|
| |
| Sun Java System Message Queue 3 2005Q1 Developer's Guide for Java Clients | |
Chapter 3
Message Queue Clients: Design and FeaturesThis chapter addresses architectural and configuration issues that depend upon Message Queue’s implementation of the Java Message Specification. It covers the following topics:
Client Design ConsiderationsThe choices you make in designing a JMS client relate to portability, to allocating work between connections and sessions, to reliability and performance, to resource use, and to ease of administration. This section discusses basic issues that you need to address in client design. It covers the following topics:
Developing Portable Clients
The Java Messaging Specification was developed to abstract access to message-oriented middleware systems (MOMs). A client that writes JMS code should be portable to any provider that implements this specification. If code portability is important to you, be sure that you do the following in developing clients:
Administered objects encapsulate provider-specific implementation and configuration information. Besides allowing for portability, administered objects also make it much easier to share connection factories between applications and to tune a JMS application for performance and resource use. So, even if portability is not important to you, you might still want to leave the work of creating and configuring these objects to an administrator. See Chapter 2 for more information.
Choosing Programming Domains
As described in the Message Queue Technical Overview, JMS supports two distinct message delivery models: point-to-point and publish/subscribe. These two message delivery models can be handled using different API objects—with slightly different semantics—representing different programming domains, as shown in Table 3-1, or they can be handled by base (unified domain) types.
Table 3-1 JMS Programming Objects
Unified Domain
Point-to-Point Domain
Publish/Subscribe Domain
Destination (Queue or Topic)1
Queue
Topic
ConnectionFactory
QueueConnectionFactory
TopicConnectionFactory
Connection
QueueConnection
TopicConnection
Session
QueueSession
TopicSession
MessageProducer
QueueSender
TopicPublisher
MessageConsumer
QueueReceiver
TopicSubscriber
1Depending on programming approach, you might specify a particular destination type.
Using the point-to-point or publish/subscribe domains offers the advantage of a clean API that prevents certain types of programming errors; for example, creating a durable subscriber for a queue destination. However, the non-unified domains have the disadvantage that you cannot combine point-to-point and publish/subscribe operations in the same transaction or in the same session. If you need to do that, you should choose the unified domain API.
The JMS 1.1 specification continues to support the separate JMS 1.02 programming domains. (The example applications included with the Message Queue product as well as the code examples provided in this book all use the separate JMS 1.02 programming domains.) You can choose the API that best suits your needs. The only exception are those developers needing to write clients for the Sun Java System Application Server 7 environment, as explained in the following note.
Connections and Sessions
A connection is a relatively heavy-weight object because of the authentication and communication setup that must be done when a connection is created. For this reason, it’s a good idea to use as few connections as possible. The real allocation of work occurs in sessions, which are light-weight, single-threaded contexts for producing and consuming messages. When you are thinking about structuring your client, it is best to think of the work that is done at the session level.
A session
- Is a factory for its message producers and consumers.
- Supplies provider-optimized message factories.
- Supports a single series of transactions that combine work spanning its producers and consumers into atomic units.
- Defines a serial order for the messages it consumes and the messages it produces.
- Retains messages until they have been acknowledged.
- Serializes execution of message listeners registered with its message consumers.
The requirement that sessions be operated on by a single thread at a time places some restrictions on the combination of producers and consumers that can use the same session. In particular, if a session has an asynchronous consumer, it may not have any other synchronous consumers. For a discussion of the connection and session’s use of threads, see Managing Client Threads. With the exception of these restrictions, let the needs of your application determine the number of sessions, producers, and consumers.
Producers and Consumers
Aside from the reliability your client requires, the design decisions that relate to producers and consumers include the following:
There are some interesting permutations here. There are times when you would want to use publish/subscribe even when you have only one subscriber. On the other hand, performance considerations might make the point-to-point model more efficient than the publish/subscribe model, when the work of sorting messages between subscribers is too costly. Sometimes You cannot make these decisions cannot in the abstract, but must actually develop and test different prototypes.
Let the administrator know how to set the ping interval, so that your client gets an exception if the connection should fail. For more information see Using the Client Runtime Ping Feature.
You might need to allow a small time interval between connecting and calling the receiveNoWait() method in order not to miss a pending message. For more information, see Synchronous Consumption in Distributed Applications.
Benefits vary with the size and format of messages, the number of consumers, network bandwidth, and CPU performance; and benefits are not guaranteed. For a more detailed discussion, see Message Compression.
Assigning Client Identifiers
A connection can have a client identifier. This identifier is used to associate a JMS client’s connection to a message service, with state information maintained by the message service for that client. The JMS provider must ensure that a client identifier is unique, and applies to only one connection at a time. Currently, client identifiers are used to maintain state for durable subscribers. In defining a client identifier, you can use a special variable substitution syntax that allows multiple connections to be created from a single ConnectionFactory object using different user name parameters to generate unique client identifiers. These connections can be used by multiple durable subscribers without naming conflicts or lack of security.
Message Queue allows client identifiers to be set in one of two ways:
- Programmatically: You use the setClientID method of the Connection object. If you use this method, you must set the client id before you use the connection. Once the connection is used, the client identifier cannot be set or reset.
- Administratively: The administrator specifies the client ID when creating the connection factory administrative object.
For more information about client identifiers and how these work with client authentication, see the Message Queue Administration Guide.
Message Order and Priority
In general, all messages sent to a destination by a single session are guaranteed to be delivered to a consumer in the order they were sent. However, if they are assigned different priorities, a messaging system will attempt to deliver higher priority messages first.
Beyond this, the ordering of messages consumed by a client can have only a rough relationship to the order in which they were produced. This is because the delivery of messages to a number of destinations and the delivery from those destinations can depend on a number of issues that affect timing, such as the order in which the messages are sent, the sessions from which they are sent, whether the messages are persistent, the lifetime of the messages, the priority of the messages, the message delivery policy of queue destinations (see the Message Queue Administration Guide), and message service availability.
Using Selectors Efficiently
The use of selectors can have a significant impact on the performance of your application. It's difficult to put an exact cost on the expense of using selectors since it varies with the complexity of the selector expression, but the more you can do to eliminate or simplify selectors the better.
One way to eliminate (or simplify) selectors is to use multiple destinations to sort messages. This has the additional benefit of spreading the message load over more than one producer, which can improve the scalability of your application. For those cases when it is not possible to do that, here are some techniques that you can use to improve the performance of your application when using selectors:
- Have consumers share selectors. As of version 3.5 of Message Queue, message consumers with identical selectors “share” that selector in imqbrokerd which can significantly improve performance. So if there is a way to structure your application to have some selector sharing, consider doing so.
- Use IN instead of multiple string comparisons. For example, the following expression:
color IN ('red', 'green', 'white')
Balancing Reliability and Performance
Reliable messaging is implemented in a variety of ways: through the use of persistent messages, acknowledgements or transactions, durable subscriptions, and connection failover.
In general, the more reliable the delivery of messages, the more overhead and bandwidth are required to achieve it. The trade-off between reliability and performance is a significant design consideration. You can maximize performance and throughput by choosing to produce and consume non-persistent messages. On the other hand, you can maximize reliability by producing and consuming persistent messages in a transaction using a transacted session. For a detailed discussion of design options and their impact on performance, see Factors Affecting Performance.
Managing Client ThreadsUsing client threads effectively requires that you balance performance, throughput, and resource needs. To do this, you need to understand JMS restrictions on thread usage, what threads Message Queue allocates for itself, and the architecture of your applications. This section addresses these issues and offers some guidelines for managing client threads.
JMS Threading Restrictions
The Java Messaging Specification mandates that a session not be operated on by more than one thread at a time. This leads to the following restrictions:
- A session may not have an asynchronous consumer and a synchronous consumer.
- A session that has an asynchronous consumer can only produce messages from within the onMessage() method (the message listener). The only call that you can make outside the message listener is to close the session.
- A session may include any number of synchronous consumers, any number of producers, and any combination of the two. That is, the single-thread requirement cannot be violated by these combinations. However, performance may suffer.
The system does not enforce the requirement that a session be single threaded. If your client application violates this requirement, you will get a JMSIllegalState exception or unexpected results..
Thread Allocation for Connections
When the Message Queue client runtime creates a connection, it creates two threads: one for consuming messages from the socket, and one to manage the flow of messages for the connection. In addition, the client runtime creates a thread for each client session. Thus, at a minimum, for a connection using one session, three threads are created. For a connection using three sessions, five threads are created, and so on.
Managing threads in a JMS application often involves trade-offs between performance and throughput. Weigh the following considerations when dealing with threading issues.
- When you create several asynchronous message consumers in the same session, messages are delivered serially by the session thread to these consumers. Sharing a session among several message consumers might starve some consumers of messages while inundating other consumers. If the message rate across these consumers is high enough to cause an imbalance, you might want to separate the consumers into different sessions. To determine whether message flow is unbalanced, you can monitor destinations to see the rate of messages coming in. See Chapter 4, "Using the Metrics Monitoring API".
- You can reduce the number of threads allocated to the client application by using fewer connections and fewer sessions. However, doing this might slow your application’s throughput.
- You might be able to use certain JVM runtime options to improve thread memory usage and performance. For example, if you are running on the Solaris platform, you may be able to run with the same number (or more) threads by using the following vm options with the client: Refer to the JDK documentation for details.
Managing Memory and ResourcesThis section describes memory and performance issues that you can manage by increasing JVM heap space and by managing the size of your messages. It covers the following topics:
You can also improve performance by having the administrator set connection factory attributes to meter the message flow over the client-broker connection and to limit the message flow for a consumer. For a detailed explanation, please see the Message Queue Administration Guide.
Managing Memory
A client application running in a JVM needs enough memory to accommodate messages that flow in from the network as well as messages the client creates. If your client gets OutOfMemoryError errors, chances are that not enough memory was provided to handle the size or the number of messages being consumed or produced.
Your client might need more than the default JVM heap space. On most systems, the default is 64 MB but you will need to check the default values for your system.
Consider the following guidelines:
- Evaluate the normal and peak system memory footprints when sizing heap space.
- You can start by doubling the heap size using a command like the following:
java -Xmx128m MyClass
- The best size for the heap space depends on both the operating system and the JDK release. Check the JDK documentation for restrictions.
- The size of the VM’s memory allocation pool must be less than or equal to the amount of virtual memory that is available on the system.
Managing Message Size
In general, for better manageability, you can break large messages into smaller parts, and use sequencing to ensure that the partial messages sent are concatenated properly. You can also use a Message Queue JMS feature to compress the body of a message. This section describes the programming interface that allows you to compress messages and to compare the size of compressed and uncompressed messages.
Message compression and decompression is handled entirely by the client runtime, without involving the broker. Therefore, applications can use this feature with a pervious version of the broker, but they must use version 3.6 or later of the Message Queue client runtime library.
Message Compression
You can use the Message.setBooleanProperty() method to specify that the body of a message be compressed. If the JMS_SUN_COMPRESS property is set to true, the client runtime, will compress the body of the message being sent. This happens after the producer’s send method is called and before the send method returns to the caller. The compressed message is automatically decompressed by the client runtime before the message is delivered to the message consumer.
For example, the following call specifies that a message be compressed:
MyMessage.setBooleanProperty(“JMS_SUN_COMPRESS”,true);
Compression only affects the message body; the message header and properties are not compressed.
Two read-only JMS message properties are set by the client runtime after a message is sent.
Applications can test the properties (JMS_SUN_UNCOMPRESSED_SIZE and JMS_SUN_COMPRESSED_SIZE) after a send returns to determine whether compression is advantageous. That is, applications wanting to use this feature, do not have to explicitly receive a compressed and uncompressed version of the message to determine whether compression is desired.
If the consumer of a compressed message wants to resend the message in an uncompressed form, it should call the Message.clearProperties() to clear the JMS_SUN_COMPRESS property. Otherwise, the message will be compressed before it is sent to its next destination.
Advantages and Limitations of Compression
Although message compression has been added to improve performance, such benefit is not guaranteed. Benefits vary with the size and format of messages, the number of consumers, network bandwidth, and CPU performance. For example, the cost of compression and decompression might be higher than the time saved in sending and receiving a compressed message. This is especially true when sending small messages in a high-speed network. On the other hand, applications that publish large messages to many consumers or who publish in a slow network environment, might improve system performance by compressing messages.
Depending on the message body type, compression may also provide minimal or no benefit. An application client can use the JMS_SUN_UNCOMPRESSED_SIZE and JMS_SUN_COMPRESSED_SIZE properties to determine the benefit of compression for different message types.
Message consumers deployed with client runtime libraries that precede version 3.6 cannot handle compressed messages. Clients wishing to send compressed messages must make sure that consumers are compatible. C clients cannot currently consume compressed messages.
Compression Examples
Code Example 3-1 shows how you set and send a compressed message:
Code Example 3-2 shows how you examine compressed and uncompressed message body size. The bytesMessage was created as in Code Example 3-1:
Code Example 3-2 Comparing Size of Compressed and Uncompressed Messages
//get uncompressed body size
int uncompressed=bytesMessage.getIntProperty(“JMS_SUN_UNCOMPRESSED_SIZE”);
//get compressed body size
int compressed=bytesMessage.getIntProperty(“JMS_SUN_COMPRESSED_SIZE”);
Managing the Dead Message Queue
When a message is deemed undeliverable, it is automatically placed on a special queue called the dead message queue. A message placed on this queue retains all of its original headers (including its original destination) and information is added to the message’s properties to explain why it became a dead message. An administrator or a developer can access this queue, remove a message, and determine why it was placed on the queue.
This section describes the message properties that you can set or examine programmatically to determine the following:
- Whether a dead message can be sent to the dead message queue.
- Whether the broker should log information when a message is destroyed or moved to the dead message queue.
- Whether the body of the message should also be stored when the message is placed on the dead message queue.
- Why the message was placed on the dead message queue and any ancillary information.
Message Queue 3.6 clients can set properties related to the dead message queue on messages and send those messages to clients compiled against earlier versions. However clients receiving such messages cannot examine these properties without recompiling against 3.6 libraries.
The dead message queue is automatically created by the broker and called mq.sys.dmq. You can use the message monitoring API, described in Chapter 4, to determine whether that queue is growing, to examine messages on that queue, and so on.
You can set the properties described in Table 3-2 for any message to control how the broker should handle that message if it deems it to be undeliverable. Note that these message properties are needed only to override destination, or broker-based behavior.
Table 3-2 Message Properties Relating to Dead Message Queue
Property
Type
Description
JMS_SUN_PRESERVE_UNDELIVERED
Boolean
For a dead message, the default value of unset, specifies that the message should be handled as specified by the useDMQ property of the destination to which the message was sent.
A value of true overrides the setting of the useDMQ property and sends the dead message to the dead message queue,.
A value of false overrides the setting of the useDMQ property and prevents the dead message from being placed in the dead message queue.
JMS_SUN_LOG_DEAD_MESSAGES
Boolean
The default value of unset, will behave as specified by the broker configuration property imq.destination.logDeadMsgs.
A value of true overrides the setting of the imq.destination.logDeadMsgs broker property and specifies that the broker should log the action of removing a message or moving it to the dead message queue.
A value of false overrides the setting of the imq.destination.logDeadMsgs broker property and specifies that the broker should not log these actions.
JMS_SUN_TRUNCATE_MSG_BODY
Boolean
The default value of unset, will behave as specified by the broker property imq.destination.DMQ.truncateBody.
A value of true overrides the setting of the imq.destination.DMQ.truncateBody property and specifies that the body of the message should be discarded when the message is placed in the dead message queue.
A value of false overrides the setting of the imq.destination.DMQ.truncateBody property and specifies that the body of the message should be stored along with the message header and properties when the message is placed in the dead message queue.
The properties described in Table 3-3 are set by the broker for a message placed in the dead message queue. You can examine the properties for the message to retrieve information about why the message was placed on the queue and to gather other information about the message and about the context within which this action was taken.
Table 3-3 Dead Message Properties
Property
Type
Description
JMSXDeliveryCount
Integer
Specifies the most number of times the message was delivered to a given consumer. This value is set only for ERROR or UNDELIVERABLE messages.
JMS_SUN_DMQ_UNDELIVERED_TIMESTAMP
Long
Specifies the time (in milliseconds) when the message was placed on the dead message queue.
JMS_SUN_DMQ_UNDELIVERED_REASON
String
Specifies one of the following values to indicate the reason why the message was placed on the dead message queue:
OLDEST
LOW_PRIORITY
EXPIRED
UNDELIVERABLE
ERRORIf the message was marked dead for multiple reasons, for example it was undeliverable and expired, only one reason will be specified by this property.
The ERROR reason indicates that an internal error made it impossible to process the message. This is an extremely unusual condition, and the sender should just resend the message.
JMS_SUN_DMQ_PRODUCING_BROKER
String
For message traffic in broker clusters: specifies the broker name and port number of the broker that placed the message on the dead message queue. A null value indicates that it was the local broker.
JMS_SUN_DMQ_UNDELIVERED_EXCEPTION
String
Specifies the name of the exception (if the message was dead because of an exception) on either the client or the broker.
JMS_SUN_DMQ_UNDELIVERED_COMMENT
String
An optional comment provided when the message is marked dead.
JMS_SUN_DMQ_BODY_TRUNCATED
Boolean
A value of true indicates that the message body was not stored. A value of false indicates that the message body was stored.
Managing Physical Destination Limits
When creating a topic or queue destination, the administrator can specify how the broker should behave when certain memory limits are reached. Specifically, when the number of unconsumed messages reaching a physical destination exceeds the number specified with the maxNumMsgs property or when the total amount of memory allowed for unconsumed messages exceeds the number specified with the maxTotalMsgBytes property, the broker takes one of the following actions, depending on the setting of the limitBehavior property:
If the default value REJECT_NEWEST is specified for the limitBehavior property, the broker throws out the newest messages received when memory limits are exceeded. If the message discarded is a persistent message, the producing client gets an exception which should be handled by resending the message later.
If any of the other values is selected for the limitBehavior property or if the message is not persistent, the application client is not notified if a message is discarded. Application clients should let the administrator know how they prefer this property to be set for best performance and reliability.
Programming Issues for Message ConsumersThis section describes two problems that consumers might need to manage: the undetected loss of a connection, or the loss of a message for distributed synchronous consumers.
Using the Client Runtime Ping Feature
Message Queue defines a connection factory attribute for a ping interval. This attribute specifies the interval at which the client runtime should check the client’s connection to the broker. The ping feature is especially useful to Message Queue clients that exclusively receive messages and might therefore not be aware that the absence of messages is due to a connection failure. This feature could also be useful to producers who don’t send messages frequently and who would want notification that a connection they’re planning to use is not available.
The connection factory attribute used to specify this interval is called imqPingInterval. Its default value is 30 seconds. A value of -1 or 0, specifies that the client runtime should not check the client connection.
Developers should set (or have the administrator set) ping intervals that are slightly more frequent than they need to send or receive messages, to allow time to recover the connection in case the ping discovers a connection failure. Note also that the ping may not occur at the exact time specified by the value you supply for interval; the underlying operating system’s use of i/o buffers may affect the amount of time needed to detect a connection failure and trigger an exception.
A failed ping operation results in a JMSException on the subsequent method call that uses the connection. If an exception listener is registered on the connection, it will be called when a ping operation fails.
Preventing Message Loss for Synchronous Consumers
It is always possible that a message can be lost for synchronous consumers in a session using AUTO_ACKNOWLEDGE mode if the provider fails. To prevent this possibility, you should either use a transacted session or a session in CLIENT_ACKNOWLEDGE mode.
Synchronous Consumption in Distributed Applications
Because distributed applications involve greater processing time, such an application might not behave as expected if it were run locally. For example, calling the receiveNoWait method for a synchronous consumer might return null even when there is a message available to be retrieved.
If a client connects to the broker and immediately calls the receiveNoWait method, it is possible that the message queued for the consuming client is in the process of being transmitted from the broker to the client. The client runtime has no knowledge of what is on the broker, so when it sees that there is no message available on the client’s internal queue, it returns with a null, indicating no message.
You can avoid this problem by having your client do either of the following:
Factors Affecting PerformanceApplication design decisions can have a significant effect on overall messaging performance. The most important factors affecting performance are those that impact the reliability of message delivery; among these are the following:
Other application design factors impacting performance include the following:
The sections that follow describe the impact of each of these factors on messaging performance. As a general rule, there is a trade-off between performance and reliability: factors that increase reliability tend to decrease performance.
Table 3-4 shows how application design factors affect messaging performance. The table shows two scenarios—a high reliability, low performance scenario and a high performance, low reliability scenario—and the choice of application design factors that characterizes each. Between these extremes, there are many choices and trade-offs that affect both reliability and performance.
Table 3-4 Comparison of High Reliability and High Performance Scenarios
Application Design
FactorHigh Reliability
Low Performance ScenarioHigh Performance
Low Reliability ScenarioDelivery mode
Persistent messages
Non-persistent messages
Use of transactions
Transacted sessions
No transactions
Acknowledgement mode
AUTO_ACKNOWLEDGE or CLIENT_ACKNOWLEDGE
DUPS_OK_ACKNOWLEDGE
NO_ACKNOWLEDGE
Durable/non-durable subscriptions
Durable subscriptions
Non-durable subscriptions
Use of selectors
Message filtering
No message filtering
Message size
Small messages
Large messages
Message body type
Complex body types
Simple body types
Note
In the graphs that follow, performance data was generated on a two-CPU, 1002 Mhz, Solaris 8 system, using file-based persistence. The performance test first warmed up the Message Queue broker, allowing the Just-In-Time compiler to optimize the system and the persistent database to be primed.
Once the broker was warmed up, a single producer and a single consumer were created, and messages were produced for 30 seconds. The time required for the consumer to receive all produced messages was recorded, and a throughput rate (messages per second) was calculated. This scenario was repeated for different combinations of the application design factors shown in Table 3-4.
Delivery Mode (Persistent/Non-persistent)
Persistent messages guarantee message delivery in case of message server failure. The broker stores these message in a persistent store until all intended consumers acknowledge they have consumed the message.
Broker processing of persistent messages is slower than for non-persistent messages for the following reasons:
- A broker must reliably store a persistent message so that it will not be lost should the broker fail.
- The broker must confirm receipt of each persistent message it receives. Delivery to the broker is guaranteed once the method producing the message returns without an exception.
- Depending on the client acknowledgment mode, the broker might need to confirm a consuming client’s acknowledgement of a persistent message.
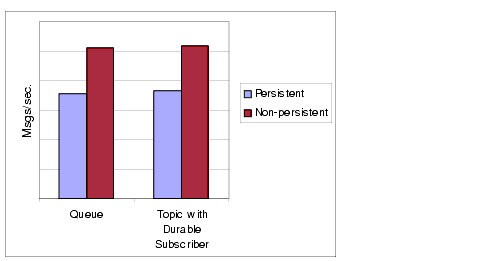
The differences in performance for persistent and non-persistent modes can be significant--about 25% faster for non-persistent messages. Figure 3-1 compares throughput for persistent and non-persistent messages in two reliable delivery cases: 10k-sized messages delivered both to a queue and to a topic with durable subscriptions. Both cases use the AUTO_ACKNOWLEDGE acknowledgement mode.
Figure 3-1 Performance Impact of Delivery Modes
Use of Transactions
A transaction guarantees that all messages produced in a transacted session and all messages consumed in a transacted session will be either processed or not processed (rolled back) as a unit. Message Queue supports both local and distributed transactions.
A message produced or acknowledged in a transacted session is slower than in a non-transacted session for the following reasons:
- Additional information must be stored with each produced message.
- In some situations, messages in a transaction are stored when normally they would not be. For example, a persistent message delivered to a topic destination with no subscriptions would normally be deleted, however, at the time the transaction is begun, information about subscriptions is not available.
- Information on the consumption and acknowledgement of messages within a transaction must be stored and processed when the transaction is committed.
Acknowledgement Mode
Other than using transactions, you can ensure reliable delivery by having the client acknowledge receiving a message. If a session is closed without the client acknowledging the message or if the message server fails before the acknowledgment is processed, the broker redelivers that message, setting a JMSRedelivered flag.
For a non-transacted session, the client can choose one of three acknowledgement modes, each of which has its own performance characteristics:
- AUTO_ACKNOWLEDGE. The system automatically acknowledges a message once the consumer has processed it. This mode guarantees at most one redelivered message after a provider failure.
- CLIENT_ACKNOWLEDGE. The application controls the point at which messages are acknowledged. All messages processed in that session since the previous acknowledgement are acknowledged. If the message server fails while processing a set of acknowledgments, one or more messages in that group might be redelivered.
- DUPS_OK_ACKNOWLEDGE. This mode instructs the system to acknowledge messages in a lazy manner. Multiple messages can be redelivered after a provider failure.
- NO_ACKNOWLEDGE In this mode, the broker considers a message acknowledged as soon as it has been written to the client. The broker does not wait for an acknowledgement from the receiving client. This mode is best used by typic subscribers who are not worried about reliability.
Performance is impacted by acknowledgement mode for the following reasons:
- Extra control messages between broker and client are required in AUTO_ACKNOWLEDGE and CLIENT_ACKNOWLEDGE modes. The additional control messages add processing overhead and can interfere with JMS payload messages, causing processing delays.
- In AUTO_ACKNOWLEDGE and CLIENT_ACKNOWLEDGE modes, the client must wait until the broker confirms that it has processed the client’s acknowledgment before the client can consume more messages. (This broker confirmation guarantees that the broker will not inadvertently redeliver these messages.)
- The Message Queue persistent store must be updated with the acknowledgement information for all persistent messages received by consumers, thereby decreasing performance.
Durable vs. Non-Durable Subscriptions
Subscribers to a topic destination have either durable and non-durable subscriptions. Durable subscriptions provide increased reliability at the cost of slower throughput for the following reasons:
- The Message Queue message server must persistently store the list of messages assigned to each durable subscription so that should a message server fail, the list is available after recovery.
- Persistent messages for durable subscriptions are stored persistently, so that should a message server fail, the messages can still be delivered after recovery, when the corresponding consumer becomes active. By contrast, persistent messages for non-durable subscriptions are not stored persistently (should a message server fail, the corresponding consumer connection is lost and the message would never be delivered).
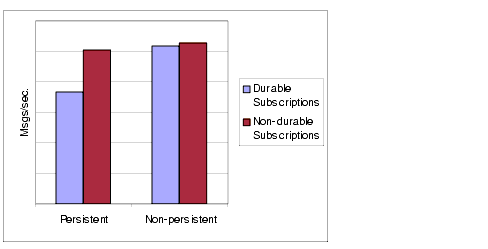
Figure 3-2 compares throughput for topic destinations with durable and non-durable subscriptions in two cases: persistent and non-persistent 10k-sized messages. Both cases use AUTO_ACKNOWLEDGE acknowledgement mode.
You can see from Figure 3-2 that using durable subscriptions affects performance only in the case of persistent messages; this is because persistent messages are only stored persistently for durable subscriptions, as explained above.
Figure 3-2 Performance Impact of Subscription Types
Use of Selectors (Message Filtering)
Application developers can have the messaging provider sort messages according to criteria specified in the message selector associated with a consumer and deliver to that consumer only those messages whose property value matches the message selector. For example, if an application creates a subscriber to the topic WidgetOrders and specifies the expression NumberOfOrders >1000 for the message selector, messages with a NumberOfOrders property value of 1001 or more are delivered to that subscriber.
Creating consumers with selectors lowers performance (as compared to using multiple destinations) because additional processing is required to handle each message. When a selector is used, it must be parsed so that it can be matched against future messages. Additionally, the message properties of each message must be retrieved and compared against the selector as each message is routed. However, using selectors provides more flexibility in a messaging application and may lower resource requirements at the expense of speed.
Message Size
Message size affects performance because more data must be passed from producing client to broker and from broker to consuming client, and because for persistent messages a larger message must be stored.
However, by batching smaller messages into a single message, the routing and processing of individual messages can be minimized, providing an overall performance gain. In this case, information about the state of individual messages is lost.
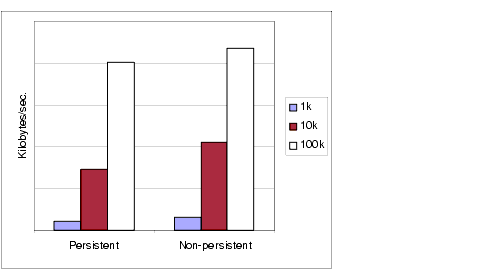
Figure 3-3 compares throughput in kilobytes per second for 1k, 10k, and 100k-sized messages for persistent and non-persistent messages. All messages are sent to a queue destination and use AUTO_ACKNOWLEDGE acknowledgement mode.
Figure 3-3 shows that in both cases there is less overhead in delivering larger messages compared to smaller messages. You can also see that the almost 50% performance gain of non-persistent messages over persistent messages shown for 1k and 10k-sized messages is not maintained for 100k-sized messages, probably because network bandwidth has become the bottleneck in message throughput for that case.
Figure 3-3 Performance Impact of a Message Size
Message Body Type
JMS supports five message body types, shown below roughly in the order of complexity:
While, in general, the message type is dictated by the needs of an application, the more complicated types (MapMessage and ObjectMessage) carry a performance cost—the expense of serializing and deserializing the data. The performance cost depends on how simple or how complicated the data is.
Client Connection Failover (Auto-Reconnect)Message Queue supports client connection failover. A failed connection can be automatically restored not only to the original broker, but to a different broker in a broker cluster. There are circumstances under which the client-side state cannot be restored on any broker during an automatic reconnection attempt; for example, when the client uses transacted sessions or temporary destinations. At such times the auto-reconnect will not take place, and the connection exception handler is called instead. In this case the application code has to catch the exception, reconnect, and restore state.
This section explains how automatic reconnection is enabled, how the broker behaves during a reconnect, how automatic reconnection impacts producers and consumers. Reconnection limitations are also discussed and some examples are provided. For additional information about this feature, please see the Message Queue Administration Guide.
Enabling Auto-Reconnect
The developer or the administrator can enable automatic reconnection by setting the connection factory imqReconnectEnabled attribute to true. The connection factory administered object must also be configured to specify the following:
- A list of message-service addresses (using the imqAddressList attribute). When the client runtime needs to establish or re-establish a connection to a message service, it attempts to connect to the brokers in the list until it finds (or fails to find) an available broker. If you specify only a single broker instance on the imqAddressList attribute, the configuration won’t support recovery from hardware failure.
When you specify more than one broker, you can decide whether to use parallel brokers or a broker cluster. In a parallel configuration, there is no communication between brokers, while in a broker cluster, the brokers interact to distribute message delivery loads. (Refer to the Message Queue Administration Guide for more information on broker clusters.)
- To enable parallel-broker reconnection, set the imqReconnectListBehavior attribute to PRIORITY. Typically, you would specify no more than a pair of brokers for this type of reconnection. This way, the messages are published to one broker, and all clients fail over together from the first broker to the second.
- To enable clustered-broker reconnection, set the imqReconnectListBehavior attribute to RANDOM. This way, the client runtime randomizes connection attempts across the list, and client connections are distributed evenly across the broker cluster.
Each broker in a cluster uses its own separate persistent store (which means that undelivered persistent messages are unavailable until a failed broker is back online). If one broker crashes, its client connections are re-established on other brokers.
- The number of iterations to be made over the list of brokers when attempting to create a connection or to reconnect, using the imqAddressListIterations attribute.
- The number of attempts to reconnect to a broker if the first connection fails, using the imqReconnectAttempts attribute.
- The interval, in milliseconds, between reconnect attempts, using the imqReconnectInterval attribute.
Auto-Reconnect Behaviors
A broker treats an automatic reconnection as it would a new connection. When an original connection is lost, all the resources associated with that connection are released. For example, in a broker cluster, as soon as one broker fails, the other brokers assume that the client connections associated with the failed broker are gone. After auto-reconnect takes place, the client connections are re-created from scratch.
Sometimes the client-side state cannot be fully restored by auto-reconnect. Perhaps a resource that the client needs cannot be re-created. In this case, the client runtime calls the client’s connection exception handler and the client must explicitly reconnect and restore state.
If the client is automatically-reconnected to a different broker instance, persistent messages and other state information held by the failed or disconnected broker can be lost. The messages held by the original broker, once it is restored, might be delivered out of order. This is because broker instances in a cluster do not use a shared, highly available persistent store.
A transacted session is the most reliable method of ensuring that a message isn’t lost if you are careful in coding the transaction. If auto-reconnect happens in the middle of a transaction, then the broker loses the information, the client runtime throws an exception when the transaction is committed, and the transaction is rolled back. At that point, you must make sure that the client restarts the whole transaction. (This is especially important when you use a broker cluster.)
When auto-reconnect happens in a CLIENT_ACKNOWLEDGE session, the client runtime throws a JMSException and the acknowledgement of any set of messages must be rolled back. Therefore, if you get a JMSException message in such a session, call session.recover.
Automatic reconnection affects producers and consumers differently:
- During reconnection, producers cannot send messages. The production of messages (of any operation that involves communication with the message server) is blocked until the connection is re-established.
- For consumers, automatic reconnection is supported for all client acknowledgement modes. After a connection is re-established, the broker will redeliver all unacknowledged messages it had previously delivered, marking them with a Redeliver flag. The client can examine this flag to determine whether any message has already been consumed (but not yet acknowledged). In the case of non-durable subscribers, some messages might be lost because the message server does not hold their messages once their connections have been closed. Any messages produced for non-durable subscribers while the connection is down cannot be delivered when the connections is re-established.
Auto-Reconnect Limitations
Notice the following points when using the auto-reconnect feature:
- Messages might be redelivered to a consumer after auto-reconnect takes place. In an AUTO_ACKNOWLEDGE session, you will get no more than one redelivered message. In other session types, all unacknowledged persistent messages are redlivered.
- While the client runtime is trying to reconnect, any messages sent by the broker to non-durable topic consumers are lost.
- Any messages that are in queue destinations and that are unacknowledged when a connection fails are redelivered after auto-reconnect. However, in the case of queues delivering to multiple consumers, these messages cannot be guaranteed to be redelivered to the original consumers. That is, as soon as a connection fails, an unacknowledged queue message might be rerouted to other connected consumers.
- In the case of a broker cluster, the failure of the master broker has more implications than the failure of other brokers in the cluster. While the master broker is down, the following operations on any other broker do not succeed:
- Creating or destroying a new durable subscription.
- Creating or destroying a new physical destination using the imqcmd create dst command.
- Starting a new broker process. (However, the brokers that are already running continue to function normally even if the master broker goes down.)
You can configure the master broker to restart automatically using Message Queue broker support for rc scripts or the Windows service manager.
- Auto-reconnect doesn’t work if the client uses a ConnectionConsumer to consume messages. In that case, the client runtime throws an exception.
Auto-Reconnect Configuration Examples
The following examples illustrate how to enable each type of auto-reconnect support.
Single-Broker Auto-Reconnect
Configure your connection-factory object as follows:
Code Example 3-3 Example of Command to Configure a Single Broker
imqobjmgr add -t cf -l "cn=myConnectionFactory" \
-o “imqAddressList=mq://jpgserv/jms” \
-o “imqReconnect=true” \
-o “imqReconnectAttempts=10”
This command creates a connection-factory object with a single address in the broker address list. If connection fails, the client runtime will try to reconnect with the broker 10 times. If an attempt to reconnect fails, the client runtime will sleep for three seconds (the default value for the imqReconnectInterval attribute) before trying again. After 10 unsuccessful attempts, the application will receive a JMSException.
You can ensure that the broker starts automatically with at system start-up time. See the Message Queue Installation Guide for information on how to configure automatic broker start-up. For example, on the Solaris platform, you can use /etc/rc.d scripts.
Parallel Broker Auto-Reconnect
Configure your connection-factory objects as follows:
Code Example 3-4 Example of Command to Configure Parallel Brokers
imqobjmgr add -t cf -l "cn=myCF" \
-o "imqAddressList=myhost1, mqtcp://myhost2:12345/jms" \
-o "imqReconnect=true" \
-o "imqReconnectRetries=5"
This command creates a connection factory object with two addresses in the broker list. The first address describes a broker instance running on the host myhost1 with a standard port number (7676). The second address describes a jms connection service running at a statically configured port number (12345).
Clustered-Broker Auto-Reconnect
Configure your connection-factory objects as follows:
Code Example 3-5 Example of Command to Configure a Broker Cluster
imqobjmgr add -t cf -l "cn=myConnectionFactory" \
-o "imqAddressList=mq://myhost1/ssljms, \
mq://myhost2/ssljms, \
mq://myhost3/ssljms, \
mq://myhost4/ssljms” \
-o "imqReconnect=true" \
-o "imqReconnectRetries=5" \
-o "imqAddressListBehavior=RANDOM"
This command creates a connection factory object with four addresses in the imqAddressList. All the addresses point to jms services running on SSL transport on different hosts. Since the imqAddressListBehavior attribute is set to RANDOM, the client connections that are established using this connection factory object will be distributed randomly among the four brokers in the address list.
This is a clustered broker configuration, so you must configure one of the brokers in the cluster as the master broker. In the connection-factory address list, you can also specify a subset of all the brokers in the cluster.
Custom Client AcknowledgmentMessage Queue supports the standard JMS acknowledgement modes (AUTO_ACKNOWLEDGE, CLIENT_ACKNOWLEDGE, and DUPS_OK_ACKNOWLEDGE). When you create a session for a consumer, you can specify one of these modes. Your choice will affect whether acknowledgement is done explicitly (by the client application) or implicitly (by the session) and will also affect performance and reliability. This section describes additional options you can use to customize acknowledgment behavior:
The following sections explain how you program these options.
Using Client Acknowledge Mode
For more flexibility, Message Queue lets you customize the JMS CLIENT_ACKNOWLEDGE mode. In CLIENT_ACKNOWLEDGE mode, the client explicitly acknowledges message consumption by invoking the acknowledge() method of a message object. The standard behavior of this method is to cause the session to acknowledge all messages that have been consumed by any consumer in the session since the last time the method was invoked. (That is, the session acknowledges the current message and all previously unacknowledged messages, regardless of who consumed them.)
In addition to the standard behavior specified by JMS, Message Queue lets you use the CLIENT_ACKNOWLEDGE mode to acknowledge one message at a time.
Observe the following rules when implementing custom client acknowledgement:
- To acknowledge an individual message, call the acknowledgeThisMessage() method. To acknowledge all messages consumed so far, call the acknowledgeUpThroughThisMessage() method. Both are shown in Code Example 3-6.
Code Example 3-6 Syntax for Acknowledge Methods
public interface com.sun.messaging.jms.Message {
void acknowledgeThisMessage() throws JMSException;
void acknowledgeUpThroughThisMessage() throws JMSException;
}
- When you compile the resulting code, include both imq.jar and jms.jar in the classpath.
- Don’t call acknowledge(), acknowledgeThisMessage(), or acknowledgeUpThroughThisMessage() in any session except one that uses the CLIENT_ACKNOWLEDGE mode. Otherwise, the method call is ignored.
- Don’t use custom-acknowledgement in transacted sessions. A transacted session defines a specific way to have messages acknowledged.
If a broker fails, any message that was not acknowledged successfully (that is, any message whose acknowledgement ended in a JMSException) is held by the broker for delivery to subsequent clients.
Code Example 3-7 demonstrates both types of custom client acknowledgement.
Code Example 3-7 Example of Custom Client Acknowledgement Code
...
import javax.jms.*;
... [Look up a connection factory and create a connection.]
Session session = connection.createSession(false,
Session.CLIENT_ACKNOWLEDGE);
... [Create a consumer and receive messages.]
Message message1 = consumer.receive();
Message message2 = consumer.receive();
Message message3 = consumer.receive();
... [Process messages.]
... [Acknowledge one individual message.
Notice that the following acknowledges only message 2.]
((com.sun.messaging.jms.Message)message2).acknowledgeThisMessage();
... [Continue. Receive and process more messages.]
Message message4 = consumer.receive();
Message message5 = consumer.receive();
Message message6 = consumer.receive();
... [Acknowledge all messages up through message 4. Notice that this
acknowledges messages 1, 3, and 4, because message 2 was acknowledged
earlier.]
((com.sun.messaging.jms.Message)message4).
acknowledgeUpThroughThisMessage();
... [Continue. Finally, acknowledge all messages consumed in the session.
Notice that this acknowledges all remaining consumed messages, that is,
messages 5 and 6, because this is the standard behavior of the JMS API.]
message5.acknowledge();
Using No Acknowledge Mode
The NO_ACKNOWLEDGE acknowledgement mode is a non-standard extension to the Java Messaging Specification API(JMS). Normally, the broker waits for a client acknowledgement before considering that a message has been acknowledged and discarding it. That acknowledgement must be made programmatically if the client has specified CLIENT_ACKNOWLEDGE or it can be made automatically, by the session, if the client has specified AUTO_ACKNOWLEDGE or DUPS_OK. If a consuming client specifies the NO_ACKNOWLEDGE mode, the broker discards the message as soon as it has sent it to the consuming client. This feature is intended for use by non-durable subscribers consuming non-persistent messages, but it can be used by any consumer.
Using this feature improves performance by reducing protocol traffic and broker work involved in acknowledging a message. This feature can also improve performance for brokers dealing with misbehaving clients who do not acknowledge messages and therefore tie down broker memory resources unnecessarily. Using this mode has no effect on producers.
You use this feature by specifying NO_ACKNOWLEDGE for the acknowledgeMode parameter to the createSession, createQueueSession, or createTopicSession method. The NO_ACKNOWLEDGE mode must be used only with the connection methods defined in the com.sun.messaging.jms package. Note however that the connection itself must be created using the javax.jms package.
The following are sample variable declarations for connection, queueConnection and topicConnection:
javax.jms.connection Connection;
javax.jms.queueConnection queueConnection
javax.jms.topicConnection topicConnection
The following are sample statements to create different kinds of NO_ACKNOWLEDGE sessions:
//to create a no ack session
Session noAckSession =
((com.sun.messaging.jms.Connection)connection)
.createSession(com.sun.messaging.jms.Session.NO_ACKNOWLEDGE);// to create a no ack topic session
TopicSession noAckTopicSession =
((com.sun.messaging.jms.TopicConnection) topicConnection)
.createTopicSession(com.sun.messaging.jms.Session.NO_ACKNOWLEDGE);//to create a no ack queue session
QueueSession noAckQueueSession =
((com.sun.messaging.jms.QueueConnection) queueConnection)
.createQueueSession(com.sun.messaging.jms.Session.NO_ACKNOWLEDGE);Specifying NO_ACKNOWLEDGE for a session results in the following behaviors:
- The client runtime will throw a JMSException if Session.recover() is called on a NO_ACKNOWLEDGE session.
- The client runtime will ignore a call to the Message.acknowledge() method from a consumer belonging to a session with NO_ACKNOWLEDGE mode set.
- Messages can be lost. As opposed to the DUPS_OK mode, which can result in duplicate messages being sent, this mode bypasses checks and balances built into the system and may result in message loss.
Communicating with C ClientsMessage Queue supports C clients as message producers and consumers.
A Java client consuming messages sent by a C client faces only one restriction: a C client cannot be part of a distributed transaction, and therefore a Java client receiving a message from a C client cannot participate in a distributed transaction either.
A Java client producing messages for a consuming C client must be aware of the following differences in the Java and C interfaces because these differences will affect the C client’s ability to consume messages: C clients