Sun MPI 6.0 Software Programming and Reference Manual MPI 6.0 Software Programming and Reference Manual
|
| Sun MPI 6.0 Software Programming and Reference Manual
|
| C H A P T E R 4 |
|
Programming With Sun MPI I/O |
File I/O in Sun MPI is fully MPI-2 compliant. MPI I/O is specified as part of that standard, which was published in 1997. Its goal is to provide a library of routines featuring a portable parallel file system interface that is an extension of the MPI framework. See Related Documentation for more information about the MPI-2 Standard.
MPI I/O models file I/O on message passing; that is, writing to a file is analogous to sending a message, and reading from a file is analogous to receiving a message. The MPI library provides a high-level way of partitioning data among processes, which saves you from having to specify the details involved in making sure that the right pieces of data go to the right processes. This section describes basic MPI I/O concepts and the Sun MPI I/O routines.
MPI I/O uses the MPI model of communicators and derived data types to describe communication between processes and I/O devices. MPI I/O determines which processes are communicating with a particular I/O device. Derived data types can be used to define the layout of data in memory and of data in a file on the I/O device. (For more information about derived data types, see Data Types.) Because MPI I/O builds on MPI concepts, it's easy for a knowledgeable MPI programmer to add MPI I/O code to a program.
Data is stored in memory and in the file according to MPI data types. Herein lies one of MPI and MPI I/O's advantages: Because they provide a mechanism whereby you can create your own data types, you have more freedom and flexibility in specifying data layout in memory and in the file.
The library also simplifies the task of describing how your data moves from processor memory to the file and back again. You create derived data types that describe how the data is arranged in the memory of each process and how it should be arranged in that part of the disk file associated with the process.
Three functions are provided to handle the external32 format. This format, defined by the MPI Forum, represents data in a universal format that is useful for exchanging data between implementations or for writing it to a file. The functions are:
The Sun MPI I/O routines are described in Routines. But first, to be able to define a data layout, you will need to understand some basic MPI I/O data-layout concepts. The next section explains some of the fundamental terms and concepts.
The following terms are used to describe partitioning data among processes. FIGURE 4-1 illustrates some of these concepts.
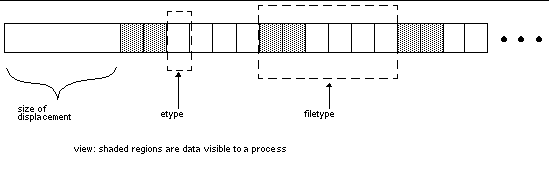
For a more detailed description of MPI I/O, see Chapter 9, "I/O," of the MPI-2 Standard.
When writing a Fortran program, you must declare the variable ADDRESS as follows:
INTEGER*MPI_ADDRESS_KIND ADDRESS |
MPI_ADDRESS_KIND is a constant defined in mpi.h. This constant defines the length of the declared integer.
This release of Sun MPI includes all the MPI I/O routines, which are defined in Chapter 9, "I/O," of the MPI-2 Standard.
Code samples that use many of these routines are provided in Sample Code.
MPI_File_open() and MPI_File_close() are collective operations that open and close a file, respectively; that is, all processes in a communicator group must together open or close a file. To achieve a single-user, UNIX-like open, set the communicator to MPI_COMM_SELF.
MPI_File_delete() deletes a specified file.
The routines MPI_File_set_size(), MPI_File_get_size(), MPI_File_get_group(), and MPI_File_get_amode() get and set information about a file. When using the collective routine MPI_File_set_size() on a UNIX file, if the size that is set is smaller than the current file size, the file is truncated at the position defined by size. If size is set to be larger than the current file size, the file size becomes size.
When the file size is increased this way with MPI_File_set_size(), new regions are created in the file with displacements between the old file size and the larger, newly set file size. Sun MPI I/O does not necessarily allocate file space for such new regions. You can reserve file space either by using MPI_File_preallocate() or by performing a read or write to unallocated bytes. MPI_File_preallocate() ensures that storage space is allocated for a set quantity of bytes for the specified file; however, its use is very "expensive" in terms of performance and disk space.
The routine MPI_File_get_group() returns a communicator group, but it does not free the group.
The opaque info object enables you to provide hints for optimization of your code, making it run faster or more efficiently, for example. These hints are set for each file, using the MPI_File_open(), MPI_File_set_view(), MPI_File_set_info(), and MPI_File_delete() routines. MPI_File_set_info() sets new values for the specified file's hints. MPI_File_get_info() returns all the hints that the system currently associates with the specified file.
When using UNIX files, Sun MPI I/O provides four hints for controlling how much buffer space it uses to satisfy I/O requests: noncoll_read_bufsize, noncoll_write_bufsize, coll_read_bufsize, and coll_write_bufsize. These hints can be tuned for your particular hardware configuration and application to improve performance for both noncollective and collective data accesses. For example, if your application uses a single MPI I/O call to request multiple noncontiguous chunks that form a regular strided pattern in the file, you can adjust the noncoll_write_bufsize to match the size of the stride. Note that these hints limit the size of MPI I/O's underlying buffers but do not limit the amount of data a user can read or write in a single request.
The MPI_File_set_view() routine changes the view the process has of the data in the file, specifying its displacement, elementary data type, and file type, as well as setting the individual file pointers and shared file pointer to 0.
MPI_File_set_view() is a collective routine; all processes in the group must pass identical values for the file handle and the elementary data type, although the values for the displacement, the file type, and the info object can vary. However, if you use the data-access routines that use file positioning with a shared file pointer, you must also give the displacement and the file type identical values. The data types passed in as the elementary data type and the file type must be committed.
You can also specify the type of data representation for the file. See File Interoperability for information about registering data representation identifiers.
|
Note - Displacements within the file type and the elementary data type must be monotonically nondecreasing. |
The 35 data-access routines are categorized according to file positioning. Data access can be achieved by any of these methods of file positioning:
This section discusses each of these methods in more detail.
While blocking I/O calls do not return until the request is completed, nonblocking calls do not wait for the I/O request to complete. A separate "request complete" call, such as MPI_Test() or MPI_Wait(), is necessary to confirm that the buffer is ready to be used again. Nonblocking routines have the prefix MPI_File_i, where the i stands for immediate.
All the nonblocking collective routines for data access are "split" into two routines, each with _begin or _end as a suffix. These split collective routines are subject to the semantic rules described in Section 9.4.5 of the MPI-2 Standard.
To access data at an explicit offset, specify the position in the file where the next data access for each process should begin. For each call to a data-access routine, a process attempts to access a specified number of file types of a specified data type (starting at the specified offset) into a specified user buffer.
The offset is measured in elementary data type units relative to the current view; moreover, holes are not counted when locating an offset. The data is read from (in the case of a read) or written into (in the case of a write) those parts of the file specified by the current view. These routines store the number of buffer elements of a particular data type actually read (or written) in the status object, and all the other fields associated with the status object are undefined. The number of elements that are read or written can be accessed using MPI_Get_count().
MPI_File_read_at() attempts to read from the file by the associated file handle returned from a successful MPI_File_open(). Similarly, MPI_File_write_at() attempts to write data from a user buffer to a file. MPI_File_iread_at() and MPI_File_iwrite_at() are the nonblocking versions of MPI_File_read_at() and MPI_File_write_at(), respectively.
MPI_File_read_at_all() and MPI_File_write_at_all() are collective versions of MPI_File_read_at() and MPI_File_write_at(), in which each process provides an explicit offset. The split collective versions of these nonblocking routines are listed in the preceding table.
For each open file, Sun MPI I/O maintains one individual file pointer per process per collective MPI_File_open(). For these data-access routines, MPI I/O implicitly uses the value of the individual file pointer. These routines use and update only the individual file pointers maintained by MPI I/O by pointing to the next elementary data type after the one that most recently has been accessed. The individual file pointer is updated relative to the current view of the file. The shared file pointer is neither used nor updated. (For data access with shared file pointers, see the next section.)
These routines have similar semantics to the explicit-offset data-access routines, except that the offset is defined here to be the current value of the individual file pointer.
MPI_File_read_all() and MPI_File_write_all() are collective versions of MPI_File_read() and MPI_File_write(), with each process using its individual file pointer.
MPI_File_iread() and MPI_File_iwrite() are the nonblocking versions of MPI_File_read() and MPI_File_write(), respectively. The split collective versions of MPI_File_read_all() and MPI_File_write_all() are listed in the preceding table.
MPI_File_seek
MPI_File_get_position
MPI_File_get_byte_offset
Each process can call the routine MPI_File_seek() to update its individual file pointer according to the update mode. The update mode has the following possible values:
The offset can be negative for seeking backwards, but you cannot seek to a negative position in the file. The current position is defined as the elementary data item immediately following the last-accessed data item.
MPI_File_get_position() returns the current position of the individual file pointer relative to the current displacement and file type.
MPI_File_get_byte_offset() converts the offset specified for the current view to the displacement value, or absolute byte position, for the file.
Sun MPI I/O maintains one shared file pointer per collective MPI_File_open() (shared among processes in the communicator group that opened the file). As with the routines for data access with individual file pointers, you can also use the current value of the shared file pointer to specify the offset of data accesses implicitly. These routines use and update only the shared file pointer; the individual file pointers are neither used nor updated by any of these routines.
These routines have similar semantics to the explicit-offset data-access routines, except:
After a shared file pointer operation is initiated, it is updated, relative to the current view of the file, to point to the elementary data item immediately following the last one requested, regardless of the number of items actually accessed.
MPI_File_read_shared() and MPI_File_write_shared() are blocking routines that use the shared file pointer to read and write files, respectively. The order of serialization is not deterministic for these noncollective routines, so you need to use other methods of synchronization if you want to impose a particular order.
MPI_File_iread_shared() and MPI_File_iwrite_shared() are the nonblocking versions of MPI_File_read_shared() and MPI_File_write_shared(), respectively.
MPI_File_read_ordered() and MPI_File_write_ordered() are the collective versions of MPI_File_read_shared() and MPI_File_write_shared(). They must be called by all processes in the communicator group associated with the file handle, and the accesses to the file occur in the order determined by the ranks of the processes within the group. After all the processes in the group have issued their respective calls, for each process in the group, these routines determine the position of the shared file pointer after all processes with ranks lower than this process's rank had accessed their data. Then data is accessed (read or written) at that position. The shared file pointer is then updated by the amount of data requested by all processes of the group.
The split collective versions of MPI_File_read_ordered() and MPI_File_write_ordered() are listed in the preceding table.
MPI_File_seek_shared() is a collective routine, and all processes in the communicator group associated with the particular file handler must call MPI_File_seek_shared() with the same file offset and the same update mode. All the processes are synchronized with a barrier before the shared file pointer is updated.
The offset can be negative for seeking backwards, but you cannot seek to a negative position in the file. The current position is defined as the elementary data item immediately following the last-accessed data item, even if that location is a hole.
MPI_File_get_position_shared() returns the current position of the shared file pointer relative to the current displacement and file type.
MPI_Register_datarep()
MPI_File_get_type_extent()
Sun MPI I/O supports the basic data representations described in Section 9.5 of the MPI-2 Standard:
These data representations, as well as any user-defined representations, are specified as an argument to MPI_File_set_view().
You can create user-defined data representations with MPI_Register_datarep(). Once a data representation has been defined with this routine, you can specify it as an argument to MPI_File_set_view(), so that subsequent data-access operations can call the conversion functions specified with MPI_Register_datarep().
If the file data representation is anything but native, you must be careful when constructing elementary data types and file types. For those functions that accept displacements in bytes, the displacements must be specified in terms of their values in the file for the file data representation being used.
You can use MPI_File_get_type_extent() to calculate the extents of data types in the file. The extent is the same for all processes accessing the specified file. If the current view uses a user-defined data representation, MPI_File_get_type_ extent() uses one of the functions specified in setting the data representation to calculate the extent.
The routines ending in _atomicity enable you either to set a file's mode as atomic or nonatomic, or to query which mode it is in. In atomic mode, all operations within the communicator group that opens a file are completed as if sequentialized into a serial order. In nonatomic mode, no such guarantee is made. In nonatomic mode, MPI_File_sync() can be used to ensure weak consistency.
The default mode varies with the number of nodes you are using. If you are running a job on a single node, a file is in nonatomic mode by default when it is opened. If you are running a job on more than one node, a file is in atomic mode by default.
MPI_File_set_atomicity() is a collective call that sets the consistency semantics for data-access operations. All the processes in the group must pass identical values for both the file handle and the Boolean flag that indicates whether atomic mode is set.
MPI_File_get_atomicity() returns the current consistency semantics for data-access operations. Again, a Boolean flag indicates whether the atomic mode is set.
This section provides sample code to get you started with programming your I/O using Sun MPI. The first example shows how a parallel job can partition file data among its processes. That example is then adapted to use a broad range of other I/O programming styles supported by Sun MPI I/O. The last code sample illustrates the use of the nonblocking MPI I/O routines.
Remember that MPI I/O is part of MPI, so be sure to call MPI_Init() before calling any MPI I/O routines, and call MPI_Finalize() at the end of your program, even if you use only MPI I/O routines.
MPI I/O was designed to enable processes in a parallel job to request multiple data items that are noncontiguous within a file. Typically, a parallel job partitions file data among the processes.
One method of partitioning a file is to derive the offset at which to access data from the rank of the process. The rich set of MPI derived types also makes it easy to partition file data. For example, you could create an MPI vector type as the filetype passed into MPI_File_set_view(). Because vector types do not end with a hole, you would make a call to either MPI_Type_create_resized() or MPI_Type_ub() to complete the partition. This call would lengthen the extent to include holes at the end of the type for processes with higher ranks. You can create a partitioned file by passing various displacements to MPI_File_set_view(). Each of these displacements would be derived from the process's rank. Consequently, offsets would not need to be derived from the ranks, because only the data in the portion of the partition belonging to the process would be visible to the process.
The following example uses the first method that derives the file offsets directly from the rank of the process. Each process writes and reads NUM_INTS integers starting at the offset rank * NUM_INTS. It passes an explicit offset to the MPI I/O data-access routines MPI_File_write_at() and MPI_File_read_at(). It calls MPI_Get_elements() to find out how many elements were written or read. To verify that the write was successful, it compares the data written and read as well as set up an MPI_Barrier() before calling MPI_File_get_size() to verify that the file is the size expected upon completion of all the writes of the process.
Note that MPI_File_set_view() was called to set the view of the file as essentially an array of integers instead of the UNIX-like view of the file as an array of bytes. Thus, the offsets that are passed to MPI_File_write_at() and MPI_File_read_at() are indices into an array of integers and not a byte offset.
In CODE EXAMPLE 4-1, each process writes and reads NUM_INTS integers to a file using MPI_File_write_at() and MPI_File_read_at(), respectively.
You can adapt CODE EXAMPLE 4-1 to support the I/O programming style that best suits your application. Essentially, there are three dimensions on which to choose an appropriate data access routine for a particular task: file pointer type, collective or noncollective, and blocking or nonblocking.
You need to choose which file pointer type to use: explicit, individual, or shared. The CODE EXAMPLE 4-1 used an explicit pointer and passed it directly as the offset parameter to the MPI_File_write_at() and MPI_File_read_at() routines. Using an explicit pointer is equivalent to calling MPI_File_seek() to set the individual file pointer to offset, and then calling MPI_File_write() or MPI_File_read(), which is directly analogous to calling UNIX lseek() and write() or read(). If each process accesses the file sequentially, individual file pointers save you the effort of recalculating offset for each data access. A different shared file pointer could be used in situations where all the processes needed to cooperatively access a file in a sequential way, such as to write log files.
Collective data-access routines enable you to enforce some implicit coordination among the processes in a parallel job when making data accesses. For example, if a parallel job alternately reads in a matrix and performs computation on it, but cannot progress to the next stage of computation until all processes have completed the last stage, then a coordinated effort between processes when accessing data might be more efficient. In CODE EXAMPLE 4-1, you could easily append the suffix _all to MPI_File_write_at() and MPI_File_read_at() to make the accesses collective. By coordinating the processes, you could achieve greater efficiency in the MPI library or at the file system level in buffering or caching the next matrix. In contrast, noncollective accesses are used when it is not evident that any benefit would be gained by coordinating disparate accesses by each process. UNIX file accesses are noncollective.
MPI I/O also supports nonblocking versions of each of the data-access routines-- that is, the data-access routines that have the letter i before write or read in the routine name (i stands for immediate). By definition, nonblocking I/O routines return immediately after the I/O request has been issued and do not wait until the I/O request has completed. This functionality enables you to perform computation and communication at the same time as the I/O. Because large I/O requests can take a long time to complete, this provides a way to more efficiently utilize your program's waiting time.
As in the previous example, parallel jobs often partition large matrices stored in files. These parallel jobs can use many large matrices, or matrices that are too large to fit into memory at once. Thus, each process can access the multiple and/or large matrices in stages. During each stage, a process reads in a chunk of data, and then performs a computation on it (which can involve communicating with the other processes in the parallel job). While performing the computation and communication, the process could issue a nonblocking I/O read request for the next chunk of data. Similarly, once the computation on a particular chunk has completed, a nonblocking write request could be issued before performing computation and communication on the next chunk.
The following example code illustrates the use of a nonblocking data-access routine. Note that like nonblocking communication routines, the nonblocking I/O routines require a call to MPI_Wait() to wait for the nonblocking request to complete, or repeated calls to MPI_Test() to determine when the nonblocking data access has completed. Once complete, the write or read buffer is available for use again by the program.
In CODE EXAMPLE 4-2, each process reads and writes NUM_BYTES bytes to a file using the nonblocking MPI I/O routines MPI_File_iread_at() and MPI_File_iwrite_at(), respectively. Note the use of MPI_Wait() and MPI_Test() to determine when the nonblocking requests have completed.
| Sun MPI 6.0 Software Programming and Reference Manual
| 817-0085-10 |
Copyright © 2002, Sun Microsystems, Inc. All rights reserved.