|
| |
| Sun Java System Application Server Enterprise Edition 8.1 2005Q1 Deployment Planning Guide | |
Chapter 3
Selecting a TopologyAfter estimating the factors related to performance as explained in Chapter 2, "Planning your Deployment," determine the topology that you will use to deploy the Application Server. A topology is the arrangement of machines, Application Server instances, and HADB nodes, and the communication flow among them.
There are two fundamental deployment topologies. Both topologies have common building blocks: multiple Application Server instances in a cluster, a mirrored set of HADB nodes, and HADB spare nodes. Both of them require a set of common configuration settings to function properly.
This chapter discusses:
- Common Requirements for both topologies.
- The two topologies:
- Co-located Topology - Application Server instances and HADB nodes are on the same machine.
- Separate Tier Topology - Application Server instances and HADB nodes are on different machines.
Common RequirementsThis section describes the requirements that are common to both topologies:
General Requirements
Both topologies must meet the following general requirements:
- Machines that host HADB nodes must be in pairs. That is, there must be an even number of them.
- Each data redundancy unit (DRU) must have the same number of machines. Create the HADB database in such a way that the mirrored (paired) nodes are on a different DRU than the primary nodes.
- Each machine that hosts HADB nodes must have local disk storage, used to store all persisted information in the HADB.
- Machines that host the HADB nodes must run the same operating system. It is best to use identical or nearly identical machines, in terms of configuration and performance.
- For HTTP and SFSB session information to be persisted to the HADB, the Application Server instances must be in a cluster and satisfy all related requirements. For more information on configuring clusters, see the Sun Java System Application Server Administration Guide.
- Machines hosting the Application Server instances must be as identical as possible, in terms of configuration and performance. This is because the load balancer plug-in uses a round-robin policy for load balancing, and if machines of different classes host instances, then the load will not be balanced in the most optimum way across these machines.
- Preferably have a separate uninterruptible power supply (UPS) for each DRU.
HADB Nodes and Machines
Each DRU contains a complete copy of the data in HADB and can continue servicing requests if the other DRU becomes unavailable. However, if a node in one DRU and its mirror in another DRU fail at the same time, some portion of data is lost. For this reason, it is important that the system is not set up so that both DRUs can be affected by a single failure such as a power failure or disk failure.
Follow these guidelines when setting up the HADB nodes and machines:
- To increase capacity and throughput, add nodes in pairs with one node for each DRU.
- Set up each DRU with a number of spare nodes equal to the number of nodes running on each machine. This is because if each machine in the configuration runs n data nodes, the failure of a single machine brings down n nodes.
- Run the same number of HADB nodes on all machines to balance load as evenly as possible.
Load Balancer Configuration
Both the topologies have Application Server instances in a cluster. These instances persist session information to the HADB. Configure the load balancer to include configuration information for all the Application Server instances in the cluster.
For more information on setting up a cluster and adding Application Server instances to clusters, see the Sun Java System Application Server Administration Guide.
Co-located TopologyIn the co-located topology, the Application Server instance and the HADB nodes are on the same machine (hence the name co-located). This topology requires fewer machines than the separate tier topology. The co-located topology uses CPUs more efficiently—an Application Server instance and an HADB node share one machine and the processing is distributed evenly among them.
This topology requires a minimum of two machines. To improve throughput, add more machines in pairs.
Note
The co-located topology is a good for large, symmetric multiprocessing (SMP) machines, since you can take full advantage of the processing power of these machines.
Example Configuration
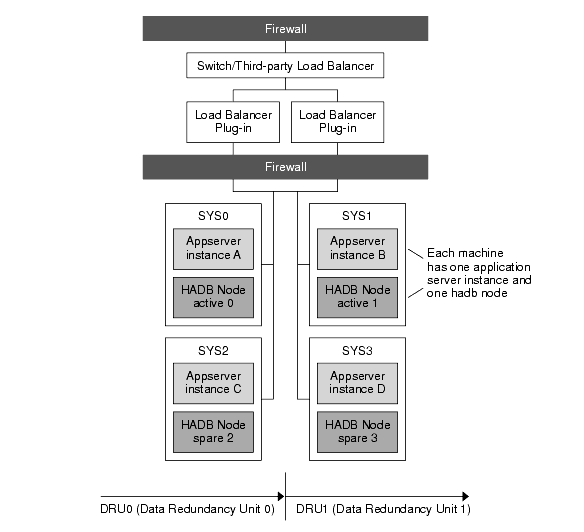
Figure 3-1 illustrates an example configuration of the co-located topology.
Figure 3-1 Example Co-located Topology
Machine SYS0 hosts Application Server instance A, machine SYS1 hosts Application Server instance B, machine SYS2 hosts Application Server instance C, and machine SYS3 hosts Application Server instance D.
These four instances form a cluster that persists information to the two DRUs:
Variation of Co-located Topology
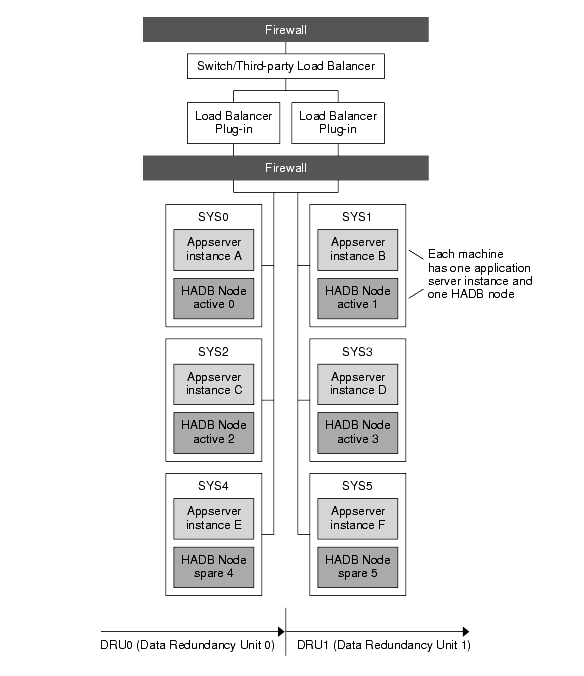
For better scalability and throughput, increase the number of Application Server instances and HADB nodes by adding more machines. For example, you could add two machines, each with one Application Server instance and one HADB node. Make sure to add the HADB nodes in pairs, assigning one node for each DRU. Figure 3-2 illustrates this configuration.
Figure 3-2 Variation of Co-located Topology
In this variation, the machines SYS4 and SYS5 have been added to the co-located topology described in Example Configuration.
Application Server instances are hosted as follows:
These instances form a cluster that persists information to the two DRUs:
- DRU0 comprises machines SYS0, SYS2, and SYS4. HADB node active 0 is on the machine SYS0. HADB node active 2 is on the machine SYS2. HADB node spare 4 is on the machine SYS4.
- DRU1 comprises the machines SYS1, SYS3, and SYS5. HADB node active 1 is on the machine SYS1. HADB node active 3 is on the machine SYS3. HADB node spare 5 is on the machine SYS5.
Separate Tier TopologyIn this topology, Application Server instances and the HADB nodes are on different machines (hence the name separate tier).
This topology requires more hardware than the co-located topology. It might be a good fit if you have different types of machines—you can allocate one set of machines to host Application Server instances and another to host HADB nodes. For example, you could use more powerful machines for the Application Server instances and less powerful machines for HADB.
Example Configuration
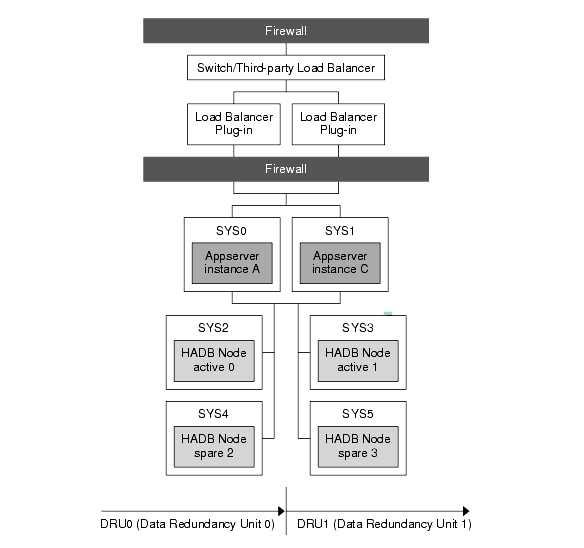
Figure 3-3 illustrates the separate tier topology.
Figure 3-3 Example Separate Tier Topology
In this topology, machine SYS0 hosts Application Server instance A and machine SYS1 hosts Application Server instance B. These two instances form a cluster that persists session information to the two DRUs:
All the nodes on a DRU are on different machines, so that even if one machine fails, the complete data for any DRU continues to be available on other machines.
Variation of Separate Tier Topology
A variation of the separate tier topology is to increase the number of Application Server instances by adding more machines horizontally to the configuration. For example, add another machine to the example configuration by creating a new Application Server instance. Similarly, increase the number of HADB nodes by adding more machines to host HADB nodes. Recall you must add the HADB nodes in pairs with one node for each DRU.
Figure 3-4 illustrates this configuration.
Figure 3-4 Variation of Separate Tier Topology
In this configuration, each machine hosting Application Server instances has two instances. There are thus a total of six Application Server instances in the cluster.
HADB nodes are on machines SYS3, SYS4, SYS5, and SYS6.
DRU0 comprises two machines:
DRU1 comprises two machines:
Each machine hosting HADB nodes hosts two nodes. Thus, there are a total of eight HADB nodes: four active nodes and four spare nodes.
Determining Which Topology to UseTo determine which topology (or variation) best meets your performance and availability requirements, test the topologies and experiment with different combinations of machines and CPUs.
Determine what trade-offs are required to meet your goals. For example, if ease of maintenance is critical, the separate tier topology is more suitable. The trade-off is that this topology requires more machines than the co-located topology.
An important factor in the choice of topology is the type of machines available. If the system contains large, Symmetric Multiprocessing (SMP) machines, the co-located topology is attractive because you can take full advantage of the processing power of these machines. If the system contains various types of machines, the separate tier topology can be more useful because you can allocate a different set of machines to the Application Server tier and to the HADB tier. For example, you might want to use the most powerful machines for the Application Server tier and less powerful machines for the HADB tier.
Comparison of Topologies
Table 3-1 presents a comparison of the co-located topology and the separate tier topology. The left column lists the name of the topology, the middle column lists the advantages of the topology, and the right column lists the disadvantages of the topology