|
|
| Sun ONE Portal Server 6.0 管理者ガイド |
この章では、Sun™ ONE Portal Server 検索エンジンロボットおよび対応する構成ファイルについて説明します。 この章には、次の節があります。
検索エンジンロボットの概要
検索エンジンロボットは、ドメイン内のリソースを特定し、レポートを作成するエージェントです。 これには 、列挙子フィルタとジェネレータフィルタの 2 種類のフィルタを使用します。
列挙子フィルタは、ネットワークプロトコルを使用してリソースを検出します。 列挙子フィルタは、各リソースをテストし、適切な基準に一致した場合はリソースを列挙します。 たとえば、列挙子フィルタは HTML ファイルからハイパーテキストリンクを抽出し、そのリンクを使用して別のリソースを検索できます。
ジェネレータフィルタは、各リソースをテストし、リソース記述 (RD) を作成する必要があるかどうかを確認します。 リソースがテストに合格した場合、ジェネレータは検索エンジンデータベースに格納される RD を作成します。
ロボットの動作の仕組み
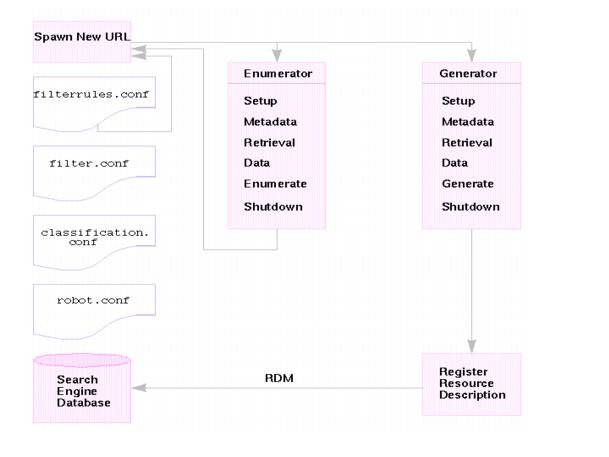
図 9-1 に、検索エンジンロボットの動作の仕組みを示します。 図 9-1 に示すように、ロボットは URL および関連のあるネットワークリソースを調べます。 各リソースは、列挙機能と生成機能の両方によってテストされます。 リソースが列挙テストに合格すると、ロボットがそのリソースをほかの URL について検査します。 リソースがジェネレータテストに合格すると、ロボットは検索エンジンデータベースに格納されているリソース記述を生成します。
図 9-1 ロボットの動作の仕組み
ロボット設定ファイル
ロボット設定ファイルでは、検索エンジンロボットの動作が定義されます。 これらのファイルは、/var/opt/SUNWps/http-hostname-domain/portal/config ディレクトリにあります。表 9-1では、各ロボット構成ファイルを説明しています。 この表は 2 つの列で構成されています。 最初の列には設定ファイルを、2 番目の列にはファイルの内容の説明を示しています。
注 検索サービスは、この他にconvert.conf と import.conf の 2 つの設定ファイルを使用します。 これらのファイルは検索サーバーにより生成され、一般に手動で編集できません。
検索エンジン管理インターフェイスを使用すれば、ほとんどのパラメータを設定できるので、通常は robot.conf ファイルを編集する必要はありません。
ただし、上級ユーザーはこのファイルを手動で編集して、インターフェイスを介して設定できないパラメータを設定できます。
ロボットプロセスパラメータの設定
robot.conf ファイルでは、ロボットに filter.conf 中の使用するフィルタを指示する、ロボット用の多くのオプションが定義されます (旧バージョンとの下位互換性については、robot.conf にシード URL を含めることもできます) 。
iPlanet™ Directory Server Access Management Edition 管理コンソールは、ファイル robot.conf の編集に使用されます。 手動で編集できるパラメータついては、「ユーザが変更できるパラメータ」の節で詳細に説明します。
もっとも重要なパラメータは、enumeration-filter および generation-filter で、これらのパラメータは、ロボットが列挙および生成で使用するフィルタを指定します。 これらのパラメータのデフォルト値は、enumeration-default および generation-default です。これらは、filter.conf ファイルにおいてデフォルトで提供されるフィルタ名です。
フィルタはすべて filter.conf ファイルで定義される必要があります。 filter.conf で独自のフィルタを定義する場合、必要なパラメータを robot.conf に追加する必要があります。
たとえば、my-enumerator という名前の新しい列挙フィルタを定義する場合、robot.conf に次のパラメータを追加します。
enumeration-filter=my-enumerator
フィルタリング処理
ロボットは、処理するリソースとそのリソースの処理方法の決定にフィルタを使用します。 ロボットがリソースと同時にリソースの参照を検出すると、各リソースにフィルタを適用して、それらのリソースを列挙し、検索エンジンデータベースに格納するリソース記述を生成するかどうかを決定します。
ロボットは 1 つあるいは複数のシード URL を調べ、フィルタを適用し、シード URL などを列挙して生成された URL にそのフィルタを適用します。 シード URL は filterrules.conf ファイルで定義されます。
フィルタは、必須の初期化操作を実行し、現在のリソースに比較テストを適用します。 各テストの目標は、リソースを許可あるいは拒否することです。 フィルタにはシャットダウンフェーズも備わっており、必要なクリーンアップ操作を実行します。
リソースが許可される場合は、フィルタ通過の続行が許可されることを表します。 リソースが否認される場合、そのリソースは拒否されます。 拒否されたリソースのフィルタは、それ以上動作しません。 リソースが拒否されない場合、ロボットは最後にそのリソースを列挙し、リソースの検出をさらに試みます。 ジェネレータはリソース記述も作成できます。
これらの操作は必ずしもリンクされていません。 リソースの中には列挙につながるものや、RD 生成につながるものもあります。 多くのリソースは列挙にも、RD 生成にもつながります。 たとえば、リソースが FTP ディレクトリである場合、一般的にはそのリソース用に RD は生成されません。 ただし、ロボットは FTP ディレクトリの個別ファイルを列挙できます。 ほかのドキュメントへのリンクを含む HTML ドキュメントは、RD を受信し、また、関連のドキュメントを列挙することもできます。
次の節では、フィルタ処理について詳しく説明します。
フィルタ処理の段階
列挙フィルタ、生成フィルタのどちらにも、フィルタリング処理における 5 つのフェーズがあります。 どちらのフィルタにも共通の 4 つのセットアップ初期化操作を実行します。 ロボットの生存期間において一度だけ発生します。メタデータ−そのリソースについて利用可能なメタデータに基づき、リソースをフィルタリングします。 リソースがネットワークを介して取得される前に、メタデータのフィルタリングがリソースごとに 1 回実行されます。表 9-2 に、共通のメタデータのタイプの例を一覧表示します。 この表には、メタデータのタイプ、およびその説明と例を示しています。データ−そのデータに基づいてリソースをフィルタリングします。 データのフィルタリングは、ネットワークを介して取得されたあとにリソースごとに 1 回実行されます。 フィルタリングに使用できるデータには、次のものがあります。および シャットダウン−必要な終了操作を実行します。 ロボットの生存期間において一度だけ発生します。リソースがデータフェーズを通過する場合、フィルタが列挙子あるいはジェネレータであるかどうかによって、そのリソースは 列挙−検査すべきほかのリソースを参照するかどうかを判断するため、現行のリソース中の参照を列挙します。 リソースのリソース記述 (RD) を生成し、検索エンジンデータベースにその RD を保存します。 これらのフェーズは次のとおりです。
- セットアップ初期化操作を実行します。 ロボットの生存期間において一度だけ発生します。
- メタデータ−そのリソースについて利用可能なメタデータに基づき、リソースをフィルタリングします。 リソースがネットワークを介して取得される前に、メタデータのフィルタリングがリソースごとに 1 回実行されます。表 9-2 に、共通のメタデータのタイプの例を一覧表示します。 この表には、メタデータのタイプ、およびその説明と例を示しています。
- データ−そのデータに基づいてリソースをフィルタリングします。 データのフィルタリングは、ネットワークを介して取得されたあとにリソースごとに 1 回実行されます。 フィルタリングに使用できるデータには、次のものがあります。
- content-type
- content-length
- content-encoding
- content-charset
- last-modified
- expires
- 列挙−検査すべきほかのリソースを参照するかどうかを判断するため、現行のリソース中の参照を列挙します。
- リソースのリソース記述 (RD) を生成し、検索エンジンデータベースにその RD を保存します。
- シャットダウン−必要な終了操作を実行します。 ロボットの生存期間において一度だけ発生します。
フィルタの構文
filter.conf ファイルには、列挙フィルタおよび生成フィルタの定義が含まれています。 このファイルには、列挙と生成の両方に対する複数のフィルタを含むことができます。 robot.conf ファイルの enumeration-filter パラメータおよび generation-filter パラメータでフィルタを指定するため、使用するフィルタをロボットが指定できます。
フィルタの定義は、ヘッダー、本文、終了という明確に定義された構造になります。 ヘッダーは、フィルタの開始を識別し、次の例のような名前を宣言します。
<Filter name="myFilter">
本文は、セットアップ、テスト、列挙または生成、およびシャットダウン中のフィルタの動作を定義する一連のフィルタディレクティブで構成されています。 各ディレクティブは、関数および該当する場合はその関数のパラメータを指定します。
終了は </Filter> によって示されます。
コード例 9-1 に、enumeration1 という名のフィルタを示します。
<Filter name="enumeration1>
Setup fn=filterrules-setup config=./config/filterrules.conf
# Process the rules
MetaData fn=filterrules-process
# Filter by type and process rules again
Data fn=assign-source dst=type src=content-type
Data fn=filterrules-process
# Perform the enumeration on HTML only
Enumerate enable=true fn=enumerate-urls max=1024 type=text/html
# Cleanup
Shutdown fn=filterrules-shutdown
</Filter>
"> コード例 9-1 列挙ファイルの構文
<Filter name="enumeration1>
Setup fn=filterrules-setup config=./config/filterrules.conf
# Process the rules
MetaData fn=filterrules-process
# Filter by type and process rules again
Data fn=assign-source dst=type src=content-type
Data fn=filterrules-process
# Perform the enumeration on HTML only
Enumerate enable=true fn=enumerate-urls max=1024 type=text/html
# Cleanup
Shutdown fn=filterrules-shutdown
</Filter>
フィルタディレクティブ
フィルタディレクティブは、ロボットアプリケーション関数 (RAF) を使用して、操作を実行します。 このディレクティブの使用法および実行の流れは、obj.conf ファイルの NSAPI ディレクティブおよびサーバーアプリケーション関数 (SAF) とよく似ています。 NSAPI、SAF と同様に、pblocks とも呼ばれるパラメータブロックを使用して、データは格納および送信されます。
「フィルタリング処理」 に表示されたフィルタリングフェーズや操作に対応して、 6 つのロボットディレクティブあるいは RAF クラスがあります。
- セットアップ
- メタデータ
- データ
- 列挙
- 生成
- シャットダウン
各ディレクティブは、独自のロボットアプリケーション関数を持っています。 たとえば、Metadata ディレクティブおよび Data ディレクティブを持つフィルタリング関数、Enumerate ディレクティブを持つ列挙関数、Generate ディレクティブを持つ生成関数などを使用します。
ロボットアプリケーションの組み込み関数と独自のロボットアプリケーション関数を書き込む手順については、『Sun ONE Portal Server 6.0 Developerユs Guide』で説明しています。
フィルタの書き込みまたは修正
ほとんどの場合、スクラッチからフィルタを書き込む必要はありません。 管理インタフェースを使用すると、ほとんどのフィルタを作成できます。 修正が必要な場合は、filter.conf ファイルおよび filterrules.conf ファイルを変更することができます。 これらのファイルはディレクトリ /var/opt/SUNWps/http-hostname-domain/portal に存在します。
ただし、さらに複雑なパラメータのセットを作成する場合、ロボットが使用する構成ファイルを編集する必要があります。
フィルタの書き込みあるいは変更の際は、次の点に注意してください。
- ディレクティブの実行順序 (特に各フェーズで使用可能な情報)
- 規則の順序
robot.conf ファイルで変更できるパラメータ、filter.conf ファイルで使用できるロボットアプリケーション関数、および独自のロボットアプリケーション関数の作成方法については、『Sun ONE Portal Server 6.0 Developerユs Guide』を参照してください。
ユーザが変更できるパラメータ
robot.conf ファイルは、ロボットを filter.conf にある適切なフィルタに向けるなどの、ロボット用の多くのオプションを定義します。 旧バージョンとの下位互換性のために、robot.conf にシード URL を含めることもできます。
管理コンソールを使用すれば、ほとんどのパラメータを設定できるので、通常は robot.conf ファイルを編集する必要はありません。 ただし、上級ユーザーはこのファイルを手動で編集して、管理コンソールを介して設定できないパラメータを設定できます。 このファイルの例については、「サンプルの robot.conf ファイル」を参照してください。
表 9-3に、robot.conf ファイルでユーザーが修正可能なパラメータを示します。パラメータ、その説明および列には例を示しています。
サンプルの robot.conf ファイル
この節では、サンプルの robot.conf ファイルについて説明します。 サンプルの中のコメントが付いたパラメータは、表示されているデフォルト値を使用します。 最初のパラメータである csid は、このファイルを使用する検索エンジンインスタンスを示しています。このパラメータの値は変更しないでください。 このファイルのパラメータの定義については、「ユーザが変更できるパラメータ」を参照してください。
注 このサンプルファイルには、csid パラメータのように変更してはならない、検索エンジン管理インタフェースによって使用されるいくつかのパラメータが含まれています。
<Process csid="x-catalog://budgie.siroe.com:80/jack" \
auto-proxy="http://sesta.varrius.com:80/"
auto_serv="http://sesta.varrius.com:80/"
command-port=21445
convert-timeout=600
depth="-1"
# email="user@domain"
enable-ip=true
enumeration-filter="enumeration-default"
generation-filter="generation-default"
index-after-ngenerated=30
loglevel=2
max-concurrent=8
site-max-concurrent=2
onCompletion=idle
password=boots
proxy-loc=server
proxy-type=auto
robot-state-dir="/var/opt/SUNWps/https-budgie.siroe.com/ \
ps/robot"
server-delay=1
smart-host-heuristics=true
tmpdir="/var/opt/SUNWps/https-budgie.siroe.com/ps/tmp"
user-agent="iPlanetRobot/4.0"
username=jack
</Process>