|
| |
| Sun Java System Messaging Server 6 2004Q2 Deployment Planning Guide | |
Chapter 10
Planning for Service AvailabilityThis chapter helps you determine the level of service availability that is right for your deployment. The level of service availability is related to the hardware you choose as well as your software infrastructure and maintenance practices. This chapter discusses several choices, their value, and their costs.
This chapter contains the following sections:
Automatic System Reconfiguration (ASR) OverviewIn addition to evaluating a purely highly available (HA) solution, you should consider deploying hardware that is capable of ASR.
ASR is a process by which hardware failure related downtime can be minimized. If a server is capable of ASR, it is possible that individual component failures in the hardware result in only minimal downtime. ASR enables the server to reboot itself and configure the failed components out of operation until they can be replaced. The downside is that a failed component that is taken out of service could result in a less performing system. For example, a CPU failure could result in a machine rebooting with fewer CPUs available. A system I/O board or chip failure could result in system with diminished or alternative I/O paths in use.
Different Sun SPARC systems support very different levels of ASR. Some systems support no ASR to very high levels. As a general rule, the more ASR capabilities a server has, the more it costs. In the absence of high availability software, choose machines with a significant amount of hardware redundancy and ASR capability for your data stores, assuming that it is not cost prohibitive.
Understanding High Availability ModelsYou can use a variety of high availability models for Messaging Server. Three of the more common models are:
- Asymmetric (hot standby)
The following subsections describe each of these models in more detail.
Note
Different HA products potentially do or do not support different models. Refer to the appropriate product HA documentation to determine which models are supported.
Asymmetric
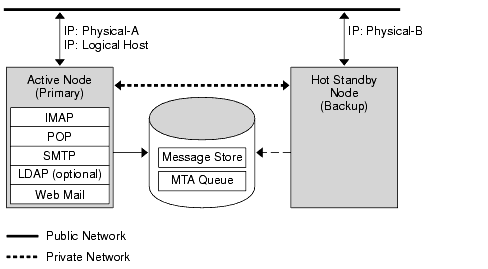
The basic asymmetric or “hot standby” high availability model consists of two clustered host machines or “nodes.” A logical IP address and associated host name are designated to both nodes.
In this model, only one node is active at any given time. The backup or hot standby node remains idle most of the time. A single shared disk array between both nodes is configured and is mastered by the active or “primary” node. The Message Store partitions and Message Transfer Agent (MTA) queues reside on this shared volume. The following figure shows the asymmetric model.
Figure 10-1 Asymmetric High Availability Model
The preceding figure shows two physical nodes, Physical-A and Physical-B. Before failover, the active node is Physical-A. Upon failover, Physical-B becomes the active node and the shared volume is switched so that it is mastered by Physical-B. All services are stopped on Physical-A and started on Physical-B.
The advantage of this model is that the backup node is dedicated and completely reserved for the primary node. Additionally, there is no resource contention on the backup node when a failover occurs. However, this model also means that the backup node stays idle most of the time and this resource is therefore under utilized.
Symmetric
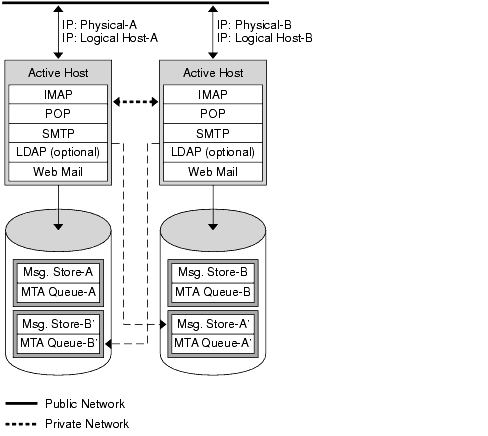
The basic symmetric or “dual services” high availability model consists of two hosting machines, each with its own logical IP address. Each logical node is associated with one physical node, and each physical node controls one disk array with two storage volumes. One volume is used for its local message store partitions and MTA queues, and the other is a mirror image of its partner’s message store partitions and MTA queues.
The following figure shows the symmetric high availability mode. Both nodes are active concurrently, and each node serves as a backup node for the other. Under normal conditions, each node runs only one instance of Messaging Server.
Figure 10-2 Symmetric High Availability Model
Upon failover, the services on the failing node are shut down and restarted on the backup node. At this point, the backup node is running Messaging Server for both nodes and is managing two separate volumes.
The advantage of this model is that both nodes are active simultaneously, thus fully utilizing machine resources. However, during a failure, the backup node will have more resource contention as it runs services for Messaging Server from both nodes. Therefore, you should repair the failed node as quickly as possible and switch the servers back to their dual services state.
This model also provides a backup storage array. In the event of a disk array failure, its redundant image can be picked up by the service on its backup node.
To configure a symmetric model, you need to install shared binaries on your shared disk. Note that doing so might prevent you from performing rolling upgrades, a feature that enables you to update your system during Messaging Server patch releases. (This feature is planned for future releases.)
N+1 (N Over 1)
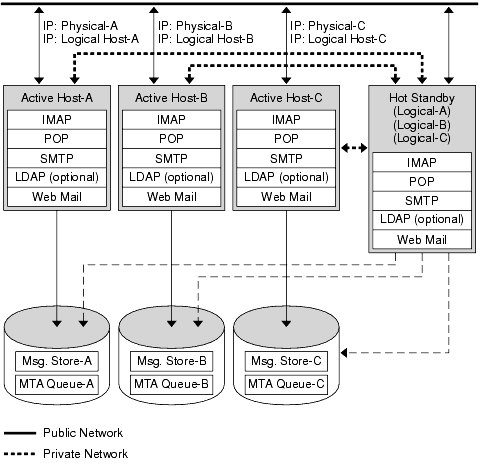
The N + 1 or “N over 1” model operates in a multi-node asymmetrical configuration. N logical host names and N shared disk arrays are required. A single backup node is reserved as a hot standby for all the other nodes. The backup node is capable of concurrently running Messaging Server from the N nodes.
Figure 10-3 illustrates the basic N + 1 high availability model.
Figure 10-3 N + 1 High Availability Model
Upon failover of one or more active nodes, the backup node picks up the failing node’s responsibilities.
The advantages of the N + 1 model are that the server load can be distributed to multiple nodes and that only one backup node is necessary to sustain all the possible node failures. Thus, the machine idle ratio is 1/N as opposed to 1/1, as is the case in a single asymmetric model.
To configure an N+1 model, you need to install binaries only on the local disks (that is, not shared disks as with the symmetric model). The current Messaging Server installation and setup process forces you to put the binaries on the shared disk for any symmetric, 1+1, or N+1 asymmetrical or symmetrical HA solution.
Choosing a High Availability ModelThe following table summarizes the advantages and disadvantages of each high availability model. Use this information to help you determine which model is right for your deployment.
System Down Time Calculations
The following table illustrates the probability that on any given day the messaging service will be unavailable due to system failure. These calculations assume that on average, each server goes down for one day every three months due to either a system crash or server hang, and that each storage device goes down one day every 12 months. These calculations also ignore the small probability of both nodes being down simultaneously.
Locating Product Reference InformationFor more information on high availability models supported by Messaging Server, see the following product documentation:
Understanding Remote Site FailoverRemote site failover is the ability to bring up a service at a site that is WAN connected to the primary site in the event of a catastrophic failure to the primary site. There are several forms of remote site failover and they come at different costs.
For all cases of remote site failover, you need additional servers and storage capable of running all or part of the users’ load for the service installed and configured at the remote site. By all or part, this means that some customers might have priority users and non-priority users. Such a situation exists for both ISPs and enterprises. ISPs might have premium subscribers, who pay more for this feature. Enterprises might have divisions that provide email to all of their employees but deem this level of support too expensive for some portion of those users. For example, an enterprise might choose to have remote site failover for mail for those users that are directly involved in customer support but not provide remote site failover for people who work the manufacturing line. Thus, the remote hardware must be capable of handling the load of the users that are allowed to access remote failover mail servers.
While restricting the usage to only a portion of the user base reduces the amount of redundant server and storage hardware needed, it also complicates configuration and management of fail back. Such a policy can also have other unexpected impacts on users in the long term. For instance, if a domain mail router disappears for 48 hours, the other MTA routers on the Internet will hold the mail destined for that domain. At some point, the mail will be delivered (hopefully without experiencing DoS failures) when the server comes back online. Further, if you do not configure all users in a failover remote site, then the MTA will be up and give permanent failures (bounces) for the users not configured. Lastly, if you configure mail for all users to be accepted, then you have to fail back all users or set up the MTA router to hold mail for the nonfunctional accounts while the failover is active and stream it back out once a failback has occurred.
Potential remote site failover solutions include:
- Simple, less expensive scenario. The remote site is not connected by large network bandwidth. Sufficient hardware is setup but not necessarily running. In fact, it might be used for some other purpose in the meantime. Backups from the primary site are shipped regularly to the remote site, but not necessarily restored. The expectation is that there will be some significant data loss and possibly a significant delay in getting old data back online. In the event of a failure at the primary site, the network change is manually started; services are started, followed by beginning the imrestore process; and the file system restore is started following which services are brought up.
- More complicated, more expensive solution. Both Veritas and Sun sell software solutions that cause all writes occurring on local (primary) volumes to also be written to remote sites. In normal production, the remote site is in lock step or near lock step with the primary site. Upon primary site failure, the secondary site can reset the network configurations and bring up services with very little to no data loss. In this scenario, there is no reason to do restores from tape. Any data that does not make the transition prior to the primary failure is lost, at least until failback or manual intervention occurs in the case of the MTA queued data. Veritas Site HA software is often used to detect the primary failure and reset the network and service bring up, but this is not required to get the higher level of data preservation.This solution requires a significant increase in the quantity of hardware at the primary site as there is a substantial impact in workload and latency on the servers to run the data copy.
- Most available solution. This solution is essentially the same as the software real time data copy solution except the data copy is not happening on the Message Store server. Instead, a Hitachi Data Systems (HDS) array performs this function. Hitachi arrays have the ability to do this data copy between arrays with little to no impact on the store servers. The HDS arrays are large, so the base cost of obtaining this solution is higher than a few Sun StorEdge™ T3 or 3000 arrays. Also, the cost per megabyte is higher even if the HDS is fully utilized. If you need a large quantity of storage, the savings in server hardware due to allowing the HDS do the copy work can balance the additional cost of the storage, at least to some degree.
There are a variety of costs to these solutions, from hardware and software, to administrative, power, heat, and networking costs. These are all fairly straightforward to account for and put a number on. Nevertheless, it is difficult to account for some costs: the cost of mistakes when putting a rarely practiced set of procedures in place, the inherent cost of downtime, the cost of data loss, and so forth. There are no fixed answers to these types of costs. For some customers, downtime and data loss are extremely expensive or totally unacceptable. For others, it is probably no more than an annoyance.
In doing remote site failover, you also need to ensure that the remote directory is at least as up to date as the messaging data you are planning to recover. If you are using a restore method for the remote site, the directory restore needs to be completed before beginning the message restore. Also, it is imperative that when users are removed from the system that they are only tagged as disabled in the directory. Do not remove users from the directory for at least as long as the messaging backup tapes that will be used might contain that user’s data.
Questions for Remote Site Failover
Use the following questions to assist you in planning for remote site failover:
For some organizations, it is sufficient to use a scripted set of manual procedures in the event of a primary site failure. Others need the remote site to be active in rather short periods of time (minutes). For these organizations, the need for Veritas remote site failover software or some equivalent is overriding.