| Netra Data Plane Software Suite 1.1 User's Guide |
| Netra Data Plane Software Suite 1.1 User's Guide |
| C H A P T E R 1 |
|
Software Overview |
This chapter is an introduction to the Netra Data Plane Software Suite 1.1, and provides installation and theoretical information. Topics include:
The Netra Data Plane Software Suite 1.1 is a complete board software package solution. The software provides an optimized rapid development and runtime environment on top of multi-strand partitioning firmware for Sun CMT platforms. The software enables a scalable framework for fast-path network processing, encompassing the following features:
The Netra Data Plane Software Suite 1.1 uses the tejacc compiler. tejacc is a component of the Teja NP 4.0 Software Platform, used to develop scalable, high-performance C applications for embedded multiprocessor target architectures.
tejacc operates on a system-level view of the application, through three techniques not usually found in a traditional language system:
The result is superior code validation and optimization, enabling more reliable and higher performance systems.
The Netra Data Plane Software Suite 1.1 is distributed in the Netra_Data_Plane_Software_Suite_1.1.zip package for SPARC® platforms. TABLE 1-1 describes the contents of the unzipped package:
For the Netra Data Plane Software Suite 1.1 to be supported, your system must have the appropriate, or newer, firmware installed.
 As superuser, use the banner command to verify your version of the OpenBoot
As superuser, use the banner command to verify your version of the OpenBoot PROM firmware.
PROM firmware.
See the following three examples for each system supported:
1. As superuser, obtain the system controller prompt.
| Note - If your system has not been configured to access the system controller over the network, refer to your system's documentation for information on how to do so. |
2. Use the showsc -v version command to check your system controller firmware versions.
If your system controller firmware versions are lower or older than that provided in the example, contact your Sun Service representative to inquire about a firmware upgrade.
The software in the package has the following dependencies:
| Note - The SUNWndps software package is only supported on a SPARC system running the Solaris 10 Operating System. |
| Note - If you have previously installed an older version of the Netra Data Plane Software Suite 1.1, remove it before installing the new version. See To Remove the Software |
1. After downloading the Netra Data Plane Software Suite 1.1 from the web, as superuser, change to your download directory and go to Step 2.
3. Install the SUNWndps and SUNWndpsd packages. Type:
The software is installed in the /opt directory.
4. Use a text editor to add both the /opt/SUNWndps/tools/bin and /opt/SUNWndpsd/tools/bin directories to your PATH environment variable.
|
|
1. After downloading the Netra Data Plane Software Suite 1.1 from the web, as superuser, change to your download directory and go to Step 2.
3. Add the SUNWndps and SUNWndpsd packages to your_directory. Type:
The software is installed in the /usr/local/your_directory directory.
4. Open the /usr/local/your_directory/opt/SUNWndps/tools/bin/tejacc.sh file in a text editor and find the following line:
5. Change the line in Step 4 to:
6. Use a text editor to add the /usr/local/your_directory/opt/SUNWndps/tools/bin directory to your PATH environment variable.
To remove the SUNWndps and SUNWndpsd packages, as superuser, type:
The Netra Data Plane Software Suite 1.1 is removed.
| Note - For more details about using the pkgadd and pkgrm commands, see the man pages. |
The instructions for building reference applications are located in the application directories. TABLE 1-2 lists the directories and instructional file.
The application image is booted over the network. Ensure the target system is configured for network boot. The command syntax is:
boot network_device:[dhcp|bootp,][server_ip],[boot_filename], [client_ip],[router_ip],[boot_retries],[tftp_retries],[subnet_mask],[boot_arguments]
TABLE 1-3 describes the optional parameters.
| Note - For the boot command, commas are required to demark missing parameters unless the parameters are at end of the list. |
|
1. Copy the application image to the tftpboot directory of the boot server.
2. As superuser, obtain the ok prompt on the server that is to boot.
3. From the ok prompt, type one of the following commands:
| Note - The -v argument is an optional verbose flag. |
In Teja NP, you write an application with multiple C programs that execute in parallel and coordinate with each other. The application is targeted to multiprocessor architectures with shared resources. Ideally, the applications are written to be used in several projects and architectures. Additionally, the Teja NP attains maximum performance in the target mapping.
When writing the application, you:
tejacc provides the constructs of threads, mutex, queue, channel, and memory pool within the application code. These constructs enable you to specify coordinated parallel behavior in a target-independent, reusable manner. When the application is mapped to a specific target, tejacc generates optimized, target-specific code. The constructs and their associated API is called late-binding.
One technique for scaling performance is to organize the application in a parallel-pipeline matrix. This technique is effective when the processed data is in the form of independent packets. For this technique, the processing loop is broken up into multiple stages and the stages are pipelined. For example, in an N-stage pipeline, while stage N is processing packet k, stage (N - 1) is processing packet (k + 1), and so on. In order to scale performance even further and balance the pipeline, each stage can run its code multiple times in parallel, yielding an application-specific parallel-pipeline matrix.
There are several issues with this technique. The most important being where to break the original processing loop into stages. This choice is dictated by several factors:
The context carried over from one stage to the next is reduced when the stack is empty at the end of that stage. Applications written with modular functions are more flexible for such architecture exploration. During the processing of a context, the code might wait for the completion of some long-latency operation, such as I/O. During the wait, the code could switch to another available data context. While applicable to most targets, such a technique is important when the processor does not support hardware multithreading. If the stack is empty when the context is switched, the context information is minimized. Performance is improved as code modularity becomes more granular.
Expressing the flow of code as state machines (finite state automata) enables multiple levels of modularity and fine-grained architecture exploration.
Standardized C programs can be compiled using tejacc without change. Two methods are available to reuse C code with tejacc:
Increasing the execution performance of existing C programs on multicore architectures requires targeting for parallel-pipeline execution. This process is iterative.
In the first iteration, some program functions are mapped to a second and additional processors, executing in parallel. All threads of execution operate on the same copy of the shared global data structures, with mutual exclusion primitives for protection.
In the second iteration, each thread operates on its own copy of the global data structures, leaving the others as shared. The threads coordinate with each other using both mutual exclusion and communication messages.
In the final iteration, each thread runs its functions in a loop, operating on a stream of data to be processed.
By using this method, the bulk of the application code is reused while small changes are made to the overall control flow and coordination.
C code developers are familiar with a compiler that takes a C source file and generates an object file. When multiple source files are submitted to the compiler, it processes the source files one by one. The tejacc compiler extends this model to a system-level, multifile process for a multiprocessor target.
The basic function of tejacc is to take multiple sets of user application source files and produce multiple sets of generated files. When processed by target-specific compilers or assemblers, these generated file sets produce images that are loaded into the processors of the target architecture. All user source files must adhere to the C syntax (see Language for the language reference). The translation of the source to the image is governed by options that control or configure the behavior of tejacc.
tejacc is a command-line program suitable for batch processing. For example:
In this example, there are two sets of source files, mysrcset and yoursrcset. The files in mysrcset are file1 and file2, and the files in yoursrcset are file2, file3, and file4. file2 intentionally appears in both source sets.
file2 defines a global variable, myglobal, whose scope is the source file set. This situation means that tejacc allocates two locations for myglobal, one within mysrcset and the other within yoursrcset. References to myglobal within mysrcset resolve to the first location, and references to myglobal within yoursrcset resolve to the second location.
A source set can be associated to one or more application processes. In that case, the source set is compiled several times and the global variable is scoped to the respective process address space. An application process can also have multiple source sets associated to it.
Each source set can have a set of compile options. For example:
tejacc options -srcset mysrcset -D mydefine file1 file2 -srcset yoursrcset -D mydefine -I mydir/include file2 file3 file4 |
In this example, when mysrcset is compiled, tejacc defines the symbol mydefine for file1 and file2. Similarly, when yoursrcset is compiled, tejacc defines the symbol mydefine and searches the mydir/include directory for file2, file3 and file4.
When a particular option is applied to every set of source files, that option is declared to tejacc before any source set is specified. For example:
tejacc -D mydefine other_options -srcset mysrcset file1 file2 -srcset yoursrcset -I mydir/include file2 file3 file4 |
In this example, the definition of mydefine is factored into the options passed to tejacc.
TABLE 1-4 lists some options to tejacc:
In addition to the tejacc mechanics and options, the behavior of tejacc is configured by user libraries that are dynamically linked into tejacc. The libraries describe to tejacc the target hardware architecture, the target software architecture, and the mapping of the variables and functions in the source set files to the target architecture. TABLE 1-5 describes some of the configuration options of tejacc.
The three entry point functions into the shared library files take no parameters and return an int.
The shared library files can be used for multiple configuration options, but the entry point for each option must be unique, take no parameters, and return an int. The trade-off is the ease of maintaining fewer libraries versus the speed of updating only one of several libraries.
Once the memory models are created, tejacc parses and analyzes the source sets and generates code for the source sets within the context of the models. Using the system-level information tejacc obtains from the models, in conjunction with specific API calls made in the user's source files, tejacc can apply a variety of validation and optimization techniques during code generation. The output by tejacc is source code as input to the target-specific compilers. Although the compiler-generated code is available for inspection or debugging, you should not modify this code.
Figure 1.1 shows the interaction of tejacc with the other platform components of Teja NP.
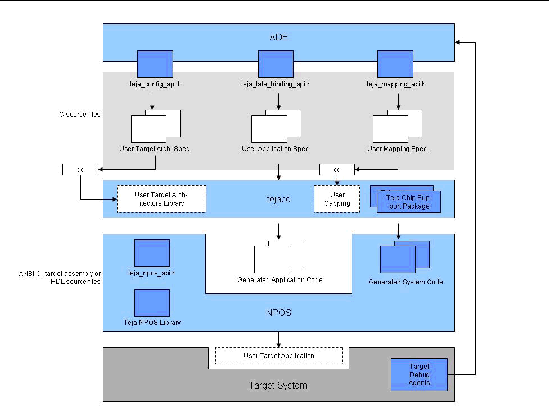
FIGURE 1-1 Teja NP 4.0 Overview Diagram
You create the dynamically linked shared libraries for the hardware architecture, software architecture, and map by writing C programs using the Teja Hardware Architecture API, the Teja Software Architecture API, and the Teja Map API respectively. The C programs are compiled and linked into dynamically linked shared libraries using the C compiler.
Your application source files might contain calls to the Teja Late-Binding API and the Teja NPOS API. tejacc is aware of the Late-Binding API. Depending on the context of the target hardware, software architecture, and the mapping, tejacc generates code for the Late-Binding API calls. The calls are optimized for the specific situation described in the system context. tejacc is not aware of the NPOS API, and calls to it pass to the generated code where the calls are either macro expanded (if defined in the NPOS library include file) or linked to the target-specific NPOS library.
Teja NP also provides a graphical application development environment (ADE) to visualize and manipulate applications. Description of the ADE is not within the scope of this document.
The Hardware Architecture API is used to describe target hardware architectures. A hardware architecture is comprised of processors, memories, buses, hardware objects, ports, address spaces, address ranges, and the connectivity among all these elements. A hardware architecture might also contain other hardware architectures, thereby enabling hierarchical description of complex and scalable architectures.
Most users will not need to specify the hardware architectures as the Teja NP platform is predefined. Only in the situation of a custom hardware architecture is the API used.
| Note - The hardware architecture API runs on the development host in the context of the compiler and is not a target API. |
Hardware architecture elements are building blocks that appear in almost all architectures. Each element is defined using the relevant create function, of the form: teja_type_create(). You can assign values to the properties of each function using the teja_type_set_property() and teja_type_get_property() functions.
TABLE 1-6 describes basic hardware architecture elements.
An architecture can contain other architectures, processors, memories, hardware objects, and buses. The respective create function for a given element indicates the containment relationship. An architecture, a processor, a memory, and a hardware object can connect to a bus using teja_type_connect() functions.
Utility functions are provided to look up a named element within an architecture, set the value of a property, and get the value of a property. These actions are accomplished with the teja_lookup_type(), teja_type_set_property(), and teja_type_get_property() functions respectively. Properties are set to select or influence specific validation, code generation, or optimization algorithms in tejacc. Each property and its effect is described in the Netra Data Plane Software Suite 1.1 Reference Manual.
Some hardware architecture elements are available for advanced users and might not be needed for all targets. Each element is defined using the relevant create function, of the form: teja_type_create(). You can assign values to their properties using the teja_type_set_property() and teja_type_get_property() functions.
TABLE 1-7 describes advanced hardware architecture elements.
A software architecture is comprised of operating systems, processes, threads, mutexes, queues, channels, memory pools, and the relationships among these elements.
A subgroup of the software architecture elements is defined in the software architecture description and used in the application code. This subgroup consists of mutex, queue, channel, and memory pool. The software architecture part of the API runs on the development host in the context of the compiler. The application part of the API runs on the target. The API that uses elements of the subgroup in the application code is called late-binding and it is treated specially by tejacc.
The Late-Binding API offers the functionality of mutual exclusion, queuing, sending and receiving messages, memory management, and interruptible wait. The functions in this API are known to tejacc. tejacc generates the implementation of this functionality in a context-sensitive manner. The context that tejacc uses to generate the implementation consists of:
You can choose the implementation of a late-binding object. For example, a communication channel could be implemented as a shared memory circular buffer or as a TCP/IP socket. You can also indicate how many producers and consumers a certain queue has, affecting the way late-binding API code is generated. For example, if a communication channel is used by one producer and one consumer, tejacc can generate the read/write calls from and to this channel as a mutex-free circular buffer. If there are two producers and one consumer, tejacc generates an implementation that is protected by a mutex on the sending side.
The advantage of this method over precompiled libraries is that system functions contain only the minimal necessary code. Otherwise, a comprehensive, generic algorithm must account for all possible execution paths at runtime.
If the channel ID is passed to the channel function as a constant, then tejacc knows all the characteristics of the channel and can generate the unique, minimal code for each call to that channel function. If the channel ID is a variable, then tejacc must generate a switch statement and the implementation must be picked at runtime.
Regardless of the method you prefer, you can modify the context without touching the application code, as the Late-Binding API is completely target independent. This flexibility enables different software configurations at optimization time without changing the algorithmic part of the program.
| Note - The software architecture API runs on the development host in the context of the compiler and is not a target API. The Late-Binding API runs on the target and not on the development host. |
You declare each of the late-binding objects (mutex, queue, channel, and memory pool) using the teja_type_declare() function. You can assign values to the properties of most of these elements using the teja_type_set_property() and teja_type_get_property() functions.
Each of these objects has an identifier indicated by the user as a string in the software architecture using the declare() function. In the application code, the element is labeled with a C identifier and not a string. tejacc reads the string from the software architecture and transforms it in a #define for the application code. The transformation from string to preprocessor macro is part of the interaction between the software architecture and the application code.
Multiple target-specific (custom) implementations of the late-binding objects are available. Refer to the Netra Data Plane Software Suite 1.1 Reference Manual for a full list of these custom implementations. Every implementation has the same semantics but different algorithms. Choosing the right custom implementation and related parameters is important at optimization time.
For example, with mutex, one custom implementation might provide fair access while another might be unfair. In another example, a channel with multiple consumers might not broadcast the same message to all consumers.
TABLE 1-8 describes the late-binding elements.
|
The mutex element provides mutual exclusion functionality and is used to protect critical regions of code. |
|
|
The queue element provides thread safe and atomic enqueue and dequeue API functions for storing and accessing nodes[1] in a first-in-first-out method. The Late-Binding API for queue consists of:
|
|
|
Memory pools provide an efficient, thread-safe, cross-platform memory management system. This system requires you to subdivide memory in preallocated pools. A memory pool is a set of user-defined, same-size contiguous memory nodes. At runtime, you can get a node from, or put a node to, a memory pool. This mechanism is more efficient at dynamic allocation than the traditional malloc() and free() calls. Sometimes the application needs to match accesses to two memory pools. Given a buffer from one memory pool, obtain the memory pool's index value and then obtain the node with the same index value from the other memory pool. The Late-Binding API for memory pool consists of:
|
|
|
The Channel API is used to establish connections among threads, to inspect connection state, and to exchange data across threads. Channels are logical communication mediums between two or more threads. Threads sending messages to a channel are called producers, threads receiving messages from a channel are called consumers. Channels are unidirectional, and they can have multiple producers and consumers. The semantics of channels are that of a pipe. Data is copied into the channel at the sender and is copied out of the channel at the receiver. It is possible to send a pointer over a channel, as the pointer value is simply copied into the channel as data. When pointers are sent across the channel, ensure that the consumer has access to the same memory or is able to convert the pointer to access that same memory. The Late-Binding API for channel consists of:
|
Each of the non-late-binding elements can be defined using the relevant teja_type_create() create function.
Use the teja_type_set_property() and teja_type_get_property() functions to assign values to the properties of most of these elements.
TABLE 1-9 describes other elements.
Utility functions are provided to look up a named element within an architecture, set the value of a property, and get the value of a property. These actions are accomplished with the teja_lookup_type(), teja_type_set_property(), and teja_type_get_property() functions respectively. Set properties to select or influence specific validation, code generation, or optimization algorithms in tejacc. Each property and its effect is described in the Netra Data Plane Software Suite 1.1 Reference Manual.
This section gives an overview of the Teja NP API for writing the user application files in the source sets given to tejacc. This API is executed on the target.
The Late-Binding API provides primitives for the synchronization of distributed threads, communication, and memory allocation. This API is treated specially by the tejacc compiler and it is generated on the fly based on contextual information. See Late-Binding Elements for more details. A complete reference of this API is provided in the Netra Data Plane Software Suite 1.1 Reference Manual.
The NPOS API consists of portable, target-independent abstractions over various operating system facilities such as thread management, heap-based memory management, time management, socket communication, and file descriptor registration and handling. Unlike late-binding APIs, NPOS APIs are not treated specially by the compiler and are implemented in precompiled libraries.
The memory management functions offer malloc and free functionality. These functions are computationally expensive, and should only be used in initialization code or non-relative critical code. On bare hardware targets the free() function is an empty operation, so only malloc() should be used to obtain memory that is not meant to be released. For all other purposes, the memory pool API should be used.
The thread management functions offer the ability to start and end threads dynamically.
The time management functions offer the ability to measure time.
The socket communication functions offer an abstraction over connection and non-connection oriented socket communication.
The signal handling functions offer the ability to register Teja signals with a handler function. Teja signals can be sent to a destination thread that runs in the same process as the sender. These functions are cross-platform, so they can also be used on systems that do not support UNIX-like signaling mechanism. Signal handling functions are more efficient than OS signals, and unlike OS signals, their associated handler is called synchronously.
Any function can be safely called from within the handler. This ability removes the limitations of asynchronous handling. Even in case the registered signal is a valid OS signal code, when the application receives an actual OS signal, the handler will still be called synchronously. If a Teja process running multiple threads receives an OS signal, every one of its threads will receive the signal.
Since Teja signals are handled synchronously, threads can only receive signals and execute their registered handler when the thread is in an interruptible state given by the teja_wait() function.
Any positive integer is a valid Teja signal code that can be passed to the registration function. However, if the signal code is also a valid OS code, such as SIGUSR1 on UNIX, the signal is also registered using the native OS mechanism. The thread will react to OS signals as well as to Teja signals.
A typical Teja signal handler reads any data from the relevant source and returns the data to the caller. The caller is teja_wait(), which in turn exits and returns the data to user program.
Registration of file descriptors has some similarities to registration of signals. The operation registers a fd with the system and associates the fd with a user-defined handler and optionally with a context, which is a user-defined value (for example, a pointer). Whenever data is received on the fd, the system automatically executes the associated handler and passes to it the context.
Just like signal handlers, file descriptor handlers are called synchronously, so any function can be safely called from within the handler. This ability removes the limitations of asynchronous handling.
Since fd handlers are called synchronously, threads can only receive fd input and execute their registered handler when the thread is in an interruptible state given by the teja_wait() function.
An fd handler reads the data from the fd and returns it to teja_wait(), which in turn returns the data to the user application.
A complete reference of the NPOS API is provided in the Netra Data Plane Software Suite 1.1 Reference Manual.
The Finite State Machine API enables easy modularization and pipelining of code. Finite state machines are used to organize the control flow of code execution in an application. State machine support is through various macros, which are expanded before they reach tejacc. While tejacc does not recognize these macros, higher level tools such as Teja NP ADE might impose additional formatting restrictions on how these macros are used.
A complete reference of the state machine API is given in the Netra Data Plane Software Suite 1.1 Reference Manual. The API includes facilities to:
The Map API is used to map elements of the user's source files to the target architecture. TABLE 1-10 describes these relationships.
If a variable is mapped multiple times, the last mapping is used. This functionality enables you to specify a general class of mappings using a regular expression and then refine the mapping for a specific variable.
| Netra Data Plane Software Suite 1.1 User's Guide | 820-2374-10 |
Copyright © 2007, Sun Microsystems, Inc. All Rights Reserved.
 Checking Your OpenBoot PROM Firmware Version
Checking Your OpenBoot PROM Firmware Version