
![]()
![]()
![]()
![]()
言語によって文字が異なることはよく知られています。文字の地域対応化のプロセスでは、最初に、その文字の表現方法、符号化の方法を定めます。一般に、文字の符号化は、文字によって異なります。
7 ビット ASCII コードセットは、UNIX システムで一般に使用されています。
8 ビットコードセットは、東ヨーロッパ、西ヨーロッパ、中近東、アジアのさまざまな言語の処理に対応しています。その内のいくつかは、7 ビット ASCII コードセットの拡張であり、7 ビット ASCII コードに加えて、通常の ASCII で対応していない 128 文字コードをサポートしています。このような拡張コードセットは、西ヨーロッパのユーザーの需要に応えたものです。また、アラビア語やギリシア語など、まったく異なる文字を持つ言語をサポートするために、より大きな 8 ビット コードセットが用意されています。
中国の文字をもとにした日本の表意文字を含む、漢字などの 256 文字以上の文字数がある文字には、複数バイト文字コードが必要です。漢字には数万の文字があり、それぞれを 2 バイトで表します。ASCII との下位互換性を維持するために、複数バイトコードセットは ASCII コードセットのスーパーセットになっており、1 バイト文字と 2 バイト文字の両方をまとめたものになっています。
以上の言語のために、さまざまな符号化スキーマが定義されてきました。これらの符号化スキーマでは、バイトストリームをコード文字のグループに構文解析する規則のセットを用意しています。
複数バイト文字符号化の処理は、簡単ではありません。複数バイト文字シーケンスの解析だけでなく、多くの場合で、バイト文字とワイド文字間の変換が必要とされるためです。
複数バイト符号化スキーマは、一般的な例で簡単に説明することができます。複数バイト文字サポートの最初にしておそらく最大の市場は日本にあります。したがって、以下の例は日本語テキストの処理の符号化スキーマがもとになっています。
日本では、1つのテキストメッセージは、4 種類の表記体系で構成されます。漢字には数万の文字があり、絵文字で表します。ひらがなとカタカナは音節文字であり、それぞれ約 80 の音を表し、表意文字としても使用します。ローマ字には 95 の文字、数字、句読点が含まれます。
図 1 は、以上 4 種類の文字体系からなる符号化日本文を示したものです。

日本では、さまざまな日本語文字セットが採用されています。
| JIS C 6226-1978 |
JIS X 0208-1983 |
| JIS X 0208-1990 |
JIS X 0212-1990 |
| JIS-ROMAN |
ASCII |
国際的に採用されている日本語の複数バイト符号スキーマはありませんが、当社では、以下に示す 3 種類の複数バイト符号化スキーマをサポートしています。
| JIS (日本工業規格) |
| シフト JIS |
| EUC (拡張 UNIX コード) |
JIS (日本工業規格) では、多くの標準日本語文字セットをサポートしてしており、それらには 1 バイトを必要とするものと、2 バイトを必要とするものがあります。1 バイトと 2 バイトのモード切り替えには、エスケープシーケンスが必要です。
エスケープシーケンスは別名をシフトシーケンスといい、制御文字のシーケンスを指します。制御文字は文字には含まれません。目に見える形を持たない人工的な文字です。しかし、制御文字も符号化スキーマの一部を構成し、異なる文字セット間の区切り文字として機能し、文字シーケンスに割り込むスイッチを表します。シフトシーケンスの使用例を図 2 に示します。
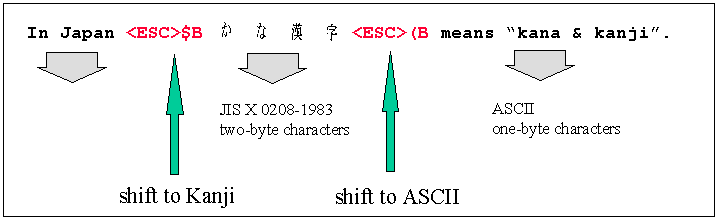
符号化スキーマに JIS のようなシフトシーケンスを組み込むには、文字シーケンスの解析時にシフトステートを維持する必要があります。上記の例では、シーケンスの最初は、何らかの初期シフトステートになります。この場合は ASCII です。したがって、シフトシーケンス <ESC>$B が出現するまで 1 バイト ASCII コードだと考えられます。このシフトシーケンスで、JIS X 0208-1983 の定義どおり 2 バイトモードに切り替わります。次に、シフトシーケンス <ESC>(B で ASCII モードに戻ります。
シフトステートを使用する符号化スキーマは、内部的な記憶や処理の面では効率的ではありません。シフトシーケンスでは、場合によっては 6 バイトが必要なこともあります。文字列のファイル内で文字セット間で頻繁に切り替えを行うと、シーケンスの使用バイト数が実際のデータの表現に必要なバイト数よりも多くなることがあります。
シフトシーケンスを含む符号化は、基本的に外界との情報交換用の外部コードとして使用します。
その名前にも関わらず、シフト JIS はシフトシーケンスやシフトステートとは無関係です。この符号化スキーマでは、バイトごとに 1 バイト文字か 2 バイト文字の最初のバイトかを確認します。判別のために、一定の目的のためのバイト値セットが予約されています。次にその例を示します。
この符号化は JIS よりもコンパクトですが、JIS ほど多くの文字は表現できません。実際、シフト JIS では 6,000 文字以上をおさめた補助漢字セット JIS X 0212-1990 を表現することはできません。
EUC は日本語符号化固有のものではありません。これは、1 つのテキストストリームで、日本語など複数の文字セットを処理するために開発されたスキーマです。
EUC 符号化では、文字に 3 バイト以上をおさめることができ、シフト JIS よりも高い拡張性があります。この符号化スキーマを日本語の文字に使用すると次のようになります。
最後の 2 例は、それぞれ値が 0x8E と 0x8F の接頭辞バイトを表します。これらのバイトは、後続のバイトの変換を左右する点でシフトシーケンスに似ています。ただし JIS のシフトシーケンスが文字シーケンスの先頭に置かれるのとは異なり、この接頭辞は、シーケンスの最初の文字だけでなく、すべての複数バイト文字の先頭に付きます。そのため、この方法で符号化した複数バイト文字は独立しており、EUC はシフトステートを持っていません。
以上に述べた 3 種類の複数バイト符号化スキーマは、一般には別々の分野に使用します。
複数バイト符号化スキーマでは、プログラム外やプログラム内で文字を効率よく移動することができます。しかし、プログラム内では、同じサイズや書式の文字を処理する方が簡単です。これをワイド文字と呼びます。
例では、ワイド文字で簡単にプログラム内のテキストを処理できることを示しています。/CC/include/locale.h のように、隣接する文字をスラッシュで区切ったディレクトリパスのあるファイル名の文字列を例に挙げます。1 バイト文字列で実際のファイル名を探すには、文字列の最後から探します。最初の区切り文字が見つかると、ファイル名の先頭がわかります。文字列に複数バイト文字が含まれている場合は、先頭から探すことができるので、コンテキスト外のバイトを調べる必要がありません。ただし、文字列にワイド文字が含まれている場合でも、それを 1 バイト文字として処理して末尾から調べることもできます。
概念的には、一意の文字ごとに別々の値が割り当てられたワイド文字セットは、拡張された ASCII または EBCDIC と考えることもできます。ワイド文字セットは、複数バイト符号化スキーマに代わるものとして使用されるため、ワイド文字セットには、複数バイト符号化スキーマで表現できるすべての文字表現をワイド文字で表現できることが要求されます。複数バイト符号化スキーマでは数千文字をサポートしているため、ワイド文字は、一般に 1 バイトよりも大きくなり、通常 2 バイトか 4 バイトになります。ワイド文字セットの文字はすべて同じサイズです。ただし、ワイド文字のサイズは国際的に固定されているわけではなく、ワイド文字セットによって異なります。
以下のものを含めてワイド文字にはさまざまな規格があります。
| ISO 10646.UCS-2 |
16 ビット文字 |
| ISO 10646.UCS-4 |
32 ビット文字 |
| Unicode |
16 ビット文字 |
プログラミング言語 C++ では、ワイド文字をサポートしています。C++ におけるそのネイティブタイプを wchar_t といいます。ワイド文字の定数とワイド文字の文字列の構文は、通常の文字定数や文字列と同様のものです。
| L'a' は、ワイド文字定数です。 |
| L"abc"は、ワイド文字列です。 |
ワイド文字はプログラム内の文字の内部表現に使用し、複数バイト符号化スキーマは外部表現に使用するため、複数バイト文字からワイド文字への変換は、入出力演算で一般に行われています。ファイルからの入出力がその典型的な使用例です。ファイルには一般に複数バイト文字が含まれています。そのようなファイルを読み取るときは、複数バイト文字を内部文字バッファに保存できるワイド文字に変換し、以後の処理に対応します。複数バイトファイルに書き込むときは、内部のワイド文字を外部ファイルで保存できる複数バイトに変換する必要があります。図 3 は、ファイル入力時に行われるこの変換処理を示したものです。
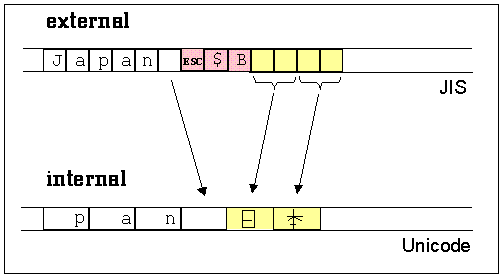
複数バイトシーケンスをワイド文字シーケンスに変換するには、1 バイト文字を 2 バイトや 4 バイトのワイド文字 に拡張する必要があります。エスケープシーケンスは削除されます。2 バイト以上の複数バイトはそれぞれ対応するワイド文字に変換されます。
![]()
![]()
![]()
![]()
Copyright (c) 1998, Rogue Wave Software, Inc.
このマニュアルに関する誤りのご指摘やご質問は、電子メールにてお送りください。
OEM リリース, 1998 年 6 月