| Oracle® Enterprise Data Quality for Product Data Fusion PIM Integration Implementation and User's Guide Release 5.6.2 Part Number E27167-01 |
|
|
View PDF |
| Oracle® Enterprise Data Quality for Product Data Fusion PIM Integration Implementation and User's Guide Release 5.6.2 Part Number E27167-01 |
|
|
View PDF |
Oracle DataLens Server is built on industry-leading DataLens™ Technology to standardize, match, enrich, and correct product data from different sources and systems. The core DataLens Technology uses patented semantic technology designed from the ground up to tackle the extreme variability typical of product data.
Oracle Enterprise Data Quality for Product Data, formerly Oracle Product Data Quality, uses three core DataLens Technology modules: Governance Studio, Knowledge Studio, and Application Studio. The following figure illustrates the process flow of these modules.
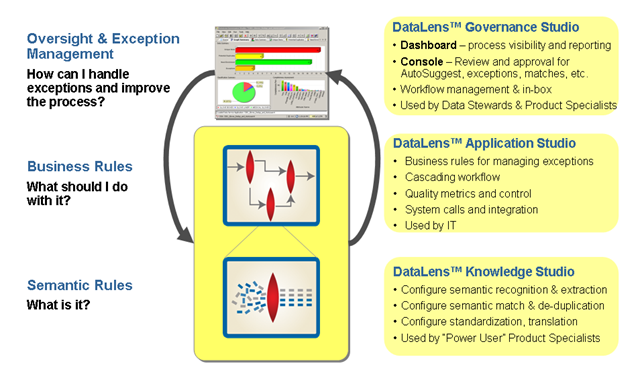
The Oracle DataLens Server can be configured to run with multiple servers:
Oracle DataLens Administration Server
Oracle DataLens Transform Server
The administration of all servers in a multi-server configuration is controlled with the Oracle DataLens Administration Server. The purpose of the Administration Server is to manage the various administrative tasks of the servers for the server groups (referred to as Transform Servers) and can itself serve as its own Transform Server when installed alone in a single node configuration. By spreading the data processing load across multiple servers the Oracle DataLens Server system provides scalability and configuration control over the various functional areas involved in developing, testing, and ultimately executing Oracle DataLens jobs.
The type of Oracle DataLens Server Group that a Transform Server belongs to controls the individual server functionality. A server group may contain one or many physical servers. There are three types of server groups:
Development Server Group
Production Server Group
Quality Assurance Server Group
The Server Groups contain individual Oracle DataLens Servers on physical machines that can load balance among servers within the group. The data lenses and DataLens Service Applications (DSAs) are deployed from one group to the next beginning with the development group, then migrating to the Quality Assurance Group for testing before arriving in the Production Group for deployment to production. This multiple group migration function facilitates an enterprise business process where multiple functional areas work on data lens objects in stages before releasing them to production.
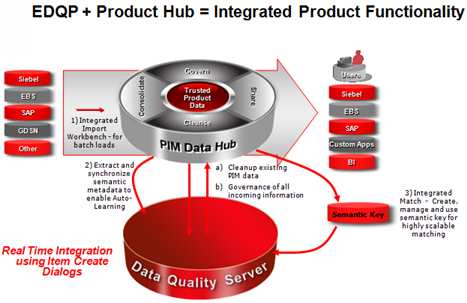
The integration of Oracle Fusion Product Information Management (PIM) and Enterprise DQ for Product (EDQP) adds a package called the "Fusion PIM" to the Enterprise DQ for Product solution upload package.
The integration of the EDQP solution with the Fusion PIM Data Hub (PIMDH) provides an integrated set of capabilities to categorize, standardize, match, govern, validate, and correct product data being introduced from any source system(s) or catalog(s). The EDQP Fusion PIMDH solution delivers an out of the box integration DSA that facilitates the real time data quality processes using the Fusion PIMDH Batch Import and the New Item Create processes.
The system can be configured to perform any or all of these checks on all batches of data being imported into the system using the Fusion PIMDH Import Workbench process. These configuration steps are fully described in this document. The integration is delivered with a set of preconfigured integration files that can be personalized to meet your project requirements. The files allow you to run operations such as populating user defined attributes (Form, Fit or Function) for an item on-boarding process using the EDQP system.
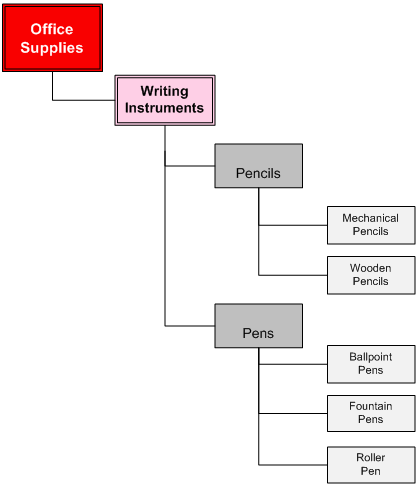
For most effective metadata synchronization, the PIM ICC structure should be set up as a product hierarchy. For example, you might have a four-level hierarchy consisting of the following levels:
A product hierarchy contains multiple levels and each level is identified by a set of defining attributes. The levels must be non-overlapping and unique. Each item in PIM should belong to one and only one ICC. The category-specific descriptive attributes must be defined at the leaf-node level while the more general category attributes may be defined at higher ICC levels.
The following is an example of well-formed four-level product hierarchy:
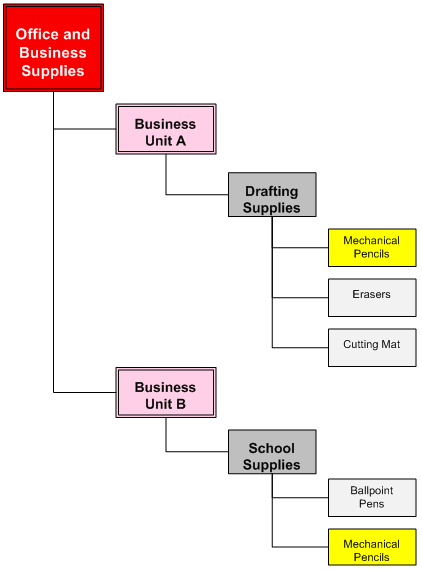
In contrast, the following diagram shows an example of a business-unit/product hierarchy. This type of hierarchy combines business unit structure with product structure. Although this type of structure may be useful within business organizations, it can undermine the value of a PIM system.
In the following example, note that the category "Mechanical Pencils" occurs in more than one place in the hierarchy. This type of hierarchy is not ideal for PIM ICC setup; use of this structure will result in lower data quality and higher costs related to maintaining data quality:
There is a one-to-one relationship between the ICC structure and the data lens generated from the Semantic Model. Since a product hierarchy ICC structure ensures that any given item will have only one Semantic Model, the process of standardizing data is automated, accurate, and reproducible. If a PIM system were to contain more than one ICC for a given category, then multiple Semantic Models and possibly multiple and conflicting standardization rules could exist for a given item. This can be successfully avoided by upholding the one-to-one relationship between the ICC structure and the Semantic Models, a natural result of using a product hierarchy, as previously described.
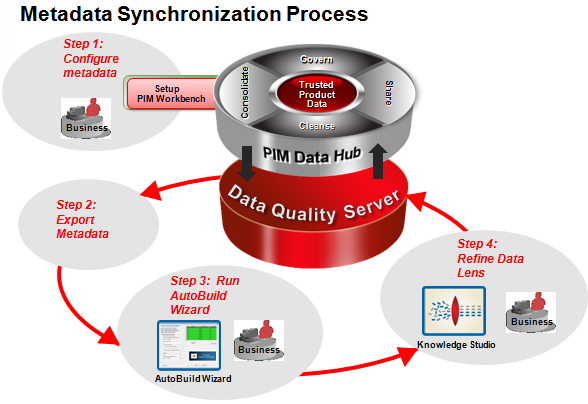
The integration of the EDQP solution with the Fusion PIMDH system adds an important set of data quality capabilities every time product data is imported using the Import Workbench into PIM. The set of pre-built integration processes allow for various automated data quality checks and operations such as:
Automated Categorization of data into the correct ICC.
Automated assignments to alternate catalogs categories thru ICC and attribute mappings.
Automated extraction, validation and standardization of category specific attributes.
Automated multiple description generation and standardization from category specific attributes.
Duplicate identification of incoming data.
Duplicate prevention and cross-reference of new items to existing items in the production tables.
Exception identification and routing.
Real time and batch data quality checks from the Fusion PIMDH system and processes.
|
Copyright © 2012, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|