|
|
| Sun ONE Directory Server インストールおよびチューニングガイド |
Directory Server で扱うエントリ数が多くなると、検索で潜在的に消費する時間やシステムリソースも多くなります。インデックスは検索パフォーマンスを向上するツールの 1 つです。この章では、特定の導入で特定のインデックスを使用する場合のコストと利点について理解するために、Directory Server インデックスの操作について説明します。
インデックスについて
インデックスは、検索情報を Directory Server エントリと関連付けます。インデックスはファイルとして Directory Server データベースに格納されています。この場合に データベースはサフィックスの物理表現です。ほとんどの導入の場合、サフィックス 1 つはデータベース 1 つに対応しています。1 つのサフィックスが複数のデータベースに分割可能な導入もあります。Directory Server では、データベースをデフォルトで ServerRoot/slapd-ServerID/db/ に格納します。デフォルト値は nsslapd-directory です。このディレクトリに、インデックスが作成された属性ごとにインデックスファイルを 1 つ保持する単一のデータベースがあります。たとえば、サフィックス dc=example,dc=com からのエントリを保持するデータベース example の CN インデックスファイルの場合は、ServerRoot/slapd-ServerID/db/example/example_cn.db3 になります。
インデックスする対象は、クライアントアプリケーションがディレクトリデータにアクセスする方法によって異なります。表 7-1 に、標準的なインデックスのタイプについて簡単な説明をまとめます。
CN など特定の属性のインデックスファイルには、複数のタイプのインデックスが格納されていることがあります。たとえば、CN が等価インデックスと部分文字列インデックスで example データベースにインデックスが作成されている場合、example_cn.db3 には等価インデックスと部分文字列インデックスの両方が含まれます。
次については、『Sun ONE Directory Server 管理ガイド』を参照してください。
- 各インデックスタイプの概要
- インデックスの作成や削除の手順
- Directory Server によって作成されるデフォルトインデックスのリスト
- Directory Server で必要とされるシステムインデックスのリスト
デフォルトインデックスは、多くの場合で検索パフォーマンスを向上させます。また、メッセージングなどほかのアプリケーションもいくつかサポートしています。パフォーマンス上の理由から、特定のデフォルトインデックスを無効にしたり、場合によっては削除したりすることも選択できます。システムインデックスは、Directory Server に必要なインデックスです。削除したり変更したりしないでください。
利点: 検索でインデックスを使用する方法
インデックスを使用すると検索速度が向上します。インデックス 1 つに値のリスト 1 つが含まれており、それぞれ値に対応するエントリ識別子のリストに関連付けられています。Directory Server ではインデックス内のエントリ識別子のリストを使用して、エントリをすばやく検索することができます。エントリのリストを管理するのにインデックスがないと、Directory Server では検索に一致するエントリを探すために、エントリすべてをチェックすることが必要になる場合があります。
インデックスを使用した検索がインデックスを使用しない検索より極めて少ない処理で済む理由は、検索要求処理を説明すると明白です。Directory Server では、次の手順で、検索要求を処理します。
- クライアントアプリケーションは Directory Server に検索要求を送信します。
- Directory Server では、処理可能なサフィックスに検索ベースが対応していることを確認するために、要求を調べます。対応していない場合は、エラーをクライアントに返し、場合によっては別の Directory Server インスタンスへの参照を返します。
- Directory Server では検索に適したインデックス (複数の場合あり) があるかどうか判断します。
そのようなインデックスが存在する場合、Directory Server では図 6-2 に示すように、インデックス内で候補エントリ (検索要求に一致するかもしれないエントリ) を検索します。
そのようなインデックスが存在しない場合、Directory Server によってデータベース内の全エントリから候補エントリのセットが生成されることに注意してください。大規模な導入の場合、検索によっては、この手順にかなりの時間とシステムリソースが消費される可能性があります。
- Directory Server では、検索基準に一致するかどうかを判断するために、各候補エントリが調べられます。一致するエントリは見つかるごとに、Directory Server によってクライアントに返されます。
すべての候補が調べ終わるか、「クライアントが使用できるリソースの制限」で説明するように nsslapd-lookthroughlimit、nsslapd-sizelimit、または nsslapd-timelimit などのリソース制限に達するまで、Directory Server では候補を調べ続けます。
手順 3 で明らかなように、インデックスを使用すると、クライアントからの検索要求に対応するために Directory Server で実行する処理を大幅に減らすことができます。
コスト : 更新がインデックスに与える影響
更新ではエントリ自体が変更されるだけでなく、そのエントリを参照するインデックスも更新されます。インデックス内のエントリへの参照が増えるほど、更新中にインデックスを変更するための潜在的な処理コストも増えていきます。特に Directory Server では 図 6-3 に示すように、更新通知をクライアントアプリケーションに送信する前に、影響のあるインデックスをすべて変更します。
インデックスには、その維持にかかる処理コストに加えて、ディスクの空き容量や場合によってはメモリの空き容量に関してコストがかかることもあります。「検索の最適化」で説明するように、検索に使用するデータベースキャッシュのサイズを最適化するときは、データベースキャッシュにエントリとインデックスの両方を保持できるだけのメモリを用意するように選択できます。インデックスが大きくなると、それだけ必要な空き容量も増えます。64 ビットのインデックスでは、32 ビットのインデックスよりも多少多くの空き容量が必要になります。
一般に、Directory Server のインスタンスのインデックスをチューニングすることは、高速検索処理から得られる利点で、多くの更新処理にかかるコストや多くの空き容量を必要とするコストが埋め合わせされるようなインデックスだけを維持することを意味します。有用なインデックスを維持するのは利点になりますが、クライアントで検索する頻度が少ない属性に対して使用することもないインデックスを維持することは無益です。
実在インデックス
図 7-1 は nsRoleDN 属性に対する実在インデックスです。このインデックスは属性の値には依存せず、データベース内の nsRoleDN 属性を持つすべてのエントリを含んでいることを示しています。この属性のすべての値は、* を使用して参照します。
図 7-1 実在インデックスの表現
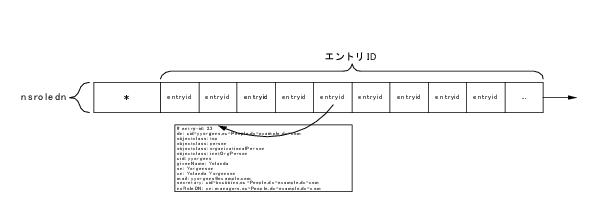
図に示すように、内部の entryid 属性値を使用すると Directory Server によって、すばやい取得に備えてエントリへの参照を格納できます。Directory Server では、dbinstance_id2entry.db3 インデックスを使用するエントリを実際に取得します。ここで dbinstance は「インデックスについて」で説明するように、データベース識別子に依存しています。
Directory Server では実在にインデックスされた属性を持つエントリの更新要求を受信すると、エントリをインデックスから削除する必要があるかどうかを判断し、更新通知をクライアントアプリケーションに返す前に、必要な変更を実行する必要があります。
実在インデックスにおけるコストは、一般にその他のインデックスタイプよりも低いですが、実在インデックスに保持されるインデックスのリストは長くなることがあります。
等価インデックス
図 7-2 は SN (姓) 属性の等価インデックスです。このインデックスに SN 属性の属性値を持つエントリの属性ごとにリストを保持する様子を示します。
図 7-2 等価インデックスの表現
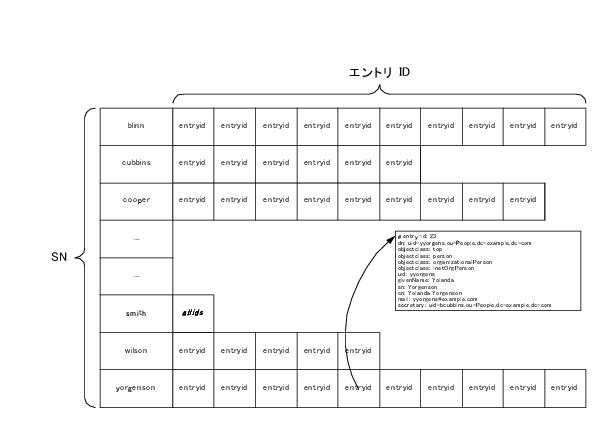
Directory Server では等価にインデックスが作成された属性を持つエントリの更新要求を受信すると、エントリをインデックスから削除する必要があるかどうかを判断する必要があります。次に、インデックスに対してリストを追加または削除する必要があるかどうかを判断し、更新通知をクライアントアプリケーションに返す前に、必要な変更を実行する必要があります。
等価インデックスにおけるコストはたとえば部分文字列インデックスよりも一般に低くなりますが、空き容量は実在インデックスよりも多く必要になります。しかし、メッセージングサーバーのようなクライアントアプリケーションでは、検索パフォーマンスが最高であることから等価インデックスを使用します。写真や暗号化パスワードなど、大きなバイナリ属性に等価インデックスを使用することは避けてください。
部分文字列インデックス
図 7-3 は SN (姓) 属性の部分文字列インデックスです。このインデックスが属性値ごとの一連のリストを保持する様子の一部を示します。
Directory Server では、部分文字列 2 文字による検索がインデックスに見つかるように部分文字列のインデックスを作成します。そのため (sn=*ab*) という検索はインデックスを使用して高速化できますが、(sn=*a*) という検索は高速化できません。
図 7-3 部分文字列インデックスの表現
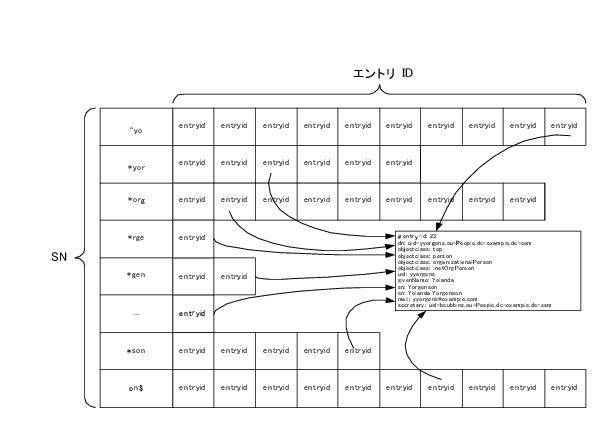
Directory Server では、ワイルドカードの前に 1 文字だけあるような前方部分文字列検索を可能とする高度な最適化も用意しています。つまり、たとえば (sn=*a*) や (sn=*a) ではなく、(sn=a*) の場合も部分文字列インデックスが利用できるときは高速化されます。
Directory Server では、組み込みのルールに準拠して部分文字列インデックスを作成します。これらの部分文字列は、システム管理者が設定することはできません。
Directory Server では部分文字列にインデックスが作成された属性を持つエントリの更新要求を受信すると、エントリをインデックスから削除する必要があるかどうかと、エントリの変更がインデックスに与える影響を判断する必要があります。次に、インデックスに対してエントリ ID またはエントリ ID のリストを追加または削除する必要があるかどうかを判断し、更新通知をクライアントアプリケーションに返す前に、必要な変更を実行する必要があります。更新する回数は、属性値の文字列の長さによって異なります。
部分文字列インデックスを維持するコストは、一般にとても高くなります。コストはインデックス化された文字列の長さの関数となるため、description のように、長い文字列値となる可能性のある属性に対しては、不必要な部分文字列インデックスは避けてください。部分文字列インデックスは写真のようなバイナリ属性に適用することはできません。
ブラウズ (仮想リスト表示) インデックス
図 7-4 は仮想リスト表示のブラウズインデックスです。このインデックスが仮想リスト表示情報に依存している様子を示します。つまり、ブラウザインデックスの vlvBase、vlvScope、vlvFilter、および vlvSort の各属性値に依存しています。このタイプのインデックスのエントリ ID は vlvSort 基準に基づいて並べられています。
図 7-4 ブラウズインデックスの表現
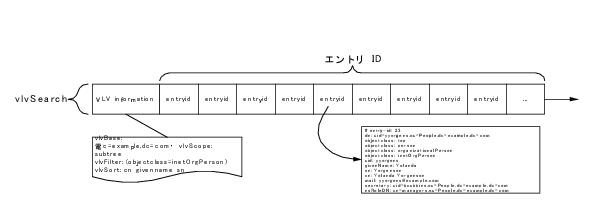
Directory Server では vlvFilter に一致するエントリの更新要求を受信すると、エントリをインデックスから削除する必要があるかどうかを判断する必要があります。次に、エントリのリスト内の位置が正しいことを確認し、更新通知をクライアントアプリケーションに返す前に、必要な変更を実行する必要があります。
近似インデックス
Directory Server では、metaphone 音声アルゴリズムのバリエーションを使用した近似インデックスを維持します。このアルゴリズムでは、属性の文字列値を英語の音声発音の近似に分割します。着信した検索要求で一致する値は、同じアルゴリズムを使用して処理されます。アルゴリズムは音節に対しては厳密でないため、電話番号のように数値を含む属性には効果的ではありません。
アルゴリズムによって、属性値の文字列ごとにターゲット文字列が生成されます。そのため、この英語の文字列に「似た音」のインデックスにおけるコストは、等価インデックスのコストと同程度になります。
国際化インデックス
国際化インデックスでは、インデックスの維持に、ある特定のロケール用のマッチングルールを使用します。そのため、国際化インデックスにおけるコストは、部分文字列インデックスや等価インデックスを使用する場合のコストと同程度になります。
カスタムマッチングルールのサーバープラグインを使用すると、国際化インデックスやほかのタイプのインデックスに対する標準サポートを拡張できます。カスタムマッチングルールのプラグインについての詳細は、『Sun ONE Directory Server Plug-In API Programming Guide』を参照してください。
例 : エントリのインデックス
次に示すような、インデックスが作成されたサフィックスに追加されるユーザーエントリを考えてみます。ここで uid は等価検索、共通名 (cn) と姓 (sn) 属性は等価、部分文字列、および近似検索、mail 属性は等価検索、telephoneNumber 属性は等価および部分文字列検索、そして description 属性は部分文字列検索のために、それぞれインデックスが作成されています。
このエントリを追加する際、Directory Server では cn、sn、mail、telephoneNumber、および description の各インデックスを変更する必要があります。表 7-2 に予想されるエントリの数を示します。
表 7-2 ユーザーエントリの例におけるインデックスの更新
属性
近似
等価
部分文字列1
インデックス更新の合計
uid
1
1
cn
1
1
17
19
sn
1
1
9
11
1
1
telephoneNumber
1
11
12
description
47
47
ここでの description 文字列と同じぐらいの長さの文字列に対して、部分文字列インデックスを使用することは、ほとんどの場合でお勧めできません。
description に対する部分文字列インデックスの更新数 (47) が、ほかの全属性の更新数を合わせた数 (44) よりも大きいことに注意してください。また、description 文字列をさらに変更すると、更新回数が上限に達したり、新しい文字列への依存度が増加したりします。ほとんどの場合、description 値と同程度の長さの文字列に対して部分文字列インデックスを適用しないことで、この量の部分文字列インデックスを回避してください。
パフォーマンスに対するインデックスのチューニング
多くの場合、パフォーマンスに対してインデックスをチューニングするということは、インデックスをアクティブ化して頻繁に行われる検索の速度を上げること、および維持にコストがかかり、あまり頻繁に使用されないインデックスを無効にすることを指します。
注 データベースバックアップにはインデックスも含まれるため、Directory Server 設定に一致する必要があります。
インデックスの設定方法を変更したら、設定とデータの両方をバックアップしてください。
特定のアプリケーション専用のレプリカを含む大規模な導入では、Directory Server インスタンスごとに異なるインデックスを設定するように選択することができます。たとえば、次のようなトポロジがあるとします。
- 書き出しだけを処理するマスタ
- コンシューマに対するレプリカの負荷を処理するハブ
- メッセージングなど特定のアプリケーションを使用するコンシューマ
この場合のマスタは検索を処理しないため、たとえばコストのかかる部分文字列インデックスをマスタで保持しないようにすることができます。また、これまでほとんど使われていないほかのインデックスを無効にすることもできます。
ハブでは基本的に管理要求以外のクライアント要求を受信しません。そのため、Directory Server 自体で必要とするシステムインデックス以外のインデックスは無効にできます。
個別のアプリケーションだけを使用する特定のコンシューマに対しては、そのアプリケーションで使用しないインデックスをすべて無効にすることもできます。無効にするインデックスは、そのアプリケーションで実行される検索によって異なります。
インデックス検索だけを許可する
Directory Server では、コストのかかる、インデックスを使用しない検索を行わないようにすることが可能です。インデックスを使用しない検索を要求するクライアントには LDAP_UNWILLING_TO_PERFORM を返します。
特定のデータベースに対してインデックスを使用しない検索を許可しないようにするには、そのデータベースの nsslapd-require-index 属性値を on にします。
$ ldapmodify -h host -p port -D "cn=directory manager" -w password
dn:cn=example,cn=ldbm database, cn=plugins, cn=config
changetype:modify
replace:nsslapd-require-index
nsslapd-require-index:on
^D (Windows システムでは ^Z)変更内容はすぐに有効になります。Directory Server を再起動する必要はありません。
インデックスリストの長さを制限する
大規模で成長の速いディレクトリの導入では、特定のインデックスキーが効果がなくなる点に到達する可能性があります。効果がなくなる点では、あるキーに関連付けられたリストがとても長くなり、候補エントリのそのキーに対してときどき発生するインデックスされていない検索を実行するコストよりも、リストの維持にかかるコストの方がかかってしまいます。姓で等価インデックスされた大規模な電話帳アプリケーションを考えてみます。電話帳で Smith の個数が多すぎて、Smith のインデックスを維持するコストが、検索で得られる利益を上回ってしまうとします。このとき Directory Server では、Smith を姓でインデックスの作成を停止する必要があります。しかし Directory Server は別の姓のインデックスは継続する必要があります。
Directory Server にはこのような状況を処理するメカニズムが備わっています。設定属性にしきい値を設定します。あるキーに対するリスト内のエントリ数が設定した値になると、Directory Server では、そのキーの候補エントリを検索するために、インデックスされていない検索を実行する必要があると指定するトークンでキーのリストを置き換えます。表 9-1 で説明するように、この値は検索でチェックした候補エントリの最大数 (nsslapd-lookthroughlimit で設定) に近いが小さな値になります。
このメカニズムは 全 ID しきい値 (all IDs threshold) と呼ばれ、cn=config,cn=ldbm database,cn=plugins,cn=config の場合の nsslapd-allidsthreshold というグローバルしきい値を設定するための設定属性にちなんで名付けられています。この値は現在 Directory Server インスタンスに対してグローバルになっている点に注意してください。この値をインデックスごとに別々に設定することはできません。
nsslapd-allidsthreshold よりも多い個数の Smith で姓をインデックスを作成する例を、図 7-5 に示します。
図 7-5 インデックスキーの全 ID しきい値に到達する
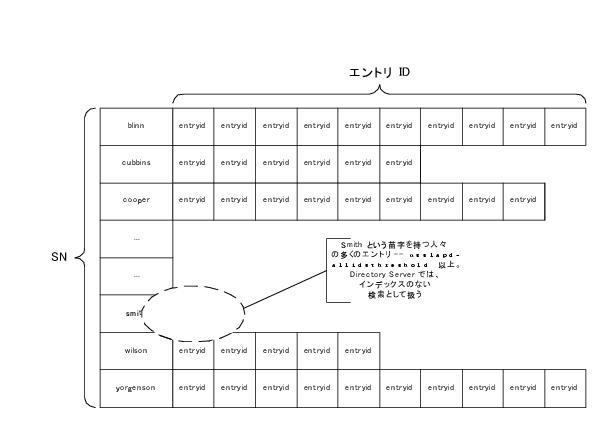
このしきい値は、このインデックステーブルでは 1 リストだけに影響します。ほかのキーのリストには影響しません。
不適切なインデックスリストサイズによる現象
クライアントが第 6 章「キャッシュサイズのチューニング」で説明するように、最初にインデックスされた検索を実行し、キャッシュサイズが適切にチューニングされている場合でも検索パフォーマンスが低いときは、不適切なしきい値がその原因である可能性があります。インデックスを使用した検索で検索パフォーマンスが低いときは、まずキャッシュサイズが適切にチューニングされていることを確認してください。次に、Directory Server が頻繁に全 ID しきい値に達しているかを確認するために、アクセスログを調べます。
アクセスログの RESULT メッセージの末尾にある notes=U フラグは、Directory Server がインデックスを使用しない検索を実行したことを示しています。同じ接続と操作における前の SRCH メッセージでは、使用する検索フィルタを指定します。次の 2 行では、10000 エントリを返す (cn=Smith) に対するインデックスを使用しない検索をトレースします。タイムスタンプはメッセージから削除されています。
conn=2 op=1 SRCH base="o=example.com" scope=0 filter="(cn=Smith)"
conn=2 op=1 RESULT err=0 tag=101 nentries=10000 notes=Uインデックスされているはずの検索でこのようなペアが多くある場合は、しきい値を増やすことで検索パフォーマンスを向上させることができる可能性があります。
インデックスリストのしきい値サイズを変更する
nsslapd-allidsthreshold の適切な値は、通常、ディレクトリのエントリ総数のうち、5% 程度です。たとえば、デフォルト値 4000 は、80,000 エントリ以下を処理する Directory Server インスタンスに対してほぼ適切です。近いうちに多数のエントリをディレクトリに追加する予定がある場合、またはディレクトリが非常に大きくなることが予想される場合は、合計の 5% よりも大幅に多い値を設定できます。また、ほとんどの場合で書き出しだけをサポートするマスタよりも多くの検索をサポートするコンシューマのレプリカに、異なるしきい値を設定することもできます。近いうちに大きなディレクトリを LDIF から再初期化する予定がある場合、再初期化の直前に nsslapd-allidsthreshold の値を調整することもできます。ただしこの属性の値に対する変更には、すべてのインデックスを再構築する必要があります。どのような場合でも、全 ID しきい値を非常に高く (50,000 より高く) 設定することは、適切で明確な理由がない限り、大規模導入であっても避けてください。
全 ID しきい値の変更は次のように行います。変更を行なっている間、Directory Server インスタンスはサービスを中断します。
- 当該の Directory Server インスタンスを停止します。
- すべてのディレクトリデータベースを LDIF にエクスポートします。
詳細は、『Sun ONE Directory Server 管理ガイド』を参照してください。
- ServerRoot/slapd-ServerID/config/dse.ldif の nsslapd-allidsthreshold 属性の値を慎重に調整します。
- すべてのディレクトリデータベースを LDIF から再初期化します。
詳細は、『Sun ONE Directory Server 管理ガイド』を参照してください。
- データベースキャッシュのサイズが古い全 ID しきい値でチューニングされていて、サーバーに十分な物理メモリがある場合は、データベースキャッシュのサイズをしきい値の増加分の 25% 増やしてみます。
つまり、全 ID しきい値を 4000 から 6000 に増やす場合は、データベースキャッシュのサイズを増加したインデックスリストのサイズの 12.5% 程度増やすことができます。変更を実際の運用サーバーに適用する前に、最適なサイズを経験的に見つけてください。データベースキャッシュのチューニングについて詳細は、第 6 章「キャッシュサイズのチューニング」を参照してください。
- Directory Server インスタンスを再起動します。
インデックスの断片化のトラブルシューティング
大規模インデックスと高い更新速度をサポートする Directory Server インスタンスでは、極端なインデックスキーの断片化を起こすおそれがあります。極端なインデックスキーの断片化が発生すると、データベースサイズが一定であってもパフォーマンスが低下することがあります。極端なインデックスキーの断片化がサーバーのパフォーマンスに深刻な影響を与えていると思われる理由がある場合は、影響を受けているインデックスを再生成して断片化を減らすことを検討してください。
インデックスを作成する方法については、『Sun ONE Directory Server 管理ガイド』を参照してください。