|
| |
| Sun Java(TM) System Directory Server 5.2 2005Q1 Performance Tuning Guide | |
Chapter 4
Tuning IndexingAs Directory Server handles more and more entries, searches potentially consume more and more time and system resources. Indexes are one tool to improve search performance. This chapter covers how Directory Server indexes work so that you understand the costs and benefits of using a specific index in the context of a particular deployment. It includes the following sections:
About IndexesIndexes associate lookup information with Directory Server entries. Indexes take the form of files stored with Directory Server databases. A database in this context is the physical representation of a suffix. For most deployments, one suffix corresponds to one database. For some deployments, one suffix may be split across multiple databases. Directory Server stores databases under ServerRoot/slapd-ServerID/db/ by default (the default value of nsslapd-directory). Here you find individual database instances having one index file per indexed attribute. For instance, a CN index file for a database, example, holding entries from the suffix dc=example,dc=com, is called ServerRoot/slapd-ServerID/db/example/example_cn.db3.
What you index depends upon how client applications access directory data. Table 4-1 includes short descriptions of standard index types.
An index file for a particular attribute such as CN may contain multiple types of indexes. For instance, if CN is indexed in the example database for equality and for substring matching, then example_cn.db3 contains both equality and substring indexes.
Refer to the Directory Server Administration Guide for:
Default indexes improve search performance in many situations, and support searches performed by certain other applications. In some cases, you may choose to disable or even delete particular default indexes for performance reasons. System indexes are those on which Directory Server depends. Do not delete or modify them.
Benefits: How Searches Use IndexesIndexes speed up searches. An index contains a list of values, each associated with a list of entry identifiers corresponding to the value. Directory Server can look up entries quickly using the lists of entry identifiers in indexes. Without an index to manage a list of entries, Directory Server may have to check every entry in a suffix to find matches for a search.
The reason an indexed search may require significantly less processing than an unindexed search becomes evident when search request processing is explained. Here is how Directory Server processes each search request:
- A client application sends a search request to Directory Server.
- Directory Server examines the request to ensure the search base corresponds to a suffix it can handle. If not, it returns an error to the client, and may return a referral to another Directory Server instance.
- Directory Server determines whether it manages an index or indexes appropriate to the search.
For each such index that exists, Directory Server looks up candidate entries — entries that might be a match for the search request — in the index, as shown in Figure 3-2.
Notice that if no such index exists, Directory Server generates the set of candidate entries from all entries in the database. For large deployments, this step may consume considerable time and system resources, depending on the search.
- Directory Server examines each candidate entry to determine if it matches the search criteria. Directory Server returns matching entries to the client application as it finds them.
Directory Server continues examining candidates either until all candidates have been examined, or until it reaches a resource limit such as nsslapd-lookthroughlimit, nsslapd-sizelimit, or nsslapd-timelimit, as described in Limiting Resources Available to Clients.
As is evident from Step 3, indexes can reduce significantly the processing Directory Server must perform to respond to a search request from a client.
Costs: How Updates Affect IndexesUpdates change not only entries themselves, but also indexes referencing the entries. The more references to an entry in indexes, the higher the potential processing cost to modify the indexes during an update. Specifically, Directory Server modifies all impacted indexes as shown in Figure 3-3 before sending acknowledgement of the update to the client application.
In addition to the processing costs incurred for index maintenance, indexes have a cost in terms of space on disk and potentially space in memory. When optimizing database cache size for searches, as described Optimizing For Searches, you may opt to provide enough memory to hold both entries and indexes in database cache. The larger the indexes, the more space required. 64-bit indexes require somewhat more space than 32-bit indexes, as well.
In general, tuning indexing for an instance of Directory Server means maintaining only those indexes for which the benefits from faster search processing offset the costs of more update processing and of more space needed. Maintaining useful indexes is good practice; maintaining unused indexes for attributes on which clients rarely search is a waste.
This section explains the costs of using each type of indexing:
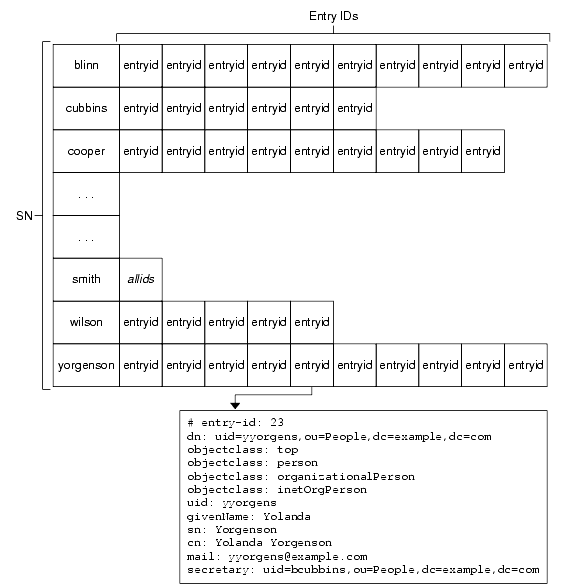
Presence Indexes
Figure 4-1 depicts a presence index for the nsRoleDN attribute, showing how this index is independent of the attribute value, but simply includes all entries in the database having an nsRoleDN attribute. Every value of the attribute matches +.
Figure 4-1 Representation of a Presence Index
As shown, the internal entryid attribute value allows Directory Server to store a reference to the entry that allows for quick retrieval. Directory Server actually retrieves the entry using the dbinstance/id2entry.db3 index file, where dbinstance depends on the database identifier as implied in About Indexes.
When Directory Server receives an update request to remove an attribute value indexed for presence, it must remove the entry from the presence index for that attribute before returning acknowledgement of the update to the client application.
The cost of presence indexes is generally lower than for other index types, although the list of entries maintained for a presence index may be long. When index list length is limited, presence indexes are useful primarily for attributes present in a relatively small percentage of directory entries. Refer to Limiting Index List Length for further information.
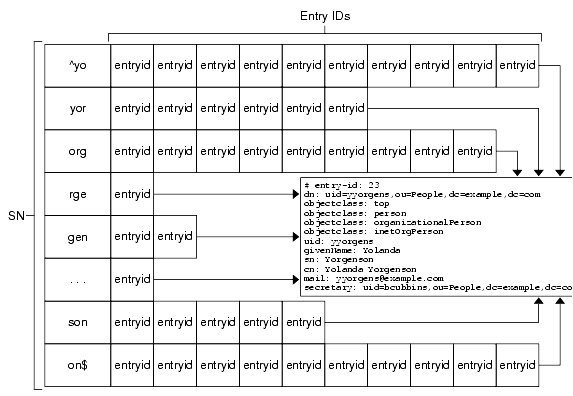
Equality Indexes
Figure 4-2 depicts an equality index for the SN (surname) attribute. It shows how this index maintains a list per attribute value of entries having that attribute value for the SN attribute.
Figure 4-2 Representation of an Equality Index
When Directory Server receives an update request for an entry having an attribute indexed for equality, it must determine whether the entry must be removed from the index or not, determine whether a list must be added to or removed from the index, and must then carry out any necessary modifications before returning acknowledgement of the update to the client application.
The cost of equality indexes is generally lower than for substring indexes, for example, but higher in terms of space than for presence. Some client applications such as messaging servers may, however, rely on equality indexes for top search performance. Avoid equality indexes for large binary attributes such as photos and hashed passwords.
Substring Indexes
Figure 4-3 depicts a substring index for the SN (surname) attribute. It shows an excerpt of how this index maintains a series of lists per attribute value.
Directory Server indexes substrings in three-character group. The search algorithm includes an optimization such that searches for two-character substrings may use the index. A search for (sn=*ab*) may therefore be accelerated using an index, for example, but a search for (sn=*a*) cannot. The optimization still is less efficient than using substring searches with at least three-character groups, as the three-character groups are actually stored in the indexes, as shown in Figure 4-3.
Figure 4-3 Representation of a Substring Index
Furthermore, two-character substring search are more subject to reaching the index list length limit, after which the search no longer uses indexes. Refer to Limiting Index List Length for further information.
Directory Server offers a further optimization allowing initial substring searches of only one character before the wildcard. Thus a search for (sn=a*), but not (sn=*a*) or (sn=*a), can also be accelerated when a substring index is available, for example. This optimization is subject to the same limitations as the two-character substring searches.
Notice that Directory Server builds an index of substrings according to its own built-in rules. These substrings are not configurable by the system administrator.
When Directory Server receives an update request for an entry having an attribute indexed for substrings, it must determine whether the entry must be removed from the index, determine whether and how modifications to the entry affect the index, determine whether entry IDs or lists of entry IDs must be added to or removed from the index, and must then carry out any necessary modifications before returning acknowledgement of the update to the client application. The number of updates depends on the length of the attribute value string.
Maintaining substring indexes is generally quite costly. As the cost is a function of the length of the string indexed, avoid unnecessary substring indexes, especially for attributes having potentially long string values such as description. Substring indexes cannot be applied to binary attributes such as photos.
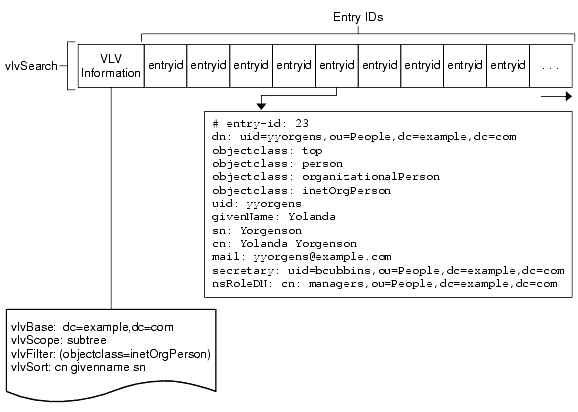
Browsing (Virtual List View) Indexes
Figure 4-4 depicts a browsing index for a virtual lists view. It shows how this index depends on the virtual list view information. That is, the vlvBase, vlvScope, vlvFilter, and vlvSort attribute values for the browsing index. Entry IDs in this type of index are ordered according to the vlvSort criteria.
Figure 4-4 Representation of a Browsing Index
When Directory Server receives an update request for an entry matching a vlvFilter value, it must determine whether the entry must be removed from the index or not, determine the correct position of the entry in the list, and must then carry out any necessary modifications before returning acknowledgement of the update to the client application.
Approximate Indexes
Directory Server maintains approximate indexes using a variation of the metaphone phonetic algorithm. This algorithm breaks down an attribute string value into a rough approximation of its English phonetic pronunciation. Values to match in incoming search requests are handled using the same algorithm. As the algorithm is based loosely on syllables, it is not effective for attributes containing numbers such as telephone numbers.
The algorithm generates a target string for each attribute value string. Costs for this "sounds like" indexing of English-language strings are therefore similar to those for equality indexing.
International Indexes
International indexes use matching rules for particular locales to maintain indexes. Costs for such indexes therefore resemble costs for substring and equality indexes.
Using a custom matching rule server plug-in, you can extend standard support for international and other types of indexing. Refer to the Directory Server Plug-in Developer's Guide for more information on custom matching rule plug-ins.
Example: Indexing an Entry
Consider a user entry as shown in Code Example 4-1 being added to a suffix indexed for equality on uid, for equality, substring and approximate searches on Common Name (cn) and surname (sn) attributes, for equality searches on the mail attribute, for equality and substring searches on the telephoneNumber attribute, and for substring searches on the description attribute. This section examines why you might not want, for example, to create substring attributes on long string values, such as that in the description attribute.
In adding this entry, Directory Server must modify indexes for cn, sn, mail, telephoneNumber, and description. Table 4-2 illustrates the expected number of entries.
Table 4-2 Index Updates for Sample User Entry
Attribute
Approximate
Equality
Substring1
Total Index Updates
uid
1
1
cn
1
1
17
19
sn
1
1
9
11
1
1
telephoneNumber
1
11
12
description
47
47
1Substring indexing on strings as long as the description string here is not recommended for most deployments.
Notice that the number of substring index updates for the description string is larger (47) than the number of updates (44) for all other attributes combined. Also, further modifications to the description string may again imply a maximum number of updates or more depending on the new string. In most cases, avoid substring indexing of this volume by not applying substring indexing to long strings such as description values.
Tuning Indexing for PerformanceIn many cases, tuning indexing for performance implies activating indexes to speed up frequent searches, and deactivating indexes that are expensive to maintain and not frequently used.
Note
Database backups include indexes, and so should match the Directory Server configuration.
After changing how indexes are configured, back up both the configuration and the data.
Allowing Only Indexed Searches
Directory Server makes it possible to prevent costly unindexed searches, returning LDAP_UNWILLING_TO_PERFORM to clients requesting an unindexed search.
To prevent unindexed searches against a particular database, set the nsslapd-require-index attribute value to on for the database:
$ ldapmodify -h host -p port -D "cn=Directory Manager" -w password
dn: cn=example, cn=ldbm database, cn=plugins, cn=config
changetype: modify
replace: nsslapd-require-index
nsslapd-require-index: on
^D (^Z on Windows systems)The change takes effect immediately. No need to restart Directory Server.
Limiting Index List Length
In large and fast growing directory deployments, indexing may reach the point of diminishing returns for a particular index key. At the point of diminishing returns, the list associated with a particular key becomes so long that maintaining the list costs more than performing an occasional unindexed search on that particular key for candidate entries.
Imagine a library card catalog proposal for indexing by topic. Imagine one of the topics is fiction. Yet, the library has so many works of fiction that looking them up in the card catalog and then going to the shelves to retrieve the books takes longer than simply browsing through the fiction section. So the library does not maintain a catalog for fiction, but still maintains card catalogs for other topics.
Directory Server has a mechanism for handling this situation, using a configuration attribute holding a threshold value. If the number of entries in the list for a particular key reaches the threshold, Directory Server replaces the list for the key with a token specifying that an unindexed search should be performed to find candidate entries for that particular key. The value is somewhere near but less than the value for the maximum number of candidate entries checked for a search, set using nsslapd-lookthroughlimit, as described in Table 6-2.
The mechanism is referred to as the all IDs threshold, named after the configuration attribute used to set the global threshold value, nsslapd-allidsthreshold on cn=config,cn=ldbm database,cn=plugins,cn=config. Notice this value is currently global to the Directory Server instance. It cannot be set differently for different indexes.
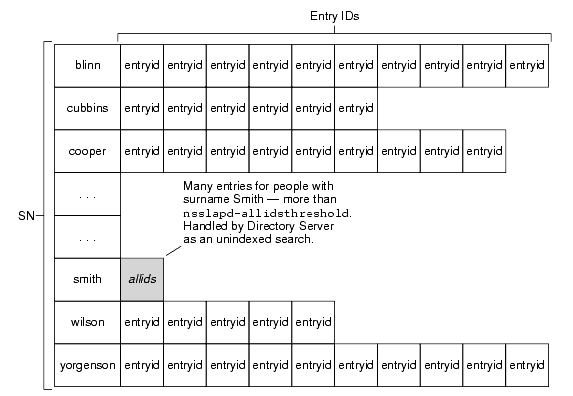
Figure 4-5 illustrates the example of indexing on surname with a number of Smiths greater than nsslapd-allidsthreshold.
Figure 4-5 Reaching the All IDs Threshold for an Index Key
Notice that the threshold affects only one list in the index table. Lists for other keys are not affected.
Symptoms of Inappropriate Index List Size
If clients perform primarily indexed searches and cache sizes are correctly tuned as described in Chapter 3, "Tuning Cache Sizes," yet you still observe poor search performance, an inappropriate threshold value may be the cause. When you observe poor search performance for indexed searches, ensure cache sizes are appropriately tuned first. Next, examine the access log to determine whether Directory Server is reaching the all IDs threshold often.
The notes=U flag at the end of an access log RESULT message indicates Directory Server performed an unindexed search. A previous SRCH message for the same connection and operation specifies the search filter used. The following two-line example traces an unindexed search for (cn=Smith) returning 10000 entries. Time stamps have been removed from the messages.
conn=2 op=1 SRCH base="o=example.com" scope=0 filter="(cn=Smith)"
conn=2 op=1 RESULT err=0 tag=101 nentries=10000 notes=UIf you observe many such pairs for searches that should be indexed, you may be able to improve search performance by increasing the threshold.
Changing the Index List Threshold Size
Good values for nsslapd-allidsthreshold typically fall in a range around 5 percent of the total number of entries in the directory. For example, the default value of 4000 is generally right for Directory Server instances handling 80,000 entries or less. You may decide to set the value significantly higher than 5 percent of the total if you expect to add large numbers of entries to the directory in the near term, or if you expect the directory to grow considerably. You may also decide to set the threshold differently on consumer replicas supporting many searches than on masters supporting almost only writes. If you plan to initialize a large directory from LDIF in the near term, you may even choose to adjust the value for nsslapd-allidsthreshold just before initialization, as each change to the value of this attribute requires that all indexes be rebuilt. Finally, you may choose to set this value quite high in directories with deeply hierarchical DITs, so searches for all entries below a given branch are indexed. In any case, avoid setting the all IDs threshold very high (above 50,000) even for very large deployments unless you have a good, specific reason for doing so.
Change the all IDs threshold as follows. Note that service is interrupted on the Directory Server instance undergoing the change.
Refer to the Directory Server Administration Guide for specific instructions.
- If database cache size was tuned for the old all IDs threshold value and the server has adequate physical memory, consider increasing database cache size by 25 percent of the magnitude of the increase to the threshold.
In other words, if you increase the all IDs threshold from 4000 to 6000, you may choose to increase database cache size by about 12.5 percent to account for increased index list size. Find the optimum size empirically before applying changes to production servers. Refer to Chapter 3, "Tuning Cache Sizes," for details on database cache tuning.
- Restart the Directory Server instance.