| Oracle® Enterprise Manager Cloud Control管理者ガイド 12c リリース5 (12.1.0.5) B65081-16 |
|


 前 |
 次 |
この章の内容は次のとおりです。
Enterprise Manager Cloud Control監視機能により、使用中のIT環境の無人監視が可能になります。Enterprise Managerには、パフォーマンスと状態メトリックのセットが付属しており、これにより、ご使用環境内の主要コンポーネント(アプリケーション、アプリケーション・サーバー、データベースなど)はもちろんのこと、ホスト、オペレーティング・システム、ストレージなど、それらの依存するバックエンド・コンポーネントの監視も可能です。
各管理対象ホストの管理エージェントによって、そのホストのすべての管理対象コンポーネント(ターゲット)のステータス、状態およびパフォーマンスが監視されます。ターゲットが停止するか、パフォーマンス・メトリックが警告またはクリティカルのしきい値を超えると、イベントが作成され、Enterprise Managerに送信されます。管理者または関連するパーティには、Enterprise Manager通知システムを通じてトリガーされたイベントを通知できます。
監視するターゲットの追加は簡単です。Enterprise Managerでは、ターゲットを手動で追加するか、またはホスト上の監視可能なすべてのターゲットを自動的に検出するかを選択できます。Enterprise Managerではまた、新たに追加したターゲットに対する監視設定を自動的およびインテリジェントに適用できます。詳細は、第1.4.2項「管理グループおよびテンプレート・コレクション」を参照してください。Enterprise Managerでは監視に使用する包括的なメトリックのセットを提供しますが、使用環境に特有の状況を監視するために、メトリック拡張も使用できます(第1.3.6項「メトリック拡張: 監視のカスタマイズ」参照)。データ・センターの拡大に従い、各ターゲットを個別に管理することはさらに難しくなるので、Enterprise Managerのグループ管理機能を使用すると、多数のターゲットのセットをグループ化し、多数のターゲットを1つのものとして監視および管理できます。
監視はEnterprise Manager Cloud Control 12cをインストールするとすぐに開始します。Enterprise Managerの管理エージェントは、デプロイおよび起動されるとすぐに、ホストのシステム(ホストのハードウェアおよびソフトウェア構成データを含む)の監視を自動的に開始します。Enterprise Managerが提供する自動検出スクリプトにより、これらのエージェントは、すべてのOracleコンポーネントを自動的に検出し、Oracle推奨のしきい値が設定された広範なメトリックのセットを使用して監視を開始できます。
この監視機能には、NetApp Filer、BIG-IPロード・バランサ、Checkpoint FirewallおよびIBM WebSphereなどの、Oracleエコシステムの他のコンポーネントも含まれます。すべての監視対象コンポーネントからのメトリックは、管理リポジトリに格納および集計され、管理者に診断情報と傾向分析データの豊富なソースを提供します。クリティカル・アラートが検出されると、迅速な解決を促す通知が管理者に送信されます。
デフォルトのEnterprise Managerの監視機能は、次のとおりです。
オラクル社推奨のメトリックおよびしきい値による詳細な監視。
実行中のアプリケーションおよびサービスはもちろん、使用中のITインフラストラクチャ(Oracle製品、Oracle以外の製品を問わず)のすべてのコンポーネントの監視。
リアルタイム・パフォーマンス・チャートへのアクセス。
管理リポジトリへのメトリック・データの収集、格納および集約。これにより、傾向分析やレポート作成などの戦略的タスクを実行できます。
検出したクリティカル・イベントの電子メールおよびページャによる通知。
Enterprise Managerでは、ITインフラストラクチャの多様なコンポーネント(データベース、ホストおよびルーターなど)を監視できます。
監視されるメトリックの例は、次のとおりです。
アーカイブ領域使用量(データベース)
コンポーネント・メモリー使用量(アプリケーション・サーバー)
最大エクステントに近づいているセグメント数(データベース)
ネットワーク・インタフェース合計I/Oレート(ホスト)
管理エージェントなしの監視
IPトラフィック・コントローラまたはリモートWebアプリケーションなど、ITインフラストラクチャの特定のコンポーネントを監視するように管理エージェントを配置することが実用的でない場合に備えて、Enterprise Managerでは拡張ネットワークおよびクリティカルURL監視機能が用意されています。この機能により、エージェントがそのデバイスに物理的に存在することなく、エージェントのビーコン機能によって、可用性および反応性について、リモート・ネットワーク・デバイスおよびURLを監視できます。必要な作業は、特定のビーコンを選択し、主要ネットワーク・コンポーネントおよびURLをネットワークおよびURL監視リストに追加するのみです。この機能の使用方法の詳細は、Enterprise Managerのオンライン・ヘルプおよびOracle Technology NetworkのWebサイトから入手できます。Enterprise Manager監視の概念とこの機能をサポートする基本となるサブシステムについては、次の各項で説明します。
Enterprise Manager Cloud Control 12cには、パフォーマンスと状態メトリックのセットが付属しており、これにより、ご使用環境内の主要コンポーネント(アプリケーション、アプリケーション・サーバー、データベースなど)はもちろんのこと、ホスト、オペレーティング・システム、ストレージなど、それらの依存するバックエンド・コンポーネントの自動監視も可能です。Enterprise Managerは多くのタイプの条件(イベント)を監視できますが、この監視機能の最も一般的な用途は、メトリック値で定義された許容可能なパフォーマンス境界の違反の監視の基本が中心です。次の各項では、基本概念とターゲットの監視をサポートするEnterprise Mangerの機能について説明します。
一部のメトリックには、しきい値と呼ばれる事前定義済の制限パラメータが関連付けられており、収集されたメトリック値がその制限を超えると、メトリック・アラート(イベントのタイプに特有)が起動されます。Enterprise Managerでは、次の2つのレベルのアラート重大度に対してメトリックしきい値を設定できます。
警告 - 特定の領域で注意が必要ですが、その領域は機能を続けています。
クリティカル - 特定の領域で迅速な対処が必要です。その領域は、機能していないか、緊急の問題が発生しています。
したがって、しきい値は監視対象のメトリックと比較される境界値です。たとえば、ディスク使用状況(%)メトリックに関連付けられた各ディスク・デバイスごとに、警告しきい値をディスク使用領域80%に、クリティカルしきい値を95%に定義します。
|
注意: すべてのメトリックにしきい値が必要なわけではなく、値に意味がない場合や、特定の環境でその値が必要ない場合は、削除したり、設定せずにおくこともできます。 |
即時利用可能な事前定義済のメトリックしきい値はほとんどの監視条件で使用可能ですが、環境によっては操作基準をより正確に反映するため、しきい値のカスタマイズが必要になります。ただし、パフォーマンス・メトリックなどの特定カテゴリのメトリックでは、正確なしきい値の設定は困難な場合があります。
たとえば、1トランザクション当たりレスポンス時間のデータベース・メトリックでは、適切な警告およびクリティカルしきい値はどのようになるか考えます。このようなメトリックの場合、パフォーマンス・メトリックに対する管理対象の値が通常動作から逸脱した場合のアラート発生がより有効です。Enterprise Managerでは、ターゲットについて通常のパフォーマンス動作を取得し、そのパフォーマンス基準からの逸脱を示すしきい値を決定可能な機能が提供されます。
|
注意: Enterprise Managerの管理者がメトリックしきい値を変更するには、ターゲットに対する「ターゲット・メトリックの管理」以上の権限が付与されている必要があります。 |
どのメトリックしきい値が環境のパフォーマンス監視要求を正確に反映しているかを決定することは重要です。正しい値を決定するために試行錯誤に頼るのではなく、Enterprise Managerではメトリック・ベースラインを提供します。メトリック・ベースラインは、Enterprise Managerがシステムのパフォーマンス・メトリックを取得した期間に相当する適切に定義された時間間隔(ベースライン期間)で、特定の期間のシステム・パフォーマンスの統計的特性です。この履歴データは、システム・パフォーマンスの正規化されたビューを提供することにより、有効なメトリックしきい値を決定する作業を大幅に簡略化します。メトリック動作のベースラインで正規化されたビューにより、管理者はイベントの発生を説明および理解できます。
メトリック・ベースラインの基礎となる仮定は、比較的安定したパフォーマンスのシステムが、比較可能なワークロード期間において同じようなメトリック測定(値)を示していることです。2つのタイプのベースライン期間がサポートされます。
変動ウィンドウ・ベースライン期間: 変動ウィンドウ・ベースライン期間は現在の日付より前の一定の日数(過去7日間など)として定義されます。これにより、現在のメトリック値と最近測定された履歴を比較できます。変動ウィンドウ・ベースラインは、予測可能なワークロード・サイクル(日中はOLTP処理、夜間はバッチ処理など)で運用されている業務系システムに適しています。
静的ベースライン期間: 静的ベースラインは、管理者が特に関心のある対象として定義した時間間隔(会計年度末など)です。これらのベースラインは、将来同じワークロードが発生したときに比較対象とするワークロード期間を指定するために使用できます(ある暦年と次の暦年の会計年度末を比較する場合など)。
一般的に、メトリック・ベースラインは有効なターゲットのアラートしきい値を判断するために有効ですが、これらのしきい値は静的で、予測されるパフォーマンスの変化に対応することができません。定期的な(予測できる)間隔で、ターゲットに異なるワークロードが発生する監視状況があります。この場合、静的なアラートしきい値では正確な結果が得られないことがわかります。たとえば、日中はオンライン・トランザクション処理(OLTP)を実行していて、夜間にバッチ処理を実行するデータベースのアラートしきい値は異なります。同様に、平日と週末など、期間が異なれば、データベースのワークロードは変わります。つまり、しきい値が固定された静的な値であれば、間違ったアラート・レポートが生成される可能性があり、過剰なアラートによって、パフォーマンス管理に関するオーバーヘッドが大幅に増える可能性があります。このOLTPの例では、正確なアラートのしきい値を判断するために静的なベースラインを使用することで、予測されるパフォーマンスの循環的な変化に対応することに失敗し、逆に問題の検出に影響を与えました。静的なベースラインによって、次の構成上の問題が発生します。
バッチ・パフォーマンス用に構成されたベースラインでは、OLTPのパフォーマンスの低下を検出できません。
OLTPパフォーマンス用に構成されたベースラインでは、バッチ・サイクルで過剰なアラートが生成されます。
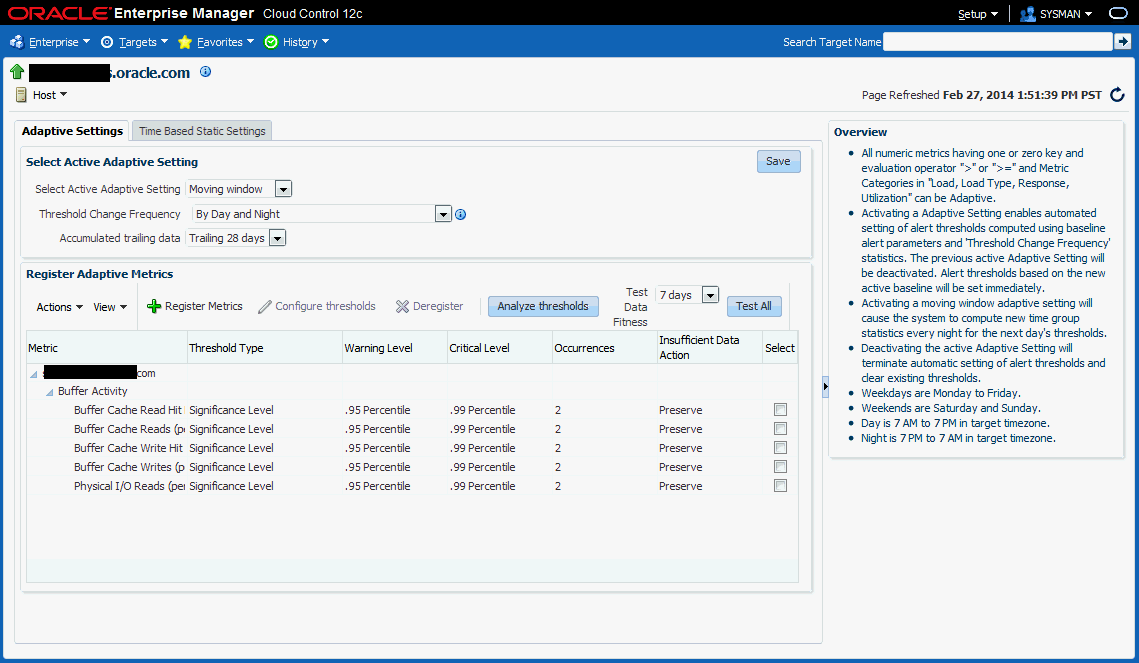
Enterprise Managerリリース12.1.0.4以上では、高度なしきい値管理によって、適応(自己調整)または時間ベース(ユーザー定義)のいずれかのベースラインを使用して、しきい値を計算できます。
適応しきい値: Enterprise Managerが適応しきい値を統計的に計算できます。適応しきい値は、すべてのターゲット(エージェントおよびリポジトリの両方が監視するターゲット)に適用されます。
時間ベースのしきい値: 時間によって変化するワークロードに対応するために、様々な時間に使用する固有のしきい値を定義できます。
便利なUIを使用すると、時間ベースのしきい値および適応しきい値を作成できます。ターゲットのホームページ(ホストなど)から、メトリック・コレクションおよび設定ページに移動します。「関連リンク」リージョンの「高度なしきい値管理」をクリックします。
適応しきい値として登録できるのは、数値およびコレクションの表示メトリックのみです。また、許可されるのは、次のタイプのメトリックのみです。
負荷
ロード・タイプ
使用率およびレスポンス
メトリックしきい値に達すると、メトリック・アラートが発生します。メトリック・アラートは、イベントの1タイプです。イベントは、監視されているメトリックの警告またはクリティカルしきい値のいずれかがクロスしたなどの、潜在的な問題を示す重要な発生です。イベントの別の例には、データベース・インスタンスの停止、構成ファイルの変更、ジョブ実行のエラーでの終了、ホストの指定したCPU使用率のパーセントの超過などがあります。次の2つの最も重要なイベント・タイプがエンタープライズ監視で使用されます。
メトリック・アラート
ターゲット可用性
イベントと監視可能なイベント・タイプの詳細は、第3章「インシデント管理の使用」を参照してください。
修正処理により、メトリック・アラートに対して自動化されたレスポンスを指定できるため、管理者は時間を節約でき、ユーザーに対して顕著な影響が出る前に問題を処理できます。たとえば、Enterprise ManagerがSQL*Netリスナーなどのコンポーネントの停止を検出した場合に、自動的にバックアップを開始する修正処理を指定できます。したがって、修正処理は、メトリックによって警告またはクリティカルの重大度のアラートが発生したときに実行されるユーザー指定の任意のタスクです。修正タスクを実行することに加え、必要に応じてより多くの診断情報を収集するために修正処理を使用できます。デフォルトでは、修正処理はイベントが発生したターゲット上で実行されます。
修正処理は、それぞれ別のターゲットで実行される複数のタスクで構成することも可能です。管理者は、修正処理の成功または失敗に対する通知を受け取ることもできます。修正処理は、それぞれ別のターゲットで実行される複数のタスクで構成することも可能です。
ターゲットの修正処理を定義できるのは、そのターゲットに対する「ターゲット・メトリックの管理」以上の権限を付与されているすべてのEnterprise Manager管理者です。任意のメトリックについて、そのメトリックが警告またはクリティカルの重大度に到達した場合に異なる修正処理を定義できます。
修正処理は、特定のEnterprise Manager管理者の資格証明を使用して実行する必要があります。そのため、修正処理を作成または変更する場合は、常に変更した処理を実行するための資格証明を指定する必要があります。
メトリック拡張を使用すると、Enterprise Managerの監視機能を拡張して使用IT環境に固有の条件を網羅でき、監視環境の完全な包括的なビューが提供されます。
メトリック拡張では、Oracleが提供するメトリックにより使用されるデータ収集メカニズムと同じフルセットを利用する、あらゆるターゲット・タイプに新しいメトリックを定義できます。たとえば、次のターゲット・タイプにメトリックを作成できます。
ホスト
データベース
IBM Websphere
Oracle Exadataデータベースおよびストレージ・サーバー
Oracle Business Intelligenceコンポーネント
これらの新しいメトリックが定義されると、その他のEnterprise Managerメトリックのように使用できます。メトリック拡張の詳細は、第9章「メトリック拡張の使用」を参照してください。
ユーザー定義メトリック(12c以前)
Enterprise Manager 12cサイトを以前のバージョンのEnterprise Managerからアップグレードした場合、以前のバージョンで定義したすべてのユーザー定義メトリックもEnterprise Manager 12cに移行されます。これらのユーザー定義メトリックは引き続き動作しますが、将来のリリースではサポートされなくなります。既存のユーザー定義メトリックがある場合、できるだけ早くメトリック拡張に移行して、管理環境内で監視の中断が起こらないようにすることをお薦めします。移行プロセスの詳細は、第9章「メトリック拡張の使用」の「メトリック拡張へのユーザー定義メトリックの変換」を参照してください。
ブラックアウトにより、緊急メンテナンスや予定されているメンテナンスを実行するための計画停止期間をサポートできます。ターゲットがブラックアウト状態になると、監視は一時停止されます。そのため、データベース・バックアップやハードウェア・アップグレードなどの予定されているメンテナンス作業でターゲットを停止するときに、不要なアラートが送信されるのを回避できます。ターゲットの全体的な可用性を計算する場合、ブラックアウト期間は自動的に除外されます。
ブラックアウト期間は、個々のターゲット、ターゲットのグループ、またはホスト上のすべてのターゲットに対して定義できます。ブラックアウトは、即時実行または将来において実行、あるいは無期限に実行または特定期間実行後に停止のいずれかにスケジュールできます。ブラックアウトは必要に応じて作成でき、また定期的に実行するようスケジュールできます。メンテナンス期間中にメンテナンス・タスクの完了までにより長い(または短い)時間が必要であることがわかった場合は、その時点で有効なブラックアウトを簡単に延長(または停止)できます。ブラックアウト機能は、Enterprise Managerコンソールと、Enterprise Managerコマンドライン・インタフェース(EM CLI)のどちらからでも使用できます。EM CLIは、通常、管理者がメンテナンス・スクリプト内にターゲットのブラックアウトを組み込むために使用できます。ブラックアウトが終了すると、管理エージェントによって、ターゲットのすべてのメトリックが自動的に再評価され、ブラックアウト後のターゲットの現行のステータスが表示されます。
管理者が、先にターゲットをブラックアウトせずに、そのターゲットで予定されたメンテナンスを誤って実行すると、その期間は計画されたブラックアウト期間ではなく、ターゲットの停止時間として認識されます。これは、ターゲットの可用性の記録にとって不都合な結果となります。このような場合、Enterprise Managerでは、スーパー管理者が前に戻ってその期間に発生する予定だったブラックアウト期間を定義できます。これらの遡及ブラックアウト作成機能により、スーパー管理者は、ターゲットの可用性のより正確な記録を柔軟に定義できます。
Enterprise Managerでは、監視環境の管理が大幅に簡略化され、Enterprise Managerの監視機能をカスタマイズおよび拡張することもできます。しかし、Enterprise Managerの監視の一番の利点は、大規模な異機種環境を監視および管理できる機能が提供されることです。監視している環境に存在するターゲットが10であろうと10,000であろうと、次のEnterprise Managerの高度な機能により、同じレベルの利便性と簡単さで、監視環境を実装および保守できます。
監視テンプレートを使用すると、監視の標準をテンプレートに一度指定してそれらを組織全体の監視ターゲットに適用することで、エンタープライズ全体の監視設定を簡単に標準化できます。これにより、エンタープライズ全体で特定の監視設定をターゲットの特定のクラスに適用することが容易になります。たとえば、ある監視テンプレートをテスト・データベース用に定義し、別の監視テンプレートを本番データベース用に定義できます。
監視テンプレートでは、ターゲットを監視するために通常設定している次のようなすべてのEnterprise Managerパラメータを定義します。
テンプレートを適用するターゲット・タイプ。
メトリック(ユーザー定義メトリックを含む)、しきい値、メトリック収集スケジュールおよび修正処理。
テンプレートを変更したら、その新しい変更を伝播するために、影響を受けるターゲット全体にテンプレートを再適用できます。適用操作は管理グループおよびテンプレート・コレクションを使用して自動化できます。どのターゲットでも、テンプレートによる上書きが不可能なメトリック設定を指定することで、カスタム監視設定を維持できます。
Enterprise Managerには多数のオラクル社認定テンプレートが用意され、様々なOracleターゲット・タイプ用の推奨メトリック設定が提供されます。
監視テンプレートの詳細は、第8章「監視テンプレートの使用」を参照してください。
監視環境は静的であることはほとんどありません。エコシステム全体から新しいターゲットが常に追加されます。Enterprise Managerではこの動的環境の制御を管理グループを通じて管理できます。管理グループは、設定またはコンプライアンス標準の監視などの管理設定の自動的な適用により、Enterprise Managerで管理するターゲットの設定プロセスを自動化します。通常、これらの設定は個別のターゲットに手動で適用されるか、監視テンプレート(第1.4.1項「監視テンプレート」)またはカスタム・スクリプトを使用して、半自動的に適用されることもあります。管理グループは、監視テンプレートを使用した監視設定の適用の利便性と自動化の力とを組み合せます。
テンプレート・コレクションには、ターゲットを管理グループに追加する際に適用する監視設定およびその他の管理設定が含まれています。ターゲットの監視設定は監視テンプレートに定義されています。監視テンプレートはターゲット・タイプごとに定義されるため、管理グループ内の異なるターゲット・タイプのそれぞれに対して監視テンプレートを作成する必要があります。おそらく、複数の監視テンプレートを作成し、管理グループに適した監視設定を定義することになります。
Enterprise Managerに追加された各ターゲットはターゲット・プロパティと呼ばれる固有の属性を処理します。Enterprise Managerはこれらのターゲット・プロパティを使用してターゲットを適切な管理グループに追加します。管理グループのメンバーシップはメンバーシップ基準としてターゲット・プロパティに基づくので、ターゲット・メンバーシップは動的です。管理グループに追加されると、Enterprise Managerにより、関連付けられたテンプレート・コレクションの一部である監視テンプレートを使用して、必要な監視設定が自動的に適用されます。
管理グループは次のターゲット・プロパティを使用してメンバーシップ基準を定義します。
連絡先
コストセンター
カスタマ・サポートID
部門
ライフサイクル・ステータス
ライン・オブ・ビジネス
場所
ターゲット・バージョン
ターゲット・タイプ
メトリックのしきい値に到達すると、メトリック固有のメッセージと一緒にアラートが生成されます。これらのメッセージは、一般的なメトリック・アラート条件に対処するように書き込まれます。Enterprise Managerリリース12.1.0.4以降では、監視対象環境固有の要件に合うようにこれらのメッセージをカスタマイズできます。
アラート・メッセージをカスタマイズして、監視のニーズに合うようにメッセージを変更できます。メッセージを変更して、データ・センターで使用されるITエラー・コードなど、環境固有の操作コンテキストを含めたり、Enterprise Managerによって収集される次の情報を追加したりすることができます。
アラートがトリガーされたメトリック名
アラートまたは違反の重大レベル
警告違反またはクリティカル違反がトリガーされたしきい値
アラートがトリガーされた後の発生数
アラート・メッセージをカスタマイズすると、メッセージが使いやすくなり、アラートの管理効率が向上します。
メトリック・アラート・メッセージをカスタマイズする手順:
ターゲットのホームページにナビゲートします。
ターゲットのメニュー(ホスト・ターゲット・タイプが図に表示される)から、「モニタリング」を選択し、「メトリックと収集設定」を選択します。
「メトリックと収集設定」ページが表示されます。
メトリック表で、変更しようとするメッセージのメトリックを探し、編集アイコン(鉛筆)をクリックします。
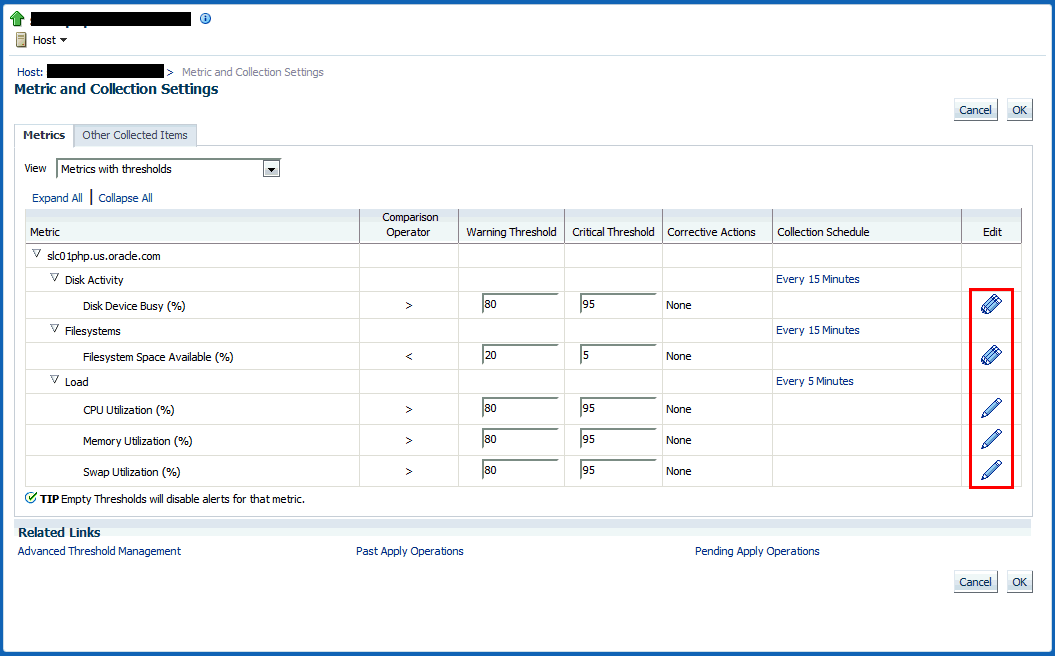
「詳細設定の編集」ページが表示されます。
「モニター対象オブジェクト」リージョンで「アラート・メッセージの編集」をクリックします。
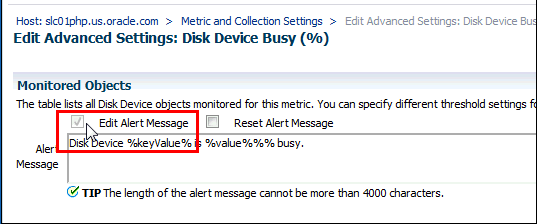
必要に応じてアラート・メッセージを変更します。
|
注意: 変更したメッセージをOracleによって定義された元のメッセージに戻すには、いつでも「アラート・メッセージのリセット」をクリックします。 |
「続行」をクリックして、「メトリックと収集設定」ページに戻ります。
さらにメトリック・アラート・メッセージを変更するには、3から6までの手順を繰り返します。
終了したら、「OK」をクリックして、すべての変更内容をEnterprise Managerリポジトリに保存します。更新が成功したことを示すメッセージがEnterprise Managerによって表示されます。
「OK」をクリックしてメッセージを閉じ、ターゲットのホームページに戻ります。
通常の監視シナリオでは、ターゲットが使用不可になるか、パフォーマンスのしきい値を超えると、イベントが発生し、適切な管理者に通知が送信されます。Enterprise Managerでは、電子メール、ページャ、SNMPトラップ、またはカスタム・スクリプトの実行による通知がサポートされ、これにより管理者は次のものを通じた通知メカニズムを制御できます。
通知メソッド
ルールとルール・セット
通知メソッド
通知メソッドは通知を送信する特定の方法を表します。電子メール以外にも、OSコマンド、PL/SQL、SNMPトラップの3種類の通知メソッドがあります。通知メソッドの構成時に、電子メールにどのSMTPゲートウェイを使用するか、どのカスタムOSスクリプトを実行するかといった、特定の通知メカニズムと関連付けられた詳細を指定する必要があります。スーパー管理者は、使用できる様々なタイプの通知メソッドの設定を1回のみ行います。
ルールでは、イベントまたはインシデント(1つの重要なイベントまたは関連イベントを含むエンティティ)が発生したときに、管理者への通知やヘルプデスク・チケットのオープンなどの、Enterprise Managerがとる特定のアクションを指示します(第1.6項「イベント、インシデントおよび問題の管理」を参照)。たとえば、ホスト・ターゲットのCPU使用率がクリティカルな重要度になったら電子メールが送信されることを指定するルールや、インシデントが24時間以内に確認できなかったら管理者のスーパーバイザに通知する別のルールを定義できます。
管理者に送信される通知は、メッセージ・タイプおよびオンコール・スケジュールに基づいてカスタマイズできます。メッセージのカスタマイズは、通知の受信手段として電子メールとページング・システムの両方を使用している管理者には便利です。これらのシステム間では、メッセージの書式は通常異なります。電子メールで送信されるメッセージは長く、URLを含む可能性があります。ページャに送信されるメッセージは短く、文字数に制限があります。これらのタイプのメカニズムをサポートするため、管理者はEnterprise Managerを使用して長いメッセージ書式および短いメッセージ書式を各電子メール・アドレスに関連付けできます。通常の電子メール送信に使用される電子メール・アドレスは、長い書式に関連付けでき、ページ送信に使用される電子メール・アドレスは、短い書式に関連付けできます。長い書式にはイベント/インシデントの詳細が完全な形で含まれ、短い書式には情報の最も重要な部分のみが含まれます。
通知は管理者のオンコール・スケジュールに基づいてもカスタマイズできます。オンコールの管理者には、業務時間中は本人のページャおよび会社の電子メール・アドレス、業務時間外には本人のページャのアドレスのみで連絡を受ける場合があります。Enterprise Managerは、多様なオンコール・スケジュールをサポートする柔軟な通知スケジュールを提供しています。管理者はこのスケジュールを使用して、オンコール時の連絡用の電子メール・アドレスを指定し、自身のオンコール・スケジュールを定義します。オンコール以外の期間、またはインシデント通知を受信しない期間については、単にスケジュールの該当部分を空白のままにします。管理者に送信されるすべてのアラートが、指定したスケジュールに従って自動的に処理されます。
Enterprise Managerの監視機能は、例外による監視の教訓に基づき構築されています。つまり、例外状況がIT環境に存在するとイベントが発生し、監視して、管理者は適時に対応できます。前述のとおり、監視に最もよく使用される2つのイベント・タイプは「メトリック・アラート」と「ターゲット可用性」です。これらはEnterprise Managerが監視する最も一般的なイベント・タイプですが、他にも多数あります。使用可能なイベント・タイプは次のとおりです。
ターゲット可用性
メトリック・アラート
メトリック評価エラー
ジョブ・ステータスの変更
コンプライアンス標準ルール違反
コンプライアンス標準スコア違反
高可用性
サービス・レベル合意のアラート
ユーザー報告
アプリケーションの依存性とパフォーマンスのアラート
JVM診断しきい値違反
定義によると、インシデントは、管理環境内で管理者の注意を必要とする問題を識別する、単一または密接に関連付けられたイベントのセットを含む1つの単位です。そのため、インシデントは、表領域内の使用可能領域が指定した制限を下回ったことを示す単一のイベントと同じくらい単純な場合もあれば、リソース不足でサーバーが実行しているときの潜在的なパフォーマンスの問題に関連する複数のイベントを含む1つのインシデントのようにもっと複雑な場合もあります。このようなイベントは、CPU、I/Oおよびメモリー・リソースに関連するイベントを含みます。インシデントによる管理では、いくつもの原因となる要素からなる可能性のある問題に対応できます。インシデントおよびイベントに関する詳細な説明は、第3章「インシデント管理の使用」を参照してください。
インシデントは1つのイベントに対応する場合もありますが、より一般的には、関連するイベントのグループに対応します。多数のイベントはすぐに管理しにくくなりますが、関連イベントの集合として処理されるインシデントにより、多数のイベント発生をより効果的に管理できます。
インシデントが作成されると、Enterprise Managerの豊富なインシデント管理ワークフロー機能群が使用できるようになり、インシデントをライフサイクル全体を通して管理および追跡できます。インシデント管理機能には次のものが含まれます。
インシデント所有権の割当て。
インシデント解決ステータスの追跡。
インシデント優先度の設定。
インシデントのエスカレーション・レベルの設定。
手動での要約を提供する機能。
ユーザー・コメントを追加する機能。
抑止および抑止解除する機能。
手動でインシデントをクリアする機能。
手動でチケットを作成する機能。
問題は、自動診断リポジトリ(ADR)に格納される診断インシデントおよび問題に関係し、そのような問題は、ソフトウェアにクリティカルなエラーが発生したときにOracleソフトウェアにより自動的に生成されます。Oracleソフトウェアに問題が発生した場合、オラクル社の推奨する問題解決の手続きは、サービス・リクエスト(SR)をオープンしてサポートに診断ログを送信してもらい、最終的にオラクル社からソリューションを提供することです。問題は、インシデントの基礎となる根本原因を表します。Enterprise Managerには、問題のライフサイクルを追跡し管理する機能が用意されています。
Enterprise Manager Cloud Controlは、インシデント管理を、インシデント・マネージャと呼ばれる直感的なUIを使用して実行します。インシデント・マネージャは使いやすいインタフェースを提供し、これにより、環境に影響を与えるインシデントおよび問題を検索、表示、管理および解決できます。インシデント・マネージャにアクセスするには、「エンタープライズ」メニューから、「監視」、「インシデント・マネージャ」の順に選択します。
インシデント・マネージャのUIから、次のことを実行できます。
カスタム・ビューの使用によるインシデント、問題およびイベントのフィルタ処理
インシデントの応答および処理
割当て、確認、ステータスの追跡、優先度付け、およびエスカレーションといったインシデントのライフサイクル管理
インシデントの解決には、My Oracle Supportのナレッジ・ベースの記事へのアクセス(コンテキスト依存)、およびその他のオラクル社のドキュメントが役立ちます。
インシデントをすばやく診断または解決するには、関連するEnterprise Manager機能へのコンテキスト依存の診断/アクション・リンクに直接アクセスします。
インシデント・ルールは、イベントまたはインシデントが発生したときに通知が送信されるタイミングや送信方法を決定する、条件とアクションを指定します。ルール内で定義された基準は、ターゲット・タイプ、イベントおよび重要度の状態(クリア、警告、クリティカル)などの属性や、ルール基準に一致するインシデントが発生したときに使用される通知メソッドに適用できます。ルール・アクションには、条件的な性質が含まれます。たとえば、ルール・アクションを定義して、インシデントの重大度がクリティカルの場合にページを表示し、警告の場合には電子メールを送信するのみにできます。
ルール・セットは、ホスト、データベース、グループ、ジョブ、メトリック拡張、または自己更新などのターゲットの共通セットに適用され、基礎となるインシデントのビジネス・プロセスを自動化する適切なアクションをとる、ルールのコレクションです。インシデント・ルール・セットは、管理者間で共有するために公開できます。たとえば、各管理者がルールに定義されたものと同じ基準で通知を受信する場合、それぞれの管理者は同じルール・セットにサブスクライブできます。または、Enterprise Managerのスーパー管理者は、ルールに定義されたとおりにインシデントの通知を受信するよう他の管理者にインシデント・ルール・セットを割り当てることができます。
通知システムによる使用(第1.5項「通知」の「ルール」参照)に加えて、第1.6.3項「コネクタ」での説明のとおり、ルール・セットにより、Enterprise Managerがインシデントの作成、インシデントの更新、またはトラブル・チケット・システムへのコールなどのその他のアクションを実行するように指示することもできます。
Oracle Management Connectorはサード・パーティの管理システムとEnterprise Managerを統合します。コネクタには、イベント・コネクタとヘルプデスク・コネクタの2つのタイプがあります。
イベント・コネクタを使用して、Enterprise ManagerをOracle以外の管理システムとイベントを共有するように構成できます。コネクタはOracle Enterprise Managerからのすべてのイベントを監視し、サード・パーティの管理システムでのアラート情報を自動的に更新します。イベント・コネクタは次の機能をサポートします。
Oracle Enterprise Managerからサード・パーティの管理システムへのイベント情報の共有。
Oracle Enterprise Managerとサード・パーティの管理システム間でのアラート・マッピングへのイベントのカスタマイズ。
Oracle Enterprise Managerでのイベント変更と、サード・パーティの管理システムでのアラートの同期化。
ヘルプデスク・コネクタを使用して、Enterprise Managerで作成されたイベントのチケットを作成、更新またはクローズするようにEnterprise Managerを構成できます。コネクタにより生成されたチケットには、Enterprise Managerインシデントに関連する情報が含まれ、これにはヘルプデスク・アナリストがインシデントを解決するためのEnterprise Managerの診断および解決機能を利用できる、Enterprise Managerコンソールへのリンクが含まれています。Enterprise Mangerでは、チケットID、チケット・ステータス、およびサード・パーティのチケッティング・システムへのリンクが、インシデントのコンテキストに表示されます。これによりEnterprise Manager管理者にはチケット・ステータス情報と、チケットにすばやくアクセスする簡単な方法が提供されます。
使用可能なコネクタは次のとおりです。
BMC Remedy Service Deskコネクタ
HP Service Managerコネクタ
CA Service Deskコネクタ
HP Operations Managerコネクタ
Microsoft Systems Center Operations Managerコネクタ
IBM Tivoli Enterprise Consoleコネクタ
IBM Tivoli Netcool/OMNIbusコネクタ
Oracle組込みコネクタの詳細は、Enterprise Manager Plug-ins Exchangeを参照してください。
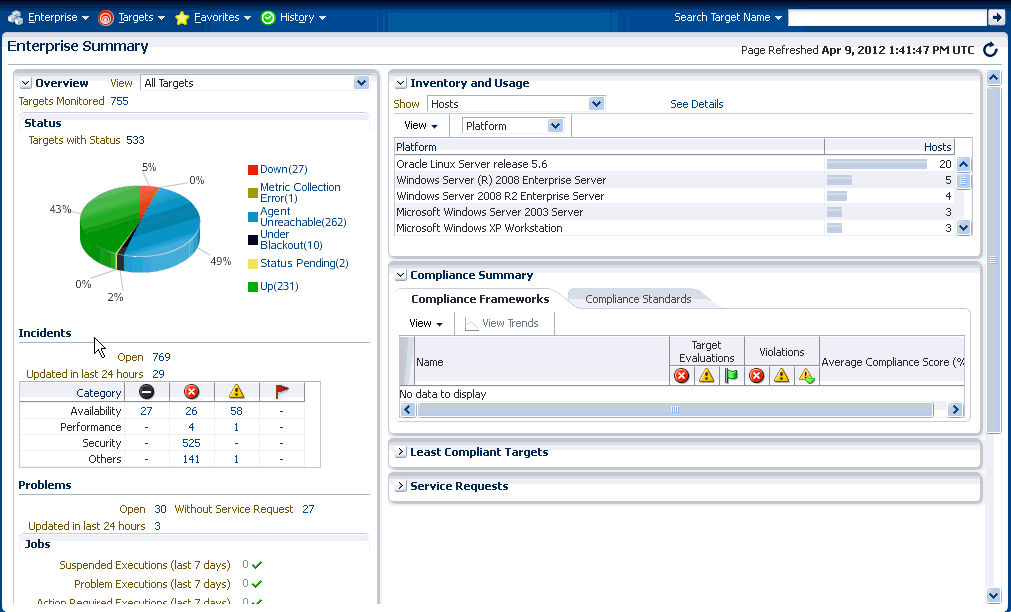
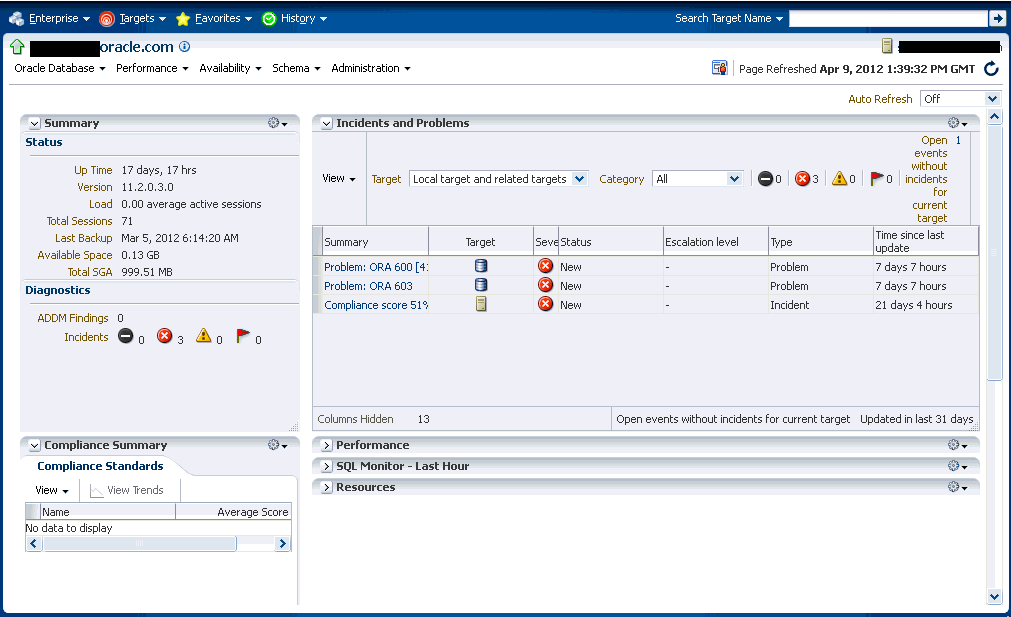
Enterprise Managerでは監視情報にアクセスするための複数の方法を用意しています。インシデント管理の主な焦点は、インシデント・マネージャ・コンソールですが、Enterprise Managerにも、監視情報にアクセスするための別の方法が用意されています。次の図に、Enterprise Manager内でターゲット監視情報を表示する様々な場所を示します。次の図に、ターゲット・ステータスのロールアップとインシデントのロールアップを便利に表示するEnterprise Managerの概要ページを示します。
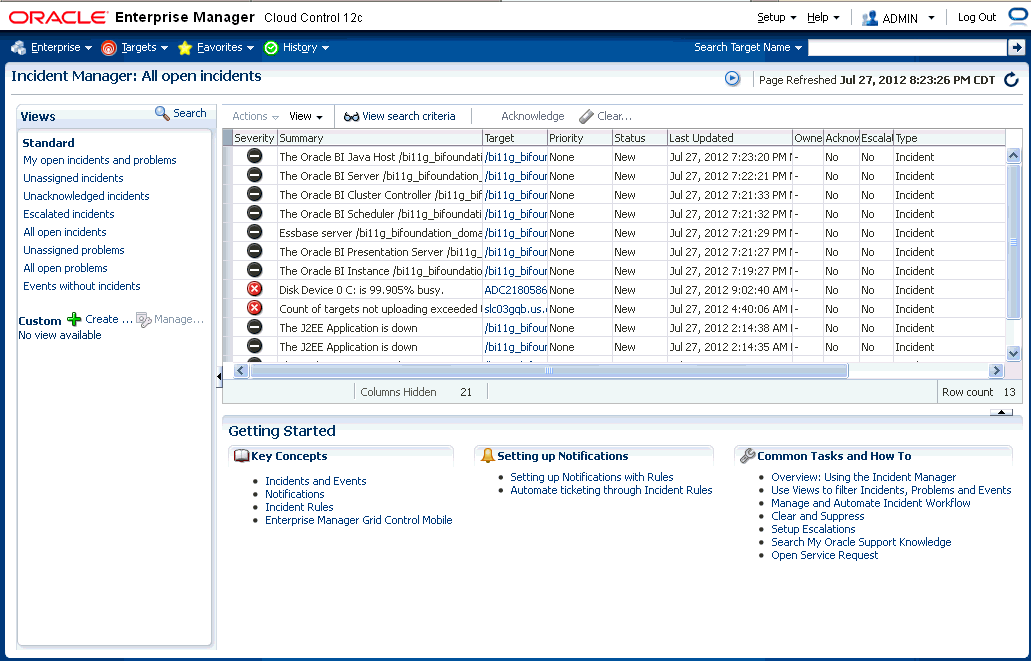
次の図に、システムまたはターゲットのインシデントを表示するインシデント・マネージャのホームページを示します。
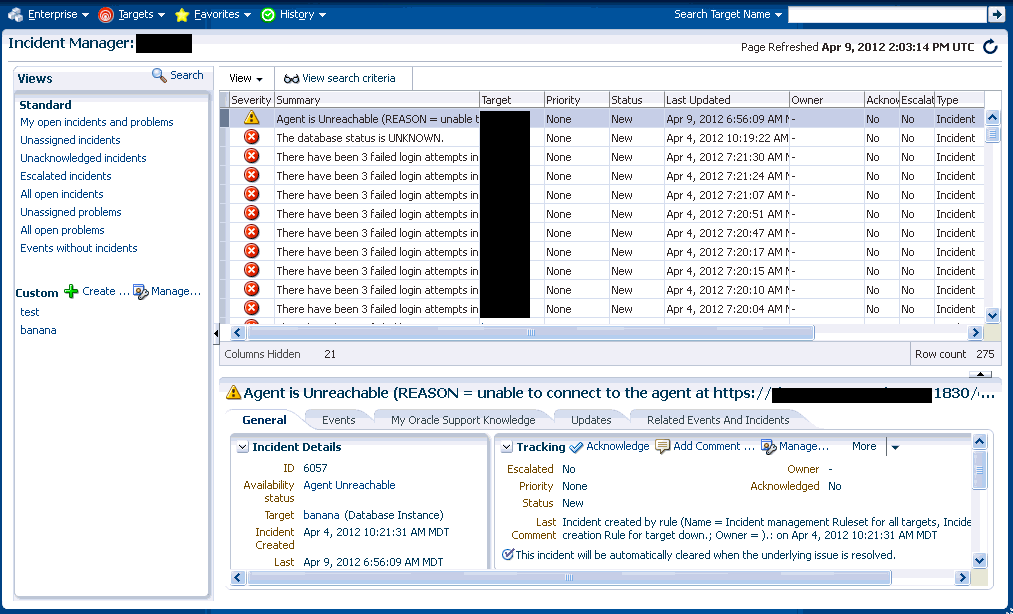
監視情報はターゲットのホームページにも表示されます。次の図で、ターゲット・ステータスとインシデントのロールアップを確認できます。