|
| |
| Sun Java System Application Server Enterprise Edition 7 2004Q2 System Deployment Guide | |
Chapter 2
Planning your EnvironmentPlanning your environment is one of the first phases of deployment. In this phase, you should first decide your performance and availability goals, and then accordingly make decisions about the hardware, network, and storage requirements.
The main objective of this phase is to determine the environment that best meets your business requirements.
This chapter contains the following sections:
Introducing HADBThis section contains the following topics:
Sun Java™ System Application Server 7 Enterprise Edition supports persistence of HTTP sessions, Stateful Session Beans, and remote references of EJB look-ups on the RMI/IIOP path. The high-availability database (HADB), bundled with the Enterprise Edition of Application Server provides a highly available persistence store.
An HADB system is comprised of various nodes. Each HADB node consists of the following:
There are two types of HADB nodes:
HADB nodes are organized into two Data Redundancy Units (DRUs) that mirror each other. Each DRU consists of half of the active node, and half of the spare node. One DRU contains one complete copy of the data.
To ensure fault tolerance, the servers that support one DRU must be completely self-supported with respect to power (use of uninterruptible power supplies is needed), processing units, and storage. If a power failure occurs in one DRU, the nodes in the other DRU can continue servicing requests until the power returns.
Active Nodes
Each active node must have a mirror node; that is active nodes must be configured in pairs. In addition, to maximize HADB availability, you should include two spare nodes for each pair so that if an active node fails, a spare node can take over while the failed node is repaired.
Spare Nodes
A spare node is an additional HADB node connected to a DRU. A spare node initially does not contain data, but constantly monitors for failure of active nodes in the DRU. If an active node fails, the spare node takes over the functions of the failed node while the failed node is being repaired.
Though you can configure an HADB system without spare nodes, it is not recommended. If the machine running an active node fails, the other nodes (including the mirror node) will become overloaded and drastically reduce performance. Depending on the impact of losing one machine, this may make your system effectively unavailable because machines running the other nodes also become overloaded.
Moreover, your system will be running without fault tolerance till you repair the failed machine as there is no mirror node to replicate the data. For high availability, you should minimize the time during which the system functions with only a single node.
Spare nodes are not mandatory, but should be used if you require high availability. Spare nodes allow a single machine to fail and yet maintain overall level of service. You should allocate one machine for each DRU to act as a spare machine, so that if one of your machines fails, your HADB system can continue without adversely affecting performance. A spare node also makes it easy for you to perform planned maintenance on the machines that host the active nodes.
Note
As a general rule, you should have a spare machine with enough Application Server instances and HADB nodes to replace any machine that becomes unavailable.
Sample Spare Node Configuration 1
If you have a co-located deployment, with four Sun FireTM V480 servers where each server has one Application Server instance and two HADB data nodes, you should allocate two more servers as spare machines (one machine per DRU). Each spare machine should run one application server instance and two spare HADB nodes.
Sample Spare Node Configuration 2
Suppose you have a separate-tier deployment where the HADB tier has two Sun FireTM 280R servers, each running two HADB data nodes. To maintain this system at full capacity, even if one machine becomes unavailable, configure one spare machine for the Application Server instances tier and one spare machine for the HADB tier.
The spare machine for the Application Server instances tier should have as many instances as the other machines in the Application Server instances tier. Similarly, the spare machine for the HADB tier should have as many HADB nodes as the other machines in the HADB tier.
For more information about the co-located and the separate tier deployment topologies, see Chapter 3, "Selecting a Topology."
Sample HADB Architecture
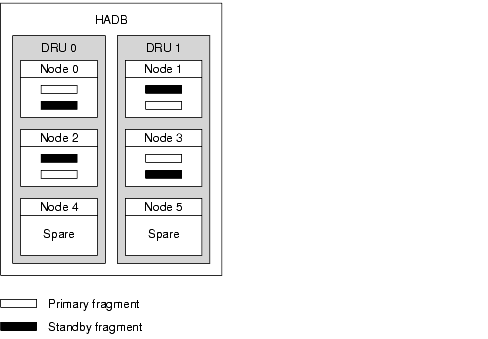
The following figure shows the architecture of a database with four active nodes and two spare nodes. Nodes 0 and 1 are a mirror node pair, as are nodes 2 and 3.
Figure 2-1 HADB Architecture with Four Active Nodes and Two Spare Nodes
Establishing Performance GoalsAs explained in Chapter 1, "Overview of Deployment," one of your main goals is to maximize performance. This essentially translates into maximizing throughput and reducing response time.
Beyond these basic goals, you should establish specific goals by determining the following:
These factors are interrelated. If you know the answer to any three of these four factors, you can calculate the fourth.
Some of the metrics described in this chapter can be calculated using a remote browser emulator (RBE) tool, or web site performance and benchmarking software, that simulates your enterprise’s web application activity. Typically, RBE and benchmarking products generate concurrent HTTP requests and then report back the response time and number of requests per minute. You can then use these figures to calculate server activity.
The results of the calculations described in this chapter are not absolute. Treat them as reference points to work against, as you fine-tune the performance of Sun Java System Application Server.
This section describes the following topics:
Estimating Throughput
Throughput, as measured for application server instances and for the HADB, has different implications.
A good measure of the throughput for Application Server instances is the number of requests precessed per minute. A good measure of throughput for the HADB is the number of requests precessed per minute by the HADB, and the session size per request. The session size per request is important because the size of session data stored varies from request to request.
For more information session persistence, see Chapter 1, "Overview of Deployment."
Estimating Load on Application Server Instances
Consider the following factors to estimate the load on application server instances:
Calculating Maximum Number of Concurrent Users
A user runs a process (for example through a web-browser) that periodically sends requests from a client machine to the Application Server. When estimating the number of concurrent users, include all users currently active. A user is considered active as long as the session that user is running is active (for example, the session has neither expired nor terminated).
A user is concurrent for as long as the user is on the system as a running process submitting requests, receiving results of requests from the server, and viewing the results.
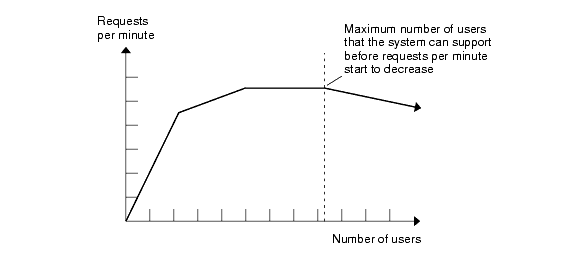
Eventually, as the number of concurrent users submitting requests increases, requests processed per minute begins to decline (and the response time begins to increase). The following diagram illustrates this situation.
Figure 2-2 Performance Pattern with Increasing Number of Users.
You should identify the point at which adding more concurrent users reduces the number of requests that can be processed per minute. This point indicates when performance starts to degrade.
Calculating Think Time
A user does not submit requests continuously. A user submits a request, the server receives the request, processes it and then returns a result, at which point the user spends some time analyzing the result before submitting a new request. The time spent reviewing the result of a request is called think time.
Determining the typical duration of think time is important. You can use the duration to calculate more accurately the number of requests per minute, as well as the number of concurrent users your system can support. Essentially, when a user is on the system but not submitting a request, a gap opens for another user to submit a request without altering system load. This implies that you can support more concurrent users.
Calculating Average Response Time
Response time refers to the amount of time it takes for results of a request to be returned to the user. The response time is affected by a number of factors including network bandwidth, number of users, number and type of requests submitted, and average think time.
In this section, response time refers to the mean, or average, response time. Each type of request has its own minimal response time. However, when evaluating system performance, you should base your analysis on the average response time of all requests.
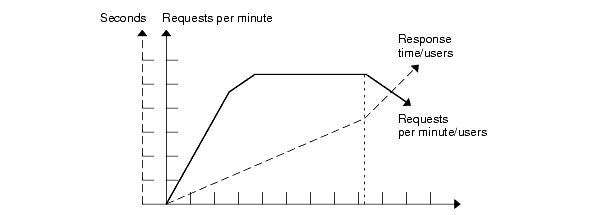
The faster the response time, the more requests per minute are being processed. However, as the number of users on your system increases, response time starts to increase as well, even though the number of requests per minute declines, as the following diagram illustrates:
Figure 2-3 Response Time with Increasing Number of Users
A system performance graph similar to Figure 2-3, indicates that after a certain point (point A in this diagram), requests per minute are inversely proportional to response time- the sharper the decline in requests per minute, the steeper the increase in response time (represented by the dotted line arrow).
In Figure 2-3, point A represents peak load, that is, the point at which requests per minute start to decline. Prior to this point response time calculations are not necessarily accurate because they do not use peak numbers in the formula. After this point, (because of the inversely proportional relationship between requests per minute and response time), you can more accurately calculate response time using maximum number of users and requests per minute.
To determine response time at peak load, use the following formula:
Response time = (concurrent users / requests per second) - think time in seconds
To obtain an accurate response time result, you must always include think time in the equation.
Example Calculation of Response Time
For example, if the following conditions exist:
Therefore, the response time is 2 seconds.
After you have calculated your system’s response time, particularly at peak load, decide what is an acceptable response time for your enterprise. Response time, along with throughput, is one of the main factors critical to Sun Java System Application Server performance. Improving the response time should be one of your goals.
If there is a response time beyond which you do not want to wait, and performance is such that you get response times over that level, then work towards improving your response time or redefine your response time threshold.
Calculating Requests Per Minute
If you know the number of concurrent users at any given time, the response time of their requests and the average user think time at that time, you can determine requests per minute. Typically, you start by knowing how many concurrent users are on your system.
For example, after running a few web site performance calculation software, you conclude that the average number of concurrent users submitting requests on your online banking web site is 3,000. This number is dependent on the number of users who have signed up to be members of your online bank, their banking transaction behavior, the times of the day or week they choose to submit requests, and so on.
Therefore, knowing this information enables you to use the requests per minute formula described in this section to calculate how many requests per minute your system can handle for this user base. Since requests per minute and response time become inversely proportional at peak load, decide if fewer requests per minute are acceptable as a trade-off for better response time, or alternatively, if a slower response time is acceptable as a trade-off for more requests per minute.
Essentially, you should experiment with the requests per minute and response time thresholds that is acceptable as a starting point for fine-tuning system performance. Thereafter, decide which areas of your system you want to adjust.
The formula for obtaining the requests per second is as follows:
requests per second = concurrent users / (response time in seconds + think time in seconds)
Example Calculation of Requests per Second
For example, if the following conditions exists:
Therefore, the number of requests per second is 700 and the number of requests per minute is 42000.
Estimating Load on the HADB
To calculate load on the HADB, consider the following factors:
The session persistence settings that you specify affect the load on the HADB. For more information on configuring session persistence, see Sun Java System Application Server Administration Guide.
Number of Requests per Minute Received by the HADB
The number of requests per minute received by the HADB depends on the persistence frequency. This is the frequency at which HTTP session and SFSB session information is stored in the HADB, defined through the persistence frequency settings.
The persistence frequency options are:
This section discusses the following topics:
Comparison of Persistence Frequency Options
Table # summarizes the advantages and disadvantages of both HTTP and SFSB session persistence frequency options. The left column lists the persistence frequency options, the middle column lists the advantages and the right column lists the disadvantages of using this option.
Session Size Per Request
The session size per request depends on the amount of session information stored in the session.
Tip
To improve overall performance, reduce the amount of information in the session as much as possible.
You can further fine-tune the session size per request through the persistence scope settings. Choose from the following options for HTTP and SFSB session persistence scope:
- session: The entire session is saved every time session information is saved to the HADB database.
- modified-session: The session is saved only if it has been modified.
- modified-attribute: Only those attributes are stored that have been modified (inserted, updated, or deleted) since the last time the session was stored.
Comparison of Persistence Scope Options
Table # summarizes the advantages and disadvantages of the persistence scope options. The left column lists the persistence frequency options, the middle column lists the advantages, and the right column lists the disadvantages of this option.
In the case of an SFSB session persistence, the load on HADB database depends on the number of SFSB beans enabled for check pointing. Checkpointing generally occurs after any transaction involving the SFSB is completed (even if the transcation rolls back), and how many methods in each bean are enabled for checkpointing in the case of non-transactional methods.
For better performance, specify a small subset of methods for checkpointing. The size of the data that is being checkpointed and the frequency at which checkpointing takes place determines the additonal overhead in respone time for a given client interaction.
Design Decisions to MakeDepending on the load on the application server instances, the load on the HADB, and the failover requirements, you should make the following decisions at this stage:
Number of Application Server Instances Required
To determine the number of applications server instances needed, evaluate your environment on the basis of the factors explained in Estimating Load on Application Server Instances. Each application server instance can use more than one Central Processing Unit (CPU) and should have at least one CPU allocated to it.
Number of HADB Nodes Required
As a general guideline, you should plan to have one HADB node for each CPU in your system. For example, use two HADB nodes for a machine that has two CPUs.
HADB Storage Capacity Required
The HADB provides near-linear scaling with the addition of more nodes, until you exceed the network capacity. Each node must be configured with storage devices on a dedicated disk or disks. All nodes must have equal space allocated on the storage devices. Make sure that the storage devices are allocated on local disks.
For example, suppose the expected session data is X MB. The HADB replicates the data on mirror nodes, and therefore, 2X MB of storage is needed.
Further, the HADB uses indexes to enable fast access to data. An additional 2X MB is required (for both nodes together) for indexes (assuming a less than 100% fillings rate). This implies that a storage capacity of 4X is required.
Therefore, the expected storage capacity needed by the HADB is four times the expected data volume.
If the system has to be designed for future expansion (by adding bigger disks to nodes or adding new nodes to the system) without loss of data from the HADB, the expected storage capacity is eight times the expected data volume. This is because, for online upgrades you might want to refragment the data after adding new nodes. In this case, you will need a similar amount (4X) of additional space on the data devices, thus increasing the total storage capacity required to 8X.
Additionally, HADB uses disk space for internal use as follows:
For more information, see Sun Java System Application Server Administration Guide and Sun Java System Application Server Performance Tuning Guide.
The following table summarizes the HADB storage space requirements for a session data of X MB. The left row lists the condition (whether online addition or removal of HADB nodes is required), and the right row lists the HADB storage space required.
If the HADB runs out of device space, client requests to insert or update data are not accepted. However, delete operations are accepted.
Setting Data Device Size
Use the following command to set the size of the data devices of the HADB:
hadbm set TotalDatadeviceSizePerNode
The hadbm command restarts all the nodes, one by one, for the change to take effect. For more information on configuring the HADB, see Sun Java System Application Server Administration Guide.
Designing for Peak Load Compared to Steady State Load
In a typical deployment, there is a difference between steady state and peak workloads.
If you design for peak load, you must deploy a system that can sustain the expected maximum load of users and requests without a degradation in response time. This implies that your system can handle extreme cases of expected system load.
If the difference between peak load and steady state load is substantial, designing for peak loads may mean that you are spending on resources that will be idle for a significant amount of time.
If you design for steady state load, then you don’t have to deploy a system with all the resources required to handle the server’s expected peak load. However a system designed to support steady load will have slower response time when peak load occurs.
Frequency and Duration of Peak Load
The factor that may affect whether you want to design for peak load or for steady state is how often your system is expected to handle the peak load. If peak load occurs several times a day or even per week, you may decide that this is enough time to warrant expanding capacity to handle this load. If the system operates at steady state 90 percent of the time, and at peak only 10 percent of the time, then you may prefer to deploy a system designed around steady state load.
This implies that your system’s response time will be slower only 10 percent of the time. Decide if the frequency or duration of time that the system operates at peak justifies the need to add resources to your system (should this be required to handle peak load).
Planning Network Configuration to Meet Your Performance GoalsWhen planning how to integrate Sun Java System Application Server into your network for optimal performance, you should estimate the bandwidth requirements and plan your network in such a way that it can meet your performance requirements.
The following topics are covered in this section:
Estimating Bandwidth Requirements
When you decide on the desired size and bandwidth of your network, first determine your network traffic and identify its peak. Check if there is a particular hour, day of the week, or day of the month when overall volume peaks, and then determine the duration of that peak.
Tip
At all times consult network experts at your site about the size and type of network components you are considering.
During peak load times, the number of packets in the network is at its highest level. In general, if you design for peak load, scale your system with the goal of handling 100 percent of peak volume. Bear in mind, however, that any network behaves unpredictably and that despite your scaling efforts, 100 percent of peak volume might not always be handled.
For example, assume that at peak load, five percent of your users occasionally do not have immediate Internet access when accessing applications deployed on Application Server. Of that five percent, determine how many users retry access after the first attempt. Again, not all of those users may get through, and of that unsuccessful portion, another percentage will retry. As a result, the peak appears longer because peak use is spread out over time as users continue to attempt access.
To ensure optimal access during times of peak load, start by verifying that your Internet service provider (ISP) has a backbone network connection that can reach an Internet hub without degradation.
Calculating Bandwidth Required
Based on the calculations you made in Establishing Performance Goals, you should determine the additional bandwidth required for deploying Sun Java System Application Server at your site.
Depending on your method of access (T-1 lines, ISDN, and so on), you can calculate the amount of increased bandwidth you require to handle your estimated load. For example, suppose your site uses T-1 or higher-speed T-3 links for Internet access. Given their bandwidth, you can estimate how many lines you will need on your network, based on the average number of requests generated per second at your site and the maximum peak load. You can calculate these figures using a web site analysis- and monitoring-tool.
Example Calculation of Bandwidth Required
A single T-1 line can handle 1.544 Mbps. Therefore, a network of four T-1 lines carrying 1.544 Mbps each can handle approximately 6 Mbps of data. Assuming that the average HTML page sent back to a client is 30 kilobytes (KB), this network of four T-1 lines can handle the following traffic per second:
6,176,000 bits/8 bits = 772,000 bytes per second
772,000 bytes per second/30 KB = approximately 25 concurrent client requests for pages per second.
With a traffic of 25 pages per second, this system can handle 90,000 pages per hour (25 x 60 seconds x 60 minutes), and therefore 2,160,000 pages per day maximum, assuming an even load throughout the day. If the maximum peak load is greater than this, you will have to increase the bandwidth accordingly.
Estimating Peak Load
Having an even load throughout the day is probably not realistic. You need to determine when peak load occurs, how long it lasts, and what percentage of the total load is the peak load.
Example Calculation of Peak Load
If peak load lasts for two hours and takes up 30 percent of the total load of 2,160,000 pages, this implies that 648,000 pages must be carried over the T-1 lines during two hours of the day.
Therefore, to accommodate peak load during those two hours, you should increase the number of T-1 lines according to the following calculations:
648,000 pages/120 minutes = 5,400 pages per minute
5,400 pages per minute/60 seconds = 90 pages per second
If four lines can handle 25 pages per second, then approximately four times that many pages requires four times that many lines, in this case 16 lines. The 16 lines are meant for handling the realistic maximum of a 30 percent peak load. Obviously, the other 70 percent of your load can be handled throughout the rest of the day by these many lines.
Configuring Subnets
If you use the separate tier topology, where the application server instances and HADB nodes are on separate tiers, you can achieve a performance improvement by keeping HADB nodes on a separate subnet. This is because HADB uses the User Datagram Protocol (UDP). Using a separate subnet reduces the UDP traffic on the machines outside of that subnet.
Choosing Network Cards
For greater bandwidth and optimal network performance, use at least 100 Mbps Ethernet cards or, preferably, 1 Gbps Ethernet cards between servers hosting Sun Java System Application Server and the HADB nodes, as well as among other resources such as HADB databases that are hosted on other machines.
Network Settings for HADB
Use the following suggestions to make HADB work optimally in the network:
- Use switched routers so that each network interface has a dedicated 100 Mbps or better Ethernet channel.
- If you are running HADB on a multi-CPU machine hosting four or more HADB nodes, use 1 Gbps Ethernet cards.
- If you suspect network bottlenecks within HADB nodes:
- The current release of HADB is not generally capable of running on servers with multiple network interface cards. If you need network bandwidth beyond what can be offered with a single network interface card per computer, consult Sun customer support for alternative solutions.
Planning for AvailabilityAvailability must be planned according to the application and customer requirements.
There are two ways to achieve high availability:
Adding Redundancy to the System
One way to achieve high availability is to add redundancy to the system—redundancy of hardware and software. When one unit fails, the redundant unit takes over. This is also referred to as fault tolerance.
In general, to achieve high availability, you should determine and remove every possible point of failure in the system.
This section discusses the following topics:
Identifying Failure Classes
The level of redundancy is determined by the failure classes (types of failure) that the system needs to tolerate. Some examples of failure classes are: system process, machine, power supply, disk, network failures, building fires and catastrophes.
Duplicated system processes tolerate single system process failures. Duplicated machines tolerate single machine failures. Attaching the duplicated mirrored (paired) machines to different power supplies tolerates single power failures. By keeping the mirrored machines in separate buildings, a single-building fire can be tolerated and by keeping them in separate geographical locations, natural catastrophes like earth quake in a location can be tolerated.
When planning availability, you should determine the failure classes covered by the system.
Using Redundancy Units to Improve Availability
To improve availability, HADB nodes are always used in Data Redundancy Units (DRUs) as explained in Introducing HADB.
Using Spare Nodes to Improve Fault Tolerance
The use of spare nodes as explained in Spare Nodes improves fault tolerance. Although spare nodes are not mandatory, their use is recommended for maximum availability.
Planning Failover Capacity
Failover capacity planning implies deciding how many additional servers and processes you need to add to Sun Java System Application Server installation so that in the event of a server or process failure, the system can seamlessly recover data and continue processing. If your system gets overloaded, a process or server failure might result, causing response time degradation or even total loss of service. Preparing for such an occurrence is critical to successful deployment.
To maintain capacity, especially at peak loads, we recommended that you add spare machines running Application Server instances to your existing Application Server installation. For example, assume you have a system with two machines running one Application Server instance each. Together, these machines can handle a peak load of 300 requests per second. If one of these machines becomes unavailable, the system will be able to handle only 150 requests, assuming an even load distribution between the machines. Therefore half the requests during peak load would not be served.
Using Multiple Clusters to Improve Availability
To improve availability, instead of using a single cluster, you should group the application server instances into multiple clusters. This way, you can perform online upgrades for clusters (one by one) without loss of service.
For more information on setting up multiple clusters and using multiple clusters to perform online upgrades without loss of service, see Sun Java System Application Server Administration Guide.