

|
| |
| Sun Java System Application Server Enterprise Edition 8 2004Q4 Beta Administration Guide | |
Chapter 7
Administering High Availability DatabaseThis chapter describes the high-availability database (HADB) in the Sun Java™ System Application Server 8 2004Q4 Beta Enterprise Edition environment and explains how to configure and administer the HADB. The following topics are descdribed in this chapter:
About the High-Availability DatabaseHADB Architecture
High-availability means availability despite planned outages for upgrades or unplanned outages caused by hardware or software failures. The HADB is based on a simple data model and the Always-On technology. The HADB offers an ideal platform for delivering all types of session state persistence within a high performance enterprise application server environment.
The following figure shows the architecture of a database with four active nodes and two spare nodes. Nodes 0 and 1 are a mirror node pair, as are nodes 2 and 3.
Figure 7-1 HADB Architecture
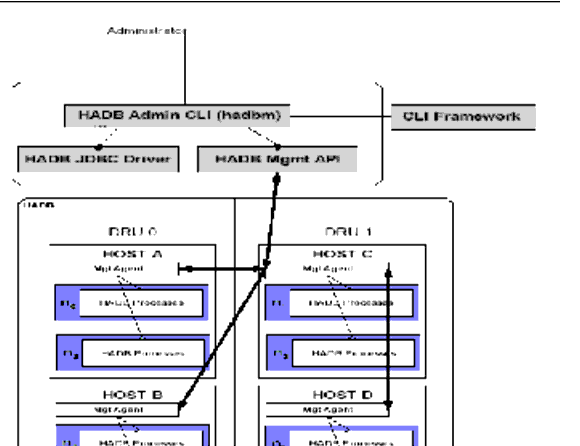
The HADB achieves high data availability through fragmentation and replication of data. All tables in the database are partitioned to create subsets of approximately the same size called fragments. This process of fragmentation is based on a hash function. This hash function fragments and evenly distributes the data among the database's nodes. Each fragment is stored twice in the database, in mirror nodes. This ensures fault tolerance and fast recovery of data. In addition, if a node fails or is shut down, a spare node can take over until the node is active again.
The HADB version included with Sun Java System Applciation Server 8 2004 Q2 Enterprise Edition, 4.4.x, contains a number of changes from the previous version, including a new management architure along with a few new commands. The hadbm interface from the earlier versions is kept with a few modifications. The new management system is a distributed system consisting of two main components:
Management Agent
The management agent is a server side process, capable of accessing resources on a host, like creating devices, starting database processes. It configures and starts the HADB management agent installed on a host that belongs to a HADB management domain. The management agent ensures the availability of the HADB nodes on the hostlist runs, by restarting them if there is a failure during operation.
On Windows platforms the availability of the management agent can be ensured by registering it as a Windows service, so that it restarts automatically when the host system reboots.
The management agent is installed in hadb_install_dir
/bin.Management Domain
An HADB management domain is a set of hosts which can be used for HADB node instances. All hosts in a domain run a management agent at the same port number, and all agents are aware of each other and their participation in the management domain. Use hadbm commands, to create, modify, or delete management domains. For more details on these commands, see the respective man pages.
MA Repository
The management agents maintains a repository where the database configuration is stored.
Before starting the management agents, you must create a directory called repository under
hadb_install_dir/HADB Nodes
A database node consists of a set of processes, a dedicated area of shared memory, and one or more secondary storage devices. It is used for storing and updating session data. Each node must have a mirror node, therefore nodes occur in pairs. In addition, to maximize availability, you should include two or more spare nodes, one in each DRU, so if a node fails a spare can take over while the node is repaired.
For an explanation of node topology alternatives, see the Sun Java System Application Server System Deployment Guide. For more general information about nodes and how to monitor them, see "Node Status".
Using the hadbm Command
Note
If you have not configured
rshorssh, thehadbmcommand will not work. For details aboutrshorsshconfiguration, see the Sun Java System Application Server Installation Guide.
The hadbm command is the CLI interface used in managing the HADB domain and its database instances. This
hadbmCLI is located in the install_dir/SUNWhadb/4/bin directory by default. Thehadbmsends management requests to the specified management agent. The database configuration information is available to the management agent from the repository.The commands you use to administer HADB are subcommands of the
hadbmcommand. The general syntax is as follows:hadbm subcommand [-short-form [argument]]* [--long-form [argument]]* [dbname]For example, the following is one use of the
hadbm statussubcommand, which lets you check the status of HADB:hadbm status --nodesThe subcommand identifies the operation or task you wish to perform. Subcommands are case-sensitive.
Options are also case-sensitive. Each option has a long form and a short form. Short forms have a single dash (
-); while long forms have two dashes (--). Options modify howhadbmperforms a subcommand. Most options require argument values, except for boolean options, which must be present to switch a feature on. Options are enclosed in square brakets [ ]and are not required for successful execution of the command.For subcommands that take a database name, if a database is not identified, the default database is used. The default database is
hadb, all lowercase.You can set the password for a subcommand from a file instead of entering the password at the command line. The
--dbpasswordfileoption takes the file containing the passwords. The valid contents for the file are:HADBM_DBPASSWORD=passwordThe rest of the contents of the file are ignored. If both the
--dbpasswordand--dbpasswordfileoptions are specified, the--dbpasswordtakes precedence. If a password is required, but is not specified in the command, you are prompted for a password.The
hadbmgeneral command options, which you can use with anyhadbmsubcommand, are listed in the following table. All are booleans that are not present by default.
Configuring the HADBThis section describes the following basic HADB configuration tasks:
Starting Management Agents
The management agent must be configured and started on all hosts where HADB will be deployed. You can start management agents using three different methods, to suit your requirements:
Use the following procedure to start the management agent on each machine that will host the HADB:
- Edit the management agent configuration file (optional).
A sample management agent configuration file, called
mgt.cfg, is installed inHADB_install_dir/lib/directory. If you have not installed HADB in the default location, edit themgt.cfgfile to enter appropriate values that match your environment.
Note
When specifying Windows paths as property values (in the
mgt.cfgfile or on the command line), ensure the following:
The configuration file, mgt.cfg, is useful for custom deployments, and can be re-used on all hosts within the same domain.
Sample configuration file available in the
Entries in the management agent configuration file, mgt.cfg- Start management agent
On Unix:
ma [-i|-r|-s] [-n name] [COMMON-OPTIONS] [AGENT-CONFIG]On Windows
ma.exe [-i|-r|-s] [-n name] [COMMON-OPTIONS] [AGENT-CONFIG]The ma command takes the options described in "ma options".
Starting the MA agent as a service
On Unix, use the the
ma-initdscript.Hardlink the
ma-initdscript located in the HADB_install_dir/bindirectory to/ etc/init.d.This will allow you to start or stop management agents manually.
ln ma-initd/etc/init.d/ma-initdThe management agents can now be start/stopped with the following command:
/etc/init.d/ma-initd {start/stop}On Windows, use the ma.exe executable with the
-ioption. See the ma command options described in "ma options"
Table 7-2 ma options
Option
Description
Type/Value-ranges
Default
--version
-V
Prints the version details of the management agent and exit
boolean
FALSE
--javahome
-j
Path to Java Runtime Environment to use for the agent (Version 1.4 or later).
Pathname
None
--define
-D
Property value assignment for an agent property defined in "Sample configuration file available in the Entries in the management agent configuration file, mgt.cfg". Can be repeated.
String
None
--systemroot
-y
Path to the operating system root as normally set in %SystemRoot%.
--service
-s
Runs the agent in Windows service manger compliant mode.
boolean
FALSE
--name
-n
Use this name for the service (when running multiple agents on a host).
String
HADBMgmtAgent
--install
-i
Installs the agent as a Windows service and starts the service.
boolean
FALSE
--remove
-r
Stops the service and deletes the agent from the Windows service manger.
boolean
FALSE
--help
-?
Prints brief description about the management agent.
boolean
FALSE
Creating Management Domains
The command,
hadbm createdomaincreates a management domain of HADB hosts listed inhostlist,by initializing the internal communication channels between hosts, along with the persistence configuration store.The following prerequisites must be met before using the
hadbm createdomaincommand:All the hosts that will be part of the desired domain must be included in the hostlist.
To form a domain, the hostlist must consist of valid network addresses and hostnames. After the management domain is successfully created, all the hosts in the domain are enabled and the management agents are ready to manage databases
Usage:
hadbm createdomain [--adminpassword=password |--adminpasswordfile=file | --no-adminauthentication --agent=maurl] hostlistAfter creating the HADB domains, you can create the HADB database that will hold your data. For more information on creating HADB databses, see "Creating a Database".
Example
Creating an HADB management domain:
hadbm createdomain--adminpassword=passwordhost1,host2,host3,host4Domain host1,host2,host3 created.
For more details on the options and operands used with hadbm createdomain, see Table 7-3 and Table 7-4.
Table 7-3 hadbm createdomain options
Table 7-4 hadbm createdomain Operands
Option
Description
Type/Value-ranges
Default
hostlist
Comma separated list of all hosts that are part of the management domain.
String
None
The following commands are available to manage HADB domains:
For more information on using these commands, see the
hadbm createdomainmanpages.Creating a Database
To manually create a database to store the session data, use the
hadbm createcommand. The syntax is as follows.hadbm create [--package=package name] [--packagepath=path][--installpath=path] [--historypath=path] [--devicepath=path] [--datadevices=devices-per-node] [--portbase=base-no] [--spares=sparecount] [--set=attr-name-value-list] [--agent=maurl] [--no-cleanup] [--no-clear] --devicesize=size --dbpassword=password | --dbpasswordfile=file --adminpassword=password | --adminpasswordfile=file | --no-adminauthentication --hosts=host list [dbname]For example:
hadbm create --spares 2 --devicesize 1024 --dbpassword secret123 --hosts n0,n1,n2,n3,n4,n5If you have difficulty creating a database, check the following:
- Sun Java System Application Server and HADB port assignments must not conflict with other port assignments on the same machine. Default and recommended port assignments are as follows:
- Sun Java System Message Queue: 7676
- IIOP: 3700
- HTTP server (UNIX root or Windows administrator): 80
- HTTP server (UNIX non-root): 1024
- Admin server (UNIX root or Windows administrator): 4848
- HADB nodes: Each node uses six consecutive ports. If the default portbase (
15200) is used, node 0 uses15200through15205, node 1 uses15220through15225, and so on.- Disk space must be adequate; see the Sun Java System Application Server Installation Guide.
Database creation errors are written to the following files:
- The Sun Java System Application Server log file. See Chapter 20, "Configuring Logging."
- The HADB history file. See "Clearing and Archiving History Files".
- The operating system's
syslogfiles if theSysLoggingconfiguration attribute is set toTRUE, the default. See "Configuration Attributes".The
hadbm createcommand options are listed in the following table.
Table 7-5
hadbm createOptionsLong Form
Short Form
Default
Description
--packagepath
Supports package registration through the create command.
--set
variable for heterogeneous path settings. This option allows for specifying different file paths for each node.
--no-clear
None
The database will not be started after create.
--no-cleanup
None
This will leave device, history, and config file if database fails to create.
--installpath
-nparent of the directory where
hadbmresides: install_dir/SUNWhadb/4/Specifies the HADB system installation path. This path must already exist and be writable. Use this option if the HADB server installation resides in a location different from the management-client machine from which the
hadbm createcommand is run.
--historypath
-t
/var/tmpSpecifies the path to the history files. This path must already exist and be writable. For details about history files, see "Clearing and Archiving History Files".
When database creation fails, the history files are removed from the HADB machines, and valuable debugging information is lost. However, if you create a writable directory with the same path as the
--historypathon the machine from which you execute thehadbm createcommand, and this machine is different from the HADB machines, the history files are saved there.
--devicepath
-d
/var/opt/SUNWhadbSpecifies the path to the devices. There are three devices: the
DataDevice, theNiLogDevice(node internal log device), and theRelalgDevice(relational algebra query device). This path must already exist and be writable. To set this path differently for each node or each device, see "Setting Heterogeneous Device Paths".
--configpath
-c
/etc/opt/SUNWhadbSpecifies the path to the configuration files used internally by the HADB. This path must already exist and be writable.
--datadevices
-a
1Specifies the number of data devices on each node, between 1 and 8 inclusive. Data devices are numbered starting at 0.
--portbase
-b
15200Specifies the port base number used for node 0. Successive nodes are automatically assigned port base numbers in steps of 20 from this number. Each node uses its port base number and the next five consecutively numbered ports.
If you want to run several databases on the same machine, you should have a plan for allocating port numbers and allocate them explicitly.
--spares
-s
0Specifies the number of spare nodes. This number must be even and must be less than the number of nodes specified in the
--hostsoption. Spare nodes are optional, but having two or more ensures high availability.
--set
-Snone
Specifies a comma-separated list of database configuration attributes in name=value format. For explanations of valid database configuration attributes, see "Viewing and Modifying Configuration Attributes".
For example, to specify the use of
rshinstead ofssh(the default), use the following option:--set ManagementProtocol=rshTo use
--setto set the--devicepathdifferently for each node or each device, see "Setting Heterogeneous Device Paths".
--inetd
-Inot specified
If specified, the database is configured to run with the
inetddaemon, and is not automatically started after it is created.
--inetdsetupdir
-ucurrent directory
Specifies the directory in which to store the
inetdsetup files. The directory must exist and be writable.
--devicesize
-znone
Specifies the size of each device in MB. The device size should be as large as possible. The recommended size is four times the expected size of the user data, based on the number of users and the size of each user record.
The maximum size is the maximum operating system file size or 256 GB, whichever is smaller. The minimum size is as follows:
(4 x
LogbufferSize+ 16MB) /--datadevicesYou can increase the device size later as described in "Adding Storage Space to Existing Nodes".
For more information on setting the
LogbufferSize, see "Viewing and Modifying Configuration Attributes".
--dbpassword
-pnone
Creates a password for the HADB system user. Must be at least 8 characters. You can use
--dbpasswordfileinstead. For details, see "Using the hadbm Command".
--dbpasswordfile
-Pnone
Specifies a file that stores the password to be created for the HADB system user. For details, see "Using the hadbm Command".
--adminpassword
-w
none
The administrator password to manage the domain. If you use the
adminpasswordoption withhadbm createdomainorhadbm create, then you must enter this password each time you use any hadbm command.--adminpasswordfile
-W
None
Use the adminpasswordfile option to provide the password as a path to a file that contains the password
--no-adminauthentication
-U
None
The --no-adminauthentication option allows the administrator to use all hadbm commands without providing the administrator's password.
--hosts
-Hnone
Specifies a comma-separated list of host names or IP addresses for the nodes in the database. Using IP addresses is recommended because there is no dependence on DNS lookups. Host names must be absolute. You cannot use
localhostor127.0.0.1as a host name.One node is created for each comma-separated item in the list. The number of nodes must be even. Using duplicate host names creates multiple nodes on the same machine with different port numbers. Make sure that nodes on the same machine are not mirror nodes.
Nodes are numbered starting at
0in the order listed in this option. The first mirrored pair are nodes0and1, the second2and3, and so on. Odd numbered nodes are in one DRU, even numbered nodes in the other. If--sparesis used, spare nodes are those with the highest numbers.For information about configuring double network interfaces, see "Configuring Double Networks".
dbname
none
hadbSpecifies the database name, which must be unique. To make sure the database name is unique, use the
hadbm listcommand to list existing database names.Use the default database name unless you need to create multiple databases. For example, to create multiple clusters with independent databases on the same set of HADB machines, use a separate database name for each cluster.
Setting Heterogeneous Device Paths
You can use the
--setoption ofhadbm createto set the--devicepathdifferently for each node or each device. There are three types of devices: theDataDevice, theNiLogDevice(node internal log device), and theRelalgDevice(relational algebra query device). The syntax for each name=value pair is as follows, where-devno is required only if the device isDataDevice:Node-nodeno.device-devno.Path=pathFor example:
--set Node-0.DataDevice-0.Path=/disk0,Node-1.DataDevice-0.Path=/disk1Any device path that is not set for a particular node or device defaults to the
--devicepathvalue. You cannot change device paths using thehadbm setorhadbm addnodescommands.Configuring Double Networks
To allow the HADB to tolerate single network failures, you can equip each HADB machine with two NIC cards. For each machine, the IP addresses of each of the NIC cards must be on separate IP subnets.
During database creation, you specify two IP addresses or host names for each node, one for each NIC card IP address, using the
--hostsoption. For each node, the first IP address is onnet-0and the second onnet-1. The syntax is as follows, with host names for the same node separated by a plus sign (+):--hosts=node0net0name+node0net1name,node1net0name+node1net1name,node2net0name+node2net1name, ...For example, the following creates two nodes, each with two host names. The host names for node 0 are
n0aandn0b, and the host names for node 1 aren1aandn1b. Then0aandn1ahosts are onnet-0, and then0bandn1bhosts are onnet-1.--hosts n0a+n0b,n1a+n1bWithin a database, all nodes must have one host name, or all nodes must have two host names. A database cannot have a mixture of nodes with double host names and single host names.
Setting Up the JDBC Connection Pool
The Sun Java System Application Server communicates with the HADB in the same way that it communicates with relational databases used for data storage, therefore you need to set up a JDBC connection pool for the HADB as you would for any other database.
Using the
clsetupcommand is recommended for configuring a JDBC connection pool and JDBC resource for the HADB in the Sun Java System Application Server. This command is described in the Sun Java System Application Server Installation Guide.Manual configuration of a JDBC connection pool and JDBC resource for the HADB is briefly summarized in these sections:
For general information about connection pools and JDBC resources, see "JDBC Resources".
Getting the JDBC URL
Before you can set up the JDBC connection pool, you need to determine the JDBC URL of the HADB using the
hadbm getcommand as follows:hadbm get JdbcUrl [dbname]For example:
hadbm get JdbcUrlThe JDBC URL is displayed on the standard output device in the following form:
jdbc:sun:hadb:host:port,host:port,...Remove the
jdbc:sun:hadb:prefix and use the host:port,host:port...part as the value of theserverListconnection pool property, described in the next section.Creating a Connection Pool
The following table summarizes connection pool settings required for the HADB. Change Steady Pool Size when adding nodes, but do not change other settings.
The following table summarizes connection pool properties required for the HADB. Change
serverListwhen adding nodes, but do not change other properties.
Table 7-7 HADB Connection Pool Properties
Property
Description
usernameSpecifies the name of the
storeuserto be specified in theasadmin create-session-storecommand.
passwordSpecifies the
storepasswordto be specified in theasadmin create-session-storecommand.
serverListSpecifies the JDBC URL of the HADB. To determine this value, see "Getting the JDBC URL".
You must change this value if you add nodes to the database. See "Adding Nodes to the HADB".
cacheDatabaseMetaDataSetting this property to
falseas required ensures that calls toConnection.getMetaData()make calls to the database, which ensures that the connection is valid.
eliminateRedundantEndTransactionSetting this property to
trueas required improves performance by eliminating redundant commit and rollback requests and ignoring these requests if no transaction is open.
maxStatementSpecifies the maximum number of statements per open connection that are cached in the driver statement pool. Set this property to
20.
Connection Pool Example
Here is an example
asadmin create-jdbc-connection-poolcommand that creates an HADB JDBC connection pool. For more details about this command, see the Sun Java System Application Server Developer's Guide to J2EE Services and APIs.asadmin create-jdbc-connection-pool --user adminname --password secret --datasourceclassname com.sun.hadb.jdbc.ds.HadbDataSource --steadypoolsize=32 --isolationlevel=repeatable-read --isconnectvalidatereq=true --validationmethod=meta-data --property username=storename:password=secret456:serverList=host\\:port,host\\:port,host\\:p ort,host\\:port,host\\:port,host\\:port:cacheDatabaseMetaData=false:eliminateRedund antEndTransaction=true hadbpoolNote that colon characters (
:) within property values must be escaped with double backslashes (\\) on Solaris™ platforms, because otherwise they are interpreted as property delimiters. On Windows platforms, colon characters (:) must be escaped with single backslashes (\).Creating a JDBC Resource
The following table summarizes JDBC resource settings required for the HADB.
Table 7-8 HADB JDBC Resource Settings
Setting
Description
JNDI Name
The following JNDI name is the default in the session persistence configuration:
jdbc/hastore. You can use the default name or a different name.You must also specify this JNDI name as the value of the
store-pool-jndi-namePersistence Store property when you activate the availability service. See Chapter 6, "JDBC Resources."Pool Name
Select from the list the name (or ID) of the HADB connection pool used by this JDBC resource. For more information, see "Creating a Connection Pool".
Data Source Enabled
Checked/true
Managing the HADBIn general, management operations are not necessary unless you are replacing or upgrading your network, hardware, operating system, or HADB software. The following sections explain various management operations:
Starting a Node
If no node is running in the database, use
hadbm clearto start the nodes even if you are running withinetd. See "Clearing the HADB".You may want to start a node in the following circumstances:
- If you have stopped a node, for example for hardware or software replacement. See "Stopping a Node".
- If a node has stopped due to a hardware failure, after the hardware has been mended.
- If a node has stopped due to a software failure and the node was unable to recover automatically.
In most cases, you should first attempt to start the node using the
normalstart level. You must use therepairstart level if starting a node using thenormalstart level fails or times out.To start a node in the database, use the
hadbm startnodecommand. The syntax is as follows:hadbm startnode [--startlevel=level] nodeno [dbname]For example:
hadbm startnode 1The
hadbm startnodecommand options are listed in the following table.
Stopping a Node
You may want to stop a node if you want to replace hardware or software on the machine, and you need to stop the machine.
Caution
Do not stop a node if its mirror node is not running, because this may force the database into a Non Operational state. For details about node status, see "Getting the Status of the HADB".
To stop a node in the database, use the
hadbm stopnodecommand. The syntax is as follows:hadbm stopnode [--no-repair] nodeno [dbname]For example:
hadbm stopnode 1
The
hadbm stopnodecommand options are listed in the following table.
Restarting a Node
You may want to restart a node if you notice strange behavior in a node (for example excessive CPU consumption) and want to check whether a restart cures the problem.
Caution
Do not stop a node if its mirror node is not running, because this may force the database into a Non Operational state. For details about node status, see "Getting the Status of the HADB".
To restart a node in the database, use the
hadbm restartnodecommand. The syntax is as follows:hadbm restartnode [--startlevel=level] nodeno [dbname]For example:
hadbm restartnode 1The
hadbm restartnodecommand options are listed in the following table.
Starting the HADB
To start a database, use the
hadbm startcommand. The syntax is as follows:hadbm start [dbname]For example:
hadbm startThe default dbname is
hadb, all lowercase.This command starts all nodes that were running before the database was stopped. Individually stopped (offline) nodes are not started when the database is started after a stop.
Stopping the HADB
When you stop and start the HADB in separate operations, data is unavailable while the HADB is stopped. To keep data available, you can restart the HADB as described in "Restarting the HADB".
You may want to stop the HADB in the following circumstances:
- If you want to remove the HADB database.
- If you want to perform system maintenance that affects all HADB nodes.
- Before executing the
hadbm clearcommand to reinitialize the database. See "Clearing the HADB".Before stopping the HADB, you should either stop dependent Sun Java System Application Server instances or configure them to use a different persistence method.
Note
If you stop the HADB with
hadbm stop, you must start it withhadbm start, even ifinetdis used, becauseinetdcan't start offline nodes.
To stop a database, use the
hadbm stopcommand. The syntax is as follows:hadbm stop [dbname]For example:
hadbm stopThe default dbname is
hadb, all lowercase. For more information about database states, see "Getting the Status of the HADB".When you stop the database, all the running nodes in the database are stopped and the status of the database is Stopped.
Restarting the HADB
You may want to restart the HADB if you notice strange behavior in the HADB (for example consistent timeout problems) and want to check whether a restart cures the problem.
When you restart the HADB, data and database services remain available. When you stop and start the HADB in separate operations, data and database services are unavailable while the HADB is stopped. This is because
hadbm restartperforms a rolling restart of nodes: it stops and starts the nodes one by one. In contrast,hadbm stopstops all nodes simultaneously.If an
hadbm setcommand fails, restarting the HADB restores the previous configuration. For details abouthadbm set, see "Viewing and Modifying Configuration Attributes".To restart a database, use the
hadbm restartcommand. The syntax is as follows:hadbm restart [--no-rolling] [dbname]For example:
hadbm restartThe default dbname is
hadb, all lowercase. By default, this command restarts each of the nodes in the database to the current state or a better state. If you specify the--no-rollingor-goption, this command restarts all nodes at once, with loss of service.Listing Databases
To list all the databases that have been created, use the
hadbm listcommand. The syntax is as follows:hadbm listClearing the HADB
You may want to clear the HADB in the following circumstances:
- If you are creating a database that uses
inetd.- If the
hadbm statuscommand reveals that the database is Non Operational or that multiple nodes are in the Waiting state. See "Getting the Status of the HADB".- If you are recovering from session data corruption. See "Recovering from Session Data Corruption".
The
hadbm clearcommand stops the database nodes, clears the database devices, then starts the nodes. The syntax is as follows.hadbm clear [--fast] [--spares=sparecount] --dbpassword=password | --dbpasswordfile=file [dbname]For example:
hadbm clear --fast --spares=2 --dbpassword secret123The
hadbm clearcommand options are listed in the following table.
Table 7-12
hadbm clearOptionsLong Form
Short Form
Default
Description
--fast
-Fnot present
If present, skips device initialization while initializing the database. Do not use if the disk storage device is corrupted or if you have just created the database and set up
inetd.
--spares
-sprevious number of spares
Specifies the number of spare nodes the reinitialized database will have. This number must be even and must be less than the number of nodes in the database. Spare nodes are optional, but having two or more ensures high availability.
--dbpassword
-pnone
Specifies the HADB system user password. You can use
--dbpasswordfileinstead. For details, see "Using the hadbm Command".
--dbpasswordfile
-Pnone
Specifies a file that stores the password for the HADB system user. For details, see "Using the hadbm Command".
dbname
none
hadbSpecifies the database name.
Removing a Database
The database you want to remove must exist and must be in the Stopped state. See "Stopping the HADB". To remove an existing database from the HADB system, use the
hadbm deletecommand. The syntax is as follows:hadbm delete [dbname]For example:
hadbm deleteThe default database name is
hadb, all lowercase. When you execute this command, the configuration files, device files, log files, and history files of the database are deleted, and shared memory resources are freed.
Expanding the HADBIf you determine that your system performance is limited because the HADB cannot persist data fast enough, you can expand the HADB to increase throughput without shutting down your Sun Java System Application Server cluster or the HADB. This section describes how you can expand the HADB in the following sections:
You should also read "Maintaining the HADB Machines".
Adding Storage Space to Existing Nodes
You may want to add storage space to the HADB in the following circumstances:
- If there is unused space on the disks on which the HADB nodes reside, or if you have upgraded these disks.
- If one of the following messages appears:
4592: No free blocks on data devices4593: No unreserved blocks on data devices- If the
hadbm deviceinfocommand reports insufficient free size. See "Getting Device Information".You can increase the device size in MB using either of the following
hadbm setcommands:hadbm set DataDeviceSize=sizehadbm set TotalDatadeviceSizePerNode=sizeFor example:
hadbm set DataDeviceSize=1024The
TotalDatadeviceSizePerNodeis equal to theDataDeviceSizemultiplied by theNumberOfDatadevices. Therefore,TotalDatadeviceSizePerNodeandDataDeviceSizeare mutually dependent: changing one changes the other.The
DataDeviceSizeshould be as large as possible. The recommended size is four times the expected size of the user data, based on the number of users and the size of each user record.Changing the
DataDeviceSizeorTotalDatadeviceSizePerNodeon a database in a FaultTolerant or higher state means that the system is upgraded without loss of data, and the database remains in an Operational state during the reconfiguration. If you change device size on a system that is not FaultTolerant or better, data is lost. For more information about database states, see "Database Status".Adding Machines
You may want to add machines if the HADB requires more processing or storage capacity. For an explanation of node topology alternatives, see the Sun Java System Application Server System Deployment Guide.
To add a new machine on which to run the HADB, install the HADB packages with or without the Sun Java System Application Server as described in the Sun Java System Application Server Installation Guide.
Adding Nodes to the HADB
When you create new nodes and add them to the database, you increase processing and storage capacity. To add nodes, use the
hadbm addnodescommand. The syntax is as follows:hadbm addnodes [--no-refragment] [--spares=sparecount] --dbpassword=password | --dbpasswordfile=file [--inetdsetupdir=path] --hosts=node-list [dbname]For example:
hadbm addnodes --dbpassword secret123 --hosts n6,n7,n8,n9After you have added nodes, you must perform these additional tasks:
For details, see "Setting Up the JDBC Connection Pool".
The
hadbm addnodescommand options are listed in the following table.
Table 7-13
hadbm addnodesOptionsLong Form
Short Form
Default
Description
--no-refragment
-rnot specified
If specified, does not refragment the database during node creation; you can refragment the database later using the
hadbm refragmentcommand. For details about refragmentation, see "Refragmenting the HADB".You must use this option if you created the database using
--inetd. In this case, you must refragment the database in a separate step usinghadbm refragment.If you do not have sufficient device space for a refragmentation, you can recreate the database with more nodes. See "Adding Nodes Without Refragmenting".
--spares
-s
0Specifies the number of new spare nodes in addition to those that already exist. This number must be even and must not be greater than the number of nodes added. Spare nodes are optional, but having two or more ensures high availability.
--dbpassword
-pnone
Specifies the HADB system user password. You can use
--dbpasswordfileinstead. For details, see "Using the hadbm Command".
--dbpasswordfile
-Pnone
Specifies a file that stores the password for the HADB system user. For details, see "Using the hadbm Command".
--hosts
-Hnone
Specifies a comma-separated list of new host names for the new nodes in the database. One node is created for each comma-separated item in the list. The number of nodes must be even.
Using duplicate host names creates multiple nodes on the same machine with different port numbers. Make sure that nodes on the same machine are not mirror nodes.
Odd numbered nodes are in one DRU, even numbered nodes in the other. If
--sparesis used, new spare nodes are those with the highest numbers.If the database was created with double network interfaces, the new nodes must be configured in the same way. See "Configuring Double Networks".
dbname
none
hadbSpecifies the database name. The database must be in the HA Fault Tolerant or Fault Tolerant state. For more information about database states, see "Getting the Status of the HADB".
Refragmenting the HADB
You must refragment the database before new nodes can store data. Refragmentation is required to store data evenly across all active nodes. To refragment the database, use the
hadbm refragmentcommand. The syntax is as follows:hadbm refragment --dbpassword=password | --dbpasswordfile=file [dbname]For example:
hadbm refragment --dbpassword secret123Refragmentation requires that the user data size not exceed 50% of the space available for user data. For details, see "Getting Device Information".
If this command fails even after multiple attempts, see "Adding Nodes Without Refragmenting".
The
hadbm refragmentcommand options are listed in the following table.
Table 7-14
hadbm refragmentOptionsLong Form
Short Form
Default
Description
--dbpassword
-pnone
Specifies the HADB system user password. You can use
--dbpasswordfileinstead. For details, see "Using the hadbm Command".
--dbpasswordfile
-Pnone
Specifies a file that stores the password for the HADB system user. For details, see "Using the hadbm Command".
dbname
none
hadbSpecifies the database name. The database must be in the HA Fault Tolerant or Fault Tolerant state. For more information about database states, see "Getting the Status of the HADB".
Adding Nodes Without Refragmenting
If you don't refragment the database when adding nodes, you must clear the database and recreate the session store instead, otherwise the session store can't use the new nodes. You should not add nodes without refragmenting the database unless you can tolerate losing all data stored in the database. However, it may be the best alternative if all of the following conditions are met:
- You don't have enough disk space to expand each node as described in "Adding Storage Space to Existing Nodes".
- The user data size exceeds 50% of the space available for user data, which means you cannot refragment as described in "Refragmenting the HADB".
- You are not passivating the session state.
To add nodes without refragmenting, perform the following tasks:
- Perform the following tasks for each server instance:
- Disable the server instance in the load balancer, as described in the Release Notes.
- Disable session persistence.
- Restart the server instance.
- Re-enable the server instance in the load balancer.
If you do not need to maintain availability, you can disable and reenable all the server instances at once in the load balancer. This saves time and prevents failover of outdated session data.
- Stop the database as described in "Stopping the HADB".
- Delete the database as described in "Removing a Database".
- Recreate the database with the additional nodes as described in "Creating a Database".
- Reconfigure the JDBC connection pool as described in "Setting Up the JDBC Connection Pool". You can also use the
cladmincommand.- Reload the session persistence store. You can also use the
cladmincommand.- Perform the following tasks for each server instance:
- Disable the server instance in the load balancer.
- Enable session persistence.
- Restart the server instance.
- Re-enable the server instance in the load balancer.
If you do not need to maintain availability, you can disable and reenable all the server instances at once in the load balancer. This saves time and prevents failover of outdated session data.
Monitoring the HADBYou can monitor the activities in the HADB by performing the following tasks:
These sections briefly describe the
hadbm status,hadbm deviceinfo, andhadbm resourceinfocommands. For details about interpreting HADB information, see the Sun Java System Application Server Performance Tuning Guide.Getting the Status of the HADB
To display the status of the database or its nodes, use the
hadbm statuscommand. The syntax is as follows:hadbm status [--nodes] [dbname]For example:
hadbm status --nodesThe physical node number is associated with a specific database node and port number combination, and does not vary during the life of the database. The logical node number, on the other hand, can vary during the lifetime of the database. Initially, logical node numbers are identical to physical node numbers for active nodes used to store data. Logical node numbering can change if individual nodes are stopped (for example, for maintenance), and spare nodes take over.
The
hadbm status --nodescommand gives information about both physical and logical node numbers. All other hadbm subcommands deal with physical node numbers only. You only need to know about logical node numbers if you need to know which nodes are currently mirror nodes. This information is useful when you are performing maintenance on machines. See "Maintaining the HADB Machines".The
hadbm statuscommand options are listed in the following table.
Table 7-15
hadbm statusOptionsLong Form
Short Form
Default
Description
--nodes
-nnot present
If present, displays node status information. See "Node Status".
dbname
none
hadbSpecifies the database name.
Database Status
The possible states of a database are as follows:
- High-Availability Fault Tolerant (HAFT) - The database is fault tolerant and has at least one spare node on each DRU.
- Fault Tolerant (FT) - All the mirrored node pairs are up and running.
- Operational (O) - At least one node in each mirrored node pair is running.
- Non Operational (NO) - One or more mirrored node pairs is missing both nodes.
- Stopped (S) - No nodes are running in the database.
- Unknown (U) - The command cannot determine the state of the database.
If the database is Non Operational, clear the database using
hadbm clearas described in "Clearing the HADB".Node Status
If you specify the
--nodesoption, the following information is displayed for each node in the database:
- Node number
- Name of the machine where the node is running
- Port number of the node
- Role of the node. For a list of possible roles and their meanings, see "Roles of a Node".
- State of the node. For a list of possible states and their meanings, see "States of a Node".
- Number of the corresponding mirror node.
A node's role and state can change as described in these sections:
Roles of a Node
A node is assigned a role during its creation and can take any one of these roles:
- Active: An active node allows data storage and client access. Active nodes are in mirrored pairs.
- Spare: After having their data devices initialized, spare nodes monitor other data nodes to initiate repair if another node becomes unavailable. A spare node allows client access, but not data storage.
- Offline: A node is taken offline prior to stopping it to prevent restart by
inetd. Offline nodes provide no services until their role changes. An offline node's role can change back to its former role.- Shutdown: An intermediate step between active and offline, which a node occupies while waiting for a spare node to take over its functioning. After the spare node has taken over, the node is taken offline.
States of a Node
A node can be in any one of the following states:
- Starting: The node is starting.
- Waiting: The node cannot decide its start level and is offline. If a single node is in this state for more than two minutes, stop the node and then start it at the
repairlevel; see "Stopping a Node" and "Starting a Node". If multiple nodes are in this state, clear the database as described in "Clearing the HADB".- Running: The node is providing all services that are appropriate for its role.
- Stopping: The node is in the process of stopping.
- Stopped: The node is inactive. Repair of a stopped node is prohibited.
- Recovering: The node is being recovered. When a node fails, the mirror node takes over the functions of the failed node. The failed node tries to recover by using the data and log records in main memory or on disk. The failed node uses the log records from the mirror node to catch up with the transactions performed when it was down. If recovery is successful, the node becomes active. If recovery fails, the node state changes to Repairing.
- Repairing: The node is being repaired. This operation reinitializes the node and copies the data and log records from the mirror node. Repair is more time consuming than recovery.
Getting Device Information
Monitoring the HADB involves making sure that there is enough free space for the growth of the database. To get information about disk storage devices on each active node, use the
hadbm deviceinfocommand. The syntax is as follows:hadbm deviceinfo [--details] [dbname]For example:
hadbm deviceinfo --detailsThe default dbname is
hadb.The information displayed for each node of the database includes:
To determine the space available for user data, take the total device size, then subtract 4 times the
LogBufferSize. If you do not know the size of the log buffer, use the commandhadbm get logbufferSize. For example, if the total device size is 128 MB and theLogBufferSizeis 24 MB, the space available for user data is 128 - (4 x 24) = 32 MB.The difference between the total device size and the free size is the user data size. If the data may be refragmented in the future, the user data size should not exceed 50% of the space available for user data. If refragmentation is not relevant, close to 100% may be used. Resource consumption warnings are written to the history files when the system is running short on device space.
For more information about tuning the HADB, see the Sun Java System Application Server Performance Tuning Guide.
If the
--detailsoption is specified, additional information is displayed:For example:
NodeNO Totalsize Freesize Usage NReads NWrites DeviceName0 128 120 6% 10000 5000 /var/opt/hadb.data.01 128 124 3% 10000 5000 /var/opt/hadb.data.12 128 126 2% 9500 4500 /var/opt/hadb.data.23 128 126 2% 9500 4500 /var/opt/hadb.data.3If you need additional information, you can use the
hadbm resourceinfocommand. This command displays HADB runtime resource information that helps to identify resource contention, which you can use to reduce performance bottlenecks. For details, see the Sun Java System Application Server System Deployment Guide and the Sun Java System Application Server Performance Tuning Guide. The syntax is as follows:hadbm resourceinfo [--databuf] [--locks] [--logbuf] [--nilogbuf] [dbname]The following database information is displayed based on the options you specify:
For example, data buffer pool information is as follows:
NodeNO Avail Free Access Misses Copy-on-Write
0 256 128 100000 50000 1000
1 256 128 110000 45000 950Locks information is as follows:
For example:
NodeNO Avail Free Waits
0 50000 20000 10
1 50000 20000 0No more than 50% of the allocated locks are used for primary recording operations. The other 50% are reserved for hot standby recording operations. To change the
NumberOfLocks, see "Viewing and Modifying Configuration Attributes".Log buffer information is as follows:
For example:
NodeNO Avail Free
0 16 2
1 16 3Node internal log device information is as follows:
For example:
NodeNO Avail Free
0 16 2
1 16 3
Maintaining the HADB MachinesThe HADB achieves fault tolerance by replicating data on mirror nodes. Mirror nodes should be placed on separate DRUs in a production environment as described in "HADB Architecture".
A failure is an unexpected event such as a hardware failure, power failure, or operating system reboot. The HADB tolerates single failures: of one node, one machine (that has no mirror node pairs), one or more machines belonging to the same DRU, or even one entire DRU. However, the HADB does not automatically recover from a double failure, which is the simultaneous failure of one or more mirror node pairs. If a double failure occurs, you must clear the HADB and recreate its session store, which erases all its data.
Installing the entire HADB on a single machine is recommended only for development and test environments, because in this case any failure except a single node failure is a double failure.
Caution
Before performing any maintenance, make sure you know which nodes are mirror nodes so you don't shut down a mirror node pair and make the database Non Operational. See "Getting the Status of the HADB".
Otherwise, to perform planned or unplanned maintenance on a single machine without interrupting HADB service:
- For planned maintenance, stop all nodes on the machine. See "Stopping a Node".
- Perform the maintenance procedure and get the machine up and running.
- Start all nodes on the machine if either of the following is true:
- If you stopped all nodes manually in Step 1, regardless of whether you are using
inetd- If you are not using
inetd, regardless of how the nodes were stoppedSee "Starting a Node".
- Check whether the nodes are active and running. See "Getting the Status of the HADB".
To perform planned maintenance on all HADB machines without interrupting HADB service:
To perform planned maintenance with HADB service interruption on all HADB machines, or when the entire HADB is on a single machine:
- Stop the HADB. See "Stopping the HADB".
- Perform the maintenance procedure and get all the machines up and running.
- Start the HADB. See "Starting the HADB". The data stored in the database before the stop is available again.
To perform unplanned maintenance in the event of a failure, first check the database status. See "Getting the Status of the HADB".
- If the database state is Operational or better, this means the machines needing unplanned maintenance do not include mirror nodes. Follow the single machine procedure for each failed machine, one DRU at a time. HADB service is not interrupted.
- If the database state is Non-Operational, this means the machines needing unplanned maintenance include mirror nodes. One such case is when the entire HADB is on a single failed machine. Get all the machines up and running first. Then clear the HADB and recreate the session store. See "Clearing the HADB". This interrupts HADB service.
Viewing and Modifying Configuration AttributesYou can modify database configuration attributes. This section describes the following tasks:
Getting the Values of Configuration Attributes
To get the values of configuration attributes (for a list, see "Configuration Attributes"), use the
hadbm getcommand. The syntax is as follows:hadbm get attribute-list | --all [dbname]For example:
hadbm get JdbcUrl,NumberOfSessionsThe default dbname is
hadb. The attribute-list is a comma-separated or quote-enclosed space-separated list of attributes. The--alloption displays values for all attributes.Setting the Values of Configuration Attributes
To set the values of configuration attributes (for a list, see "Configuration Attributes"), use the
hadbm setcommand. The syntax is as follows:hadbm set [dbname] attribute=value,attribute=value ...The default dbname is
hadb. The attribute-list is a comma-separated or quote-enclosed space-separated list of attributes.If execution of this command is successful, the database is restarted in the state it was in previously, or in a better state. For information about database states, see "Getting the Status of the HADB".
If execution of this command is unsuccessful, restart the HADB as described in "Restarting the HADB".
The following attributes cannot be set by
hadbm set, but can be set during database creation using--setor other options ofhadbm create:ConfigPath,DatabaseName,DevicePath,HistoryPath,InstallPath,ManagementProtocol,NumberOfDatadevices, andPortbase. For information abouthadbm create, see "Creating a Database".The
JdbcUrlattribute value is derived from the--hostsand--portbaseoptions during database creation withhadbm createand cannot be set byhadbm setor the--setoption.All other attributes listed in Table 7-16 can be set using
hadbm set.
Configuration Attributes
The following table lists the configuration attributes that you can get and set. Except where noted, sizes are in MB, and times are in seconds.
Clearing and Archiving History FilesHADB history files contain a record of database operations and error messages. The location of these files is determined by the
--historypathoption of thehadbm createcommand. The default location is/var/tmp. These files have names of the format dbname.out.nodeno. For details abouthadbm create, see "Creating a Database".These history files grow over time. To save space and prevent files from getting too large, you should periodically clear and archive older history files. To clear the history files of a database, use the
hadbm clearhistorycommand. The syntax is as follows:hadbm clearhistory [--saveto=path] [dbname]The default dbname is
hadb.Use the
--savetoor-ooption to specify a directory if you want to store the old history files. This directory must have write permissions set.Each message in the history file contains the following information:
Messages about resource shortages contain
HIGH LOAD.You do not need a detailed knowledge of all the various types of entries in the history file. If for any reason you need to study a history file in greater detail, you should obtain help from Sun customer support. See "Using Sun Customer Support for the HADB".
Recovering from Session Data CorruptionThe following are indications that session data may be corrupted:
- Error messages appear in the Sun Java System Application Server system log (server log) every time you try to save the session state.
- Error messages are written to the server log indicating that the session could not be found or could not be loaded during session activation.
- Sessions that are activated after previously being passivated contain empty or incorrect session data.
- When an instance fails, failed-over sessions contain empty or incorrect session data.
- When an instance fails, instances that try to load a failed-over session cause an error in the server log indicating the session could not be found or could not be loaded.
To bring the session store back to a consistent state if you determine that the data has been corrupted, do the following:
- Clear the session store.
- If clearing the session store doesn't work or you continue to see errors in the server log, reinitialize the data space on all the nodes and clear the data in the database. See "Clearing the HADB".
- If clearing the database doesn't work, delete and then recreate the database. See "Removing a Database" and "Creating a Database".
Using Sun Customer Support for the HADBBefore calling Sun customer support about HADB issues, you should gather as much of the following information about your system as possible:
Environment VariablesThis table lists environment variables that correspond to
hadbmcommand options.