Defining Map Groups and Map Group Chunking Criteria
This section discusses how to:
Define map groups.
Define chunking criteria.
You can configure the data transformation process to run on maps as a group. A map group may contain map groups within the main map group, as well as one or more individual maps. Map groups are submitted as a job unit and can run either in serial or parallel mode. To optimize performance by processing data more efficiently, you can define chunking criteria on the Map Group Filter page.
Pages Used to Define Map Groups and Chunking Criteria
|
Page Name |
Definition Name |
Navigation |
Usage |
|---|---|---|---|
|
Map Groups |
EOEW_GRP_DFN |
|
Create map groups. |
|
Map Group Filter |
EOEW_GRP_FLTR |
Click the Chunking link on the Map Groups page. |
Define chunking criteria for maps. |
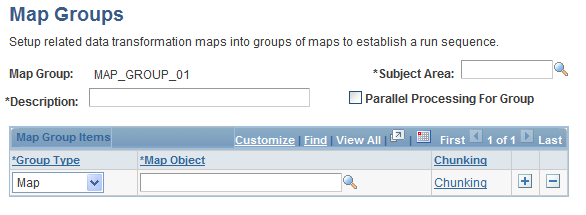
Map Groups Page
Use the Map Groups page (EOEW_GRP_DFN) to create map groups.
Image: Map Groups page
This example illustrates the fields and controls on the Map Groups page. You can find definitions for the fields and controls later on this page.
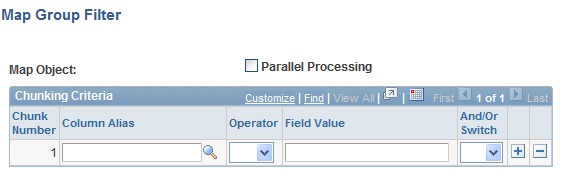
Map Group Filter Page
Use the Map Group Filter page (EOEW_GRP_FLTR) to define chunking criteria for maps.
Image: Map Group Filter page
This example illustrates the fields and controls on the Map Group Filter page. You can find definitions for the fields and controls later on this page.
Chunking is a mechanism that makes large amounts of processing easier through the use of multiple small parallel processes. By enabling chunking, multiple jobs are spawned from one job stream. These jobs run in parallel or serial to process data efficiently. It is an optional mechanism to help with performance. The user is responsible to define chunks that include all of the source data without duplicating any rows. The system will not verify this. The map group is still the unit of work. The group job is not complete until all of the chunks are also complete.
Note: The chunks you define must be configured to capture all of the source data without duplicating rows.