In This Section:
Starting and Stopping Essbase Using OPMN
Logging In to Essbase Using Logical Names
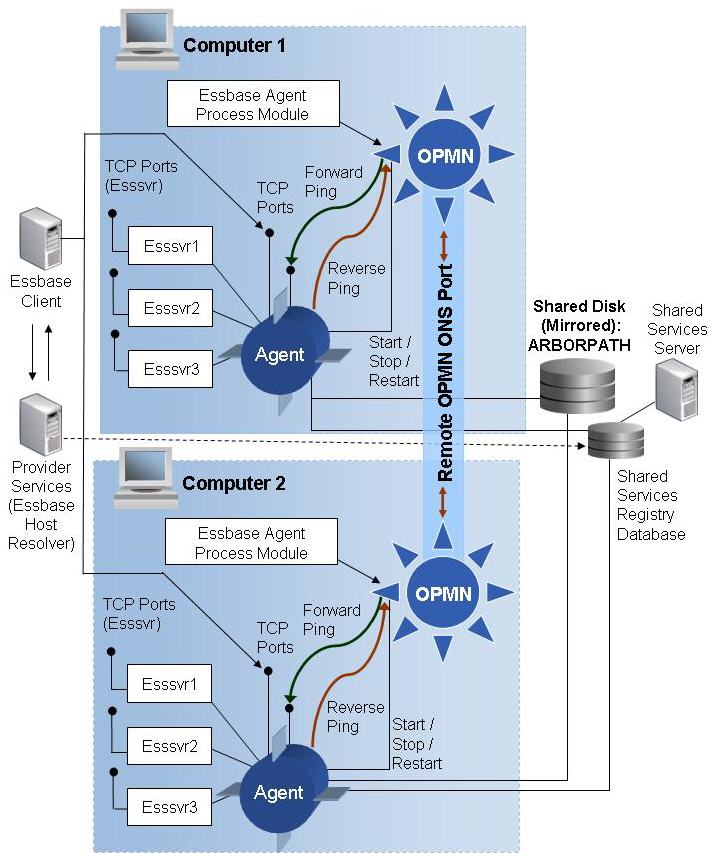
Oracle Process Manager and Notification server (Oracle Process Manager and Notification Server) enables you to monitor and control the Essbase Agent process. You add Essbase Agent information to the opmn.xml file to enable OPMN to start, stop, and restart the agent using the OPMN command line interface. OPMN can automatically restart the Essbase Agent when it become unresponsive, terminates unexpectedly, or becomes unreachable as determined by ping and notification operations.
Figure 148, Essbase Integration with OPMN shows how Essbase integrates with OPMN.
Additionally, you can use the failover functionality available in OPMN to provide high availability of Essbase clusters (see Understanding Essbase Failover Clusters).

Oracle Process Manager Modules (PM Modules) communicate with the Essbase Agent for process administration and health monitoring. As a managed component, the Essbase Agent and OPMN communicate using Oracle Notification Server (ONS), which is the transport mechanism for notifications between components.
When you start Essbase using the OPMN command line interface (see Starting and Stopping Essbase Using OPMN), OPMN spawns the agent process and sets the status to initialized (a message is logged in the opmn.log file). Whether this state transitions to alive depends on whether OPMN receives a response (a reverse ping) from the agent, which implies that the agent is active.
After Essbase is up and running, OPMN periodically sends a TCP-based forward ping to the agent. If a ping attempt fails, OPMN retries up to three times to contact the agent. If all ping attempts fail, OPMN stops the agent. OPMN attempts to restart the agent for these scenarios:
restart-on-death (in opmn.xml) is set to TRUE (the default setting is FALSE in non-failover mode).
Failover mode is on, which supersedes the restart-on-death value. If restart-on-death is FALSE and failover mode is on, OPMN may bring up Essbase on the active or passive node.
When you stop Essbase using the OPMN command line interface, OPMN shuts down the agent, thereby releasing all resources held by the agent. Essbase Servers shut down when they detect that the parent agent process has shut down.
Components that are managed by OPMN should never be started or stopped manually. Use the opmnctl command line utility to start and stop system components.
Note: | If you attempt to use MaxL to shut down an Essbase instance that was started using OPMN, you are warned to use OPMN to shut down Essbase. |
Use these commands to start, stop, and monitor Essbase from OPMN:
opmnctl status
Enables you to determine the status of system component processes.
opmnctl startproc ias-component=EssbaseInstanceName
Starts the system component named EssbaseInstanceName
opmnctl restartproc ias-component=EssbaseInstanceName
Restarts the system component named EssbaseInstanceName
opmnctl stopproc ias-component=EssbaseInstanceName
Stops the system component named EssbaseInstanceName
where EssbaseInstanceName is one of the following:
If you did not implement failover clustering, EssbaseInstanceName is the name of the Essbase instance that you entered when you configured Essbase Server.
If you implemented failover clustering, EssbaseInstanceName is the name of the Essbase cluster that you entered when you set up the Essbase cluster.
Note that the Essbase Server start and stop scripts redirect to OPMN. See the Oracle Hyperion Enterprise Performance Management System Installation and Configuration Guide.
For more information on OPMN commands, see the Oracle Process Manager and Notification Server Administrator's Guide.
For troubleshooting and logging information, see Oracle Hyperion Enterprise Performance Management System Installation and Configuration Troubleshooting Guide.
Essbase clients can use a URL to connect to an Essbase cluster, in the form:
http(s)://host:port/aps/Essbase?ClusterName=clusterName&SecureMode=yesORno
To simplify login, Essbase clients should use the logical cluster name directly, in the form <name>:<secure>, instead of the URL. If you want to enable client login using the cluster name, you must first specify a property to configure Provider Services. The cluster name is resolved by the Provider Services servers specified in configuration files:
APSRESOLVER in essbase.cfg—Server-to-server communication; for example, when defining Essbase servers for partitions, XRefs, and XWrites
See Oracle Essbase Technical Reference.
aps.resolver.urls in essbase.properties—Client-to-server communication; for example, when connecting to Essbase from Oracle Essbase Spreadsheet Add-in or Smart View
See Oracle Hyperion Provider Services Administration Guide.
The Login API adheres to this precedence order when resolving the server name:
Look up the server name in the internal cache (maintained in the API layer).
If the server name is not found in the cache, contact each Provider Services server listed in essbase.cfg and attempt to resolve the server name.
If the server name is not found, treat the server name as a physical server name.
An active-passive Essbase cluster consists of two Essbase instances, one on each node that share a common storage for configuration and data. Storage is shared across two computers (for example, using a SAN), which removes the need for the administrator to synchronize storage, as well as the constraint of read-only support (as is the case with Essbase active-active clusters in Provider Services). Essbase uses database tables to ensure that only one agent and its associated servers are active to avoid data corruptions on writes. During installation and configuration, a table is created to hold information on configuration and application data existing in the cluster. Active-passive Essbase clusters do not use any file-system locking (that is, essbase.lck files).
We use the Service Failover functionality available in OPMN to cluster Essbase servers to provide active-passive service failover with write-back capability and API support. Clustering Essbase servers provides the capability to switch over automatically to a passive server when the active server fails, thus ensuring that the Essbase Agent is highly available.
These topics explain the concept of leases:
Essbase failover uses a leasing mechanism to solve the problem of split-brain. A split-brain situation can develop when both instances in an active-passive clustered environment think they are “active” and are unaware of each other, which violates the basic premise of active-passive clustering. Situations where split-brain can occur include network outages or partitions.
An Essbase process acquires a lease on a specified shared resource or set of resources upon startup; it renews the lease periodically and surrenders the lease upon termination.
This lease establishes the process as the primary service provider and grants the right to update the specified set of shared resources, service client requests, and spawn processes.
Essbase servers can acquire leases if and only if its authorizing agent has a current lease.
Essbase failover implements a leasing mechanism using a centralized relational database to store, update, and retrieve information about the following:
Shared resources
Lease ownership
Lease validity
The set of tables used for this purpose is created during Essbase installation and configuration. These tables reside in the same database and schema as the Shared Services Registry.
On startup, Essbase Agent and servers inspect the database table to see if any other process currently owns the lease for its shared resource . If yes, the agent and servers wait until the lease expires and retries. If not, the agent and servers take ownership of the shared resource; that is, they get a lease.
The agent and servers acquires a lease on startup and surrender the lease on termination. The agent and servers periodically renew the lease to indicate its health. If the lease cannot be renewed, the agent and servers self-terminate.
Lease ownership grants exclusive right to update a set of shared resources residing on a shared disk. The lease owner (Essbase Agent or Essbase Server) attempts to renew the lease within a preconfigured interval of time. See the AGENTLEASERENEWALTIME and SERVERLEASERENEWALTIME configuration settings in the Oracle Essbase Technical Reference.
The tunable parameters shown in Table 127, Table 128, and Table 129 control failover detection. By default, these parameters are set so that failover occurs in less than one minute. You may need to fine tune these parameters based on your business requirements.
Table 127. Tunable Agent Parameters (in essbase.cfg)
| Agent Parameter | Value |
|---|---|
| Agent Lease Expiry Time | 20 seconds |
| Agent Lease Renewal Interval | 10 seconds |
| Agent Lease Acquire Max Retry | 5 |
Table 128. Tunable Server Parameters (in essbase.cfg)
| Server Parameter | Value |
|---|---|
| Server Lease Expiry Time | 20 seconds |
| Server Lease Renewal Interval | 10 seconds |
| Server Lease Acquire Max Retry | 5 |
The time delay between each lease acquire failed attempt until maximum retry is calculated based on how much time is left for the lease to expire. If the lease is available and acquire fails, then the delay could be one second. See Oracle Essbase Technical Reference.
Table 129. Tunable OPMN Parameters (in opmn.xml)
| OPMN Parameter | Default Value |
|---|---|
| restart-on-death | FALSE. If FAILOVERMODE is set to TRUE (in essbase.cfg), you must change this value to TRUE so that OPMN restarts Essbase Agent if it terminates abnormally. |
| shutdown-force-enabled | FALSE. You must set this to TRUE if you enabled Essbase failover clustering. Setting this to TRUE enables you to forcibly kill Essbase if graceful shutdown by OPMN fails. |
| OPMN Forward Ping Interval | 20 seconds |
| OPMN PROC_READY (reverse ping) Interval | 20 seconds |
| Agent Start or Restart Retries | 2 This means that OPMN tolerates two failures to start or restart the agent before marking this instance as nonfunctional for this service, which is when the agent service failover begins in failover mode; otherwise it will throw an error. |
| OPMN Agent Start Timeout | 10 minutes |
| OPMN Agent Restart Timeout | 10 minutes |
| OPMN Agent Stop Timeout | 10 minutes |
See the Oracle Process Manager and Notification Server Administrator's Guide.
Table 130 lists the failure conditions that cause Essbase Agent and Essbase Server to terminate, the affected components, OPMN reactions, and Essbase client responses.
Table 130. Essbase Agent and Server Termination Scenarios
Failure Condition | Assumed Working | Failover Functionality | Expected Service Level Agreement |
|---|---|---|---|
Essbase Server death:
| Essbase Agent Network Shared disk | OPMN is not involved. Essbase Agent restarts an Essbase Server on getting a new request; there may be a slight delay in server startup while waiting for lease availability. | Client gets a “request failed” error (while request is bound to the server). Client must reissue the request. |
Essbase Agent death:
| Network Shared disk | OPMN ping of Essbase Agent fails. OPMN attempts to restart Essbase Agent on same node. If Essbase Agent does not restart on the same node, OPMN initiates failover on the passive node. Essbase Agent restarts servers on getting application requests. | Client gets a network disconnect error (when attempting to contact Essbase Agent using SessionID). Servers become orphaned and the following events occur:
Either (1) or (2) occurs, whichever comes earlier, and servers terminate. Client must re-login to Essbase (after the agent restarts). Client must resubmit request. |
Network outage (network partition, that is. primary IP [eth0] down on active node) | Essbase Agent (on current active node) Essbase Servers (on current active node) Shared disk Lease database (potentially, if reachable using from a different network interface—not eth0) | OPMN “forward ping” of Essbase Agent fails. OPMN attempts to restart Essbase Agent on local node, which fails (eth0 is down); Essbase Agent terminates. Servers detect Essbase Agent death and terminate. Network heartbeat between ONS peers in active and passive node fails (that is, a network partition). OPMN in passive node becomes new active node. OPMN brings up the Essbase Agent on the new active node; there might be a slight delay for the Essbase Agent lease to become available. Essbase Agent brings up Essbase Servers as requests are received. | Client gets “error” while trying to reuse Session or “hangs” until network outage detected. Essbase Agent and servers becomes unreachable. Client musty re-login to the Essbase Agent after it comes up on passive node; and then it needs to resubmit requests. |
Essbase.lck file exists after Agent death | Not applicable | Not applicable Essbase.lck file is removed in failover mode. | Not applicable |
Essbase.sec file is corrupt after Essbase Agent death (non-unique scenario; could be a follow on to Essbase Agent crash or network partition) | Network Shared disk | Not applicable for Essbase failover. Essbase Agent does not start until the administrator restores good essbase.sec from backup. | Service unavailable without Administrator. After Essbase Agent comes back up, clients must re-login. |
Disk outage (Shared disk down) | Network | Not applicable for Essbase failover. Customer needs to eliminate single point of failure in shared disk. This can be addressed by running the shared disk with a mirroring setup, like in a SAN with disk redundancy (RAID 1-0 configuration). | Both active and passive nodes fail. Service is not available. |
Lease database outage | Network Shared disk | Essbase Agent unable to renew lease and terminates. Servers unable to renew lease and terminate. You need to eliminate single point of failure for lease database. Oracle recommends that you run the lease database (which is relational) in cold failover cluster (CFC) (active-passive) mode or RAC mode (active-active). | Service unavailable. Both active and passive nodes are unable to run Essbase. |
Node failure (catastrophic hardware failure) | Network Shared disk | Network heartbeat between ONS peers on active and passive nodes fails (current active node has crashed). OPMN on the passive node becomes the new active node. OPMN brings up Essbase Agent on the new active node; there might be a slight delay for the Essbase Agent lease to become available. Essbase Agent brings up Essbase Servers as requests come in. | Client gets “error” while trying to reuse Session; Agents and Servers have died. Client must re-login to Essbase Agent after it comes up on standby node; then, it needs to resubmit requests. |
Shared Services Web application outage | Network Shared disk Essbase Agent Essbase Servers | Not applicable to Essbase failover. As long as the LDAP provider is up (OpenLDAP, Oracle LDAP/External Directory) , Essbase Agent can authenticate users (there is no runtime dependency on Shared Services). | Certain user operations will fail; for example, create and delete application fails (which updates Shared Services Registry using the Oracle's Hyperion® Shared Services Web server). Existing clients continue to work. |
Essbase Agent and server hang (application bug) | Network Shared disk Essbase Agent | Essbase Agent and server hangs are not explicitly handled, but the overall robustness of the agent and servers improves when using failover clusters. | As long as Essbase Agent and server are able to renew their leases, there is no change to the existing behavior. |