リリース11g (11.1.1)
部品番号 B63038-01
目次
前
次
| Oracle Fusion Middleware Oracle Business Intelligence Publisherレポート・デザイナーズ・ガイド リリース11g (11.1.1) 部品番号 B63038-01 | 目次 | 前 | 次 |
この章では、次のトピックについて説明します。
eTextテンプレートは、EFT(Electronic Funds Transfer)やEDI(Electronic Data Interchange)用のテキスト出力の生成に使用する、RTFベースのテンプレートです。BI Publisherでは、実行時にこのテンプレートを入力XMLデータ・ファイルに適用し、銀行や他の顧客に転送可能な出力テキスト・ファイルを作成します。この出力は電子通信用であるため、eTextテンプレートにデータを配置する際は、書式に関する具体的な指示に忠実に従う必要があります。
注意: EFTとは、特定の定位置形式のフラット・ファイル(テキスト)を使用した、銀行への財務データや支払いの電子伝送のことです。
EDIはEFTと似ていますが、銀行への支払い情報の伝送だけでなく、発注書や請求書などのビジネス文書を企業間で交換するための手段としてもよく利用されます。EDIデータはデリミタベースで、これもまたフラット・ファイル(テキスト)として伝送されます。
これらの形式のファイルは、用紙に印刷するかわりに、フラット・ファイルとして伝送されます。レコード長は、数百文字にわたることがあるため、標準サイズの用紙でレイアウトを設定することは困難です。
このようなレコード長に対応するため、EFTおよびEDIテンプレートの設計には表が使用されています。各レコードは、表形式で表されます。表の各行は、レコード内の1つのフィールドに対応しています。表の列は、フィールドの位置、長さおよび値を指定します。
これらの形式では、入力XMLファイルのデータに対する特別な処理が必要な場合もあります。この特別な処理は、グローバル・レベル(文字の置換や順序付けなど)またはレコード・レベル(ソートなど)で実行されます。これらの機能の実行コマンドは、コマンド行で宣言します。グローバル・レベルのコマンドは、設定表で宣言します。
BI Publisherでは、実行時に表内の設定コマンドおよびレイアウト指定に従って、出力ファイルが生成されます。
この項は、EDIおよびEFTトランザクションの知識があるユーザーを対象としています。eTextテンプレートを用意するには、機能的知識と技術的知識の両方が必要です。つまり、銀行および国固有の支払い書式要件について理解するための機能的知識と、XMLデータ構造およびeText固有のコーディング構文コマンド、関数、操作について理解するための技術的知識が必要です。
eTextテンプレートには、定位置ベース(EFTテンプレート)とデリミタベース(EDIテンプレート)の2種類があります。テンプレートは一連の表で構成されています。これらの表では、レイアウト、設定コマンドおよびデータ・フィールド定義が定義されます。2種類のテンプレートに必要とされるデータの説明列は異なりますが、使用可能なコマンドと関数は同じです。表には、コマンドのみを含めることも、コマンドとデータ・フィールドを含めることもできます。
次の図に、コマンドおよびデータ行の一般的な構造を表示する、EFTテンプレートのサンプルを示します。
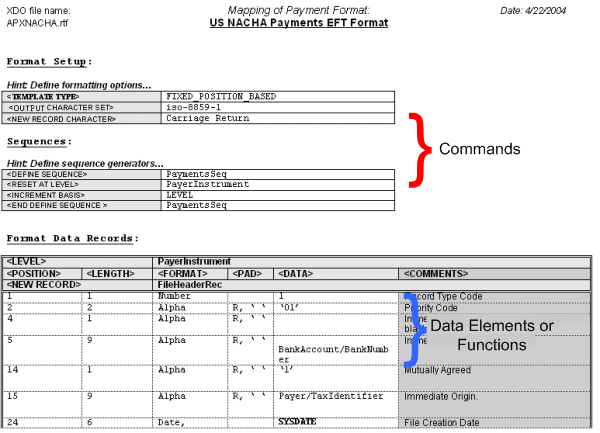
グローバルに適用されるコマンド、またはテンプレートのプログラム要素を定義するコマンドは、設定コマンドと呼ばれます。これらのコマンドは、テンプレートの始めの表で指定する必要があります。設定コマンドの例には、テンプレート・タイプやキャラクタ・セットがあります。
データ表では、ソースXMLのデータ要素名、および受信側の銀行またはエンティティが必要とする特定の配置および書式設定定義を指定します。データおよび条件付き文に対して実行する関数を定義することもできます。
データ表は必ず、レベルを定義するコマンド行で始める必要があります。レベルは、表をXMLデータ・ファイルの要素に関連付けて、階層を確立します。レベルの表で次に定義するデータ・フィールドは、XML要素の子要素に対応します。
次の図に、XMLデータ階層とテンプレート・レベル間の関連を示します。XML要素RequestHeaderは、レベルとして定義されています。表に定義されているデータ要素(FileIDおよびEncryption)は、RequestHeader要素の子です。
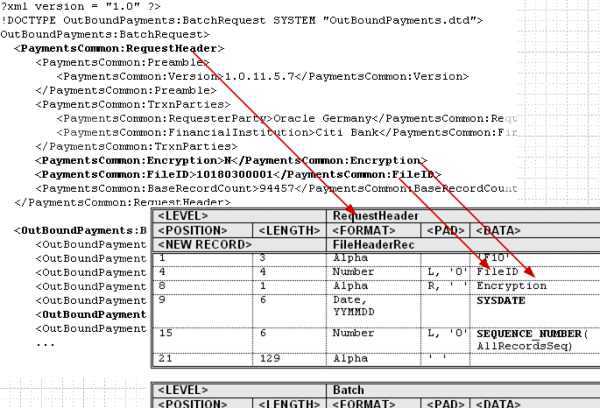
テンプレート内の表の順序は、レコードの印刷順序を決定します。実行時に、システムは表(レベル)に対応するXML要素のすべてのインスタンスをループし、その表に属するレコードを印刷します。その後、テンプレート内の次の表を処理します。表がネストされている場合は、次の親インスタンスに移動する前に、子表のネストされているレコードを生成します。
次の表に、コマンド行、データ行およびデータ列ヘッダー行の配置を示します。

コマンド行は、テンプレート内のコマンドの指定に使用します。コマンド行には、コマンド名とコマンド・パラメータの2つの列が常に存在します。コマンド行には列ヘッダーはありません。コマンドは、テンプレートの全体的な設定とレコード構造を制御します。
表は、任意の位置に空白行を挿入することによって、見やすくすることができます。空白行は、設定表のコマンド間で最も頻繁に使用されています。BI Publisherでは、テンプレートの解析時にこの空白行が無視されます。
データ列ヘッダーは、データ・フィールドの列ヘッダーを指定します(位置、長さ、書式、埋込み、コメントなど)。列ヘッダー行は、通常は表のレベル・コマンド(ソート・コマンドの使用時にはソート・コマンド)の後に続きます。データ列ヘッダー行は、表のデータ行よりも前に配置する必要があります。また、表の任意の位置に空の列ヘッダー行を挿入すると、表を見やすくすることができます。空の行は、実行時には無視されます。
必要なデータ列ヘッダー行は、テンプレート・タイプに応じて異なります。「データ行の構造」を参照してください。
データ行は、各データ・フィールドのデータ列ヘッダーの値を提供します。
データ行の内容は、テンプレート・タイプに応じて異なります。「データ行の構造」を参照してください。
データ表には、コマンド行とデータ・フィールド行の組合せが含まれます。各データ表は、そのXML要素を指定するレベル・コマンド行で始まる必要があります。各レコードは、新しいレコードの始めと前のレコード(存在する場合)の終わりを指定する新規レコード・コマンドで始まる必要があります。
データ・フィールドに必要な列は、テンプレート・タイプに応じて異なります。
コマンド行には、コマンド名とコマンド・パラメータの2つの列が常に存在します。サポートされているコマンドは次のとおりです。
レベル
新規レコード
昇順ソート
降順ソート
表示条件
これらの各コマンドの使用方法は、次の各項で説明します。
レベル・コマンドは、表をXML要素に関連付けます。レベル・コマンドのパラメータは、XML要素です。レベルは、データ入力ファイル内でXML要素のインスタンスが出現するたびに1度印刷されます。
レベル・コマンドは、テンプレートの階層を定義します。たとえば、支払いXMLのデータ抽出は階層的になります。バッチには複数の子支払いを、また支払いには複数の子請求書を含めることができます。この階層は、親要素内にネストされている子要素としてXMLで表されます。レベル・コマンドを使用して表をXML要素に関連付けることで、その表も同じ階層構造を持つことになります。
XML要素の終了タグと同様、レベル・コマンドには対となるレベル終了コマンドがあります。子表は、親要素に対して定義されたレベル・コマンドとレベル終了コマンドの間に定義する必要があります。
XML要素は、1つのレベルのみと関連付けることができます。レベルに属するすべてのレコードは、そのレベルの表内か、そのレベルに属するネストされた表内に存在する必要があります。レベル終了コマンドは、最後の表の終わりに指定されます。
次に、EFTファイル・レコード・レイアウトのサンプル構造を示します。
FileHeaderRecordA
BatchHeaderRecordA
BatchHeaderRecordB
PaymentRecordA
PaymentRecordB
InvoiceRecordA
BatchFooterRecordC
BatchFooterRecordD
FileFooterRecordB
この表のレイアウトは次のとおりです。
| <LEVEL> | RequestHeader |
| <NEW RECORD> | FileHeaderRecordA |
| FileHeaderRecordAのデータ行 |
| <LEVEL> | Batch |
| <NEW RECORD> | BatchHeaderRecordA |
| BatchHeaderRecordAのデータ行 | |
| <NEW RECORD> | BatchHeaderRecordB |
| BatchHeaderRecordBのデータ行 |
| <LEVEL> | Payment |
| <NEW RECORD> | PaymentRecordA |
| PaymentRecordAのデータ行 | |
| <NEW RECORD> | PaymentRecordB |
| PaymentRecordBのデータ行 |
| <LEVEL> | Invoice |
| <NEW RECORD> | InvoiceRecordA |
| InvoiceRecordAのデータ行 | |
| <END LEVEL> | Invoice |
| <END LEVEL> | Payment |
| <LEVEL> | Batch |
| <NEW RECORD> | BatchFooterRecordC |
| BatchFooterRecordCのデータ行 | |
| <NEW RECORD> | BatchFooterRecordD |
| BatchFooterRecordDのデータ行 | |
| <END LEVEL> | Batch |
| <LEVEL> | RequestHeader |
| <NEW RECORD> | FileFooterRecordB |
| FileFooterRecordBのデータ行 | |
| <END LEVEL> | RequestHeader |
同じレベルの複数のレコードは、同じ表に入れることができますが、各表に定義できるレベルは1つのみです。前述の例では、BatchHeaderRecordAとBatchHeaderRecordBはどちらも同じ表で定義されていますが、PaymentのEND LEVELは、子要素Invoiceの後の独自の表で定義する必要があります。PaymentのEND LEVELとInvoiceレベルは、同じ表には存在できません。
テンプレートでは、データ抽出の全レベルを使用する必要はありません。たとえば、ある抽出にRequestHeader > Batch > Payment > Invoiceというレベルが含まれる場合は、バッチと請求書のレベルのみを使用できます。ただし、レベルの階層は保持する必要があります。
表の階層は、レコードが印刷される順序を決定します。親XML要素では、それぞれ対応する親表のレコードが、表に出現する順序で印刷されます。システムは子表に対応する子XML要素のインスタンスをループし、指定された順序で子レコードを印刷します。その後、子を囲んでいる(レベル終了の)親表が存在する場合は、そのレコードを印刷します。
たとえば、前述のEFTテンプレート構造において、入力データ・ファイルに次のデータが含まれているとします。
Batch1
Payment1
Invoice1
Invoice2
Payment2
Invoice1
Batch2
Payment1
Invoice1
Invoice2
Invoice3
これによって、次の印刷済レコードが生成されます。
| レコードの順序 | レコード・タイプ | 説明 |
|---|---|---|
| 1 | FileHeaderRecordA | EFTファイルの1つのヘッダー・レコード |
| 2 | BatchHeaderRecordA | Batch1用 |
| 3 | BatchHeaderRecordB | Batch1用 |
| 4 | PaymentRecordA | Batch1、Payment1用 |
| 5 | PaymentRecordB | Batch1、Payment1用 |
| 6 | InvoiceRecordA | Batch1、Payment1、Invoice1用 |
| 7 | InvoiceRecordA | Batch1、Payment1、Invoice2用 |
| 8 | PaymentRecordA | Batch1、Payment2用 |
| 9 | PaymentrecordB | Batch1、Payment2用 |
| 10 | InvoiceRecordA | Batch1、Payment2、Invoice1用 |
| 11 | BatchFooterRecordC | Batch1用 |
| 12 | BatchFooterRecordD | Batch1用 |
| 13 | BatchHeaderRecordA | Batch2用 |
| 14 | BatchHeaderRecordB | Batch2用 |
| 15 | PaymentRecordA | Batch2、Payment1用 |
| 16 | PaymentRecordB | Batch2、Payment1用 |
| 17 | InvoiceRecordA | Batch2、Payment1、Invoice1用 |
| 18 | InvoiceRecordA | Batch2、Payment1、Invoice2用 |
| 19 | InvoiceRecordA | Batch2、Payment1、Invoice3用 |
| 20 | BatchFooterRecordC | Batch2用 |
| 21 | BatchFooterRecordD | Batch2用 |
| 22 | FileFooterRecordB | EFTファイルの1つのフッター・レコード |
新規レコード・コマンドは、レコードの始めと前のレコード(存在する場合)の終わりを表します。テンプレートの各レコードは、新規レコード・コマンドで始まる必要があります。レコードは、次の新規レコード・コマンドや表の終わりまで、またはレベル終了コマンドまで続きます。
レコードは、レベルに属している要素の集まりを表すコンストラクトです。レコード名は、XML入力ファイルに関連付けられていません。
表には、複数のレコードを含めることができるため、複数の新規レコード・コマンドが存在します。表のレコードは、すべて同じ階層レベルにあります。これらは、表に指定されている順序で印刷されます。
新規レコード・コマンドは、名前をパラメータとして使用できます。この名前はレコードの名前になります。レコード名はレコード・タイプとも呼ばれており、レコードの生成済インスタンスを数えるCOUNT関数で使用できます。詳細は、COUNT関数を参照してください。
連続した新規レコード・コマンド(つまり空のレコード)は使用できません。
レベルのインスタンスをソートするには、昇順ソートおよび降順ソート・コマンドを使用します。ソートする要素は、カンマ区切りリストで入力します。これはオプションのコマンドです。このコマンドを使用する際には、(最初の)レベル・コマンドの直後に指定する必要がありますが、この場合、レコードが複数の表で指定されていても、そのレベルのすべてのレコードに適用されます。
表示条件コマンドは、囲まれているレコードやデータ・フィールド・グループをいつ表示するかを指定します。このコマンドのパラメータはブール式です。この式がTrueと評価された場合、レコードまたはデータ・フィールド・グループが表示されます。それ以外の場合は、それらのレコードまたはデータ・フィールド・グループがスキップされます。
表示条件コマンドは、レコードまたはデータ・フィールド・グループのいずれかで使用できます。レコードで使用する場合、表示条件コマンドは新規レコード・コマンドの後に指定する必要があります。データ・フィールド・グループで使用する場合、表示条件コマンドはデータ・フィールド行の後に指定する必要があります。この場合、表示条件はレコードの終わりまで、残りのすべてのフィールドに適用されます。
連続した表示条件コマンドは、AND条件としてマージされます。マージされた表示条件は、囲まれている同じレコードやデータ・フィールド・グループに適用されます。
出力レコードのデータ・フィールドは、テンプレート内では表の行によって表されます。FIXED_POSITION_BASEDテンプレートの各行には、次の属性(または列)があります。
位置
長さ
書式
埋込み
データ
コメント
最初の5つの列は必須で、ここに示されている順序で表示する必要があります。
DELIMITER_BASEDテンプレートの各データ行には、次の属性(列)があります。
最大長
書式
データ
タグ
コメント
最初の3つの列は必須で、ここに示されている順序で宣言する必要があります。
どちらのテンプレート・タイプでも、コメント列はオプションになり、システムで無視されます。必須列の後にある列はすべて無視されるため、必要に応じて追加の情報列を挿入できます。
各列の使用ルールは次のとおりです。
レコード内のフィールドの開始位置を指定します。単位は文字数です。この列は、FIXED_POSITION_BASEDテンプレートでのみ使用されます。
フィールドの長さを指定します。単位は文字数です。FIXED_POSITION_BASEDテンプレートでは、すべてのフィールドが固定長になります。データが指定された長さよりも短い場合は埋込みが行われ、データが長い場合は切り捨てられます。切捨ては、常に右端で行われます。
DELIMITER_BASEDテンプレートでは、この値はフィールドの最大長を指定します。データが最大長を超える場合は切り捨てられます。データが最大長より短くても、埋込みは行われません。
データ型と書式設定を指定します。許容されているデータ型は次の3つです。
Alpha
数値
Date
これらの使用方法については、「フィールドレベル・キーワード」を参照してください。
数値データには、Integer、Decimal、書式マスク定義、という3つのオプションの書式設定があります。Numberデータ型のこれらのオプション設定は、次のように指定します。
Number, Integer
Number, Decimal
Number, <書式マスク>
例:
Number, ###,###.00
Integer書式では、数値の整数部分のみを使用し、小数を破棄します。Decimal書式では、数値の小数部分のみを使用し、整数部分を破棄します。
次の表に、書式マスクの設定方法の例を示します。マスクを指定するとき、#はデータに存在する桁を表示することを表し、0は、データが存在するかどうかに関係なく、桁のプレースホルダを表示することを表します。
書式マスクを指定するときは、グループ・セパレータに","を、小数のセパレータには"."を必ず使用する必要があります。これらを実際の出力で変更するには、NUMBER THOUSANDS SEPARATORおよびNUMBER DECIMAL SEPARATORの設定コマンドを使用する必要があります。これらのコマンドの詳細は、「設定コマンド表」を参照してください。
次の表に、サンプルのデータ、書式指定子および出力を示します。出力では、デフォルトのグループ・セパレータと小数セパレータが使用されています。
| データ | 書式指定子 | 出力 |
|---|---|---|
| 123456789 | ###,###.00 | 123,456,789.00 |
| 123456789.2 | ###.00 | 123456789.20 |
| 1234.56789 | ###.000 | 1234.568 |
| 123456789.2 | # | 123456789 |
| 123456789.2 | #.## | 123456789.2 |
| 123456789 | #.## | 123456789 |
Dateデータ型の書式設定は、常に明示的に指定する必要があります。この書式設定は、MMDDYYなどのSQL日付スタイルに従います。
一部のEDI(DELIMITER_BASED)書式では、より説明的なデータ型を使用します。これらは次の表に示す3種類のテンプレート・データ型にマッピングされます。
| ASC X12データ型 | フォーマット・テンプレートのデータ型 |
|---|---|
| A - 英字 | Alpha |
| AN - 英数字 | Alpha |
| B - バイナリ | 数値 |
| CD - コンポジット・データ要素 | 該当なし |
| CH - 文字 | Alpha |
| DT - 日付 | Date |
| FS - 固定長文字列 | Alpha |
| ID - 識別子 | Alpha |
| IV - 増分値 | 数値 |
| Nn - 数値 | 数値 |
| PW - パスワード | Alpha |
| R - 小数 | Number |
| TM - 時間 | Date |
次の設定コマンドを指定したとします。
| NUMBER THOUSANDS SEPARATOR | . |
| NUMBER DECIMAL SEPARATOR | , |
次の表に、この場合のデータ、書式指定子および出力を示します。書式指定子には、設定コマンドのエントリに関係なく、デフォルトのセパレータを使用する必要があることに注意してください。
| データ | 書式指定子 | 出力 |
|---|---|---|
| 123456789 | ###,###.00 | 123.456.789,00 |
| 123456789.2 | ###.00 | 123456789,20 |
| 1234.56789 | ###.000 | 1234,568 |
| 123456789.2 | # | 123456789 |
| 123456789.2 | #.## | 123456789,2 |
| 123456789 | #.## | 123456789 |
これは、FIXED_POSITION_BASEDテンプレートにのみ適用されます。埋込み側(L = 左またはR = 右)および文字を指定します。埋込みは、数値および英数字の両方のフィールドで可能です。このフィールドを指定しない場合、数値フィールドでは左側に"0"が埋め込まれ、Alphaフィールドでは右側に空白が埋め込まれます。
使用例:
フィールドの左側に"0"を埋め込むには、Pad列フィールドに次のように入力します。
L, '0'
フィールドの右側に空白を埋め込むには、Pad列フィールドに次のように入力します。
R, ' '
フィールドに移入する、データ抽出からのXML要素を指定します。データ列には、単にXMLタグ名を含めることも、式と関数を含めることもできます。詳細は、「式、制御構造および関数」を参照してください。
DELIMITER_BASEDテンプレートのコメント列として機能します。EDIFACT書式で参照タグを指定し、ASC X12で参照IDを指定します。
この列を使用して、自由書式コメントをテンプレートに追加します。通常、この列は、ビジネス要件やデータ・フィールドの使用方法の記述に使用します。
テンプレートは必ず、設定コマンドを指定する表で始まります。設定コマンドは、テンプレート・タイプや出力キャラクタ・セットなどのグローバル属性、および順序付けや連結などのプログラム要素を定義します。
設定コマンドは次のとおりです。
TEMPLATE TYPE
OUTPUT CHARACTER SET
OUTPUT LENGTH MODE
NEW RECORD CHARACTER
INVALID CHARACTERS
REPLACE CHARACTERS
NUMBER THOUSANDS SEPARATOR
NUMBER DECIMAL SEPARATOR
DEFINE LEVEL
DEFINE SEQUENCE
DEFINE CONCATENATION
CASE CONVERSION
次の図に、設定表の例を示します。


このコマンドは、テンプレートのタイプを指定します。FIXED_POSITION_BASEDとDELIMITER_BASEDの2種類のタイプがあります。
FIXED_POSITION_BASEDテンプレートは、EFTなどの固定長レコード形式に使用します。この形式では、レコード内のすべてのフィールドが固定長になります。指定した長さよりもデータが短い場合は、埋込みが行われ、長い場合には、切り捨てられます。システムには、データの埋込みと切捨てのデフォルトの動作が指定されています。定位置ベースの形式の例には、欧州で使用されているEFTや、米国で使用されているNACHA ACHファイルがあります。
DELIMITER_BASEDテンプレートでは、データの埋込みは行われず、最大フィールド長に達したときにのみ切り捨てられます。空のフィールドは許可されます(データがnullの場合)。データ・フィールドを区切るには、指定されているデリミタが使用されます。フィールドが空の場合は、2つのデリミタが並んで表示されます。デリミタベース・テンプレートの例には、ASC X12 820などのEDI形式、およびPAYMUL、DIRDEB、CREMULなどのUN EDIFACT形式があります。
EDI形式では、レコードはセグメントと呼ばれることがあります。EDIセグメントはレコードと同様に処理されます。各セグメントは新規レコード・コマンドで始め、レコード名を指定します。新規レコード・コマンドの直後には、出力データの一部としてセグメント名を指定するデータ・フィールドを用意する必要があります。
DELIMITER_BASEDテンプレートでは、データ・フィールド間の個別の行に適切なデータ・フィールド・デリミタを挿入します。デリミタ行は、各データ・フィールド行の後に挿入します。空のフィールドにプレースホルダを挿入するには、2つの連続したデリミタ行を定義します。
空のフィールドは多くの場合、構文上の理由で使用されます。つまり、空のフィールドにプレースホルダを挿入し、その後に続くフィールドが適切に識別されるようにします。
データ・フィールド、コンポジット・データ・フィールドおよびレコードの終わりを示すために、それぞれ異なるデリミタが用意されています。一部の書式では、デリミタ文字を選択できる場合もあります。いずれの場合も、同じ用途には同じデリミタを一貫して使用して、構文エラーを避けるようにしてください。
DELIMITER_BASEDテンプレートでは、<POSITION>および<PAD>列は適用されません。これらはデータ表から省略されます。
DELIMITER_BASEDテンプレートの一部では、最大長と最小長を指定できます。このような場合は、Oracle Paymentsによって長さが検証されます。
一部の書式では、データ抽出にはない追加の特定データ・レベルが必要な場合があります。たとえば、ある書式では、支払いを支払い日ごとにまとめる必要があります。レベル定義コマンドを使用すると、支払い日のグループが入力抽出ファイルにない場合でも、このグループを定義して、テンプレート内のレベルとして参照できるようになります。
レベル定義コマンドを使用するときは、抽出内に存在するベース・レベルを宣言します。レベル定義コマンドにより、抽出のベース・レベルよりも1レベル高位にある新しいレベルが挿入されます。新しいレベルは、ベース・レベルのインスタンスのグルーピングとして機能します。
レベル定義コマンドは設定コマンドであるため、設定表で定義する必要があります。このコマンドには、次の3つのサブコマンドがあります。
ベース・レベル・コマンド: 新しいレベルのベースになっている抽出レベル(XML要素)を定義します。レベル定義コマンドには、常に1つのベース・レベル・サブコマンドのみを含める必要があります。
グルーピング基準: ベース・レベルのインスタンスをグループ化し、新しいレベルのインスタンスを形成するために使用するXML抽出要素を定義します。グルーピング基準コマンドのパラメータは、カンマで区切られた要素のリストで、これらの要素はグルーピング条件を指定します。
グルーピングの階層は、要素の順序で決定されます。ベース・レベルのインスタンスは最初の基準値に従ってグループ分けされ、これらの各グループが2番目の基準に従ってさらにグループ分けされます。この処理が基準値の数だけ繰り返されます。最後のサブグループはそれぞれ、新しいレベルのインスタンスとみなされます。
昇順グループ・ソートまたは降順グループ・ソート: グループのソートを定義します。<GROUP SORT ASCENDING>または<GROUP SORT DESCENDING>コマンド行を、<DEFINE LEVEL>と<END DEFINE LEVEL>コマンドの間の任意の場所に挿入します。ソート・コマンドのパラメータは、カンマで区切られた要素のリストで、これらの要素によってグループがソートされます。
たとえば、次の表は、1つのバッチ内の5つの支払いを示しています。
| 支払いインスタンス | PaymentDate(グルーピング基準1) | PayeeName(グルーピング基準2) |
|---|---|---|
| Payment1 | PaymentDate1 | PayeeName1 |
| Payment2 | PaymentDate2 | PayeeName1 |
| Payment3 | PaymentDate1 | PayeeName2 |
| Payment4 | PaymentDate1 | PayeeName1 |
| Payment5 | PaymentDate1 | PayeeName3 |
テンプレートで次のような設定表を作成し、Payment DateとPayee Nameに従ってグループ化されたベース・レベルPaymentから、PaymentsByPayDatePayeeというレベルを作成します。PaymentDateとPayeeNameで各グループをソートするために、昇順グループ・ソート・コマンドを追加します。
| <DEFINE LEVEL> | PaymentsByPayDatePayee |
| <BASE LEVEL> | Payment |
| <GROUPING CRITERIA> | PaymentDate, PayeeName |
| <GROUP SORT ASCENDING> | PaymentDate, PayeeName |
| <END DEFINE LEVEL> | PaymentsByPayDatePayee |
5つの支払いでは、新しいレベル用の次の4つのグループ(インスタンス)が生成されます。
| 支払いグループ・インスタンス | グループ基準 | グループ内の支払い |
|---|---|---|
| Group1 | PaymentDate1、PayeeName1 | Payment1、Payment4 |
| Group2 | PaymentDate1、PayeeName2 | Payment3 |
| Group3 | PaymentDate1、PayeeName3 | Payment5 |
| Group4 | PaymentDate2、PayeeName1 | Payment2 |
新しいインスタンスの順序は、レコードが印刷される順序になります。複数のグルーピング基準を評価して新しいレベルのインスタンスを形成する場合、基準は階層を形成させるものと考えることができます。最初の基準は階層の最上位に、最後の基準は階層の最下位に位置付けられます。
一般的に、EFT形式には2種類の固有のデータ・グルーピング・シナリオがあります。1つの形式ではグループ・レコードのみが印刷され、もう1つの形式ではグループ内にネストされている個別の要素レコードを持つグループが印刷されます。次に、前述の5つの支払いとグルーピング条件に基づいたこれらのシナリオの例を2つ示します。
最初のシナリオ: グループ・レコードのみ
EFTファイル構造:
BatchRec
PaymentGroupHeaderRec
PaymentGroupFooterRec
| レコード順序 | レコード・タイプ | 説明 |
|---|---|---|
| 1 | BatchRec | |
| 2 | PaymentGroupHeaderRec | Group1(PaymentDate1、PayeeName1)用 |
| 3 | PaymentGroupFooterRec | Group1(PaymentDate1、PayeeName1)用 |
| 4 | PaymentGroupHeaderRec | Group2(PaymentDate1、PayeeName2)用 |
| 5 | PaymentGroupFooterRec | Group2(PaymentDate1、PayeeName2)用 |
| 6 | PaymentGroupHeaderRec | Group3(PaymentDate1、PayeeName3)用 |
| 7 | PaymentGroupFooterRec | Group3(PaymentDate1、PayeeName3)用 |
| 8 | PaymentGroupHeaderRec | Group4(PaymentDate2、PayeeName1)用 |
| 9 | PaymentGroupFooterRec | Group4(PaymentDate2、PayeeName1)用 |
シナリオ2: グループ・レコードと個別レコード
EFTファイル構造:
BatchRec
PaymentGroupHeaderRec
PaymentRec
PaymentGroupFooterRec
次の出力が生成されます。
| レコード順序 | レコード・タイプ | 説明 |
|---|---|---|
| 1 | BatchRec | |
| 2 | PaymentGroupHeaderRec | Group1(PaymentDate1、PayeeName1)用 |
| 3 | PaymentRec | Payment1用 |
| 4 | PaymentRec | Payment4用 |
| 5 | PaymentGroupFooterRec | Group1(PaymentDate1、PayeeName1)用 |
| 6 | PaymentGroupHeaderRec | Group2(PaymentDate1、PayeeName2)用 |
| 7 | PaymentRec | Payment3用 |
| 8 | PaymentGroupFooterRec | Group2(PaymentDate1、PayeeName2)用 |
| 9 | PaymentGroupHeaderRec | Group3(PaymentDate1、PayeeName3)用 |
| 10 | PaymentRec | Payment5用 |
| 11 | PaymentGroupFooterRec | Group3(PaymentDate1、PayeeName3)用 |
| 12 | PaymentGroupHeaderRec | Group4(PaymentDate2、PayeeName1)用 |
| 13 | PaymentRec | Payment2用 |
| 14 | PaymentGroupFooterRec | Group4(PaymentDate2、PayeeName1)用 |
レベル定義コマンドを使用して定義した新しいレベルは、抽出内のレベルと同じ方法で、テンプレートで使用できます。ただし、新しいレベルのレコードは、そのグルーピング基準に定義されているベース・レベル・フィールドのみを参照できます。集計関数以外から他のベース・レベル・フィールドを参照することはできません。
たとえば、PaymentGroupHeaderRecでは、そのフィールド内でPaymentDateとPayeeNameを参照できます。また、SUM関数でPaymentAmount(支払いレベル・フィールド)も参照できます。ただし、PaymentDocNameやPaymentDocNumなどの他の支払いレベル・フィールドは参照できません。
DEFINE LEVELコマンドには、常に1つのグルーピング基準サブコマンドのみを含める必要があります。DEFINE LEVELコマンドには、対となるEND DEFINE LEVELコマンドがあります。サブコマンドは、このDEFINE LEVELコマンドとEND DEFINE LEVELコマンドの間に指定する必要があります。これらのサブコマンドは、任意の順序で宣言できます。
DEFINE SEQUENCEコマンドは、SEQUENCE_NUMBER関数とともに使用できる順序を定義して、生成済EFTレコードまたは抽出インスタンス(データベース・レコード)のいずれかの索引を作成します。EFTレコードは、テンプレート内で定義される物理レコードで、データベース・レコードは、抽出されたレコードです。混乱を避けるために、レコードという用語は常にEFTレコードを指すために使用します。データベース・レコードは、抽出要素のインスタンスまたはレベルと呼びます。
DEFINE SEQUENCEコマンドには、RESET AT LEVEL、INCREMENT BASIS、START ATおよびMAXIMUMという4つのサブコマンドがあります。
RESET AT LEVELサブコマンドは、順序の開始番号をリセットする位置を定義します。これは必須のサブコマンドです。たとえば、支払いをバッチ別に番号付けするには、RESET AT LEVELをBatchとして定義します。バッチ間にまたがって番号付けするには、RESET AT LEVELをRequestHeaderとして定義します。
順序がテンプレートの外部でリセットされる場合もあります。たとえば、周期的順序では、日付によるリセットが定義される場合があります。この場合は、RESET AT LEVELにPERIODIC_SEQUENCEキーワードを使用します。システムでは、支払いファイルで使用された最後の順序番号をデータベースに保存します。データベース内の順序のリセットは、外部イベントによって制御されます。次の支払いファイルの実行時には、この順序番号がデータベースから抽出され、開始番号として使用されます(「開始位置サブコマンド」を参照)。
INCREMENT BASISサブコマンドは、レコードまたは抽出インスタンスに基づいて順序を増分させる必要があるかどうかを指定します。このサブコマンドで使用可能なパラメータはRECORDとLEVELです。
RECORDを入力すると、レコードごとに順序が増分します。
LEVELを入力すると、レベルの新しいインスタンスごとに順序が増分します。
複数のレコードを持つレベルでは、レベルベースの増分を使用した場合、レベル内のレコードすべてに同じ順序番号が付けられます。レコードベースの増分では、レベル内の各レコードに新しい順序番号が割り当てられます。
レベルベースの増分では、順序番号は1つのレベルのフィールドでのみ使用できます。たとえば、抽出にバッチ>支払い>請求書の階層がある場合に、バッチ・レベルでリセットされるレベル順序によるRESET AT LEVELを定義したとします。この場合、順序は支払いまたは請求書レベル・フィールドのいずれかで使用できますが、その両方で使用することはできません。つまり、階層レベル間をまたがった順序番号を使用することはできません。
しかし、このルールはレコード順序による増分基準には適用されません。この場合、レコードにレベル間をまたがった順序番号を付けることができます。
増分基準がレベル順序およびレコード順序のどちらの場合でも、順序のレベルは、順序が定義されている場所に基づいて暗黙的に定義されます。
連結定義コマンドを使用すると、親レベル・フィールドで使用する子レベル抽出要素を連結できます。たとえば、このコマンドを使用して、1つの支払いに属しているすべての請求書の請求書番号と期日を連結し、支払いレベル・フィールドで使用できます。
連結定義コマンドには、ベース・レベル、要素、デリミタの3つのサブコマンドがあります。
ベース・レベル・サブコマンドは、操作の子レベルを指定します。各親レベル・インスタンスに対し、連結操作では子レベルのインスタンスをループして、連結文字列を生成します。
要素サブコマンドは、各要素の生成に使用する操作を指定します。要素とは、連結文字列を生成するために連結される子レベルの式です。
デリミタ・サブコマンドは、文字列内で連結されているアイテムを区切るデリミタを指定します。
SUBSTR関数を使用すると、連結された文字列をより小さな文字列に分割し、異なるフィールドに配置できます。たとえば、次の表は、1つの支払いに含まれている5つの請求書を示しています。
| Invoice | InvoiceNum |
|---|---|
| 1 | car_parts_inv0001 |
| 2 | car_parts_inv0002 |
| 3 | car_parts_inv0003 |
| 4 | car_parts_inv0004 |
| 5 | car_parts_inv0005 |
次の連結定義を使用します。
| <DEFINE CONCATENATION> | ConcatenatedInvoiceInfo |
| <BASE LEVEL> | Invoice |
| <ELEMENT> | InvoiceNum |
| <DELIMITER> | ',' |
| <END DEFINE CONCATENATION> | ConcatenatedInvoiceInfo |
支払いレベル・フィールドでは、ConcatenatedInvoiceInfoを参照できます。文字列は次のようになります。
car_parts_inv0001,car_parts_inv0002,car_parts_inv0003,car_parts_inv0004,car_parts_inv0005
連結された請求書情報の最初の40文字のみを使用する場合は、TRUNCATE関数またはSUBSTR関数を次のように使用します。
TRUNCATE(ConcatenatedInvoiceInfo, 40)
SUBSTR(ConctenatedInvoiceInfo, 1, 40)
これらの文はいずれも、次の結果になります。
car_parts_inv0001,car_parts_inv0002,car_
次の40文字を分離するには、SUBSTR関数を使用します。
SUBSTR(ConcatenatedInvoiceInfo, 41, 40)
その結果、次の文字列が得られます。
parts_inv0003,car_parts_inv0004,car_par
Oracle Applicationsでのデータ入力に使用されたものとは異なるキャラクタ・セットを必要とする書式もあります。たとえば、一部のドイツ語の書式ではASCIIの出力ファイルが必要ですが、データはドイツ語で入力されている場合があります。元のキャラクタ・セットとターゲットのキャラクタ・セットが一致しない場合は、ASCIIの対応文字を定義して元のキャラクタ・セットを置換できます。たとえば、ドイツ語のウムラウト記号付き"a"は、"ao"に置き換えます。
書式の中には、特定の文字を使用できないものもあります。既知の無効な文字が出力ファイルに転送されないようにするには、無効文字コマンドを使用して、特定の文字の出現をフラグ付けします。
置換文字コマンドを使用するには、左側の列にソース文字を指定し、右側の列に置換文字を指定します。ソース文字は元のキャラクタ・セットで入力する必要があります。これは、出力対象ではないキャラクタ・セットを書式テンプレートで使用する唯一のケースです。置換文字列は、必要な出力キャラクタ・セットで入力します。
DELIMITER_BASED書式では、データにデリミタが含まれている場合、エスケープ文字"?"を使用してその意味を保持できます。例:
First name?+Last nameは、Fist name+Last nameと同じです。
Which source??は、Which source?と同じです。
データ内でエスケープ文字を使用する場合には、そのエスケープ文字自体をエスケープする必要があることに注意してください。
置換文字コマンドは、エスケープ文字の要件のサポートに使用できます。デリミタをソースとして指定し、エスケープ文字にデリミタを加えたものをターゲットとして指定します。たとえば、前述の例のコマンド・エントリは次のようになります。
| <REPLACEMENT CHARACTERS> | |
| + | ?+ |
| ? | ?? |
| <END REPLACEMENT CHARACTERS> |
無効文字コマンドには、システム・エラーを発生させる無効な文字を含む文字列のパラメータが1つあります。
文字の置換プロセスは、キャラクタ・セットの変換前または変換中に実行されます。キャラクタ・セットの変換は書式設定前に、XML抽出に対して直接実行されます。キャラクタ・セットの変換後は、出力キャラクタ・セットにおいて無効な文字がチェックされます。無効な文字が見つからなかった場合は、書式設定が行われます。
新規レコード文字コマンドを使用すると、実行時に明示的および暗黙的なレコード・ブレイクを区切るための文字を指定できます。新規レコード・コマンドは、それぞれ明示的なレコード・ブレイクを表します。表の終わりは、それぞれ暗黙的なレコード・ブレイクを表します。パラメータは、カンマで区切られた定数文字名のリストです。
書式の中には、レコード・ブレイクが含まれていないものもあり、生成される出力は1行のデータになります。この場合、新規レコード文字コマンドのパラメータ・フィールドは空のままにします。
新規レコード文字フィールドをテンプレートで定義しなかった場合は、デフォルトの新規レコード文字として\nが設定されます。
Output Length Modeは、characterまたはbyteに設定できます。OUTPUT LENGTH MODEをcharacterに設定した場合、各フィールドの出力レコードの長さは文字の長さによって決まります。OUTPUT LENGTH MODEをbyteに設定した場合、各フィールドの出力レコードの長さはバイトの長さによって決まります。
OUTPUT LENGTH MODEの設定が指定されていない場合は、characterが使用されます。
デフォルトの3桁の(またはグループ)セパレータはカンマ(",")で、デフォルトの小数セパレータはピリオド(".")です。3桁のセパレータ・コマンドおよび小数セパレータ・コマンドを使用すると、デフォルト以外のセパレータを指定できます。たとえば、グループ・セパレータとして"."を定義し、小数セパレータとして","を定義するには、次のように入力します。
| <NUMBER THOUSANDS SEPARATOR> | . |
| <NUMBER DECIMAL SEPARATOR> | , |
NUMBER DECIMAL SEPARATORを設定する場合は、NUMBER THOUSANDS SEPARATORも設定する必要があることに注意してください。表示されるフィールドには適切な書式マスクを設定するようにします。数値の書式設定の詳細は、「書式列」を参照してください。
書式のタイプがALPHAであるフィールドで、文字列を小文字から大文字に変換するにはCASE CONVERSIONを使用します。このコマンドは、FIXED_POSITION_BASEDテンプレートで使用されます。
| <CASE CONVERSION> | UPPER |
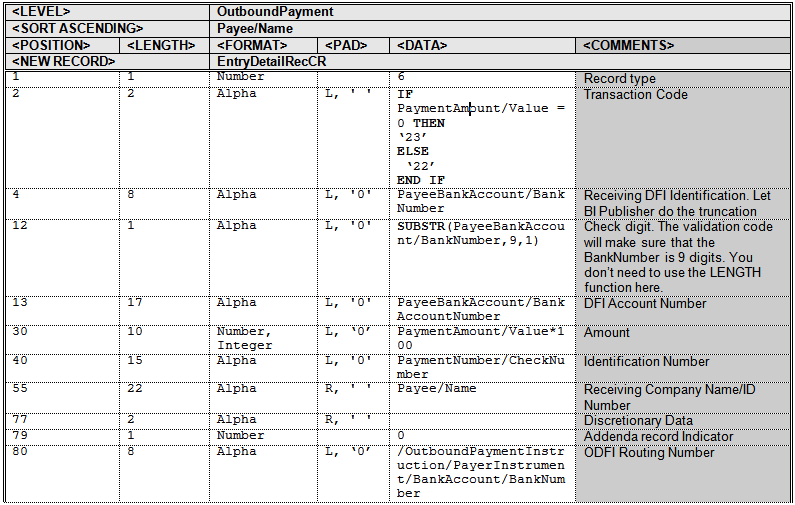
FIXED_POSITION_BASEDテンプレートでは、埋込みブロックを使用して、eText出力用に特定のブロック・サイズを定義できます。実際のデータが指定のブロック・サイズに満たない場合、ブロックの残りは指定の埋込み文字で満たされます。
たとえば、BLOCK SIZEを9で定義したとき、生成されたeText出力がテキスト3行だけの場合は、残りの6行が指定されたFILLER CHARACTERで満たされます。
コマンドの使用方法は次のとおりです。
<BEGIN FILLER BLOCK>: これはブロックの始まりを表します。このブロックの名前を入力します。
<FILLER CHARACTER>: データでブロックが満たされない場合に、ブロックの残りの部分を埋めるために使用する文字または文字列を入力します。
次に<FILLER CHARACTER>の入力例を示します。
ブロックを?で埋めるには、次のように入力します。
| <FILLER CHARACTER> | ? |
ブロックをabcで埋めるには、次のように入力します。
| <FILLER CHARACTER> | 'abc' |
ブロックを空のスペースで埋めるには、次のように入力します。
| <FILLER CHARACTER> |
<BLOCK SIZE>: テキストの行数単位でブロックのサイズを指定するために、整数を入力します。
これらのコマンドはテンプレートの定義を始める前に使用する必要があります。
ブロックの最後に次のコマンドを入力します。
<END FILLER BLOCK>: ブロックの終わりを示します。<BEGIN FILLER BLOCK>コマンドですでに指定済のこのブロックの名前を入力します。
FILLER BLOCKの使用例


FILLER BLOCKで生成された出力。
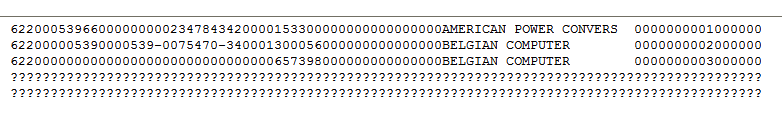
FILLER BLOCKを使用せずに生成された出力。

この項では、テンプレート内の式のルールと使用方法について説明します。また、サポートされている制御構造と関数についても説明します。
式は、データ・フィールドのデータ列と一部のコマンド・パラメータで使用できます。式は、XML抽出フィールド、リテラル、関数および演算子の集まりで、ネストが可能です。式には"IF"制御構造を含めることもできます。式が評価されると、常に結果が生成されます。この評価では、二次的作用が許可されません。式は評価結果に基づいて、次の3つのカテゴリに分類されます。
ブール式: trueまたはfalseのブール値を戻す式。この種の式は、"IF-THEN-ELSE"制御構造、および表示条件コマンドのパラメータでのみ使用できます。
数式: 数を戻す式。この種の式は、数値データ・フィールドで使用できます。数値パラメータを必要とする関数やコマンドで使用することもできます。
文字式: 英数字の文字列を戻す式。この種の式は、文字列データ・フィールド(Alpha書式タイプ)で使用できます。文字列パラメータを必要とする関数やコマンドで使用することもできます。
サポートされている唯一の制御構造は"IF-THEN-ELSE"で、これは式の中で使用可能です。構文は次のとおりです。
IF <boolean_expressionA> THEN
<numeric or character expression1>
[ELSIF <boolean_expressionB THEN
<numeric or character expression2>]
...
[ELSE
<numeric or character expression3]
END IF一般的に、制御構造は数字または英数字文字列に評価される必要があります。制御構造は、数式または文字式とみなされます。ELSIFとELSE句はオプションで、ELSIF句は必要な数だけ定義できます。制御構造はネストできます。
IF-THEN-ELSE制御構造では、IN条件がサポートされています。例:
IF PaymentAmount/Currency/Code IN ('USD', 'EUR', 'AON', 'AZM') THEN
PayeeAccount/FundsCaptureOrder/OrderAmount/Value * 100
ELSIF PaymentAmount/Currency/Code IN ('BHD', 'IQD', 'KWD') THEN
PayeeAccount/FundsCaptureOrder/OrderAmount/Value * 1000
ELSE
PayeeAccount/FundsCaptureOrder/OrderAmount/Value
END IF; 次に、サポートされている関数の一覧を示します。
SEQUENCE_NUMBER: レコード要素の索引。順序定義コマンドとともに使用されます。順序定義コマンドによって定義される順序を、1つのパラメータとして持ちます。実行時には、レコード内で参照されるたびに、その順序値が1つずつ増えます。
COUNT: 子レベルの抽出インスタンスまたは特定タイプの子レベル・レコードをカウントします。COUNT関数は、カウントするエンティティよりも上位のレベルで宣言します。この関数は、1つの引数を持ちます。引数がレベルの場合は、現在の(親)レベル・インスタンスに属している(子)レベルのインスタンスがすべてカウントされます。
たとえば、カウントするレベルがPaymentで、現在のレベルがBatchの場合、COUNTはバッチ内の支払いの合計数を戻します。しかし、現在のレベルがRequestHeaderの場合、COUNTは全バッチのファイル内に含まれている支払いの合計数を戻します。引数がレコード・タイプの場合は、現在のレベル・インスタンスに属している(子レベル)レコード・タイプの生成済レコードがすべてカウントされます。
INTEGER_PART、DECIMAL_PART: 数値の整数部分または小数部分を戻します。これは、ネストされている式とコマンド(表示条件およびグループ別)で使用されます。データ列の数値フィールドの最終的な書式には、整数書式または小数書式を使用します。
IS_NUMERIC: 引数が数値であるかどうかをチェックするブール・テスト。"IF"制御構造でのみ使用されます。
TRUNCATE: 最初の引数の文字列を2番目の引数の長さに切り捨てます。最初の引数が、2番目の引数で指定されている長さよりも短い場合は、最初の引数がそのまま戻されます。これは、SQL substr()機能の使いやすいサブセット・バージョンです。
SUM: XML抽出フィールドの引数の子インスタンスをすべて合計します。フィールドは数値である必要があります。合計するフィールドは、SUM関数を宣言したレベルよりも下位のレベルに存在する必要があります。
MIN、MAX: XML抽出フィールドの引数のすべての子インスタンスで、最小値または最大値を検索します。フィールドは数値である必要があります。操作対象のフィールドは、関数を宣言したレベルよりも下位のレベルに存在する必要があります。
FORMAT_DATE: 日付文字列を必要な日付書式に設定します。例:
FORMAT_DATE("1900-01-01T18:19:20", "YYYY/MM/DD HH24:MI:SS")
生成される出力は次のとおりです。
1900/01/01 18:19:20
FORMAT_NUMBER: 表示対象の数字を必要な書式に設定します。例:
FORMAT_NUMBER("1234567890.0987654321", "999,999.99")
生成される出力は次のとおりです。
1,234,567,890.10
MESSAGE_LENGTH: EFTメッセージ内のメッセージの長さを戻します。
RECORD_LENGTH: EFTメッセージ内のレコードの長さを戻します。
INSTR: テキスト・フィールド内の名前付き文字の数値位置を戻します。
SYSDATE、DATE: 現在の日時を取得します。
POSITION: XML文書ツリー構造内のノードの位置を戻します。
REPLACE: 文字列を別の文字列に置き換えます。
CONVERT_CASE: 文字列または文字を大文字または小文字に変換します。
CHR: ASCII値である引数の文字表現を取得します。
LPAD、RPAD: 文字列値の左側または右側の埋込みを生成します。
AND、OR、NOT: 要素に対する演算子関数。
DISTINCT_VALUES: XPATH関数のDISTINCT-VALUESに相当します。値が等しいものを重複と見なし、重複を除いたうえで、すべての数列を返します。使用方法: distinct_values(フィールド名)。
INCREASE_DATE: 指定された日数分だけ日にちを増やします。
使用方法
increase_date(.//date, 2)
.//dateの値より2日後の日付値を返します。
DECREASE_DATE: 指定された日数分だけ日にちを減らします。
使用方法
decrease_date(.//date, 2)
.//dateの値より2日前の日付値を返します。
その他のSQL関数は、次に示すとおりです。SQL関数に対応する構文を使用してください。
TO_DATE
LOWER
UPPER
LENGTH
GREATEST
LEAST
DECODE
CEIL
ABS
FLOOR
ROUND
CHR
TO_CHAR
SUBSTR
LTRIM
RTRIM
TRIM
IN
TRANSLATE
この項では、予約されているキーワードと句、およびそれらの使用方法について示します。サポートされている演算子の定義、XML抽出フィールドの参照とリテラルの使用に関するルールも示されています。
キーワードとキーワード句には、次の4つのカテゴリがあります。
コマンドおよび列ヘッダー・キーワード
コマンド・パラメータおよび関数パラメータ・キーワード
フィールドレベル・キーワード
式キーワード
次のキーワードは、ここに示すとおり、<>で囲んでから、すべて大文字の太字にして使用する必要があります。
<LEVEL> : データ表の最初のエントリ。表をXML要素に関連付け、表の階層を指定します。
<END LEVEL>: 現在のレベルの終わりを宣言します。表の終わりまたはスタンドアロン表で使用できます。
<POSITION>: データ・フィールド行の最初の列の列ヘッダーで、レコード内のデータ・フィールドの開始位置を指定します。
<LENGTH>: データ・フィールド行の2番目の列の列ヘッダーで、データ・フィールドの長さを指定します。
<FORMAT>: データ・フィールド行の3番目の列の列ヘッダーで、データ型と書式設定を指定します。
<PAD>: データ・フィールド行の4番目の列の列ヘッダーで、埋込みスタイルと埋込み文字を指定します。
<DATA>: データ・フィールド行の5番目の列の列ヘッダーで、データソースを指定します。
<COMMENT>: データ・フィールド行の6番目の列の列ヘッダーで、自由書式コメントを入力できます。
<NEW RECORD>: 新しいレコードを指定します。
<DISPLAY CONDITION>: レコードの印刷時の条件を指定します。
<TEMPLATE TYPE>: FIXED_POSITION_BASEDまたはDELIMITER_BASEDのいずれかのテンプレート・タイプを指定します。
<OUTPUT CHARACTER SET>: 出力の生成時に使用するキャラクタ・セットを指定します。
<NEW RECORD CHARACTER>: 実行時に、明示的および暗黙的に新規レコードを示すために使用する文字を指定します。
<DEFINE LEVEL>: テンプレートの書式固有のレベルを定義します。
<BASE LEVEL>: レベル定義および連結定義コマンド用のサブコマンド。
<GROUPING CRITERIA>: レベル定義コマンド用のサブコマンド。
<END DEFINE LEVEL>: レベルの終わりを表します。
<DEFINE SEQUENCE>: テンプレート・フィールドで使用するレコードまたは抽出要素ベースの順序を定義します。
<RESET AT LEVEL>: 順序定義コマンド用のサブコマンド。
<INCREMENT BASIS>: 順序定義コマンド用のサブコマンド。
<START AT>: 順序定義コマンド用のサブコマンド。
<MAXIMUM>: 順序定義コマンド用のサブコマンド。
<MAXIMUM LENGTH>: データ・フィールド行の最初の列の列ヘッダーで、データ・フィールドの最大長を指定します。DELIMITER_BASEDテンプレートでのみ使用します。
<END DEFINE SEQUENCE>: 順序定義コマンドの終わりを表します。
<DEFINE CONCATENATION>: 親レベル・フィールドの文字列として参照可能な、子レベル要素の連結を定義します。
<ELEMENT>: 連結定義コマンド用のサブコマンド。
<DELIMITER>: 連結定義コマンド用のサブコマンド。
<END DEFINE CONCATENATION>: 連結定義コマンドの終わりを表します。
<SORT ASCENDING>: レベルのインスタンスに対する書式固有のソート。
<SORT DESCENDING>: レベルのインスタンスに対する書式固有のソート。
これらのキーワードは、すべて大文字の太字以外のフォントで入力する必要があります。
PERIODIC_SEQUENCE: 順序定義コマンドのリセット・レベル・サブコマンドで使用します。順序番号がテンプレートの外部でリセットされることを示します。
FIXED_POSITION_BASED、DELIMITER_BASED: テンプレート・タイプ・コマンドで使用し、テンプレートのタイプを指定します。
RECORD、LEVEL: 順序定義コマンドの増分基準サブコマンドで使用します。RECORDでは、新しいレコードで使用されるたびに順序が増分されます。LEVELでは、レベルの新しいインスタンスでのみ順序が増分されます。
Alpha: <FORMAT>列で、データ型が英数字であることを指定します。
Number: <FORMAT>列で、データ型が数値であることを指定します。
Integer: <FORMAT>列で、Numberキーワードとともに使用します。数字の整数部分を抽出します。その機能はINTEGER関数と同様ですが、INTEGER関数は式内で使用するのに対し、Integerキーワードは<FORMAT>列でのみ使用します。
Decimal: <FORMAT>列で、Numberキーワードとともに使用します。数字の小数部分を抽出します。その機能はDECIMAL関数と同様ですが、DECIMAL関数は式内で使用するのに対し、Decimalキーワードは<FORMAT>列でのみ使用します。
Date: <FORMAT>列で、データ型が日付であることを指定します。
L、R: <PAD>列で、埋込み側(左または右)を指定します。
式で使用するキーワードと句は、大文字の太字で指定する必要があります。
IF THEN ELSE IF THEN ELSE END IF: これらのキーワードは、常にグループとして使用します。これらは、"IF"制御構造式を指定します。
IS NULL、IS NOT NULL: これらの句は、IF制御構造で使用します。これらは、式がNULLであるかどうかをテストするためのブール条件の一部を形成します。
演算子には、ブール・テスト演算子と式演算子という2つのグループがあります。ブール・テスト演算子には、=、<>、<、>、>=および<=があります。これらはIF制御構造でのみ使用できます。式演算子には、()、||、+、-および*があります。これらは任意の式で使用できます。
| 記号 | 使用方法 |
|---|---|
| = | テストと等しい。IF制御構造でのみ使用されます。 |
| <> | テストに等しくない。IF制御構造でのみ使用されます。 |
| > | テストより大きい。IF制御構造でのみ使用されます。 |
| < | テストより小さい。IF制御構造でのみ使用されます。 |
| >= | テスト以上。IF制御構造でのみ使用されます。 |
| <= | テスト以下。IF制御構造でのみ使用されます。 |
| () | 関数の引数および式グループのデリミタ。()内の式グループは常に最初に評価されます。()は、ネスト可能です。 |
| || | 文字列連結演算子。 |
| + | 加算演算子。オペランドのいずれかが数字でない場合は、暗黙の型変換を実行できます。 |
| - | 減算演算子。オペランドのいずれかが数字でない場合は、暗黙の型変換を実行できます。 |
| * | 乗算演算子。オペランドのいずれかが数字でない場合は、暗黙の型変換を実行できます。 |
| DIV | 除算オペランド。オペランドのいずれかが数字でない場合は、暗黙の型変換を実行できます。/は、XPATH構文の一部であるため使用されません。 |
| IN | テストのいずれかのメンバーと等しい。 |
| NOT IN | IN演算子を否定します。テストのどのメンバーにも等しくありません。 |
XML要素は、任意の式で使用できます。実行時に、これらの要素は対応するフィールド値に置き換えられます。フィールド名では、大文字と小文字が区別されます。
XML抽出フィールドをテンプレートで使用する場合は、XPATH構文に従う必要があります。これは、BI PublisherエンジンがXML要素を正しく解釈するために必要です。
BI Publisherの書式設定のプロセス中は、コンテキスト要素とみなされる抽出要素が常に存在します。BI Publisherが表内のデータ行を処理するときは、表のレベル要素がコンテキスト要素になります。たとえば、BI PublisherがPayment表内のデータ行を処理するときは、Paymentがコンテキスト要素になります。抽出要素の参照に使用する相対XPATHは、コンテキスト要素の観点から指定されます。
たとえば、Paymentデータ表でPayeeName要素を参照する必要がある場合は、次の相対パスを指定します。
Payee/PayeeInfo/PayeeName
XML要素階層の各レイヤーは、バックスラッシュ「/」で区切られます。この表記法は、ネストされているすべての要素に使用します。レベルの直属の子要素の相対パスは、要素名自体になります。たとえば、TransactionID要素名は、Payment表でそのまま使用できます。
子レベル表内で親レベル要素を参照するには、「../」の表記法を使用できます。たとえば、Payment表でBatchName要素を参照する必要がある場合は、../BatchNameと指定できます。「../」により、Batchがコンテキストとして提供されます。このコンテキスト内では、BatchNameがBatchの直属の子であるため、BatchName要素名を直接使用できます。この表記法では、どの階層レベルの親要素も指定できます。たとえば、Paymentデータ表で(RequestHeader内の)RequesterParty要素を参照する必要がある場合は、次のように指定できます。
../../TrxnParties/RequesterParty
テンプレート内の任意の場所で任意の抽出要素を参照するには、絶対パスを使用できます。絶対パスは、バックスラッシュ「/」で始まります。前述のPayment表の例のPayeeNameを指定する場合は、次の絶対パスを使用します。/BatchRequest/Batch/Payment/Payee/PayeeInfo/PayeeName。
絶対パスの構文を使用すると、パフォーマンスが向上します。
レベル定義、順序定義、連結定義などの設定コマンドによって定義される識別子は、グローバルな識別子であるとみなされます。これらはテンプレート内のあらゆる場所で使用可能で、絶対パスや相対パスは必要ありません。設定コマンドのベース・レベルおよびリセット・レベルも指定できます。BI Publisherでは、これらの正しいコンテキストを検索できます。
相対パスの構文を使用する場合は、次のコマンドで、ベース・レベルに対して相対的に指定する必要があります。
連結定義コマンドの要素サブコマンド
レベル定義コマンドのグルーピング基準サブコマンド
順序定義コマンドの開始位置サブコマンド内で抽出フィールドを参照する場合は、絶対パスで指定する必要があります。
レベル・コマンドで抽出要素を参照するためのルールは、データ・フィールドのルールと同じです。たとえば、Batchレベル表とネストされているPaymentレベル表がある場合は、Payment表でPayment要素名をそのまま使用できます。Payment表のレベル・コマンドを評価する際のコンテキストは、Batchであるためです。
ただし、Paymentレベルが省略されていて、Batch表の直下にInvoiceレベル表がある場合は、Payment/InvoiceをInvoice表のレベル要素として指定する必要があります。
テンプレートに必要なXPATH構文は、UNIXやLINUXのディレクトリ構文とほとんど同じです。コンテキスト要素は現行ディレクトリに相当します。そのため、ファイルを現行ディレクトリに対して相対的に指定したり、「/」で始まる絶対パスを使用することができます。
最後に、レベル定義コマンドのグルーピング基準サブコマンドの結果として抽出フィールドを参照するには、一重引用符で囲んで指定する必要があります。これにより、グルーピング基準として抽出フィールドの値ではなく、抽出フィールド自体を使用するようにBI Publisherエンジンに認識させることができます。
レポート・データに簡体字中国語が含まれていて、<OUTPUT CHARACTER SET>がGBKに設定されている場合、エンコーディングにgbk2312を使用しているInternet Explorer 7では中国語が正しく表示されません。この問題は、日本語や韓国語など英語以外の他のエンコードでも同様に発生する場合があります。出力は、eTextテンプレートで文字セットをGBKに設定し、ブラウザのエンコードをGBKまたはGB2312に設定している場合は、Firefox 3.5で正しく表示されます。この問題は、<OUTPUT CHARACTER SET>をutf-8に設定することで回避できます。これはブラウザの表示にのみ関する問題であることに注意してください。テキスト・ファイルは正しく生成されます。
![]()
Copyright © 2010, 2011, Oracle and/or its affiliates. All rights reserved.