 Understanding PS/nVision SQL
Understanding PS/nVision SQLThis chapter provides overviews of PS/nVision SQL and indexes and discusses how to:
Assign ledger tables.
Use indexes and PS/nVision tuning.
Set tree performance options.
Use tree tables.
Understanding PS/nVision SQLThis section discusses:
PS/nVision SQL basics.
Tree joins.
Combination rules.
Capture of PS/nVision SQL.
 PS/nVision SQL Basics
PS/nVision SQL Basics
PS/nVision produces a great variety of reports from multiple database tables. The SQL statements it generates are not overly complex but are sensitive to the performance of the underlying database, especially in the following areas:
Large tables (ledgers often have millions of rows) make efficient use of essential indexes.
The use of trees and reporting (security) views causes multiple tables to be joined. The database’s efficiency in processing these joins dictates most PS/nVision performance.
Most PS/nVision aggregate queries are defined with minimal built-in criteria and could tire your database server if executed without the added criteria of a PS/nVision layout.
Unlike traditional batch-reporting tools, PS/nVision supports interactive, focused reporting using a probing or querying approach to database access. PS/nVision queries tend to be more numerous than traditional report writers but also more focused on the specific data the user needs to see.
Much of this chapter focuses on the performance aspects of retrieving information from ledgers for financial reporting. However, most of the information is equally applicable to other types of fact tables, particularly when trees are used to retrieve the data.
Tree Joins
PS/nVision often relates tree node criteria to data tables by joining the data table to a tree selector table. This selector table contains a row for every detail range defined for the tree in PeopleSoft Tree Manager and is keyed by SELECTOR_NUM (a system-generated constant number for all the rows representing a particular tree) and the tree node number. Because some database platforms join tables efficiently only if the field sizes match, we use up to 30 selector tables, one for each supported field length. Each selector table has RANGE_FROM_nn and RANGE_TO_nn columns matching the corresponding field size.
The following is a typical Select statement for selection via nodes on a single tree.
SELECT L.TREE_NODE_NUM, SUM(POSTED_TOTAL_AMT) FROM PS_LEDGER A, PSTREESELECT06 L WHERE A.LEDGER='ACTUALS' AND A.FISCAL_YEAR=1991 AND A.ACCOUNTING_PERIOD BETWEEN 1 AND 9 AND A.ACCOUNT>=L.RANGE_FROM_06 AND A.ACCOUNT<=L.RANGE_TO_06 AND L.SELECTOR_NUM=198 AND (L.TREE_NODE_NUM BETWEEN 1612345 AND 3098765 OR L.TREE_NODE_NUM BETWEEN 3512345 AND 4098765) GROUP BY TREE_NODE_NUM
The bold part of this statement accomplishes the tree criteria selection. If the report had tree criteria for other fields, their selector tables would be added to the From list and similar Join criteria to the Where clause. The Group By clause returns an answer row for each node that has a detail range attached to it; these node numbers are used to post amounts from the answer set into the appropriate rows or columns of the report.
See Also
Combination Rules
PS/nVision tries to retrieve the data for each report instance with as few Select statements as possible. It examines all row and column criteria to determine which can be combined. It then builds a Select statement to retrieve each intersection of a combined group of rows with a combined group of columns. The following built-in rules should be understood when you design indexes:
Different ledgers cannot be combined.
Different TimeSpans cannot be combined.
nPloded rows or columns cannot be combined with non-nPloded rows or columns.
To be combined, multiple rows or columns must have criteria for the same set of fields, and each field’s criteria must be of the same type. (For example, selected tree nodes cannot be combined with selected detail values).
If criteria for a field are specified by tree node, they can be combined only if they use the same tree.
If the combined rows or columns have identical criteria for a particular field, the criteria are included in the Where clause, but a Group By clause on that field is not required. But if different rows or columns in the group have different criteria, PS/nVision adds this field (or the corresponding tree node number) to the Group By clause to retrieve a value for use in posting the answer set to the appropriate rows or columns of the report.
A single Select statement can retrieve amounts for multiple combined rows and columns.
Different scope instances are retrieved with separate Select statements.
Some additional rules apply for layouts defined using queries rather than ledgers:
Different queries are not combined.
References to different answer columns in the same query can be retrieved with a single Select statement if they meet the above tests.
Capture of PS/nVision SQL
To examine the SQL produced by PS/nVision, you can capture the statements in one of two ways:
Use the Show Report SQL option in the PeopleSoft nVision Options dialog box. This option causes PS/nVision to display each Select statement used to retrieve labels or amounts in a dialog box. You can select the text with the mouse, then copy (CTRL+C) it to the Clipboard, then paste (CTRL+V) the text into another application, such as Notepad, WordPad, an interactive SQL tool, or a text editor. You can then save the text to a file or work with it within the application.
Note. To capture the SQL without waiting for it to execute, you can also select the Suppress Amount Retrieval option. PS/nVision generates all the SQL but does not execute Select statements for amounts.
Turn on the PeopleTools SQL trace through the Trace tab on the Configuration Manager. The SQL statements executed by PeopleTools will be written to a file that you specify.
Assigning Ledger Tables
Each ledger is assigned to a database table, but different ledgers might not be stored in the same table. Some ledgers need different amount formats (for example, number of decimal places) or a different field configuration than others. Summary ledgers must be stored in different tables than their corresponding detail ledgers.
Because each installation of PeopleSoft General Ledger has different ChartFields and reporting requirements, each installation must assign ledger tables and indexes to meet its requirements and ensure good reporting performance.
Using Indexes and PS/nVision TuningThis section provides an overview of indexes and discusses how to use:
Optimizers.
Filter factors.
Index matching.
Ledger access paths.
Access path analysis.
Index column suggestions.
Understanding Indexes
An index is a fast way to find data. At a simple level, an index works like the tabs on a large dictionary; you can go directly to all the words that begin with a particular letter. After that, you need to do some additional searching, taking advantage of the fact that the words are stored in alphabetical sequence. The range of words on a page is generally printed at the top, so you do not have to scan through individual words until you find the page you want. Many database systems include a type of index, often called a primary or clustered index, that has the same sequence as the data.
But suppose you are searching an atlas, where data is generally stored in geographical sequence. If you are looking up Majorca, you are likely to look it up first in the alphabetical index, and then search the page that has a map of the Mediterranean. Data is accessed through an attribute different from its storage attribute.
Suppose you wan to find all the words in the dictionary derived from Finnish words. Unless you had a dictionary with an etymological index, your scan of the data pages would be very time-consuming. This type of access should be avoided when accessing large database tables, because it is slow even on the fastest server.
Typically, the Where clause in a query contains a mixture of criteria resolvable through an index and criteria resolvable only through access to the data pages. To be efficient, use the index criteria to limit the number of data rows searched.
Relational databases allow indexes over multiple columns, so that if you have Where criteria for two or more columns in the index, the database manager can use one index to satisfy criteria on multiple columns at a time. Having the pertinent criteria columns in an index, however, does not guarantee that index will be used or that it will be used effectively on all the columns that have criteria.
Optimizers
Most relational database systems include a cost-based optimizer, a complex program responsible for choosing an access path to satisfy a particular query, such as a Select statement issued by PS/nVision. Using statistics stored in the database, the optimizer tries to determine the index to use for each of the tables accessed in the query and the table access sequence that yields the data with minimal searching.
Some database optimizers have a choice between cost-based and rule-based optimizers. For PS/nVision, and for most PeopleSoft software, you should use the cost-based optimizer because:
PS/nVision creates dynamic SQL based on the report criteria you provide.
Rule-based optimizers are designed for static SQL that is written following its rules.
Cost-based optimizers adapt much better to changes in data and indexes because they use statistics in their optimum access path calculations.
This discussion of tuning PS/nVision's SQL performance assumes use of a cost-based optimizer.
Filter Factors
Although it might be named differently, a filter factor applies to all optimizers. It estimates how effective a particular index will be in narrowing a search.
Assume we have a table in which financial results are stored by fiscal year, period, and account number. The table has two indexes, one on fiscal year and another on account. Assume that our query contains the following:
WHERE FISCAL_YEAR = 1994 AND ACCOUNT='500120'
If the table has data for 4 fiscal years and 800 accounts, then the filter factor for the fiscal year index is ¼ or 0.25; and the filter factor for the account index is 1/800 or 0.00125. Using the index for fiscal year narrows the search to about one fourth of the total table, which is not that great. But using the index for account narrows the data searched to about one eight hundredth of the total table and will be much more efficient. Of course, an index combining fiscal year and account would be even better.
The measure of the selectivity of an index, or a column within an index, is often called its cardinality. Cardinality is the number of discrete values in that column or the number of discrete combinations represented by a multicolumn index. Cardinality is one of the most important statistics used by optimizers to select indexes and access paths. Like most other statistics, cardinality is updated on request rather than constantly.
When data changes substantially, update the statistics so the optimizer has accurate information. Updating statistics requires different processes on different database platforms.
See Also
PeopleTools Installation Guide for your platform.
Index Matching
The effective filter factor for an index is the combined cardinalities for the index columns actually used in a particular access. For example, if an index is built over FISCAL_YEAR, LEDGER, and ACCOUNT, and the table contains 4 years, 5 ledgers, and 800 accounts, the potential filter factor is 1/(4*5*800), or 1/16000, or 0.0000625. However, if the ACCOUNT field in the index couldn’t be used because of the nature its criteria, the filter factor would be only 1/20, which isn’t very selective.
These general rules apply to matching index columns:
Database systems provide direct access to data very quickly if the criteria can be processed through an optimized look-up process (such as searching a tree structure) within the index.
Scanning index pages to satisfy criteria is much slower, although it is usually much faster than scanning the corresponding data.
Columns are matched from left to right in the order they were specified when the index was created.
If, for example, an index is created over DEPTID, BUSINESS_UNIT, and ACCOUNT, but no criteria were provided for BUSINESS_UNIT, only the DEPTID field in the index would be matched, even if criteria were specified for ACCOUNT.
To get index matching on multiple columns, the leftmost columns must have simple criteria, often equality (such as FISCAL_YEAR=1996).
More complex criteria, such as In (...), Between, or a Join to another table, generally either prevent a random-access match on the index column or prevent matching any of the columns to its right.
Ledger Access Paths
As a general rule, it is most efficient to access ledger data through trees by accessing the tree table first, then using the detail ranges (or values) for the selected nodes to select the desired rows from the ledger. If the Select statement joins multiple trees, the database engine should select the one that best fits the available indexes or the one with the highest cardinality (if multiple indexes are possible).
Access Path Analysis
Different techniques exist for showing the access path for a given SQL statement.
First, create a PLAN_TABLE if your database doesn’t already have one. You can find a sample Create statement in the DB2 Performance Tuning guide.
Include the SQL statement in the following and execute it via a utility like SPUFI:
DELETE FROM PLAN_TABLE WHERE QUERYNO=nnn; EXPLAIN PLAN SET QUERYNO=nnn FOR statement;
where nnn is a number you assign to this statement.
Retrieve the plan from the PLAN_TABLE with the following Select statement:
SELECT QBLOCKNO, PLANNO, TNAME, ACCESSNAME, METHOD, ACCESSTYPE, MATCHCOLS, INDEXONLY, PREFETCH, SORTC_GROUPBY FROM PLAN_TABLE WHERE QUERYNO=nnn ORDER BY QBLOCKNO, PLANNO;
The table contains other plan information; these are generally the most pertinent columns for PS/nVision queries.
First, create a PLAN_TABLE if your database does not already have one. Here is a sample Create statement:
CREATE TABLE PLAN_TABLE( STATEMENT_ID VARCHAR2(254), TIMESTAMP DATE, REMARKS VARCHAR2(80), OPERATION VARCHAR2(30), OPTIONS VARCHAR2(30), OBJECT_NODE VARCHAR2(128), OBJECT_OWNER VARCHAR2(30), OBJECT_NAME VARCHAR2(30), OBJECT_INSTANCE NUMERIC, OBJECT_TYPE VARCHAR2(30), OPTIMIZER VARCHAR2(255), SEARCH_COLUMNS NUMERIC, ID NUMERIC, PARENT_ID NUMERIC, POSITION NUMERIC, other long);
You can use SQL*Plus to evaluate access plans interactively. First, include the SQL statement in the following code and execute it.
DELETE FROM PLAN_TABLE WHERE QUERYNO=nnn; EXPLAIN PLAN SET STATEMENT_ID = 'nnn' FOR statement;
where nnn is an identifier you assign to this statement.
Retrieve the plan from the PLAN_TABLE with the following Select statement:
SELECT LPAD(' ',2*LEVEL)||OPERATION,OPTIONS,OBJECT_NAME, OBJECT_INSTANCE,SEARCH_COLUMNS FROM PLAN_TABLE WHERE STATEMENT_ID='nnn' CONNECT BY PRIOR ID = PARENT_ID AND STATEMENT_ID='nnn' START WITH ID = 1 AND STATEMENT_ID='nnn' ORDER BY ID;
The plan is retrieved in a hierarchical tree format, in which the steps are evaluated from inside out, and then top to bottom. The first step listed (not indented) is actually the final step in the plan, and it is preceded by the step on the following line. For example, a Join is presented first, followed by two indented lines showing the two tables joined and the indexes used to access them.
Index Suggestions
Designing indexes for PS/nVision can be difficult because different reports can have different criteria. The following suggestions may be helpful:
|
Index Column |
Suggestion |
|
When using a TimeSpan (required for ledger reporting but optional for queries), PS/nVision always generates an equality for fiscal year (for example, FISCAL_YEAR=1996). If the TimeSpan requires data from multiple fiscal years, then PS/nVision generates multiple Select statements, one for each fiscal year, which makes Fiscal_Year a good candidate for the first column in a multicolumn index. |
|
|
Ledger |
When accessing ledger data, PS/nVision retrieves data from only one ledger at a time, so this column is guaranteed to have an equality. Thus, Ledger is a good choice as the second column in a multicolumn index. |
|
Business_Unit |
If you use the report request option to retrieve data from the requesting business unit only, PS/nVision generates an equality (for example, BUSINESS_UNIT=‘M04’) for this column. If this is the most common way of requesting reports or if you use a scope to get instances by business unit, then use business unit as the second or third column in a multicolumn index, especially if you have many business units in the same ledger table. If most of your reporting accesses multiple business units in a single instance, position it in the index as you would any other field. |
|
Accounting_Period |
When using TimeSpans, accounting period is specified using either an equality (ACCOUNTING_PERIOD=12) or a range (ACCOUNTING_PERIOD BETWEEN 10 AND 12). If you do a lot of reporting for the current period or other single periods (such as current period a year ago), performance may be improved using an alternate index beginning with accounting period. A good optimizer uses this index only when accounting period has an equality. |
|
Account |
In many companies, Account is the field with the highest cardinality. It also has criteria in almost all ledger reports, in part because PS/nVision enforces this rule. Use it as the next index column following the columns that you expect to have equalities. |
Using Trees
This section provides an overview of using trees with PS/nVision and discusses how to:
Enhance tree performance with SQL techniques.
Set tree performance options.
Understanding Trees and PS/nVision
PS/nVision performance may suffer when trees are used, especially when the SQL statements used to retrieve data access two or more trees at once. On some database platforms, the Where criteria used with most tree joins can cause the database optimizer to select the wrong access path, making the PSTREESELECTnn table an obstacle to performance rather than an aid. This often happens when the tree uses ranges of detail values.
To address these performance issues, PS/nVision includes techniques for building SQL that implement tree criteria, and it also implements SQL that is readily understood by database optimizers, yielding better access paths with less need for index tuning and so on. Additionally, you have control over the techniques used, so you can tune the performance of individual reports.
Enhancing Tree Performance with SQL Techniques
PS/nVision includes a number of SQL techniques to improve performance whenever trees are used. You can use static selectors or dynamic selectors. You can specify where or how to use selectors. A selector represents nodes of a single tree and is represented by the set of rows in the PSTREESELECTnn table having a single SELECTOR_NUM value.
Static Selectors
A static selector represents the entire tree, and it remains valid until the tree changes. For all database platforms, these selectors contain ranges (unless the tree had no ranges).
Static selectors do not need to be rebuilt except when the tree changes. However, the SQL statements that join static selectors to fact tables (such as ledgers) can be complex because they include both range predicates (if the tree has ranges) and node criteria to select that portion of the tree required on a particular section of a report. This can be difficult for database optimizers to process, especially if multiple trees use this technique.
Note. You should not run reports while you are modifying trees; it could lead to incorrect results.
A dynamic selector is created for use in a section of a single report, so it only lasts to the end of the report request. This section, however, may be selected several times, especially if the report uses a scope to produce multiple instances.
In addition to the ability to use a pre-existing (static) selector, PS/nVision can build one on the fly when preparing to run a report. This technique can boost performance, but can also create more overhead, especially if there are multiple users running the same report (using static selectors, users can share selectors).
PS/nVision builds each dynamic tree selector for a specific set of criteria (such as a set of rows or the current instance node), so that a selector (SELECTOR_NUM value) has exactly the nodes needed for a group of rows or columns to be retrieved with a Select statement. This eliminates the need for the often-cumbersome selection criteria PS/nVision generates for a static selector:
TREE_NODE_NUM BETWEEN x AND y OR TREE_NODE_NUM BETWEEN...
A dynamic selector creates a new SELECTOR_NUM value that PS/nVision uses and then deletes once the report is complete. Therefore, distribution statistics (or skew statistics) are not present for that selector. (Distribution statistics are still a factor for static selectors.) With certain PS/nVision reports, the absence of distribution statistics can improve performance significantly; that’s because distribution st atistics can make the SELECTOR_NUM criteria appear less selective to the database system optimizer, preventing the optimizer from accessing the selector table first.
The disadvantage of dynamic selectors is that one or more selectors may be needed to process a single report. In some cases, the time used to create the selectors can exceed the time saved by using them. Dynamic selectors are most effective on joins that drive the access path; static selectors may be just as fast, or faster, for additional criteria that do not affect the access plan.
Use single-value selectors only in conjunction with dynamic selectors. Combining dynamic and single-value selector techniques improves the performance of PS/nVision in many cases where trees are used.
Single-value selectors enable a more efficient equi-join between PSTREESELECTnn.RANGE_FROM_nn and the criteria field in the fact table (the one you are selecting data from). In building the dynamic selector, we do not merely copy the ranges of values (such as account numbers) from PSTREELEAF into PSTREESELECTnn. Instead, we join the tree ranges to the underlying detail table (such as the GL_ACCOUNT_TBL), and insert the individual detail values into the RANGE_FROM_nn column of PSTREESELECTnn. This may generate more rows in this table, but it can also generate a more efficient join without maintaining the tree with individual detail values (the only way you could get equi-joins without this option).
A disadvantage of this technique is that, especially where the tree has large ranges containing many detail values, single value selectors can contain many more rows than ranged selectors have. Unless the join is processed in a more efficient manner, the number of rows in the selector can mean slower join processing.
The suppress join technique eliminates a SQL join by retrieving the detail ranges associated with the selected node and coding them in the Select statement. This technique is most effective in the following cases:
The selected tree is used in the scope you expect to be used with this report, and each instance of that report is a tree node.
The node or nodes selected represent a relatively small number of detail values or ranges.
The suppress join technique cannot be used where PS/nVision needs to group the answer set by tree node number, because these numbers are not available without joining the data to the tree. This happens, for example, if multiple rows or columns with otherwise similar criteria select different nodes of this tree. This is typical in the rows of most financial reports. However, if nPlosion to underlying details is specified for these rows or columns, the suppress join technique can be used, because PS/nVision can Group By the detail values rather than tree nodes.
Additionally, when the selected node (or nodes) includes large numbers of detail ranges, the suppress join technique may not be practical or efficient. While PS/nVision can build the very large statements that can result in this case, use of the suppress join technique when tree nodes refer to very large lists of detail ranges can be slower than the other techniques, or even fail to run because the statements exceed the size limits imposed by your database platform.
The sub-select method is very similar to a join. Instead of adding the tree selector to the From list of the main query, the tree selector criteria and its relation to the data (for example, DEPTID) in the main query is within an "Exists (Select ...)" clause in the Where portion of the main query. This is called a correlated sub-query, because part of the criteria in the sub-select relates to data in the main query (A.DEPTID=B.RANGE_FROM_05). This is what makes it so much like a join. Database engines and optimizers differ in how they handle this syntax. Some process a correlated sub-query just like a join, while others are subtly different. You may need to experiment to determine which works better for which reports on your database platform.
Data from the sub-select statement cannot be included in the main Select list; thus, none can be visible to the program (for example, PS/nVision) that is running the query. This is because the sub-select statement is hidden in the Where clause, rather than appearing in the From clause. When PS/nVision retrieves multiple nodes of data for different rows or columns of a report, it uses the node number (from the tree selector) to distinguish the data, and this means a join is required. If you specify either sub-select or Suppress Join in this case, PS/nVision ignores the option and forces a join. You need to specify join options even if not using a join method, because you may get a join after all. If you don't see a performance benefit using the sub-select method, we recommend using join instead, because it can be used whether or not tree node criteria are needed in the answer set.
Additional Options
Before the tree performance options were added, PS/nVision invoked the following type of syntax when joining a selector for a tree with ranges:
WHERE _ field >= L.RANGE_FROM_nn AND field <= L.RANGE_TO_nn _
This syntax is equivalent to using the Between predicate. It resulted in better access plans on the DB2/MVS platform. PS/nVision now includes an option to generate the following syntax:
WHERE _ field BETWEEN L.RANGE_FROM_nn AND L.RANGE_TO_nn _
This syntax should result in better access plans on certain database platforms.
Note. This option is only relevant to trees that use range selectors.
Below is an example of the SQL alternatives made possible through the use of tree performance options. Here is the default query (with the node criteria highlighted):
SELECT L1.TREE_NODE_NUM, SUM(A.POSTED_TOTAL_AMT) FROM PS_LEDGER A, PSTREESELECT05 L, PSTREESELECT06 L1 WHERE A.LEDGER='ACTUALS' AND A.FISCAL_YEAR=1996 AND A.ACCOUNTING_PERIOD BETWEEN 1 AND 8 AND L.SELECTOR_NUM=216 AND A.BUSINESS_UNIT>=L.RANGE_FROM_05 AND A.BUSINESS_UNIT<=L.RANGE_TO_05 AND (L.TREE_NODE_NUM BETWEEN 1000000000 AND 1666666665) AND A.CURRENCY_CD='USD' AND L1.SELECTOR_NUM=215 AND A.ACCOUNT>=L1.RANGE_FROM_06 AND A.ACCOUNT<=L1.RANGE_TO_06 AND (L1.TREE_NODE_NUM BETWEEN 1916275676 AND 1923430847) AND A.STATISTICS_CODE=' ' GROUP BY L1.TREE_NODE_NUM;
Here’s an alternative query using the Suppress Join technique for business unit criteria and a dynamic, single-value selector for ACCOUNT:
SELECT L1.TREE_NODE_NUM, SUM(A.POSTED_TOTAL_AMT) FROM PS_LEDGER A, PSTREESELECT06 L1 WHERE A.LEDGER='ACTUALS' AND A.FISCAL_YEAR=1996 AND A.ACCOUNTING_PERIOD BETWEEN 1 AND 8 AND (A.BUSINESS_UNIT BETWEEN ‘B0006' AND ‘B0006' OR A.BUSINESS_UNIT BETWEEN ‘B5030' AND ‘B5030' OR A.BUSINESS_UNIT BETWEEN ‘B9013' AND ‘B9014' OR A.BUSINESS_UNIT BETWEEN ‘B0015' AND ‘B0015' OR A.BUSINESS_UNIT BETWEEN ‘B9026' AND ‘B9026' OR A.BUSINESS_UNIT BETWEEN ‘B0019' AND ‘B0031' OR A.BUSINESS_UNIT BETWEEN ‘B0016' AND ‘B0018') AND A.CURRENCY_CD='USD' AND L1.SELECTOR_NUM=1215 AND A.ACCOUNT=L1.RANGE_FROM_06 AND A.STATISTICS_CODE=' ' GROUP BY L1.TREE_NODE_NUM;
Next is another form of the same query, with dynamic business unit selectors and dynamic ACCOUNT selectors:
SELECT L1.TREE_NODE_NUM, SUM(A.POSTED_TOTAL_AMT) FROM PS_LEDGER A, PSTREESELECT05 L, PSTREESELECT06 L1 WHERE A.LEDGER='ACTUALS' AND A.FISCAL_YEAR=1996 AND A.ACCOUNTING_PERIOD BETWEEN 1 AND 8 AND L.SELECTOR_NUM=1216 AND A.BUSINESS_UNIT = L.RANGE_FROM_05 AND A.CURRENCY_CD='USD' AND L1.SELECTOR_NUM=1215 AND A.ACCOUNT=L1.RANGE_FROM_06 AND A.STATISTICS_CODE=' ' GROUP BY L1.TREE_NODE_NUM;
Setting Tree Performance Options
PS/nVision and PeopleSoft Tree Manager each provide a number of techniques and tuning options that can dramatically improve reporting performance. These performance enhancement techniques apply to both query-based and ledger-based layouts.
To change the technique used for a given tree, you can specify the technique using the Tree Performance Options dialog box in PeopleSoft Tree Manager. To override any Tree Manager settings and specify the technique used for a particular report layout, you specify the technique using the Tree Performance tab on the Layout Options dialog box in PS/nVision.
The tree performance options enable you to control the database access techniques PS/nVision uses to implement tree criteria for your report. These options can have a dramatic effect on how fast your reports run.
In setting these options, work with your database administrator to determine the best options, and to ensure that indexes are tuned for the SQL techniques selected. You should be prepared for some trial and error to find the best settings for your data and reporting requirements.
Note. The performance-tuning information presented here is intended for database administrators and advanced PS/nVision users who understand how PS/nVision accesses relational databases. The techniques discussed are not useful for casual users or for customizing performance on a workstation-by-workstation basis.
Access the Tree Performance tab from Excel, select nVision, Open Layout, Layout Options; and then select the Tree Performance tab.
This is an example of the PeopleSoft nVision Layout Options – Tree Performance dialog box:
Tree performance options are saved in the sheets named NvsTree.treename for each specified tree.
You are setting performance options for a specific layout, one tree at a time. Optimum performance often is achieved using different techniques for different trees, depending on the nature of those trees and the way each tree is used in the report.
If you do not specify the tree performance options for a tree used in a report layout, and no performance options are defined in Tree Manager for that tree, PS/nVision uses the same SQL techniques used in the past on your database platform.
|
Join to tree selector |
Select to include the tree selector table in the From clause and use join criteria to select the appropriate rows from the fact table. This method is sometimes used by PS/nVision even when another method is specified, if tree node information is needed to produce the report. |
|
Suppress join; use literal values |
Select to eliminate a SQL join by retrieving the detail ranges associated with the selected node and coding them in the Select statement. If you select the suppress join technique, but PS/nVision cannot use it because of the need to group results by tree node, it will automatically use the join method you select (that is, either static or dynamic). However, if PS/nVision can use the suppress join technique, it ignores the selector options for this tree. Therefore, pick a selector technique in addition to selecting the suppress join option. Note. This option is not available for use with winter trees. |
|
Sub-SELECT tree selector |
Select to add the tree selector to the From list of the main query. The tree selector criteria and its relation to the data in the main query is within an Exists clause in the Where portion of the main query. |
|
Static Selectors |
Select to build a selector that represents the entire tree and remains valid until the tree changes. |
|
Dynamic Selectors |
Select to creates a new tree selector for use in a section of a single report. The dynamic selector represents just the requested nodes. |
|
Single values |
Used only with dynamic selectors. Select to cause PS/nVision or PeopleSoft Query to build a selector using the individual detail values (from the detail table specified in the tree structure) that fall within the detail ranges of the selected nodes. |
|
Range of values (>= <=) |
For a tree with ranges of values, select to make the selectors more compact (fewer rows) and less likely to become obsolete as detail values are added. For some database optimizers, the syntax “fieldname >= RANGE_FROM_nn AND fieldname <= RANGE_TO_nn” gets a better access plan than BETWEEN. Note. If you specify one of the range syntax options, but the tree has no ranges, PS/nVision uses the single-value syntax (field = L.RANGE_FROM_nn). |
|
Range of Values (BETWEEN) |
Select to use the syntax “fieldname BETWEEN RANGE_FROM_nn AND RANGE_TO_nn”. This choice is best for ranged selectors on most database platforms. |
|
Non-specific node criteria (above 2 billion) |
Select to prevent the optimizer from selecting the driving criteria field based on how inclusive the node number criteria are. This option has been used on DB2 when criteria for multiple trees were present. Unless you are a DB2 customer who has tuned your database around this extra criteria, we recommend that you not use this option. |
Note. Trees with a mixture of dynamic detail and range detail are not supported by nVision. Reports generated using such trees may not be accurate.
See Also
Using PS/nVision-Defined Names
Setting Tree Performance Options
Understanding Restrictions on Tree Performance Options
In certain cases, PS/nVision may override the specified tree SQL technique. The dynamic selector technique is not used when a field has tree criteria in multiple dimensions (for example, both row and column), or when a field has the same tree criteria in multiple places (for example, in both sheet level and row level). This can also happen at DrillDown time if criteria for a field are inherited from multiple dimensions (for example, the scope and column) of the parent report. With the dynamic selector technique unavailable, PS/nVision uses either the suppress join technique (if requested and if feasible) or the static selector technique.
You cannot select the single value option with static selectors because the static selector remains unchanged until the tree changes. However, the addition of single values to the fact table, which the tree detail is based on, doesn’t affect a tree change. The single-value options exist for dynamic selectors and for enabling you to control the syntax used with ranged selectors.
PS/nVision ignores the suppress join technique if specified for a tree with summary ChartField node criteria. Summary ChartField nodes, or detail values in summary trees, are tree nodes from a detail tree rather than values from a database field. In addition, PS/nVision does not support translation of summary ChartField nodes when drilling down to the detail ledger, so we recommend that you use the summary tree criteria.
The suppress join technique is available for reports based on summary trees, as long as tree node information is not needed to group the result. It may be possible to recode some reports that use detail value criteria for summary trees for performance reasons.
These performance-enhancement techniques are not used when retrieving labels (such as account descriptions). Labels for detail fields associated with tree criteria are retrieved using static selectors. The SQL code used to retrieve labels is defined at a different level from the SQL used to retrieve amounts, so it isn’t possible to use the same dynamic selectors for both.
Because criteria from multiple rows and columns are combined with the instance (scope) criteria in a single Select statement, SQL statements generated by PS/nVision can be long and complex. While current releases of PS/nVision no longer enforce a statement size limit, every database platform has a maximum statement size, and even statements shorter than the maximum may be inefficient. You control statement size through judicious use of the performance options.
Here are the common causes of oversized SQL statements:
Use of the suppress join technique on a tree (or trees) from which nodes representing too many detail ranges are requested.
Suppressing a join can be very useful, but is recommended only when criteria from a given tree require a relatively short list of detail values or ranges.
Use of static selectors with a very long list of nodes.
PS/nVision combines node number ranges for sibling nodes where possible, so it takes lots of nodes to exceed the limit. Use of dynamic selectors makes the SQL much shorter.
An extremely long list of detail values.
The messages that indicate a statement is too long vary from platform to platform. For statements made long by tree criteria, the most successful solution is generally to use the dynamic selectors technique on one or more of the trees involved.
Optimizing Indexes With Dynamic Selectors
If you use the dynamic selector technique heavily for certain criteria fields, you should try an index on that field’s selector table that is optimized around this technique. For example, a ACCOUNT is a six-character field (meaning its selector table is PSTREESELECT06) and you plan to use dynamic selectors, with single values, for the ACCOUNT trees on most of your production reports. You should create an index on PSTREESELECT06 on SELECTOR_NUM and RANGE_FROM_06, since these are the only fields that will appear in the Where clause with single-value dynamic selectors. But also bear in mind the following:
Other fields that are the same size may use the same selector table, so you might not want to eliminate an index if removing it would penalize those reports.
Although only SELECTOR_NUM and RANGE_FROM_06 will appear in the Where clause, TREE_NODE_NUM may appear in the Select list (if PS/nVision needs to Group By tree node).
An index that includes this field as well would enable index-only access (that is, access with no need to read the data table) when using this selector.
Index use varies depending on the optimizer and the volume and distribution of data, so experiment to get optimum results.
Using Tree Tables
Understanding the structure of the various tree tables that PS/nVision uses and how they interact is helpful. The main tables used in this example are PSTREEDEFN, PSTREELEAF, PSTREESELCTL, and PSTREESELECTnn:
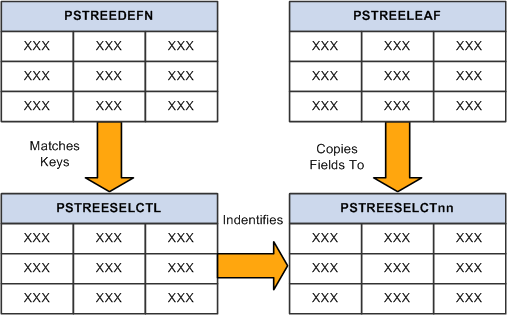
Tree tables used by PS/nVision
The following sections provide details about each of these tables.
PSTREEDEFN: Tree Definition
Details about the PSTREEDEFN table follow.
Description
This system table defines an effective-dated version of a tree.
Fields
|
Field Name |
Type |
Length |
Format |
Long Name |
|
SETID |
Char |
5 |
Upper |
SetID |
|
SETCNTRLVALUE |
Char |
5 |
Upper |
Set control value. Alternative to setID |
|
TREE_NAME |
Char |
18 |
Upper |
Tree name |
|
EFFDT |
Date |
10 |
|
Effective date |
|
EFF_STATUS |
Char |
1 |
Upper |
Status as of effective date |
|
VERSION |
Nbr |
10 |
Raw B |
Version |
|
TREE_STRCT_ID |
Char |
18 |
Upper |
Tree structure ID |
|
DESCR |
Char |
30 |
Mixed |
Description |
|
ALL_VALUES |
Char |
1 |
Upper |
All values |
|
USE_LEVELS |
Char |
1 |
Upper |
Use levels |
|
VALID_TREE |
Char |
1 |
Upper |
Valid tree |
|
LEVEL_COUNT |
Nbr |
3 |
|
Level count |
|
NODE_COUNT |
Nbr |
5 |
Raw B |
Node count |
|
LEAF_COUNT |
Nbr |
5 |
Raw B |
Leaf count |
|
TREE_HAS_RANGES |
Char |
1 |
Upper |
Tree has ranges |
|
DUPLICATE_LEAF |
Char |
1 |
Upper |
Allow duplicate leaf |
|
TREE_CATEGORY |
Char |
18 |
Upper |
Category |
|
TREE_ACC_METHOD |
Char |
1 |
Upper |
Tree access method |
|
TREE_ACC_SELECTOR |
Char |
1 |
Upper |
Tree access selector |
|
TREE_ACC_SEL_OPT |
Char |
1 |
Upper |
Tree access selector option |
PSTREELEAF: Tree Leaf
Details about the PSTREELEAF table follow.
Description
This user table defines the data value ranges that are the leaves of a tree. For each leaf node (nodes without children), one or more ranges define the detail values that correspond to that node.
Fields
|
Field Name |
Type |
Length |
Format |
Long Name |
|
SETID |
Char |
5 |
Upper |
SetID |
|
SETCNTRLVALUE |
Char |
5 |
Upper |
Set control value |
|
TREE_NAME |
Char |
18 |
Upper |
Tree name |
|
EFFDT |
Date |
10 |
|
Effective date |
|
TREE_BRANCH |
Char |
20 |
Upper |
Tree branch name |
|
TREE_NODE_NUM |
Nbr |
10 |
Raw B |
Tree node number |
|
RANGE_FROM |
Char |
30 |
Upper |
Range from |
|
RANGE_TO |
Char |
30 |
Upper |
Range to |
|
DYNAMIC_RANGE |
Char |
1 |
Upper |
Dynamic range |
|
OLD_TREE_NODE_NUM |
Char |
1 |
Upper |
Old tree node |
PSTREESELCTL: Tree Selection Control
Details about the PSTREESELCTL table follow.
Description
This system table controls and manages static selectors (see PSTREESELECTnn). Each row in this table corresponds to a row in PSTREEDEFN and to a group of rows (with the same SELECTOR_NUM) in PSTREESELECTnn. This table is only used for static selectors.
Fields
|
Field Name |
Type |
Length |
Format |
Long Name |
|
SETID |
Char |
5 |
Upper |
SetID |
|
SETCNTRLVALUE |
Char |
5 |
Upper |
Set control value |
|
TREE_NAME |
Char |
18 |
Upper |
Tree name |
|
EFFDT |
Date |
10 |
|
Effective date |
|
VERSION |
Nbr |
10 |
Raw B |
Version |
|
SELECTOR_NUM |
Nbr |
10 |
Raw B |
Selector number |
|
SELECTOR_DT |
Date |
10 |
|
Selector date |
|
TREE_ACC_SEL_OPT |
Char |
1 |
Upper |
Tree access selector option |
|
LENGTH |
Nbr |
5 |
Raw B |
Length |
PSTREESELECTnn: Tree Select Work-Size nn
Details about the PSTREESELECTnn table follow.
Description
These system tables define selectors used by PS/nVision to speed tree-based data selection. A selector table is defined for every possible detail field length (nn = 01-30); thus this description applies to tables named PSTREESELECT01, PSTREESELECT02, and so on, through PSTREESELECT30.
Fields
|
Field Name |
Type |
Length |
Format |
Long Name |
|
SELECTOR_NUM |
Nbr |
10 |
Raw B |
Selector number |
|
TREE_NODE_NUM |
Nbr |
10 |
Raw B |
Tree node number |
|
RANGE_FROM_nn |
Char |
n |
Upper |
Range from |
|
RANGE_TO_nn |
Char |
n |
Upper |
Range to |
PSTREESELNUM: Tree Selector Number
Details about the PSTREESELNUM table follow.
Description
PS/nVision uses this table to assign a unique SELECTOR_NUM value to each tree selector as it is built. This table has only one row.
Fields
|
Field Name |
Type |
Length |
Format |
Long Name |
|
SELECTOR_NUM |
Nbr |
10 |
Raw B |
Selector number |