Chapter 13
Session Management Service
- Overview of the Predefined Objects
- The request Object
- The client Object
- The project Object
- The server Object
- Techniques for Maintaining the client Object
- Sharing Objects Safely with Locking
request, client, project, and server.
In addition, you can construct instances of Lock to control access during the sharing of information. Lock instances provide you with fine-grained control over information sharing by getting exclusive access to specified objects.
Overview of the Predefined Objects
The predefinedrequest, client, project, and server objects contain data that persists for different periods and is available to different clients and applications. There is one server object shared by all running applications on the server. There is a separate project object for each running application. There is one client object for each browser (client) accessing a particular application. Finally, there is a separate request object for each client request from a particular client to a particular application. Figure 13.1 illustrates the relative availability of the different objects.
Figure 13.1 Relative availability of session-management objects
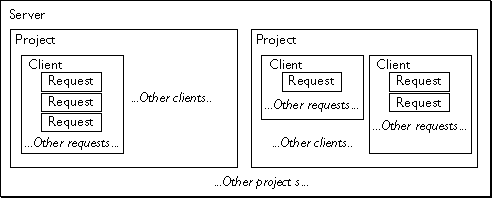
-
requestobject
Contains data available only to the current client request. Nothing else shares this object. The -
clientobject
Contains data available only to an individual client/application pair. If a single client is connected to two different applications at the same time, the JavaScript runtime engine constructs a separate -
projectobject
Contains data that is available to all clients accessing any part of the application. All clients accessing the same application share the same -
serverobject
Contains data available to all clients and all applications for the entire server. All applications and all client/application pairs share the same
request object has predefined properties you can access.
Treat the request object almost as a read-only object. The runtime engine stores the current value of all form elements as properties of the request object. You can use it to store information specific to a single request, but it is more efficient to use JavaScript variables for this purpose.
request object each time the server responds to a client request from the web browser. It destroys the object at the end of the client request. The runtime engine does not save request data at all.
For more details, see "The request Object" on page 239.client object for each client/application pair. All requests from a single client to the same application share the same client object. The client object has no predefined properties.
In general, use the client object for data that should be shared across multiple requests from the same client (user) but that should not be shared across multiple clients of the application. For example, you can store a user's customer ID as a property of the client object.
client object for each client request, but properties persist across the lifetime of the client's connection to the application. Therefore, although the physical client object exists only for a single client request, conceptually you can think of it as being constructed when the client is first connected to the application, and not destroyed until the client stops accessing the application. There are several approaches to maintaining the properties of the client object across multiple requests. For more information, see "Techniques for Maintaining the client Object" on page 253.
The runtime engine destroys the client object when the client has finished using the application. In practice, it is tricky for the JavaScript runtime engine to determine when the client object and its properties should be destroyed. For information on how it makes this determination, see "The Lifetime of the client Object" on page 264. Also, see "The client Object" on page 242.project object. The project object has no predefined properties.
In general, use the project object to share data among multiple clients accessing the same application. For example, you can store the next available customer ID as a property of the project object. When you use the project object to share data, you need to be careful about simultaneous access to that data; see "Sharing Objects Safely with Locking" on page 268. Because of limitations on the client object's properties, you sometimes use the project object to store data for a single client.
project object when the application is started by the Application Manager or when the server is started. It destroys the object when the application or the server is stopped.
For more details, see "The project Object" on page 250.server object. The server object has predefined properties you can access.
Use the server object to share data among multiple applications on the server. For example, you might use the server object to track usage of all of the applications on your server. When you use the server object to share data, you need to be careful about simultaneous access to that data; see "Sharing Objects Safely with Locking" on page 268.
server object when the server is started and destroys the object when the server is stopped.
For more details, see "The server Object" on page 251.
Figure 13.2 Predefined objects in a URL
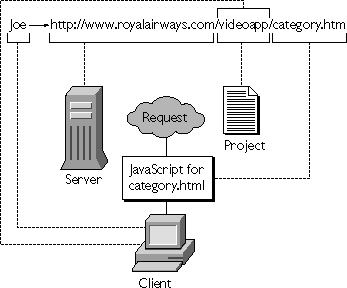
http://www.royalairways.com/videoapp/category.html, corresponding to a page in the videoapp sample application. When the runtime engine receives the request, it uses the already-existing server object corresponding to www.royalairways.com and the already-existing project object corresponding to the videoapp application. The engine creates a client object corresponding to the combination of Joe and the videoapp application. If Joe has already accessed other pages of this application, this new client object uses any stored properties. Finally, the engine creates a new request object for the specific request for the category.html page.
The request Object
Therequest object contains data specific to the current client request. It has the shortest lifetime of any of the objects. JavaScript constructs a new request object for each client request it receives; for example, it creates an object when
- A user manually requests a URL by typing it in or choosing a bookmark.
- A user clicks a hyperlink or otherwise requests a document that refers to another page.
-
Client-side JavaScript sets the property
document.locationor navigates to the page using thehistorymethod. -
Server-side JavaScript calls the
redirectfunction.
request object when it finishes responding to the request (typically by providing the requested page). Therefore, the typical lifetime of a request object can be less than one second.
NOTE: You cannot use theFor summary information on therequestobject on your application's initial page. This page is run when the application is started on the server. At this time, there is no client request, and so there is no availablerequestobject. For more information on initial pages, see "Installing a New Application" on page 59.
request object, see "Overview of the Predefined Objects" on page 236.
Properties
The following table lists the predefined properties of therequest object. Several of these predefined properties correspond to CGI environment variables. You can also access these and other CGI environment variables using the ssjs_getCGIVariable function described in "Accessing CGI Variables" on page 218.
Table 13.1 Properties of the request object
1
For HTTP 1.0, method is one of GET, POST, or HEAD.
|
request properties. For example, this declaration persists during the current request only:
var number = 42;In addition to the predefined properties, you can, in your client code, have information that will become properties of the
request object. You do so by using form elements and by encoding properties into the request URL, as described "Sending Values from Client to Server" on page 223.
Although you can also create additional properties for request directly in server-side JavaScript statements, performance may be better if you instead use JavaScript variables. The properties of the request object you create can be of any legal JavaScript type, including references to other JavaScript objects.
Remember that the lifetime of the request object and hence of its properties is the duration of the request. If you store a reference to another object in the request object, the referenced object is destroyed at the end of the request along with the request object, unless the referenced object has other live references to it, directly or indirectly from the server or project object.
Working with Image Maps
TheISMAP attribute of the IMG tag indicates a server-based image map. If the user clicks on an image map, the horizontal and vertical positions of the cursor are sent to the server. The imageX and imageY properties return these horizontal and vertical positions. Consider this HTML:
<A HREF="mapchoice.html">The page
<IMG SRC="images\map.gif" HEIGHT=599 WIDTH=424 BORDER=0
ISMAP ALT="SANTA CRUZ COUNTY">
</A>
mapchoice.html has properties request.imageX and request.imageY based on the cursor position at the time the user clicked.
The client Object
Many browser clients can access a JavaScript application simultaneously. Theclient object provides a method for dealing with each browser client individually. It also provides a technique for tracking each browser client's progress through an application across multiple requests.
The JavaScript runtime engine on the server constructs a client object for every client/application pair. A browser client connected to one application has a different client object from the same browser client connected to a different application. The runtime engine constructs a new client object each time a user accesses an application; there can be hundreds or thousands of client objects active at the same time.
NOTE: You cannot use theThe runtime engine constructs and destroys theclientobject on your application's initial page. This page is run when the application is started on the server. At this time, there is no client request, and so there is no availableclientobject. For more information on initial pages, see "Installing a New Application" on page 59.
client object for each client request. However, while processing a request, the runtime engine saves the names and values of the client object's properties. In this way, the runtime engine can construct a new client object from the saved data when the same user returns to the application with a subsequent request. Thus, conceptually you can think of the client object as remaining for the duration of a client's session with the application.
JavaScript does not save client objects that have no property values. Therefore, if an application does not need client objects and does not assign any client object property values, it incurs no additional overhead.
You have several options for how and where the runtime engine saves client object properties. These options are discussed in "Techniques for Maintaining the client Object" on page 253.
For summary information on the client object, see "Overview of the Predefined Objects" on page 236.
Properties
There are no predefined property values in theclient object, because it is intended to contain data specific to the application. JavaScript statements can assign application-specific properties and values to the client object. A good example of a client object property is a customer ID number. When the user first accesses the application, the application might assign a customer ID, as in the following example:
client.custID = getNextCustID();This example uses the application-defined
getNextCustID function to compute a customer ID. The runtime engine then assigns this ID to the client object's custID property.
Once the customer ID has been established, it would be inconvenient to require the user to reenter the ID on each page of the application. However, without the client object, there would be no way to associate the correct customer ID with subsequent requests from a client.
Because of the techniques used to maintain client properties across multiple client requests, there is one major restriction on client property values. The JavaScript runtime engine on the server converts the values of all of the client object's properties to strings.
Do not assign an object as the value of a client property. If you do so, the runtime engine converts that object to a string; once this happens, you won't be able to work with it as an object anymore. If a client property value represents another data type, such as a number, you must convert the value from a string before using it. For example, you can create an integer client property as follows:
client.totalNumber = 17;You could then use
parseInt to increment the value of totalNumber as follows:
client.totalNumber = parseInt(client.totalNumber) + 1;Similarly, you can create a Boolean
client property as follows:
client.bool = true;Then you can check it as follows:
if (client.bool == "true")Notice that the conditional expression compares
write("It's true!");
else
write("It's false!");
client.bool to the string "true". You can use other techniques to handle Boolean expressions. For example, to negate a Boolean property, you can use code like this:
client.bool = (client.bool == "true") ? false : true;Although you can work with
client properties directly, you incur some overhead doing so. If you repeatedly use the value of a client property, consider using top-level JavaScript variables. Before using the client property, assign it to a variable. When you have finished working with that variable, assign the resulting value back to the appropriate client property. This technique can result in a substantial performance improvement.
As noted previously, you cannot store references to other objects in the client object. You can, however, store object references in either the project or the server object. If you want a property associated with the client to have object values, create an array indexed by client ID and store a reference to the array in the project or server object. You can use that array to store object values associated with the client. Consider the following code:
if client.id == nullThis code uses the
client.id = ssjs_generateClientID();
project.clientDates[client.id] = new Date();
ssjs_generateClientID function, described next, to create a unique ID for this client object. It uses that ID as an index into the clientDates array on the project object and stores a new Date object in that array associated with the current client object.
Uniquely Referring to the client Object
For some applications, you may want to store information specific to a client/application pair in theproject or server objects. Two common cases are storing a database connection between client requests (described in Chapter 15, "Connecting to a Database") or storing a custom object that has the same lifetime as the predefined client object and that contains object values (described in "Creating a Custom client Object" on page 246).
In these situations, you need a way to refer uniquely to the client/application pair. JavaScript provides two functions for this purpose, ssjs_getClientID and ssjs_generateClientID. Neither function takes any arguments; both return a unique string you can use to identify the pair.
Each time you call ssjs_generateClientID, the runtime engine returns a new identifier. For this reason, if you use this function and want the identifier to last longer than a single client request, you need to store the identifier, possibly as a property of the client object. For an example of using this function, see "Sharing an Array of Connection Pools" on page 309.
If you use this function and store the ID in the client object, you may need to be careful that an intruder cannot get access to that ID and hence to sensitive information.
An alternative approach is to use the ssjs_getClientID function. If you use one of the server-side maintenance techniques for the client object, the JavaScript runtime engine generates and uses a identifier to access the information for a particular client/application pair. (For information on maintaining the client object, see "Techniques for Maintaining the client Object" on page 253.)
When you use these maintenance techniques, ssjs_getClientID returns the identifier used by the runtime engine. Every time you call this function from a particular client/application pair, you get the same identifier. Therefore, you do not need to store the identifier returned by ssjs_getClientID. However, if you use any of the other maintenance techniques, this function returns "undefined"; if you use those techniques you must instead use the ssjs_generateClientID function.
If you need an identifier and you're using a server-side maintenance technique, you probably should use the ssjs_getClientID function. If you use this function, you do not need to store and track the identifier yourself; the runtime engine does it for you. However, if you use a client-side maintenance technique, you cannot use the ssjs_getClientID function; you must use the ssjs_generateClientID function.
Creating a Custom client Object
As discussed in earlier sections, properties of the predefinedclient object can have only string values. This restriction can be problematic for some applications. For instance, your application may require an object that persists for the same lifetime as the predefined client object, but that can have objects or other data types as property values. In this case, you can create your own object and store it as a property of the client object.
This section provides an example of creating such an object. You can include the code in this section as a JavaScript file in your application. Then, at the beginning of pages that need to use this object, include the following statement:
var customClient = getCustomClient()(Of course, you can use a different variable name.) If this is the first page that requests the object,
getCustomClient creates a new object. On other pages, it returns the existing object.
This code stores an array of all the custom client objects defined for an application as the value of the customClients property of the predefined project object. It stores the index in this array as a string value of the customClientID property of the predefined client object. In addition, the code uses a lock stored in the customClientLock property of project to ensure safe access to that array. For information on locking, see "Sharing Objects Safely with Locking" on page 268.
The timeout variable in the getCustomClient function hard-codes the expiration period for this object. If you want a different expiration time, specify a different value for that variable. Whatever expiration time you use, you should call the predefined client object's expiration method to set its expiration to the same time as specified for your custom object. For information on this method, see "The Lifetime of the client Object" on page 264.
To remove all expired custom client objects for the application, call the following function:
expireCustomClients()That's all there is to it! If you use this code, the predefined
client and project objects have these additional properties that you should not change:
You can customize the custom class by changing its onInit and onDestroy methods. As shown here, those methods are just stubs. You can add code to modify what happens when the object is created or destroyed.
Here's the code:
// This function creates a new custom client object or retrieves
// an existing one.
function getCustomClient()
{
// ==========> Change the hardcoded hold period <==========
// Note: Be sure to set the client state maintenance
// expiration to the same value you use below by calling
// client.expiration. That allows the index held in the predefined
// client object to expire about the same time as the state held in
// the project object.
var timeout = 600;
var customClient = null;
var deathRow = null;
var newObjectWasCreated = false;
var customClientLock = getCustomClientLock();
customClientLock.lock();
var customClientID = client.customClientID;
if ( customClientID == null ) {
customClient = new CustomClient(timeout);
newObjectWasCreated = true;
}
else {
var customClients = getCustomClients();
customClient = customClients[customClientID];
if ( customClient == null ) {
customClient = new CustomClient(timeout);
newObjectWasCreated = true;
}
else {
var now = (new Date()).getTime();
if ( customClient.expiration <= now ) {
delete customClients[customClientID];
deathRow = customClient;customClient = new CustomClient(timeout);
newObjectWasCreated = true;
}
else {
customClient.expiration = (new Date()).getTime() +
timeout*1000;
}
}
}
if ( newObjectWasCreated )
customClient.onInit();
customClientLock.unlock();
if ( deathRow != null )
deathRow.onDestroy();
return customClient;
}
// Function to remove old custom client objects.
function expireCustomClients()
{
var customClients = getCustomClients();
var now = (new Date()).getTime();
for ( var i in customClients ) {
var clientObj = customClients[i];
if ( clientObj.expiration <= now ) {
var customClientLock = getCustomClientLock();
customClientLock.lock();
if ( clientObj.expiration <= now ) {
The project Object
Theprojectobject contains global data for an application and provides a method for sharing information among the clients accessing the application. JavaScript constructs a newprojectobject when an application is started using the Application Manager. Each client accessing the application shares the sameprojectobject. For summary information on theprojectobject, see "Overview of the Predefined Objects" on page 236. In this release the JavaScript runtime engine does not, as in previous releases, create or destroy theprojectobject for each request. When you stop an application, that application'sprojectobject is destroyed. A newprojectobject is created for it when the application is started again. A typicalprojectobject lifetime is days or weeks. JavaScript constructs a set ofprojectobjects for each Netscape HTTP process running on the server. JavaScript constructs aprojectobject for each application running on each distinct server. For example, if one server is running on port 80 and another is running on port 142 on the same machine, JavaScript constructs a distinct set ofprojectobjects for each process.Properties
There are no predefined properties for theprojectobject, because it is intended to contain application-specific data accessible by multiple clients. You can create properties of any legal JavaScript type, including references to other JavaScript objects. If you store a reference to another object in theprojectobject, the runtime engine does not destroy the referenced object at the end of the client request during which it is created. The object is available during subsequent requests. A good example of aprojectobject property is the next available customer ID. An application could use this property to track sequentially assigned customer IDs. Any client that accesses the application without a customer ID would be assigned an ID, and the value would be incremented for each initial access. Remember that theprojectobject exists only as long as the application is running on the server. When the application is stopped, theprojectobject is destroyed, along with all of its property values. For this reason, if you have application data that needs to be stored permanently, you should store it either in a database (see Part 4, "LiveWire Database Service") or in a file on the server (see "File System Service" on page 280).Sharing the project Object
There is oneprojectobject for each application. Thus, code executing in any request for a given application can access the sameprojectobject. Because the server is multithreaded, there can be multiple requests active at any given time, either from the same client or from several clients. To maintain data integrity, you must make sure that you have exclusive access to a property of theprojectobject when you change the property's value. There is no implicit locking as in previous releases; you must request exclusive access. The simplest way to do this is to use theprojectobject'slockandunlockmethods. For details, see "Sharing Objects Safely with Locking" on page 268.The server Object
Theserverobject contains global data for the entire server and provides a method for sharing information between several applications running on a server. Theserverobject is also automatically initialized with information about the server. For summary information on theserverobject, see "Overview of the Predefined Objects" on page 236. The JavaScript runtime engine constructs a newserverobject when the server is started and destroys theserverobject when the server is stopped. Every application that runs on the server shares the sameserverobject. JavaScript constructs aserverobject for each Netscape HTTPD process (server) running on a machine. For example, there might be a server process running for port 80 and another for port 8080. These are entirely distinct server processes, and JavaScript constructs aserverobject for each.Properties
The following table describes the properties of theserverobject.
| Property | Description |
Example
hostname www.netscape.com:85 host www.netscape.com protocol http: port 85 jsVersion 3.0 WindowsNT |
|---|
jsVersion property to conditionalize features based on the server platform (or version) on which the application is running, as demonstrated here:
if (server.jsVersion == "3.0 WindowsNT")In addition to these automatically initialized properties, you can create properties to store data to be shared by multiple applications. Properties may be of any legal JavaScript type, including references to other JavaScript objects. If you store a reference to another object in the
write ("Application is running on a Windows NT server.");
server object, the runtime engine does not destroy the referenced object at the end of the request during which it is created. The object is available during subsequent requests.
Like the project object, the server object has a limited lifetime. When the web server is stopped, the server object is destroyed, along with all of its property values. For this reason, if you have application data that needs to be stored permanently, you should store it either in a database (see Part 4, "LiveWire Database Service") or in a file on the server (see "File System Service" on page 280).
Sharing the server Object
There is oneserver object for the entire server. Thus, code executing in any request, in any application, can access the same server object. Because the server is multithreaded, there can be multiple requests active at any given time. To maintain data integrity, you must make sure that you have exclusive access to the server object when you make changes to it.
Also, you must make sure that you have exclusive access to a property of the server object when you change the property's value. There is no implicit locking as in previous releases; you must request exclusive access. The simplest way to do this is to use the server object's lock and unlock methods. For details, see "Sharing Objects Safely with Locking" on page 268.
Techniques for Maintaining the client Object
Theclient object is associated with both a particular application and a particular client. As discussed in "The client Object" on page 242, the runtime engine creates a new client object each time a new request comes from the client to the server. However, the intent is to preserve client object properties from one request to the next. In order to do so, the runtime engine needs to store client properties between requests.
There are two basic approaches for maintaining the properties of the client object; you can maintain them either on the client or on the server. The two client-side techniques either store the property names and their values as cookies on the client or store the names and values directly in URLs on the generated HTML page. The three server-side techniques all store the property names and their values in a data structure in server memory, but they differ in the scheme used to index that data structure.
You select the technique to use when you use the JavaScript Application Manager to install or modify the application, as explained in "Installing a New Application" on page 59. This allows you (or the site manager) to change the maintenance technique without recompiling the application. However, the behavior of your application may change depending on the client-maintenance technique in effect, as described in the following sections. Be sure to make clear to your site manager if your application depends on using a particular technique. Otherwise, the manager can change this setting and break your application.
Because some of these techniques involve storing information either in a data structure in server memory or in the cookie file on the client, the JavaScript runtime engine additionally needs to decide when to get rid of those properties. "The Lifetime of the client Object" on page 264 discusses how the runtime engine makes this decision and describes methods you can use to modify its behavior.
Comparing Client-Maintenance Techniques
Each maintenance technique has its own set of advantages and disadvantages and what is a disadvantage in one situation may be an advantage in another. You should select the technique most appropriate for your application. The individual techniques are described in more detail in subsequent sections; this section gives some general comparisons. The following table provides a general comparison of the client-side and server-side techniques.Table 13.3 Comparison of server-side and client-side maintenance techniques
Figure 13.3 Client-side techniques
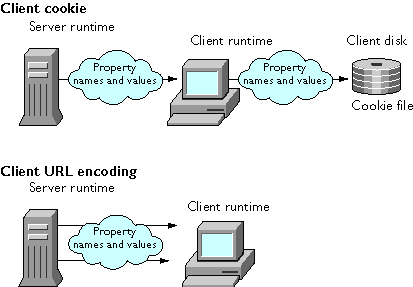
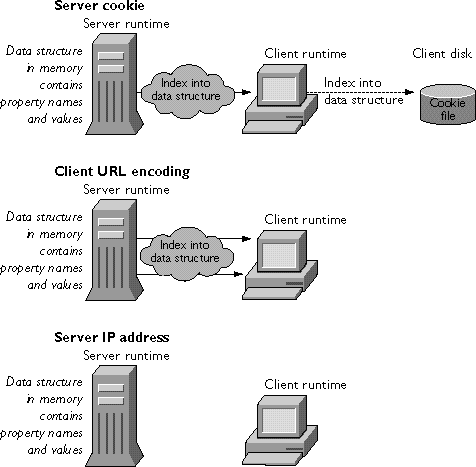
Figure 13.4 Server-side techniques
client object. By contrast, the client cookie technique creates a separate cookie for each property of the client object. The client cookie technique is therefore more likely to be affected by the limit of 20 cookies per application.
With the client cookie technique, the client object properties are sent to the client when the first piece of the HTML page is sent. If you change client property values later in the execution of that page, those changes are not sent to the client and so are lost. This restriction does not apply to any other maintenance technique.
For both techniques that use URL encoding, if your application constructs a URL at runtime or uses the redirect function, it must either manually append any client properties that need to be saved or use addClient to have the runtime engine append the properties. Although appending properties is not required for other techniques, you might want to do it anyway, so that changing the maintenance technique does not break your application.
In addition, for the URL encoding techniques, as soon as the browser accesses any page outside the application, or even submits a form to the application using the GET method, all client properties are lost. Properties are not lost this way for the other techniques. Your choice of technique should be partially guided by whether or not you want client properties to be persist in these situations.
Your choice of maintenance technique rests with the requirements of your application. The client cookie technique does not use extra server memory (as do the server-side techniques) and sends information only once per page (in contrast to the client URL encoding technique). These facts may make the client cookie technique appropriate for high-volume Internet applications. However, there are circumstances under which another technique is more suitable. For example, server IP address is the fastest technique, causing no increase in network traffic. You may use it for a speed-critical application running on your intranet.
Client-Side Techniques
There are two client-side maintenance techniques: For a comparison of all of the maintenance techniques, see "Comparing Client-Maintenance Techniques" on page 254. When an application uses client-side maintenance techniques, the runtime engine encodes properties of theclient object into its response to a client request, either in the header of the response (for client cookie) or in URLs in the body of the response (for client URL encoding).
Because the actual property names and values are sent between the client and the server, restarting the server does not cause the client information to be lost. However, sending this information causes an increase of network traffic.
Using Client Cookie
In the client cookie technique, the JavaScript runtime engine on the server uses the Netscape cookie protocol to transfer the properties of theclient object and their values to the client. It creates one cookie per client property. The properties are sent to the client once, in the response header of the generated HTML page. The Netscape cookie protocol is described in the Client-Side JavaScript Guide.
To avoid conflicts with other cookies you might create for your application, the runtime engine creates a cookie name by adding NETSCAPE_LIVEWIRE. to the front of the name of a client property. For example, if client has a property called custID, the runtime engine creates a cookie named NETSCAPE_LIVEWIRE.custID. When it sends the cookie information to the client, the runtime engine performs any needed encoding of special characters in a property value, as described in the Client-Side JavaScript Guide.
Sometimes your application needs to communicate information between its JavaScript statements running on the client and those running on the server. Because this maintenance technique sends client object properties as cookies to the client, you can use it as a way to facilitate this communication. For more information, see "Communicating Between Server and Client" on page 222.
With this technique, the runtime engine stores client properties the first time it flushes the internal buffer containing the generated HTML page. For this reason, to prevent losing any information, you should assign all client property values early in the scripts on each page. In particular, you should ensure that client properties are set before (1) the runtime engine generates 64KB of content for the HTML page (it automatically flushes the output buffer at this point), (2) you call the flush function to clear the output buffer, or (3) you call the redirect function to change client requests. For more information, see "Flushing the Output Buffer" on page 217 and "Runtime Processing on the Server" on page 211.
By default, when you use the client cookie technique, the runtime engine does not explicitly set the expiration of the cookies. In this case, the cookies expire when the user exits the browser. (This is the default behavior for all cookies.) As described in "The Lifetime of the client Object" on page 264, you can use the client object's expiration method to change this expiration period. If you use client.expiration, the runtime engine sets the cookie expiration appropriately in the cookie file.
When using the client cookie technique, client.destroy eliminates all client property values but does not affect what is stored in the cookie file on the client machine. To remove the cookies from the cookie file or browser memory, do not use client.destroy; instead, use client.expiration with an argument of 0 seconds.
In general, Netscape cookies have the following limitations. These limitations apply when you use cookies to store client properties:
-
4KB for each cookie (including both the cookie's name and its value). If a single cookie is longer than 4KB, the cookie entry is truncated to 4KB. This may result in an invalid
clientproperty value. -
20 cookies for each application. If you create more than 20 cookies for an application, the oldest (first created) cookies are eliminated. Because the client cookie technique creates a separate cookie for each
clientproperty, theclientobject can store at most 20 properties. If you want to use other cookies in your application as well, the total number of cookies is still limited to 20. - 300 total cookies in the cookie file. If you create more than 300 cookies, the oldest (first created) cookies are eliminated.
Using Client URL Encoding
In the client URL encoding technique, the runtime engine on the server transmits the properties of theclient object and their values to the client by appending them to each URL in the generated HTML page. Consequently, the properties and their values are sent as many times as there are links on the generated HTML page, resulting in the largest increase in network traffic of all of the maintenance techniques.
The size of a URL string is limited to 4KB. Therefore, when you use client URL encoding, the total size of all the property names and their values is somewhat less than 4KB. Any information beyond the 4KB limit is truncated.
If you generate URLs dynamically or use the redirect function, you can add client properties or other properties to the URL. For this reason, whenever you call redirect or generate your own URL, the compiler does not automatically append the client properties for you. If you want client properties appended, use the addClient function. For more information, see "Manually Appending client Properties to URLs" on page 266.
In the client URL encoding technique, property values are added to URLs as those URLs are processed. You need to be careful if you expect your URLs to have the same properties and values. For example, consider the following code:
<SERVER>When the runtime engine processes the first
...
client.numwrites = 2;
write (addClient(
"<A HREF='page2.htm'>Some link</A>"));
client.numwrites = 3;
write (addClient(
"<A HREF='page3.htm'>Another link</A>"));
...
</SERVER>
write statement, it uses 2 as the value of the numwrites property, but when it processes the second write statement, it uses 3 as the value.
Also, if you use the client.destroy method in the middle of a page, only those links that come before the method call have property values appended to their URLs. Those that come after the method call do not have any values appended. Therefore, client property values are propagated to some pages but not to others. This may be undesirable.
If your page has a link to a URL outside of your application, you may not want the client state appended. In this situation, do not use a static string as the HREF value. Instead, compute the value. This prevents the runtime engine from automatically appending the client state to the URL. For example, assume you have this link:
<A HREF="mailto:me@royalairways.com">In this case, the runtime engine appends the
client object properties. To instead have it not do so, use this very similar link:
<A HREF=`"mailto:me@royalairways.com"`>In this technique, the
client object does not expire, because it exists solely in the URL string residing on the client. Therefore, the client.expiration method does nothing.
In client URL encoding, you lose all client properties when you submit a form using the GET method and when you access another application,. Once again, you may or may not want to lose these properties, depending on your application's needs.
In contrast to the client cookie technique, client URL encoding does not require the web browser support the Netscape cookie protocol, nor does it require writing information on the client machine.
Server-Side Techniques
There are three server-side maintenance techniques: For a comparison of all of the maintenance techniques, see "Comparing Client-Maintenance Techniques" on page 254. In all of these techniques, the runtime engine on the server stores the properties of theclient object and their values in a data structure in server memory. A single data structure, preserved between client requests, is used for all applications running on the server. These techniques differ only in the index used to access the information in that data structure, ensuring that each client/application pair gets the appropriate properties and values for the client object.
None of these techniques writes information to the server disk. Only the server cookie technique can cause information to be written to the client machine's disk, when the browser is exited.
Because these techniques store client object information in server memory between client requests, there is little or no network traffic increase. The property names and values are never sent to the client. Additionally, there are no restrictions on the number of properties a client object can have nor on the size of the individual properties.
The trade-off, of course, is that these techniques consume server memory between client requests. For applications that are accessed by a large number of clients, this memory consumption could become significant. Of course, this can be considered an advantage as well, in that you can store as much information as you need.
Using IP Address
The IP address technique indexes the data structure based on the application and the client's IP address. This simple technique is also the fastest, because it doesn't require sending any information to the client at all. Since the index is based on both the application and the IP address, this technique does still create a separate index for every application/client pair running on the server. This technique works well when all clients have fixed IP addresses. It does not work reliably if the client is not guaranteed to have a fixed IP address, for example, if the client uses the Dynamic Host Configuration Protocol (DHCP) or an Internet service provider that dynamically allocates IP addresses. This technique also does not work for clients that use a proxy server, because all users of the proxy report the same IP address. For this reason, this technique is probably useful only for intranet applications.Using Server Cookie
The server cookie technique uses a long unique name, generated by the runtime engine, to index the data structure on the server. The runtime engine uses the Netscape cookie protocol to store the generated name as a cookie on the client. It does not store the property names and values as cookies. For this reason, this technique creates a single cookie, whereas the client cookie technique creates a separate cookie for each property of theclient object.
The generated name is sent to the client once, in the header of the HTML page. You can access this generated name with the ssjs_getClientID function, described in "Uniquely Referring to the client Object" on page 245. This technique uses the same cookie file as the client cookie technique; these techniques differ in what information is stored in the cookie file. The Netscape cookie protocol is described in the Client-Side JavaScript Guide.
Also, because only the generated name is sent to the client, and not the actual property names and values, it does not matter where in your page you make changes to the client object properties. This contrasts with the client cookie technique.
By default, the runtime engine sets the expiration of the server data structure to ten minutes and does not set the expiration of the cookie sent to the client. As described in "The Lifetime of the client Object" on page 264, you can use the client object's expiration method to change this expiration period and to set the cookie's expiration.
When using server cookie, client.destroy eliminates all client property values.
In general, Netscape cookies have the limitations listed in "Using Client Cookie" on page 258. When you use server cookies, however, these limits are unlikely to be reached because only a single cookie (containing the index) is created.
This technique is fast and has no built-in restrictions on the number and size of properties and their values. You are limited more by how much space you're willing to use on your server for saving this information.
Using Server URL Encoding
The server URL encoding technique uses a long unique name, generated by the runtime engine, to index the data structure on the server. In this case, rather than making that generated name be a cookie on the client, the server appends the name to each URL in the generated HTML page. Consequently, the name is sent as many times as there are links on the generated HTML page. (Property names and values are not appended to URLs, just the generated name.) Once again, you can access this generated name with thessjs_getClientID function, described in "Uniquely Referring to the client Object" on page 245.
If you generate URLs dynamically or use the redirect function, you can add properties to the URL. For this reason, whenever you call redirect or generate your own URL, the compiler does not automatically append the index for you. If you want to retain the index for the client properties, use the addClient function. For more information, see "Manually Appending client Properties to URLs" on page 266.
If your page has a link to a URL outside of your application, you may not want the client index appended. In this situation, do not use a static string for the HREF value. Instead, compute the value. This prevents the runtime engine from automatically appending the client index to the URL. For example, assume you have this link:
<A HREF="mailto:me@royalairways.com">In this case, the runtime engine appends the
client index. To instead have it not do so, use this very similar link:
<A HREF=`"mailto:me@royalairways.com"`>In server URL encoding, you lose the
client identifier (and hence its properties and values) when you submit a form using the GET method. You may or may not want to lose these properties, depending on your application's needs.
The Lifetime of the client Object
Once a client accesses an application, there is no guarantee that it will request further processing or will continue to a logical end point. For this reason, theclient object has a built-in expiration mechanism. This mechanism allows JavaScript to occasionally "clean up" old client objects that are no longer necessary. Each time the server receives a request for a page in an application, JavaScript resets the lifetime of the client object.
Causing client Object Properties to Expire
The default behavior of the expiration mechanism varies, depending on theclient object maintenance technique you use, as shown in the following table.
Table 13.4 Default expiration of client properties based on the maintenance technique
client object properties. To change the length of this period, use the expiration method, as in the following example:
client.expiration(30);In response to this call, the runtime engine causes
client object properties to expire after 30 seconds. For server-side maintenance techniques, this call causes the server to remove the object properties from its data structures after 30 seconds. For the two cookie techniques, the call sets the expiration of the cookie to 30 seconds.
If the client object expires while there is an active client request using that object, the runtime engine waits until the end of the request before destroying the client object.
You must call expiration on each application page whose expiration behavior you want to specify. Any page that does not specify an expiration uses the default behavior.
Destroying the client Object
An application can explicitly destroy aclient object with the destroy method, as follows:
client.destroy();When an application calls
destroy, JavaScript removes all properties from the client object.
If you use the client cookie technique to maintain the client object, destroy eliminates all client property values but has no effect on what is stored in the client cookie file. To also eliminate property values from the cookie file, do not use destroy; instead, use expiration with an argument of 0 seconds.
When you use client URL encoding to maintain the client object, the destroy method removes all client properties. Links on the page before the call to destroy retain the client properties in their URLs, but links after the call have no properties. Because it is unlikely that you will want only some of the URLs from the page to contain client properties, you probably should call destroy either at the top or bottom of the page when using client URL maintenance. For more information, see "Using Client URL Encoding" on page 259.
Manually Appending client Properties to URLs
When using URL encoding either on the client or on the server to maintain theclient object, in general the runtime engine should store the appropriate information (client property names and values or the server data structure's index) in all URLs sent to the client, whether those URLs were presented as static HTML or were generated by server-side JavaScript statements.
The runtime engine automatically appends the appropriate information to HTML hyperlinks that do not occur inside the SERVER tag. So, for example, assume your HTML page contains the following statements:
<HTML>If the application uses URL encoding for the
For more information, contact
<A HREF="http://royalairways.com/contact_info.html">
Royal Airways</a>
...
</HTML>
client object, the runtime engine automatically appends the client information to the end of the URL. You do not have to do anything special to support this behavior.
However, your application may use the write function to dynamically generate an HTML statement containing a URL. You can also use the redirect function to start a new request. Whenever you use server-side JavaScript statements to add a URL to the HTML page being generated, the runtime engine assumes that you have specified the complete URL as you want it sent. It does not automatically append client information, even when using URL encoding to maintain the client object. If you want client information appended, you must do so yourself.
You use the addClient function to manually add the appropriate client information. This function takes a URL and returns a new URL with the information appended. For example, suppose the appropriate contact URL varies based on the value of the client.contact property. Instead of the HTML above, you might have the following:
<HTML>In this case, the runtime engine does not append
For more information, contact
<server>
if (client.contact == "VIP") {
write ("<A HREF='http://royalairways.com/vip_contact_info.html'>");
write ("Royal Airways VIP Contact</a>");
}
else {
write ("<A HREF='http://royalairways.com/contact_info.html'>");
write ("Royal Airways</a>");
}
</server>
...
</HTML>
client properties to the URLs. If you use one of the URL-encoding client maintenance techniques, this may be a problem. If you want the client properties sent with this URL, instead use this code:
<HTML>Similarly, any time you use the
For more information, contact
<server>
if (client.contact == "VIP") {
write (addClient(
"<A HREF='http://royalairways.com/vip_contact_info.html'>"));
write ("Royal Airways VIP Contact</a>");
}
else {
write (addClient(
"<A HREF='http://royalairways.com/contact_info.html'>"));
write ("Royal Airways</a>");
}
</server>
...
</HTML>
redirect function to change the client request, you should use addClient to append the information, as in this example:
redirect(addClient("mypage.html"));
Conversely, if your page has a link to a URL outside of your application, you may not want client information appended. In this situation, do not use a static string for the HREF value. Instead, compute the value. This prevents the runtime engine from automatically appending the client index or properties to the URL. For example, assume you have this link:
<A HREF="mailto:me@royalairways.com">In this case, the runtime engine appends client information. To instead have it not do so, use this very similar link:
<A HREF=`"mailto:me@royalairways.com"`>Even though an application is initially installed to use a technique that does not use URL encoding to maintain
client, it may be modified later to use a URL encoding technique. Therefore, if your application generates dynamic URLs or uses redirect, you may always want to use addClient.
Sharing Objects Safely with Locking
The execution environment for a 3.x version of a Netscape server is multithreaded; this is, it processes more than one request at the same time. Because these requests could require JavaScript execution, more than one thread of JavaScript execution can be active at the same time. If multiple threads simultaneously attempt to change a property of the same JavaScript object, they could leave the object in an inconsistent state. A section of code in which you want one and only one thread executing at any time is called a critical section. Oneserver object is shared by all clients and all applications running on the server. One project object is shared by all clients accessing the same application on the server. In addition, your application may create other objects it shares among client requests, or it may even share objects with other applications. To maintain data integrity within any of these shared objects, you must get exclusive access to the object before changing any of its properties.
Important There is no implicit locking for theTo better understand what can happen, consider the following example. Assume you create a shared objectprojectandserverobjects as there was in previous releases.
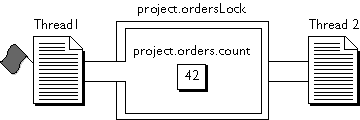
project.orders to keep track of customer orders. You update project.orders.count every time there is a new order, using the following code:
var x = project.orders.count;Assume that
x = x + 1;
project.orders.count = x;
project.orders.count is initially set to 1 and two new orders come in, in two separate threads. The following events occur:
-
The first thread stores
project.orders.countintox. -
Before it can continue, the second thread runs and stores the same value in its copy of
x. -
At this point, both threads have a value of 1 in
x. -
The second thread completes its execution and sets
project.orders.countto 2. -
The first thread continues, unaware that the value of
project.orders.counthas changed, and also sets it to 2.
project.orders.count is 2 rather than the correct value, 3.
To prevent problems of this kind, you need to obtain exclusive access to the properties of shared objects when writing to them. You can construct your own instances of Lock for this purpose that work with any shared object. In addition, the server and project objects have lock and unlock methods you can use to restrict access to those objects.
Using Instances of Lock
Think of a lock as a named flag that you must hold before you gain access to a critical section. If you ask for the named flag and somebody else is already holding it, you wait in line until that person releases the flag. While waiting, you won't change anything you shouldn't. Once you get the flag, anybody else who's waiting for it won't change anything either. If an error occurs or a timeout period elapses before you get the flag, you can either get back in line to wait some more or do something else, such as letting your user know the application is too busy to perform that operation right now. You should not decide to break into the line (by changing shared information)! Figure 13.5 illustrates this process.
Figure 13.5 Thread 2 waits while thread 1 has the lock
Lock class. You can use an instance of Lock to gain exclusive access to any shared object, providing all code that accesses the shared object honors the lock. Typically, you create your Lock instances on the initial page of your application (for reasons that explained later).
In your other pages, before a critical section for the shared object (for example, sections that retrieve and change a property value), you call the Lock instance's lock method. If that method returns true, you have the lock and can proceed. At the end of the critical section, you call the Lock instance's unlock method.
When a client request in a single execution thread calls the lock method, any other request that calls lock for the same Lock instance waits until the original thread calls the unlock method, until some timeout period elapses, or until an error occurs. This is true whether the second request is in a different thread for the same client or in a thread for a different client.
If all threads call the lock method before trying to change the shared object, only one thread can enter the critical section at one time.
Important The use of locks is completely under the developer's control and requires cooperation. The runtime engine does not force you to callYou can create as many locks as you need. The same lock may be used to control access to multiple objects, or each object (or even object property) can have its own lock. A lock is just a JavaScript object itself; you can store a reference to it in any other JavaScript object. Thus, for example, it is common practice to construct alock, nor does it force you to respect a lock obtained by someone else. If you don't ask, you can change anything you want. For this reason, it's very important to get into the habit of always callinglockandunlockwhen entering any critical section of code and to check the return value oflockto ensure you have the lock. You can think of it in terms of holding a flag: if you don't ask for the flag, you won't be told to wait in line. If you don't wait in line, you might change something you shouldn't.
Lock instance and store it in the project object.
NOTE: Because using a lock blocks other users from accessing the named flag, potentially delaying execution of their tasks, it is good practice to use locks for as short a period as possible.The following code illustrates how to keep track of customer orders in the shared
project.orders object discussed earlier and to update project.orders.count every time there is a new order. In the application's initial page, you include this code:
// Construct a new Lock and save in projectThis code creates the
project.ordersLock = new Lock();
if (! project.ordersLock.isValid()) {
// Unable to create a Lock. Redirect to error page
redirect ("sysfailure.htm");
}
Lock instance and verifies (in the call to isValid) that nothing went wrong creating it. Only in very rare cases is your Lock instance improperly constructed. This happens only if the runtime engine runs out of system resources while creating the object.
You typically create your Lock instances on the initial page so that you don't have to get a lock before you create the Lock instances. The initial page is run exactly once during the running of the application, when the application is started on the server. For this reason, you're guaranteed that only one instance of each lock is created.
If, however, your application creates a lock on another of its pages, multiple requests could be invoking that page at the same time. One request could check for the existence of the lock and find it not there. While that request creates the lock, another request might create a second lock. In the meantime, the first request calls the lock method of its object. Then the second request calls the lock method of its object. Both requests now think they have safe access to the critical section and proceed to corrupt each other's work.
Once it has a valid lock, your application can continue. On a page that requires access to a critical section, you can use this code:
// Begin critical section -- obtain lock
if ( project.ordersLock.lock() ) {
var x = project.orders.count;
x = x + 1;
project.orders.count = x;
// End critical section -- release lockThis code requests the lock. If it gets the lock (that is, if the
project.ordersLock.unlock();
}
else
redirect("combacklater.htm");
lock method returns true), then it enters the critical section, makes the changes, and finally releases the lock. If the lock method returns false, then this code did not get the lock. In this case, it redirects the application to a page that indicates the application is currently unable to satisfy the request.
Special Locks for project and server Objects
Theproject and server objects each have lock and unlock methods. You can use these methods to obtain exclusive access to properties of those objects.
There is nothing special about these methods. You still need cooperation from other sections of code. You can think of these methods as already having one flag named "project" and another named "server." If another section of code does not call project.lock, it can change any of the project object's properties.
Unlike the lock method of the Lock class, however, you cannot specify a timeout period for the lock method of the project and server objects. That is, when you call project.lock, the system waits indefinitely for the lock to be free. If you want to wait for only a specified amount of time, instead use an instance of the Lock class.
The following example uses lock and unlock to get exclusive access to the project object while modifying the customer ID property:
project.lock()
project.next_id = 1 + project.next_id;
client.id = project.next_id;
project.unlock();
Avoiding Deadlock
You use locks to protect a critical section of your code. In practice, this means one request waits while another executes in the critical section. You must be careful in using locks to protect critical sections. If one request is waiting for a lock that is held by a second request, and that second request is waiting for a lock held by the first request, neither request can ever continue. This situation is called deadlock. Consider the earlier example of processing customer orders. Assume that the application allows two interactions. In one, a user enters a new customer; in the other, the user enters a new order. As part of entering a new customer, the application also creates a new customer order. This interaction is done in one page of the application that could have code similar to the following:// Create a new customer.
if ( project.customersLock.lock() ) {
var id = project.customers.ID;
id = id + 1;
project.customers.ID = id;
// Start a new order for this new customer.
if ( project.ordersLock.lock() ) {
var c = project.orders.count;
c = c + 1;
project.orders.count = c;
project.ordersLock.unlock();
}
project.customersLock.unlock();In the second type of interaction, a user enters a new customer order. As part of entering the order, if the customer is not already a registered customer, the application creates a new customer. This interaction is done in a different page of the application that could have code similar to the following:
}
// Start a new order.
if ( project.ordersLock.lock() ) {
var c = project.orders.count;
c = c + 1;
project.orders.count = c;
if (...code to establish unknown customer...) {// Create a new customer.
// This internal lock is going to cause trouble!
if ( project.customersLock.lock() ) {
var id = project.customers.ID;
id = id + 1;
project.customers.ID = id;
project.customersLock.unlock();
}
}
project.ordersLock.unlock();Notice that each of these code fragments tries to get a second lock while already holding a lock. That can cause trouble. Assume that one thread starts to create a new customer; it obtains the
}
customersLock lock. At the same time, another thread starts to create a new order; it obtains the ordersLock lock. Now, the first thread requests the ordersLock lock. Since the second thread has this lock, the first thread must wait. However, assume the second thread now asks for the customersLock lock. The first thread holds that lock, so the second thread must wait. The threads are now waiting for each other. Because neither specified a timeout period, they will both wait indefinitely.
In this case, it is easy to avoid the problem. Since the values of the customer ID and the order number do not depend on each other, there is no real reason to nest the locks. You could avoid potential deadlock by rewriting both code fragments. Rewrite the first fragment as follows:
// Create a new customer.
if ( project.customersLock.lock() ) {
var id = project.customers.ID;
id = id + 1;
project.customers.ID = id;
project.customersLock.unlock();
}
// Start a new order for this new customer.
if ( project.ordersLock.lock() ) {
var c = project.orders.count;
c = c + 1;
project.orders.count = c;
project.ordersLock.unlock();The second fragment looks like this:
}
// Start a new order.
if ( project.ordersLock.lock() ) {
var c = project.orders.count;
c = c + 1;
project.orders.count = c;
project.ordersLock.unlock();
}
if (...code to establish unknown customer...) {// Create a new customer.
if ( project.customersLock.lock() ) {
var id = project.customers.ID;
id = id + 1;
project.customers.ID = id;
project.customersLock.unlock();Although this situation is clearly contrived, deadlock is a very real problem and can happen in many ways. It does not even require that you have more than one lock or even more than one request. Consider code in which two functions each ask for the same lock:
}
}
function fn1 () {
if ( project.lock() ) {
// ... do some stuff ...
project.unlock();
}
}function fn2 () {
if ( project.lock() ) {
// ... do some other stuff ...
project.unlock();
}
}
By itself, that is not a problem. Later, you change the code slightly, so that fn1 calls fn2 while holding the lock, as shown here:
function fn1 () {
if ( project.lock() ) {
// ... do some stuff ...
fn2();
project.unlock();
}
}
Now you have deadlock. This is particularly ironic, in that a single request waits forever for itself to release a flag!
Table of Contents | Previous | Next | Index
Last Updated: 11/12/98 15:29:31
Any sample code included above is provided for your use on an "AS IS" basis, under the Netscape License Agreement - Terms of Use