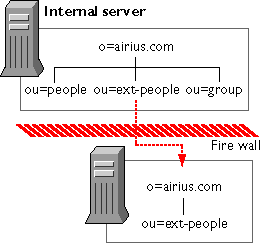
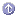Replication Overview—This section briefly introduces replication, including the benefits that replication brings to your directory service. This section also includes a brief look at the supplier-consumer architecture used by Netscape's replication strategy.
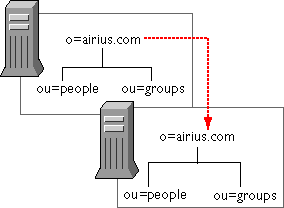
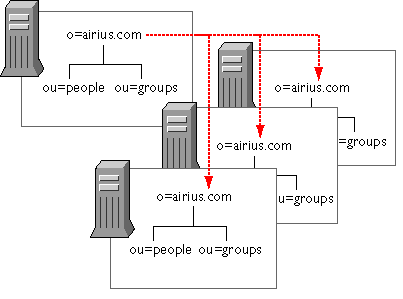
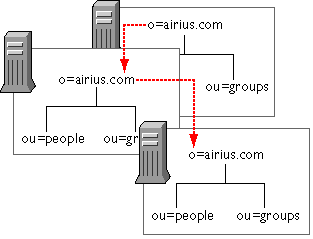
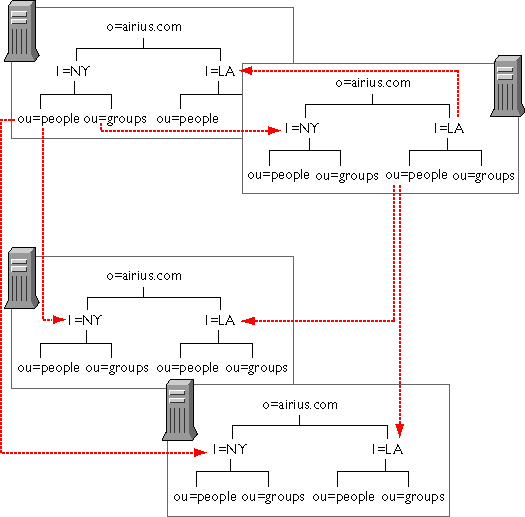
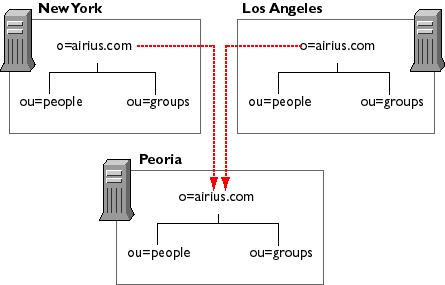
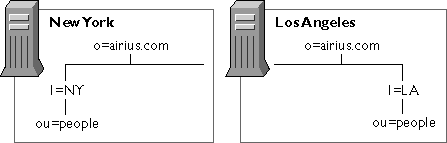
Replicating Directory Trees—This section describes the kinds of replication that you can configure for your directory service. Topics include whole tree replication, subtree replication, cascading replication, and multiple subtree replication. This section also describes replication initialization, and directory configuration requirements for creating replication.
Building a Highly Available Directory Service—This section provides concepts and examples of how to use replication to build high availability into your directory service. DNS strategies, using replication for load balancing, and using replication for local availability are also discussed. Examples include how to load balance for a small site, a large site, for local data management, and for server traffic. A specific section on how to load balance for Netscape Messaging Server 3.0 is also provided.