|
| |
| Sun Java Enterprise System Deployment Planning White Paper | |
Chapter 5
Designing a Deployment ArchitectureThis chapter provides information on how to design a deployment for performance, security, availability and other system qualities. The chapter also provides information on optimizing the deployment design.
A deployment architecture depicts the mapping of a logical architecture to a physical environment. The physical environment includes the computing nodes in an intranet or Internet environment, CPUs, memory, storage devices, and other hardware and network devices.
Designing the deployment architecture involves sizing the deployment to determine the physical resources necessary to meet the system requirements specified during the technical requirements phase. You also optimize resources by analyzing the results of sizing the deployment to create a design that provides the best use of resources within business constraints.
After a deployment architecture design is complete the actual cost of the deployment is assessed during project approval. Once the project is approved, contracts for completion of the deployment need to be signed and resources to implement the project acquired.
A detailed design specification occurs before or after project approval. The detailed design specification is used in the implementation phase to build out the design.
This chapter continues using the example deployment from Chapter 4 to illustrate various steps in the process of designing a deployment architecture.
This chapter contains the following sections:
Sizing a Planned DeploymentSizing a planned deployment is the process of determining the set of hardware resources necessary to fulfill the system requirements and ultimately satisfy the business goals. As with other aspects of planning and designing a deployment, sizing is not an exact science and cannot be prescribed with formulas and recipes. Successful sizing is the result of a combination of past design experience, knowledge of systems architecture, domain knowledge, and applied creative thinking.
Sizing revolves around the system requirements you previously determined for the following system qualities, as described in System Requirements. The business requirements, usage analysis, and use cases from the earlier phases of deployment design also play a role in sizing a system.
When performing a sizing exercise, the use cases and usage analysis help determine the resources necessary to support the use cases. You typically start with the heaviest weighted use cases (representing the most common transactions) and proceed to the least weighted ones. This use of weighted use cases helps allocate resources according to the expected stress on the system.
The following sections provide some general guidance on how to size a deployment for the following system qualities:
Sizing for Performance
Sizing for performance and load requirements is an iterative process that estimates the number of CPUs and corresponding memory required to support the services in the deployed system. When estimating the number of CPUs required to support a service, consider the following:
- Use cases and corresponding usage analysis that apply to the service
- System requirements determined during analysis for technical requirements
- Past experience with the Java Enterprise System components providing the service
- Consultation with Sun professional services, who have experience with sizing various types of deployment scenarios
The process of sizing for performance typically consists of the following steps. The ordering of these steps is not critical—it simply provides a way to consider the factors that affect the final result.
- Determine a baseline CPU estimate for components identified as user entry points to the system.
- Make adjustments to the CPU estimates to account for dependencies between components.
- Make adjustments to the CPU estimates to reflect security, availability, scalability, and latent capacity requirements.
Determine Baseline CPU Estimate for User Entry Points
Begin by estimating the number of CPUs required to handle the expected load on each component that is a user entry point. Note the estimates on your layout design of the logical architecture.
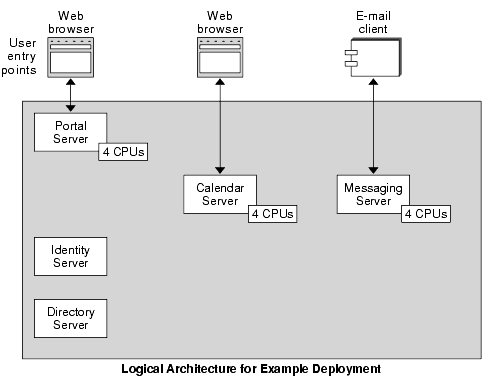
The following figure uses the example deployment introduced in Deployment Planning Example, depicting initial CPU estimates for components that are user entry points. These estimates represent figures that might result from analysis of the system requirements, use cases, and usage analysis.
Figure 5-1 Baseline CPU Estimates for Components Providing User Entry Points
Adjust CPU Estimates for Service Dependencies
The components providing user entry points require support from other Java Enterprise System services. To continue specifying performance requirements, adjust the performance estimates to take into account support required from other components.
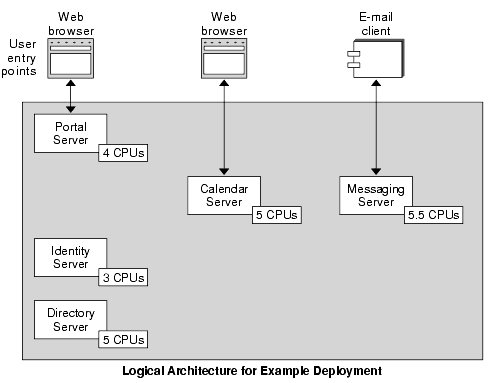
In the example, examine the logical flow of data, as illustrated in Figure 4-4, and make adjustments for components providing support to other components. The following table summarizes the adjustments to the CPU estimates. In your estimates, you can specify fractional CPUs. When performance estimates are complete, the CPU counts are totaled and rounded up.
As with the estimates in the previous section, the performance estimates in the following table are arbitrary values for illustration purposes only.
The following figure updates the estimates for performance, based on the information in Table 5-1.
Figure 5-2 CPU Estimates adjusted for Supporting Services
Adjust CPU Estimates for Latent Capacity, Scalability, and Availability
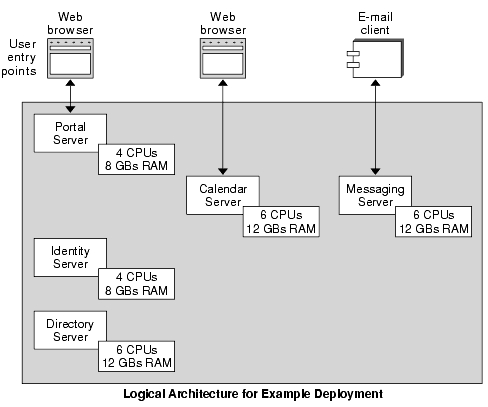
Once you complete sizing estimates for performance, round up the figures for CPUs. Typically, you round up CPUs to the next even number. When rounding up CPU estimates, consider the following factors:
The following figure adjusts the CPU estimates for the example deployment. The figure also specifies memory requirements for each CPU. The example assumes each CPU requires 2GB of memory. These memory specifications for the example are arbitrary figures for illustration purposes. The calculation of memory required for each CPU is beyond the scope of this white paper.
Figure 5-3 Performance Figures Including Memory Requirements
Sizing for Security
When sizing a deployment, security issues become a factor in the following ways:
Secure transport of data involves handling transactions over a secure transport protocol such as Secure Sockets Layer (SSL). Authentication of users can also require handling transactions over a secure transport.
Transactions handled over a secure transport typically require additional computing power to first, establish a secure session (known as the handshake) and second, to encrypt and decrypt transported data. Depending on the encryption algorithm used (for example, 40-bit or 128-bit encryption algorithms), the additional computing power can be substantial.
For secure transactions to perform at the same level as non-secure transactions, you must plan for additional computing power. Depending on the nature of the transaction, and the Java Enterprise System services that handle it, secure transactions might require four times (or more) computing power.
When estimating the performance requirement to handle secure transactions, first analyze use cases to determine the percentage of transactions that require secure transport. If the performance requirements for secure transactions are the same as for non-secure transactions, modify the CPU estimates to account for the additional computing power needed for the secure transactions.
In some usage scenarios, secure transport might only be required for authentication. Once a user is authenticated to the system, no additional security measures for transport of data is required. In other scenarios, secure transport might be required for all transactions. An estimate of five to ten percent of transactions requiring secure transport is reasonable in many cases.
For example, when browsing a product catalog for an online e-commerce site, all transactions can be non-secure until the customer has finished making selections and is ready to “check out.” Additionally, many of these e-commerce sites relax the latent response requirement for secure transactions. However some usage scenarios, such as deployments for banks or brokerage houses, require most, if not all, transactions to be secure and apply the same performance standard for both secure and non-secure transactions.
Calculating Performance for Secure Transactions
This section continues the example deployment to illustrate a worksheet for calculating CPU requirements for a use case that includes both secure and non-secure transactions.
To calculate the CPU requirements, in the worksheet make the following calculations:
- Start with a baseline figure for the CPU requirements, such as you calculated in the previous section, Sizing for Performance.
- Calculate the percentage of transactions that require SSL, and compute the CPU requirements for the SSL transactions.
- Adjust the CPU calculations for the non-secure transactions.
- Tally the secure and non-secure requirements to calculate the total CPU requirements.
The worksheet in Figure 5-4 is based on additional use cases and usage analysis for the Portal Server. The additional use cases and usage analysis assume the following:
For the purposes of this example, to account for the extra computing power to handle SSL transactions, the number of CPUs to handle these transactions will be increased by a factor of five. As with other CPU figures in the example, this is an arbitrary figure for illustration purposes only.
Figure 5-4 Worksheet for Calculating CPU Estimates for Secure Transactions
Specialized Hardware to Handle SSL Transactions
Specialized hardware devices, such as SSL accelerator cards and other appliances, are available to provide computing power to handle establishment of secure sessions and/or encryption and decryption of data. When using specialized hardware for SSL operations, computational power is dedicated to some part of the SSL computations, typically the “handshake” operation that establishes a secure session.
This hardware might be of benefit to your final deployment architecture. However, because of the specialized nature of the hardware, it is best to estimate secure transaction performance requirements first in terms of CPU power, and then consider the benefits of using specialized hardware to handle the additional load.
Some factors to consider when using specialized hardware are whether the use cases support using the hardware (for example, use cases that require a large number of SSL “handshake” operations) and the added layer of complexity this type of hardware brings to the design. This complexity includes the installation, configuration, testing, and administration of these devices.
Sizing for Availability
After you complete sizing for performance you can begin sizing your system for availability. This is where you designate specific servers to host the components in the logical architecture and design load balancing, redundancy, and failover strategies for the various Java Enterprise System components.
Study the use cases and usage analysis to determine which availability solutions to consider. The following items are examples of the type of information you gather to help determine availability strategies:
- How many nines of availability are specified?
- Are there performance specifications specific to failover situations (for example, at least 50% of performance during failover)?
- Do the use cases and usage analysis identify times of peak and non-peak usage?
- What are the latent performance requirements?
- Are there geographical considerations?
For each component, analyze the use cases to determine a best-fit solution for failover and load balancing requirements. Also, consider the use cases and usage analysis to determine the best way to load balance services.
The availability strategy you choose must also take into consideration serviceability requirements, as discussed in Serviceability Issues. Try to avoid complex solutions that require considerable administration and maintenance in favor of systems that are easy to manage.
Directory Design for Complex Systems
Complex deployments for a large number of users might require a directory design for Directory Server that can affect the availability strategy. This is because the LDAP directory design might affect availability strategy for Identity Server and Messaging Server, which in turn might affect other system qualities.
If you are designing a complex deployment, consider creating a preliminary directory design to aid in the availability design. Later, during detailed design specification or development phases, provide the complete directory design.
Hardware and Software Failures
Your availability design should provide protections for both hardware and software failures. Software failure typically has a higher cost than hardware failure. There is higher mean time between software failures than between hardware failures. Additionally, software failures are harder to diagnose and repair and require higher administration and maintenance costs to prevent.
General Approaches to Availability
This section provides some general ways you can design for availability requirements. Specific availability designs are outside the scope of this white paper.
Single Server System
Place all your computing resources for a service on a single server. If the server fails, the entire service fails.
Figure 5-5 Single Server
Sun provides high-end servers that provide the following benefits:
A high-end server typically costs more than a comparable multi-server system. However, a single server provides savings on administration, monitoring, and hosting costs for servers in a data center. However, load balancing, failover, and removal of single points of failure is more flexible with multi-server systems.
Horizontally Redundant Systems
There are several ways to increase availability with parallel redundant servers that provide both load balancing and failover. The following figure illustrates two replicate servers providing an N+1 availability system. An N+1 system has an additional component to provide 100% capacity should one server fail.
Figure 5-6 Two Replicate Servers
The computing power of each server in Figure 5-6 above is identical. One server alone handles the performance requirements. The other server provides 100% of performance when called into service as a backup.
Advantages of a replica server design is 100% performance during a failover situation. Disadvantages include increased hardware costs with no corresponding gain in overall performance.
The following figure illustrates a scenario that distributes the performance between two servers for load balancing and failover.
Figure 5-7 Distribution of Load Between Two Servers
In Figure 5-7 above, if one server fails, all services are still available, although at a percentage of the full capacity. The remaining server provides 6 CPUs of computing power, which is 60% of the 10 CPU requirement.
An advantage of this design is the additional 2 CPU latent capacity when both servers are available. Also if one server fails, all of the services are available, but possibly at diminished performance.
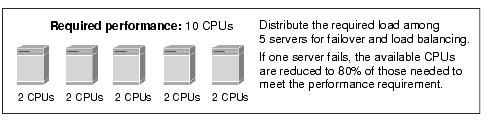
The following figure illustrates the distribution between a number of servers for performance and load balancing.
Figure 5-8 Distribution of Load Between n Servers
Because there are five servers in the design illustrated inFigure 5-8, if one server fails the remaining servers provide a total 8 CPUs of computing power, which is 80% of the 10 CPU performance requirement. If you add an additional server with 2 CPUs capacity to the design, you effectively have an N+1 design. If one server fails, 100% of the performance requirement is met by the remaining servers.
This design includes the following advantages:
However, administration and maintenance costs can increase significantly with additional servers. There are also hosting costs for servers in a data center. At some point you run into diminishing returns by adding additional servers.
Sun Cluster
For situations that require a high degree of availability (such as four or five nines), you might consider Sun Cluster as part of your availability design. A cluster system is the coupling of servers, storage, and other network resources. The servers in a cluster continually communicate with each other. If one of the servers goes offline, the rest of the devices in the cluster isolate the server and fail-over any application or data from the failing node to another node. This failover process is done achieved relatively quickly with little interruption of service to the users of the system.
Sun Cluster requires additional dedicated hardware and specialized skills to configure, administer, and maintain.
Availability Design for Sample Deployment
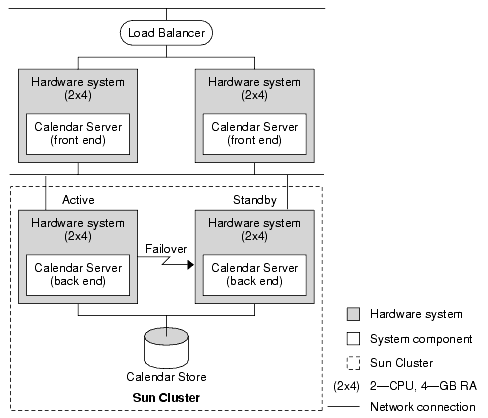
The following figure shows an availability design for the calendar service portion of the example deployment, which was introduced in Chapter 4, "Designing the Logical Architecture." The figure depicts an availability solution for the Calendar Server piece of the logical architecture for the example deployment. An analysis of the complete availability solution for the example deployment is beyond the scope of this white paper.
The sizing exercise earlier in this chapter determined that Calendar Server requires 6 CPUs and 12 GB of memory, as depicted in Figure 5-3. The following figure shows the front end of Calendar Server deployed on two servers for load balancing incoming and outgoing requests. The back end of Calendar Server is deployed on a separate server, and is replicated in a Sun Cluster 3.1 4/04 for failover. For failover purposes, the CPU and memory required for the Calendar Server back end is replicated in the Sun Cluster 3.1 4/04.
Figure 5-9 Availability Design for Calendar Server in Example Deployment
Serviceability Issues
When designing for availability, you must also consider the administration and maintenance costs of your solution. These costs are often overlooked in a design because they are not specifically tied to the purchase of hardware. Rather, they can be hidden, ongoing costs that reflect the complexity of your design.
For example, your design might include a large number of horizontally redundant servers that provide a high degree of availability. But if you do not factor in the costs to set up and configure the servers, continually upgrade the software, and monitor the health of the system the availability gain can be compromised.
When designing for serviceability, consider the following administration and maintenance costs:
Sizing for Scalability
Scalability describes the ability to add capacity to your system, usually by the addition of system resources, but without changes to the deployment architecture. This section discusses topics to consider when designing for scalability.
During requirements analysis, you typically make projections of expected growth to a system based on the business requirements and subsequent usage analysis. These projections of the number of users of a system, and the capacity of the system to meet their needs, are often estimates that can vary significantly from the actual numbers for the deployed system. Your design should be flexible enough to allow for variance in your projections.
Latent Capacity
Latent capacity is one aspect of scalability where you include additional performance and availability resources into your system so it can easily handle unusual peak loads. Latent capacity is one way to build safety into your design.
A careful analysis of use cases can help identify the scenarios that can create unusual peak loads (for example, a business to employee deployment that schedules mandatory webcasts). Use this analysis of unusual peak loads, plus a factor to cover unexpected growth, to design latent capacity that builds safety into your system.
You can also monitor how latent capacity is used in a deployed system to help determine when it is necessary to scale the system by adding resources.
Upgrading the Capacity of a System
Your system design should be able to handle projected capacity for the first 6 to 12 months of operation. Maintenance cycles can be used to add resources or increase capacity as needed. Ideally, you should be able to schedule upgrades to the system on a regular basis, but predicting needed increases in capacity is often difficult. Rely on careful monitoring of your resources as well as business projections to determine when to upgrade a system.
If you are performing an incremental deployment, where you defer deployment of parts of the system for business or technical reasons, you might schedule upgrading the capacity of the system to coincide with other upgrades that include new features of the system.
Optimizing ResourcesSizing a deployment is not just the estimation of resources to meet the system requirements. Sizing is also an exercise in both risk management and resource management. How a design handles risk management and resource management is often the key to meeting business goals.
Risk Management
Much of the information on which sizing is based, such as business requirements and usage analysis, is not empirical data but data based on estimates and projections. Before completing the sizing of a planned deployment, revisit the data and make sure your sizing design takes into account any reasonable deviations from the estimates or projections.
For example, if the projections from the business requirements underestimate the actual usage of the system, you run the risk of building a system that cannot cope with the amount of traffic it encounters. A design that under performs will surely be considered a failure.
On the other hand, if you build a system that is several orders more powerful than required, you divert resources that could be used elsewhere. The key is to include a margin of safety above the requirements, but to avoid extravagant use of resources.
Extravagant use of resources can also result in a failure of the design because t under utilized resources could have been applied to other areas critical to success. Additionally, extravagant solutions might be perceived as not fulfilling contracts in good faith.
Managing Resources
Managing resources is the process of analyzing all available sizing options and selecting the best fit solution that minimizes cost but still fulfills system requirements. This involves understanding the trade-offs for each design decision to make sure a benefit in one area is not offset by a cost in another.
For example, horizontal scaling for availability might increase overall availability, but at the cost of increased maintenance and service. Vertical scaling for performance might increase computing power inexpensively, but the additional power might be used inefficiently by some services.
Before completing your sizing strategy, examine your decisions to make sure you have balanced the use of resources with overall benefit to the design. This typically involves examining how system qualities in one area affect other system qualities. The following table lists some topics you might want to consider for management of resources.
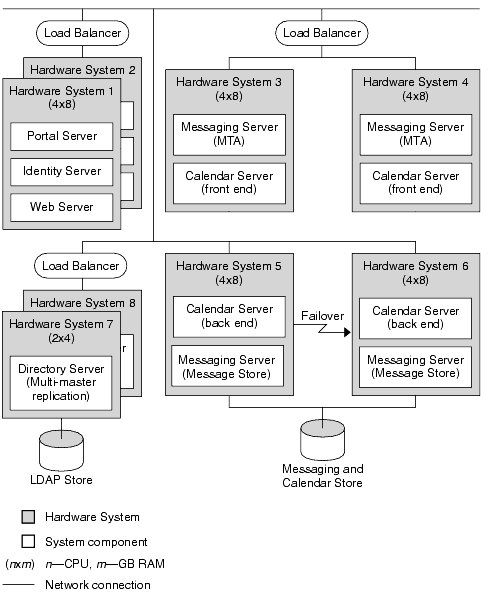
Example Deployment ArchitectureThe following figure represents a completed deployment architecture for the example deployment introduced earlier in this white paper. This figure provides an idea of how to present a deployment architecture.
Figure 5-10 Example Deployment Architecture
Detailed Design SpecificationAfter a deployment architecture is complete, there is a period for customer review, followed by, hopefully, project approval. In some cases the customer might redirect you to make changes to the deployment architecture before granting approval.
After project approval, you create a detailed design specification that is a starting point for implementation of the deployment. The design specification includes details on specific hardware resources and network devices, as well as a detailed LDAP directory specification.