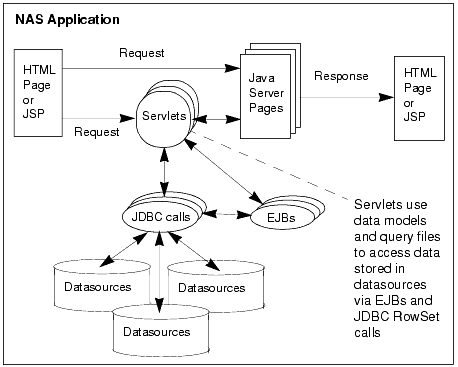
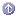While this chapter is not a JDBC primer, it does introduce you to using JDBC in EJBs with NAS 4.0. The following sections describe various JDBC interfaces and classes that have either have special requirements in the NAS environment, or that are new JDBC 2.0 features that you are especially encouraged to use when developing NAS server applications.
For example, "Working With Connections" describes what resources NAS releases when a connection is closed because that information differs among different JDBC implementations. On the other hand, "Pooling Connections" and "Working with Rowsets" offer more extensive coverage because these are new JDBC 2.0 features that offer increased power, flexibility, and speed for your server applications.
Working With Connections
When you open a connection in JDBC, NAS allocates resources for the connection. If you call Connection.close() when a connection is no longer needed, the connection resources are freed. Always reestablish connections before continuing database operations after you call Connection.close().
You can use Connection.isClosed() to test whether the connection is
closed. This method returns false if the connection is open, and returns true
only after Connection.close() is called.
You can determine if a database connection is invalid by catching the exception that is thrown when a JDBC operation is attempted on a closed connection.
Finally, opening and closing connections is an expensive operation. If your application uses several connections, and if connections are frequently opened and closed, NAS automatically provides connection pooling. Connection pooling provides a cache of connections that are automatically closed when necessary.
Note. Connection pooling is an automatic feature of NAS; the API is not exposed.
setTransactionIsolation
Not all database vendors support all levels of transaction isolation available in JDBC. NAS permits you to specify any isolation level your database supports, but throws an exception against values your database does not support. For more information, see Specifying Transaction Isolation Level.
getTypeMap, setTypeMap
The NAS implementation of the JDBC driver does not support type mapping, a new SQL-3 feature that most database vendors also do not support. The methods exist, but currently do nothing.
cancel
cancel() is supported for all databases.
Pooling Connections
Two of the costlier database operations you can execute in JDBC are for creating and destroying database connections. Connection pooling permits a single connection cache to be used for connection requests. When you use connection pooling, a connection is returned to the pool for later reuse without actually destroying it. A later call to create a connection merely retrieves an available connection from the pool instead of actually creating a new one.
NAS automatically provides JDBC connection pooling wherever you make JDBC calls.
Working with ResultSet
ResultSet is a class that encapsulates the data returned by a database query. Be aware of the following behaviors or limitations associated with this class.
Concurrency Support
NAS 4.0 supports concurrency for FORWARD-ONLY READ-ONLY result sets. On callable statements, NAS 4.0 also supports concurrency for FORWARD-ONLY UPDATABLE result sets.
NAS also supports concurrency for SCROLL-INSENSITIVE READ-ONLY result sets.
SCROLL-SENSITIVE concurrency is not supported.
Updatable Result Set Support
In NAS 4.0, creation of updatable result sets is restricted to queries on a single table. The SELECT query for an updatable result set must include the FOR UPDATE clause:
SELECT...FOR UPDATE [OF column_name_list]
Note. You can use join clauses to create read-only result sets against multiple tables;
these result sets are not updateable.
For Sybase, the select list must include a unique index column. Sybase also permits you to call execute() or executeQuery() to create an updatable result set, but the statement must be then be closed before you can execute any other SQL statements.
To use an updatable result set with Oracle 8, you must wrap the result set query in a transaction:
conn.setAutoCommit(false);
ResultSet rs =
stmt.executeQuery("SELECT...FOR UPDATE...");
...
rs.updateRows();
...
conn.commit();
For Microsoft SQL Server, if concurrency for a result set is CONCUR_UPDATABLE, the SELECT statement in the execute() or executeQuery() methods must not include the ORDER BY clause.
getCursorName
One method of ResultSet, getCursorName(), enables you to determine the name of the cursor used to fetch a result set. If a cursor name is not specified by the query itself, different database vendors return different information. NAS attempts to handle these differences as transparently as possible. The following table indicates the name of a cursor returned by different database vendors if no cursor name is specified in the initial query
.
getObject
NAS implements this JDBC method in a manner that only works with scalar data types. JDBC 2.0 adds additional versions of this method that include a map argument. NAS does not implement maps, and ignores the map argument if it is supplied.
getRef, getBlob, getClob, and getArray
References, blobs, clobs, and arrays are new SQL-3 data types. NAS does not implement these data objects or the methods that work with them. You can, however, work with references, blobs, clobs, and arrays using getBinaryStream() and setBinaryStream().
Working with ResultSetMetaData
The getTableName() method only returns meaningful information for OBDC-compliant databases. For all other databases, this method returns an empty string.
Working with PreparedStatement
PreparedStatement is a class that encapsulates a query, update, or insert statement that is used repeatedly to fetch data. Be aware of the following behaviors or limitations associated with this class.
Note.
You can use the NAS feature SqlUtil.loadQuery() to load a NASRowSet with a prepared statement. For more information, see the entry for the SqlUtil class in the NAS Foundation Class Reference.
setObject
This method may only be used with scalar data types.
addBatch
This method enables you to gang a set of data manipulation statements together to pass to the database as if it were a single statement. addBatch() only works with SQL data manipulation statements that return a count of the number of rows updated or inserted. Contrary to the claims of the JDBC 2.0 specification, addBatch() does not work with any SQL data definition statements such as CREATE TABLE.
setRef, setBlob, setClob, setArray
References, blobs, clobs, and arrays are new SQL-3 data types. NAS does not implement these data objects or the methods that work with them. You can, however, work with references, blobs, clobs, and arrays using getBinaryStream() and setBinaryStream().
getMetaData
Not all database systems return complete metadata information. See your database vendor's documentation to determine what kind of metadata your database provides to clients.
Working with CallableStatement
CallableStatement is a class that encapsulates a database procedure or function call for databases that support returning result sets from stored procedures. Be aware of the following limitation associated with this class. The JDBC 2.0 specfication states that callable statements can return an updatable result set. This feature is not supported in NAS.
getRef, getBlob, getClob, getArray
References, blobs, clobs, and arrays are new SQL-3 data types. NAS does not implement these data objects or the methods that work with them. You can, however, work with references, blobs, clobs, and arrays using getBinaryStream() and setBinaryStream().
Handling Batch Updates
The JDBC 2.0 Specification provides for a batch update feature that allows for an application to pass multiple SQL update statements (INSERT, UPDATE, DELETE) in a single request to a database. This ganging of statements can result in a significant increase in performance when a large number of update statements are pending.
The Statement class includes two new methods for executing batch updates:
In order to use batch updates, your application must disable auto commit options:
...
// turn off autocommit to prevent each statement from commiting
separately
con.setAutoCommit(false);
Statement stmt = con.createStatement();
stmt.addBatch("INSERT INTO employees VALUES(4671, 'James Williams')");
stmt.addBatch("INSERT INTO departments VALUES(560, 'Produce')");
stmt.addBatch("INSERT INTO emp_dept VALUES( 4671, 560)");
//submit the batch of updates for execution
int[] updateCounts = stmt.executeBatch();
con.commit();
To remove all ganged statements from a batch operation before executeBatch() is called, (for example, because an error is detected), call clearBatch().
Note. The JDBC 2.0 specification erroneously implies that batch updates can include
data definition language (DDL) statements such as CREATE TABLE. DDL
statements do not return a simple update count, and so cannot be grouped for
a batch operation. Also, some databases do not allow data definintion
statements in transactions.
Creating Distributed Transactions
The JDBC 2.0 Specification provides the capability for handling distributed transactions. A distributed transaction is a single transaction that applies to multiple, heterogeneous databases that may reside on separate server machines.
Distributed transaction support is already built into the NAS 4.0 EJB container, so if you use EJBs that do not specify the TX_BEAN_MANAGED transaction attribute, you get automatic support for distributed transactions in your application.
In servlets and in EJBs that specify the TX_BEAN_MANAGED transaction attribute, you can still use distributed transactions, but you must manage transactions using the JTS UserTransaction class. For example:
InitialContext ctx = null;
String dsName1 = "jdbc/SampleDS1";
String dsName2 = "jdbc/SampleDS2";
DataSource ds1 = null;
DataSource ds2 = null;
try {
ctx = new InitialContext();
ds1 = (DataSource)ctx.lookup(dsName1);
ds2 = (DataSource)ctx.lookup(dsName2);
} catch(Exception e) {
e.printStackTrace(System.out);
}
UserTransaction tx = ejbContext.getUserTransaction();
tx.begin();
Connection conn1 = ds1.getConnection();
Connection conn2 = ds2.getConnection();
// do some work here
tx.commit();
In this example, ds1 and ds2 must be registered with NAS as global datasources. In other words, their datasource properties files must include a ResourceMgr entry whose value must be configured at install time.
For example a global database properties file looks like:
DataBase=ksample
DataSource=ksample
UserName=kdemo
PassWord=kdemo
DriverType=ORACLE_OCI
ResourceMgr=orarm
In this example, orarm must be a valid ResourceMgr entry and must be enabled to get a global connection successfully. In order to be a valid ResourceMgr entry, an resource manager must be listed the registry in CCS0\RESOURCEMGR, and the entry itself must have the following properties.
DatabaseType (string key)
IsEnabled (integer type)
Openstring ( string type key)
ThreadMode ( string type key)
Working with Rowsets
A rowset is an object that encapsulates a set of rows retrieved from a database or other tabular data store, such as a spreadsheet. To implement a rowset, your code must import javax.sql, and implement the RowSet interface. RowSet extends the java.sql.ResultSet interface, permitting it to act as a JavaBeans component.
Because a RowSet is a JavaBean, you can implement events for the rowset, and you can set properties on the rowset. Furthermore, because RowSet is an extension of ResultSet, you can iterate through a rowset just as you would iterate through a result set.
You fill a rowset by calling the RowSet.execute() method. The execute() method uses property values to determine the datasource and retrieve data. The actual properties you must set and examine depends upon the implementation of RowSet you invoke.
For more information about the RowSet interface, see the JDBC 2.0 Standard Extension API Specification.
Using NASRowSet
NAS 4.0 provides a rowset class called NASRowSet. NASRowSet extends ResultSet, so call methods are inherited from the ResultSet object. NASRowSet overrides the getMetaData() and close() methods of ResultSet.
The RowSet interface is fully supported except as noted in the following table.
RowSetReader
NASRowSet provides a full implementation of the RowSetReader class.
RowSetWriter
NASRowSet is read-only, but an interface for this class is provided for future expansion. At present, its only method, writeData() throws SQLException.
RowSetInternal
This internal class is used by RowSetReader to retrieve information about the RowSet. It has a single method, getOriginalRow(), which returns the original result set instead of a single row.
Using CachedRowSet
The JDBC specification provides a rowset class called CachedRowSet. CachedRowSet permits you to retrieve data from a datasource, then detach from the datasource while you examine, and modify the data. A cached rowset keeps track both of the original data retrieved, and any changes made to the data by your application. If the application attempts to update the original datasource, the rowset is reconnected to the datasource, and only those rows that have changed are merged back into the database.
Creating a RowSet
There are two ways to create a rowset in a NAS server application:
To create a NAS-dependent rowset:
NASRowSet rs = new NASRowSet();
To create a NAS-independent rowset:
Look up the class that implements the RowSet interface using InitialContext():
InitialContext ctx = new InitialContext();
RowSet rs = (javax.sql.RowSet) ctx.lookup("javax.sql.RowSet");
Using JNDI
JDBC 2.0 specifies that you can use the Java Naming and Directory Interface (JNDI) to provide a uniform, platform and JDBC vendor-independent way for your applications to find and access remote services over the network. For example, all JDBC driver managers, such as the JDBC driver manager implemented in NAS 4.0, must find and access a JDBC driver by looking up the driver and a JDBC URL for connecting to the database. For example:
Class.forName("SomeJDBCDriverClassName");
Connection con =
DriverManager.getConnection("jdbc:NAS_subprotocol:machineY:portZ");
This code illustrates how a JDBC URL may not only be specific to a particular vendor's JDBC implementation, but also to a specific machine and port number. Such hard-coded dependencies make it hard to write portable applications that can easily be shifted to different JDBC implementations and machines at a later time.
In place of this hard-coded information, JNDI permits you to assign a logical name to a particular datasource. Once you establish the logical name, you need only modify it a single time to change the deployment and location of your application.
JDBC 2.0 specifies that all JDBC datasources should be registered in the jdbc naming subcontext of a JNDI namespace, or in one of its child subcontexts. The JNDI namespace is hierarchical, like a file system's directory structure, so it is easy to find and nest references. A datasource is bound to a logical JNDI name. The name identifies a subcontext, "jdbc", of the root context, and a logical name. In order to change the datasource, all you need to do is change its entry in the JNDI namespace without having to modify a line of code in your application.
For more information about JNDI, see the JDBC 2.0 Standard Extension API.