|
| |
| Sun Java(TM) System Directory Server 5 2004Q2 Deployment Planning Guide | |
Chapter 6
Understanding ReplicationReplicating directory contents increases the availability of your directory. It can also assist in increasing global search performance if additional measures such as load balancing are implemented. Although replication can increase write availability, it does not increase write or update performance.
In Chapter 4 and Chapter 5, you made decisions about the design of the directory tree and the directory topology. This chapter addresses the physical and geographical location of your data, and specifically, how to use replication to ensure that the data is available when and where you need it.
This chapter discusses the use of replication in your deployment, and contains the following topics:
Introduction to ReplicationReplication is the mechanism that automatically copies directory data from one Directory Server to another. Using replication, you can copy any directory tree or subtree (stored in its own suffix) between servers, except the configuration or monitoring information subtrees.
Replication enables you to provide a highly available directory service, and to distribute data geographically. In practical terms, replication provides the following benefits:
By replicating directory trees to multiple servers, you can ensure that your directory is available even if a hardware, software, or network problem prevents directory client applications from accessing a particular Directory Server. Clients can be referred to another directory for read and write operations. Note that to support write failover, you must have more than one master copy of your data in the replication environment.
Before defining a replication strategy, you should have a basic understanding of how replication works. This section includes an overview of:
Replication Concepts
When considering implementing replication, start by answering the following fundamental questions:
- What information do you want to replicate?
- Which server or servers hold the master copy of that information?
- Which server or servers hold read-only copies of the information?
- What should happen when a read-only server receives modification requests from client applications; that is, to which server should requests be referred?
These decisions cannot be made effectively without an understanding of how Directory Server implements replication. For example, when you decide what information you want to replicate, you need to know the smallest replication unit that Directory Server can handle. The following sections explain the replication concepts as implemented in Directory Server.
Replica
A database that participates in replication is defined as a replica. There are three kinds of replicas:
- Master replica or read-write replica: a read-write database that contains a master copy of the directory data. A master replica can process update requests from directory clients.
- Consumer replica: a read-only database that contains a copy of the information held in the master replica. A consumer replica can process search requests from directory clients but refers update requests to master replicas.
- Hub replica: a read-only database, like a consumer replica, but stored on a Directory Server that supplies one or more consumer replicas.
You can configure Directory Server to manage several replicas. Each replica can have a different role in replication.
Unit of Replication
The smallest unit of replication is the suffix. The replication mechanism requires that one suffix correspond to one database. This means that you cannot replicate a suffix (or namespace) that is distributed over two or more databases using custom distribution logic. The unit of replication applies to both consumers and suppliers, which means that you cannot replicate two suffixes to a consumer holding only one suffix, and vice versa.
Replica ID
Master replicas require a unique replica identifier (ID) while consumer replicas all have the same replica ID. The replica ID for masters can be any 16 bit integer between 1 and 65534. Consumer replicas all have the replica ID of 65535. The replica ID identifies the replica on which changes were made, enabling the changes to be replicated correctly.
If a server hosts several replicas (or suffixes,) the replicas may all have the same replica ID, provided that the replica ID is unique between the masters of a single, replicated suffix. Using the same replica ID for all the suffixes on a master enables you to associate a master with only one replica ID independently of the suffixes.
Suppliers and Consumers
A Directory Server that replicates to other servers is called a supplier. A Directory Server that is updated by other servers is called a consumer. The supplier replays all updates on the consumer through specially designed LDAP v3 extended operations. In terms of performance, a supplier is therefore likely to be a demanding client application for the consumer.
In some cases a server can be both a supplier and a consumer. This is true in the following cases:
- When the server contains a hub replica; that is, it receives updates from a supplier and replicates the changes to consumer(s). For more information, refer to Cascading Replication.
- In multi-master replication, when a master replica is mastered on two different Directory Servers, each server acts as a supplier and a consumer of the other server. For more information, refer to Multi-Master Replication.
- When the server manages a combination of master replicas and consumer replicas.
A server that plays the role of a consumer only (that is, it contains only a consumer replica) is called a dedicated consumer.
In Directory Server, replication is always initiated by the supplier, never by the consumer. This is called supplier-initiated replication, as suppliers push the data to consumers. Earlier versions of Directory Server allowed consumer-initiated replication, in which consumers could be configured to pull data from suppliers. From Directory Server 5.0, this has been replaced by a procedure in which the consumer can prompt the supplier to send updates.
For a master replica, the server must:
For a hub replica, the server must:
For a consumer replica, the server must:
Whenever a request to add, delete, or change an entry is received by a consumer, the request is referred via the client to the server, or servers, that contain the master replica; that is, the server acting as the supplier in the replication flow. The supplier performs the request, then replicates the change.
It is possible to configure consumer or hub replicas not to return a referral, but to return an error instead (if this is required for security or performance reasons.) See Referrals for more information.
Online Replica Promotion and Demotion
Directory Server 5.2 enables you to promote and demote replicas online. Promoting or demoting a replica changes its role in the replication topology. Dedicated consumers may be promoted to hubs, and hubs may be promoted to masters. Masters may be demoted to hubs, and hubs may be demoted to dedicated consumers. To promote a consumer replica to a master replica, you need to promote it first to a hub replica and then to a master replica. The same incremental approach applies to online demotion. For more information see “Promoting and Demoting Replicas,” in Chapter 8 of the Directory Server Administration Guide.
In addition to providing increased flexibility, online replica promotion and demotion provides increased failover capabilities. Imagine, for example, a two-way multi-master replication scenario, with two hubs configured for additional load balancing and failover. Should one of the masters go offline, you would simply need to promote one of the hubs to a master to maintain optimal read-write availability. When the master replica came back online, a simple demotion back to a hub replica would return you to the original topology.
Note
Once a hub is demoted to a consumer, the replica is no longer able to propagate changes (as a consumer it will not have a change log.) Before demoting a hub to a consumer, you must therefore verify that the hub is synchronized with the other servers. To ensure this, you can use the replication monitoring tool insync (see Replication Monitoring for more information.)
Referrals
When a consumer receives a modification request, it does not forward the modification request to the server that contains the master replica. Instead, it returns a list containing the URLs of the possible masters that could satisfy the client’s modification request. These URLs are referrals.
The replication mechanism automatically configures consumers to return referrals for all known masters in the replication topology. However, you can also add your own referrals and overwrite the referrals set automatically by the server. The ability to control referrals helps you to optimize security and performance by enabling you to:
For information about configuring referrals see “Setting Referrals” in Chapter 2 of the Directory Server Administration Guide.
Change Log
Every server acting as a supplier (a master replica or a hub replica,) maintains a change log. A change log is a record that describes the modifications that have occurred on a master replica. The supplier replays these modifications to its consumers.
When an entry is modified, renamed, added or deleted, a change record describing the LDAP operation that was performed is recorded in the change log.
In earlier versions of Directory Server, the change log was accessible over LDAP. Now, however, it is intended only for internal use by the server, and is stored in its own database which means that it is no longer accessible over LDAP. If you have applications that need to read the change log, you must use the retro change log plug-in for backward compatibility. For more information about the retro change log plug-in refer to “Using the Retro Change Log Plug-In” in the Directory Server Administration Guide.
Replication Authentication
The consumer server authenticates the supplier server when the supplier binds to the consumer to send replication updates. This authentication process requires that the entry used by the supplier to bind to the consumer is stored on the consumer server. This entry is called the Replication Manager entry. When, in the context of replication, Directory Server Console refers to the DN or bind DN, it is referring to the DN of the Replication Manager entry.
The Replication Manager, or any entry you create to fulfill that role, must meet the following criteria:
The Replication Manager entry has a special user profile that bypasses all access control rules defined on the consumer server. This special user profile is only valid in the context of replication.
When you configure replication between two servers, you must identify the Replication Manager entry on both servers:
- On the consumer server, you must specify this entry as the one authorized to perform replication updates, when you configure the consumer replicas, hub replicas, or master replicas (in the case of multi-master replication). If you use the console, the Replication Manager entry is used by default.
- On supplier server (all master and hub replicas), you must specify the bind DN of this entry when you configure the replication agreement.
The Replication Manager entry is created by default when you configure replication through Directory Server Console. You can also create your own Replication Manager entry.
If you are using SSL with replication, there are two possible methods of authentication:
- When using SSL Server Authentication, you must have a Replication Manager entry, and its associated password, in the server you are authenticating to.
- When using SSL Client Authentication you must have an entry containing a certificate in the server you are authenticating to. This entry may or may not be mapped to the Replication Manager entry.
Replication Agreement
Directory Server uses replication agreements to define how replication occurs between two servers. A replication agreement describes replication between one supplier and one consumer. The replication agreement is configured on the supplier, and must be enabled for replication to work. You can enable or disable existing replication agreements. This can be useful if you currently have no need for a replication agreement, but want to maintain its configuration for future use.
A replication agreement identifies:
- The suffix to replicate.
- The consumer server to which the data is pushed.
- The times during which replication can occur.
- The bind DN and credentials the supplier must use to bind to the consumer (see Replication Authentication.)
- How the connection is secured (SSL, client authentication).
- If fractional replication is configured, a pointer to the set of attributes to be excluded or included (see Fractional Replication.)
- The group and window sizes to configure the number of changes you can group into one request and the number of requests that can be sent before consumer acknowledgement is required.
- Information about the replication status for this particular agreement.
- The level of compression used in replication.
Consumer Initialization
Consumer initialization, or total update, is the process by which all data is physically copied from the supplier to the consumer. Once you have created a replication agreement, the consumer defined by that agreement must be initialized. When a consumer has been initialized, the supplier can begin replaying, or replicating update operations to the consumer. Under normal circumstances, the consumer should not require further initialization. However, if the data on a supplier is restored from a backup, you may need to reinitialize the consumers dependent on that supplier. For example if a restored supplier is the only supplier for a consumer in the topology, consumer reinitialization may be necessary.
You can initialize consumers online or offline. For more information on the consumer initialization process see “Initializing Replicas,” in Chapter 8 of the Directory Server Administration Guide.
In a multi-master replication topology, the default behavior of a read-write replica that has been reinitialized from a backup or LDIF file, is to REFUSE client update requests. By default the replica remains in read-only mode indefinitely and refers any update operations to other suppliers in the topology. In this case, you must configure the replica to begin accepting updates again. See “Convergence After Multi-Master Initialization,” in Chapter 8 of the Directory Server Administration Guide.
Directory Server provides an advanced binary copy feature that can be used to clone master or consumer replicas using the binary backup files of one server to restore the identical directory contents on another server. Certain restrictions on this feature make it practical and time-efficient only for replicas with large database files. For information on the binary copy procedure and a list of the feature’s limitations see “Initializing a Replica Using Binary Copy,” in Chapter 8 of the Directory Server Administration Guide.
Incremental Updates
Once a consumer has been initialized, replication updates are sent to the consumer as the modifications are made on the supplier. These updates are called incremental updates. A consumer can be incrementally updated by several suppliers at once, provided that the updates originate from different replica IDs.
Data Consistency
Consistency refers to how closely the contents of replicated databases match each other at any given time. When you set up replication between two servers, part of the configuration is to schedule updates. The supplier determines when consumers must be updated, and initiates replication. Replication can start only after consumers have been initialized.
Directory Server provides the option of keeping replicas always synchronized, or of scheduling updates for a particular time of day, or day of the week. The advantage of keeping replicas always in sync is that data remains consistent across your topology. The cost, however, is the network traffic resulting from the frequent update operations. This solution is preferable when:
If you can afford to have looser data consistency, you can choose a frequency of updates that lowers the effect on network traffic. This solution is preferable when:
In the case of multi-master replication, the replicas on each master are said to be loosely consistent because at any given time, there can be differences in the data stored on each master. This is true even when you have selected to keep replicas in sync, because:
Common Replication ConfigurationsYour replication topology determines how updates flow from server to server, and how the servers interact when propagating updates. There are five basic replication configurations, which can be combined to suit your deployment.
The following sections describe these configurations and provide strategies for deciding which method is most suited to your deployment.
Note
Whatever replication configuration you implement, you must consider the schema replication. See Schema Replication for more information.
Single Master Replication
In the most basic replication configuration, a supplier copies a master replica directly to one or more consumers. In this configuration, all directory modifications are made to the master replica, and the consumers contain read-only copies of the data.
The supplier maintains a change log that records all changes made to the replica. The supplier also defines the replication agreement.
The consumer stores the entry corresponding to the Replication Manager entry, so that the consumer can authenticate the supplier when the supplier binds to send replication updates.
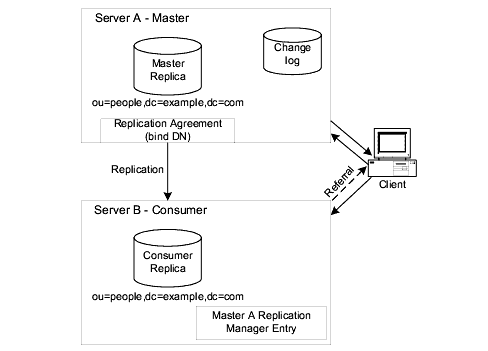
The supplier propagates all modifications to the consumer replicas, in accordance with the replication agreement. This basic scenario is illustrated in Figure 6-1.
Figure 6-1 Single-Master Replication
In this example, the ou=people,dc=example,dc=com suffix receives a large number of search and update requests from clients. To distribute the load, this suffix, which is mastered on Server A, is replicated to a consumer replica located on Server B.
Server B can process and respond to search requests from clients, but cannot process requests to modify directory entries. Server B processes modification requests received from clients by sending a referral to Server A back to the client. The consumer stores referral information about the supplier, but does not forward modification requests from clients to the supplier. Instead, the client follows the referral sent back by the consumer.
Although this example shows just one server acting as a consumer, a supplier can replicate to several consumers. The total number of consumers that a single supplier can manage depends on the speed of your network and the total number of entries that are modified on a daily basis.
Multi-Master Replication
In a multi-master replication configuration, master replicas of the same data exist on more than one server. This section includes the following topics:
Multi-Master Replication Basic Concepts
In a multi-master configuration, data can be updated simultaneously in different locations. Each master maintains a change log for its replica, and the changes that occur on each master are replicated to the other servers. This means that each master plays the role of supplier and consumer. Multi-master configurations have the following advantages:
When updates are sent between the two servers, the conflicting changes need to be resolved. Mostly, resolution occurs automatically, based on the timestamp associated with each change. The most recent change takes precedence. However, there are some cases where change conflicts require manual intervention in order to reach a resolution. For more information, see “Solving Common Replication Conflicts,” in Chapter 8 of the Directory Server Administration Guide.
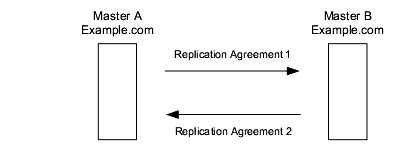
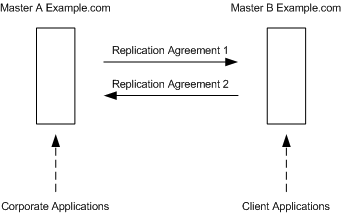
Although two separate servers can have master copies of the same data, within the scope of a single replication agreement, there is only ever one supplier and one consumer. Therefore, to create a multi-master environment between two suppliers that share responsibility for the same data, you must create two replication agreements, one on each supplier. Figure 6-2 shows this configuration:
Figure 6-2 Multi-Master Replication Configuration (Two Masters)
In the preceding figure, Master A and Master B each hold a master replica of the same data and there are two replication agreements governing the replication flow. Master A acts as a master in the scope of Replication Agreement 1, and as a consumer in the scope of Replication Agreement 2.
Directory Server 5.2 supports a maximum of four masters in a multi-master replication topology. The number of consumer replicas and hubs is theoretically unlimited, although the number of consumers to which a single supplier can replicate will depend on the capacity of the supplier server.
Multi-Master Replication Capabilities
Directory Server 5.2 introduces a more streamlined, flexible replication protocol. This protocol enables you to:
- Replicate updates based on the replica ID. Replica ID-based updates result in improved performance because they make it possible for a consumer to be updated by multiple suppliers at the same time (provided that the updates originate from different replica IDs).
- Enable or disable a replication agreement, providing greater replication configuration flexibility. Replication agreements can be configured but left disabled, then enabled rapidly should they be required.
Multi-Master Replication over Wide Area Networks
Support for multi-master replication over Wide Area Networks (WANs), introduced in Directory Server 5.2, enables multi-master replication configurations across geographical boundaries in international, multiple data center deployments. (Prior to Directory Server 5.2, multiple masters had to be connected via high-speed, low-latency networks with minimum connection speeds of 100Mb/second, for full support, which ruled out the possibility of multi-master replication over WAN.)
From Directory Server 5.2 onwards, the replication protocol provides full asynchronous support, window and grouping mechanisms, and support for compression. These features render multi-master replication over WAN a viable deployment possibility. Although the viability of multi-master replication over WAN is a direct result of these protocol improvements, they are equally valid for Local Area Network (LAN) deployments.
Due to differences in protocols, multi-master replication over WAN is not backward compatible with versions of Directory Server prior to 5.2. As a result, in a multi-master replication over WAN configuration, all Directory Server instances separated by a WAN must be 5.2 instances.
Group and Window Mechanisms
To optimize replication flow, Directory Server enables you to group changes, rather than sending them individually. It also allows you to specify a certain number of requests that can be sent to the consumer without the supplier having to wait for an acknowledgement from the consumer before continuing.
Since both the group and window mechanisms are based on entry size, optimizing replication performance using these mechanisms may be impractical if the size of your entries varies considerably. If the size of your entries is relatively constant, you can use the group and window mechanisms to optimize incremental and total updates. Note that the performance of multi-master replication over WAN will depend on the latency and bandwidth of your WAN.
For more information on adjusting the window and group size, see “Configuring Network Parameters,” in Chapter 8 of the Directory Server Administration Guide.
Replication Compression
In addition to the grouping and window mechanisms, Directory Server provides a compression mechanism. Prior to Directory Server 5.2, limited bandwidth often caused a bottleneck in replication over WAN. Replication compression helps to streamline replication flow and avoid this bottleneck. For information on how to configure replication compression via the command line, see “ds5ReplicaTransportCompressionLevel,” in Chapter 4 of the Directory Server Administration Reference.
Fully Meshed Multi-Master Topology
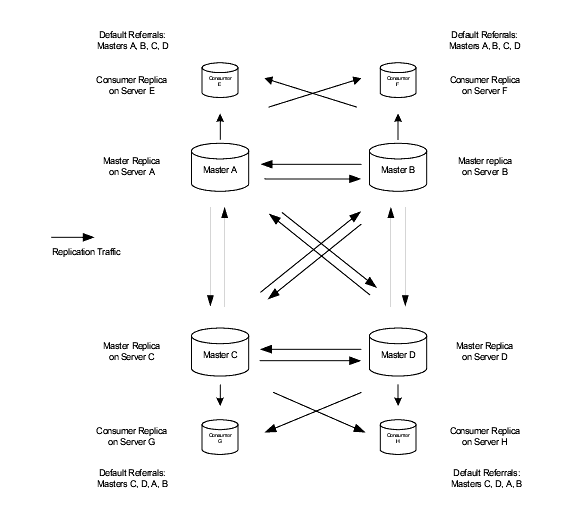
A fully meshed topology implies that each of the masters in a topology is connected to each of the other masters. Such a topology provides high availability and guaranteed data integrity. Figure 6-3 shows a fully meshed, four-way, multi-master topology.
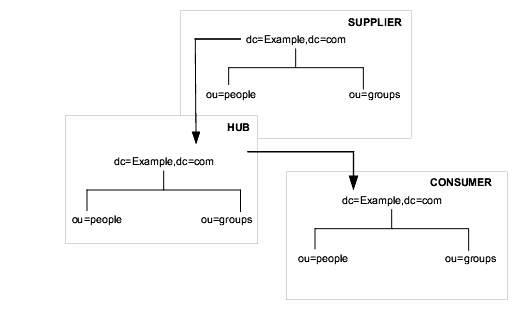
Figure 6-3 Fully Meshed Four-Way Multi-Master Replication Configuration on Suffix “ou=people,dc=example,dc=com”
In this example, the ou=people,dc=example,dc=com suffix is held on four masters to ensure that it is always available for modification requests. Each master maintains its own change log. When one of the masters processes a modification request from a client, it records the operation in its change log. It then sends the replication update to the other masters, and in turn to the other consumers. This requires that the masters have replication agreements with each other, as well as with the consumers. Each master also stores a Replication Manager entry that it uses to authenticate the other masters when they bind to send replication updates.
Each consumer stores one or more entries, corresponding to the Replication Manager entries, so that they can authenticate the masters when they bind to send replication updates. It is possible for each consumer to have just one Replication Manager entry, enabling all masters to use the same Replication Manager entry for authentication. The consumers have referrals set up by default for all masters in the topology. When consumers receive modification requests from the clients, referrals to the masters are sent back to the clients by the consumers. For more information on referrals, see Referrals.
Although this topology is the most secure in terms of read-write failover capability, utilising this capability may impact performance. A fully meshed topology is preferable if high availability is crucial to your deployment. If your high availability requirements are not as important, or if you want to reduce replication traffic for performance reasons, you may want to opt for a “lighter” deployment in terms of read-write failover.
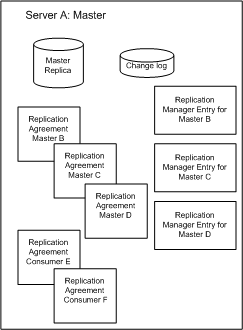
To assist you in understanding the replication elements required to configure this fully meshed, four-way, multi-master replication topology, Figure 6-4 presents a detailed view of the replication agreements, change logs, and Replication Manager entries that must be set up on master A. Figure 6-5 provides the same detailed view for consumer E.
Figure 6-4 Replication Configuration for Master A (Fully Meshed Topology)
As Figure 6-4 illustrates, Master A requires a master replica, a change log and Replication Manager entries for Masters B, C, and D (if you do not use the same Replication Manager entry for all four masters). Master A also requires replication agreements for Masters B, C, and D, and for consumers E and F.
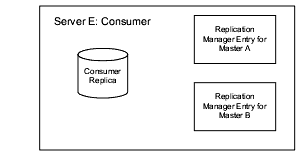
Figure 6-5 Replication Configuration for Consumer Server E (Fully Meshed Topology)
The replication configuration presented in Figure 6-5 illustrates that Consumer E requires a consumer replica and Replication Manager entries to authenticate Master A and Master B when they bind to send replication updates.
Cascading Replication
In a cascading replication configuration, a server acting as a hub receives updates from a server acting as a supplier, and replays those updates to consumers. The hub is a hybrid: it holds a read-only copy of the data, like a consumer and it maintains a change log like a supplier.
Hubs pass on copies of the master data as they are received from the original masters and refer update requests from directory clients to masters.
Figure 6-6 illustrates a cascading replication configuration:
Figure 6-6 Cascading Replication Configuration
Cascading replication is particularly useful in the following cases:
- When you need to balance heavy traffic loads. Because the masters in a replication topology handle all update traffic, it may put them under a heavy load to support replication traffic to consumers as well. You can off-load replication traffic to a hub that can service replication updates to a large number of consumers.
- To reduce connection costs by using a local hub in geographically distributed environments.
- To increase performance of your directory service: if you direct all client applications performing read operations to the consumers, and all those performing update operations to the master, you can remove all of the indexes (except system indexes) from your hub. This will increase the speed of replication between the master and the hub.
Figure 6-7 shows how the servers described in the previous example are configured in terms of Replication Agreements, change logs, and default referrals.
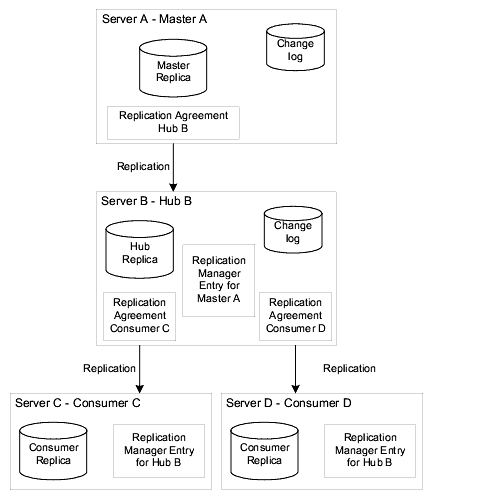
Figure 6-7 Server Configuration in Cascading Replication
In this example, Hub B is used to relay replication updates to Consumers C and D, leaving Master A with more resources to process directory updates. The master and the hub both maintain a change log. However, only the master can process directory modification requests from clients. The hub contains a Replication Manager entry for Master A, so that Master A can bind to the hub to send replication updates. Consumers C and D both contain Replication Manager entries for Hub B, which it uses to authenticate when sending its updates to the consumers.
The consumers and the hub can process search requests received from clients, but in the case of modification requests, send the client a referral to the master. Figure 6-7 shows that Consumer C and D have a referral to Master A. These are the automatic referrals that are created when you create the replication agreement between the hub and the consumers. You can, however, overwrite these referrals for performance or security reasons. For more information see the Referrals.
Mixed Environments
You can combine any of the replication configurations outlined in the previous sections to suit your deployment. For example, you could combine a multi-master configuration with a cascading configuration to produce a topology similar to that illustrated in Figure 6-8:
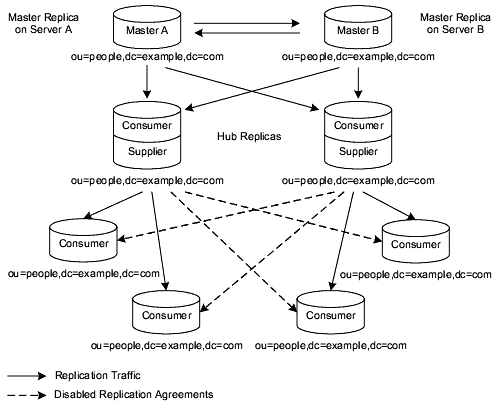
Figure 6-8 Combined Multi-Master and Cascading Replication
Figure 6-8 shows two masters and two hubs replicating data to four consumers. As in the previous scenario, the hubs are used to balance the load of replication updates by sharing it between the masters and the hubs.
In this example, the dotted lines represent disabled replication agreements. If these replication agreements are not enabled, the topology presented contains a single point of failure (if one of the hubs were to go off line.) In deploying this topology, you would need to weigh up performance requirements against high availability requirements to determine whether you enable all replication agreements to provide full read-write failover.
Fractional Replication
While the unit of replication is the suffix or subsuffix, fractional replication functionality provides a greater degree of granularity in replication. Fractional replication enables you to replicate a subset of the attributes of all entries in a suffix or subsuffix.
Benefits of Fractional Replication
Fractional replication is useful in a variety of scenarios.
When you need to synchronize between intranet and extranet servers and filter out content for security reasons, fractional replication provides the filtering functionality.
Because fractional replication enables you to be selective in what you replicate, you can reduce replication costs. If your deployment requires only certain attributes to be available everywhere, you can use the fractional replication functionality to replicate the required attributes only, rather than replicating all attributes.
For example, you may want e-mail and phone attributes to be replicated but not all attributes on a user entry, particularly if the other attributes are modified frequently and generate heavy network traffic. Fractional replication enables you to filter in the required attributes and reduce traffic to a minimum. This filtering functionality is particularly valuable where replication is over a WAN.
Fractional replication is not backward compatible with versions of Directory Server prior to 5.2. If you are using fractional replication, you must ensure that all other instances of Directory Server are 5.2 instances.
Configuring Fractional Replication
Fractional replication can be configured easily from Directory Server Console. Configuring fractional replication involves either:
Under most circumstances, an exclusion configuration approach is preferable. The complexity of certain features such as ACIs, CoS and Roles, and the dependency these features have on certain attributes, make managing a list of excluded attributes far safer, and less prone to human error, than managing a list of included attributes.
When configuring fractional replication, the server being replicated to must be a read-only replica.
Generally, you replicate all required attributes for each entry as defined in the schema, to avoid schema violations. If you want to filter out certain required attributes using fractional replication, you must disable schema checking. If schema checking is enabled with fractional replication, you may not be able to initialize the server off line (from an LDIF file). This is because the server will not allow you to load the LDIF file if required attributes are filtered out. If you have disabled schema checking on a fractional consumer replica, the whole server instance on which that fractional consumer replica resides will not enforce the schema. Because schema is pushed by suppliers in fractional replication configurations, the schema on the fractional consumer replica will be a copy of the master replica’s schema. Therefore, it will not correspond to the fractional replication configuration being applied.
Before modifying a fractional replication configuration, you must disable the replication agreements it affects. Once you have modified the configuration, you will need to re-enable the replication agreements and re-initialize the consumers so that the new configuration is taken into account.
For more information see “Configuring Fractional Replication,” in Chapter 8 of the Directory Server Administration Guide.
Defining a Replication StrategyYour replication strategy will be determined by the service you want to provide. This section provides replication topology examples that focus on the following:
To assess how important each of these aspects is in your deployment, start by performing a survey of your network, users, client applications, and how they will use the directory service. For guidelines on performing this survey, refer to Performing a Replication Survey.
When you understand your replication strategy, you can start deploying Directory Server. Putting your directory into production in stages, will give you a better sense of the load that your enterprise places on the directory. Unless you can base your load analysis on an operating directory, be prepared to alter your directory as you develop a better understanding of how the directory is used.
The following sections describe the main factors affecting your replication strategy:
Performing a Replication Survey
When performing a replication survey, concentrate on gathering the following information:
For example, if your messaging server uses the directory, you need to know how many operations it performs for each e-mail message it handles. Other products that rely on the directory are typically products such as authentication applications, or meta-directory applications. For each one you must determine the type and frequency of operations performed on the directory.
Replication Resource Requirements
Replication functionality requires system resources. Consider the following resource requirements when defining your replication strategy:
On suppliers, the change log is written to after each update operation. If a supplier contains multiple replicated suffixes, the change log will be updated more frequently, and disk usage will be higher.
Consumers must be at least equivalent to suppliers in terms of machine size, to prevent bottlenecks.
Each replication agreement creates two additional threads. Replication agreement threads are separate from operational threads. If there are several replication agreements, the number of threads available to client applications is reduced, possibly affecting the server performance for the client applications.
Replication Backward Compatibility
If you are using multiple Directory Server versions in a replication topology you should take into account the backward compatibility information in Table 6-1, to ensure that replication functions correctly. This table presents the supplier and consumer combinations that are possible between different versions of Directory Server.
If you are using replication with different Directory Server versions, take note of the following:
- If you configure a 4.x master to replicate to a 5.x master and you enable legacy replication on the 5.x master, the 5.x master will not be able to receive either client updates or replication updates from other 5.x masters in the topology. It will only receive replication updates from the 4.x master. However, when legacy replication is disabled, the 5.x master will resume fully-operational master replication behavior.
- When you are replicating from a 5.2 server to a 5.0/5.1 server, the features and enhancements that are new in 5.2 should not be used. These features include fractional replication, multiple password policies, multi-master replication over WAN, and online promotion and demotion.
- The nsslapd-schema-replicate-useronly attribute must be set to on to make sure that 5.1 servers are not disrupted by 5.2 schema extensions.
Using Replication for High Availability
Replication can be used to prevent the loss of a single server from causing your directory to become unavailable. At a minimum you should replicate the local directory tree to at least one backup server.
Some directory architects argue that you should replicate three times per physical location for maximum data reliability. How much you use replication for fault tolerance is up to you, but you should base this decision on the quality of the hardware and networks used by your directory. Unreliable hardware requires more backup servers.
Note
You should not use replication as a replacement for a regular data backup policy. For information on backing up directory data, refer to Choosing a Backup Method and to “Backing Up Data” in the Directory Server Administration Guide.
To guarantee write failover for directory clients, you should use a multi-master replication topology. If read failover is sufficient, and your directory is not geographically dispersed, you can use single-master replication.
LDAP client applications are usually configured to search one LDAP server only. That is, unless you have written a custom client application to rotate through LDAP servers located at different DNS hostnames, you can only configure your LDAP client application to look at a single DNS hostname for Directory Server. Therefore, you may need to use either DNS round robins or network sorts to provide failover to your backup Directory Servers. For information on setting up and using DNS round robins or network sorts, see your DNS documentation.
To maintain write failover over two geographically distributed sites, you can use four-way multi-master replication over WAN. In this scenario, you would set up two master servers in one location and two master servers in the second location, and configure them to be fully meshed over the WAN. This safeguards against the eventuality of one master going off line.
Alternatively, you can use the Sun Java System Directory Proxy Server product. For more information on Directory Proxy Server, see http://www.sun.com/software/products/directory_proxy/home_dir_proxy.html.
Using Replication for Local Availability
You can use replication for local availability when:
This is important for large, multinational enterprises that need to maintain directory information of interest only to users in a specific geographical location. Having a local master copy of the data is also useful in enterprises where there is a need for data to be managed at a divisional or organizational level.
Using Replication for Load Balancing
Replication can balance the load on your Directory Server in several ways:
Figure 6-9 shows how replication can be used to divide directory activities between different types of applications, thereby reducing the load placed on each supplier server.
Figure 6-9 Using Multi-Master Replication for Load Balancing
Replicating directory data also balances the load placed on your network. Where possible, you should move data to servers that can be accessed using a fast and reliable network connection.
Directory entries generally average around one KB in size. Therefore, an entire entry lookup adds about one KB to your network load each time. If your directory users perform around ten directory lookups per day, then for every directory user you will see an increased network load of around 10,000 bytes per day. If you have a slow, heavily loaded, or unreliable WAN, you may need to replicate your directory tree to a local server.
Note that the benefit of locally available data must be weighed up against the cost of the increased network traffic caused by replication. For example, if you replicate an entire directory tree to a remote site, you are potentially adding a large strain on your network in comparison to the traffic caused by your users’ directory lookups. This is especially true if your directory tree changes frequently, yet you have only a few users at the remote site performing a few directory lookups per day.
Consider that your directory tree on average includes in excess of 1,000,000 entries and that it is not unusual for about ten percent of those entries to change every day. If your average directory entry is only one KB in size, you could be increasing your network load by 100 MB per day. However, if your remote site has only 100 employees, and they are performing an average of ten directory lookups per day, the network load caused by their directory access is only one MB per day.
Given the difference in network load caused by replication versus that caused by normal directory usage, you may decide that replication purely for network load-balancing is not viable. On the other hand, you may find that the benefits of locally available directory data far outweigh any considerations you may have regarding network load.
A compromise between making data available to local sites without overloading the network is to use scheduled replication. For more information on data consistency and replication schedules, refer to Data Consistency.
Example of Network Load Balancing
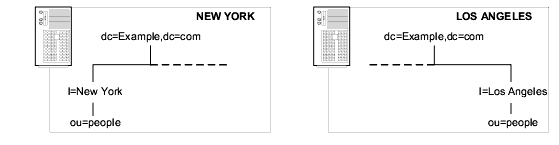
Suppose your enterprise has offices in two cities. Each office manages a separate subtree, as illustrated in Figure 6-10:
Figure 6-10 New York and Los Angeles Subtrees in Respective Geographical Locations
Each office contains a high-speed LAN, but uses a dial-up connection to network between the two cities. To balance network load:
- Replicate the directory tree on each master (including data supplied from the remote office) to at least one local Directory Server to ensure local availability of directory data.
- Configure cascading replication in each location with an increased number of consumers dedicated to lookups on the local data to provide further load balancing.
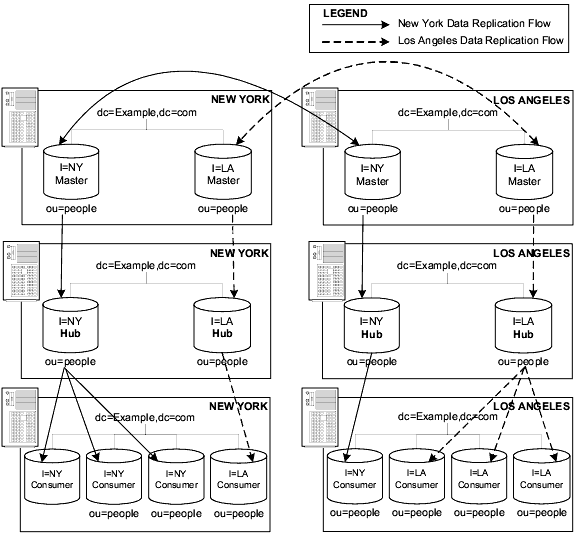
The New York office has to deal with more New York specific lookups than Los Angeles specific lookups and as a result, our example shows the New York office with three New York data consumers and one Los Angeles consumer. Following the same logic, the Los Angeles office has three Los Angeles data consumers and one New York data consumer.
This network load balancing configuration is illustrated in Figure 6-11:
Figure 6-11 Load Balancing Using Multi-Master and Cascading Replication
Example of Load Balancing for Improved Performance
In this example, the directory contains 15,000,000 entries, is accessed by 10,000,000 users, and each user performs ten directory lookups a day. The messaging server handles 250,000,000 mail messages a day, and performs five directory lookups for every mail message that it handles. There are approximately 1,250,000,000 directory lookups per day, just as a result of mail. The total combined traffic is, therefore, 1,350,000,000 directory lookups per day.
Assuming an eight-hour business day, with the directory users clustered in four time zones, the business day (or peak usage) across the four time zones is 12 hours. Therefore, the directory must support 1,350,000,000 lookups in a 12-hour day. This equates to 31,250 lookups per second (1,350,000,000 / (60*60*12)). That is:
Assume a combination of CPU and RAM that allows the directory to support 5,000 reads per second. Simple division indicates that in this scenario, you need at least six or seven Directory Servers to support this load. For enterprises with 10,000,000 directory users, you would add more Directory Servers for local availability.
A single Directory Server 5.2 with the appropriate hardware and configuration can sustain much more than the 5,000 reads per second.
In this scenario, you would replicate as follows:
The read, search, and compare requests serviced by your directory should be targeted at the consumers, thereby freeing the masters to handle write requests. For more information, see Cascading Replication.
Example Replication Strategy for a Small Site
Suppose your entire enterprise is contained within a single building. This building has a fast (100 MB per second) and lightly used network. The network is stable and you are reasonably confident of the reliability of your server hardware and OS platforms. You are also sure that a single server’s performance will easily handle your site’s load.
In this case, you should replicate at least once to ensure availability when your primary server is shut down for maintenance or hardware upgrades. Also, set up a DNS round robin to improve LDAP connection performance in the event that one of your Directory Servers becomes unavailable. Alternatively, use an LDAP proxy such as Sun Java System Directory Proxy Server. For more information on Directory Proxy Server, see http://www.sun.com/software/products/directory_proxy/home_dir_proxy.html.
Example Replication Strategy for a Large Site
Suppose your entire enterprise is contained within two buildings. Each building has a fast (100 MB per second) and lightly used network. The network is stable and you are reasonably confident of the reliability of your server hardware and OS platforms. You are also sure that a single server’s performance will easily handle the load placed on a server within each building.
Also assume that you have slow (ISDN) connections between the buildings, and that this connection is very busy during normal business hours.
A typical replication strategy for this scenario would be:
Replication Strategy for a Large, International Enterprise
Suppose your enterprise comprises two major data centers - one in France and the other in the USA - separated by a WAN. Not only do you need to replicate over a WAN, but you do not want your partners to have access to all data and want to filter out certain data. Your network is very busy during normal business hours.
A typical replication strategy for this scenario would be:
- Hold master copies of directory data on servers in both data centers.
- For write-failover within the French and American sites, replicate your data to a second master in each data center.
- Deploy a fully meshed, four-way, multi-master replication topology between France and the USA to provide high-availability and write-failover across the deployment.
- Deploy as many consumers as you require in each data center to reduce the load on your masters in terms of directory lookups.
- Set up fractional replication agreements between masters and consumers in both geographical locations, to filter out the data you do not wish your partners to access.
- Schedule replication so that it occurs only during off peak hours to optimize bandwidth.
Using Replication with Other Directory FeaturesReplication interacts with other Directory Server features to provide advanced replication functionality. The following sections describe feature interactions to assist you in designing your replication strategy.
Replication and Access Control
The directory stores ACIs as attributes of entries. This means that the ACI is replicated along with other directory content. This is important because Directory Server evaluates ACIs locally.
For more information about designing access control for your directory, refer to Chapter 7, "Access Control, Authentication, and Encryption."
Replication and Directory Server Plug-Ins
You can use replication with most of the plug-ins delivered with Directory Server. There are some exceptions and limitations, which are described in the following sections:
Replication and the Retro Change Log Plug-In
The retro change log plug-in provides backward compatibility with 4.x releases of Directory Server. This plug-in does not log the result of conflict resolution (that is, the changes actually applied on the entry.) By default the retro change log plug-in is disabled, and must be enabled using Directory Server Console or the command line.
The retro change log plug-in can be deployed in a multi-master replication topology, but there are caveats to note about its use in this environment. If the plug-in is configured on more than one of the masters, there is no guarantee that the changes will be logged in the same order. In fact the changes will almost certainly not be logged in the same order, and the change numbers will not be the same. Applications that require consistent ordering of changes from the change log will not be able to shift from using one change log to another.
The ability to use only one change log introduces a single point of failure. However, if the master with the retro change log fails, changes on other masters will be seen by applications once the failed master is brought back online.
For more information see “Using the Retro Change Log Plug-In,” in Chapter 8 of the Directory Server Administration Guide.
Replication and the Referential Integrity Plug-In
You can use the referential integrity plug-in with multi-master replication, provided that the plug-in is enabled on all master replicas. By default the referential integrity plug-in is disabled, and must be enabled using Directory Server Console or the command line.
Before enabling the referential integrity plug-in on servers issuing chaining requests, analyze your performance resource, time and integrity needs, as integrity checks can consume significant memory and CPU resources.
For more information, see “Using Referential Integrity with Replication,” in Chapter 2 of the Directory Server Administration Guide.
Replication and Pre-Operation and Post-Operation Plug-Ins
When writing pre- and post-operation plug-ins, you can specify that the plug-ins ignore any replicated operations. This is likely to be the desired plug-in behavior, in most cases. Be aware that changing replicated operations can result in unexpected behavior.
For more information, see “Pre-Operation and Post-Operation Plug-Ins, ”” in Chapter 5 of the Directory Server Plug-In Developer’s Guide.
Replication and Chained Suffixes
When you distribute entries using chaining, the server containing the chained suffix points to a remote server that contains the actual data. This remote server is also called a farm server. In this environment, you cannot replicate the chained suffix itself. You can, however, replicate the suffix that contains the actual data on the remote server. You must configure the replication agreement on the remote server and not on the server containing the chained suffix.
Do not use replication as a backup for chained suffixes. You must back up chained suffixes manually. For more information about chaining and entry distribution refer to Referrals and Chaining.
Schema Replication
When Directory Server is used in a replicated environment, the schema must be consistent across all of the servers that participate in replication. If the schema is not consistent across servers, the replication process is likely to generate errors.
The best way to guarantee schema consistency is to make schema modifications on a single master, even in a multi-master replication topology. There is no conflict resolution with regard to schema modifications. Therefore, if you make schema modifications on two masters in a multi-master topology, the master that was updated last will propagate its schema to the consumer. This means that you risk losing modifications made to one master, if different modifications are made to another master at a later stage.
Never update the schema on a consumer. If you update the schema on a consumer, and as a result the version of the schema on the supplier is older than the version on the consumer, you will encounter errors when you attempt to search the consumer or update the supplier.
Schema replication occurs automatically. If replication has been configured between a supplier and a consumer, the schema is replicated by default.
The logic used by Directory Server for schema replication can be described as follows:
- Before pushing data to a consumer, the supplier checks whether its own version of the schema is in sync with the version of the schema held by the consumer.
- If the schema entries on both supplier and consumer are the same, the replication operation proceeds.
- If the version of the schema on the supplier is more recent than the version on the consumer, the supplier replicates its schema to the consumer before proceeding with data replication.
Changes made to custom schema files are only replicated if the schema is updated using LDAP or Directory Server Console. Custom schema files should be copied to each server to maintain the information in the same schema file on all servers. For more information, see “Replicating Schema Definitions,” in Chapter 9 of the Directory Server Administration Guide.
Replicating only user-defined schema reduces the amount of data transferred and thus speeds up the replication of schema. For more information, see “Limiting Schema Replication,” in Chapter 9 of the Directory Server Administration Guide.
Replication and Multiple Password Policies
When using multiple password policies, you must replicate the LDAP subentry containing the definition of the policy to apply to the replicated entries. If you do not do so, the default password policy is applied. This policy will not work for entries that have been configured to use a non-default password policy.
If you replicate these entries to a 5.0/5.1 server, replication functions correctly but the password policy is not enforced on the 5.0/5.1 server. Multiple password policy functionality is supported for Directory Server 5.2 only.
Replication MonitoringDirectory Server 5.2 provides command-line tools that enable replication monitoring between servers. The ability to monitor replication activity assists in identifying the causes of replication problems. All the monitoring tools can be used over a secure connection.
The replication monitoring tools constitute an LDAP client, and as such, need to authenticate to the server and use a bind DN that has read access to cn=config.
The following replication monitoring tools are provided:
- insync - indicates the state of synchronization between a master replica and one or more consumer replicas.
- entrycmp - enables you to compare the same entry on two or more servers.
- repldisc - enables you to “discover” a replication topology. Topology discovery starts with one server and builds a graph of all known servers within the topology. This replication topology discovery tool is useful for large, complex deployments where it might be difficult to recall the global topology you have deployed.
For more information regarding the replication monitoring tools, refer to “Replication Monitoring Tools” in the Directory Server Reference. For information on the monitoring possibilities available with certain replication attributes, see the replication attributes section of in “Core Server Configuration Attributes” in the Directory Server Reference.