|
| |
| Sun Java System Portal Server 6 2005Q4 管理指南 | |
第 14 章
管理搜尋引擎網頁抓取程式本章說明 Sun Java™ System Portal Server 搜尋引擎網頁抓取程式及對應的配置檔案。將討論下列主題:
搜尋引擎網頁抓取程式簡介搜尋引擎網頁抓取程式是一個在其網域中識別與報告資源的代理程式。使用兩種篩選器可以執行這個作業:列舉篩選器與產生篩選器。
列舉篩選器使用網路通訊協定尋找資源。它會測試每個資源,且若符合適當的準則,會將之列舉。例如,列舉篩選器可以從 HTML 檔案中擷取超文字連結並使用連結找出其他資源。
產生篩選器會測試每個資源以決定是否應建立資源說明 (RD)。若資源通過測試,產生器會建立 RD 並將其儲存在搜尋引擎資料庫中。
網頁抓取程式的作業方式
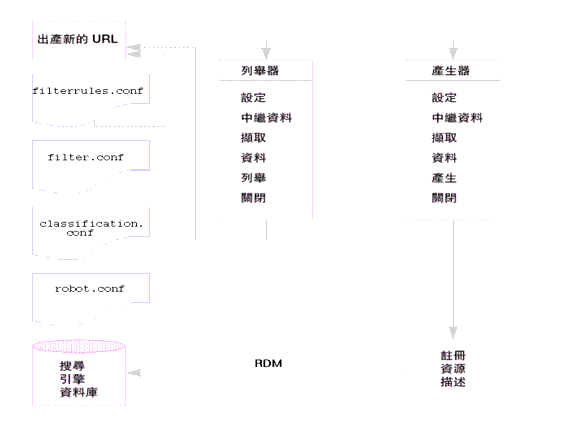
圖 14-1 會說明搜尋引擎網頁抓取程式的作業方式。圖 14-1 中,網頁抓取程式會檢驗 URL 和與其相關的網路資源。每個資源會由列舉器與產生器測試。若資源通過列舉測試,網頁抓取程式會檢查是否還有其他的 URL。若資源通過產生器測試,網頁抓取程式會產生儲存於搜尋引擎資料庫的資源說明。
圖 14-1 網頁抓取程式的作業方式
網頁抓取程式配置檔案
Robot 配置檔案會定義搜尋引擎 網頁抓取程式的運作方式。這些檔案位於 /var/opt/SUNWps/http-hostname-domain/portal/config 目錄中。表 14-1 會提供其中每個網頁抓取程式配置檔案的說明。本表格包括兩欄。第一欄會列出配置檔案,第二欄會說明檔案內容。
因為您可以藉由使用「搜尋引擎管理介面」設定大部分的參數,一般來說不需要編輯 robot.conf 檔案。
然而,進階使用者可以手動編輯此檔案,以設定無法透過介面設定的參數。
設定網頁抓取程式程序參數robot.conf 檔案會定義許多網頁抓取程式的選項,包括將網頁抓取程式指向 filter.conf 中適合的篩選器。(由於較舊版本的向下相容性,robot.conf 也可以包含種子 URL。)
Sun Java System Access Manager 管理主控台會用於編輯 robot.conf 檔案。使用者可修改的參數一節會詳細說明您可以手動編輯的一些參數。
最重要的參數是 enumeration-filter 和 generation-filter。這些參數會決定用於列舉和產生的篩選器和網頁抓取程式。這些參數的預設值為 enumeration-default 與 generation-default,也就是在 filter.conf 檔案中依預設提供的篩選器名稱。
所有篩選器必須定義於 filter.conf 檔案中。若在 filter.conf 檔案中定義您自己的篩選器,您必須將所有必須的參數新增至 robot.conf。
例如,若您定義一個名為 my-enumerator 的新列舉篩選器,則必須新增下列參數至 robot.conf:
enumeration-filter=my-enumerator
篩選程序網頁抓取程式會使用篩選器決定要處理何種資源,與如何處理。當網頁抓取程式發現資源參考與資源本身,會套用篩選器至每個資源以將其列舉並決定是否產生資源說明以儲存至搜尋引擎資料庫中。
網頁抓取程式會檢驗一個或多個種子 URL,套用篩選器然後將篩選器套用至由列舉種子 URL 產生的 URL 等等。種子 URL 定義於 filterrules.conf 檔案中。
篩選器會執行所有要求的初始化作業並套用比較測試至目前資源。每個測試的目標為允許或拒絕資源。篩選器也擁有關閉階段,在此階段將執行所有必要清除作業。
若允許某個資源,則意味允許其繼續通過篩選器。網頁抓取程式最終會列舉該資源,以嘗試進一步探索其他資源。產生器也可能會為其建立資源說明。
若拒絕某個資源,則不會繼續處理該資源。對於被拒絕的資源,篩選器不會採取更進一步的動作。
這些作業不一定會被連結。某些資源會被列舉,其他則會產生 RD。很多資源會同時被列舉與產生 RD。例如,若資源位於 FTP 目錄中,則資源通常不會為其產生 RD。然而,網頁抓取程式可能會在 FTP 目錄中列舉個別的檔案。包含至其他文件連結的 HTML 文件可以接收 RD 也可以導致列舉連結的文件。
下列章節會詳細說明篩選器程序:
篩選器程序的階段
列舉與產生篩選器的篩選程序中都擁有五個階段。他們兩者有四個共用階段:
階段如下所示:
- 設定 — 執行初始化作業。在網頁抓取程式的有效使用期中只會發生一次。
- 中介資料 — 以中介資料為基礎並可用於資源的篩選資源。在從網路上擷取資源之前,每個資源中只會發生一次中介資料篩選。表 14-2 會列出共用中介資料類型的範例。本表格包括三欄。第一欄會列出中介資料類型、第二欄會提供說明,第三欄會提供範例。
- 資料 — 根據其資料篩選資源。在從網路上擷取資源之後,每個資源都會完成一次資料篩選。可用於篩選的資料包括:
- 列舉 — 列舉目前的資源,以決定其是否指向其他要檢查的資源。
- 產生 — 為資源產生資源說明 (RD) 並將之儲存於搜尋引擎資料庫中。
- 關閉 — 執行任何所需的終止作業。在網頁抓取程式的使用有效期中會發生一次。
篩選器語法
filter.conf 檔案包含列舉與產生篩選器的定義。這個檔案可以包含多個用於列舉與產生的篩選器。請注意,網頁抓取程式可以決定使用哪個篩選器,因為其已由 robot.conf 檔案中的 enumeration-filter 與 generation-filter 參數所指定。
篩選器定義擁有一個定義良好的結構:標題、內文與結尾。標題會識別篩選器的開始並公佈其名稱,例如:
<Filter name="myFilter">
此內文由一系列篩選器指令組成,其中定義了篩選器在設定、測試、列舉或產生以及關閉期間的運作方式。每條指令會指定一個功能,且若適用,還會為功能指定參數。
結尾標記符為 </Filter>。
程式碼範例 14-1 會顯示名稱為 enumeration1 的篩選器。
程式碼範例 14-1 列舉檔案語法
篩選器指令
篩選器指令會使用「網頁抓取程式應用程式功能 (RAF)」執行作業。執行的運作與流程與 NSAPI 指令和 obj.conf 檔案的「伺服器應用程式功能 (SAF)」類似。類似 NSAPI 與 SAF,使用參數區段,也稱為 pblocks,儲存與傳送資料。
有六個網頁抓取程式指令或 RAF 類別,對應至列示在篩選程序的篩選階段與作業:
每個指令擁有自己的網頁抓取程式應用程式功能。例如,Metadata 與 Data 指令有篩選功能、Enumerate 指令有列舉功能、Generate 指令有產生功能等等。
內建的網頁抓取程式應用程式功能和撰寫自己網頁抓取程式應用程式功能的指示皆會在「Sun Java System Portal Server 6 2005Q4 開發人員指南」中有所解釋。
撰寫或修改篩選器
在大部分情況下,可以使用管理主控台建立大多數篩選器。隨後您可以修改 filter.conf 與 filterrules.conf 檔案以進行想要的變更。這些檔案會位於 /var/opt/SUNWps/http-hostname-domain/portal 目錄中。
然而,若您希望建立更複雜的參數集,則需要編輯網頁抓取程式使用的配置檔案。
在撰寫或編輯篩選器時,請注意下列幾點:
對於可以在 robot.conf 檔案中修改的參數、可以用於 filter.conf 檔案的網頁抓取程式應用程式功能,與如何建立自己的網頁抓取程式應用程式功能的討論,請參閱「Sun Java System Portal Server 6 2005Q4 開發人員指南」。
使用者可修改的參數robot.conf 檔案會定義許多網頁抓取程式選項,包括將網頁抓取程式指向在 filter.conf 檔案中適當的篩選器。由於較舊版本的向下相容性,robot.conf 也可以包含種子 URL。
因為您可以藉由使用管理主控台設定大部分的參數,一般來說不需要編輯 robot.conf 檔案。然而,進階使用者可以手動編輯這個檔案,以設定無法經由此管理主控台設定的參數。有關這個檔案的範例,請參閱 robot.conf 檔案範例。
表 14-3 會列出在 robot.conf 檔案中使用者可以修改的參數。表格第一欄會列出參數、第二欄會提供參數的說明,第三欄會提供範例。
表 14-3 使用者可修改的參數
參數
說明
範例
auto-proxy
指定網頁抓取程式的代理程式設定值。可以使用代理伺服器或 JavaScript 檔案自動配置代理程式。有關詳細資訊,請參閱「Sun Java System Portal Server 6 2005Q4 管理指南」。
auto-proxy="http://proxy_server/proxy.pac"
bindir
指定網頁抓取程式是否要新增連結目錄至 PATH 環境。對使用者而言,這是一個額外的 PATH,使用者可以在網頁抓取程式中執行外部程式,例如由 cmd-hook 參數指定的外部程式。
bindir=path
cmd-hook
指定外部的完成程序檔以在網頁抓取程式完成一次執行作業之後執行。這必須要是指令名稱的一個完整路徑。網頁抓取程式會在 /var/opt/SUNWps/ 目錄中執行此程序檔。
未設定任何預設值。
必須為要執行的指令註冊至少一個 RD。
有關撰寫完成程序檔的資訊,請參閱「Sun Java System Portal Server 6 2005Q4 開發人員指南」。
cmd-hook=”command-string”
command-port
指定網頁抓取程式用於偵聽以接受來自其他程式指令的插槽,例如「管理介面」或網頁抓取程式控制面板。
為了安全理由,Robot 僅可接受來自本地主機的指令,除非 remote-access 設定為 yes。
command-port=port_number
connect-timeout
指定允許網路回應連接請求的最長時間。
預設為 120 秒。
command-timeout=seconds
convert-timeout
指定允許文件轉換的最長時間。
預設為 600 秒。
convert-timeout=seconds
depth
指定網頁抓取程式要檢查的種子 URL (也稱為起點) 的連結數。這個參數會為沒有指定深度的所有種子 URL 設定預設值。
預設為 10。
值負 1 (depth=-1) 表示連結深度為無限。
depth=integer
指定執行網頁抓取程式者的電子郵件位址。
電子郵件位址是使用 HTTP 請求標題的使用者代理程式所傳送,因此網路管理員可以聯繫在他們站台上執行網頁抓取程式的人。
預設為 user@domain。
email=user@hostname
enable-ip
為已建立的每個 RD 的 URL 產生 IP 位址。
預設為 true。
enable-ip=[true | yes | false | no]
enable-rdm-probe
確定伺服器是否支援 RDM,網頁抓取程式會使用這個參數決定是否查詢每個其所遇到的伺服器。若伺服器支援 RDM,則網頁抓取程式不會嘗試列舉伺服器的資源,因為此伺服器可以作為本身的資源說明伺服器。
預設為 false。
enable-rdm-probe=[true | false | yes | no]
enable-robots-txt
確定網頁抓取程式是否應該檢查每個造訪的站台的 robots.txt 檔案 (若有的話)。
預設為 yes。
enable-robots-txt=[true | false | yes | no]
engine-concurrent
指定網頁抓取程式要使用的預建立執行緒的數目。
預設為 10。
您無法使用管理主控台以互動方式設定此參數。
engine-concurrent=[1..100]
enumeration-filter
指定由網頁抓取程式使用以決定是否應列舉資源的列舉篩選器。值必須是定義於 filter.conf 檔案的篩選器名稱。
預設為 enumeration-default。
您無法使用管理主控台以互動方式設定此參數。
enumeration-filter=enumfiltername
generation-filter
指定由網頁抓取程式使用以決定是否應為資源產生資源說明的產生篩選器。值必須是定義於 filter.conf 檔案的篩選器名稱。
預設為 generation-default。
您無法使用管理主控台以互動方式設定此參數。
generation-filter=genfiltername
index-after-ngenerated
指定網頁抓取程式在為搜尋引擎批次處理 RD 之前收集 RD 應持續的分鐘數。
若無指定這個參數,則將被設定為 256 分鐘。
index-after-ngenerated=30
loglevel
指定記錄層級。loglevel 值如下所示:
預設值為 1。
loglevel=[0...100]
max-connections
指定網頁抓取程式可以執行的最大並行擷取數。
預設為 8。
max-connections=[1..100]
max-filesize-kb
指定由網頁抓取程式擷取的檔案的最大檔案大小 (千位元組)。
max-filesize-kb=1024
max-memory-per-url / max-memory
指定由每個 URL 使用的最大記憶體 (位元組)。若 URL 需要更多記憶體,RD 會儲存至磁碟。
預設為 1。
您無法使用管理主控台以互動方式設定此參數。
max-memory-per-url=n_bytes
max-working
指定網頁抓取程式工作設定的大小,也是網頁抓取程式一次可執行的最大 URL 數。
您無法使用管理主控台以互動方式設定此參數。
max-working=1024
onCompletion
確定網頁抓取程式在完成執行之後的工作事項。網頁抓取程式可以成為閒置模式、回送、重新開始或退出。
預設為 idle。
這個參數可與 cmd-hook 參數一起使用。網頁抓取程式完成時,會執行 onCompletion 動作,然後執行 cmd-hook 程式。
OnCompletion=[idle | loop | quit]
password
指定用於 httpd 認證與 ftp 連線的 password。
password=string
referer
存取網頁時,若其設定為識別網頁抓取程式為 referrer,則指定在 HTTP 請求中傳送的參數。
referer=string
register-user
指定用於註冊 RD 至搜尋引擎資料庫的使用者名稱。
這個參數無法透過搜尋引擎管理介面互動式設定。
register-user=string
register-password
指定用於註冊 RD 至搜尋引擎資料庫的密碼。
這個參數無法透過管理主控台互動式設定。
register-password=string
remote-access
這個參數會決定網頁抓取程式是否可以接受來自遠端主機的指令。
預設為 false.。
remote-access=[true | false | yes | no]
robot-state-dir
指定網頁抓取程式儲存其狀態的目錄。在這個工作目錄中,網頁抓取程式可以記錄已收集的 RD 數等等。
robot-state-dir="/var/opt/SUNWps/instance/portal/robot"
server-delay
指定兩次造訪相同網站之間的時間週期,可以避免網頁抓取程式存取相同站台的頻率過高。
server-delay=delay_in_seconds
site-max-connections
指定網頁抓取程式可以連至任何站台的最大並行連線數。
預設為 2。
site-max-connections=[1..100]
smart-host-heuristics
使得網頁抓取程式可以變更正在輪換其 DNS 正規主機名稱的站台。例如,www123.siroe.com 會變更為 www.siroe.com。
預設為 false。
smart-host-heuristics=[true | false]
tmpdir
指定網頁抓取程式建立暫時檔的位置。
使用這個值設定環境變數 TMPDIR。
tmpdir=path
user-agent
指定使用 http-request 中的電子郵件位址傳送至伺服器的參數。
user-agent=iPlanetRobot/4.0
username
指定執行網頁抓取程式的使用者與用於 http 認證與 ftp 連線的使用者名稱。
預設為 anonymous。
username=string
robot.conf 檔案範例本節將介紹一個 robot.conf 檔案範例。範例中有註釋的參數會使用顯示的預設值。第一個參數 csid 會指出使用該檔案的 搜尋引擎 實例。請勿變更該參數的值。有關這個檔案中的參數定義,請參閱使用者可修改的參數。
<Process csid="x-catalog://budgie.siroe.com:80/jack" \
auto-proxy="http://sesta.varrius.com:80/"
auto_serv="http://sesta.varrius.com:80/"
command-port=21445
convert-timeout=600
depth="-1"
# email="user@domain"
enable-ip=true
enumeration-filter="enumeration-default"
generation-filter="generation-default"
index-after-ngenerated=30
loglevel=2
max-concurrent=8
site-max-concurrent=2
onCompletion=idle
password=boots
proxy-loc=server
proxy-type=auto
robot-state-dir="/var/opt/SUNWps/https-budgie.siroe.com/ \
ps/robot"
server-delay=1
smart-host-heuristics=true
tmpdir="/var/opt/SUNWps/https-budgie.siroe.com/ps/tmp"
user-agent="iPlanetRobot/4.0"
username=jack
</Process>