|
| |
| Sun Java™ System Directory Server 5.2 2005Q1 配備計画ガイド | |
第 9 章
参考のアーキテクチャとトポロジディレクトリの配備を計画するときは、いくつかの事項を考慮する必要があります。もっとも重要な事項には、データの物理的な配置場所、このデータをどこに、また、どのようにレプリケートするか、障害を最小化するにはどうすればよいか、障害が発生した場合にどのように対応するか、などが含まれます。この章で説明するアーキテクチャ戦略は、これらの事項について考える上でのガイドラインとなります。
この章は、次の節から構成されています。
障害と復元について障害発生時にサービスの中断を最小限にとどめるための戦略を準備しておくことが重要です。ここでいう障害とは、必要とされる最小限のサービスを Directory Server が提供できなくなる原因として定義されます。ここでは、配備で発生する障害の原因を特定し、障害に迅速に対応できるように、障害のさまざまな発生原因について説明します。
障害は、主に次の 2 つに分けられます。
システムが使用できなくなることには、次のような原因があります。
システムが信頼できなくなることには、次のような原因があります。
書き込み可能なサーバーが利用できなくなった場合に、ディレクトリ内のデータを追加、変更する機能を維持するには、書き込み操作が代替サーバーを経由する必要があります。書き込み操作のルーティングにはさまざまな方法があり、Sun Java System Directory Proxy Server の使用もそれに含まれます。
ディレクトリ内のデータを読み取る機能を維持するには、適切なロードバランス戦略を配備する必要があります。読み取りの負荷を複数のコンシューマレプリカに分散するには、ソフトウェアとハードウェアの両方のロードバランスソリューションを利用できます。それぞれのソリューションには、各レプリカの状態を特定し、ロードバランストポロジの中でどのような役割を果たすべきかを管理する機能 (完全性と精度はそれぞれ異なる) があります。
ディレクトリの内容をレプリケートすると、Directory Server の可用性が向上します。信頼できるレプリケーショントポロジを構築することで、障害が発生した場合でも、データセンターにアクセスするすべてのクライアントは最新のデータに確実にアクセスできます。
次に、読み取り操作と書き込み操作のための障害戦略について説明します。これは、レプリケーショントポロジにも関連します。
バックアップ戦略の策定データの破損や喪失をともなう障害では、データの最新のバックアップが不可欠になります。最新のバックアップが得られない場合、障害が発生したマスターを別のマスターから初期化し直す必要があります。データのバックアップについては、『Directory Server 管理ガイド』の「データのバックアップ」を参照してください。
ここでは、バックアップと復元の戦略を計画する上で考慮すべき事項について簡単に説明します。
バックアップ方法の選択
Directory Server では、バイナリバックアップ (db2bak) と、LDIF ファイルへのバックアップ (db2ldif) という 2 つの方法でデータをバックアップできます。これらのコマンドは、両方とも directoryserver コマンドのサブコマンドです。詳細は、『Directory Server Man Page Reference』を参照してください。どちらの方法にも利点と制限があるため、効果的なバックアップ戦略を計画するには、それぞれの方法について理解することが役立ちます。
バイナリバックアップ (db2bak)
バイナリバックアップは、ファイルシステムレベルで行われます。バイナリバックアップの出力は、すべてのエントリ、インデックス、更新履歴ログ、トランザクションログを含むバイナリファイルのセットです。
バイナリバックアップには、次のような利点があります。
バイナリバックアップには、次のような制約があります。
- バイナリバックアップからの復元は、同じ設定のサーバーだけで実行できる。つまり、次の制約が適用される。
- 両方のマシンが同じハードウェア、同じオペレーティングシステム (サービスパックやパッチも含まれる) を使用している必要がある。
- 両方のマシンに同じバージョンの Directory Server (バイナリ形式 (32 ビットまたは 64 ビット)、サービスパック、パッチも含まれる) がインストールされている必要がある。
- 両方のサーバーは、同じサフィックスに分岐する同じディレクトリツリーを持つ必要がある。すべてのサフィックスのデータベースファイルをまとめてコピーする必要があり、サフィックスを個別にコピーすることはできない。
- 両方のサーバーの各サフィックスには同じインデックス (VLV (仮想リスト表示) インデックスも含まれる) が設定されている必要がある。サフィックスのデータベースの名前は同じである必要がある。
- コピーする Directory Server には o=NetscapeRoot サフィックスを含めることはできない。つまり、Directory Server をAdministration Serverの設定ディレクトリにすることはできない。
- 各サーバーでは、同じサフィックスがレプリカとして設定されている必要があり、両方のサーバーでレプリカに同じ役割 (マスター、ハブ、コンシューマ) が設定されている必要がある。部分レプリケーションが設定されている場合は、すべてのマスターサーバーが同じように設定されている必要がある。
- どちらのサーバーでも、属性の暗号化を使用していてはならない。
バイナリ復元機能によるデータの復元については、『Directory Server 管理ガイド』の「バイナリコピーによるレプリカの初期化」を参照してください。
互いに連携するマシンの各セット (上で定義した同じ設定を持つマシン) で、少なくとも定期的にバイナリバックアップを行う必要があります。
この章に示される図で使用される略語の意味は次のとおりです。
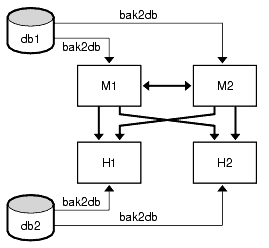
図 9-1 は、M1 と M2 が同じ設定を持ち、H1 と H2 が同じ設定を持つことを前提としています。この例では、M1 と H1 でバイナリバックアップが行われます。障害が発生した場合、いずれかのマスターを M1 (db1) のバイナリバックアップから復元し、いずれかのハブを H1 (db2) のバイナリバックアップから復元することができます。H1 のバイナリバックアップからマスターを復元したり、M1 のバイナリバックアップからハブを復元することはできません。
図 9-1 バイナリバックアップ
LDIF (db2ldif) へのバックアップ
LDIF へのバックアップはサフィックスレベルで行われます。db2ldif の出力は、フォーマットされた LDIF ファイルです。このため、このプロセスはバイナリバックアップと比較して時間がかかります。
注
db2ldif の実行時に -r オプションを指定しない限り、レプリケーション情報はバックアップされません。
LDIF へのバックアップでは、dse.ldif 設定ファイルはバックアップされません。失われた設定情報を復元するには、このファイルを手動でバックアップする必要があります。
LDIF へのバックアップには、次のような利点があります。
LDIF へのバックアップには、次のような制約があります。
トポロジの単一マスターで、レプリケートされた各サフィックスを LDIF に定期的にバックアップしてください。
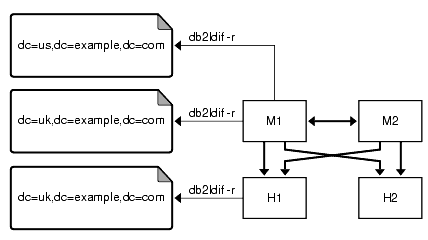
次の図では、M1 だけ、または M1 と H1 のレプリケートされた各サフィックスに対して db2ldif -r を実行しています。
図 9-2 db2ldif -r によるバックアップ
復元方法の選択
Directory Server では、バイナリ復元 (bak2db) と、LDIF ファイルからの復元 (ldif2db) という 2 つの方法でデータを復元できます。すでに説明したバックアップ方法と同様に、どちらの方法にも利点と制限があります。
バイナリ復元 (bak2db)
バイナリ復元では、データベースレベルでデータがコピーされます。このため、バイナリ復元によるデータの復元には、次のような利点があります。
バイナリ復元によるデータの復元には、次のような制約があります。
- 復元は、同じ設定を持つサーバー (「バイナリバックアップ (db2bak)」を参照) だけで実行できる。バイナリ復元機能によるデータの復元については、『Directory Server 管理ガイド』の「バイナリコピーによるレプリカの初期化」を参照してください。
- バイナリバックアップではデータベースの同一コピーが作成されるため、データベースが破損していることに気付かずにバイナリバックアップを行った場合、破損したデータベースが復元される危険性がある。
マシンの設定が同一であり、実行時間に特に考慮が必要な場合、推奨される復元方法はバイナリ復元になります。
図 9-3 は、M1 と M2 が同じ設定を持ち、H1 と H2 が同じ設定を持つことを前提としています。この例では、いずれかのマスターを M1 (db1) のバイナリバックアップから復元し、いずれかのハブを H1 (db2) のバイナリバックアップから復元することができます。
図 9-3 バイナリ復元
LDIF からの復元 (ldif2db)
LDIF ファイルからの復元は、サフィックスレベルで行われます。このため、このプロセスはバイナリ復元と比較して時間がかかります。LDIF ファイルからの復元には、次のような利点があります。
LDIF ファイルからの復元には、次のような制限があります。
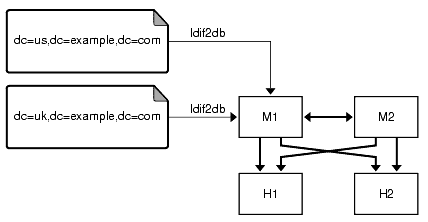
次の図では、M1 だけ、または M1 と H1 のレプリケートされた各サフィックスに対して ldif2db を実行しています。
図 9-4 ldif2db による復元
レプリケーショントポロジの例レプリケーショントポロジは、企業の規模と、データセンターの物理的な場所によって決定されます。このため、ここで紹介するレプリケーショントポロジの例は、企業がディレクトリを維持するデータセンター (サイト) の数によって分けられています。
ディレクトリを最初に配備するときは、エントリの現在の数と、ディレクトリへの読み取りおよび書き込み操作の現在のボリュームに基づいて配備を行います。エントリ数が増えると、読み取りパフォーマンス向上のためにディレクトリのスケーリングが必要になる場合があります。それぞれの企業に合わせたスケーラビリティが提案されます。
これらのトポロジは、1 つのコンポーネントで障害が発生した場合にも、迅速な人的対応なしでサービスを提供し続けることを目的としています。1 つまたは 2 つのデータセンターで、読み取りと書き込みのフェイルオーバーもローカルに行われます。
1 つのデータセンター
1 つのデータセンターのトポロジには、ディレクトリの想定パフォーマンス要件が大きく影響します。提案される基本的なトポロジでは、読み取りと書き込みの操作を処理するために、少なくとも 2 つのサーバーの動作が保証される配備が想定されています。2 つのマスターによって、高可用性ソリューションも提供されます。
1 つのデータセンターの基本トポロジ
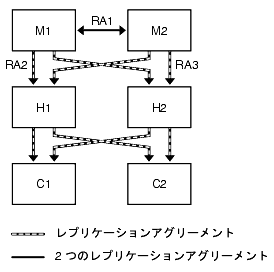
図 9-5 に示されるトポロジは、読み取りと書き込みのパフォーマンスのために 2 つのマスターを持つ 1 つのデータセンターを示しています。この基本例では、クライアントはいずれかのマスターに書き込みを行い、いずれかのマスターから読み取りを行います。
図 9-5 1 つのデータセンター: 基本トポロジ
読み取りパフォーマンスのための 1 つのデータセンターのスケーリング
図 9-6 に示されるように、ハブとコンシューマを追加することで、読み取りパフォーマンスが向上します。第 3 レベルのコンシューマを簡単に追加できるように、まず、マスターの下にハブを追加します。第 2 レベルのサーバーをハブとして設定することで、マシンを再設定する必要なく、その下にコンシューマを追加できます。
図 9-6 読み取りパフォーマンスのための 1 つのデータセンターのスケーリング
1 つのデータセンターの障害マトリックス
図 9-6 の例では、「障害と復元について」に示されるいずれかの原因により、さまざまなコンポーネントが使用不可能になる可能性があります。表 9-1 は、これらの障害と、それに対応する復元処理を示しています。
1 つのデータセンターの復元手順 (1 つのコンポーネント)
2 つのマスターを持つ 1 つのデータセンターでは、1 つのマスターで障害が発生しても読み取りと書き込みの機能は維持されます。ここでは、障害が発生したコンポーネントの復元に適用できる復元戦略の例について説明します。
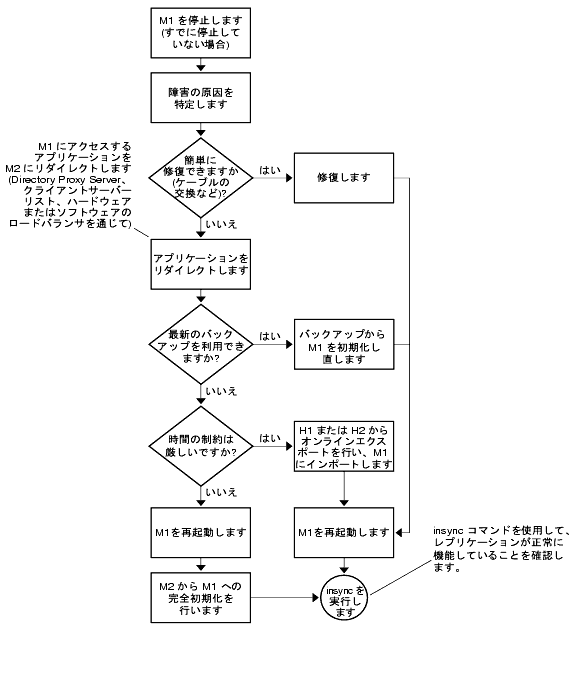
図 9-7 のフローチャートとその後の手順は、1 つのマスター (M1) で障害が発生したことを前提としています。
図 9-7 1 つのデータセンターの復元手順を示すフローチャート (1 つのコンポーネント)
- M1 を停止します (すでに停止していない場合)。
- 障害の原因を特定します。たとえばネットワークケーブルの交換などによって簡単に修復できる場合は、修復します。
- 問題がより重大で修復に時間がかかる場合は、M1 にアクセスするアプリケーションが、Sun Java System Directory Proxy Server、クライアントサービスリスト、ハードウェアまたはソフトウェアのロードバランサを通じて M2 にリダイレクトされることを確認します。
- 最新のバックアップがあれば、バックアップから M1 を初期化し直します。
- 最新のバックアップを利用できない場合は、M1 を再起動し、M2 から M1 への完全初期化を行います。詳細な手順については、『Directory Server 管理ガイド』の「オンラインでのレプリカ初期化の実行」を参照してください。
- 最新のバックアップを利用できず、完全初期化を行う時間もない場合は、H1 または H2 からオンラインエクスポートを行い、M1 に ldif2db でインポートします。
- M1 を起動します (すでに起動していない場合)。
- M1 のモードが読み取り専用モードであれば、読み書き有効モードに設定します。
- insync コマンドを使用して、レプリケーションが正常に機能していることを確認します。詳細は、『Directory Server Man Page Reference』を参照してください。
1 つのデータセンターの復元手順 (2 つのコンポーネント)
この例で 2 つのマスターに障害が発生した場合、書き込み機能は失われます。障害が重大で修復に時間がかかる場合は、できるだけ早急に書き込み機能を提供するための戦略を実装する必要があります。
次の手順は、M1 と M2 の両方に障害が発生し、すぐには復元できない状況を前提としています。もっとも迅速で、できるだけ簡単な復元方法を考える必要があります。この手順では、もっとも簡単な方法の例として、サーバーの昇格を紹介します。
2 つのデータセンター
複数のサイトでデータが共有される場合は、パフォーマンスとフェイルオーバーの両方の面で効果的なレプリケーショントポロジが欠かせません。
2 つのデータセンターの基本トポロジ
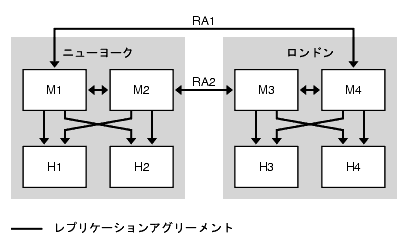
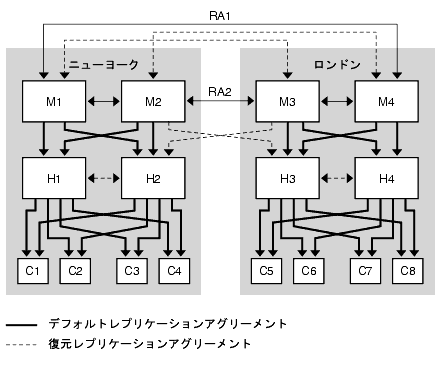
図 9-8 に示されるトポロジは、最適な読み取り、書き込みパフォーマンスのために、各データセンターが 2 つのマスターと 2 つのハブを持つことを前提としています。第 2 レベルのサーバーをハブとして設定することで、マシンを再設定する必要なく、その下にコンシューマを追加できます。
この例では、レプリケーションアグリーメント RA1 と RA2 を異なるネットワーク経由で設定しています。この設定であれば、いずれかのネットワークリンクが使用不可能になったり、信頼できなくなった場合でも、データセンター間のレプリケーションを行えます。
図 9-8 2 つのデータセンターの基本トポロジ
読み取りパフォーマンスのための 2 つのデータセンターのスケーリング
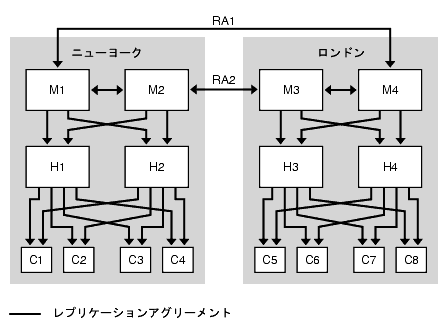
図 9-6 に示される 1 つのデータセンターの例のように、ハブとコンシューマを追加することで読み取りパフォーマンスを向上させることができます。
この例では、レプリケーションアグリーメント RA1 と RA2 を異なるネットワーク経由で設定しています。この設定であれば、いずれかのネットワークリンクが使用不可能になったり、信頼できなくなった場合でも、データセンター間のレプリケーションを行えます。
図 9-9 読み取りパフォーマンスのための 2 つのデータセンターのスケーリング
2 つのデータセンターの復元例
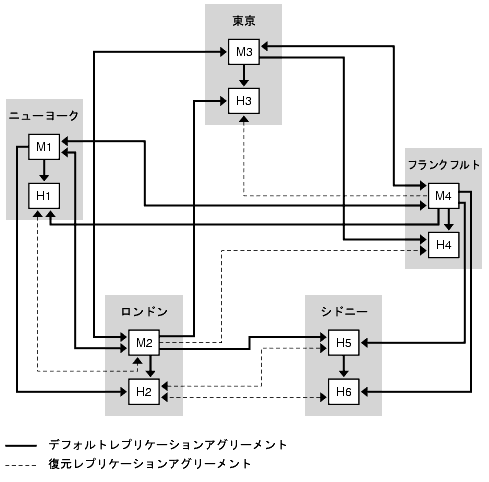
図 9-9 に示される配備では、1 つのマスターで障害が発生した場合に、1 つのデータセンターに適用した復元戦略をそのまま適用できます。いずれかのデータセンターの 1 つのデータセンターが使用不可能な状態になった場合でも、M1 と M4 の間、および M2 と M3 の間のレプリケーションアグリーメントにより、どちらのデータセンターもレプリケートされた更新を受け取り続けることができます。
しかし、複数のマスターで障害が発生した場合は、高度な復元戦略が必要となります。これには、復元アプリケーションアグリーメントの作成が関連します。このアグリーメントは、デフォルトでは無効化されていますが、障害が発生した場合には迅速に有効化できます。
図 9-10 は、この復元戦略を示しています。
図 9-10 2 つのデータセンターの復元レプリケーションアグリーメント
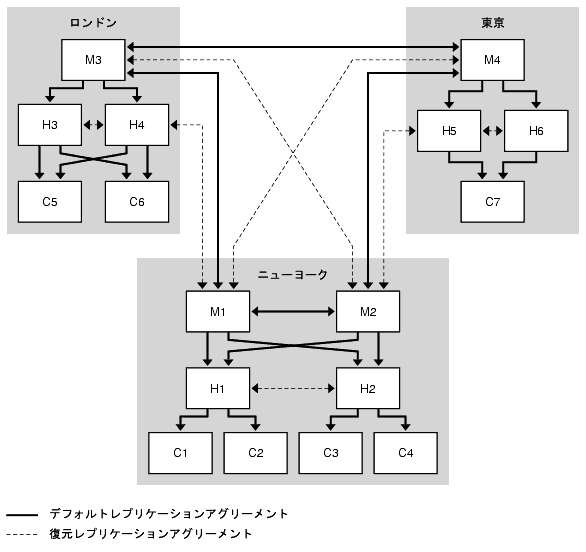
適用される復元戦略は、どのような組み合わせでコンポーネントに障害が発生するかによって異なります。しかし、複数の障害に対する基本的な戦略を準備しておけば、その他のコンポーネントに障害が発生した場合にもそれを適用できます。
図 9-10 のトポロジ例は、ニューヨークデータセンターの両方のマスターに障害が発生したことを前提としています。この場合の復元戦略は、次のようになります。
- M3 と H2 の間の復元レプリケーションアグリーメントを有効化します。
これにより、ロンドンサイトへのリモート書き込みが、引き続きニューヨークサイトにレプリケートされます。
- H2 を書き込み可能なマスターに昇格させます。具体的な手順については、『Directory Server 管理ガイド』の「レプリカの昇格と降格」を参照してください。
これにより、ニューヨークサイトでの書き込み機能が維持されます。
- 新たに昇格したマスター (それまでの H2) と M3 の間にレプリケーションアグリーメントを作成します。
これにより、ニューヨークサイトへのリモート書き込みが、引き続きロンドンサイトにレプリケートされます。
- H2 と H1 の間の復元レプリケーションアグリーメントを有効化します (1 方向のみ)。
これにより、H1 は、引き続きレプリケーショントポロジ全体からの更新を受け取ることができます。
3 つのデータセンター
Directory Server 5.2 は、4 方向のマルチマスターレプリケーションをサポートしています。地理的に離れた 3 つの拠点にまたがる企業では、それぞれの地域で 2 つのマスターを持つ 1 つのデータセンターが必要になる可能性があります。このディレクトリの機能をどのように分割するかは、各データセンターで行われる読み取りおよび書き込み操作の相対的なトラフィックボリューム (など) によって異なります。
3 つのデータセンターの基本トポロジ
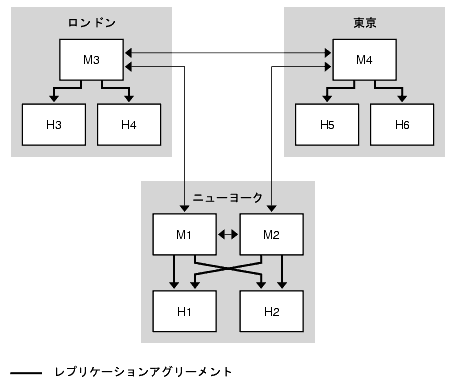
図 9-11 に示されるトポロジは、ニューヨークのデータセンターに対する読み取り、書き込み要求の数が最大で、3 つのデータセンターのそれぞれでローカルな読み取り、書き込み要求が可能であることを前提としています。
図 9-11 3 つのデータセンターの基本トポロジ
読み取りパフォーマンスのための 3 つのデータセンターのスケーリング
これまでの例のように、ハブとコンシューマを追加することで読み取りパフォーマンスを向上させることができます。ただし、それぞれのデータセンターでの想定パフォーマンス要件を考慮する必要があります。図 9-12 は、このトポロジを示しています。
図 9-12 読み取りパフォーマンスのための 3 つのデータセンターのスケーリング
3 つのデータセンターの復元例
2 つのデータセンターの場合と同様に、複数のマスターに障害が発生した場合の復元戦略には、復元レプリケーションアグリーメントの作成が必要となります。図 9-13 に示されるように、これらのアグリーメントは、デフォルトでは無効化されていますが、障害が発生した場合には迅速に有効化できます。
図 9-13 3 つのデータセンターの復元レプリケーションアグリーメント
3 つのデータセンターの復元手順 (1 つのコンポーネント)
図 9-13 の例で、ロンドンまたは東京のマスターに障害が発生し、ローカル書き込み機能が失われたと仮定します。次の手順は、M3 (ロンドン) で障害が発生したことを前提としています。
5 つのデータセンター
Directory Server 5.2 は、4 方向のマルチマスターレプリケーションをサポートしています。地理的に離れた 5 つの拠点にまたがる企業では、どの地域のローカル更新パフォーマンス要件が最小であるかを考慮する必要があります。この地域にはマスターサーバーを置かず、書き込みをいずれかの地域のマスターにリダイレクトします。
5 つのデータセンターの基本トポロジ
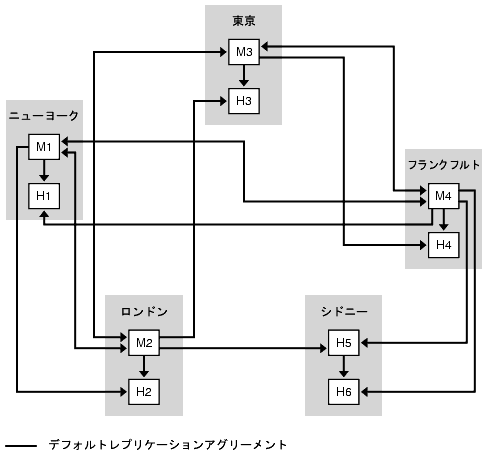
図 9-14 に示されるトポロジは、シドニーデータセンターがもっとも少ない書き込み要求を受け取ることを前提としています。ローカル読み取り要求は、5 つのそれぞれのデータセンターで可能です。
図 9-14 5 つのデータセンターの基本トポロジ
読み取りパフォーマンスのための 5 つのデータセンターのスケーリング
これまでの例のように、ハブとコンシューマを追加することで読み取りパフォーマンスを向上させることができます。ただし、それぞれのデータセンターでの想定パフォーマンス要件を考慮する必要があります。
5 つのデータセンターの復元例
2 つのデータセンターの場合と同様に、複数のマスターに障害が発生した場合の復元戦略には、復元レプリケーションアグリーメントの作成が必要となります。図 9-15 に示されるように、これらのアグリーメントは、デフォルトでは無効化されていますが、障害が発生した場合には迅速に有効化できます。
5 つのデータセンターの復元手順 (1 つのコンポーネント)
図 9-15 の例で、いずれかのマスターに障害が発生し、ローカル書き込み機能が失われたと仮定します。次の手順は、M1 (ニューヨーク) で障害が発生したことを前提としています。
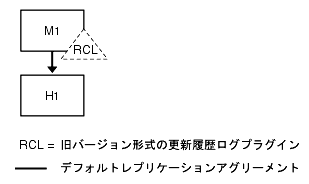
旧バージョン対応更新履歴ログプラグインを使用する 1 つのデータセンター
すでに説明した 1 つのデータセンターのトポロジは、旧バージョン形式の更新履歴プラグインの使用を考慮していませんでした。旧バージョン形式の更新履歴に依存するほとんどのアプリケーションは、更新が順序よくリストされていることを前提としており、マルチマスターレプリケーションモデルの旧バージョン形式の更新履歴で一貫性が失われることによって失敗してしまいます。一般に、配備するアプリケーションが旧バージョン形式の更新履歴を必要とする場合は、その配備ではマルチマスターレプリケーショントポロジを採用するべきではありません。詳細は、「レプリケーションと旧バージョン対応更新履歴ログプラグイン」および『Directory Server 管理ガイド』の「旧バージョン形式の変更履歴ログプラグインの使用」を参照してください。
旧バージョン対応更新履歴ログプラグインの基本トポロジ
マルチマスターレプリケーションを配備できない場合は、図 9-16 に示される基本トポロジが推奨されます。
図 9-16 旧バージョン対応更新履歴ログプラグインを使用する 1 つのデータセンター
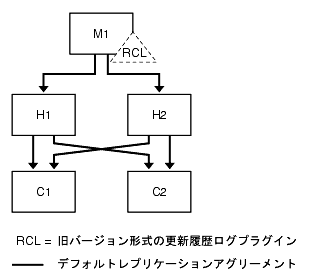
読み取りパフォーマンスのための旧バージョン対応更新履歴ログプラグインのスケーリング
1 つのデータセンターのトポロジと同様に、図 9-17 に示されるように、ハブとコンシューマを追加することで読み取りパフォーマンスを向上させることができます。
図 9-17 旧バージョン対応更新履歴ログプラグインを使用する 1 つのデータセンター (スケーリング)
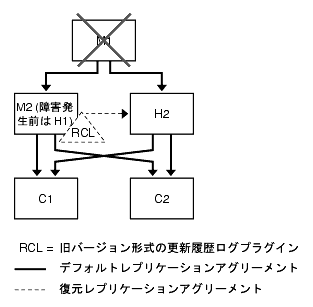
旧バージョン対応更新履歴ログプラグインの復元手順
図 9-17 に示される配備では、マスターサーバーに障害が発生した場合に次の戦略を適用できます。
- M1 を停止します (すでに停止していない場合)。
- H1 または H2 をマスターサーバーに昇格させます。具体的な手順については、『Directory Server 管理ガイド』の「レプリカの昇格と降格」を参照してください。
- 新しいマスター (M2) で旧バージョン対応更新履歴ログプラグインを有効化します。
- 旧バージョン対応更新履歴ログのバックアップを M2 に復元します。
- サーバーを再起動します。
- 変更がハブにレプリケートされ続けるように、M2 と残りのハブの間に新しいレプリケーションアグリーメントを追加します。
図 9-18 は、この復元戦略を示しています。
図 9-18 旧バージョン対応更新履歴ログプラグインを使用する 1 つのデータセンター (復元)