13 Oracle Secure Enterprise Search APIs
This chapter explains the Oracle Secure Enterprise Search (Oracle SES) APIs and related information. This chapter contains the following topics:
Overview of Oracle Secure Enterprise Search APIs
Oracle Secure Enterprise Search provides the following APIs:
The Web Services APIs are used to integrate Oracle SES search capabilities into your search application. Oracle SES provides Java proxy libraries. You either can use the Java libraries or create proxies, based on the published Web Services Description Language (WSDL) files, to access Oracle SES Web Services. Oracle SES provides two Web Services APIs:
-
Query Web Services API
-
Administration Web Services API
Oracle SES includes an extensible crawler plug-in framework that lets you crawl and index proprietary document repositories with the Crawler Plug-in API.
Oracle SES also includes an extensible authentication and authorization framework. You use any identity management system to authorize users with the Identity Plug-in API, and you can define your own security model for each source with the Authorization Plug-in API.
The URL Rewriter API is used by the crawler to filter and rewrite extracted URL links before they are inserted into the URL queue.
The Query-time Authorization API filters search results and access to document information at search time. Query-time filtering can be used in addition to, or instead of, ACLs.
Oracle Secure Enterprise Search Web Services APIs
Oracle SES includes the following Web Services APIs:
-
Query Web Services API: Enables you to perform search queries; for example, search for "oracle benefits" and return all the documents. You can also customize the default Oracle SES ranking to create a more relevant search result list for your enterprise or configure clustering for customized applications.
-
Administration Web Services API: Enables you to perform various administrative tasks; for example, start or stop a crawl schedule, check schedule status, get the estimated index fragmentation level, and perform index optimization.
See Also:
-
Oracle Secure Enterprise Search Administration API Guide for more information about Web services interface
Oracle Secure Enterprise Search Web Services APIs let you write your own application to search and administer Oracle SES over the network. The APIs provide the following benefits:
-
Applications can be deployed into any computer that connects to Oracle SES server through a standard Internet protocol.
-
Web Services protocol is XML-based, which makes for easy application integration.
Note:
The use ofotext:: syntax is not in supported in a search string in the query application as well as in the query Web Services API.Oracle SES also provides the client-side Java proxies for marshalling and parsing Web Services SOAP messages. Client applications can use the library instead of creating SOAP requests and parsing SOAP responses by themselves to access Oracle SES Web Services.
This section contains the following topics:
Web Services APIs Installation
Oracle SES Web Services runs on the Oracle SES middle tier standalone Oracle WebLogic Server. They are installed and configured as part of the default installation. You can use Oracle SES Web Services immediately. Follow the same middle tier administration steps to start and stop Oracle SES Web Services. Note that the Query Web Service client API should be run using JDK version 6 or later.
WebLogic provides a default Oracle SES Web Services administrator console. The administrator console URL is the same as the Oracle SES Web Services URL.
Query Web Services Location
The Query Web service is located at the following address for an Oracle SES installation:
http://host:port/search/query/OracleSearch
For example, if your Oracle SES middle tier is running on host myhost and the port number is 8888, then the Query Web Services URL is the following:
http://myhost:8888/search/query/OracleSearch
You can obtain the following information from the administrator console:
-
Oracle SES Query WSDL description
-
List of Web Services messages and operations
-
Client-side Java proxies and source codes
Administration Web Services Location
The Administration Web service is located at the following address for an Oracle SES installation:
http://host:port/search/api/admin/AdminService
You can obtain the following information from the administrator console:
-
Oracle SES Administration WSDL description
-
List of Web Services messages and operations
-
Client-side JavaScript stub
Web Services Concepts
Oracle SES Web Services consists of a remote procedure call (RPC) interface to Oracle SES that enables the client application to invoke operations on Oracle SES over the network. The client application uses WSDL specification published by Oracle SES Web Services URL to send a request message using Simple Object Access Protocol (SOAP). The server then responds to the client application with a SOAP response message.
This section explains the following concepts:
Web Services
A Web Service is a software application identified by a URI whose interfaces and binding are capable of being defined, described, and discovered by XML artifacts. A Web Service supports direct interactions with other software applications using XML-based messages and internet-based products.
A Web Service does the following:
-
Exposes and describes itself: A Web Service defines its functionality and attributes so that other applications can understand it. By providing a WSDL file, a Web Service makes its functionality available to other applications.
-
Allows other services to locate it on the Web: A Web Service can be registered in a UDDI registry so that applications can locate it.
-
Can be invoked: After a Web Service has been located and examined, the remote application can invoke the service using an Internet standard protocol.
-
Web Services are of either request and response or one-way style, and they can use either synchronous or asynchronous communication. However, the fundamental unit of exchange between Web Services clients and Web Services, of either style or type of communication, is a message.
Simple Object Access Protocol
The Simple Object Access Protocol (SOAP) is a lightweight XML-based protocol for exchanging information in a decentralized distributed environment. SOAP supports different styles of information exchange, including RPC-oriented and message-oriented exchange. RPC style information exchange allows for request-response processing, where an endpoint receives a procedure-oriented message and replies with a correlated response message. Message-oriented information exchange supports organizations and applications that must exchange messages or other types of documents where a message is sent, but the sender might not expect or wait for an immediate response. Message-oriented information exchange is also called document style exchange.
SOAP has the following features:
-
Protocol independence
-
Language independence
-
Platform and operating system independence
-
Support for SOAP XML messages incorporating attachments (using the multipart MIME structure)
Web Services Description Language
The Web Services Description Language (WSDL) is an XML format for describing network services containing RPC-oriented and message-oriented information. Programmers or automated development tools can create WSDL files to describe a service and can make the description available over the Internet. Client-side programmers and development tools can use published WSDL specifications to obtain information about available Web Services and to build and create proxies or program templates that access available services.
Web Services Architecture
Oracle SES Web Services is powered by the Oracle SES middle tier Oracle WebLogic Server. The implementation, configuration, and deployment of Oracle SES Web Services follow the procedures and standards provided by Oracle WebLogic Server.
Oracle SES WSDL defines the operations and messages for Oracle SES Web Services. The message exchange of Oracle SES Web Services is RPC style, in which the contents of the SOAP message body conform to a structure that specifies a procedure and includes a set of parameters or a response with a result and any additional parameters.
Oracle SES SOAP messages use HTTP binding where a SOAP message is embedded in the body of a HTTP request and a SOAP message is returned in the HTTP response.
The following diagram illustrates the architecture of Oracle SES Web Services:
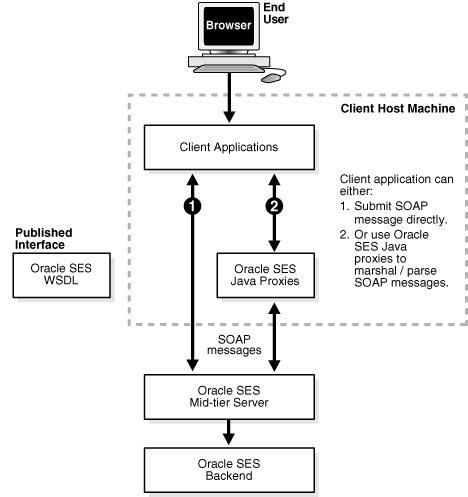
Description of the illustration ''benri001.gif''
Development Platforms
You can implement client applications using platforms that support SOAP, such as Oracle JDeveloper, Microsoft .NET, or Apache Axis. These platforms allow you to automatically create code using the Oracle SES WSDL interface. Include the generated code along with the application logic to create a request, invoke the Web Services, and interpret the response.
Query Web Services Common Data Types
This section contains the following topics:
Base Data Types
Oracle Secure Enterprise Search Web Services use the following base data types:
XML-to-Java Data Type Mappings
The mapping between XML schema data types and Java data types depends on the SOAP development environment. The following table shows mappings for the Oracle JDeveloper environment:
Complex Types
Oracle SES Web Services uses the following complex data types:
OracleSearchResult
The search result container. It has the following elements:
-
returnCount: A Boolean value indicating whether the result includes the count estimate for the hit list. -
estimatedHitCount: The estimated count of the search result; -1 means the search result does not return the estimated hit count. -
dupRemoved: A Boolean value indicating whether near duplicate documents have been removed from search result. -
dupMarked: A Boolean value indicating whether near duplicate documents have been marked in the search result. IfdupRemovedis true, thendupMarkedis always false. -
resultElements: An array ofresultElement, which represents the actual hit list. -
suggestedLinks: An array ofsuggestedLinkfor the given search. -
query: The actual search string, which uses Oracle SES query syntax. -
altKeywords: Alternate keywords (suggestions) for a given search. If you setswitch ses.qapp.multiple_alternate_keywordstotrue, then multiple alternate keywords are returned for a search term. The following terms are returned:-
ALTERNATE_SPELLING: Contains alternate words from the dictionary.
-
EXPANDED_QUERY: Contains keywords from the alternate keywords page when Auto-Expand is selected. These keywords are automatically included in the query that is sent to Oracle Text.
-
ALTERNATE_QUERY: Contains keywords from the alternate keywords page when Auto-Expand is not selected.
-
-
startIndex: The start index of search results. -
docsReturned: The number of search matches returned.
ResultElement
This is the data type for search result element. It has the following elements:
-
author: Primary author of the document -
description: Description of the document -
url: URL of the document -
snippet: Keywords in context (KWIC) of the document -
title: Title of the document -
lastModified: Last modified date of the document -
mimetype: Mime type of the document -
score: Oracle Text score of the document -
docID: Document ID -
language: Language of the document -
contentLength: Content length of the document -
signature: Signature of the document -
infoSourceID: InfoSource ID of the document -
infoSourcePath: InfoSource path of the document -
groups: Array of groups to which the document belongs -
isDuplicate: Boolean value indicating whether this document is a near duplicate of another document in the result list -
hasDuplicate: Boolean value indicating whether this document has one or more near duplicates in the result list -
fedID: Federated instance ID, used to track which federated instance the document is fetched from -
customAttributes: Array of custom nondefault attributes extracted from/for the document during crawlingCustomAttributeencapsulates the name and value of the custom (user-defined) attribute. The name of the attribute is represented by actual name and type of the attribute in name_type format. For example, the string attribute foo is represented asfoo_STRING. All Date attributes use the formatmm/dd/yyyy.
SCElement
Suggested content from a provider. It has the following elements:
-
name: name of the suggested content provider -
content: suggested content from the provider. The content is a byte array of the XML or HTML content
DataGroup
The source group. It has the following elements:
-
groupID: Source group ID -
groupName: Source group name -
groupDisplayName: Display name for the source group
Attribute
The data type for search attribute. It has the following elements:
-
id: Search attribute ID -
name: Internal name of search attribute -
displayName: Display name of search attribute -
type: The search attribute type. Value is either number, string, or date.
Filter
The data type for filter condition (predicate). It has the following elements:
-
attributeId: Search attribute ID -
attributeType: Search attribute type. Value is either number, string, or date. -
operator: Operator of the filter condition-
If
attributeTypeis string, then it should be either equals or contains. -
If
attributeTypeis number or date, then it should be either greaterthan, greaterthanequals, lessthan, lessthanequals, or equals.
-
-
attributeValue: Value of the filter condition (predicate)-
For string type attribute, the value is simply the string itself.
-
For number type attribute, the value should be represented by a string consisting of an optional sign, (+) or (-), followed by a sequence of zero or more decimal digits ("the integer"), optionally followed by a fraction. The fraction consists of a decimal point followed by zero or more decimal digits. The string must contain at least one digit in either the integer or the fraction.
-
For date type attribute, the value should be in the format
mm/dd/yyyy, wheremmis the month (01~12),ddis the date (01~31),yyyyis the year (for example, 2005)
-
Examples:
-
If the filter condition is Title contains
Oracle Secure Enterprise Search, then the client application must look up the attribute ID of search attributeTitleand include the following (element, value) pairs:-
attributeID= 1(assuming the search attribute id ofTitleis 1) -
operator= contains -
attributeValue= Oracle Secure Enterprise Search
-
-
If the filter condition is Price greater than 1000, then the client application must look up the attribute ID of search attribute
Priceand include the following (element, value) pairs:-
attributeID= 2(assuming the search attribute id of 'Price' is 2) -
operator= greaterthan -
attributeValue= 1000
-
Node
This is the data type for the infosource node. It has the following elements:
-
id: Infosource node ID -
fedId: Federated instance ID, used to track which federated instance the node belongs to -
name: Name of the node -
docCount: Number of documents under the node. If the value is -1, then there exists documents under the node but the count cannot be shown. -
hasChildren: Indicates if the node has any children -
fullpath: Full path of the category node -
fullpathIds: The IDs of each node in the full path
AttributeLOVElement
This is the element of AttributeLOV, the list of search attribute values. It has the following elements:
-
value: Attribute value (internal value) -
displayValue: Display value
SessionContextElement
This data structure is used to store authentication information for the search user in the form of a name-value pair, which can be used during query-time authorization filtering of the results. It has the following elements:
-
name: Name of the authentication attribute -
value: Value of the authentication attribute
Status
This is the status of the request. It has the following elements:
-
status: Status code. Value is either successful or 'ailed -
message: Status message. Value is null, or an error message if the status is 'ailed
Language
This is the language data type. It has the following elements:
-
languageName: Name of the language -
languageDisplayName: Display name (translated name) of the language
Array Types
Oracle Secure Enterprise Search Web Services uses the following complex array types:
-
AttributeArray: Array ofAttribute -
AttributeLOVElementArray: Array ofAttributeLOVElement -
CustomAttributeArray: Array ofCustomAttribute -
SCElementArray: Array ofSCElement -
DataGroupArray: Array ofDataGroup -
FilterArray: Array ofFilter -
IntArray: Array ofint -
LanguageArray: Array ofLanguage -
NodeArray: Array ofNode -
ResultElementArray: Array ofResultElement -
SessionContextElementArray: Array ofSessionContextElement -
StringArray: Array ofString
Query Web Services Operations
This section contains the following topics:
Overview of Query Web Services Operations
Oracle Secure Enterprise Search provides the following categories of Web Services operations:
-
Authentication: Authenticates a user's access to Oracle SES. The operation is only required if the user performs secure search.
-
Search: Runs a search on Oracle SES and obtains a hit list along with information such as estimated hit count, near duplicate documents in the result list, suggested links, and alternate keywords for the search. Gets suggested content from external providers for the given query. You can also customize the default Oracle SES ranking to create a more relevant search result list for your enterprise or configure clustering for customized Oracle SES applications.
-
Metadata: Obtains the search metadata, such as the list of source groups, the list of supported languages, or the list of search attributes.
-
Search Hit: Obtains the search result details, such as the cached version of search result and in-links and out-links of the search hit.
-
User Feedback: Sends user feedback to Oracle SES, such as user-submitted URLs.
See Also:
"Query Web Services Operations"Authentication Operations
This section describes the following authentication operations:
loginRequest Message
Requests Oracle SES to authenticate the search user. It consists of the following parameters:
-
username: User name for the search user. This value is not case-sensitive. -
password: Password for the search user
<message name="loginRequest"> <part name="username" type="xsd:string"/> <part name="password" type="xsd:string"/> </message>
loginResponse Message
Contains the return status for the loginRequest message.
<message name="loginResponse"> <part name="return" type="typens:Status"/> </message>
logoutRequest Message
Used when the user logs out from the search application.
<message name="logoutRequest"> </message>
logoutResponse Message
Contains the return status for the logoutRequest message.
<message name="logoutResponse"> <part name="return" type="typens:Status"/> </message>
setSessionContextRequest Message
Passes authentication information for the search user, which can be used during query-time filtering. It consists of the following parameter:
-
sessionContext: An array ofSessionContextElement. This array stores the authentication information needed for the query-time authentication filtering in the form of name-value pairs.
<message name="setSessionContextRequest">
<part name="sessionContext" type="typens:SessionContextElementArray"/>
</message>
Note:
Login and logout Web Services calls cause Oracle SES to automatically set or reset theAUTH_USER value in the session context that is passed to the query-time filter. This session context attribute cannot be overwritten explicitly through the setSessionContext call.setSessionContextResponse Message
Contains the return status for the setSessionContext message.
<message name="setSessionContextResponse"> <part name="return" type="typens:Status"/> </message>
proxyLoginRequest Message
Logs in the end user to Oracle SES using proxy authentication. It consists of following parameters:
-
username: User name of the proxy user -
password: Password of the proxy user -
searchUser: User name of the end user
<message name="proxyLoginRequest"> <part name="username" type="xsd:string"/> <part name="password" type="xsd:string"/> <part name="searchUser" type="xsd:string"/> </message>
The proxy user must be a federation trusted entity created on the Oracle SES instance.
See Also:
"Federation Trusted Entities"proxyLoginResponse Message
This message contains the return status for the proxyLoginRequest message.
<message name="proxyLoginResponse"> <part name="return" type="typens:Status"/> </message>
Search Operations
This section describes the following search operations:
doOracleAdvancedSearch Message
Invokes Oracle SES advanced search and returns search results. It consists of the following parameters:
-
query: The search string. This should follow Oracle SES query syntax. See "Query Web Services Query Syntax" for details. -
startIndex: Index of the first document in the hit list to be returned. The default is 1 if not set explicitly. -
docsRequested: The maximum number of documents in the hit list to be returned. The default is 10 if not set explicitly. -
dupRemoved: Boolean flag to enable or disable duplicate removal. If turned on, then duplicate documents in the hit list are removed. The default is false if not set explicitly. Note: ThedupMarkedswitch has no effect whendupRemovedis turned on. -
dupMarked: Boolean flag to enable or disable duplicate detection. The default is false if not set explicitly. Note: ThedupMarkedswitch has no effect whendupRemovedis turned on. -
groups: Data source groups that the search is restricted to. The default is all groups if not set explicitly. -
queryLang: Language of the query. This is equivalent to Locale. The default is English (en) if not set explicitly. This is used in relevancy boosting. -
docLang: Language of the documents to restrict the search. If the value is not set explicitly, then search is performed against documents of all the languages. -
returnCount: Boolean flag to fetch the total hit count with the result. The default is false if not set explicitly. -
filterConnector: Connector between all the filters: "and" indicates that the documents in the hit list must satisfy all the filters, and "or" indicates that the documents in the hit list must satisfy at least one filter. The default is "and" if not set explicitly. -
filters: An array of filters. Each filter is a restriction on the search result. Filters are connected by thefilterConnector. The default is null (no filter applies to the search result) if not set explicitly. -
fetchAttributes: Array of integers representing the IDs of custom or nondefault attributes to be fetched with the search result -
searchControls: XML string to specify advanced filter conditions and ranking parametersNote:
The attribute filterLastModifiedDateuses the formatmm/dd/yyyy.
public OracleSearchResult doOracleAdvancedSearch(
String query,
Integer startIndex,
Integer docsRequested,
Boolean dupRemoved,
Boolean dupMarked,
DataGroup[] groups,
String queryLang,
String docLang,
Boolean returnCount,
String filterConnector,
Filter[] filters,
Integer[] fetchAttributes,
String searchControls)
throws Exception
doOracleFetchSearch Message
Invokes Oracle SES fetch search and returns fetch results. It consists of the following parameters:
-
query: The search string. This should follow Oracle SES query syntax. See "Query Web Services Query Syntax" for details. -
targetDocIdList: Target document ID list, most likely from a cluster node. -
startIndex: Index of the first document in the hit list to be returned. The default is 1 if not set explicitly. -
docsRequested: Maximum number of documents in the hit list to be returned. The default is 10 if not set explicitly. -
queryLang: Language of the query. This is equivalent to Locale. The default is English (en) if not set explicitly. This is used in relevancy boosting. -
fetchAttributeNames: Array of names of custom or nondefault attributes to be fetched with the search result. -
groupAttr: Attribute used for grouping. -
sortAttrList: List of sorting attribute settings. -
clusterList: List of cluster configurations.
public OracleResultContainer doOracleFetchSearch(
String query,
String[] targetDocIdList,
Integer startIndex,
Integer docsRequested,
String queryLang,
String[] fetchAttributeNames,
GroupAttribute groupAttr,
SortAttribute[] sortAttrList,
ClusterConfig[] clusterList)
throws Exception
doOracleOrganizedSearch Message
This invokes Oracle SES organized search and returns search results. It consists of the following parameters:
query: The search string. This should follow Oracle SES query syntax. See "Query Web Services Query Syntax" for details.
topN: Top N search result for grouping, sorting, and clustering.
startIndex: Index of the first document in the hit list to be returned. The default is 1 if not set explicitly.
docsRequested: Maximum number of documents in the hit list to be returned. The default is 10 if not set explicitly.
dupRemoved: Boolean flag to enable or disable duplicate removal. If turned on, duplicate documents in the hit list are removed. The default is false if not set explicitly. Note: The dupMarked switch has no effect when dupRemoved is turned on.
dupMarked: Boolean flag to enable or disable duplicate detection. The default is false if not set explicitly. The dupMarked switch has no effect when dupRemoved is turned on.
groups: Data source groups that the search is restricted to. The default is all groups if not set explicitly.
queryLang: Language of the query. This is equivalent to Locale. The default is English (en) if not set explicitly. This is used in relevancy boosting.
docLang: Language of the documents to restrict the search. If the value is not set explicitly, then search is performed against documents of all the languages.
returnCount: Boolean flag to fetch the total hit count with the result. The default is false if not set explicitly.
filterConnector: Connector between all the filters: "and" indicates that the documents in the hit list must satisfy all filters, "or" indicates that the documents in the hit list must satisfy at least one filter. The default is "and" if not set explicitly.
filters: An array of filters. Each filter is a restriction on the search result. Filters are connected by the filterConnector. The default is null (no filter applies to the search result) if not set explicitly.
fetchAttributeNames: Array of names of custom or nondefault attributes to be fetched with the search result.
searchControls: XML string to specify advanced filter conditions and ranking parameters.
groupAttr: Attribute used for grouping.
sortAttrList: List of sorting attribute settings.
clusterList: List of cluster configurations.
public OracleResultContainer doOracleOrganizedSearch(
String query,
Integer topN,
Integer startIndex,
Integer docsRequested,
Boolean dupRemoved,
Boolean dupMarked,
DataGroup[] groups,
String queryLang,
String docLang,
Boolean returnCount,
String filterConnector,
Filter[] filters,
String[] fetchAttributeNames,
String searchControls,
GroupAttribute groupAttr,
SortAttribute[] sortAttrList,
ClusterConfig[] clusterList)
throws Exception
doOracleSearch Message
This is the main message for the search application. It consists of the following parameters:
-
query: A search string. It must be a valid string and it cannot be null. The search string should follow Oracle SES query syntax. See "Query Web Services Query Syntax" for details. -
startIndex: The index of the first result to be returned. For example, if there are 67 results, you might want to start at 20. The default is 1 if not set explicitly. -
docsRequested: The maximum number of results to be returned. The default is 10 if not set explicitly. -
dupRemoved: Enable or disable duplicate removal. If turned on, then the search result eliminate all near duplicate documents from the result list. ThedupMarkedswitch has no effect whendupRemovedis turned on. The default is false if not set explicitly. -
dupMarked: Enable or disable duplicate detection. IfdupRemovedis turned off anddupMarkedis turned on, then the search result keeps all near duplicate documents from the result list and marks them as duplicates. IfdupRemovedis turned on, then thedupMarkedswitch has no effect. The default is false if not set explicitly. -
groups: Limit the search result to the documents from specified source groups. The default is for all groups if not set explicitly. -
queryLang: The query language argument should be a valid ISO language code. These codes are the lower-case, two-letter codes as defined by ISO-639. Examples: "en" for English and "de" for German. The default is English ("en") if not set explicitly. This is used for relevancy boosting. -
docLang: Set the language of the documents to limit the search. If the value is not set explicitly, then search is performed against documents of all the languages. -
returnCount: Set to true to return total hit count with the result. The default is false if not set explicitly. -
filterConnector: The connector between all filters: "and" indicates the search result must satisfy all filters, "or" indicates the search result must satisfy at least one filter. The default is "and" if not set explicitly. -
filters: An array of filters. Each filter is a restriction on search results. Filters are connected byfilterConnector. The default is null (no filter applies to the search result) if not set explicitly. -
fetchAttributes: Array of integers representing the nondefault attribute IDs to be fetched in theresultElements. The default is null (or set one int value '0'), so no attributes other than default-attributes are fetched in theresultElements.
<message name="doOracleSearch"> <part name="query" type="xsd:string"/> <part name="startIndex" type="xsd:int"/> <part name="docsRequested" type="xsd:int"/> <part name="dupRemoved" type="xsd:boolean"/> <part name="dupMarked" type="xsd:boolean"/> <part name="groups" type="typens:DataGroupArray"/> <part name="queryLang" type="xsd:string"/> <part name="docLang" type="xsd:string"/> <part name="returnCount" type="xsd:boolean"/> <part name="filterConnector" type="xsd:string"/> <part name="filters" type="typens:FilterArray"/> <part name="fetchAttributes" type="typens:IntArray"/> </message>
doOracleSearchResponse Message
This message returns the search result in OracleSearchResult data type.
<message name="doOracleSearchResponse">
<part name="return" type="typens:OracleSearchResult"/>
</message>
doOracleBrowseSearch Message
This message restricts a search to a particular node. It consists of the following parameters:
-
query: A search string. It must be a valid string, and it cannot be null. The search string should follow Oracle SES query syntax. See "Query Web Services Query Syntax" for more details. -
nodeID: The ID of the node to restrict the search to. -
fedID: The ID of the federated instance the parent node belongs to (null for local node). -
startIndex: The index of the first result to be returned. For example, if there are 67 results, then you might want to start at 20. The default is 1 if not set explicitly. -
docsRequested: The maximum number of results to be returned. The default is 10 if not set explicitly. -
dupRemoved: Enable or disable duplicate removal. If turned on, then the search result eliminate all near duplicate documents from the result list, and thedupMarkedswitch have no effect whendupRemovedis turned on. The default is false if not set explicitly. -
dupMarked: Enable or disable duplicate detection. IfdupRemovedis turned off anddupMarkedis turned on, then the search result keeps all near duplicate documents from the result list and marks them as duplicates. IfdupRemovedis turned on, then thedupMarkedswitch has no effect. The default is false if not set explicitly. -
queryLang: The query language argument should be a valid ISO language code. These codes are the lower-case, two-letter codes as defined by ISO-639. Examples: "en" for English and "de" for German. The default is English ("en") if not set explicitly. This is used for relevancy boosting. -
docLang: Set the language of the documents to limit the search. If the value is not set explicitly, then search is performed against documents of all the languages. -
returnCount: Set to true to return total hit count with the result. The default is false if not set explicitly. -
fetchAttributes: Array of integers representing the nondefault attribute IDs to be fetched in theresultElements. The default is null (or set one int value '0'), so no attributes other than default-attributes are fetched in theresultElements.
<message name="doOracleBrowseSearch">
<part name="query" type="xsd:string"/>
<part name="nodeID" type="xsd:string"/>
<part name="fedID" type="xsd:string"/>
<part name="startIndex" type="xsd:int"/>
<part name="docsRequested" type="xsd:int"/>
<part name="dupRemoved" type="xsd:boolean"/>
<part name="dupMarked" type="xsd:boolean"/>
<part name="queryLang" type="xsd:string"/>
<part name="docLang" type="xsd:string"/>
<part name="returnCount" type="xsd:boolean"/>
<part name="fetchAttributes" type="typens:IntArray"/>
</message>
doOracleBrowseSearchResponse Message
Returns the search result in OracleSearchResult data type.
<message name="doOracleBrowseSearchResponse">
<part name="return" type="typens:OracleSearchResult"/>
</message>
doOracleSimpleSearch Message
A simplified form of the doOracleSearch message. In this message you do not need to specify the advanced search parameters that are specified in the doOracleSearch message. It consists of following parameters:
-
query: A search string. It must be a valid string and it cannot be null. The search string should follow Oracle SES query syntax. See "Query Web Services Query Syntax" for details. -
startIndex: The index of the first result to be returned. For example, if there are 67 results, you might want to start at 20. The default is 1, if not set explicitly. -
docsRequested: The maximum number of results to be returned. The default is 10, if not set explicitly. -
dupRemoved: Enable or disable duplicate removal. If turned on, then the search result eliminates all near duplicate documents from the result list. ThedupMarkedswitch has no effect whendupRemovedis turned on. The default is false if not set explicitly. -
dupMarked: Enable or disable duplicate detection. IfdupRemovedis turned off anddupMarkedis turned on, then the search result keeps all near duplicate documents from the result list and marks them as duplicates. IfdupRemovedis turned on, then thedupMarkedswitch has no effect. The default is false if not set explicitly. -
returnCount: Set to true to return total hit count with the result. The default is false if not set explicitly.
<message name="doOracleSimpleSearch"> <part name="query" type="xsd:string"/> <part name="startIndex" type="xsd:int"/> <part name="docsRequested" type="xsd:int"/> <part name="dupRemoved" type="xsd:boolean"/> <part name="dupMarked" type="xsd:boolean"/> <part name="returnCount" type="xsd:boolean"/> </message>
doOracleSimpleSearchResponse Message
Returns the search result in OracleSearchResult data type.
<message name="doOracleSimpleSearchResponse"> <part name="return" type="typens:OracleSearchResult"/> </message>
doOracleFacetSearch Message
Invokes Oracle SES faceted search and returns search results. It consists of the following parameters:
-
query: The search string. This should follow Oracle SES query syntax. See "Query Web Services Query Syntax" for details. -
topN: Top N search result for grouping, sorting, and clustering. -
startIndex: Index of the first document in the hit list to be returned. The default is 1 if not set explicitly. -
docsRequested: The maximum number of documents in the hit list to be returned. The default is 10 if not set explicitly. -
dupRemoved: Boolean flag to enable or disable duplicate removal. If turned on, then duplicate documents in the hit list are removed. The default is false if not set explicitly. Note: ThedupMarkedswitch has no effect whendupRemovedis turned on. -
dupMarked: Boolean flag to enable or disable duplicate detection. The default is false if not set explicitly. Note: ThedupMarkedswitch has no effect whendupRemovedis turned on. -
groups: Data source groups that the search is restricted to. The default is all groups if not set explicitly. -
queryLang: Language of the query. This is equivalent to Locale. The default is English (en) if not set explicitly. This is used in relevancy boosting. -
docLang: Language of the documents to restrict the search. If the value is not set explicitly, then search is performed against documents of all the languages. -
returnCount: Boolean flag to fetch the total hit count with the result. The default is false if not set explicitly. -
filterConnector: Connector between all the filters: "and" indicates that the documents in the hit list must satisfy all the filters, and "or" indicates that the documents in the hit list must satisfy at least one filter. The default is "and" if not set explicitly. -
filters: An array of filters. Each filter is a restriction on the search result. Filters are connected by thefilterConnector. The default is null (no filter applies to the search result) if not set explicitly. -
fetchAttributeNames: Array of strings representing the names of custom or nondefault attributes to be fetched with the search result. -
groupAttr: Attributes used for grouping. -
sortAttrList: List of sortable attributes settings. -
clusterList: List of cluster configurations. -
facetPaths: List of facet values in the form of facet path string. Each facet path denotes one facet tree, with the root being the facet name. For example,Bath/Faucets/Showersearches for/Faucets/Showerfacet values under theBathfacet.Note:
IffacetPathsparameter is set tonullor is assigned only the root level facet names, then the facets are used for grouping the search results and are not used for filtering the search results. The search results will contain all the documents matching the query criteria and will be grouped according to the root level facets.You can also specify per-facet limits, such as -
returnFacetDocCount,minFacetDocCount,maxFacetChildren, andsortBy- as comma separated name-value pairs in the facet path string.For example:
facetPaths[0] = Facet=Location, Path=Location/California, minFacetDocCount=1, maxFacetChildren=5, returnFacetDocCount=true, sortBy=ALPHA_ASC facetPaths[1] = Facet=Food, Path=Food/Vegetable/Cabbage, minFacetDocCount=1, maxFacetChildren=5, returnFacetDocCount=true , sortBy= ALPHA_ASC facetPaths[2] = Facet=Author, Path=Author, minFacetDocCount=1, maxFacetChildren=10, returnFacetDocCount=true, sortBy=COUNT_DES
You can also specify per-request facet limits using separate parameters -
returnFacetDocCount,minFacetDocCount,maxFacetChildren, andsortBy- of thedoOracleFacetSearch()API method, which are described in the following paragraphs. Per-facet limits take precedence over per-request facet limits. If these facet limits are not specified at per-facet level as well as at per-request level, then default values are used for the facet limits.Note:
If a facet path parameter value has either character "=" or character "," in it, then that value must be enclosed in double quotes. If a parameter value contains any double quote character, then the backslash character "\" should be used to escape the double quote character.For example:
Facet="Price, \"random\""
-
returnFacetDocCount: A boolean flag indicating whether to return document count for each facet. Default isTRUE. -
minFacetDocCount: Minimum number of document count to return for a facet node for each facet. Default is 0. -
maxFacetChildren: Maximum number of child nodes to return for each facet and facet node. Default is 5. The 0 value denotes no child nodes should be returned. The -1 value denotes all the child nodes should be returned. -
sortBy: A constant value denoting the sort order of facet child nodes. The supported values are:-
COUNT_ASC: Sort facet nodes in the ascending order of document count. -
COUNT_DES: Sort facet nodes in the descending order of document count. -
ALPHA_ASC: Sort facet nodes in the alphabetically ascending order of their names. -
ALPHA_DES: Sort facet nodes in the alphabetically descending order of their names. -
FIXED: Return facet nodes in the order they are configured in the facet tree.
Default is
COUNT_DES. -
-
searchControls: An XML string to specify advanced filter conditions and ranking parameters.
public OracleFacetResultContainer doOracleFacetSearch(
String query,
Integer topN,
Integer startIndex,
Integer docsRequested,
Boolean dupRemoved,
Boolean dupMarked,
DataGroup[] groups,
String queryLang,
String docLang,
Boolean returnCount,
String filterConnector,
Filter[] filters,
String[] fetchAttributeNames,
GroupAttribute groupAttr,
SortAttribute[] sortAttrList,
ClusterConfig clusterList,
String[] facetPaths,
Boolean returnFacetDocCount,
Integer minFacetDocCount,
Integer maxFacetChildren,
String sortBy,
String searchControls)
throws Exception
getSuggestedContent Message
Returns the suggested content for the given query. It consists of the following parameters:
-
query: Query string -
returnType: Format in which the content is to be returned, eitherhtmlorxml. If no style sheet is configured for a given provider, then the return type is the return type of the content returned by the provider, regardless of whetherhtmlorxmlis specified.
<message name="getSuggestedContent"> <part name="query" type="xsd:string"/> <part name="returnType" type="xsd:string"/> </message>
getSuggestedContentResponse Message
Returns the suggested content for the query.
<message name="getSuggestedContentResponse"> <part name="return" type="typens:SCElementArray"/> </message>
Browse Operations
This section describes the following browse operations:
getInfoSourceNodesRequest Message
Obtains the list of info source nodes given the parent node ID. It consists of the following parameters:
-
parentNodeID: The node ID for which all children nodes are returned. If it is not set, then the message returns all the root nodes. -
fedID: The ID of the federated instance the parent node belongs to (null for local node). -
locale: A two letter representation of locale. The default is English ("en") if not set explicitly.
<message name="getInfoSourceNodesRequest">
<part name="parentNodeID" type="xsd:string"/>
<part name="fedID" type="xsd:string"/>
<part name="locale" type="xsd:string"/>
</message>
getInfoSourceNodesResponse Message
Returns an array of info source nodes.
<message name="getInfoSourceNodesResponse">
<part name="nodes" type="typens:NodeArray"/>
</message>
getInfoSourceAncestorNodesRequest Message
Obtains the full path of a node, from root to node, given an info source node. It consists of the following parameters:
-
nodeID: The node ID for which all the nodes in the path from root to node are returned; nodeID must be set and it cannot be null. -
locale: A two letter representation of locale. The default is English ("en") if not set explicitly.
<message name="getInfoSourceAncestorNodesRequest">
<part name="nodeID" type="xsd:string"/>
<part name="locale" type="xsd:string"/>
</message>
Note:
ThegetInfoSourceAncestorNode messages have been deprecated in Oracle SES.getInfoSourceAncestorNodesResponse Message
Returns an array of info source ancestor nodes.
<message name="getInfoSourceAncestorNodesResponse">
<part name="nodes" type="typens:NodeArray"/>
</message>
getInfoSourceNodeRequest Message
Retrieves a particular node. It consists of the following parameters:
-
nodeID: The node ID of the node to get, nodeID must be set and it cannot be null. -
fedID: The ID of the federated instance the parent node belongs to (null for local node). -
locale: A two letter representation of Locale, the default is English ("en") if not set explicitly.
Message format:
<message name="getInfoSourceNodeRequest"> <part name="nodeID "type="xsd:string"/> <part name="fedID" "type="xsd:string"/> <part name="locale "type="xsd:string"/> </message>
getInfoSourceNodeResponse Message
This message returns the node requested.
<message name="getInfoSourceNodeResponse">
<part name="node "type="typens:Node"/>
</message>
Metadata Operations
This section describes the following metadata operations:
getLanguageRequest Message
Obtains all the languages supported by Oracle SES. It is used by the client application to display the list of languages. It consists of the following parameter:
locale: A two letter representation of locale. The default is English (en) if not set explicitly.
<message name="getLanguagesRequest">
<part name="locale" type="xsd:string"/>
</message>
getLanguageResponse Message
This message returns all supported languages.
<message name="getLanguagesResponse">
<part name="return" type="typens:LanguageArray"/>
</message>
getDataGroupsRequest Message
Requests for all source groups defined in Oracle SES. It is used by the client application to show all source groups in the search page, such that the end user can restrict their search results within one or multiple source groups. It consists of the following parameter:
locale: A two letter representation of locale. The default is English (en) if not set explicitly.
<message name="getDataGroupsRequest">
<part name="locale" type="xsd:string"/>
</message>
getDataGroupsResponse Message
Returns all source groups defined in Oracle SES.
<message name="getDataGroupsResponse">
<part name="groups" type="typens:DataGroupArray"/>
</message>
getAttributesRequest Message
Obtains a list of search attributes that applied to the given source groups. It consists of the following parameters:
-
locale: A two letter representation of locale. The default is English (en) if not set explicitly. -
groups: Limit the request to the attributes from specified source groups. The default is all groups if not set explicitly. -
groupConnector: The connector between all groups: "and" indicates the response is the attributes available in the set of source groups by finding the intersection of each group's attributes, "or" indicates the response is the attributes available in the set of source groups by finding the union of each group's attributes. The default is "or" if not set explicitly.
<message name="getAttributesRequest">
<part name="locale" type="xsd:string"/>
<part name="groups" type="typens:DataGroupArray"/>
<part name="groupConnector" type="xsd:string"/>
</message>
getAttributesResponse Message
Returns an array of search attributes.
<message name="getAttributesResponse">
<part name="return" type="typens:AttributeArray"/>
</message>
getAllAttributesRequest Message
Obtains all search attributes defined in Oracle SES. It consists of the following parameter:
locale: A two letter representation of locale. The default is English (en) if not set explicitly.
<message name="getAllAttributesRequest"> <part name="locale" type="xsd:string"/> </message>
getAllAttributesResponse Message
Returns all search attributes defined in Oracle SES.
<message name="getAllAttributesResponse">
<part name="return" type="typens:AttributeArray"/>
</message>
getAttributeLOVRequest Message
Obtains the LOV items given a search attribute. It consists of the following parameters:
-
attribute: A search attribute for the LOV (list of values) requested. -
locale: A two letter representation of locale. The default is English ("en") if not set explicitly.
<message name="getAttributeLOVRequest"> <part name="attribute" type="typens:Attribute"/> <part name="locale" type="xsd:string"/> </message>
getAttributeLOVResponse Message
Returns an array of search attribute LOV elements.
<message name="getAttributeLOVResponse"> <part name="return" type="typens:AttributeLOVElementArray"/> </message>
getFacetNodes Message
Returns an array of facet child nodes having non-zero document count for facet tree paths. It consists of the following parameters:
-
facetPaths: An array of facet tree path for which child facet nodes are to be returned.You can also specify per-facet limits, such as -
returnFacetDocCount,minFacetDocCount,maxFacetChildren, andsortBy- as comma separated name-value pairs in the facet path string.For example:
facetPaths[0] = Facet=Location, Path=Location/California, minFacetDocCount=1, maxFacetChildren=5, returnFacetDocCount=true, sortBy=ALPHA_ASC facetPaths[1] = Facet=Food, Path=Food/Vegetable/Cabbage, minFacetDocCount=1, maxFacetChildren=5, returnFacetDocCount=true , sortBy= ALPHA_ASC facetPaths[2] = Facet=Author, Path=Author, minFacetDocCount=1, maxFacetChildren=10, returnFacetDocCount=true, sortBy=COUNT_DES
You can also specify per-request facet limits using separate parameters -
returnFacetDocCount,minFacetDocCount,maxFacetChildren, andsortBy- of thegetFacetNodes()API method, which are described in the following paragraphs. Per-facet limits take precedence over per-request facet limits. If these facet limits are not specified at per-facet level as well as at per-request level, then default values are used for the facet limits.Note:
If a facet path parameter value has either character "=" or character "," in it, then that value must be enclosed in double quotes. If a parameter value contains any double quote character, then the backslash character "\" should be used to escape the double quote character.For example:
Facet="Price, \"random\""
-
returnFacetDocCount: A boolean flag indicating whether to return document count for each facet. Default isTRUE. -
minFacetDocCount: Minimum number of document count to return for a facet node in each facet. Default is 0. -
maxFacetChildren: Maximum number of child nodes to return for each facet. Default is 5. The 0 value denotes no child nodes should be returned. The -1 value denotes all the child nodes should be returned. -
sortBy: A constant value denoting the sort order of facet child nodes. The supported values are:-
COUNT_ASC: Sort facet nodes in the ascending order of document count. -
COUNT_DES: Sort facet nodes in the descending order of document count. -
ALPHA_ASC: Sort facet nodes in the alphabetically ascending order of their names. -
ALPHA_DES: Sort facet nodes in the alphabetically descending order of their names. -
FIXED: Return facet nodes in the order they are configured in the facet tree.
Default is
COUNT_DES. -
-
locale: A two letter representation of locale. The default is English (en) if not set explicitly. -
searchControls: An XML string to specify advanced filter conditions and ranking parameters.
public FacetNode[] getFacetNodes(
String[] facetPaths,
Boolean returnFacetDocCount,
Integer minFacetDocCount,
Integer maxFacetChildren,
String sortBy,
String locale,
String searchControls)
throws Exception
addTag Message
Specifies a tag for a document. Returns boolean value of true if the tag addition operation is successful, else returns false. It consists of the following parameters:
-
docID: Document ID. -
fedID: Federation ID. -
tag: Name for the tag. -
username: Name of the user adding the tag.
public boolean addTag(
Integer docID,
Integer fedID,
String tag,
String username)
throws Exception
deleteTag Message
Deletes a tag for a document. Returns boolean value of true if the tag deletion operation is successful, else returns false. It consists of the following parameters:
-
docID: Document ID. -
fedID: Federation ID. -
tag: Name for the tag. -
username: Name of the user deleting the tag. -
ctlParams: Control parameters.
public boolean deleteTag(
Integer docID,
Integer fedID,
String tag,
String username,
String ctlParams)
throws Exception
Search Hit Operations
This section describes the following search hit operations:
getCachedPageRequest Message
Obtains the cached version of a document given the document ID and the search string. The search string is highlighted in the output. It consists of the following parameters:
-
query: The search string. -
docID: The document ID to be fetched. -
fedID: The federated instance ID, used to track which federated instance the document is fetched from.
<message name="getCachedPageRequest">
<part name="query" type="xsd:string"/>
<part name="docID" type="xsd:int"/>
<part name="fedID" type="xsd:string"/>
</message>
getCachedPageResponse Message
Returns the byte array of the cached HTML page.
<message name="getCachedPageResponse">
<part name="return" type="xsd:base64Binary"/>
</message>
getInLinksRequest Message
Obtains all the incoming links for a given search hit (document). It consists of the following parameters:
-
docID: The document ID for the incoming links to be fetched. It must be a valid document ID and it cannot be null. -
maxNum: The maximum number of incoming links requested. The default is 25 if not set explicitly. -
fedID: The federated instance ID, used to track which federated instance the document is fetched from.
<message name="getInLinksRequest">
<part name="docID" type="xsd:int"/>
<part name="maxNum" type="xsd:int"/>
<part name="fedID" type="xsd:string"/>
</message>
getInLinksResponse Message
Returns an array of incoming link URL strings.
<message name="getInLinksResponse">
<part name="return" type="typens:StringArray"/>
</message>
getOutLinksRequest Message
Obtains all the outgoing links for a given search hit (document). It consists of the following parameters:
-
docID: The document ID for the outgoing links to be fetched. It must be a valid document ID and it cannot be null. -
maxNum: The maximum number of outgoing links requested. The default is 25 if not set explicitly. -
fedID: The federated instance ID, used to track which federated instance the document is fetched from.
<message name="getOutLinksRequest">
<part name="docID" type="xsd:int"/>
<part name="maxNum" type="xsd:int"/>
<part name="fedID" type="xsd:string"/>
</message>
getOutLinksResponse Message
This message returns an array of outgoing link URL strings.
<message name="getOutLinksResponse">
<part name="return" type="typens:StringArray"/>
</message>
logUserClickRequest Message
This message logs the user's click. It consists of the following parameters:
-
queryID: ID of the submitted search. -
urlID: ID of the document that the user clicked. -
infosourceID: Infosource ID. If none, then -1 is used as the default value -
position: The position of the document in the result list. For example, the first hit on the page or ninth hit on the page. -
fedID: Federation ID. Specifies the federated instance on which the document resides.
<message name="logUserClickRequest">
<part name="queryID" type="xsd:int"/>
<part name="urlID" type="xsd:int"/>
<part name="infoSourceID" type="xsd:int"/>
<part name="position" type="xsd:int"/>
<part name="fedID" type="xsd:string"/>
</message>
logUserClickResponse Message
Returns the URL of the clicked document.
<message name="logUserClickResponse"> <part name="url" type="xsd:string"/> </message>
User Feedback Operations
This section describes the following user feedback operations:
submitUrlRequest Message
Submits a URL to Oracle SES so that it crawls and indexes the URL. This operation consists of the following parameter:
-
url: The URL to be submitted to the crawler so it can be crawled next time. It must be a valid URL and it cannot be null.
<message name="submitUrlRequest">
<part name="url" type="xsd:string"/>
</message>
submitUrlResponse Message
Returns the status, which consists of two strings. The first is the submission status, which is either successful or failed. The second string is the error message when the submission status is failed.
<message name="submitUrlResponse">
<part name="return" type="typens:Status"/>
</message>
Query Web Services Query Syntax
This section describes the query syntax used in the Oracle Secure Enterprise Search Search API.
Search Term
A search term can be a single word, a phrase, or a special search term. For example, if the search string is oracle secure enterprise search, then there are four search terms in the search string: oracle, secure, enterprise, and search. If the search string is oracle "secure enterprise search", then there are two search terms in the search string: oracle and "secure enterprise search".
Search terms are case insensitive so that different cases are treated the same. For example, searching oracle, Oracle, or ORACLE returns the same search result.
Operators
The following operators are defined in the query syntax:
-
Plus [+]: The plus operator specifies that the search term immediately following it must be found in all matching documents. For example, searching for [Oracle +Applications] only finds documents that contain the word "Oracle" and "Applications". In a multiple word search, you can attach a [+] in front of every token including the very first token. You can also attach a [+] in front of a phrase enclosed in double-quotes ("). But there should be no space between the [+] and the search term.
-
Minus [-]: The minus operator specifies that the search term immediately following it cannot appear in any document included in the search result. For example, searching for [Oracle -Applications] only finds documents that do not contain the word "Applications". In a multiple word search, you can attach a [-] in front of every token except the very first token. It can be a single word or a phrase, but there should be no space between the [-] and the token.
-
Asterisk [*]: The asterisk specifies a wildcard search. For example, searching for the string [Ora*] finds documents that contain all words beginning with "Ora" such as "Oracle" and "Orator". You can also insert an asterisk in the middle of a word. For example, searching for the string [A*e] finds documents that contain words such as "Apple" or "Ape".
Default Search: Implicit AND
By default, Oracle SES searches all of your search terms and relevant variations of the terms you entered. You do not need to include any operators (like AND) between terms. The order of the terms in the search affects the search results.
Filter Conditions (Advanced Conditions)
Oracle SES query syntax only supports 'Site' and 'File type' filter conditions. It does not support any other filter conditions (advanced conditions) such as title, author, or last modified date. To restrict your search with other filter conditions, you can specify them in the Web Services API message doOracleSearch.
Special Search Terms
Oracle SES supports the use of several special search terms that allow the user or search administrator to access additional capabilities of the Oracle SES. Following is the list of special search terms:
Exclude Search Term
You can exclude a word from your search by putting a minus sign [-] immediately in front of the term you want to exclude from the search results. Exclusion does not work with stop words.
Example: oracle -search
Negative search is not allowed unless there is another positive search term. For example:
-search is an invalid search.
oracle -search is a valid search.
Wildcard Search
You can use an asterisk to match any number of characters in the middle or the end of a search term. You cannot place it at the beginning, such as searching for *earch.
Example: Ora*
Phrase Search
Search for complete phrases by enclosing them in quotation marks. Words marked in this way appear together in all results exactly as entered.
Example: "oracle secure enterprise search"
Site Restricted Search
If you know the specific Web site you want to search, but are not sure where the information is located within that site, then search only within the specific Web site. Enter the search followed by the string site: followed by the host name.
Example: oracle site:example.com
Notes:
-
Domain restriction is not supported, because Oracle SES does not support left-truncated wildcard search (such as *.example.com)
-
The exclusion operator (-) can be applied to this search term to remove a Web site from consideration in the search.
-
Site restricted search term is implicit AND with other search terms.
-
Only one site restriction is allowed. Also, you cannot have both site inclusion and exclusion in the search string. For example, the following search string is invalid:
oracle search site:www.oracle.com -site:otn.oracle.com
File Type Restricted Search
The search prefix filetype: filters the results returned to include only documents with the extension specified immediately after. There can be no space between filetype: and the specified extension.
Example: oracle filetype:doc
Notes:
-
The exclusion operator (-) can be applied to this search term to remove a file type from consideration in the search.
-
Only one file type can be included. The following extensions are supported: doc, htm, html, xml, ps, pdf, txt, rtf, ppt, and xls. doc, html, pdf, txt, rtf, ppt, xls.
-
File type restricted search term is implicit AND with other search terms.
-
Only one file type restriction is allowed. Also, you cannot have both file type inclusion and exclusion in the search string. For example, the following search string is invalid:
oracle search filetype:doc -filetype:pdf
Query Web Services Example: Basic Search
Following is a simple JSP application using Oracle Secure Enterprise Search proxy Java library to provide the basic search functionality:
<%@page contentType="text/html; charset=utf-8" %>
<%@page import = "java.util.Vector" %>
<%@page import = "java.net.URL" %>
<%@page import = "java.util.Properties" %>
<%@page import = "java.util.HashMap" %>
import javax.xml.rpc.Stub;
<%@page import = "oracle.search.query.webservice.client.*" %>
<%
//
// Get the search term entered by the user
//
String searchTerm = request.getParameter("searchTerm");
if (searchTerm == null) searchTerm = "";
//
// Define the result element array.
//
// ResultElement is a proxy Java class
ResultElement[] resElemArray = null;
int estimatedHitCount = 0;
if (searchTerm != null && !"".equals(searchTerm))
{
//
// Create the Oracle SES Web Services client stub
//
OracleSearchService stub = new OracleSearchService();
//
// Set the Oracle SES Web Services URL.
// The URL is http://<host>:<port>/search/query/OracleSearch
//
stub.setSoapURL("http://staca19:7777/search/query/OracleSearch");
//
// Get the search result by calling OracleSearchService.doOracleSearch()
//
OracleSearchResult result = stub.doOracleSearch(searchTerm,
new Integer(1),
new Integer(10),
Boolean.TRUE,
Boolean.TRUE,
null,
"en",
"en",
Boolean.TRUE,
null,
null,
null);
//
// Get the estimated hit count by calling
estimatedHitCount = result.getEstimatedHitCount().intValue();
// Get the search results
resElemArray = result.getResultElements();
}
%>
<HTML>
<HEAD>
<TITLE>Oracle SES Web Services Demo </TITLE>
</HEAD>
<BODY>
<FORM name="searchBox" method="post" action="./DemoWS.jsp">
<INPUT id="inputMain" type="text" size="40" name="searchTerm" value="<%=searchTerm%>">
<INPUT type="hidden" name="searchTerm" value="<%= searchTerm %>">
<INPUT type="submit" name="action" value="Search">
</FORM>
<BR><BR><BR>
<%
//
// Render the search results
//
if (resElemArray == null || resElemArray.length == 0)
{
%>
<H3> There are no matches for the search term </H3>
<%
}
else
{
%>
<H3> There are about <%=estimatedHitCount%> matches </H3>
<%
for (int i=0; i<resElemArray.length; i++)
{
String title = resElemArray[i].getTitle();
if (title == null) title = "Untitled Document";
%>
<P>
<B><A HREF="<%=resElemArray[i].getUrl()%>"><%=title%></A> </B>
<BR>
<%=resElemArray[i].getSnippet()%>
<BR>
</P>
<%
}
}
%>
</BODY>
</HTML>
Default-Factor Element
The default-factor element assigns a weight to an attribute.
<default-factor> <name>title</name> <weight>VERY HIGH</weight> </default-factor>
Default factor attribute names are case-insensitive.
When a default-factor does not appear in the ranking XML string, Oracle SES takes the default weight for this ranking factor, unless default factors are disabled by enable-all-default-factor.
Oracle SES supports the following values for weight element: empty (Oracle SES uses the default weight), none (this attributes is not used in the ranking query), very high, high, medium, low, and very low.
Table 13-3 lists the default-factor names and weights:
Table 13-3 Oracle SES Default Attributes and Weights
| Attribute | Weight |
|---|---|
|
|
High |
|
|
Medium |
|
|
High |
|
|
Medium |
|
|
Low |
|
|
Medium |
|
|
Low |
|
|
Very low |
|
|
Low |
|
|
High |
|
|
High |
|
|
High |
Note:
When display URL is not an absolute URL, for example, idcplg?IdcService=GET_FILE&dDocName=CNT104862&allowInterrupt=1&Rendition=web, or the depth of the URL does not have any bearing on the relevance of the document, then it is recommended to set the weight of urldepth to NONE, so that Oracle SES will not consider the depth of the URL in the final ranking order of the search result.
For example,
<default-factor> <name>urldepth</name> <weight>NONE</weight> </default-factor>
Query Web Services Example: Customizing Relevancy
The following is the signature of the method for advanced search:
public OracleSearchResult doOracleAdvancedSearch (
String query,
Integer startIndex,
Integer docsRequested,
Boolean dupRemoved,
Boolean dupMarked,
DataGroup groups[],
String queryLang,
String docLang,
Boolean returnCount,
String filterConnector,
Filter filters[],
Integer[] fetchAttributes,
String searchControls) throws Exception
The searchControls parameter accepts a XML string, which include the filter and ranking elements.
<searchControls>
<filter> ... </filter>
<ranking> ... </ranking>
</searchControls>
Filter Element
Filters for attribute search are passed in the filter element. All the various AND and OR conditions on the attributes are specified in the XML. For example:
<filter>
<operator type="and">
<operator type="or">
<attributefilter name="xxx" type="string" operation="equals" value="ttt"/>
<attributefilter name="yyy" type="number"
operation="greaterthan" value="22"/>
...
</operator>
...
<attributefiler name="aaa" type="number" operation="equals" value="22"/>
...
</operator>
</filter
If the parameter searchControls is null, then filters and filterConnector are used to create advanced search; otherwise, they are ignored.
Ranking Element
The ranking XML string is expressed as ranking element in searchControls. The following is an example of ranking element:
<ranking>
<global-settings>
<enable-all-default-factor>TRUE</enable-all-default-factor>
</global-settings>
<default-factor>
<!--default ranking factor -- >
...
</default-factor>
<default-factor>
<!--default ranking factor -- >
...
</default-factor>
<custom-factor>
<!--default ranking factor -- >
...
</custom-factor>
<custom-factor>
<!--default ranking factor -- >
...
</custom-factor>
<sortConditions>
<sortCondition order="ascending" type="system">Title</sortCondition>
</sortConditions>
</ranking>
The following rules apply to the construction of ranking XML string:
-
The whole ranking XML can be null, in which case default ranking is used.
-
The ranking XML contains the elements
default-factor,custom-factor, andsortConditions. All these elements can be null or absent at the same time. -
When
default-factoris null or absent and whencustom-factoris not null, default ranking is used with the effect ofcustom-factor. -
When
custom-factoris null or absent, it does not have any impact on the ranking.
global-settings Element
The global-settings element contains parameter settings across ranking factors. The ranking element has an attribute called enable-all-default-factor, which accepts two values: true or false. (When this attribute is absent, true is taken as the default value.)
When enable-all-default-factor is true, all default attributes are included in ranking queries, unless some default attributes are explicitly excluded in default-factor elements.
When enable-all-default-factor is false, all default attributes are excluded in ranking queries, unless some default attributes are explicitly included in default-factor elements.
custom-factor Element
The custom-factor element lets you add more attributes for ranking. Any indexed search attribute can be a custom ranking attribute.
Note:
Adding custom attributes for relevancy ranking can downgrade search performance.The custom-factor element has four elements: attribute-name, attribute-type, factor-type, and weight (or match depending on the factor-type).
<custom-factor>
<attribute-name>author manager</attribute-name>
<attribute-type>STRING</attribute-type>
<factor-type>QUERY_FACTOR</factor-type>
<weight>LOW</weight>
</custom-factor>
or
<custom-factor>
<attribute-name>document quality</attribute-name>
<attribute-type>STRING</attribute-type>
<factor-type>STATIC_FACTOR<factor-type>
<match>
<value>good</value>
<weight>HIGH</weight>
</match>
<match>
<value>fair</value>
<weight>MEDIUM</weight>
</match>
<match>
<value>bad</value>
<weight>VERY LOW</weight>
</match>
</custom-factor>
or
<custom-factor>
<attribute-name>sourcegroup</attribute-name>
<attribute-type>SYSTEM</attribute-type>
<factor-type>STATIC_FACTOR<factor-type>
<match>
<value>Corporate Site</value>
<weight>VERY HIGH</weight>
</match>
<match>
<value>Blogs</value>
<weight>VERY LOW</weight>
</match>
<match>
<value>Documentation</value>
<weight>VERY LOW</weight>
</match>
</custom-factor>
-
The
attribute-namevalues are literally matched against attribute name in Oracle SES. Any indexed search attribute name can beattribute-namevalue. The value of theattribute-nameelement is case-insensitive. -
The
attribute-typeelement defines the type of the attribute. String and System attribute types are supported. Attribute-name and attribute-type in combination define a valid Oracle SES attribute.Note:
System attribute type supports only the attribute-name sourcegroup, which represents the source group name. For System attribute type, the factor-type value must be "STATIC_FACTOR" as user's query is not applicable to source groups. -
For
factor-type, Oracle SES supports two types of ranking for custom ranking attributes.-
QUERY_FACTOR: The attribute value is matched against query terms. A positive match boosts the document based on specified weight.QUERY_FACTORis a query-based ranking factor; for example, title and reftext. Theweightelement should appear for this custom ranking factor. For example, with the query "Roger Federer", if a document has a custom attribute publisher with the value "Roger Federer", then it could be relevant. -
STATIC_FACTOR: Attribute value is matched against fixed values specified in the custom ranking factor. (Thematchelement should appear for this custom ranking factor.)STATIC_FACTORis not a query-based ranking factor. The fixed values specify qualities of the documents, such as the link score and the sources of documents. For example, assume that documents have been classified based on quality. Well-written documents are classified as good, and poorly-written documents are classified as bad. A good document should be ranked higher than a bad document, even though they are both matched against a query. You can specify in the API that a document having a good quality should be boosted in relevancy by a specified weight.
-
-
The
matchelement specifies the match values and corresponding match weights when thefactor-typeisSTATIC_FACTOR. The following XML string is a example ofmatchelement:<match> <value>bad</value> <weight>VERY LOW</weight> </match>
-
The
valueelement is used to match the corresponding attribute value of this ranking factor. Only alphanumeric letters are allowed in the attribute value. The match is case-insensitive. -
The
weightelement has the identical syntax withweightelement for default ranking element.
sortConditions Element
The sortConditions element defines one or more sort conditions for Absolute sort. Each Absolute sort condition is specified using the sortCondition child element of the sortConditions element. The value of the sortCondition element denotes the sortable attribute name.
The order parameter of the sortCondition element denotes the sort order for the specified sortable attribute. The sort order can have the value of either ascending or descending.
The type parameter of the sortCondition element denotes the attribute type of the specified sortable attribute. For a sortable search attribute, specify its value as attribute, and for a sortable system attribute, specify its value as system.
The following example specifies an Absolute sort criteria for sorting the search result based on the sortable system attribute Title in the ascending order.
<sortConditions> <sortCondition order="ascending" type="system">Title</sortCondition> </sortConditions>
See Also:
"Configuring Sort Criteria using Sortable Attributes (Absolute Sort)" for more information about configuring sort criteria for Absolute sort.Applying Ranking Factors
The XML ranking text can be applied in two places:
-
As a part of the
searchControlselement, the ranking factors can be used as an advanced control for each query execution through the Web services method. This is called per-query ranking control. -
The ranking factors specified in the
relevanceRankingobject of the Administration API are applied to all queries. This is called instance-wide ranking control.
In federated search, instance-wide ranking controls only applies to one instance. You must configure each instance for ranking customization separately.
If a conflict arises, the per-query ranking control specified in Web services method overrides the settings specified in instance-wide ranking control. That can include the following cases:
-
Per-query and instance-wide ranking specify the same factor, the factor set by per-query is taken by Oracle SES.
-
Instance-wide ranking control sets a ranking factor, but per-query ranking control does not mention. Oracle SES takes the factor set by instance-wide ranking control.
-
Per-query ranking control sets a ranking factor, which instance-wide ranking controls does not mention. Oracle SES takes the factor set by per-query ranking control.
-
If instance-wide ranking control sets
enable-all-default-factoras false and per-query ranking control setsenable-all-default-factoras true, then Oracle SES takes the default attributes set explicitly by instance-wide ranking control plus the attributes set by per-query ranking controls, with the latter overriding the former.
Client-Side Query Java Proxy Library
Oracle SES also provides client-side Java proxies for marshalling and parsing Web Services SOAP messages. Client applications can use the library to access Oracle SES Web Services.
The proxy library includes the following Java classes, which are mapped to the corresponding Web Services data types and messages:
-
oracle.search.query.webservice.client.Attribute -
oracle.search.query.webservice.client.AttributeLOVElement -
oracle.search.query.webservice.client.ClusterAttribute -
oracle.search.query.webservice.client.ClusterConfig -
oracle.search.query.webservice.client.ClusterTree -
oracle.search.query.webservice.client.CustomAttribute -
oracle.search.query.webservice.client.DataGroup -
oracle.search.query.webservice.client.Filter -
oracle.search.query.webservice.client.GroupAttribute -
oracle.search.query.webservice.client.GroupingResult -
oracle.search.query.webservice.client.Language -
oracle.search.query.webservice.client.Node -
oracle.search.query.webservice.client.OracleSearchResult -
oracle.search.query.webservice.client.OracleSearchService -
oracle.search.query.webservice.client.ResultElement -
oracle.search.query.webservice.client.SCElement -
oracle.search.query.webservice.client.SessionContextElement -
oracle.search.query.webservice.client.SortAttribute -
oracle.search.query.webservice.client.Status -
oracle.search.query.webservice.client.SuggestedLink
To compile and run your client application using the Oracle SES client-side Java proxy library, unzip the file wls_home/server/lib/wseeclient.zip, and include all the jar files present in this zip file in the Java CLASSPATH.
Also include the following jar files in the Java CLASSPATH:
-
wls_home/server/lib/weblogic.jar -
mw_home/modules/org.apache.ant_1.7.1/lib/ant.jar -
mw_home/oracle_common/modules/oracle.webservices_11.1.1/ oracle.webservices.standalone.client.jar -
ses_home/search/lib/search_client.jar -
ses_home/search/lib/plugins/cservices/jaxrpc.jar
Oracle Secure Enterprise Search Java SDK
The Oracle Secure Enterprise Search Java SDK contains the following APIs:
-
See Also:
Building Custom Crawlers white paper for detailed information about how to build secure crawlers:http://www.oracle.com/technetwork/search/oses/overview/buidling-custom-crawlersjan12-07-1-133233.doc
Crawler Plug-in API
You can implement a crawler plug-in to crawl and index a proprietary document repository. In Oracle SES, the proprietary repository is called a user-defined source. The module that enables the crawler to access the source is called a crawler plug-in (or connector).
The plug-in collects document URLs and associated metadata from the user-defined source and returns the information to the Oracle SES crawler. The crawler starts processing each URL as it is collected.
The crawler plug-in must be implemented in Java using the Oracle SES Crawler Plug-in API. Crawler plug-ins can be either stored in the ses_home/search/lib/plugins directory and accessed using their relative file path, or stored in any other directory and accessed using their absolute file path.
These are the basic steps to build a crawler plug-in:
-
Compile and build the plug-in jar file.
The Java source code for the plug-in first must be compiled into class files and put into a jar file in the
ses_home/search/lib/plugins/directory. The library needed for compilation isses_home/search/lib/search_sdk.jar. -
Create a source type.
Before you can create a source for the crawler plug-in, you first must create a source type for it. From the Oracle SES Administration GUI, go to the Global Settings - Source Types page and provide the Java class name and jar file name (created in the previous step).
-
Create a source.
From the Home - Sources page, create a source from the source type you just created. You also must define the parameter for the source type just created.
For example, suppose you want to crawl
/scratch/teston a Linux box for the file crawler plug-in. Specify the seed URL, for example,file://localhost/scratch/test. -
Run the crawler plug-in.
From the Home - Schedules page, start the schedule for the crawler.
This section includes the following topics:
Crawler Plug-in Overview
The following diagram illustrates the crawler plug-in architecture.
Description of the illustration ''benri010.gif''
Two interfaces in the Crawler Plug-in API (CrawlerPluginManager and CrawlerPlugin) must be implemented to create a crawler plug-in. A crawler plug-in does the following:
-
Provides the metadata of the document in the form of document attributes.
-
Provides access control list information (ACL) if the document is protected.
-
Maps each document attribute to a common attribute name used by end users.
-
Optionally provides the list of URLs that have changed since a given time stamp.
-
Optionally provides an access URL in addition to the display URL for the processing of the document.
-
Provide the document contents in the form of a Java Reader. In other words, the plug-in is responsible for fetching the document.
-
Can submit attribute-only documents to the crawler; that is, a document that has metadata but no document contents.
Document Attributes and Properties
Document attributes, or metadata, describe document properties. Some attributes can be irrelevant to your application. The crawler plug-in creator must decide which document attributes should be extracted and saved. The plug-in also can be created such that the list of collected attributes are configurable. Oracle SES automatically registers attributes returned by the plug-in. The plug-in can decide which attributes to return for a document.
Library Path and Java Class Path
Any other Java class needed by the plug-in should be included in the plug-in jar file. (You could add the paths for the additional jar files needed by the plug-in into the Class-Path of the MANIFEST.MF file in the plug-in jar file.) This is because Oracle SES automatically adds the plug-in jar file to the crawler Java class path, and Oracle SES does not let you add other class paths from the administration interface.
If the plug-in code also relies on a particular library file (for example, a .dll file on Windows or a .so file on UNIX), then the library must be put under the ses_home/lib directory or the ses_home/search/lib/plugins directory. The Java library path is set explicitly by the crawler to those locations.
You should use Java resource bundles instead of properties files whenever possible when developing a custom plug-in. If you must use the properties files as resource bundle files, then take these steps to ensure that the administration API loads the files properly.
To use properties files as resource bundles files:
-
Add the path of
sourceTypeJarPackageNameinto the classpath variable inses_home/search/config/searchctl.conf -
Restart the middle tier.
Crawler Plug-in Restrictions
The plug-in must handle mimetype rejection and large document rejection itself. For example, the plug-in should reject files it does not want to index based on its type or size, such as zip files. Also, plain text files, such as log files, can grow very large. Because the crawler reads HTML and plain text files into memory, it could run out of memory with very large files.
Crawler Plug-in Functionality
This section describes aspects of the crawler plug-in.
Source Registration
Source registration is automated. After a source type is defined, any instance of that source type can be defined:
-
Source name
-
Description of the source; limit to 4000 bytes
-
Source type ID
-
Default language; default is
en(English) -
Parameter values; for example:
seed - http://www.oracle.com depth - 8
Source Attribute Registration
You can add new attributes to Oracle SES by providing the attribute name and the attribute data type. The data type can be string, number, or date. Attributes returned by an plug-in are automatically registered if they have not been defined.
User-Implemented Crawler Plug-in
The crawler plug-in has the following requirements:
-
The plug-in must be implemented in Java.
-
The plug-in must support the Java plug-in APIs defined by Oracle SES.
-
The plug-in must return the URL attributes and properties.
-
The plug-in must decide which document attributes Oracle SES should keep. Any attribute not defined in Oracle SES is registered automatically.
-
The plug-in can map attributes to source properties. For example, if an attribute ID is the unique ID of a document, then the plug-in should return (document_key, 4) where
IDhas been mapped to the propertydocument_keyand its value is 4 for this particular document. -
If the attribute LOV is available, then the plug-in returns them upon request.
Crawler Plug-in APIs and Classes
The Crawler Plug-in API is a collection of classes and interfaces of the Java SDK package oracle.search.sdk.crawler that is used to implement a crawler plug-in.
Table 13-4 Crawler Plug-in Interfaces and Classes
| Interface/Class | Description |
|---|---|
|
|
This interface is used by the crawler plug-in to integrate with the Oracle SES crawler. The Oracle SES crawler loads the plug-in manager class and invokes the plug-in manager API to obtain the crawler plug-in instance. Each plug-in instance is run in a thread execution. |
|
|
This interface is used to generate the crawler plug-in instances. It provides general plug-in information for automatic plug-in registration on the administration page for defining user-defined source types. It has the control on which plug-in object (if multiple implementations are available) to return in The |
|
|
This interface is used by a crawler plug-in to perform crawl-related tasks. It has execution context specific to the crawling thread that invokes the plug-in |
|
|
This interface is implemented by the Oracle SES crawler and made available to the plug-in through the This interface is used by a crawler plug-in to manage the current crawled document set. |
|
|
This interface is used by a crawler plug-in to submit access control list (ACL) information for the document. |
|
|
This interface is used by a crawler plug-in to submit or retrieve document information. |
|
|
This interface holds a document's attributes and properties for processing and indexing. This interface is used by a crawler plug-in to submit URL-related data to the crawler. |
|
|
This interface is used by a document service plug-in to submit document attributes and/or document contents to the crawler. |
|
|
This interface is used to register the document service plug-in. It is also used by the crawler to create a DocumentService object. |
|
|
This interface provides Oracle SES service and implemented interface objects to the plug-in. It is implemented by the Oracle SES crawler and made available through plug-in manager initialization. This interface is used by a crawler plug-in to obtain Oracle SES interface objects. |
|
|
This interface is used by a crawler plug-in to output messages to the crawler log file. |
|
|
This interface is used by both the crawler and a source plug-in to set and retrieve attribute list of values (LOV) from the source. |
|
|
This interface for a crawler plug-in reads the value of the source parameter. |
|
|
This interface is implemented by the Oracle SES crawler and made available to the plug-in through the This interface is used by the crawler plug-in to submit URL-related data to the crawler. |
|
|
This class describes the general properties of a parameter. |
|
|
This provides a severity code to direct the crawler's response. |
|
|
This class encapsulates information about a data source plug-in-specific error. |
|
|
This class encapsulates information about errors from processing plug-in requests. |
|
|
The crawler manager class must implement this interface of the |
Document Service API
The Document Service API is a part of the Crawler Plug-in API and is used to create a document service plug-in. A document service plug-in is a Java class that implements the document service API interface DocumentServiceManager of the oracle.search.sdk.crawler package and is registered using Oracle SES Administration GUI.
See Also:
"Overview of Document Service"To create and use a document service plug-in:
-
Create a Java file (for example,
DocumentSummarizer.java) implementing theoracle.search.sdk.crawler.DocumentServiceinterface methodsinit,close, andprocess. -
Create another Java file (for example,
DocumentSummarizerManager.java) implementing theoracle.search.sdk.crawler.DocumentServiceManagerinterface. -
Compile all of the related Java files into class files. For example:
$java_home/bin/javac -classpath ses_home/search/lib/search_sdk.jar DocumentSummarizer.java DocumentSummarizerManager.java
-
Package all the class files into a jar file under the
ses_home/search/lib/plugins/docdirectory. For example:$java_home/bin/jar cv0f ses_home/search/lib/plugins/doc/extractor/extractor.jar DocumentSummarizer.class DocumentSummarizerManager.class
The above document service plug-in jar file can be deployed either under the
ses_home/search/lib/plugins/docdirectory and accessed using its relative file path, or under any other directory and accessed using its absolute file path. -
On the Global Setting - Document Service page, register the jar file as a new document service plug-in by providing the class name as
oracle.search.plugin.doc.extractor.DocumentSummarizerManager, and providing either the relative jar file path ofextractor/extractor.jaror the absolute jar file path (in case it is not deployed under theses_home/search/lib/plugins/docdirectory).
After registering a document service plug-in, you can create an instance for it as described in the section "Creating a Document Service".
URL Rewriter API
A URL rewriter is a user supplied Java module that implements the Oracle SES Java SDK API interface UrlRewriter of the oracle.search.sdk.crawler package. When activated, it is used by the crawler to filter and rewrite extracted URL links before they are inserted into the URL queue.
The URL Rewriter API is included as part of the Crawler Plug-in SDK. The URL Rewriter API is used for Web sources.
Web crawling generally consists of the following steps:
-
Get the next URL from the URL queue. (Web crawling stops when the queue is empty.)
-
Fetch the contents of the URL.
-
Extract URL links from the contents.
-
Insert the links into the URL queue.
The generated new URL link is subject to all existing boundary rules.
There are two possible operations that can be done on the extracted URL link:
-
Filtering: removes the unwanted URL link
-
Rewriting: transforms the URL link
URL Link Filtering
Users control what type of URL links are allowed to be inserted into the queue with the following mechanisms supported by the Oracle SES crawler:
-
robots.txtfile on the target Web site; for example, disallow URLs from the/cgidirectory -
Hosts inclusion and exclusion rules; for example, only allow URLs from
www.example.com -
File path inclusion and exclusion rules; for example, only allow URLs under the
/archivedirectory -
Mimetype inclusion rules; for example, only allow HTML and PDF files
-
Robots metatag
NOFOLLOW; for example, do not extract any link from that page -
Blacklist URLs; for example, URL explicitly singled out not to be crawled
With these mechanisms, only URL links that meet the filtering criteria are processed. However, there are other criteria that users might want to use to filter URL links. For example:
-
Allow URLs with certain file name extensions
-
Allow URLs only from a particular port number
-
Disallow any PDF file from a particular directory
The possible criteria could be very large, so it is delegated to a user-implemented module that can be used by the crawler when evaluating an extracted URL link.
URL Link Rewriting
For some applications, due to security reasons, the URL crawled is different from the one seen by the end user. For example, crawling occurs on an internal Web site behind a firewall without security checking, but when queried by an end user, a corresponding mirror URL outside the firewall must be used.
A display URL is a URL string used for search result display. This is the URL used when users click the search result link. An access URL is a URL string used by the crawler for crawling and indexing. An access URL is optional. If it does not exist, then the crawler uses the display URL for crawling and indexing. If it does exist, then it is used by the crawler instead of the display URL for crawling.
For regular Web crawling, only display URLs are available. But in some situations, the crawler needs an access URL for crawling the internal site while keeping a display URL for external use. For every internal URL, there is an external mirrored URL.
For example:
http://www.example-qa.us.com:9393/index.html http://www.example.com/index.html
When the URL link http://www.example-qa.us.com:9393/index.html is extracted and before it is inserted into the queue, the crawler generates a new display URL and a new access URL for it:
Access URL:
http://www.example-qa.us.com:9393/index.html
Display URL:
http://www.example.com/index.html
The extracted URL link is rewritten, and the crawler crawls the internal Web site without exposing it to the end user.
Another example is when the links that the crawler picks up are generated dynamically and can be different (depending on referencing page or other factor) even though they all point to the same page. For example:
http://compete3.example.com/rt/rt.wwv_media.show?p_type=text&p_id=4424&p_currcornerid=281&p_textid=4423&p_language=us http://compete3.example.com/rt/rt.wwv_media.show?p_type=text&p_id=4424&p_currcornerid=498&p_textid=4423&p_language=us
Because the crawler detects different URLs with the same contents only when there is enough duplication, the URL queue could grow to a huge number of URLs, causing excessive URL link generation. In this situation, allow "normalization" of the extracted links so that URLs pointing to the same page have the same URL. The algorithm for rewriting these URLs is application dependent and cannot be handled by the crawler in a generic way.
When a URL link goes through a rewriter, the following outcomes are possible:
-
The link is inserted with no changes.
-
The link is discarded; it is not inserted.
-
A new display URL is returned, replacing the URL link for insertion.
-
A display URL and an access URL are returned. The display URL might or might not be identical to the URL link.
Note:
URL rewriting is available for Web sources only.To create and use a URL rewriter:
-
Create a new Java file implementing the
UrlRewriterinterface methodsopen,close, andrewrite. -
Compile the rewriter Java file into a class file. For example:
$java_home/bin/javac -classpath ses_home/search/lib/search_sdk.jar SampleRewriter.java
-
Package the rewriter class file into a jar file and place it either under the
ses_home/search/lib/plugins/directory, or under any other directory. For example:$java_home/bin/jar cv0f ses_home/search/lib/plugins/sample.jar SampleRewriter.class
-
Enable the
UrlRewriteroption and specify the rewriter class name (for example,SampleRewriter) and jar file path (for example,sample.jar, if the jar file is placed under theses_home/search/lib/plugins/directory. If you place the jar file in any other directory, then you must provide its absolute file path) in the Oracle SES Administration GUI Home - Sources - Crawling Parameters page of an existing Web source. -
Crawl the target Web source by launching the corresponding schedule. The crawler log file confirms the use of the URL rewriter with the message Loading URL rewriter "SampleRewriter"...
See Also:
Oracle Secure Enterprise Search Java API Reference for the Oracle SES Java SDK URL Rewriter API (oracle.search.sdk.crawler package)Security APIs
In addition to the extensible crawler plug-in framework that lets you crawl and index proprietary document repositories (Crawler Plug-in API), Oracle SES also includes an extensible authentication and authorization framework. This lets you use any identity management system to authorize users (Identity Plug-in API). You can also define your own security model for each source (Authorization Plug-in API).
Oracle SES Java SDK provides the oracle.search.sdk.security package that contains the classes and interfaces related to the security API.
Identity Plug-in API
The Identity Plug-in API communicates with the identity management system to authenticate a user at login with a user name and password. It also provides a list of groups (or roles) for a specified user.
The identity plug-in manager manages initialization parameters and returns the IdentityPlugin object.
To add an identity plug-in, click Register New Identity Plug-in on the Global Settings - Identity Management Setup page, and enter the class name and jar file name for the identity plug-in manager.
Authorization Plug-in API
For sources with authorization requirements that do not fit the user/group model, an authorization plug-in provides a more flexible security model. (Authentication is still handled by an identity plug-in.)
With an authorization plug-in, a crawler plug-in can add security attributes similar to document attributes. The authorization plug-in is invoked at login time to build security filters onto the query string. The security filters are applied against the values of the security attributes for each document. Only documents whose security attribute values match the security filter are returned to the user. (All security attributes have string values.)
The authorization plug-in contains the following component:
-
ResultFilterPlugin: This is an interface for the query-time authorization (QTA). When building the hit list, Oracle SES calls a result filter plug-in to check if the user is authorized to view each document. Only documents the user is authorized to view are listed in the hit list. The result filter can be used as the only security device., or it can be used with other security. The result filter can also be used to modify the title or display URL.
User-Defined Security Model
With the user-defined security model, Oracle SES displays an Authorization page before a new user-defined source can be completed. The UserDefinedSecurityModel interface provides a method that returns the name of the class implementing the AuthorizationManager interface and the names and types (GRANT or DENY) of the security attributes used to build the security filter for a given user.
If you must change the AuthorizationManager plug-in class name or jar file name, then you must turn off security for that source to allow the change. After changing and applying the ACL setting to No Access Control List, you can edit the AuthorizationManager details. The new AuthorizationManager should share the same security attribute model as the previous one.
Caution:
While security is turned off, any user can access the documents in the affected source.See Also:
Oracle Secure Enterprise Search Java API Reference for the Oracle SES Java SDK Security API (oracle.search.sdk.security package)Query-time Authorization API
Query-time authorization enables you to associate a Java class with a source that, at search time, validates every document fetched out of the Oracle SES repository belonging to the protected source. This result filter class can dynamically check access rights to ensure that the current search user has the credentials to view each document.
You can apply this authorization model to any source other than self service or federated sources. Besides acting as the sole provider of access control for a source, it can also be used as a post-filter. For example, a source can be stamped with a more generic ACL, while query-time authorization can be used to fine tune the results.
Overview of Query-time Authorization
Query-time authorization has the following characteristics:
-
It allows dynamic access control at search time compared to more static ACL stamping.
-
It filters documents returned to a search user.
-
It controls the Browse functionality to determine whether a folder is visible to a search user.
-
Optionally, it allows pruning of an entire source from the results to reduce performance costs of filtering each document individually.
-
It is applicable to all source types except self service and federated sources.
-
The result filter can modify the Title or Display URL for the result returned to the search user.
Query-time filtering is handled by class implementations of the ResultFilterPlugin interface of the oracle.search.sdk.security package.
Filtering Document Access
Filtering document access is handled by the filterDocuments method of the ResultFilterPlugin interface. The most common situation for filtering occur with a search request, in which this method is invoked with batches of documents from the result list. Based on the values returned by this method, all, some, or none of the documents might be removed from the results returned to the search user.
Access of individual documents is also controlled. For example, viewing a cached copy of a document or accessing the in-links and out-links requires a call into filterDocuments to determine the authorization for the search user.
Filtering Folder Browsing
The ResultFilterPlugin implementation is also responsible for controlling the access to, and visibility of folders in, the Browse application. If a folder belongs to a source protected by a query-time filter, then the folder name in the Browse page does not have a document count listed next to it. Instead, the folder shows a view_all link.
For performance reasons, it can be costly to determine the exact number of documents visible to the current search user for every query-time filtered folder displayed on a Browse page. This calculation requires that every document in every folder be processed by the filter. To prevent this comprehensive and potentially time-consuming operation, document counts are not used. Instead, folder visibility is explicitly determined by the query-time filter.
Based on the results from the filterBrowseFolders method, a folder might be hidden or shown in the Browse page. This result also controls access to the single folder browsing page, which displays the documents contained in a folder.
If the security of folder names is not a concern for a particular source, then the filterBrowseFolders method can blindly authorize all folders to be visible in the Browse application. After a folder is selected, the document list is still filtered through the filterDocuments method. This strategy should not be employed if folder names could reveal sensitive information.
If security is very critical, then it might be easiest to hide all folders for browsing. The documents from the source are still available for search queries from the Basic and Advanced Search boxes, but users are not able to browse the source in the Browse pages of the search application.
Limitations of folder filtering:
-
The
filterBrowseFoldersmethod does not implicitly restrict access to subfolders. For example, if folder/Miscellaneous/www.example.com/privateis hidden for a search user, then it is still possible for that user to view any subfolder, such as/Miscellaneous/www.example.com/private/a/b, if that subfolder is not also explicitly filtered out by this method. It would be possible to view this subfolder if the user followed a bookmark or outside link directly to the authorized subfolder in the Browse application. -
This method does not affect functionality outside of the Browse application. This is not a generic folder pruning method. Search queries and document retrieval outside of the Browse application are only affected by the
filterDocumentsandpruneSourcemethods.
Pruning Access to an Entire Source
The ResultFilterPlugin interface provides the ability to determine access privileges at the source level. This is achieved through calls to the pruneSource method. This method can be called in situations where there are a large number of documents or folders to be filtered. Authorizing or unauthorizing the entire source for a given user could provide a large performance gain over filtering each document individually.
The implementation of ResultFilterPlugin must not rely on this method to secure access to documents or folders. This method is strictly an optimization feature. There is no guarantee that it is invoked for any particular search request or document access. For example, when performing authorization for a single document, Oracle SES may call the filterDocuments method directly without invoking this method at all. Therefore, the filterDocuments and filterBrowseFolders methods must be implemented to provide full security without pruning.
Determining the Authenticated User
A query-time filter is free to define a search user's access privileges to sources and documents based on any criteria available. For example, a filter could be written to deny access to a source depending on the time of day.
In most cases, however, a filter imposes restrictions based on the authenticated user for that search request. The Oracle SES authenticated user name for a request is contained in the oracle.search.sdk.query.RequestInfo object. The steps for accessing this user name value depend on whether the request originated from the JSP search application or the Oracle SES Query Web Services interface. For either type of request, the key used to access the authenticated user name is the string value AUTH_USER. The user name is not case-sensitive.
This sample implementation of the ResultFilterPlugin.getCurrentUserName method illustrates how to retrieve the current authenticated user from either a JSP or Web Services request:
public String getCurrentUserName( RequestInfo req )
throws PluginException
{
HttpServletRequest servReq = req.getHttpRequest();
Map sessCtx = req.getSessionContext();
String user = null;
if( servReq != null )
{
HttpSession session = servReq.getSession();
if( session != null )
user = ( String ) session.getAttribute( "AUTH_USER" );
}
else if( sessCtx != null )
{
// Web Service request
user = ( String ) sessCtx.get( "AUTH_USER" );
}
if( user == null )
user = "unknown";
return user;
}
See Also:
"Authentication Methods"Query-time Authorization Interfaces and Exceptions
The following Oracle SES Java SDK packages contain all the interfaces and exceptions for the Query-time Authorization API:
-
oracle.search.sdk.query -
oracle.search.sdk.common -
oracle.search.sdk.security
To write a Query-time Authorization filter, implement the oracle.search.sdk.security.ResultFilterPlugin interface. The methods in this interface may throw instances of oracle.search.sdk.common.PluginException.
Objects that implement the RequestInfo, DocumentInfo, and FolderInfo interfaces of the oracle.search.sdk.query package are passed as arguments for filtering, but these interfaces do not need to be implemented by the filter writer.
The Query-time Authorization API contains the following interfaces and exceptions:
Table 13-5 Query-time Authorization Interfaces and Exceptions
| Interface/Exception | Description |
|---|---|
|
|
This interface filters search results and access to document information at search time. If an object implementing this interface has been assigned to a source, then any search results or other retrieval of documents belonging to the source are passed through this filter before being presented to the end user. |
|
|
This exception is thrown by methods in the |
|
|
This interface represents information about a document that can be passed to a |
|
|
This interface represents information about a folder that can be passed to a |
|
|
This interface represents information about a request that can be passed to a |
See Also:
Oracle Secure Enterprise Search Java API Reference for the Oracle SES Java SDK Query-time Authorization APIThread-Safety of the Filter Implementation
Classes that implement the ResultFilterPlugin interface should be designed to persist for the lifetime of a running search application. A single instance of ResultFilterPlugin generally handles multiple concurrent requests from different search end users. Therefore, the filterDocuments, pruneSource, filterBrowseFolders, and getCurrentUserName methods in this class must be both reentrant and thread-safe.
Compiling and Packaging the Query-Time Filter
To compile your query-time filter class, you must include at least the two following files in the Java CLASSPATH. These files can be found in the Oracle SES server directory.
-
ses_home/search/lib/search_query.jar -
ses_home/lib/servlet.jar
Oracle recommends that you build a jar file containing your ResultFilterPlugin class (or classes) and any supporting Java classes. Place this jar file in a secure location for access by the Oracle SES server. If this jar file is compromised, then the security of document access in the search server can be compromised.
Your query-time filter might require other classes or jar files that are not included in the jar file you build and are not located in the Oracle SES class path. If so, add these files to the Class-Path attribute of the JAR file manifest. Include this manifest file in the jar file that you build.
If Oracle SES cannot locate a class used by a ResultFilterPlugin during run-time, then an error message is written to the log file and all documents from that source are filtered out for the search request being processed.
See Also:
http://docs.oracle.com/javase/6/docs/technotes/guides/jar/jar.html for more information about jar file manifests.