| Oracle® Enterprise Manager Cloud Controlアドバンスト・インストレーションおよび構成ガイド 12cリリース4 (12.1.0.4) B65085-14 |
|


 前 |
 次 |
| Oracle® Enterprise Manager Cloud Controlアドバンスト・インストレーションおよび構成ガイド 12cリリース4 (12.1.0.4) B65085-14 |
|
前 |
次 |
この章で説明する高可用性ソリューションは、通常、コンポーネントの障害やシステムレベルの問題などからEnterprise Managerを保護しますが、自然災害、火災、停電、排気、広範囲の妨害行為によるデータ・センターの壊滅的な障害などの大規模な故障からEnterprise Managerを保護することも必要です。
Enterprise Managerの最大可用性アーキテクチャには、プライマリ管理インフラストラクチャが災害による被害を受けた場合、セカンダリ・データ・センターが管理インフラストラクチャを引き継ぐことができるリモート・フェイルオーバー・アーキテクチャのデプロイが含まれます。
|
注意: OMS障害時リカバリはEnterprise Managerのバージョンによって異なります。Cloud Control 12.1.0.2以前 - スタンバイWebLogicドメインを使用するスタンバイOMSを使用する必要があります。詳細は、付録I「スタンバイWebLogicドメインを使用するスタンバイOMS」を参照してください Cloud Control 12.1.0.3以降 - この章で説明する、記憶域レプリケーションを使用するスタンバイOMSの使用をお薦めします。 BI Publisherサーバーの構成は、Cloud Control 12.1.0.4以降のリリースに対応するスタンバイWeblogicドメインを使用するスタンバイOMSではサポートされていません。 |
記憶域レプリケーションを使用するスタンバイOMSの利点は、次のとおりです。
OMSパッチおよびアップグレードは1つのサイトで実行するだけで済みます。
プラグインは1つのサイトで管理するだけで済みます。
この章の内容は次のとおりです。
Cloud Controlデプロイメントに対する障害時リカバリ・ソリューションには、OMS、ソフトウェア・ライブラリおよびリポジトリのコンポーネントのスタンバイ・サイトへのレプリケーションが含まれます。このソリューションは、前の章で説明した高可用性ソリューションと組み合せて、Cloud Controlの可用性の中断を最小限に抑えながら、コンポーネントの障害からサイト全体の停止までの多岐にわたる障害を確実にリカバリできるようにします。
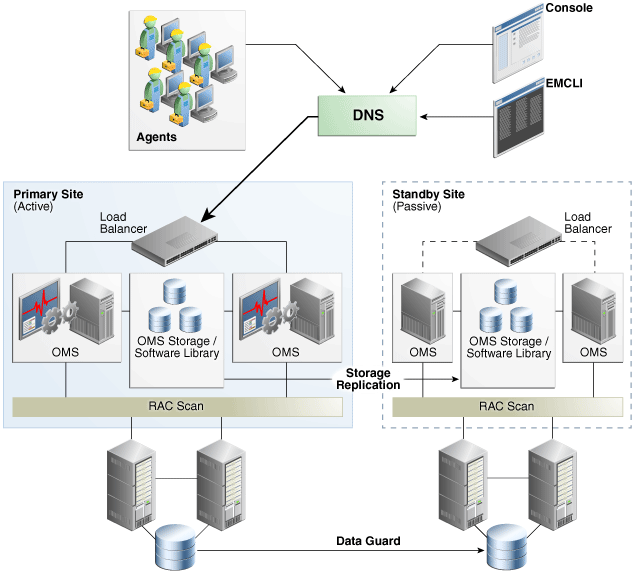
前の章で説明した高可用性設計と、この章で説明する障害時リカバリ・ソリューションとを組み合せた、Enterprise Manager Cloud Controlの完全な実装を次の図に示します。
図に示されたDRソリューションの重要な部分は次のとおりです。
このソリューションにはサイトが2つあります。プライマリ・サイトは稼働中かつアクティブであり、スタンバイ・サイトはパッシブ・モードになっています。
Enterprise Managerのユーザーおよびエージェントからのトラフィックは、グローバル・ロード・バランサまたはプライマリ・サイトでホストされるIPアドレスに解決するDNSエントリによって、プライマリ・サイトに送られます。
スタンバイ・サイトは、フェイルオーバーの発生時にパフォーマンスが損なわれないように、ハードウェアとネットワークのリソースの点でプライマリ・サイトと同様です。
スタンバイ・サイトでは、OMSのインストールを実行する必要はありません。Oracleインベントリ、OMSソフトウェア、エージェントおよびソフトウェア・ライブラリはすべてレプリケートされた記憶域にあります。本番サイトの記憶域がスタンバイ・サイトにレプリケートされると、同等のデータがスタンバイ・サイトに書き込まれます。
OMSホスト名は、プライマリ・サイトからの問合せではプライマリOMSのIPアドレスに、セカンダリ・サイトからの問合せでは対応するスタンバイ・ホストのIPアドレスに解決できる必要があります。
OMSソフトウェア、Oracleインベントリ、ソフトウェア・ライブラリ、およびすべてのOMSに対するエージェント・バイナリと構成ファイルが、レプリケートされた記憶域にあります。
各サイトのOMSホストは、同じマウント・ポイントを使用してレプリケートされた記憶域にアクセスします。
サイト間のレプリケーションは、スケジュールした一定の間隔で実施し、構成の変更後にも実施する必要があります。
Oracle Data Guard物理スタンバイを使用して、スタンバイ・サイトのリポジトリ・データベースをレプリケートします。
最大量のREDOデータの生成を処理するために、プライマリ・サイトとスタンバイ・サイト間に十分なネットワーク・バンド幅が必要です。
プライマリ・サイトに障害または計画された停止が発生した場合には、次の手順を実行して、トポロジ内でスタンバイ・サイトがプライマリのロールを引き継げるようにします。
プライマリ・サイトのOMSを停止します
記憶域のオンデマンド・レプリケーションを実行します(プライマリ・サイトを使用できる場合)
データベースをスタンバイ・サイトにフェイルオーバー/スイッチオーバーします
記憶域レプリケーションを逆にして、スタンバイ・サイトでのレプリケートされた記憶域の読取り/書込みをアクティブ化します
スタンバイ・サイトでOMSを起動します
DNSまたはグローバル・ロード・バランサを更新して、ユーザー・リクエストをスタンバイ・サイトに再ルーティングします。この時点では、スタンバイ・サイトが本番のロールを引き継いでいます。
この項では、エンタープライズ・デプロイメントにおけるCloud Control障害時リカバリ・ソリューションに関する設計上の考慮事項について説明します。
この章では、次の項目について説明します。
次の各項では、記憶域レプリケーションを使用してスタンバイ管理サービスを実装するときに考慮する必要があるネットワークに関する事項について説明します。
障害時リカバリ・トポロジでは、本番サイトのホスト名がスタンバイ・サイトの対応するピア・システムのIPアドレスに解決可能である必要があります。そのため、本番サイトとスタンバイ・サイトのホスト名を計画することが重要です。プライマリ・サイトからスタンバイ・サイトへのスイッチオーバーまたはフェイルオーバーの後、スタンバイ・サイトのホストのホスト名を変更しなくても、スタンバイ・ホストでアプリケーションを起動できる必要があります。
これは次のどちらかの方法で実施できます。
オプション1: プライマリ・サイトでの物理ホスト名とスタンバイ・サイトでの別名: プライマリ・サイトのOMSは物理ホスト名を使用して構成され、これらのホスト名の別名はスタンバイ・サイトの対応するホストで構成されます。
オプション2: 両方のサイトでの別名ホスト名: プライマリ・サイトのOMSは、プライマリおよびスタンバイの両方のサイトで構成できる別名ホスト名を使用して構成されます。
これらのオプションの選択は、ネットワーク・インフラストラクチャおよびコーポレート・ポリシーに依存します。設定プロシージャの観点から、物理ホスト名を使用する既存の単一サイトのCloud Controlインストールがある場合、DRの設定に既存サイトの変換を必要としないため、オプション1の方が実装が容易です。新しいCloud Controlインストールを設定中であり、別名ホスト名で起動する場合、または別名ホスト名を使用する既存のCloud Controlインストールがある場合は、オプション2の方が実装が容易になります。
|
注意: オプション2を使用する場合、インストーラの起動時にホスト名の別名としてORACLE_HOSTNAMEを設定する必要があります。次に例を示します。
Enterprise ManagerのrunInstaller UIからこの情報を求められた場合、ORACLE_HOSTNAMEを指定することもできます。 |
各サイトでのホスト名解決は、ローカル解決(/etc/hosts)またはDNSベースの解決、あるいは両方の組合せのいずれかを使用して行うことができます。次の例は、これらの物理ホスト名およびIPアドレスを使用しています。
HOSTNAME IP ADDRESS DESCRIPTION oms1-p.example.com 123.1.2.111 Physical host for OMS1 on Primary site oms2-p.example.com 123.1.2.112 Physical host for OMS2 on Primary site oms1-s.example.com 123.2.2.111 Physical host for OMS1 on Standby site oms2-s.example.com 123.2.2.112 Physical host for OMS2 on Standby site
|
注意: オプション1またはオプション2でローカル解決を使用する場合は、次の例に示すように、サイトの各OMS上の/etc/hostsファイルに、そのサイトのすべてのOMSの物理ホスト名と別名ホスト名が含まれることを確認します(別名ホスト名が使用されるサイトの場合)。 |
オプション1の例: OMSが、プライマリ・サイト物理ホスト名(oms1-p.example.comおよびoms2-p.example.com)を使用してプライマリ・サイトにインストールされる場合の/etc/hostsの構成:
Primary Site 127.0.0.1 localhost.localdomain localhost 123.1.2.111 oms1-p.example.com oms1-p #OMS1 123.1.2.112 oms2-p.example.com oms2-p #OMS2 Standby Site 127.0.0.1 localhost.localdomain localhost 123.2.2.111 oms1-s.example.com oms1-s oms1-p.example.com #OMS1 123.2.2.112 oms2-s.example.com oms2-s oms2-p.example.com #OMS2
ネットワークが正しく構成されている場合、プライマリ・サイトからOMSホスト名をpingすると、プライマリ・ホストから応答がある必要があり、スタンバイ・サイトからOMSホスト名をpingすると、スタンバイ・ホストから応答がある必要があります。
プライマリ・サイトからのPing結果(プライマリ・サイトから応答):
[oracle@oms1-p ~]$ ping oms1-p.example.com PING oms1-p.example.com (123.1.2.111) 56(84) bytes of data. 64 bytes from oms1-p.example.com (123.1.2.111): icmp_seq=1 ttl=64 time=0.018 ms 64 bytes from oms1-p.example.com (123.1.2.111): icmp_seq=2 ttl=64 time=0.020 ms 64 bytes from oms1-p.example.com (123.1.2.111): icmp_seq=3 ttl=64 time=0.022 ms
スタンバイ・サイトからのPing結果(スタンバイ・サイトから応答)
[oracle@oms1-s ~]$ ping oms1-p.example.com PING oms1-s.example.com (123.2.2.111) 56(84) bytes of data. 64 bytes from oms1-s.example.com (123.2.2.111): icmp_seq=1 ttl=64 time=0.018 ms 64 bytes from oms1-s.example.com (123.2.2.111): icmp_seq=2 ttl=64 time=0.020 ms 64 bytes from oms1-s.example.com (123.2.2.111): icmp_seq=3 ttl=64 time=0.022 ms
オプション2の例: OMSが、別名ホスト名(oms1.example.comおよびoms2.example.com)を使用してインストールされる場合の/etc/hostsの構成:
Primary Site 127.0.0.1 localhost.localdomain localhost 123.1.2.111 oms1-p.example.com oms1-p oms1.example.com #OMS1 123.1.2.112 oms2-p.example.com oms2-p oms2.example.com #OMS2 Standby Site 127.0.0.1 localhost.localdomain localhost 123.2.2.111 oms1-s.example.com oms1-s oms1.example.com #OMS1 123.2.2.112 oms2-s.example.com oms2-s oms2.example.com #OMS2
ネットワークが正しく構成されている場合、プライマリ・サイトからOMSホスト名をpingすると、プライマリ・ホストから応答がある必要があり、スタンバイ・サイトからOMSホスト名をpingすると、スタンバイ・ホストから応答がある必要があります。
例:
プライマリ・サイトからのPing結果(プライマリ・サイトから応答):
[oracle@oms1-p ~]$ ping oms1.example.com PING oms1-p.example.com (123.1.2.111) 56(84) bytes of data. 64 bytes from oms1-p.example.com (123.1.2.111): icmp_seq=1 ttl=64 time=0.018 ms 64 bytes from oms1-p.example.com (123.1.2.111): icmp_seq=2 ttl=64 time=0.020 ms 64 bytes from oms1-p.example.com (123.1.2.111): icmp_seq=3 ttl=64 time=0.022 ms
スタンバイ・サイトからのPing結果(スタンバイ・サイトから応答)
[oracle@oms1-s ~]$ ping oms1.example.com PING oms1-s.example.com (123.2.2.111) 56(84) bytes of data. 64 bytes from oms1-s.example.com (123.2.2.111): icmp_seq=1 ttl=64 time=0.018 ms 64 bytes from oms1-s.example.com (123.2.2.111): icmp_seq=2 ttl=64 time=0.020 ms 64 bytes from oms1-s.example.com (123.2.2.111): icmp_seq=3 ttl=64 time=0.022 ms
各サイトに複数のOMSがある場合、プライマリおよびスタンバイの両方のサイトに自身のサーバー・ロード・バランサが必要です。「ロード・バランサの構成」を参照してください。各サイト上のSLBプールは、それぞれのOMSホストのIPアドレスを参照します。
Cloud Controlクライアント(エージェントおよびユーザー)がCloud Controlにアクセスするためのホスト名が必要です。プライマリ・サイトがアクティブなとき、このホスト名は、プライマリ・サイトSLBによってホストされるIPアドレスに解決されるようにDNSで構成する必要があります。スタンバイ・サイトがアクティブ化されているとき、ホスト名がスタンバイ・サイトSLBによってホストされるIPアドレスに解決されるように、DNSエントリを更新する必要があります。
各サイトで複数のOMSとSLBを使用する場合の、Cloud Controlアプリケーション・ホスト名のDNS構成の例を次の表に示します。
表18-1 DNS構成
| DNS名 | DNSレコード・タイプ | VALUE | コメント |
|---|---|---|---|
|
em.example.com |
CNAME |
slb_primary.example.com |
Cloud Controlクライアントが管理サービスと通信するために使用する仮想ホスト名。現在アクティブなサイトを指す必要があります |
|
slb_primary.example.com |
A |
123.1.2.110 |
プライマリ・サイトのSLBアドレス |
|
slb_standby.example.com |
A |
123.2.2.110 |
スタンバイ・サイトのSLBアドレス |
DNSスイッチオーバーを実行するには、グローバル・ロード・バランサを使用するか、DNS名を手動で変更します。
グローバル・ロード・バランサは、信頼できるDNSネーム・サーバーと同等の機能を提供できます。グローバル・ロード・バランサを使用する利点の1つは、名前とIPの新しいマッピングがほとんど即時に有効になる点です。マイナス面は、グローバル・ロード・バランサに対する追加投資が必要な点です
DNS名の手動変更。Cloud ControlクライアントによってキャッシュされるDNSレコードが、更新の後すぐに更新されるようにするため、em.example.comのCNAMEのTTLを60秒などの低い値に設定することをお薦めします。このようにすると、DNSの変更がすべてのクライアントにただちに伝播されるようになります。ただし、キャッシュ時間が短くなるため、DNSリクエストが増加する可能性があります。
Cloud Controlデプロイメントに対する障害時リカバリ・ソリューションには、レプリケートされた記憶域でのソフトウェア・ライブラリ、OMSインストール、エージェント・インストールおよびOracleインベントリのインストールが含まれます。
記憶域レプリケーションの要件
選択した記憶域レプリケーションの方法で、次がサポートされている必要があります。
スナップショットおよび一貫性のあるファイルシステム・コピー
サイト間でのスケジュール済レプリケーションおよびオンデマンド・レプリケーションを実行する機能
次の項では、お薦めする記憶域構造について詳しく説明します。
OMSホストごとに1つのボリュームを作成します。
同じマウント・ポイント(例: /u01/app/oracle/OMS)を使用して、前述のボリュームを各OMSホストにマウントします。各ホストで、このボリュームはOMSインストール、エージェント・インストールおよびOracleインベントリを含みます。
前述のボリュームに対して整合性グループを作成し、すべてのボリュームに対して一貫性のあるレプリケーションを実行できるようにします。
ソフトウェア・ライブラリに対して1つのボリュームを作成します。このボリュームは、同じマウント・ポイントを使用してすべてのOMSホストに同時にマウントされる必要があります。たとえば、/swlibなどです。
BIPに1つのボリュームを作成します。このボリュームは、同じマウント・ポイントを使用してすべてのOMSホストに同時にマウントされる必要があります。たとえば、/bipなどです。
インフラストラクチャに基づいて、OMSファイルシステム、ソフトウェア・ライブラリおよびBIPに適切なレプリケーション頻度を決定します。OMSファイルシステムには24時間の最小頻度、ソフトウェア・ライブラリには連続または毎時レプリケーションをお薦めします。
これらのボリュームがマウントされた後で、マウントされたディレクトリがOracleソフトウェア所有者ユーザー(通常、oracle)およびOracleインベントリ・グループ(通常、oinstall)によって所有されていることと、Oracleソフトウェア所有者ユーザーに、マウントされたディレクトリへの読取りおよび書込みアクセス権があることを確認してください。
例: 次の表に構成例を示します。
表18-2 記憶域構成
| ボリューム | マウントされるホスト | マウント・ポイント | コメント |
|---|---|---|---|
|
VOLOMS1 |
oms1-p.example.com |
/u01/app/oracle/OMS |
プライマリ・サイトOMS1上のEnterprise Managerのインストール |
|
VOLOMS2 |
oms2-p.example.com |
/u01/app/oracle/OMS |
プライマリ・サイトOMS2上のEnterprise Managerのインストール |
|
VOLSWLIB |
oms1-p.example.comおよびoms2-p.example.com |
/swlib |
プライマリ・サイトOMS1およびOMS2上のソフトウェア・ライブラリ |
|
VOLBIP |
oms1-p.example.comおよびoms2-p.example.com |
/bip |
プライマリ・サイトOMS1およびOMS2のBIP共有記憶域(BIPが構成されている場合) |
この項では、障害時リカバリに対するリポジトリ・データベースの設定に関する推奨事項と考慮事項を説明します。
本番サイトとスタンバイ・サイトの両方にReal Application Clusterデータベースを作成することをお薦めします。
使用するOracle Data Guard構成は、データベースのデータ損失要件に加えて、REDO生成と比較した場合の使用可能な帯域幅や待機時間など、ネットワークに関する考慮事項に基づいて決定する必要があります。Oracle Data Guard構成を設定する前に、これが正しく特定されていることを確認してください。
ブローカ操作時にインスタンスを再起動するようにData Guardを有効にするには、特定の名前のサービスを、各インスタンスのローカル・リスナーに静的に登録する必要があります。
リポジトリ・データベースのスイッチオーバーおよびフェイルオーバーの操作に対してdgmgrlを最大限に効率的に使用できるようにするには、すべてのプライマリ・リポジトリ・データベースおよびスタンバイ・リポジトリ・データベースのTNS別名を、tnsnames.ora内の各データベース・インスタンスのORACLE_HOMEの下に追加する必要があります。
中間層の同期が実行された場合は必ず、Data Guardでデータベースの手動同期を強制的に実行することを強くお薦めします。これは特に、メタデータ・リポジトリに構成データを格納するコンポーネントに該当します。
18.2.3.1項「11gリリース2よりも前のOracle Databaseに関する考慮事項」および18.2.3.2項「11gリリース2以降のOracle Databaseに関する考慮事項」で説明されている推奨事項に基づいて接続記述子を選択した後、プライマリ・サイトで各OMSに対して次のコマンドを実行して、接続記述子を構成します。
emctl config oms -store_repos_details -repos_conndesc <connect descriptor> -repos_user <username>
次の使用例は、18.2.3.2項に記載されている接続記述子の推奨事項に従ったものです。
emctl config oms -store_repos_details -repos_conndesc "(DESCRIPTION_LIST=(LOAD_BALANCE=off)(FAILOVER=on)(DESCRIPTION=(CONNECT_TIMEOUT=5)(TRANSPORT_CONNECT_TIMEOUT=3)(RETRY_COUNT=3)(ADDRESS_LIST=(LOAD_BALANCE=on)(ADDRESS=(PROTOCOL=TCP)(HOST=primary_cluster_scan.example.com)(PORT=1521)))(CONNECT_DATA=(SERVICE_NAME=haemrep.example.com)))(DESCRIPTION=(CONNECT_TIMEOUT=5)(TRANSPORT_CONNECT_TIMEOUT=3)(RETRY_COUNT=3)(ADDRESS_LIST=(LOAD_BALANCE=on)(ADDRESS=(PROTOCOL=TCP)(HOST=standby_cluster_scan.example.com)(PORT=1521)))(CONNECT_DATA=(SERVICE_NAME=haemrep.example.com))))" -repos_user SYSMAN
本番サイトとスタンバイ・サイトの両方でデータベース・ホスト名の別名を設定することを強くお薦めします。これによって、シームレスなスイッチオーバー、スイッチバックおよびフェイルオーバーが実現します。次に例を示します。
| サイト | リポジトリ・ホスト名 | リポジトリ接続文字列 |
|---|---|---|
| プライマリ | repos1-p.example.com | (DESCRIPTION=(ADDRESS_LIST=(FAILOVER=ON)(ADDRESS=(PROTOCOL=TCP)(HOST=repos1-p.example.com)(PORT=1521))(ADDRESS=(PROTOCOL=TCP)(HOST=repos2-p.example.com)(PORT=1521)))(CONNECT_DATA=(SERVICE_NAME=EMREP))) |
| repos2-p.example.com | ||
| スタンバイ | repos1-s.example.com | (DESCRIPTION=(ADDRESS_LIST=(FAILOVER=ON)(ADDRESS=(PROTOCOL=TCP)(HOST=repos1-s.example.com)(PORT=1521))(ADDRESS=(PROTOCOL=TCP)(HOST=repos2-s.example.com)(PORT=1521)))(CONNECT_DATA=(SERVICE_NAME=EMREP))) |
| repos2-s.example.com |
前述の例では、フェイルオーバーまたはスイッチオーバー操作の後、スタンバイ・サイト上のOMSはスタンバイ・リポジトリ接続文字列を使用するように切り替えられる必要があります。オプションでリポジトリ・データベース・ホストのホスト名別名を設定することにより、接続文字列の変更を回避できます。次に例を示します。
| サイト | リポジトリ・ホスト名 | ホスト名別名 |
|---|---|---|
| プライマリ | repos1-p.example.com | repos1.example.com |
| repos2-p.example.com | repos2.example.com | |
| スタンバイ | repos1-s.example.com | repos1.example.com |
| repos2-s.example.com | repos2.example.com |
フェイルオーバーまたはスイッチオーバー中の変更の必要を少なくするため、このようにサイトの接続文字列を同じにすることができます。
(DESCRIPTION=(ADDRESS_LIST=(FAILOVER=ON)(ADDRESS=(PROTOCOL=TCP)(HOST=repos1.example.com)(PORT=1521))(ADDRESS=(PROTOCOL=TCP)(HOST=repos2.example.com)(PORT=1521)))(CONNECT_DATA=(SERVICE_NAME=EMREP)))
Oracle Database 11gリリース2では、Single Client Access Name (SCAN)アドレスおよびロールベース・データベース・サービスという2つのテクノロジが導入されています。これらによって、障害時リカバリ用のリポジトリ・データベースに関して接続文字列の管理が大幅に簡易化されます。
SCANアドレスによってRACクラスタの単一アドレスが提供され、接続文字列に複数のVIPアドレスを指定する必要がなくなります。SCANアドレスの詳細は、『Oracle Clusterware管理およびデプロイメント・ガイド』を参照する必要があります。
ロールベース・データベース・サービスにより、データベースのロールに基づいてRACクラスタで実行するデータベース・サービスを作成できるようになります。管理者がデータベース・トリガーを作成および保守して、データベース・サービスを管理する必要はありません。ロールベース・データベース・サービスでは、Oracle Clusterwareが、指定のロール(プライマリまたはスタンバイ)に基づいてデータベース・サービスを自動的に起動および停止します。ロールベース・データベース・サービスの詳細は、『Oracle Real Application Clusters管理およびデプロイメント・ガイド』および『高可用性Oracle Databaseでのクライアント・フェイルオーバーのベスト・プラクティス: Oracle Database 12c』テクニカル・ホワイトペーパーを参照してください。
これら2つのテクノロジを組み合せることで、プライマリ・データベースに対する1つのエントリとスタンバイ・データベースに対する1つのエントリを含む、リポジトリ接続文字列を作成できます。この接続文字列はプライマリ・サイトとスタンバイ・サイトの両方から使用できるため、スイッチオーバーまたはフェイルオーバー操作時に接続文字列を手動で変更する必要がなくなります。
レベル4のMAA構成で、リポジトリへの接続で使用するロールベース・データベース・サービスを作成するには、次のようなコマンドを実行して、プライマリ・クラスタとスタンバイ・クラスタの両方にデータベース・サービスを作成します。
プライマリ・クラスタ:
srvctl add service -d emrepa -s haemrep.example.com -l PRIMARY -r emrepa1,emrepa2
スタンバイ・クラスタ:
srvctl add service -d emreps -s haemrep.example.com -l PRIMARY -r emreps1,emreps2
最初にプライマリ・クラスタのノードで次の操作を実行して、サービスを開始します。
srvctl start service -d emrepa -s haemrep.example.com
これでロールベース・データベース・サービスがアクティブになり、アクティブなデータベースをホストするいずれかのクラスタで稼働します。
Oracle Database 11.2、Data GuardおよびRACを使用する環境では、次のような接続文字列の使用をお薦めします。各クラスタのSCANアドレスの名前とロールベース・データベース・サービス名を、ご使用の環境の該当する値で置き換えてください。
(DESCRIPTION_LIST=(LOAD_BALANCE=off)(FAILOVER=on)(DESCRIPTION=(CONNECT_TIMEOUT=5)(TRANSPORT_CONNECT_TIMEOUT=3)(RETRY_COUNT=3)(ADDRESS_LIST=(LOAD_BALANCE=on)(ADDRESS=(PROTOCOL=TCP)(HOST=primary-cluster-scan.example.com)(PORT=1521)))(CONNECT_DATA=(SERVICE_NAME=haemrep.example.com)))(DESCRIPTION=(CONNECT_TIMEOUT=5)(TRANSPORT_CONNECT_TIMEOUT=3)(RETRY_COUNT=3)(ADDRESS_LIST=(LOAD_BALANCE=on)(ADDRESS=(PROTOCOL=TCP)(HOST=standby-cluster-scan.example.com)(PORT=1521)))(CONNECT_DATA=(SERVICE_NAME=haemrep.example.com))))
スタンバイ・サイトを設定する前に、管理者はプロジェクトの開始ポイントを評価する必要があります。通常、Enterprise Manager Cloud Control障害時リカバリ・トポロジを設計する際の開始ポイントは次のいずれかです。
プライマリ・サイトがすでに作成されており、スタンバイ・サイトが計画中です
プライマリ・サイトがすでに作成されており、スタンバイ・サイトが非推奨の"スタンバイWLSドメイン"メソッドを使用してすでに作成されています
インストールが存在せず、プライマリおよびスタンバイの両方のサイトが計画中です
開始ポイントが既存のプライマリ・サイトである場合、プライマリ・サイトのOMSインストールがファイルシステムにすでに存在します。また、ホスト名、ポートおよびユーザー・アカウントもすでに定義されています。サイトを変換し障害時リカバリ・トポロジ用に準備するために、次のプロシージャを使用する必要があります。
ネットワークに関する考慮事項を確認し、ホスト名を計画します
オプション1を使用する場合、プライマリ・サイトでのホスト名変更は必要ありません。適切な別名ホスト名を追加することによって、スタンバイ・サイト・ホストを準備します。
オプション2を使用する場合、OMSホスト名を変更して、既存のOMSインストールを移動し別名ホスト名を使用するようにします。適切な別名ホスト名を追加することによって、スタンバイ・サイト・ホストを準備します。
記憶域に関する考慮事項を確認し、OMSインストールを共有記憶域に移動します
プライマリ・サイトを共有記憶域に移行します。「共有記憶域への既存のサイトの移行」を参照してください。
データベースに関する考慮事項を確認し、リポジトリ・ホスト名および接続記述子を計画します
シームレスなフェイルオーバー/スイッチオーバーを実現するために、リポジトリ・データベースのホスト名別名を使用するかどうか考えてください。その場合、リポジトリ・データベースを移行して別名ホスト名を使用します。
プライマリ・サイトの準備ができたので、「管理リポジトリの障害時リカバリの設定」および「OMS、BI Publisher共有記憶域およびソフトウェア・ライブラリの障害時リカバリの設定」のプロシージャを使用してDR設定を完了します。
スタンバイOMSの削除プロシージャを使用して、スタンバイOMSを削除します。『Oracle Enterprise Managerアドバンスト・インストレーションおよび構成ガイド』の追加のスタンバイOMSインスタンスの削除に関する説明を参照してください。
「プライマリ・サイトがすでに作成されており、スタンバイ・サイトが計画中です」に記載されているプロシージャを使用します。
新しいプライマリ・サイトを(既存のプライマリ・サイトは使用せずに)設計している場合、ソフトウェアのインストールを開始する前にサイト計画を実行できるため容易です。
ネットワークに関する考慮事項を確認し、ホスト名を計画します。
記憶域に関する考慮事項を確認し、記憶域ボリュームを準備します。
データベースに関する考慮事項を確認し、リポジトリ・ホスト名を準備します。
第17章「Enterprise Managerの高可用性」に記載されている手順を使用して、正しいホスト名を使用して共有記憶域にインストールすることに注意して、プライマリ・サイトのインストールを実行します。
プライマリ・サイトの準備ができたので、次の項のプロシージャを使用してDR設定を完了します。
管理リポジトリでは、障害時リカバリ・ソリューションとしてData Guardを使用する必要があります。
次に、スタンバイ管理リポジトリ・データベースを設定する手順を説明します。
Data Guard用のスタンバイ管理リポジトリ・ホストを準備します。
スタンバイ管理リポジトリの各ホストに管理エージェントをインストールします。プライマリ・サイトのSLBでアップロードするように管理エージェントを構成します。スタンバイ管理リポジトリ・ホストに、グリッド・インフラストラクチャおよびRACデータベース・ソフトウェアをインストールします。プライマリ・サイトと同じバージョンを使用してください。
Data Guard用のプライマリ管理リポジトリ・データベースを準備します。
プライマリ管理リポジトリ・データベースがまだ構成されていない場合、アーカイブ・ログ・モードを有効にして、フラッシュ・リカバリ領域を設定し、プライマリ管理リポジトリ・データベースのフラッシュバック・データベースを有効にします。
|
注意: アップグレード中にスタンバイ・データベースの破損を防ぐためにデータベースがFORCE LOGGINGモードになっていることを確認してください。プライマリ管理リポジトリ・データベースがFORCE LOGGINGモードである場合、一時表領域および一時セグメントに対する変更を除くすべてのデータベース変更が記録されます。FORCE LOGGINGモードは、スタンバイ・データベースがプライマリ管理リポジトリ・データベースと一貫性を維持することを保証します。 |
物理スタンバイ・データベースを作成します。
Enterprise Managerコンソールを使用して、スタンバイ環境で物理スタンバイ・データベースを設定します。スタンバイ管理リポジトリ・データベースは物理スタンバイにします。ロジカル・スタンバイ管理リポジトリ・データベースはサポートされません。
Enterprise Managerコンソールでは、スタンバイRACデータベースの作成はサポートされていません。スタンバイ・データベースをRACにする必要がある場合、単一インスタンスを使用してスタンバイ・データベースを構成し、Enterprise Managerコンソールの「RACデータベースへの変換」オプションを使用して、単一インスタンスのスタンバイ・データベースをRACに変換します。「RACデータベースへの変換」オプションは、Oracle Databaseリリース10.2.0.5、11.1.0.7以上で使用できます。Oracle Databaseリリース11.1.0.7でRACへの変換オプションが機能するにはパッチ8824966が必要です。単一インスタンスのスタンバイ作成中、後でRACへの変換が容易になるようにデータベース・ファイルを共有記憶域(理想的にはASM)に作成しておくことがベスト・プラクティスです。
リスナーに静的サービスを追加します。
ブローカ操作時にインスタンスを再起動するようにData Guardを有効にするには、特定の名前のサービスを、各インスタンスのローカル・リスナーに静的に登録する必要があります。GLOBAL_DBNAME属性の値は、連結文字列<db_unique_name>_DGMGRL.<db_domain>に設定してください。たとえば、LISTENER.ORAファイルでは次のようになります。
SID_LIST_LISTENER=(SID_LIST=(SID_DESC=(SID_NAME=sid_name) (GLOBAL_DBNAME=db_unique_name_DGMGRL.db_domain) (ORACLE_HOME=oracle_home)))
スタンバイ・データベースでフラッシュバック・データベースを有効にします。
フェイルオーバー後に古いプライマリ・データベースをスタンバイ・データベースとして修復できるようにするには、フラッシュバック・データベースを有効化する必要があります。そのために、プライマリおよびスタンバイ・データベースの両方に対して実行します。
Enterprise Managerが物理スタンバイ・データベース(通常はマウント状態)を監視できるようにするには、sysdba監視権限を指定します。これは、スタンバイの作成ウィザード中またはスタンバイ・データベース・ターゲットの「監視構成」の変更による作成後のどちらでも指定できます。
物理スタンバイを検証します。
Enterprise Managerコンソールで物理スタンバイ・データベースを検証します。「Data Guard」ページで ログ切替え ボタンをクリックしてログを切り替え、切替えが受け入れられてスタンバイ・データベースに適用されていることを検証します。
Cloud Controlデプロイメントに対する障害時リカバリ・ソリューションには、レプリケートされたファイルシステムでのソフトウェア・ライブラリ、OMSインストール、エージェント・インストールおよびOracleインベントリのインストールが含まれます。このソリューションには、BI Publisher共有記憶域の構成が含まれることもあります。
スタンバイWebLogicドメインを使用して実装されたスタンバイOMSはまだサポートされていますが、非推奨になっており、将来のリリースでサポートされない可能性があります(詳細はMy Oracle Supportノート1563541.1を参照してください)。この章に記載されているように、記憶域レプリケーションを使用してスタンバイOMSを作成する方法をお薦めします。スタンバイWebLogicドメインを使用したスタンバイOMSの作成は、付録I「スタンバイWebLogicドメインを使用するスタンバイOMS」に記載されています。
記憶域レプリケーションの要件
選択した記憶域レプリケーションの方法で、次がサポートされている必要があります。
スナップショットおよび一貫性のあるファイルシステム・コピー
サイト間でのオンデマンド・レプリケーションを実行する機能
プライマリOMSホスト名が、スタンバイ・サイトの対応するスタンバイ・ホストのIPアドレスに解決されることを確認します。これは次のどちらかの方法で実施できます。
物理ホスト名を使用してプライマリ・サイトでOMSをインストールし、スタンバイ・サイトの対応するホストでこれらのホスト名に別名を構成します。
プライマリおよびスタンバイの両方のサイトで構成できる別名ホスト名を使用して各OMSをインストールします。
各サイトでのホスト名解決は、ローカル解決(/etc/hosts)またはDNSベースの解決、あるいは両方の組合せのいずれかを使用して行うことができます。
OMSが、プライマリ・サイト物理ホスト名(oms1-p.example.comおよびoms2-p.example.com)を使用してプライマリ・サイトにインストールされる場合の/etc/hostsの構成例:
プライマリ・サイト
127.0.0.1 localhost.localdomain 123.1.2.111 oms1-p.example.com oms1-p #OMS1 123.1.2.112 oms2-p.example.com oms2-p #
スタンバイ・サイト
127.0.0.1 localhost.localdomain 123.2.2.111 oms1-s.example.com oms1-s oms1-p.example.com #OMS1 123.2.2.112 oms2-s.example.com oms2-s oms2-p.example.com #OMS2
OMSが、別名ホスト名(oms1.example.comおよびoms2.example.com)を使用してインストールされる場合の/etc/hostsの構成例:
プライマリ・サイト
127.0.0.1 localhost.localdomain 123.1.2.111 oms1-p.example.com oms1-p oms1.example.com #OMS1 123.1.2.112 oms2-p.example.com oms2-p oms2.example.com #OMS2
スタンバイ・サイト
127.0.0.1 localhost.localdomain 123.2.2.111 oms1-s.example.com oms1-s oms1.example.com #OMS1 123.2.2.112 oms2-s.example.com oms2-s oms2.example.com #OMS2
ネットワークが正しく構成されている場合、プライマリ・サイトからOMSホスト名をpingすると、プライマリ・ホストから応答がある必要があり、スタンバイ・サイトからOMSホスト名をpingすると、スタンバイ・ホストから応答がある必要があります。
例
プライマリ・サイトからのPing結果(プライマリ・サイトから応答):
[oracle@oms1-p ~]$ ping oms1-p.example.com PING oms1-p.example.com (123.1.2.111) 56(84) bytes of data. 64 bytes from oms1-p.example.com (123.1.2.111): icmp_seq=1 ttl=64 time=0.018 ms 64 bytes from oms1-p.example.com (123.1.2.111): icmp_seq=2 ttl=64 time=0.020 ms 64 bytes from oms1-p.example.com (123.1.2.111): icmp_seq=3 ttl=64 time=0.022 ms
スタンバイ・サイトからのPing結果(スタンバイ・サイトから応答)
[oracle@oms1-s ~]$ ping oms1-p.example.com PING oms1-s.example.com (123.2.2.111) 56(84) bytes of data. 64 bytes from oms1-s.example.com (123.2.2.111): icmp_seq=1 ttl=64 time=0.018 ms 64 bytes from oms1-s.example.com (123.2.2.111): icmp_seq=2 ttl=64 time=0.020 ms 64 bytes from oms1-s.example.com (123.2.2.111): icmp_seq=3 ttl=64 time=0.022 ms
プライマリ・サイトの各OMSのOMSインストール、エージェント・インストールおよびOracleインベントリがレプリケートされた記憶域に置かれるようにします。これは、レプリケートされた記憶域をOMSインストール中に指定するか、インストール後にこれらのコンポーネントをレプリケートされた記憶域に移動することによって実行できます。
|
注意: インストール後にコンポーネントを共有記憶域に移動した場合、それらは元のパス名を保持する必要があります。 |
プライマリ・サイトを指し示すようにDNSでアプリケーションの仮想ホスト名を構成します。
プライマリ・サイトに単一OMSがある場合、アプリケーションの仮想ホスト名のDNSエントリはこのOMSを指し示す必要があります。
プライマリ・サイトに複数OMSがある場合、アプリケーションの仮想ホスト名のDNSエントリはSLBを指し示す必要があります。
このホスト名は、長時間、クライアントによってキャッシュされないよう短いTTL値(30から60秒)で構成される必要があります。
スタンバイ・サイトでSLBを構成します(スタンバイ・サイトで複数OMSが必要な場合のみ必要です)。詳細は、「ロード・バランサの構成」を参照してください。スタンバイ・サイト上のSLBプールは、スタンバイOMSホストのIPアドレスを参照します。
アプリケーションの仮想ホスト名を使用してすべてのエージェントおよびOMSを再保護します。
例
OMSの場合
emctl secure oms -sysman_pwd <sysman_pwd> -reg_pwd <agent_reg_password> -host em.example.com -secure_port 4900 -slb_port 4900 -slb_console_port 443 -console -lock_upload -lock_console
エージェントの場合
emctl secure agent -emdWalletSrcUrl https://em.example.com:4901/em
記憶域レプリケーション・スケジュールを、ネットワーク・インフラストラクチャに許可されるできるかぎり頻繁な値に構成します(最低限24時間ごと)。
|
注意: ネットワーク・インフラストラクチャのリソース使用率のパフォーマンスを最大化するレプリケーション・スケジュールを決定するには、記憶域/ネットワークのドキュメントを参照してください。 |
HTTPロック・ファイルをローカル・ファイルシステムに移動します。詳細は、『Oracle Enterprise Manager Cloud Controlアドバンスト・インストレーションおよび構成ガイド』を参照してください。
スタンバイOMSホストの可用性の監視は、スイッチオーバー/フェイルオーバー操作の準備ができていることを確認するために重要です。これらのホストを監視するために、各スタンバイOMSホストのローカル・ファイルシステムにエージェントをデプロイする必要があります。スイッチオーバー/フェイルオーバー後にスタンバイ・サイトで起動されるコンポーネントとの競合を回避するために、スタンバイOMSホストにエージェントをデプロイするとき次の点を考慮する必要があります。
スタンバイOMSホストにデプロイされるエージェントは、レプリケートされたOracleインベントリを使用しないようにしてください。それらは、レプリケートされたOMSおよびエージェント・インストールを含まないローカル・インベントリを使用してインストールする必要があります。
スタンバイOMSホストにデプロイされるエージェントは、レプリケートされたエージェントによって使用されるものとは異なるポートにデプロイされる必要があります。これにより、レプリケートされたOMSおよびエージェントがスタンバイOMSホストで起動したときにポートの競合が回避されます。
使用するネットワーク・トポロジ(両方のサイトで別名またはスタンバイ・サイトでのみ別名)にかかわらず、これらのエージェントはスタンバイOMSホストの物理ホスト名を使用してデプロイする必要があります。
これらのエージェントは別のインベントリにデプロイして、OMSインストールに使用されるインベントリとは別にしておく必要があります。
エージェントがスタンバイOMSホストにデプロイされた後で、すべてのOMSエージェント(レプリケートされた記憶域に別名ホスト名でインストールされたもの、およびローカル・ストレージに物理ホスト名でインストールされたもの)が同じタイムゾーンで一貫して構成されていることを確認してください。エージェントのタイムゾーン変更の詳細は、『Oracle Enterprise Manager Cloud Control管理者ガイド』の管理エージェントのタイムゾーンの変更に関する説明を参照してください。
エージェント・インストールのインベントリの場所を指定すると、インストール中にインベントリ・ポインタ・ファイルを作成でき、-invPtrLocフラグを使用できます。
次の例に、インベントリの場所として/u01/oraInventory_standbyを指定するインベントリ・ポインタ・ファイルを示します
more /u01/oraInst_standby.loc inventory_loc=/u01/oraInventory_standbyinst_group=dba
エージェント・インストール中に-invPtrLocフラグを渡すことができるようになります。
ソフトウェア・ライブラリは記憶域レプリケーションを使用してレプリケートされるファイルシステムにある必要があります。ソフトウェア・ライブラリが現在別のファイルシステムにある場合、ソフトウェア・ライブラリ管理ページの「移行と削除」オプションを使用して移行することはできません。
詳細は、『Oracle Enterprise Manager Cloud Control管理者ガイド』のソフトウェア・ライブラリの構成に関する説明を参照してください。
記憶域レプリケーション・スケジュールを、ネットワーク・インフラストラクチャに許可されるできるかぎり頻繁な値に構成します。2時間ごとに発生する連続レプリケーションをお薦めします(最小)。
BI Publisherが構成されている場合、BI Publisherの共有記憶域も障害時リカバリ・シナリオに含める必要があります。
BI Publisher共有記憶域の場所は、記憶域レプリケーションを使用してレプリケートされるファイルシステム上である必要があります。
記憶域レプリケーション・スケジュールを、ネットワーク・インフラストラクチャに許可されるできるかぎり頻繁な値に構成します。2時間ごとに発生する連続レプリケーションをお薦めします(最小)。
|
注意: 既存の環境の高可用性ソリューションのレベル4を使用する場合でも、既存のサイトから共有記憶域ファイル・システムに移行できます。 |
ファイルシステム・バックアップを使用して、既存のOMSおよびエージェント・インストールを共有記憶域に移動します。
次のガイドラインを使用して、ローカル・ファイルシステムから共有記憶域に移行します
すべてのバックアップはオフライン・バックアップである必要があり、つまり、バックアップおよびリストアの前にホスト上のOMSおよびエージェント・プロセスの停止を完了する必要があります。
ルート・ユーザーとしてバックアップを実行する必要があり、その権限を保持している必要があります。
Middlewareホームおよびインスタンス・ホームのディレクトリ・パスは変更しないでください。
Cloud Controlが完全に停止することを回避するため、移行はローリング方式で実行できます。
「ソフトウェア・ライブラリの記憶域の場所の削除(および移行)」で説明するプロセスを使用して、ソフトウェア・ライブラリを共有記憶域に移動します。
スタンバイ・サイトのアクティブ化は、スイッチオーバーまたはフェイルオーバーのいずれかを使用して実行できます。これらは、後述のように異なる状況で使用されます。
スイッチオーバー - プライマリおよびスタンバイ・サイトの事前計画済ロール・リバーサルです。スイッチオーバーでは、機能がプライマリ・サイトからスタンバイ・サイトへ順序正しく調整された操作で転送されます。そのため、スイッチオーバーが完了するには両方のサイトが使用可能である必要があります。スイッチオーバーは、通常、障害時リカバリ(DR)シナリオのテストや検証、プライマリ・インフラストラクチャでの計画されたメンテナンス・アクティビティの場合に実行されます。スイッチオーバーは、スタンバイ・サイトをプライマリとしてアクティブ化するお薦めの方法です。
フェイルオーバー - 元のプライマリ・サイトが使用不可になったときに、スタンバイ・サイトをプライマリ・サイトとしてアクティブ化することです。
|
注意: BI Publisherが環境に構成されており、この章で説明するように障害時リカバリ・アプローチが記憶域レプリケーションを使用するスタンバイOMSである場合、スイッチオーバー/フェイルオーバーが発生すると、BI Publisherはスタンバイ・サイトで機能するようになります。 |
|
注意: スイッチオーバーまたはフェイルオーバー操作の一部としてのOMSファイルシステムのアンマウント中にエラーが発生した場合、Oracle Configuration Manager (OCM)がOMSホームから構成されて実行中であることが原因である可能性があります。OCMが実行されている場合は、OMSファイルシステムのアンマウント前に停止する必要があります。OCMのステータスをチェックするには、次のコマンドを実行します。
OCMを停止するには、次のコマンドを実行します。
スイッチオーバーまたはフェイルオーバー後にOCMを起動するには、次のコマンドを実行します。
|
この項では、スタンバイ・サイトへのスイッチオーバーの手順について説明します。どの方向にスイッチオーバーする場合も同じ手順が適用されます。
プライマリ・サイトですべてのOMSコンポーネントを停止します。
プライマリ・サイトですべての仮想管理エージェントを停止します。
プライマリ・サイトでOMSホストからOMSファイルシステムおよびソフトウェア・ライブラリ・ファイルシステムをアンマウントします。
OMSおよびソフトウェア・ライブラリ・ファイルシステムのオンデマンド・レプリケーションを実行します。
|
注意: オンデマンド・レプリケーションの実行に必要な手順は、記憶域のドキュメントを参照してください。 |
アプリケーションの仮想ホスト名に対するDNSエントリを更新します。
Data Guardスイッチオーバーを使用してOracle Databaseをスイッチオーバーします。
DGMGRLを使用してスタンバイ・データベースへのスイッチオーバーを実行します。このコマンドはプライマリ・サイトでもスタンバイ・サイトでも実行できます。スイッチオーバー・コマンドは、プライマリ・データベースおよびスタンバイ・データベースの状態を検証し、ロールのスイッチオーバーに影響を与えます。古いプライマリ・データベースを再起動して新しいスタンバイ・データベースとして設定します。
SWITCHOVER TO <standby database name>;
スイッチオーバー後の状態を検証します。スタンバイ・データベースを完全に監視するには、データベースを監視するユーザーにSYSDBA権限が必要です。スタンバイ・データベースはマウント専用状態であるため、この権限が必要になります。プライマリ・データベースとスタンバイ・データベースを監視するユーザーに両方のデータベースのSYSDBA権限があればベスト・プラクティスになります。
SHOW CONFIGURATION;
SHOW DATABASE <primary database name>;
SHOW DATABASE <standby database name>;
ソフトウェア・ライブラリおよびOMS記憶域のロール・リバーサルを実行します(手順については、記憶域のドキュメントを参照してください)。
SWLIBおよびOMS記憶域のレプリケーション・スケジュールを再び有効化します。
BI Publisherが構成されている場合、BI Publisherの共有記憶域のレプリケーション・スケジュールを再び有効化します。
スタンバイ・サイトのOMSホストにOMSおよびソフトウェア・ライブラリ・ファイルシステムをマウントします。
BI Publisherが構成されている場合、BI Publisherの共有記憶域のファイルシステムをスタンバイ・サイトのOMSホストにマウントします。
スタンバイ・サイトで最初のOMS管理サーバーを起動します。
|
注意: 18.2.3項「データベースに関する考慮事項」で説明したように、SCANアドレスおよびロールベースのデータベース・サービスを使用するなどしてプライマリ・サイトとスタンバイ・サイトの両方で機能する接続文字列を使用している場合、この手順は必要ありません。 |
次のコマンドを使用して、OMSを新しいプライマリ・リポジトリ・データベースに向けます。
emctl config oms -store_repos_details -repos_conndesc <connect descriptor> -repos_user <username>
例
emctl config oms -store_repos_details -repos_conndesc "(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=newscan.domain)(PORT=1521)))(CONNECT_DATA=(SERVICE_NAME=emreps.domain)))" -repos_user SYSMAN
|
注意: 第18.2.3項「データベースに関する考慮事項」で説明しているように、SCANアドレスおよびロールベース・データベース・サービスの使用など、プライマリ・サイトとスタンバイ・サイトの両方から機能する接続文字列を使用する場合、この手順は必要ありません。 |
各OMSでこの手順を繰り返します。
スタンバイ・サイトでOMSを起動します。
次のコマンドを使用してスタンバイ・サイトで管理エージェントを起動します。
emctl start agent
次のコマンドを使用して管理サービスおよびリポジトリ・ターゲットを再配置します。
emctl config emrep -agent <agent name> -conn_desc <repository connection>
管理サービスと管理リポジトリ・ターゲットは、プライマリ・サイトのいずれかの管理サービス上の管理エージェントで監視されます。スイッチオーバー/フェイルオーバー後にターゲットが監視されるようにするには、スタンバイ・サイトのいずれかの管理サービスで次のコマンドを実行して、そのターゲットをスタンバイ・サイトの管理サービスに再配置します。
|
注意: 次の2つの条件が満たされる場合、この手順は必要ありません。
|
管理サーバー・ホストの設定。これを行うには、GCDomainのターゲット・ホームページにナビゲートし、Cloud Control内から「WebLogicドメイン」→「ターゲット設定」→「モニタリング資格証明」を選択します。
この項では、スタンバイ・サイトにフェイルオーバーして、Enterprise Managerのアプリケーション状態をリカバリする手順について説明します。これは、管理リポジトリ・データベースをすべての管理エージェントと再同期化し、元のプライマリ・データベースを最後に有効にすることで行います。
プライマリ・サイトでOMSコンポーネントが実行中である場合はすべて停止します。
プライマリ・サイトで仮想エージェントが実行中である場合はすべて停止します。
プライマリ・サイトのOMSホストからOMSおよびソフトウェア・ライブラリ・ファイルシステムをアンマウントします。
BI Publisherが構成されている場合、BI Publisherの共有記憶域のファイルシステムをプライマリ・サイトのOMSホストからアンマウントします。
OMSおよびソフトウェア・ライブラリ・ファイルシステムのオンデマンド・レプリケーションを実行します。(発生した障害の種類によって、実行できないこともあります。)BI Publisherが構成されている場合、BI Publisher共有記憶域のファイルシステムのオンデマンド・レプリケーションも実行します。
|
注意: オンデマンド・レプリケーションの実行に必要な手順は、記憶域のドキュメントを参照してください。 |
アプリケーションの仮想ホスト名に対するDNSエントリを更新します。
Data Guardフェイルオーバーを使用してOracle Databaseをフェイルオーバーします。
ソフトウェア・ライブラリおよびOMS記憶域のロール・リバーサルを実行します。
SWLIBおよびOMS記憶域のレプリケーション・スケジュールを再び有効化します
スタンバイ・サイトのOMSホストにOMSおよびソフトウェア・ライブラリ・ファイルシステムをマウントします
最初のOMS管理サーバーを起動します。
|
注意: 次の2つの条件が満たされる場合、この手順は必要ありません。
|
新しいプライマリ・リポジトリ・データベースを指すように、OMS接続記述子を変更します。
emctl config oms -store_repos_details -repos_conndesc <connect descriptor> -repos_user <username>
例
emctl config oms -store_repos_details -repos_conndesc '(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=newscan.domain)(PORT=1521)))(CONNECT_DATA=(SERVICE_NAME=emreps.domain)))' -repos_user SYSMAN
|
注意: SCANアドレスとロールベース・データベース・サービスを使用した場合のように、プライマリ・サイトとスタンバイ・サイトの両方で機能するリポジトリ接続記述子を使用しているときは、この手順は必要ありません。 |
各OMSでこの手順を繰り返します。
リポジトリの再同期化を実行して、エージェントを新しいプライマリ・データベースと再同期化します。
Data Guardの最大保護または最大可用性レベルで実行している場合、フェイルオーバーでのデータ損失はないため、この手順を省略します。ただし、データ損失がある場合は、新しいプライマリ・データベースとすべての管理エージェントを同期化します。
スタンバイ・サイトのいずれかの管理サービスで次のコマンドを実行します。
emctl resync repos -full -name "<name for recovery action>"
このコマンドは、スタンバイ・サイトの管理サービスの起動時に各管理エージェントで実行される再同期化ジョブを発行します。
スタンバイ・サイトでエージェントを起動します。
スタンバイ・サイトでOMSを起動します。
「設定」→「Cloud Controlの管理」→「状態の概要」の順にナビゲートし、「ターゲット設定」→「モニタリング構成」を選択して、管理サービスとリポジトリ・ターゲットの接続記述子を変更します。
リポジトリ接続記述子を変更して、現在アクティブなデータベースに接続する必要があります。
|
注意: SCANアドレスとロールベース・データベース・サービスを使用した場合のように、プライマリ・サイトとスタンバイ・サイトの両方で機能するリポジトリ接続記述子を使用しているときは、この手順は必要ありません。 |
管理サーバー・ホストの設定。これを行うには、GCDomainのターゲット・ホームページにナビゲートし、Cloud Control内から「WebLogicドメイン」→「ターゲット設定」→「モニタリング資格証明」を選択します。
Data Guardと記憶域レプリケーションの組合せによって、スタンバイ・サイトのプライマリとの同期は自動的に維持されます。
OMSまたはエージェントで次の操作が行われた前後に、スタンバイ・サイトへのオンデマンド・レプリケーションが実行されることを管理者は確認する必要があります。
プラグインのデプロイメント/アンデプロイ、または既存のプラグインのアップグレード
アップグレード
パッチ
emctlコマンド(ライフサイクル動詞(start/stop/status oms)以外)
ADP/JVMD/BI Publisherの構成
|
注意: オンデマンド・レプリケーションの実行に必要な手順は、記憶域のドキュメントを参照してください。 |
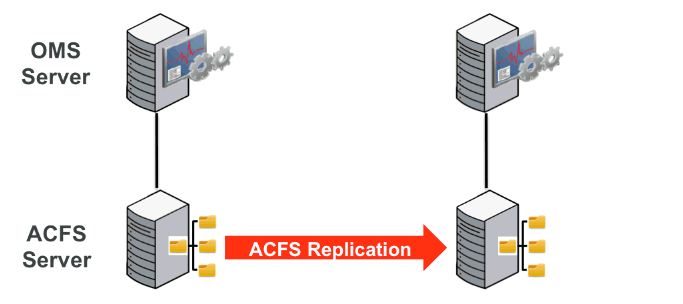
自動ストレージ管理クラスタ・ファイル・システム(ACFS)レプリケーションによって、ネットワーク経由でのACFSファイル・システムのリモート・サイトへのレプリケーションが可能になります。この機能は、障害時リカバリ機能の実現に役立ちます。次の図では、Enterprise Managerのインストールで障害時リカバリを実現するためにこの機能を利用する方法を示しています。
ACFSレプリケーションの構成
グリッド・インフラストラクチャをインストールして、ACFSサーバーを作成します。
ACFS記憶域レプリケーションでは、クラスタに対してグリッド・インフラストラクチャがインストールされる必要がありますが、単一ノードでのインストールも可能です(単一ノード・クラスタ)。
OMSインストールおよびソフトウェア・ライブラリに使用するために、ACFSサーバー(手順1で作成済)上にACFSファイル・システムを作成します。
NFSを使用してACFSファイル・システムをエクスポートします。
ACFSマウント・ポイントに対してroot squashを無効にします(無効にしないと、Enterprise Managerがクライアントにインストールされた後でroot.shが動作しなくなります)。
次のオプションを使用して、(OMS用に使用することになっている)別のノードにファイル・システムをマウントします。
Nfs rw,bg,hard,nointr,rsize=131072,wsize=131072,tcp,vers=3, timeo=300,actimeo=120
NFS (ACFS)ファイル・システムにEnterprise Managerをインストールします。
スタンバイ用として使用するために、別のACFSファイル・システムで2番目のACFSサーバー(単一ノード・クラスタ)を作成します。
プライマリACFSサーバーとスタンバイACFSサーバー間に、ACFSレプリケーションを設定します。
スタンバイ・サーバーでは、次のコマンドを使用してレプリケーションを開始します。
/sbin/acfsutil repl init standby -p
ルート・ユーザーによって実行されます。
次のコマンドを使用して、スタンバイ・ファイル・システムが起動していることを確認します。
/sbin/acfsutil repl info
プライマリ・サーバーでは、次のコマンドを使用してレプリケーションを開始します。
/sbin/acfsutil repl init primary -s
次のコマンドを使用して、プライマリ・ファイル・システムが起動していることを確認します。
/sbin/acfsutil repl info -c
プライマリ・サーバーからスタンバイにスイッチオーバーします。スイッチオーバー操作の実行に関する明示的な手順については、18.5.1項「スイッチオーバーの手順」を参照してください(ただし、次の変更があります)。
手順4:
次の手順を実行して、OMSおよびソフトウェア・ライブラリ・ファイル・システムのオンデマンド・レプリケーションを実行します。
次のコマンドを使用して、プライマリ・サーバーからEnterprise Managerファイル・システムへのACFS同期を実行します。
/sbin/asfsutil repl sync apply
手順7:
次の手順を実行して、ソフトウェア・ライブラリおよびOMS記憶域のロール・リバーサルを実行します。
次のコマンドを使用して、ACFSレプリケーションを停止します。
/sbin/acfsutil repl terminate standby
ACFSレプリケーションを再構成するには、この項で前述した手順7「プライマリACFSサーバーとスタンバイACFSサーバー間に、ACFSレプリケーションを設定します。」に示されている手順を実行します。