|
| |
| Sun Java System Portal Server 6 2005Q4 管理ガイド | |
第 14 章
検索エンジンロボットの管理Sun JavaTM System Portal Server 検索エンジンロボットと、それに対応する設定ファイルについて説明します。この章で説明する内容は次のとおりです。
検索エンジンロボットの概要検索エンジンロボットは、ドメイン内のリソースを特定し、レポートを作成するエージェントです。これには、列挙子フィルタとジェネレータフィルタの 2 種類のフィルタを使用します。
「列挙子フィルタ」は、ネットワークプロトコルを使用してリソースを検出します。列挙子フィルタは、各リソースをテストし、適切な基準に一致した場合はリソースを列挙します。たとえば、列挙子フィルタは HTML ファイルからハイパーテキストリンクを抽出し、そのリンクを使用して別のリソースを検索できます。
「ジェネレータフィルタ」は各リソースをテストし、リソース記述 (RD) を作成する必要があるかどうかを確認します。リソースがテストに合格した場合、ジェネレータは検索エンジンデータベースに格納される RD を作成します。
ロボットの動作の仕組み
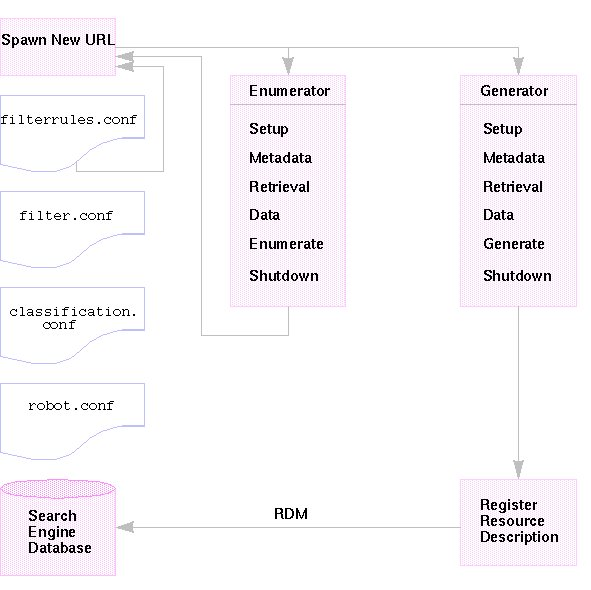
図 14-1 は、検索エンジンロボットの動作の仕組みを示しています。図 14-1 に示されるように、ロボットは URL および関連のあるネットワークリソースを調べます。各リソースは、列挙機能と生成機能の両方によってテストされます。リソースが列挙テストに合格すると、ロボットがそのリソースをほかの URL について検査します。リソースがジェネレータテストに合格すると、ロボットは検索エンジンデータベースに格納されているリソース記述を生成します。
図 14-1 ロボットの動作の仕組み
ロボット設定ファイル
ロボット設定ファイルでは、検索エンジンロボットの動作が定義されます。これらのファイルは、/var/opt/SUNWps/http-hostname-domain/portal/config ディレクトリにあります。表 14-1 は、各ロボット設定ファイルを説明しています。この表には 2 つの列があります。最初の列は設定ファイル、2 番目の列はファイルの内容の説明を示します。
注
検索サービスは、このほかに convert.conf と import.conf の 2 つの設定ファイルを使用します。これらのファイルは検索サーバーにより生成され、一般に手動では編集できません。
検索エンジン管理インタフェースを使用すれば、ほとんどのパラメータを設定できるので、通常は robot.conf ファイルを編集する必要はありません。
ただし、上級ユーザーはこのファイルを手動で編集することにより、インタフェースを介してでは設定できないパラメータを設定することができます。
ロボットプロセスパラメータの設定robot.conf ファイルは、filter.conf にある適切なフィルタにロボットを指定するなど、ロボット用の多くのオプションを定義します (旧バージョンとの下位互換性のために、robot.conf にシード URL を含めることもできる)。
Sun Java System Access Manager 管理コンソールは、robot.conf ファイルを編集するために使用されます。手動で編集できるパラメータについては、「ユーザーが変更できるパラメータ」で詳細に説明します。
もっとも重要なパラメータは、enumeration-filter および generation-filter です。これらのパラメータは、ロボットが列挙および生成で使用するフィルタを指定します。これらのパラメータのデフォルト値は、enumeration-default および generation-default です。フィルタ名は、filter.conf ファイルでデフォルトで提供されます。
フィルタはすべて filter.conf ファイルで定義される必要があります。filter.conf で独自のフィルタを定義する場合、必要なパラメータを robot.conf に追加する必要があります。
たとえば、my-enumerator という名前の新しい列挙フィルタを定義する場合、robot.conf に次のパラメータを追加します。
enumeration-filter=my-enumerator
フィルタリング処理ロボットはフィルタを使用して、処理するリソースとそのリソースの処理方法を決定します。ロボットがリソースと同時にリソースの参照を検出すると、各リソースにフィルタを適用して、それらのリソースを列挙し、検索エンジンデータベースに格納するリソース記述を生成するかどうかを決定します。
ロボットは 1 つあるいは複数のシード URL を調べ、フィルタを適用し、シード URL などを列挙して生成された URL にそのフィルタを適用します。シード URL は filterrules.conf ファイルで定義されます。
フィルタは、必須である初期化操作を実行し、現在のリソースに比較テストを適用します。各テストは、リソースを許可または拒否することが目標です。フィルタにはシャットダウンフェーズも備わっており、必要なクリーンアップ操作を実行します。
リソースが許可されるということは、フィルタ通過の続行が許可されることです。最終的にロボットはそのリソースを列挙し、さらにほかのリソースを検出しようとします。ジェネレータはリソース記述も作成できます。
リソースが否認される場合、そのリソースは拒否されます。拒否されたリソースのフィルタは、それ以上動作しません。
これらの操作は必ずしも連携されていません。リソースには列挙につながるものもあれば、RD 生成につながるものもあります。多くのリソースは列挙にも、RD 生成にもつながります。たとえば、リソースが FTP ディレクトリである場合、一般的にはそのリソース用に RD は生成されません。ただし、ロボットは FTP ディレクトリの個別ファイルを列挙できます。ほかのドキュメントへのリンクを含む HTML ドキュメントは、RD を受信し、また、関連のドキュメントを列挙することもできます。
次の節では、フィルタ処理について詳しく説明します。
フィルタ処理の段階
列挙フィルタ、生成フィルタのどちらにも、フィルタリング処理における 5 つのフェーズがあります。どちらのフィルタにも、共通する 4 つのフェーズがあります。
これらのフェーズは次のとおりです。
- セットアップ: 初期化処理を行います。ロボットが存在する間、一度だけ発生します。
- メタデータ: そのリソースについて利用可能なメタデータに基づき、リソースをフィルタリングします。リソースがネットワークを介して取得される前に、メタデータのフィルタリングがリソースごとに 1 回実行されます。表 14-2 は、共通のメタデータタイプの例を示しています。この表では 2 つの列があります。最初の列はメタデータのタイプ、2 番目の列は説明、3 番目の列は例を示します。
- データ: リソースのデータに基づいてリソースをフィルタリングします。データのフィルタリングは、ネットワークを介して取得されたあとにリソースごとに 1 回実行されます。フィルタリングに使用できるデータには、次のものがあります。
- 列挙: 検査すべきほかのリソースを参照するかどうかを判断するため、現行のリソース中の参照を列挙します。
- 生成: リソースのリソース記述 (RD) を生成し、検索エンジンデータベースにその RD を保存します。
- シャットダウン: 必要な終了操作を実行します。ロボットが存在する間、一度だけ発生します。
フィルタの構文
filter.conf ファイルには、列挙フィルタおよび生成フィルタの定義が含まれています。このファイルには、列挙と生成の両方について、複数のフィルタを含むことができます。robot.conf ファイルの enumeration-filter パラメータおよび generation-filter パラメータでフィルタを指定するため、使用するフィルタをロボットが判断できます。
フィルタの定義は、ヘッダー、本文、終了という明確に定義された構造になります。ヘッダーは、フィルタの開始を識別し、たとえば次のように名前を宣言します。
<Filter name="myFilter">
本文は、セットアップ、テスト、列挙または生成、およびシャットダウン中のフィルタの動作を定義する一連の「フィルタディレクティブ」で構成されています。各ディレクティブでは、関数とその関数のパラメータ (該当する場合) を指定します。
終了は </Filter> によって示されます。
コード例 14-1 は、enumeration1 という名のフィルタを示しています。
コード例 14-1 列挙ファイルの構文
フィルタディレクティブ
フィルタディレクティブは、ロボットアプリケーション関数 (RAF) を使用して、操作を実行します。このディレクティブの使用法および実行の流れは、obj.conf ファイルの NSAPI ディレクティブおよびサーバーアプリケーション関数 (SAF) とよく似ています。NSAPI、SAF と同様に、pblocks とも呼ばれるパラメータブロックを使用して、データは格納および送信されます。
6 つのロボットディレクティブ、または RAF クラスが、「フィルタリング処理」に示したフィルタリングのフェーズや操作に対応しています。
各ディレクティブは、独自のロボットアプリケーション関数を持っています。たとえば、Metadata ディレクティブおよび Data ディレクティブではフィルタリング関数、Enumerate ディレクティブでは列挙関数、Generate ディレクティブでは生成関数を使用します。
ロボットアプリケーションの組み込み関数と、独自のロボットアプリケーション関数を記述する手順については、『Sun Java System Portal Server 6 2005Q4 Developer不 Guide』を参照してください。
フィルタの記述または修正
ほとんどの場合、管理コンソールを使用すると、ほとんどのフィルタを作成できます。修正が必要な場合は、filter.conf ファイルおよび filterrules.conf ファイルを変更することができます。これらのファイルはディレクトリ /var/opt/SUNWps/http-hostname-domain/portal に存在します。
ただし、より複雑なパラメータのセットを作成する場合、ロボットが使用する設定ファイルを編集する必要があります。
フィルタの記述または変更の際は、次の点に注意してください。
robot.conf ファイルで変更できるパラメータ、filter.conf ファイルで使用できるロボットアプリケーション関数、および独自のロボットアプリケーション関数の作成方法については、『Sun Java System Portal Server 6 2005Q4 Developer不 Guide』を参照してください。
ユーザーが変更できるパラメータrobot.conf ファイルは、filter.conf にある適切なフィルタにロボットを指定するなど、ロボット用の多くのオプションを定義します。旧バージョンとの下位互換性のために、robot.conf にシード URL を含めることもできます。
管理コンソールを使用すれば、ほとんどのパラメータを設定できるので、通常は robot.conf ファイルを編集する必要はありません。ただし、上級ユーザーはこのファイルを手動で編集して、管理コンソールからは設定できないパラメータを設定できます。このファイルの例については、「robot.conf ファイルの例」を参照してください。
表 14-3 は、robot.conf ファイルでユーザーが変更可能なパラメータを示しています。このテーブルの最初の列はパラメータ、2 番目の列はパラメータの説明、3 番目の列は例を示します。
表 14-3 ユーザーが変更できるパラメータ
パラメータ
説明
例
auto-proxy
ロボットのプロキシ設定を指定します。これは、プロキシサーバー、またはプロキシを自動的に設定する Java スクリプトファイルです。詳細については、『Sun Java System Portal Server 6 2005Q4 管理ガイド』を参照してください。
auto-proxy="http://proxy_server/proxy.pac"
bindir
ロボットがバインドディレクトリを PATH 環境に追加するかどうかを指定します。これは cmd-hook パラメータが指定するプログラムなど、ユーザーがロボットで外部プログラムを実行するための特別な PATH です。
bindir=path
cmd-hook
ロボットが実行を完了するたびに実行される外部完了スクリプトを指定します。これは、コマンド名の完全パスで指定する必要があります。ロボットは /var/opt/SUNWps/ ディレクトリからこのスクリプトを実行します。
デフォルトはありません。
コマンドを実行するには、最低 1 つの RD が登録されている必要があります。
完了スクリプトの記述については、『Sun Java System Portal Server 6 2005Q4 Developer不 Guide』を参照してください。
cmd-hook="command-string"
command-port
管理インタフェースまたはロボットコントロールパネルのような、ほかのプログラムからコマンドを受け入れるために、ロボットが待機するソケットを指定します。
セキュリティー上の理由から、remote-access が yes に設定されていない場合、ロボットはローカルホストからのコマンドだけを受け入れます。
command-port=port_number
connect-timeout
ネットワークが接続要求に応答する最大許容時間を指定します。
デフォルトは 120 秒です。
command-timeout=seconds
convert-timeout
ドキュメント変換に許可される最大時間を指定します。
デフォルトは 600 秒です。
convert-timeout=seconds
depth
ロボットが調べるシード URL (開始ポイントとも呼ばれる) からのリンク数を指定します。このパラメータは、深さを指定しないシード URL のデフォルト値を設定します。
デフォルトは 10 です。
マイナス 1 の値 (depth=-1) は、リンクの深さが無限であることを表します。
depth=integer
ロボットを実行するユーザーの電子メールアドレスを指定します。
Web 管理者とサイトでロボットを実行するユーザーとが連絡できるように、電子メールアドレスは HTTP 要求ヘッダーで user-agent とともに送信されます。
デフォルトは user@domain です。
email=user@hostname
enable-ip
作成する各 RD の URL に IP アドレスを生成します。
デフォルトは true です。
enable-ip=[true | yes | false | no]
enable-rdm-probe
サーバーが RDM をサポートするかどうかを確認し、ロボットはこのパラメータを使用して、検出する各サーバーに照会するかどうかを決定します。サーバーが RDM をサポートする場合は、サーバーは独自のリソース記述サーバーの役割を果たすことができるため、ロボットはこのサーバーのリソースを列挙しません。
デフォルトは false です。
enable-rdm-probe=[true | false | yes | no]
enable-robots-txt
ロボットがアクセスする各サイトで、robots.txt ファイルが使用できる場合、このファイルをロボットが検査する必要があるかどうかを指定します。
デフォルトは yes です。
enable-robots-txt=[true | false | yes | no]
engine-concurrent
ロボットが使用する事前作成のスレッド数を指定します。
デフォルトは 10 です。
管理コンソールを使用して、このパラメータを対話形式で設定することはできません。
engine-concurrent=[1..100]
enumeration-filter
リソースを列挙すべきかどうかを確認する場合に、ロボットが使用する列挙フィルタを指定します。値は filter.conf ファイルで定義されるフィルタ名にする必要があります。
デフォルトは enumeration-default です。
管理コンソールを使用して、このパラメータを対話形式で設定することはできません。
enumeration-filter=enumfiltername
generation-filter
リソース用にリソース記述を生成する必要があるかどうかを確認する場合に、ロボットが使用する生成フィルタを指定します。値は filter.conf ファイルで定義されるフィルタ名にする必要があります。
デフォルトは generation-default です。
管理コンソールを使用して、このパラメータを対話形式で設定することはできません。
generation-filter=genfiltername
index-after-ngenerated
検索エンジン用にバッチ処理する前に、ロボットが RD を収集する時間を分単位で指定します。
このパラメータを指定しない場合は 256 分に設定されます。
index-after-ngenerated=30
loglevel
ロギングのレベルを指定します。loglevel の値は次のように指定されます。
デフォルト値は 1 です。
loglevel=[0...100]
max-connections
ロボットが実行できる並行検索の最大数を指定します。
デフォルトは 8 です。
max-connections=[1..100]
max-filesize-kb
ロボットが検索するファイルの最大ファイルサイズを K バイト単位で指定します。
max-filesize-kb=1024
max-memory-per-url / max-memory
各 URL が使用する最大メモリーをバイト単位で指定します。URL がより多くのメモリーを必要とする場合、RD はディスクに保存されます。
デフォルトは 1 です。
管理コンソールを使用して、このパラメータを対話形式で設定することはできません。
max-memory-per-url=n_bytes
max-working
ロボット稼動セットのサイズ、すなわちロボットが一度に処理できる URL の最大数を指定します。
管理コンソールを使用して、このパラメータを対話形式で設定することはできません。
max-working=1024
onCompletion
実行完了後のロボットの動作を決定します。ロボットはアイドルモードになるか、ループバック、再起動、または終了することができます。
デフォルトは idle です。
このパラメータは cmd-hook パラメータとともに使用します。実行後のロボットは、onCompletion アクションの次に、cmd-hook プログラムを実行します。
OnCompletion=[idle | loop | quit]
password
httpd 認証および ftp 接続に使用されるパスワードを指定します。
password=string
referer
Web ページにアクセスする際にロボットを Referer として識別するように設定されている場合、HTTP 要求に送信されるパラメータを指定します。
referer=string
register-user and register-password
検索エンジンデータベースに RD を登録するために使用されるユーザー名を指定します。
このパラメータは、検索エンジン管理インタフェースから対話形式で設定することはできません。
register-user=string
register-password
検索エンジンデータベースに RD を登録するために使用されるパスワードを指定します。
このパラメータは、管理コンソールから対話形式で設定することはできません。
register-password=string
remote-access
ロボットが、リモートホストからのコマンドを受け入れることができるどうかを指定します。
デフォルトは false です。
remote-access=[true | false | yes | no]
robot-state-dir
ロボットが状態を保存するディレクトリを指定します。この作業ディレクトリで、ロボットは収集された RD の数などを記録できます。
robot-state-dir="/var/opt/SUNWps/ instance/portal/robot"
server-delay
同じ Web サイトに次にアクセスするまでの時間間隔を指定します。この時間を指定することで、ロボットが頻繁に同じサイトにアクセスするのを防止できます。
server-delay=delay_in_seconds
site-max-connections
ロボットが任意の 1 つのサイトに対して行う同時接続の最大数を示します。
デフォルトは 2 です。
site-max-connections=[1..100]
smart-host-heuristics
ロボットが正規の DNS ホスト名を巡回するサイトを変更できます。たとえば、www123.siroe.com が www.siroe.com に変更されます。
デフォルトは falseです。
smart-host-heuristics=[true | false]
tmpdir
ロボットが一時ファイルを作成する場所を指定します。
環境変数 TMPDIR を設定する際に、この変数を使用します。
tmpdir=path
user-agent
http-request 内の電子メールアドレスとともにサーバーに送信されるパラメータを指定します。
user-agent=iPlanetRobot/4.0
username
ロボットを実行するユーザーのユーザー名を指定します。これは、httpd 認証および ftp 接続で使用されます。
デフォルトは anonymous です。
username=string
robot.conf ファイルの例ここでは、robot.conf ファイルの例について説明します。この例でコメントが付いたパラメータには、表示されているデフォルト値が適用されます。最初のパラメータである csid は、このファイルを使用する検索エンジンインスタンスを示しています。このパラメータの値は変更しないでください。このファイルのパラメータの定義については、「ユーザーが変更できるパラメータ」を参照してください。
<Process csid="x-catalog://budgie.siroe.com:80/jack" ¥
auto-proxy="http://sesta.varrius.com:80/"
auto_serv="http://sesta.varrius.com:80/"
command-port=21445
convert-timeout=600
depth="-1"
# email="user@domain"
enable-ip=true
enumeration-filter="enumeration-default"
generation-filter="generation-default"
index-after-ngenerated=30
loglevel=2
max-concurrent=8
site-max-concurrent=2
onCompletion=idle
password=boots
proxy-loc=server
proxy-type=auto
robot-state-dir="/var/opt/SUNWps/https-budgie.siroe.com/ ¥
ps/robot"
server-delay=1
smart-host-heuristics=true
tmpdir="/var/opt/SUNWps/https-budgie.siroe.com/ps/tmp"
user-agent="iPlanetRobot/4.0"
username=jack
</Process>