| Exit Print View | |
Sun OpenDS Standard Edition 2.2 Deployment Planning Guide |

|
1. Overview of Sun OpenDS Standard Edition
2. Overview of the Directory Server
3. Overview of the Proxy Server
4. Building Blocks of the Proxy Server
Load Balancing Using the Proxy
Data Distribution Using the Proxy
5. Example Deployments Using the Directory Server
6. Example Deployments Using the Proxy Server
7. Simple Proxy Deployments Using the Command Line Interface
With a distribution using DN pattern algorithm, the Sun OpenDS Standard Edition proxy forwards requests to one of the partitions, based on the match between a request base DN and a string pattern. The match is only perform on the relative part of the request base DN, that is, the part after the distribution base DN. For example, you could split your data into two partitions based on a the DN pattern in the uid of the entries, as illustrated in Figure 4-9.
Distribution using DN pattern is more onerous than distribution with numeric or lexico algorithm. If possible, use either numeric or lexico distribution algorithms.
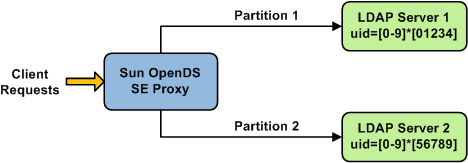
In this example, all the data entries with a uid that ends with 0, 1, 2, 3, or 4 will be sent to Partition 1. Data entries with a uid that ends with 5, 6, 7, 8, or 9 will be sent to Partition 2.
This type of distribution, although using numerical values is quite different from numeric distribution. In numerical distribution, the data is partitioned based on a numerical range, while DN pattern distribution is based on a pattern in the data string.
Distribution using a DN pattern algorithm is typically used in cases where the distribution partitions do not correspond exactly to the distribution base DN. For example, if the data is distributed as illustrated in Figure 4-10, the data for Partition 1 and Partition 2 is in both base DN ou=people,ou=region1 and ou=people,ou=region2. The only way to distribute the data easily is to use the DN pattern.
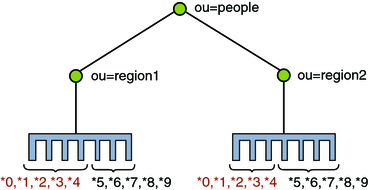
If the deployment of the information is based in two geographical locations, it may be easier to use the DN pattern distribution to distribute the data. For example, if employee numbers were 4 digit codes, where the first digit indicated the region, then you could have the following:
|
In order to spread the load of data, the entries in each location are split over two servers, where Server 1 contains all entries that end with 0, 1, 2, 3, and 4, while Server 2 contains all the entries that end with 5, 6, 7, 8, and 9, as illustrated in Figure 4-9.
Therefore, a search for DN pattern 1222 would be sent to partition 1, as would 2222.


|