
![]()
![]()
![]()
![]()
ソフトウェアの地域対応化の必要性は、言語そのもの、数字や通貨の表現方法、時間や日付の表示方法、文字や文字列の順序や分類などの、文化的な規約の違いから生じます。
当然ながら、言語そのものは国によって異なるだけでなく、同じ国の中でも異なることがあります。プログラム内のメッセージは、英語、ドイツ語、フランス語、イタリア語、その他今日の世界で広く使用されている言語で出力する必要があります。
また、各言語で使用するアルファベットはさまざまです。次に、各国の言語とそのアルファベットを参考例として示します。
| アメリカ英語: |
a-z、A-Z、句読文字 |
| ドイツ語: |
a-z、A-Z、句読文字、äöü
ÄöÜ ß |
| ギリシャ語: |
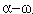 、 、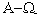 、句読文字 、句読文字 |
数字の表現方法は、地域の慣習によって異なり、国によっても異なります。たとえば、小数点を表す文字、すなわち数字の整数部分と小数部分を分ける記号の場合、アメリカ英語ではピリオドを使用しますが、ヨーロッパの多くの国々ではコンマを使用します。反対に、4 桁以上の数字を区切る記号として、アメリカ英語ではコンマを使用しますが、ヨーロッパでは、通常はピリオドを使用します。
また、桁をグループ化する規約も異なります。アメリカ英語では 3 桁ごとにグループにまとめますが、異なる方法を使用している所も多くあります。次に、国によって表現方法の異なるグループ化の例を示します。
| 1,000,000.55 |
アメリカ合衆国 |
| 1.000.000,55 |
ドイツ |
| 10,00,000.55 |
ネパール |
国によって使用する通貨が異なることは、よく知られています。しかし、その通貨単位をさまざまな方法で表現できることは、それほど知られていません。たとえば、通貨記号にはいくつかの種類があります。次の例は、同じ合衆国のドルを 2 種類の方法で示したものです。
| $24.99 |
アメリカ合衆国 |
| USD 24.99 |
アメリカ合衆国の国際通貨記号 |
また、通貨記号を付ける位置も、前や後、数字の間など、国によって異なります。
| ¥ 155 |
日本 |
| 13,50 DM |
ドイツ |
| £14 19s. 6d. |
10進制以前のイギリス |
通貨のマイナスの値もさまざまです。
| öS 1,1 |
-öS 1,1 |
オーストラリア |
| 1,1 DM |
-1,1 DM |
ドイツ |
| SFr. 1.1 |
SFr.-1.1 |
スイス |
| HK$1.1 |
(HK$1.1) |
香港 |
時間と日付の表示方法も地域によって異なります。24 時間制を採用している国もあれば、12 時間制を採用している国もあります。また、曜日や月の呼び方やその略称も、言語によって異なります。
年、月、日の順序は、それを数字で表現するときの区切り記号と共に、慣習によって異なります。年号の表現にしても、地域によっては西洋のグレゴリオ暦方式を使用せずに、季節や天文、または歴史的な基準が使用されています。日本の場合、公式のカレンダーは、現在の天皇の在位する時代が基準となっています。
次の例は、同じ日付の簡潔表現と通常の表現方法を国別に比較したものです。
| 10/29/96 |
Tuesday, October 29, 1996 |
アメリカ合衆国 |
| 1996. 10. 29. |
1996. október 29. |
ハンガリー |
| 29/10/96 |
martedì 29 ottobre 1996 |
イタリア |
| 29/10/1996 |
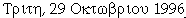 |
ギリシア |
| 29.10.96 |
Dienstag, 29. Oktober 1996 |
ドイツ |
次の例は、同じ時刻に対する異なる表現方法です。
| 4:55 pm |
アメリカ合衆国時間 |
| 16:55 Uhr |
ドイツ時間 |
次の例も、同じ時刻を異なる表現で示したものです。
| 11:45:15 |
アメリカ合衆国のデジタル表記 |
| 11:45:15 µµ |
ギリシアのデジタル表記 |
照合順序、すなわち文字や文字列の並べ方やソートの規則という点でも、言語間で異なります。次の例は、同じ単語群を異なる照合順序に基づきアルファベット順で並べて比較したものです。
| ASCII ルールによるソート: |
ドイツルールによるソート: |
| Airplane |
Airplane |
| Zebra |
ähnlich |
| bird |
bird |
| car |
car |
| ähnlich |
Zebra |
ASCII の照合順序では、バイトの数値で対象を整列しますが、これは英語の辞書のソート基準には従っていません。辞書式の場合、A と B の間に a が並びますが、ASCII 方式のソートでは、すべての大文字の後に a を並べます。
ドイツアルファベットでは、b の前に ä が来ますが、ASCII の整列では、ウムラウト付きのアルファベットはその他すべての文字の後になります。
個々の文字の順序だけでなく、言語によっては一定の文字グループを 1 つの文字として処理する場合があります。以下に例を示します。
| ASCII ルールによるソート: |
スペインルールによるソート: |
| chaleco |
cuna |
| cuna |
chaleco |
| día |
día |
| llava |
loro |
| loro |
llava |
| maíz |
maíz |
llava は、loro と maíz の間になります。スペイン語の ll は二重字、つまりソートしたときの整列位置が l と m の間になる 1 つの文字として処理されるためです。同じく、スペイン語の ch は、c と d の間に整列する二重字です。2 つの文字が組になって 1 文字として処理される文字を、二重字文字コードペアといいます。
その他、1 文字を 2 文字として処理する例もあります。ドイツ語の ß は、シャープ s と呼ぶ 1 つの文字ですが、ss として処理されます。このため、次の例のような違いが生じます。
| ASCII ルールによるソート: |
ドイツルールによるソート: |
| Rosselenker |
Rosselenker |
| Rostbratwurst |
Roßhaar |
| Roßhaar |
Rostbratwurst |
![]()
![]()
![]()
![]()
Copyright (c) 1998, Rogue Wave Software, Inc.
このマニュアルに関する誤りのご指摘やご質問は、電子メールにてお送りください。
OEM リリース, 1998 年 6 月