




|
|
データ・レコードが完全で分離不可能なものである例外的な状況を除き、レコードに含まれている情報を使用または変更するためには、レコードがフィールドに分割可能である必要があります。ATMI環境では、レコードは次のいずれかの手段によって分割できます。
レコードを再分割する一般的な手段の1つに、記憶域の隣接する部分をフィールドに分割する構造があります。フィールドには識別のための名前が付加され、各フィールドに含まれるデータの種類はデータ型宣言によって示されます。
たとえば、C言語プログラムによるデータ・アイテムに従業員のID番号、氏名、住所および性別が含まれる場合、次のような構造に設定できます。
struct S {
long empid;
char name[20];
char addr[40];
char gender;
}; この場合、empidという名前のフィールドのデータ型はlong型整数、nameおよびaddrはそれぞれ20字および40字の文字配列、そしてgenderは1字(おそらく範囲はmまたはf)であると宣言されています。
使用するCプログラムで、変数pが型構造体Sの構造体を指す場合、参照p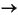
empid、pname、paddrおよびpgenderはフィールドを指し示すために使用できます。
同じデータ構造のCOBOL COPYファイルは、以下のようになります(第01行はアプリケーション側で提供されます)。
05 EMPID PIC S9(9) USAGE IS COMP-5.
05 NAME PIC X(20).
05 ADDR PIC X(40).
05 GENDER PIC X(01).
05 FILLER PIC X(03).
COBOLのプログラムで、第01行にMYRECという名前を付けた場合は、EMPID IN MYREC、NAME IN MYREC、ADDR IN MYREC、およびGENDER IN MYRECを使用して各フィールドにアクセスできます。
このデータ表現法は広く使用されており、通常は適用できますが、次の2つの潜在的な問題があります。
レコードをフィールドに分割する別の方法は、フィールド化バッファを使用することです。
フィールド化バッファは、レコードのフィールドに対して連想アクセスを提供するデータ構造体です。つまり、フィールド名は、フィールドのデータ型のほか、ストレージの位置を含む識別子と関連付けられています。
フィールド化バッファの主な利点は、データの独立性です。つまり、バッファに対してフィールドを追加または削除したり、フィールド長を変更しても、フィールドを参照するプログラムを再コンパイルする必要はありません。データの独立性を実現するため、フィールドは以下のように使用されます。
ATMI環境では、協調動作するプロセス間で送信されるデータを表現する標準的な方法として、フィールド化バッファを使用できます。
フィールド化バッファの作成、更新、アクセス、入力、出力、および操作は、フィールド操作言語(FML)によって行います。FMLには以下の特徴があります。
FMLは、Cプログラムから呼び出すことができる関数およびマクロのライブラリとして実装されています。以下の関数が用意されています。
上記のうち、最後のセットがFML VIEWSソフトウェアを構成する関数のセットです。VIEWSは、FMLフィールド化バッファとアプリケーション・プログラムの構造体(C言語またはCOBOL言語)との間でデータを交換する関数のセットです。プログラムは、別のプロセスからフィールド化バッファを受け取ると、次の動作として以下のいずれかを実行します。
バッファのデータに対して、時間のかかる操作を行う必要がある場合は、フィールド化バッファのデータを構造体に転送し、通常のCまたはCOBOL文を使用してそのデータを処理すると、プログラムのパフォーマンスを向上させることができます。次に、再びVIEWS関数を使用してデータをフィールド化バッファに戻すと、そのバッファを別のプロセスに送信できます。
VIEWSを使用する前に、受信するフィールド化バッファのデータ形式がプログラム側で認識できるようにプログラムを設定しておかなければなりません。この設定には、システム・キャッシュに保存されているVIEW記述のセットを使用します。
VIEW記述は、ソースVIEWファイル内に作成および格納されます。VIEW記述により、フィールド化バッファ内のフィールドがC構造体またはCOBOLレコード内のメンバーにマッピングされます。ソースVIEW記述がコンパイルされると、その記述は、フィールド化バッファとC構造体、またはフィールド化バッファとCOBOLレコードの間で転送されるデータをマッピングするために使用できます。
主要なファイルにVIEW記述をキャッシングしておくと、プログラムのデータ独立性を強化できます。つまり、VIEWS記述を変更し、再コンパイルするだけで、VIEWSを使用するアプリケーション・プログラム全体のデータ形式に変更を加えることができます。
フィールド化バッファとは、レコードのフィールドに対して連想アクセスを行うデータ構造です。
FMLフィールド化バッファ内の各フィールドには、関連するフィールドのデータ型に関する情報と一意のID番号を組み合せた整数がラベル付けされています。このラベルは、フィールド識別子(fldid)と呼ばれます。可変長項目の場合は、fldidの後にデータ長を指定します。
フィールド化バッファは、fldid、データ、の順で組み合せるか、または、可変長項目の場合はfldid、フィールド値長、データ、の順で組み合せて表現します。次の図を参照してください。

FML関数を使用するたびに#includeを使用して組み込まれるヘッダー・ファイル(fml.hまたはfml32.h)では、typedefにより、フィールド識別子はFLDID (FML32ではFLDID32)、フィールド値長はFLDLEN (FML32ではFLDLEN32)、フィールド・オカレンス数はFLDOCC (FML32ではFLDOCC32)と定義されます。
サポートされているフィールド型は、short型、long型、float型、double型、char型、string型、carray型(文字配列)、mbstring型(マルチバイト文字配列 - Tuxedoリリース8.1またはそれ以降で使用可能)、ptr型(バッファを指すポインタ)、FML32型(埋め込み型のFML32バッファ)、およびVIEW32型(埋め込み型のVIEW32バッファ)です。mbstring、ptr、FML32、およびVIEW32型は、FML32インタフェースでのみサポートされています。これらの型は、次のリストに示すように、fml.h (またはfml32.h)内の#define文で定義されています。
#define FLD_SHORT 0 /* short int */
#define FLD_LONG 1 /* long int */
#define FLD_CHAR 2 /* character */
#define FLD_FLOAT 3 /* single-precision float */
#define FLD_DOUBLE 4 /* double-precision float */
#define FLD_STRING 5 /* string - null terminated */
#define FLD_CARRAY 6 /* character array */
#define FLD_PTR 9 /* pointer to a buffer */
#define FLD_FML32 10 /* embedded FML32 buffer */
#define FLD_VIEW32 11 /* embedded VIEW32 buffer */
#define FLD_MBSTRING 12 /* multibyte character array */
FLD_STRING、FLD_CARRAY、およびFLD_MBSTRINGはいずれも配列ですが、次の点が異なります。
フィールドを追加または変更する関数には、FLDLEN引数を指定します。この引数は、FLD_CARRAYまたはFLD_MBSTRINGフィールドを処理する場合は必須です。文字列または文字配列のサイズは、FMLでは最大65,535文字、FML32では最大2ギガバイトに制限されています。
unsigned型のデータ型は、フィールド化バッファに格納しないでください。このデータ型を使用すると、フィールド化バッファからデータを検索するたびに、FMLの変換関数を使用して、unsigned short型データをすべてlong型データに変換するか、またはそれらのデータを正しいunsigned型にキャストしなければなりません。
ほとんどのFML関数では、型のチェックは行われません。通常、フィールド化バッファで更新または検索された値は、ネイティブな型と一致すると見なされます。たとえば、バッファ・フィールドがFLD_LONGとして定義されていると、必ず、long型の値のアドレスを渡す必要があります。FML変換関数は、データをフィールド化バッファに格納する(または、データをフィールド化バッファから検索する)ほか、ユーザー指定の型からネイティブ・フィールド型(または、ネイティブ・フィールド型からユーザー指定の型)にデータを変換します。
FLD_PTRフィールド型を使用すると、FML32バッファ内のアプリケーション・データへのポインタを埋め込むことができます。アプリケーション側では、データ・バッファへのポインタの追加、変更、アクセス、および削除が可能です。FLD_PTRフィールドが指すバッファは、tpalloc(3c)を呼び出して割り当てます。FLD_PTRフィールド型は、FML32でのみサポートされています。
FLD_FML32フィールド型は、レコード全体を単一フィールドとしてFML32バッファに格納できます。同様に、FLD_VIEW32フィールド型は、C構造体全体をFML32バッファ内に単一フィールドとして格納できます。FLD_FML32およびFLD_VIEW32フィールド型は、FML32でのみサポートされています。
VIEWSは、大半のFML関数でサポートされているデータ型のほか、ソースVIEW記述内でint型を間接的にサポートします。VIEW記述がコンパイルされると、VIEWのコンパイラは、マシンの種類に応じて、すべてのint型をshort型かlong型に自動的に変換します。詳細は、「VIEWSの機能」を参照してください。
VIEWSでは、ソースVIEW記述内でdec_tパック10進数型もサポートされています。このデータ型は、VIEW構造体からCOBOLのプログラムへの転送に便利です。dec_t型を使用するCプログラムでは、『Oracle Tuxedo ATMI Cリファレンス』の「decimal(3c)」リファレンス・ページで説明されている関数を使用してフィールドの初期化およびアクセスを行う必要があります。COBOLプログラムでは、パック10進数(COMP-3)の定義を使用してこのフィールドに直接アクセスできます。FMLではdec_tフィールドがサポートされていないため、このフィールドは、VIEWからFMLに変換するときに、フィールド化バッファ内の対応するFMLフィールドのデータ型(string型など)に自動的に変換されます。
Oracle Tuxedoシステムでは、フィールドは通常、フィールド識別子(fldid)の整数によって参照されます。フィールド識別子の詳細は、「フィールド名とフィールド識別子を定義する」を参照してください。このため、変更の可能性があるフィールド名を使用しないで、プログラム内でフィールドを参照できます。
識別子をフィールド名に割り当てる(マッピングする)には、次のいずれかの方法を使用します。
通常のアプリケーション・プログラムでは、上記の方法のどちらか、または両方を使用して、フィールド識別子をフィールド名にマッピングできます。
FMLでフィールド化レコード内のデータにアクセスするには、FMLでフィールド名と識別子のマッピング情報にアクセスできなければなりません。FMLは、以下の方法のいずれかを使用してこのマッピング情報を取得します。
フィールド名と識別子のマッピングは、COBOLでは使用できません。
フィールド表ファイルにより、FMLプログラムの実行時、フィールド名と識別子のマッピング情報が使用可能になります。ただし、フィールド名と識別子のマッピング表ファイルの場所は、2つの環境変数を用いて、プログラマが直接設定します。
環境変数FLDTBLDIRには、ディレクトリ・リストが含まれ、ここでフィールド表を検索できます。環境変数FIELDTBLSには、使用される表ディレクトリのファイル・リストが含まれます。対応するFML32の環境変数は、FLDTBLDIR32およびFIELDTBLS32です。
アプリケーション・プログラム内では、FML関数であるFldid()により、フィールド名からフィールド識別子への変換が実行時に行われます。フィールド識別子をフィールド名に変換する処理は、Fname()によって行われます(Fldid(3fml)およびFname(3fml)を参照してください)。(FML32についてはFldid32およびFname32を参照してください。)これらの2つの関数のうち、最初に呼び出された関数によってメモリー内の領域がフィールド表用に動的に割り当てられ、フィールド表がプロセスのアドレス領域にロードされます。フィールド表が不要になると、領域を回復できます。詳細は、「フィールド表をロードする」を参照してください。
アプリケーション内でフィールド名と識別子のマッピングの変更が予測される場合は、この方法を使用します。詳細は、「フィールドの定義と使用」を参照してください。
mkfldhdr() (またはmkfldhdr32())を使用すると、フィールド表ファイルからヘッダー・ファイルを作成できます。これらのヘッダー・ファイルは、Cプログラムの#includeに組み込まれており、フィールド名とフィールド識別子のマッピングを行います。mkfldhdr、mkfldhdr32(1)の詳細は、『Oracle Tuxedoコマンド・リファレンス』を参照してください。
Cプリプロセッサは、コンパイル時にフィールド・ヘッダー・ファイルを使用して、すべてのフィールド名の参照をフィールド識別子に変換します。したがって、前の項で説明したように、フィールド表ファイルを使用してFldid()関数やFname()関数を呼び出す必要はありません。
プログラムで必要なフィールド名が常にわかる場合は、フィールド表のヘッダー・ファイルを#includeでプログラムに組み込むと、データ領域を節約できます。データ領域を節約すると、プログラムではすばやく目的のタスクを実行できます。
ただし、この方法はコンパイル時にマッピングを解決するため、アプリケーション内でフィールド名とフィールド識別子のマッピングに変更が生じる可能性がある場合は使用しないでください。詳細は、「フィールドの定義と使用」を参照してください。
フィールド化バッファに多数のフィールドが含まれる場合、内部索引を使用すると、FMLでのアクセスが促進されます。通常、ユーザーはこの索引の存在を意識することはありません。
ただし、フィールド化バッファの索引は、メモリーおよびディスク領域を消費します。したがって、フィールド化バッファをディスクに格納したり、プロセス間またはコンピュータ間で転送する場合は、まず、この索引を削除すると、ディスク領域や転送時間を節約できます。
索引を削除するには、Funindex()関数を使用します。フィールド化バッファがディスクから読み取られるか、または、送信プロセスによって受け取られると、Findex()関数を使用して再び索引を明示的に作成できます。
ただし、この方法を使用してもメモリーは節約できません。Funindex()関数を使用しても、フィールド化バッファの索引用に使用されるインコア・メモリーは回復できません。
詳細は、『Oracle Tuxedo ATMI FML関数リファレンス』の「Funindex、Funindex32(3fml)」または「Findex、Findex32(3fml)」を参照してください。
フィールド化バッファ内のフィールドは、複数回出現する場合があります。FML関数の多くが、検索または変更の対象にするフィールド・オカレンスを指定する引数を取ります。フィールドが複数回出現する場合、オカレンスは、最初のオカレンスを0として、順次番号付けされます。オカレンスのセットは論理的なシーケンスを構成しますが、オカレンス番号に関連するオーバーヘッドは発生しません(つまり、オカレンス番号はフィールド化バッファに格納されません)。
フィールドのオカレンスを追加すると、そのオカレンスは、オカレンスのセットの最後に追加され、最も大きい番号の次の番号が指定されたオカレンスとして参照されます。最も大きい番号が指定されたオカレンス以外のオカレンスを削除すると、削除されたオカレンスより大きい番号のオカレンスには、1つ低い番号が指定されます。たとえば、オカレンス6はオカレンス5になり、オカレンス5はオカレンス4になります。
アプリケーション・プログラムが次に行うアクションは、ユーザー端末やデータベース・レコードなど、別のソースから受け取ったフィールド化バッファの1つまたは複数のフィールドの値によって決まります。FMLには、フィールド化バッファやVIEWに関するブール式を作成して、指定したバッファやVIEWがブール式の条件に合致するかどうかを判定するための関数がいくつか用意されています。
作成されたブール式は、評価ツリーにコンパイルされます。評価ツリーは、フィールド化バッファまたはVIEWが指定されたブール式の条件を満たすかどうかの判定に使用されます。
たとえば、プログラムがフィールド化バッファ(バッファA)にデータ・レコードを読み込み、そのバッファにブール式を適用するとします。バッファAがブール式で指定された条件を満たす場合は、FML関数が使用され、別のバッファ(バッファB)をバッファAからのデータで更新します。
VIEWSは、プログラムがフィールド化バッファを受け取った後またはフィールド化バッファを別のプログラムに送る前に、バッファのデータに対して大量の処理を行う場合に特に便利です。
このような場合、VIEWS関数を使用してフィールド化バッファのデータをバッファからC構造体に転送し、その後でデータを処理すると、処理効率を高めることができます。フィールドをバッファ内で処理する場合、FML関数よりC関数の方が処理時間が短いためです。C構造体でデータの処理を終了したら、そのデータをフィールド化バッファに戻し、さらに別のプログラムに転送できます。
viewc (またはviewc32)を使用すると、実行時にアプリケーション・プログラムによって解釈されるオブジェクトVIEW記述(バイナリ形式のファイルに格納)を生成できます。FUPDATE、FJOIN、FOJOIN、FCONCATのいずれかです。これらのモードは、Fupdate、Fupdate32(3fml)、Fjoin、Fjoin32(3fml)、Fojoin、Fojoin32(3fml)、およびFconcat、Fconcat32(3fml)の各FML関数によってサポートされているモードと似ています。FLD_PTRおよびFLD_FML32のみが例外です。さらに、ネストされたVIEWもサポートされています。詳細は、『C言語を使用したOracle Tuxedo ATMIアプリケーションのプログラミング』のVIEW型バッファの使用に関する項を参照してください。Ftypcvt()によって文字列が自動的に整数に変換されます。詳細は、『Oracle Tuxedo ATMI FML関数リファレンス』の「Ftypcvt、Ftypcvt32(3fml)」を参照してください。 ソースVIEWファイルは、1つまたは複数のソースVIEW記述を含む一般的なテキスト・ファイルです。ソースVIEWファイルは、VIEWコンパイラであるviewcまたはviewc32への入力として使用され、ソースVIEW記述をコンパイルし、オブジェクトVIEWファイルに格納します。VIEWコンパイラの詳細は、『Oracle Tuxedoコマンド・リファレンス』の「viewc、viewc32(1)」を参照してください。
VIEWコンパイラは、オブジェクトVIEWファイル用のCヘッダー・ファイルも生成します。これらのヘッダー・ファイルは、アプリケーション・プログラム内に組み込まれると、オブジェクトVIEW記述で指定された構造体を定義できます。
VIEWコンパイラは、必要に応じてオブジェクトVIEWファイルに対するCOBOL COPYファイルも生成します。これらのCOPYファイルは、COPYプログラムに組み込み、オブジェクトVIEW記述で指定するレコード形式を定義できます。
NULL値は構造体の空のメンバーを表すのに使用し、viewfileの構造体の各メンバーに対して指定できます。メンバーにNULL値を指定しないと、省略時のNULL値が使用されます。
ただし、構造体からフィールド化バッファへの転送時には、NULL値を含む構造体メンバーは転送されません。
また、CまたはCOBOL構造体のメンバーとフィールド化バッファ内のフィールドの間にマッピングが存在していても、それらの間でのデータ転送を禁止することができます。これは、ソースVIEWファイルで指定します。
FML VIEWS関数として、Fvstof()、Fvftos()、Fvnull()、Fvopt()、Fvselinit()、Fvsinit()があります。COBOLでは、VIEWS機能によってFVSTOFおよびFVFTOSの2つの手順が提供されています。どちらのVIEW関数を呼び出しても、指定されたオブジェクトVIEWファイルが検索され、そのファイルが見つかると、VIEWファイルのキャッシュに自動的にロードされます。環境変数VIEWFILESで指定される各ファイルは、順番に検索されます(「FMLおよびVIEWSの環境設定」を参照してください)。指定名を持つ最初のオブジェクトviewfileがロードされます。同じ名前を持つ以降のオブジェクトVIEWファイルは無視されます。FML VIEWS関数の詳細は、『Oracle Tuxedo ATMI FML関数リファレンス』を参照してください。
VIEWSでは、構造体の配列、ポインタ、ユニオン、typedefはサポートされていません。
VIEWSは、フィールド化バッファとC構造体、またはフィールド化バッファとCOBOLレコードの間で交換されるフィールドを扱うため、バッファ内で複数回発生するフィールドも処理する必要があります。
構造体内にフィールドの複数のオカレンスを格納するため、メンバーは、C言語またはCOBOLのOCCURS句により配列として宣言されます。フィールドの1オカレンスに対して1つの配列の要素が使用されます。配列のサイズは、バッファ内のフィールド・オカレンスの最大数を反映します。
フィールド化バッファからC構造体またはCOBOLレコードへのデータ転送時に、受信側の配列に存在する要素の数がフィールド化バッファ内のオカレンスの数より多い場合、余分な要素には、デフォルト値またはユーザー指定のNULL値が割り当てられます。バッファ内のオカレンスの数が配列内の要素の数より多い場合は、バッファ内の余分なオカレンスは無視されます。
C構造体またはCOBOLレコードからフィールド化バッファにデータを転送する場合、デフォルト値またはユーザー指定のNULL値に等しい値を含む配列メンバーは無視されます。
FML関数は、エラーを検出すると、以下の値のいずれか1つを返します。
FML関数の呼出しに対するすべての戻り値はこれらの条件と照合され、その結果、エラーが検出されます。
エラーの場合はすべて、外部整数Ferrorがfml.hで定義されたエラー番号に設定されます。FML32では、Ferror32がfml32.hで定義されたエラー番号に設定されます。
F_error()関数(またはF_error32()関数)は、標準エラー出力上にメッセージを出力します。この関数は、パラメータを1つ(文字列)とります。次に、エラー・メッセージとその後に続く改行文字を出力します。表示されるエラー・メッセージは、エラー発生時に設定されたFerror内の現在のエラー番号に対して定義されているメッセージです。
大抵の場合、F_error()関数(またはF_error32()関数)の引数文字列には、エラーを引き起こしたプログラムの名前が含まれます。詳細は、『Oracle Tuxedo ATMI FML関数リファレンス』の「F_error、F_error32(3fml)」を参照してください。
エラー・メッセージのテキストをメッセージ・カタログから取り出すため、Fstrerror、Fstrerror32(3fml)を使用できます。これらの関数は、userlog(3c)、F_error()、またはF_error32()の引数として使用できるポインタを返します。
FMLの関数のエラー・コードについては、『Oracle Tuxedo ATMI FML関数リファレンス』の各関数のエントリを参照してください。
 
|