| Exit Print View | |
Sun OpenDS Standard Edition 2.2 Deployment Planning Guide |

|
1. Overview of Sun OpenDS Standard Edition
2. Overview of the Directory Server
3. Overview of the Proxy Server
4. Building Blocks of the Proxy Server
5. Example Deployments Using the Directory Server
The Role of Directory Servers in a Topology
The Role of Replication Servers in a Topology
Multiple Data Centers and Replication Groups
Multiple Data Centers and the Window Mechanism
6. Example Deployments Using the Proxy Server
7. Simple Proxy Deployments Using the Command Line Interface
By replicating directory data across servers, you can reduce the access load on a single machine, improving server response time and providing horizontal read scalability. In addition, replication can be used to ensure availability of data in the event of machine failure.
Note that you cannot use replication to scale write operations because a write operation to one directory server results in a write operation to every other server in the topology. The only way to scale write operations horizontally is to split the directory data among multiple databases and place those databases on different servers.
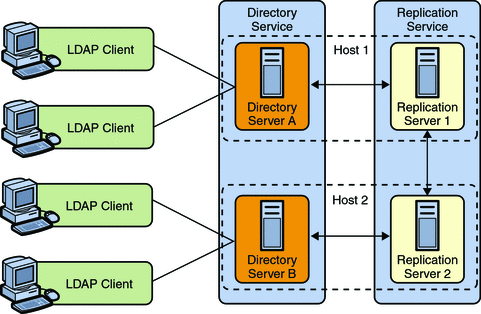
The centralized replication model in Sun OpenDS Standard Edition separates user data from replication metadata. In this model, the server that stores the user data is called the directory server. The server that stores the replication metadata is called the replication server. This approach simplifies the management of replication topologies and can improve performance.
For small deployments, you can set up replication by putting the replication servers and directory servers on the same system. You can further simplify administration by running the replication server and the directory server on each system in a single process.
The following diagram shows how replication is used to ensure availability and to provide read scalability in a small topology.


|