| Sun ONE Portal Server 6.2 管理员指南 |
第 9 章
管理搜索引擎 Robot本章描述 Sun™ ONE Portal Server 搜索引擎 robot 及其相应的配置文件。以下主题在讨论之列:
搜索引擎 Robot 概述搜索引擎 robot 是一个代理,功能是对其域内的资源进行确定和报告。它使用以下两种过滤器来完成这项工作:枚举过滤器和生成过滤器。
枚举过滤器使用网络协议来定位资源。它会对每个资源进行测试,并将满足适当标准的资源算入。例如,枚举过滤器可以从某 HTML 文件中提取超文本链接,然后利用这些链接来查找其它资源。
生成过滤器会对每个资源进行测试,确定是否应为其创建资源描述 (RD)。如果资源通过了测试,生成器便会为其创建 RD,该 RD 存储在搜索引擎数据库中。
Robot 的工作机理
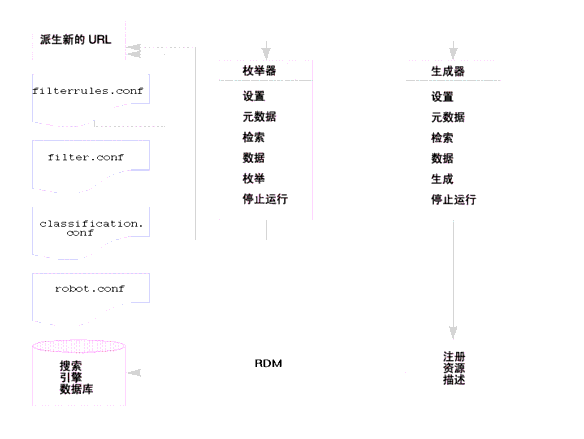
图 9-1 图解说明了搜索引擎 robot 的工作机理。在图 9-1 中,robot 会检查 URL 及其关联的网络资源。每个资源都要由枚举器和生成器进行测试。如果资源通过了枚举测试,robot 会检查该资源中是否有其它 URL。如果资源通过了生成器测试,robot 会为其生成资源描述,该资源描述存储在搜索引擎数据库中。
图 9-1 Robot 的工作机理
Robot 配置文件
Robot 配置文件定义搜索引擎 robot 的行为。这些文件驻留在 /var/opt/SUNWps/http-hostname-domain/portal/config 目录中。表 9-1 对每个 robot 配置文件都进行了描述。该表由两列组成。第一列列出配置文件,第二列描述文件内容。
由于可以使用“搜索引擎管理界面”来设置大部分参数,因此通常不需要对 robot.conf 文件进行编辑。
不过,高级用户可能需要手动编辑此文件,以设置那些无法通过界面来设置的参数。
设置 Robot 进程参数robot.conf 文件为 robot 定义许多选项,其中包括将 robot 指向 filter.conf 中的适当过滤器。(为向后兼容较早版本,robot.conf 还包含 seed URL。)
使用 iPlanet™ Directory Server Access Management Edition 管理控制台用于编辑 robot.conf 文件。请注意,少数可以手动编辑的参数在“用户可修改的参数”部分中有详细描述。
最重要的参数是 enumeration-filter 和 generation-filter,它们决定 robot 用于进行枚举和生成的过滤器。这两个参数的默认值分别为 enumeration-default 和 generation-default,它们也是默认情况下 filter.conf 文件中所提供的过滤器名称。
所有过滤器都必须在 filter.conf 文件中进行定义。如果在 filter.conf 中定义了自己的过滤器,就必须给 robot.conf 添加所有必要的参数。
例如,如果您定义了一个名为 my-enumerator 的新枚举过滤器,就应将以下参数添加到 robot.conf 中:
enumeration-filter=my-enumerator
过滤流程Robot 利用过滤器来确定需要处理的资源及处理方式。如果 robot 不但发现了资源本身,而且发现了对资源的引用,便会使用过滤器对每种资源进行过滤,以将符合标准者算入及确定是否要为其生成资源描述;该描述存储在搜索引擎数据库中。
Robot 会检查一个或多个 seed URL,使用过滤器将它们过滤,然后再使用过滤器对通过枚举 seed URL 而派生的 URL 进行过滤,依此类推。Seed URL 在 filterrules.conf 文件中进行定义。
过滤器会执行所有必需的初始化操作,并对目前资源进行对照测试。每项测试的目标都是或允许、或拒绝该资源。过滤器还有停止运行阶段,它在该阶段会执行所有必需的清除操作。
如果某资源被允许,则表明允许其继续接受过滤器的其它测试。如果某资源被拒绝,则该资源便会被弃用。过滤器不会对被拒绝的资源执行进一步操作。如果资源未被拒绝,robot 最终会将其算入,并尝试从中发现其它资源。生成器还可能会为其创建资源描述。
这些操作没有必然的连锁关系。Robot 对一些资源只会进行算入操作;对另一些资源则只会进行 RD 生成操作。Robot 对许多资源都是既进行算入操作,又进行 RD 生成操作。例如,如果某资源是一个 FTP 目录,Robot 通常不会为其生成 RD。不过,robot 可能会对 FTP 目录中的个别文件执行算入操作。Robot 可为包含到其它文档的链接的 HTML 文档生成 RD,并可能最终会对链接的文档也执行算入操作。
以下部分对过滤流程进行了详述:
过滤流程的各个阶段
枚举和生成过滤器的过滤流程都有五个阶段。它们共有的阶段有以下四个:设置 - 执行初始化操作。在 robot 的生命周期中只发生一次。元数据 - 依据资源的可用元数据对资源进行过滤。在通过网络检索资源前,只对每个资源执行一次元数据过滤。表 9-2 列有常见元数据类型的示例。该表由三列组成。第一列列出元数据类型,第二列给出说明,第三列提供一个示例。数据 - 依据资源数据过滤资源。通过网络检索资源后,只对每个资源执行一次数据过滤。可用于过滤的数据类型包括:及停止运行 - 执行任何必要的终止操作。在 robot 的生命周期中只发生一次。如果资源通过了“数据”阶段,便会进入枚举 - 枚举目前资源,以确定其是否指向其它待检查的资源。和生成 - 为资源生成资源描述 (RD),并将其保存在搜索引擎数据库中。这两个阶段之一,其实际进入的阶段取决于过滤器的类型是枚举过滤器还是生成过滤器。
这些阶段如下:
- 设置 - 执行初始化操作。在 robot 的生命周期中只发生一次。
- 元数据 - 依据资源的可用元数据对资源进行过滤。在通过网络检索资源前,只对每个资源执行一次元数据过滤。表 9-2 列有常见元数据类型的示例。该表由三列组成。第一列列出元数据类型,第二列给出说明,第三列提供一个示例。
- 数据 - 依据资源数据过滤资源。通过网络检索资源后,只对每个资源执行一次数据过滤。可用于过滤的数据类型包括:
- 枚举 - 枚举目前资源,以确定其是否指向其它待检查的资源。
- 生成 - 为资源生成资源描述 (RD),并将其保存在搜索引擎数据库中。
- 停止运行 - 执行任何必要的终止操作。在 robot 的生命周期中只发生一次。
过滤器语法
filter.conf 文件包含枚举过滤器和生成过滤器的定义。该文件包含多个枚举和生成所共用的过滤器。请注意,robot 可以决定使用哪些过滤器,因为这些过滤器由 robot.conf 文件中的 enumeration-filter 和 generation-filter 参数来指定。
过滤器定义具有一个定义明确的结构:该结构由标题、正文和结尾组成。标题用于确定过滤器的开始处和声明过滤器的名称,例如:
<Filter name="myFilter">
正文由一系列过滤器指令组成,这些指令定义过滤器在设置、测试、枚举或生成以及停止运行期间的行为。每条指令都指定了一种操作程序,在适用情况下,还指定了操作程序的参数。
结尾使用 </Filter> 来标记。
代码示例 9-1 展示了一个名为 enumeration1 的过滤器
代码示例 9-1 枚举文件语法
过滤器指令
过滤器指令使用“Robot 应用程序操作程序”(RAF) 来执行操作。其用法和执行流程与 obj.conf 文件中的 NSAPI 指令和“服务器应用程序操作程序”(SAF) 类似。与 NSAPI 和 SAF 一样,它使用参数块来进行数据的存储和传送(亦称作 pblocks)。
有六种 robot 指令(或称 RAF 类),它们分别对应于“过滤流程”中列出的过滤阶段和操作:
每条指令都有其专用的 robot 应用程序操作程序。例如,对 Metadata 和 Data 指令使用过滤操作程序,对 Enumerate 指令使用枚举操作程序,对 Generate 指令使用生成操作程序,等等。
内置 robot 应用程序操作程序以及编写自定义 robot 应用程序操作程序的说明在 Sun ONE Portal Server 6.1 Developer's Guide 中有介绍。
编写或修改过滤器
在大多数情况下,不需要从头编写过滤器。可以使用管理控制台来创建大部分过滤器。然后可根据需要修改 filter.conf 和 filterrules.conf 文件。这两个文件位于 /var/opt/SUNWps/http-hostname-domain/portal 目录中。
不过,如果想创建一组更复杂的参数,便需要编辑 robot 所使用的配置文件。
编写或修改过滤器时请注意以下两点:
有关 robot.conf 文件中可以修改的参数、filter.conf 文件中可以使用的 robot 应用程序操作程序以及如何创建自定义 robot 应用程序操作程序的论述,请参阅 Sun ONE Portal Server 6.1 Developer's Guide。
用户可修改的参数robot.conf 文件为 robot 定义许多选项,其中包括将 robot 指向 filter.conf 中的适当过滤器的选项。为向后兼容较早版本,robot.conf 还包含 seed URL。
由于可以使用管理控制台来设置大部分参数,因此通常不需要对 robot.conf 文件进行编辑。不过,高级用户可能需要手动编辑此文件,以设置那些无法通过管理控制台来设置的参数。有关该文件的示例,请参阅“robot.conf 文件示例”。
表 9-3 列出了 robot.conf 文件中用户可修改的参数。该表的第一列列出参数,第二列给出参数说明,第三列提供示例。
表 9-3 用户可修改的参数
参数
说明
示例
auto-proxy
为 robot 指定代理设置。它可以是代理服务器或用于自动配置代理的 JavaScript 文件。有关详细信息,请参阅 Sun ONE Portal Server 6.2 管理员指南。
auto-proxy="http://proxy_server/proxy.pac"
bindir
指定 robot 是否将绑定目录添加到 PATH 环境中。这是一个附加 PATH,供用户在 robot 中运行外部程序,如 cmd-hook 参数所指定的程序。
bindir=path
cmd-hook
指定当 robot 完成一次运行后,运行一个外部完成脚本。其值必须是指向命令名的完整路径。Robot 将从 /var/opt/SUNWps/ 目录执行该脚本。
无默认值。
要使命令能够执行,必须至少有一个已注册的 RD。
有关编写完成脚本的信息,请参阅 Sun ONE Portal Server 6.1 Developer’s Guide。
cmd-hook=”command-string”
无默认值。
command-port
指定 robot 为接受来自其它程序(如“管理界面”或 robot 控制面板)的命令而须侦听的套接字。
出于安全原因,如果不将 remote-access 设置为 yes,robot 便只接受来自本地主机的命令。
command-port=port_number
connect-timeout
指定网络对连接请求的最长响应时间。
默认值为 120 秒。
command-timeout=seconds
convert-timeout
指定最长文档转换时间。
默认值为 600 秒。
convert-timeout=seconds
depth
指定 robot 要检查的自 seed URL(亦称作启动点)始的链接层数。本参数为未指定深度的所有 seed URL 设置默认值。
默认值为 10。
负值 (depth=-1) 表示链接深度无限。
depth=integer
指定运行 robot 的用户的电子邮件地址。
该电子邮件地址随 HTTP 请求报头中的用户代理一并发送,这样网络管理员便可联络在其站点上运行 robot 的用户。
默认值为 user@domain。
email=user@hostname
enable-ip
为创建的每个 RD 的 URL 生成一个 IP 地址。
默认值为 true。
enable-ip=[true | yes | false | no]
enable-rdm-probe
确定服务器是否支持 RDM,robot 使用此参数来确定是否要查询它所遇到的每台服务器。如果服务器支持 RDM,robot 将不会尝试枚举该服务器的资源,因为该服务器可充当其自身的资源描述服务器。
默认值为 false。
enable-rdm-probe=[true | false | yes | no]
enable-robots-txt
确定 robot 是否应在它所访问的每个站点检查 robots.txt 文件(如果存在该文件)。
默认值为 yes。
enable-robots-txt=[true | false | yes | no]
engine-concurrent
指定供 robot 使用的预创建的线程数。
默认值为 10。
此参数无法通过管理控制台以交互方式进行设置。
engine-concurrent=[1..100]
enumeration-filter
指定 robot 用来确定是否应枚举某资源的枚举过滤器。该值必须是 filter.conf 文件中所定义的过滤器的名称。
默认值为 enumeration-default。
此参数无法通过管理控制台以交互方式进行设置。
enumeration-filter=enumfiltername
generation-filter
指定 robot 用来确定是否应为某资源生成资源描述的生成过滤器。该值必须是 filter.conf 文件中所定义的过滤器的名称。
默认值为 generation-default。
此参数无法通过管理控制台以交互方式进行设置。
generation-filter=genfiltername
index-after-ngenerated
指定在为搜索引擎而对 RD 进行分批处理前,robot 收集 RD 所应花费的时间。
如果不指定该参数,系统会将其设置为 256 分钟。
index-after-ngenerated=30
loglevel
指定日志级别。loglevel 值如下所示:
默认值为 1。
loglevel=[0...100]
max-connections
指定 robot 能进行的最大并发检索数。
默认值为 8。
max-connections=[1..100]
max-filesize-kb
指定 robot 所能检索文件的最大尺寸(千字节)。
max-filesize-kb=1024
max-memory-per-url / max-memory
指定每个 URL 可占用的最大内存(字节)。如果 URL 需要更多内存,RD 会被保存到磁盘上。
默认值为 1。
此参数无法通过管理控制台以交互方式进行设置。
max-memory-per-url=n_bytes
max-working
指定 robot 工作集合的大小,即 robot 一次最多可处理的 URL 数。
此参数无法通过管理控制台以交互方式进行设置。
max-working=1024
onCompletion
决定 robot 完成一次运行后的下一步操作。Robot 可转入空闲模式、环回并再次启动或退出。
默认值为 idle。
该参数与 cmd-hook 参数协同工作。Robot 运行完成后,将执行 onCompletion 操作,然后运行 cmd-hook 程序。
OnCompletion=[idle | loop | quit]
password
指定 httpd 验证和 ftp 连接所需要的 password。
password=string
referer
指定在 HTTP 请求中发送的参数,前提是将该参数设置为访问网页时将 robot 识别为转派方
referer=string
register-user
指定将 RD 注册到搜索引擎数据库所用的用户名。
此参数无法通过搜索引擎管理界面以交互方式进行设置。
register-user=string
register-password
指定将 RD 注册到搜索引擎数据库所用的口令。
此参数无法通过管理控制台以交互方式进行设置。
register-password=string
remote-access
该参数决定 robot 是否可以接受来自远程主机的命令。
默认值为 false。
remote-access=[true | false | yes | no]
robot-state-dir
指定 robot 用于保存其状态的目录。robot 可在此工作目录中记录收集的 RD 数等信息。
robot-state-dir="/var/opt/SUNWps/instance/portal/robot"
server-delay
指定对同一网站两次访问间的间隔,从而防止 robot 过于频繁地访问同一站点。
server-delay=delay_in_seconds
site-max-connections
指定 robot 可实现的与任一站点的最大并发连接数。
默认值为 2。
site-max-connections=[1..100]
smart-host-heuristics
使 robot 能够更改那些正在轮换其 DNS 规范主机名的站点。例如,将 www123.siroe.com 更改为 www.siroe.com。
默认值为 false。
smart-host-heuristics=[true | false]
tmpdir
指定供 robot 创建临时文件的位置。
使用该值来设置环境变量 TMPDIR。
tmpdir=path
user-agent
指定随 http-request 中的电子邮件地址一并发送给服务器的参数。
user-agent=iPlanetRobot/4.0
username
指定运行 robot 的用户的用户名,用于 httpd 验证和 ftp 连接。
默认值为 anonymous。
username=string
robot.conf 文件示例本部分描述 robot.conf 文件的一个示例。示例中所有添加注释的参数都使用所显示的默认值。第一个参数 csid 指定使用该文件的搜索引擎实例;切勿更改此参数的值。有关本文件中参数的定义,请参阅“用户可修改的参数”。
<Process csid="x-catalog://budgie.siroe.com:80/jack" \
auto-proxy="http://sesta.varrius.com:80/"
auto_serv="http://sesta.varrius.com:80/"
command-port=21445
convert-timeout=600
depth="-1"
# email="user@domain"
enable-ip=true
enumeration-filter="enumeration-default"
generation-filter="generation-default"
index-after-ngenerated=30
loglevel=2
max-concurrent=8
site-max-concurrent=2
onCompletion=idle
password=boots
proxy-loc=server
proxy-type=auto
robot-state-dir="/var/opt/SUNWps/https-budgie.siroe.com/ \
ps/robot"
server-delay=1
smart-host-heuristics=true
tmpdir="/var/opt/SUNWps/https-budgie.siroe.com/ps/tmp"
user-agent="iPlanetRobot/4.0"
username=jack
</Process>