, you can score a list to determine the product affinity. Customer Profitability model Use this model to score customers and prospects with unknown profitability to determine which ones are likely to be profitable. The Customer Profitability model will identify and score a single customer record to predict the customer’s profitability. For Organization Profitability model, you can score a list of organization contacts and predict their likelihood of being profitable. Custom Use this model to predict any type of customer behavior within the Oracle customer model (TCA) or a user-defined data source. The target behavior must be based on a data attribute that is binary (yes or no) in nature.
Sample Business Scenarios
The following scenarios are examples where you can use predictive modeling to help you generate lists whose members are most likely to exhibit the desired behavior. Sections later in the chapter describe the different functionality and tasks mentioned in the scenarios in detail.
-
You find that the number of responses to your campaigns for specific products are decreasing. You will create a Product Affinity model, train it using a list of customers who have bought the product in the past, build the model, and test its effectiveness. You can then score a list of new customers or prospects and predict the probability of their purchasing the product.
-
You have budgetary restrictions and would like to generate an optimal list of customers to target. After building and scoring your model, you will perform an Optimal Targeting Analysis. For this, you will update the cost and revenue data, generate and view the Optimal Targeting chart, enter budget constraints, and generate the optimal list you should target in a campaign activity.
About Data Sources and Targets
When creating a model, you must select a data source and a target. A data source consists of a flexible set of customer attributes that are evaluated by the data mining engine. The data mining engine determines which attribute values correlate with the target behavior (yes or no).
A target field is a column in the data source that represents the customer behavior you are trying to predict. Selecting the target while creating a model automatically selects the target field. For example, your System Administrator might define a target called Home Ownership that is mapped to a column in a specific user-defined data source with the name Own Rent Flag.
Oracle Marketing currently supports binary outcomes for the target field. As such, the possible value for a target field must either be binary or must be mapped to a binary outcome. For example, if the value for a field can be an income, and you are interested in high income households, then values equal to or exceeding $100,000 could be mapped to 1 (yes), and values under $100,000 could be mapped to 0 (no).
User-defined data sources and target fields can be set up by your System Administrator. System Administrators should also know the attributes present in these data sources.
Oracle Marketing provides two seeded data sources for each model type: TCA Persons for B2C models and TCA Organization Contacts for B2B models. Both of these data sources are associated with customer data from the Oracle customer model (TCA). Refer the Oracle Marketing Implementation Guide for a complete list of attributes included in the seeded data sources.
The following table lists the seeded targets and data sources provided by Oracle Marketing for the different model types. For Custom model types, your System Administrator must define the associated target fields and data sources. They can also create additional data sources and targets for the out-of-the-box models.
| Model Type | Data Source | Targets |
|---|---|---|
| Direct Mail Response | Organization Contacts | B2B: Direct Mail Responders |
| Persons | B2C: Direct Mail Responders | |
| E-Mail Response | Organization Contacts | B2B: E-Mail Responders |
| Persons | B2C: E-Mail Responders | |
| Telemarketing Response | Organization Contacts | B2B: Telemarketing Responders |
| Persons | B2C: Telemarketing Responders | |
| Loyalty/Retention | Organization Contacts | B2B: Loyalty/Retention |
| Persons | B2C: Loyalty/Retention | |
| Product Affinity | Organization Contacts | B2B: Product Affinity |
| Persons | B2C: Product Affinity | |
| Customer Profitability | TCA Organization Contacts | B2B: Customer Profitability |
| TCA Persons | B2C: Customer Profitability | |
| Custom | None | None. Must be set up by your System Administrator. |
About Training Data
In data mining, a model requires a data set from which to learn and build the model. The data set is referred to as the training data and the process of learning is referred to as training the model.
Training data consists of organizations contacts or individuals that you select. It should consist of members:
-
Whose characteristics closely resemble the target population that will be scored with the model
-
Whose behavior and responses are known
The more similar the training data is to the target population, the greater the predictive power of the model. For example, to conduct a telemarketing campaign for consumers, you would train the model using data that consists of consumers targeted by a similar telemarketing campaign in the past, and whose response to the campaign is known.
Note: If historical information from a similar campaign is not available, you must create and execute a test campaign before you can build a model.
About Building a Model
As mentioned above, model building is the process of training the model using a data set that you have selected. The data set consists of both positive and negative values (responses, affinity, or profitability). During model building, the data set is divided into two parts: input data (70% of the training data set) and holdout or test data (30% of the training data set). The test data is to used to validate the discovered relationship and patterns for determining the effectiveness of the model.
Both positive and negative values are split in the 70:30 ratio. Which means once split, the input data will contain 70% of the positives and 70% of the negatives and the test data will contain 30% of the positives and 30% of the negatives. This ensures that the input and the test data reflect the positives and negatives proportion in the data set. The training data should have adequate number of positive and negative values to successfully build a model.
For more information on the test data and how it is used, see Evaluating Model Build Results.
The data mining engine uses the input data to discover relationships and patterns to build a set of rules. Depending upon the target field and data source selected, the application may examine the following:
-
For a seeded data source, more than 150 customer attributes comprise the Oracle customer model (TCA). Refer the Oracle Marketing Implementation Guide for a complete list of attributes.
-
A variety of customer attributes that contain customer information from a user-defined data source.
The attributes examined can include demographic information such as age, gender, and income. Historical data can include information such as the number of times a customer has been contacted, number of past purchases, and the number of service requests they have opened. It can also include data collected using your Customer Relationship Management (CRM) applications, or data that you have purchased from outside vendors and imported into the database.
Different types of models are trained on different subsets of attributes depending upon the target audience. Here are some examples.
-
A response model targeting organization contacts through a telemarketing campaign may examine data such as the number of employees in the organization, annual revenue, and business transaction history. A response model for a telemarketing campaign targeting individuals might instead examine detailed personal information such as age, household income, and personal transaction history.
-
A loyalty/retention model will examine the attributes of customers who have and have not placed an order with your organization in the last three months.
-
A customer profitability model will examine the financial attributes, role, and department of customers and whether a customer is a decision maker.
-
A product affinity model will analyze a customer’s past purchasing pattern for products or product categories to be able to predict the customer’s affinity for the product or product category.
About Model Statuses
The status of a model indicates its state. The current status of a model determines whether or not you can use it for a build or a scoring run, modify it, copy it, or change its status.
The following table provides a description of each status, what the status can be reset to, what fields you can modify, and whether or not you can copy the model.
| Status | Meaning | Can be reset to | What you can modify | What you can copy |
|---|---|---|---|---|
| Draft | All new models have this status initially. | Archived (manually) | All fields. | Create an identical model with a different name and status of Draft. |
| Scheduled | Model is scheduled to be built. | Draft by cancelling the build. | All fields. | Create an identical model with a different name and status of Draft. |
| Building | The application is in the process of building the model. | Draft by cancelling the build. | Training data is locked. | Create an identical model with a different name and status of Draft. |
| Failed | An error occurred while building or previewing the model. | Archived (manually) | View the model log, make the necessary changes. Preview or rebuild the model. | Create an identical model with a different name and status of Draft. |
| Invalid | The model was successfully built (status was Available), but cannot be used for scoring because changes were made to the training data. See Invalid below for more information. | Archived (manually) | Rebuild the model. | Create an identical model with a different name and status of Draft. |
| Previewing | The training data has been submitted for previewing. If successful, the status is changed to Draft. If the preview fails, the status is changed to Failed. A request to build the model during this state terminates the preview. |
Cannot be reset. | All fields. | Create an identical model with a different name and status of Draft. |
| Scoring | A scoring run is taking place. | Available by cancelling the scoring run. | Target population data is locked. | Create an identical model with a different name and status of Draft. |
| Available | Model is built and available for a scoring run. When rebuilding a model, the results of the previous build are purged. |
Archived (manually) | All fields. | Create an identical model with a different name and status of Draft. |
| Expired | The model expires at the end of the date you enter in the Expiration Date field. | Cannot be reset. | Cannot be modified. | Create an identical model with a different name and status of Draft. |
| Archived | Archived models only appear in the All Models list. The application automatically deletes the source data for the model. |
Cannot be reset. | Cannot be modified. | Create an identical model with a different name and status of Draft. |
Invalid
As stated in Table Model Status, a status of Invalid means that the model was successfully built, but that some change occurred after the build that has caused the status to change. The changes that can result in a status of Invalid are:
-
A column in the data source is disabled or enabled for data mining.
-
The training data selections are changed. For example:
-
Campaign activity selections are changed for a Response model
-
Workbooks, lists, or segment selections are changed for a Loyalty/Retention model
-
Attributes or workbook filters for training data sources are changed
-
Selection methods or record counts are changed
-
-
When the status of a model is Invalid, it cannot be used for a scoring run. You can rebuild the model, and if the build is successful, the status will change to Available. You can then use it for a scoring run.
Evaluating Model Build Results
The accuracy of a model is determined by evaluating the results of the model build. The evaluation is performed by applying the set of rules created during the model build to the test data (30% of the total data made up of 30% of the positives and 30% of negatives).
Because the actual value of the target field for the test data is known, the predicted and actual values are compared to determine the effectiveness of the model.
One report and two charts are created during the evaluation. The following table describes what you can use each for.
| Report or Chart | Use |
|---|---|
| Lift Chart | A graphical representation of the benefits of using the model over contacting your target population at random. |
| Performance Matrix Report | Provides statistical insight into the accuracy of the model build. |
| Attribute Importance Chart | Displays the predictive power of the customer attributes in determining the target value. |
Based upon the information in these reports, you can make modifications to your data that will improve the predictive power of your model. See Improving Model Results.
About the Lift Chart
The Lift Chart illustrates the benefit of using a predictive model to intelligently select a portion of your target population as opposed to targeting the entire population at random. Targeting only the strong prospects allows you to reduce marketing costs and improve your return on investment.
The x axis, Percent Targeted, is the total target population. The y axis, Percent of Records, is the population exhibiting the target behavior. For a Response model, this indicates the percentage of positive responders. For a Loyalty/Retention model, this indicates the percentage of customers who have not placed an order within the last three months. For a Customer Profitability model, this indicates the percentage of profitable customers. For a Product affinity model, this indicates percentage of purchasers for a selected product or product category.
The following figure displays a sample lift chart.
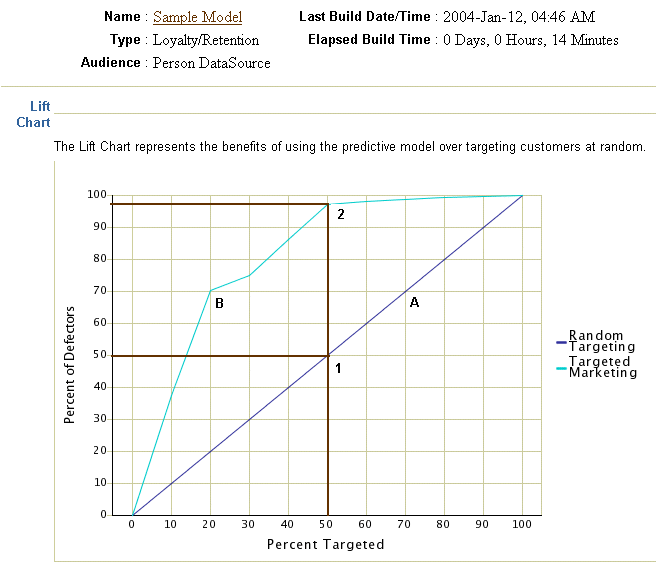
In the graph, the A and B lines represent the percentage of the total population (x axis) that you must target to reach the desired percentage of responders, purchasers, defectors, or profitable customers (y axis).
The curved line (B) is the lift. It indicates the advantage the model provides over targeting prospects at random. The more the line curves to the upper left hand corner of the graph, the more benefit you will achieve with the model.
Reading different points along the lines indicates what percentage of the total population you must target to meet your goal. In the Lift Chart in Figure 15–1, let us assume that our target population consists of 100,000 customers (x axis) and the total responders equal 5,000 (y axis). The intersection labeled 1 indicates that randomly contacting 50% (50,000) of your target population might yield a positive response rate of 50% (2,500). The intersection labeled 2 indicates that by using the predictive model, you can selectively target just 50% (50,000) of the population with the possibility of a 97% (4,850) response rate.
This outcome demonstrates the increase in campaign return on investment that may be achieved using predictive modeling.
You can also view a table reporting the lift chart details below the chart and can also download the data to a .csv file.
About the Performance Matrix Report
The Performance Matrix report (also referred to as a Confusion Matrix) provides statistical insight into the accuracy of the model. It displays information in two formats: as record counts, and as percentages. It rates the predictions made by the model against what actually occurred within the holdout sample of the training data.
The following figure displays a sample Performance Matrix Report.
A Sample Performance Matrix Report
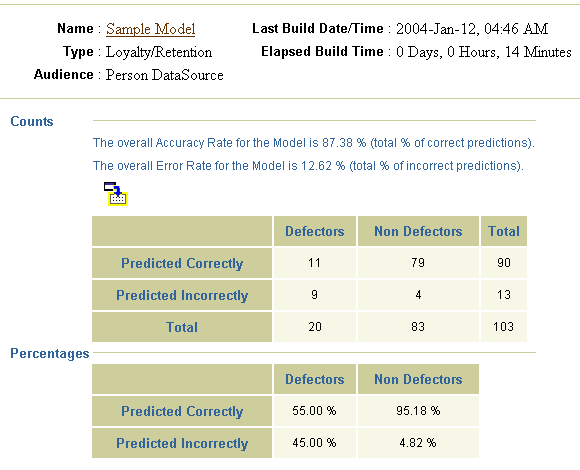
As shown in the figure, the Counts table displays the number of correct and incorrect predictions the model made. For example, out of 90 responders, the model predicted 79 non defectors correctly and 4 incorrectly.
The Percentages table shows the overall accuracy rate of the model in percentage numbers. For example, the percentage of responders predicted correctly is 79/90 or 95.18%.
About the Attribute Importance Chart
The Attribute Importance chart displays the importance of the attributes in determining the target field value. It allows you to see which customer attributes have the most significant effect on the predictive capability of a model.
Attribute importance information can be displayed in three formats: as a pie chart, vertical bar chart, or a horizontal bar chart. Each slice of the pie chart is labeled with a percent; the total of the slices equals 100%. The bar charts indicate a numerical value for each attribute on the Y-axis. In the chart legends, the attributes are displayed in descending order of importance.
The following figure displays a sample Attribute Importance Chart.
A Sample Attribute Importance Chart
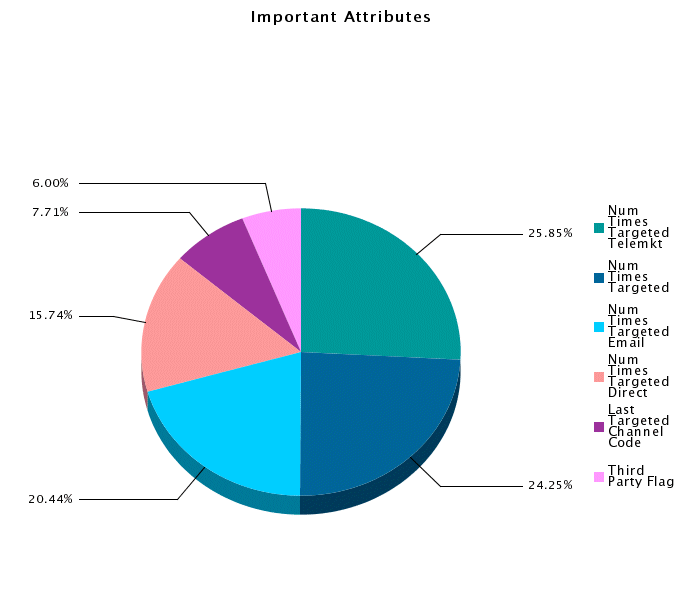
By default, only the top 10 attributes are displayed. You have the option of displaying additional or fewer attributes by entering a value in the Number of Attributes field.
Improving Model Results
After evaluating the model results, you can manipulate your training data in a number of ways to improve the predictive power of your model. You can:
-
Increase the Size of the Training Data Set
Larger sets of training data tend to produce more accurate results. While there is no minimum size, the training data set should include thousands if not tens of thousands of customers, prospects, or both for the best results.
-
Improve the Quality of Customer Data
If your data is missing many of the attributes, the models will still work, but will not be as accurate. Consider using other application products as these will automatically fill in the required customer data. For a list of attributes used in models, refer Oracle Marketing Implementation Guide.
-
Focus on Characteristics
Choose a training data with characteristics that are as close as possible to the target population. The more similar the two populations, the better the predictive model.
-
Split the Target Population
Split the target population and build multiple specialized models. The more precisely you target your audience, the more precise your model will be. For example, a shoe retailer may wish to build a separate model for marketing to males and females because the two markets behave very differently. Another approach this retailer might take would be to build a separate model for different age groups: children, adults, and seniors.
Building a Model
This section provides step-by-step instructions on model building. Use the following procedures to build a model.
Creating the Model
Use the following information to create a model.
Navigation: Analytics > Models
Notes
-
Expiration Date: Specify a date if you want your model to be available only for a specified period.
Next you will select the training data for your model. The training data can reside in the Oracle TCA or a user-defined data source. Proceed to do one of the following:
-
Selecting Training Data For Response Models Using Seeded Data Sources
-
Selecting Training Data for Loyalty/Retention Models Using Seeded Data Sources
-
Selecting Training Data for a Customer Profitability Model Using Seeded Data Sources
-
Selecting Training Data for a Product Affinity Model Using Seeded Data Sources
-
Selecting Training Data for Custom Models Using Seeded or User-Defined Data Sources
Selecting Training Data For Response Models Using Seeded Data Sources
Follow this procedure to select the training data for response models that will use an Oracle Marketing seeded data source. Your data source is seeded if it is listed as TCA Persons or TCA Organization Contacts.
Prerequisites
-
The basic information for the model must be set up. See Creating the Model.
-
You must know the name of the campaign and the campaign activity that contains the historical data that will be used to train your model.
-
The population targeted by the historical campaign must have trackable similarities to the population you will target with your new campaign.
-
The campaign must include both, responders and non-responders.
Navigation: Analytics > Models > Training Data
Notes
-
To restrict the size of the training data, choose a Selection Method and/or specify minimum and maximum Record Count numbers. For example, to select records starting from the top down until some maximum number is reached, select Top Down and enter a value in the Maximum field. The system applies the Selection Method criteria before the Record Count criteria. If a conflict occurs, the Record Count criteria takes precedence.
-
Preview: During the preview, the model status changes to Previewing and when the preview is complete, the model status changes to Draft.
-
Monitor Preview: Click to view the progress of the training. If you find the green line moving downwards from a point, that is the point of failure of the training.
Selecting Training Data for Loyalty/Retention Models Using Seeded Data Sources
Follow this procedure to select the training data for loyalty/retention models that will use an Oracle Marketing seeded data source. Your data source is seeded if it is listed as TCA Persons or TCA Organization Contacts.
-
The basic information for the loyalty/response model must be set up. See Creating the Model.
-
The source for the training data must exist
-
The training data must:
-
Include customers who have and who have not placed an order within the last three months
-
Be as similar as possible to your target population
-
Include demographic, transaction history, and account status information
Navigation: Analytics > Models > Training Data
-
Notes
-
The operations for the data sources can be:
-
Include: Include all the customer records in this source.
-
Exclude: Exclude all the customer records in this source from the previous sources.
-
Intersect: Use only the customer records common to this source and the previous sources.
When using multiple training data sources, for the first data source selected, the Order must be 1 and Operation must be Include.
-
-
To restrict the size of the training data, choose a Selection Method and/or specify minimum and maximum Record Count numbers. For example, to select records starting from the top down until some maximum number is reached, select Top Down and enter a value in the Maximum field. The system applies the Selection Method criteria before the Record Count criteria. If a conflict occurs, the Record Count criteria takes precedence.
-
Preview: During the preview, the model status changes to Previewing and when the preview is complete, the model status changes to Draft.
-
Monitor Preview: Click to view the progress of the training. If you find the green line moving downwards from a point, that is the point of failure of the training.
Note: The application looks at each list and performs the include, exclude, and intersect operations in the order specified. For example, you specify three sources numbered 1, 2 and 3, with no size restrictions.
-
The application includes all of the records in source 1 in the training data set. We will call this the current training data.
-
It then compares the current training data with source 2. If the operation is exclude, the data is modified to consist of the records unique to source 1 only. This set of records is now the current training data.
-
Finally, the application compares the current training data with source 3. If the operation is intersect, it modifies the data to consist of only the records that are common to both sets (in other words, the results from step 2 and source 3.)
Selecting Training Data for a Customer Profitability Model Using Seeded Data Sources
Follow this procedure to select the training data for customer profitability models that will use an Oracle Marketing seeded data source. Your data source is seeded if it is listed as TCA Persons or TCA Organization Contacts.
Prerequisites
-
The basic information for the Customer Profitability model must be set up. See Creating the Model.
-
The source for the training data must exist
-
The training data must:
-
Include customers who have and who have not placed an order within the last three months
-
Be as similar as possible to your target population
-
Include demographic, transaction history, and account status information
-
Navigation: Analytics > Models > Training Data
Notes
-
The operations for the data sources can be:
-
Include: Include all the customer records in this source.
-
Exclude: Exclude all the customer records in this source from the previous sources.
-
Intersect: Use only the customer records common to this source and the previous sources.
When using multiple training data sources, for the first data source selected, the Order must be 1 and Operation must be Include.
-
-
To restrict the size of the training data, choose a Selection Method and/or specify minimum and maximum Record Count numbers. For example, to select records starting from the top down until some maximum number is reached, select Top Down and enter a value in the Maximum field. The system applies the Selection Method criteria before the Record Count criteria. If a conflict occurs, the Record Count criteria takes precedence.
-
Preview: Click to preview the record count, number of positive responses, and the percent of positive responses. During the preview, the model status changes to Previewing and when the preview is complete, the model status changes to Draft.
-
Monitor Preview: Click to view the progress of the training. If you find the green line moving downwards from a point, that is the point of failure of the training.
Selecting Training Data for a Product Affinity Model Using Seeded Data Sources
Follow this procedure to select the training data for customer profitability models that will use an Oracle Marketing seeded data source. Your data source is seeded if it is listed as TCA Persons or TCA Organization Contacts.
Prerequisites
-
The basic information for the Product Affinity model must be set up. See Creating the Model
-
The source for the training data must exist
-
Target product categories and products must exist
-
The training data must:
-
Include customers who have and who have not placed an order within the last three months
-
Be as similar as possible to your target population
-
Include demographic, transaction history, and account status information
-
Navigation: Analytics > Models > Training Data
Notes
-
The operations for the data sources can be:
-
Include: Include all the customer records in this source.
-
Exclude: Exclude all the customer records in this source from the previous sources.
-
Intersect: Use only the customer records common to this source and the previous sources.
When using multiple training data sources, for the first data source selected, the Order must be 1 and Operation must be Include.
-
-
To restrict the size of the training data, choose a Selection Method and/or specify minimum and maximum Record Count numbers. For example, to select records starting from the top down until some maximum number is reached, select Top Down and enter a value in the Maximum field. The system applies the Selection Method criteria before the Record Count criteria. If a conflict occurs, the Record Count criteria takes precedence.
-
Preview: Click to preview the record count, number of positive responses, and the percent of positive responses. During the preview, the model status changes to Previewing and when the preview is complete, the model status changes to Draft.
-
Monitor Preview: Click to view the progress of the training. If you find the green line moving downwards from a point, that is the point of failure of the training.
Selecting Training Data for Custom Models Using Seeded or User-Defined Data Sources
To select training data for a custom model from the Oracle customer model (TCA) or a user-defined data source, follow the steps below.
Prerequisites
-
The basic information for the custom model must be set up. See Creating the Model
-
The source for the training data must exist
-
The training data must be as similar as possible to your target population
Navigation: Analytics > Models > Training Data
Notes
-
To restrict the size of the training data, choose a Selection Method and/or specify minimum and maximum Record Count numbers. For example, to select records starting from the top down until some maximum number is reached, select Top Down and enter a value in the Maximum field. The system applies the Selection Method criteria before the Record Count criteria. If a conflict occurs, the Record Count criteria takes precedence.
-
Preview: Click to preview the record count, number of positive responses, and the percent of positive responses. During the preview, the model status changes to Previewing and when the preview is complete, the model status changes to Draft.
-
Monitor Preview: Click to view the progress of the training. If you find the green line moving downwards from a point, that is the point of failure of the training.
Scheduling a Build for a Model
Use the following information to schedule a build for your model.
PrerequisitesFor all model types, the model must exist and the training data set must be specified, including any restrictions on the training data size.
Navigation: Analytics > Models > Build
Notes
-
Model building may impact system performance. Therefore, consider scheduling builds for off-peak hours.
-
You can check the status field for the model to ascertain when the model building is complete. If the build was successful, the status changes to Available.
Viewing Build Results
Use the following information to view the build results for your model.
Prerequisites
-
The model must exist
-
The training data set must be specified, including any restrictions on the training data size
-
Model should have been built and in Available status
Navigation: Analytics > Models
Notes
-
Navigate to Results > Lift Chart to view the benefits of using the predictive model over targeting customers at random. The information is displayed both, as a lift chart and a table.
-
Navigate to Results > Performance Matrix to view the predictive model’s accuracy in making predictions.
-
Navigate to Results > Attribute Importance and select the chart type and number of attributes you want to view in the chart. The chart helps you measure the customer attributes that have the highest predictive power.
Understanding Scoring Runs Generation
Scoring is the process of using a model to predict the future behavior of a specific population based on the attribute values of individual customer records. The score assigned to a customer or prospect indicates the likelihood that they will exhibit the desired behavior.
Because of budget, resource, or other constraints, you may need to restrict the size of the list you are scoring and specify a minimum and a maximum size for it. You may also choose to score the target population immediately or specify a date and time when the scoring should execute.
After scoring, the target population is divided into ten continuous segments called deciles. Each decile represents a certain number of customers, prospects, or both. The sum of the record counts in each decile equals the total target population. The deciles are ordered from the highest to the lowest probability of displaying the target behavior. Therefore, the customer records in decile 1 are the most likely to exhibit the behavior you are interested in.
Based on this information, you can select the groups with the highest probability of exhibiting a target behavior and generate a list. The list can then be used for marketing activities such as executing an e-mail campaign. Campaign execution closes the loop of using a predictive model to score a target population and generate a list of customers or prospects that are most likely to exhibit the target behavior.
You can also perform an Optimal Targeting analysis and then generate an optimal list of people to target for your marketing activities. See Optimal Targeting Analysis for the details of Optimal Targeting analysis.
Once you have generated a list, you can access it from Audience Workbench. To view the actual names on the list and other related details, click the Entries link.
For more information about lists, see Creating a List Using Natural Language Query and Using Target Groups.
An example of the scoring run results for a Response model is shown in the following table. The table Scoring Run Report provides a description of each column in the scoring run results table.
| Decile | Propensity to Respond* | Number of Records | Percent of Positive Values | Include in List |
|---|---|---|---|---|
| 1 | 90-100% | 1560 | 26.54 | x |
| 2 | 80-89.99% | 183 | 3.11 | x |
| 3 | 70-79.99% | 87 | 1.48 | x |
| 4 | 60-69.99% | 48 | .82 | x |
| 5 | 50-59.99% | 45 | .77 | - |
| 6 | 40-49.99% | 78 | 1.33 | - |
| 7 | 30-39.99% | 231 | 3.93 | - |
| 8 | 20-29.99% | 183 | 3.11 | - |
| 9 | 10-19.99% | 261 | 4.44 | - |
| 10 | 0-9.99% | 3,201 | 54.47 | - |
* Propensity to Respond is displayed for Response model types. For Loyalty/Retention models, this column is labeled Propensity to Defect; for Customer Profitability model it is labeled Profitability; for Product Affinity model it is labeled Propensity to Purchase; for Custom models it is labeled Propensity for Positive Target Values.
The following table describes each of the columns on a scoring run report.
| Column | Description |
|---|---|
| Decile | Each number represents a group of customers, prospects or both. The deciles are ordered by the probability of response, from the highest to the lowest. The first decile represents group members with a 90-100% likelihood of exhibiting the target behavior; the second decile includes those who are 80-89.99% likely to respond to your campaign; and so on. |
| Propensity to Respond (Response models) Propensity to Defect (Loyalty/Retention models) Propensity to Purchase (Product Affinity model) Propensity to be Profitable (Customer Profitability model) Propensity for Positive Target Values (Custom models) |
The probability that persons or organization contacts (customer records) in the decile will exhibit the target behavior. Select the deciles with the highest predicted probabilities for your list. For a Loyalty/Retention model, the percentages represent how likely the members of each decile are to defect to a competitor. For a Product Affinity model, the percentages represent the likelihood that members will purchase the specified product. For a Customer Profitability model, the percentages represent how profitable to you the customers will be. |
| Number of Records | The number of records in the decile. |
| Percent of Positive Values | A percentage representation of the number of records in the decile to the total number of records. |
| Include in List | This column contains a check box for each decile. The check boxes allow you to select the customer records in a particular decile and include them in a list. |
You can associate attachments, notes, and tasks to a scoring run and add users and teams to allow them access to the scoring run.
Related Topics
Optimal Targeting Analysis
If you have costs or budget constraints for your marketing activities, the build results from a model may not be adequate for arriving at an optimal target list. You can use the Optimal Targeting Analysis functionality and perform an analysis of the costs, revenues, and scored response probabilities of the population for a test campaign and derive the expected gross profit per customer. The result of this analysis is presented as an Optimal Targeting Chart.
Navigation: Campaign Workbench > Predictive Analytics > Select a model > Click Scoring Run to view details > in the side navigation Results: Optimal
Notes
-
Optimal Targeting Analysis is only available for the Response and Product Affinity models.
-
Profit Chart Display Type: The chart considers revenue and shows greater profit for a larger target audience. It does not consider the costs involved in increasing the target audience.
-
Return on Investment Chart Display Type: The chart considers the costs involved in a larger target audience and displays the optimum number of targeted customers to maximize the return on investment.
The X-axis of the Optimal Targeting Chart represents the total target population and the Y-axis represents the expected Return On Investment (ROI) or Profits for the campaign. The highest Y-axis value on the chart determines the optimal number of customers to target. In the following figure, it is seen that the optimal percent of customers to target is about 14%. You can modify the costs, margins per order, and costs per customer details and arrive at optimal ROI and profits.
A Sample Optimal Targeting Return On Investment Chart
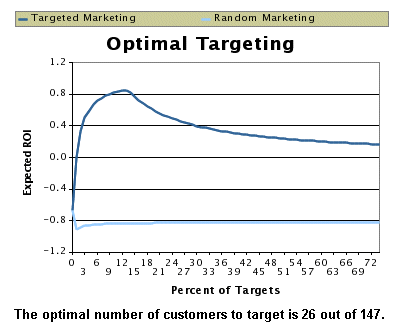
You can perform optimal targeting analysis for scored response probabilities of Response and Product Affinity models where targeted customers will place orders and you can easily identify the costs and revenues per customer. However, for Loyalty/Retention and Customer Profitability models, customers do not place orders and so identifying the costs and revenues per customer for optimal targeting analysis is not possible. The purposes of these models is to identify the profitable customers or arrive at marketing strategies to build up and retain customers. For example, in a call center, telemarketing executives may be instructed to assign higher priority to calls from profitable customers.
Once the optimal targeting chart is generated, you can generate an optimal list to target for a campaign activity. An optimal list may be associated with campaign activities in the Draft or Active statuses. You can restrict the size of the optimal list to within a budget amount or to the top x% of targets.
If a campaign activity already has a target group defined, then the entries in the optimal list generated are added to the target group. If no target group has been defined for a campaign activity, then a new target group is created with the entries of the optimal list.
Related Topics
See the Performing an Optimal Targeting Analysis and Generating an Optimal List topic in Generating a Scoring Run.
Generating a Scoring Run
The scoring process looks at the data mining attribute values for each member (customer record) of the target population. It then scores each record based on how likely that member is to exhibit the target behavior. The application then divides the population into 10 groups called deciles based on the score given to the record.
As part of the scoring process, costs and revenues for a customer can also be analyzed to arrive at optimal targeting data.
When the scoring is complete, you can generate a list by selecting the deciles (customer records) with a high likelihood of exhibiting the target behavior or by using the results of an optimal targeting analysis. The list would then be targeted in a future marketing campaign.
Use the following procedures to generate a scoring run.
-
Selecting a Target Population When Using a User-Defined Data Source
-
Performing an Optimal Targeting Analysis and Generating an Optimal List
Creating a Scoring Run
Navigate to Analytics > Models and Analytics > Scoring Runs to create a scoring run.
Prerequisites: A model that has been built and is in the Available status
To download the list of scoring runs to a .csv file, click the Download to CSV file icon, click Save in the File Download dialog box, navigate to a relevant folder, and save the .csv file.
Selecting Target Population When Using a Seeded Data Source
Your data source is seeded if it is listed as TCA Persons or TCA Organization Contacts. Use the following information to select seeded data sources for scoring.
Prerequisites: A scoring run must be created for a model
Navigation: Analytics > Scoring > Selections
Notes
-
The operations for the data sources can be:
-
Include: Include all the customer records in this source.
-
Exclude: Exclude all the customer records in this source from the previous sources.
-
Intersect: Use only the customer records common to this source and the previous sources.
When using multiple training data sources, for the first data source selected, the Order must be 1 and Operation must be Include.
Note: The application looks at each list and performs the include, exclude, and intersect operations in the order specified. For example, you specify three sources numbered 1, 2 and 3, with no size restrictions.
-
The application includes all of the records in source 1 in the target population set. We will call this the current target population.
-
It then compares the current target population with source 2. If the operation is exclude, the data is modified to consist of the records unique to source 1 only. This set of records is now the current target population.
-
Finally, the application compares the current target population with source 3. If the operation is intersect, it modifies the data to consist of only the records that are common to both sets (in other words, the results from step 2 and source 3.)
-
-
To restrict the size of the scoring data, choose a Selection Method and/or specify minimum and maximum Record Count numbers. For example, to select records starting from the top down until some maximum number is reached, select Top Down and enter a value in the Maximum field. The system applies the Selection Method criteria before the Record Count criteria. If a conflict occurs, the Record Count criteria takes precedence.
-
Preview: During the preview, the scoring run status changes to Previewing. When the preview is complete, the scoring run status changes to Draft.
-
Monitor Preview: Click to view the progress of the scoring run. This will help you trouble shoot if the run fails. If you find the green line moving downwards from a point, that is the point of failure of the scoring run.
Selecting a Target Population When Using a User-Defined Data Source
For a user-defined data source, you can use a combination of attributes and Discoverer Workbook filters to restrict the size of your target population. If no filters are specified, the scoring run will select and score all of the records in the data source.
Use the following information to select a target population from a user-defined data source.
Prerequisites: A scoring run must be created
Navigation: Analytics > Scoring Runs > Selections
Notes
-
To restrict the size of the scoring data, choose a Selection Method and/or specify minimum and maximum Record Count numbers. For example, to select records starting from the top down until some maximum number is reached, select Top Down and enter a value in the Maximum field. The system applies the Selection Method criteria before the Record Count criteria. If a conflict occurs, the Record Count criteria takes precedence.
-
Preview: During the preview, the scoring run status changes to Previewing. When the preview is complete, the scoring run status changes to Draft.
-
Monitor Preview: Click to view the progress of the scoring run. This will help you trouble shoot if the run fails. If you find the green line moving downwards from a point, that is the point of failure of the scoring run.
Scheduling a Scoring Run
Use the following information to schedule the scoring run.
Prerequisite: A scoring run for a model must exist
Navigation: Analytics > Scoring Runs > Score
-
Scoring runs may impact system performance. Therefore, consider scheduling scoring for off-peak hours.
-
Monitor Scoring: Click to view the progress of the scoring. If you find the green line moving downwards from a point, that is the point of failure of the scoring.
Viewing Scoring Run Results
Use the following information to view the results of a scoring run. For information on scoring run statuses, see About Scoring Run Statuses
Prerequisites: The scoring run must be in the Completed status.
Navigation: Analytics > Scoring Runs > Results
Notes
-
Each decile represents a portion of the target population and indicates the likelihood that they will exhibit the target behavior.
About Scoring Run Statuses
The following table describes the seeded statuses for scoring runs, and tells you:
-
The meaning of each status
-
What status the scoring run can be changed to
-
What fields you can modify
-
If you can copy scoring runs with that status
| Status | Meaning | Can reset to | What you can modify | What you can copy |
|---|---|---|---|---|
| Draft | Initial status for all scoring runs. | Archived (manually) | All fields. | Create an identical scoring run with a different name and status of Draft. |
| Scheduled | The scoring run is scheduled. | Draft by cancelling the scoring run. | All fields. | Create an identical scoring run with a different name and status of Draft. |
| Running | The application is in the process of scoring the target population. | Draft by cancelling the scoring run. | Data selections are locked. | Create an identical scoring run with a different name and status of Draft. |
| Invalid | A scoring run that completed successfully (status was Completed) has been invalidated. | Archived (manually) | All fields. | All scoring run fields are locked and cannot be modified. |
| Failed | An error occurred while generating or previewing a scoring run. View the log, make the necessary changes, and resubmit it for a run or preview. |
Archived (manually) | All fields. | All scoring run fields are locked and cannot be modified. |
| Previewing | The run has been submitted for previewing. If the preview is: - successful, the status changes to Draft. - unsuccessful, the status changes to Failed. A request to score will terminate the preview operation. |
Scheduled by setting up a run time. | All fields. | Create an identical scoring run with a different name and status of Draft. |
| Completed | The scoring run finished and was successful. | Archived (manually) | All fields. | Create an identical scoring run with a different name and status of Draft. |
| Archived | Archived scoring runs appear only in the All Scoring Runs list. The application automatically deletes any source data for the scoring run. |
Cannot be reset. | Data selections are locked. | Create an identical scoring run with a different name and status of Draft. |
Generating a List Based on Decile Scores
Use the following information to use the deciles from the scoring run to generate a list.
Prerequisite: The scoring run must be in the Completed status
For more information on scoring run statuses, see About Scoring Run Statuses.
Navigation: Analytics > Scoring Runs
Notes
-
A decile represents a portion of the target population and indicates the likelihood that they will exhibit the target behavior.
-
To generate a list, the Workflow Background Process must be running. See your System Administrator or refer to the Oracle Marketing Implementation Guide for more information on the Workflow Background Process.
Performing an Optimal Targeting Analysis and Generating an Optimal List
Use the following information to use the deciles from the scoring run to generate a list.
Prerequisite: The scoring run must be in the Completed status
For more information on scoring run statuses, see About Scoring Run Statuses.
Navigation: Analytics > Scoring Runs
Campaign Activity: Only those campaign activities whose target groups have been created using the Advanced option of the audience workbench will be available for selection.
To generate a list, the Workflow Background Process must be running. See your System Administrator or refer to the Oracle Marketing Implementation Guide for more information on the Workflow Background Process.
Viewing Logs
For Data Mining, the log sequentially summarizes the back-end process occurs during model builds and scoring runs. If your build or scoring run fails, you can view the log to help determine the cause of the failure. Log entries are listed in ascending order.