3 Supporting User Access to Oracle Big Data Appliance
This chapter describes how you can support users who are running MapReduce jobs on Oracle Big Data Appliance or using Oracle Big Data Connectors. It contains these sections:
3.1 Providing Remote Client Access to CDH
Oracle Big Data Appliance supports full local access to all commands and utilities in Cloudera's Distribution including Apache Hadoop (CDH).
You can use a browser on any computer that has access to the client network of Oracle Big Data Appliance to access Cloudera Manager, Hadoop Map/Reduce Administration, the Hadoop Task Tracker interface, and other browser-based Hadoop tools.
To issue Hadoop commands remotely, however, you must connect from a system configured as a CDH client with access to the Oracle Big Data Appliance client network. This section explains how to set up a computer so that you can access HDFS and submit MapReduce jobs on Oracle Big Data Appliance.
See Also:
My Oracle Support ID 1506203.13.1.1 Prerequisites
Ensure that you have met the following prerequisites:
-
You must have these access privileges:
-
Sudo access to the client system
-
Login access to Cloudera Manager
If you do not have these privileges, then contact your system administrator for help.
-
-
The client system must run an operating system that Cloudera supports for CDH4. For the list of supported operating systems, see "Before You Install CDH4 on a Cluster" in the Cloudera CDH4 Installation Guide at
http://ccp.cloudera.com/display/CDH4DOC/Before+You+Install+CDH4+on+a+Cluster -
The client system must run the same version of Oracle JDK as Oracle Big Data Appliance. CDH4 requires Oracle JDK 1.6.
3.1.2 Installing CDH on Oracle Exadata Database Machine
When you use Oracle Exadata Database Machine as the client, you can use the RPM files on Oracle Big Data Appliance, because both engineered systems use the same operating system (Oracle Linux 5.x). Copying the files across the local network is faster than downloading them from the Cloudera website.
Note:
In the following steps, replace version_number with the missing portion of the file name, such as 2.2.0+189-1.cdh4.2.0.p0.8.el5.To install a CDH client on Oracle Exadata Database Machine:
-
Log into an Exadata database server.
-
Verify that Hadoop is not installed on your Exadata system:
rpm -qa | grep hadoop
-
If the
rpmcommand returns a value, then remove the existing Hadoop software:rpm -e hadoop_rpm -
Copy the following Linux RPMs to the database server from the first server of Oracle Big Data Appliance. The RPMs are located in the /opt/oracle/BDAMammoth/bdarepo/RPMS/x86_64 directory.
-
ed-version_number.x86_64.rpm
-
m4-version_number.x86_64.rpm
-
nc-version_number.x86_64.rpm
-
redhat-lsb-version_number.x86_64.rpm
-
-
Install the Oracle Linux RPMs from Step 4 on all database nodes. For example:
sudo yum --nogpgcheck localinstall ed-0.2-39.el5_2.x86_64.rpm sudo yum --nogpgcheck localinstall m4-1.4.5-3.el5.1.x86_64.rpm sudo yum --nogpgcheck localinstall nc-1.84-10.fc6.x86_64.rpm sudo yum --nogpgcheck localinstall redhat-lsb-4.0-2.1.4.0.2.el5.x86_64.rpm
Be sure to install the Oracle Linux RPMs before installing the CDH RPMs.
-
Copy the following CDH RPMs from the /opt/oracle/BDAMammoth/bdarepo/RPMS/noarch directory.
-
bigtop-utils-version_number.noarch.rpm
-
zookeeper-version_number.noarch.rpm
-
-
Copy the following CDH RPMs from the /opt/oracle/BDAMammoth/bdarepo/RPMS/x86_64 directory.
-
hadoop-version_number.x86_64.rpm
-
bigtop-jsvc-version_number.x86_64.rpm
-
hadoop-hdfs-version_number.x86_64.rpm
-
hadoop-0.20-mapreduce-version_number.x86_64.rpm
-
hadoop-yarn-version_number.x86_64.rpm
-
hadoop-mapreduce-version_number.x86_64.rpm
-
hadoop-client-version_number.x86_64.rpm
-
-
Install the CDH RPMs in the exact order shown in Steps 6 and 7 on all database servers. For example:
rpm -ihv /bigtop-utils-0.4+502-1.cdh4.2.0.p0.12.el5.noarch.rpm rpm -ihv zookeeper-3.4.5+14-1.cdh4.2.0.p0.12.el5.noarch.rpm rpm -ihv hadoop-2.0.0+922-1.cdh4.2.0.p0.12.el5.x86_64.rpm rpm -ihv bigtop-jsvc-1.0.10-1.cdh4.2.0.p0.13.el5.x86_64.rpm rpm -ihv hadoop-hdfs-2.0.0+922-1.cdh4.2.0.p0.12.el5.x86_64.rpm rpm -ihv hadoop-0.20-mapreduce-0.20.2+1341-1.cdh4.2.0.p0.21.el5.x86_64.rpm rpm -ihv hadoop-yarn-2.0.0+922-1.cdh4.2.0.p0.12.el5.x86_64.rpm rpm -ihv hadoop-mapreduce-2.0.0+922-1.cdh4.2.0.p0.12.el5.x86_64.rpm rpm -ihv hadoop-client-2.0.0+922-1.cdh4.2.0.p0.12.el5.x86_64.rpm
-
Configure the CDH client. See "Configuring CDH."
3.1.3 Installing a CDH Client on Any Supported Operating System
To install a CDH client on any operating system identified as supported by Cloudera, follow these instructions.
To install the CDH client software:
-
Follow the installation instructions for your operating system provided in the Cloudera CDH4 Installation Guide at
http://ccp.cloudera.com/display/CDH4DOC/CDH4+Installation+GuideWhen you are done installing the Hadoop core and native packages, the system can act as a basic CDH client.
Note:
Be sure to install CDH4 Update 2 (CDH4u2) or a later version. -
To provide support for other components, such as Hive, Pig, or Oozie, see the component installation instructions.
-
Configure the CDH client. See "Configuring CDH."
3.1.4 Configuring CDH
After installing CDH, you must configure it for use with Oracle Big Data Appliance.
To configure the Hadoop client:
-
Open a browser on your client system and connect to Cloudera Manager. It runs on the JobTracker node (node03) and listens on port 7180, as shown in this example:
http://bda1node03.example.com:7180
-
Log in as
admin. -
On the Services tab, open the Actions menu for the cluster, and then select Client Configuration URLs.
-
Click the MapReduce URL (/cmf/services/2/client-config) and download mapreduce-clientconfig.zip.
The following figure shows the download page for the client configuration.
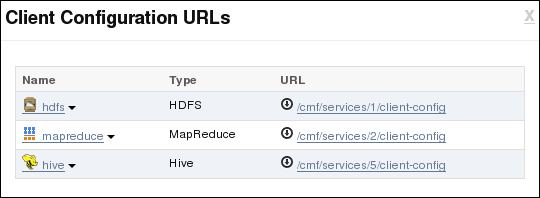
Description of the illustration generate_client.png
-
Log out of Cloudera Manager and navigate to the download directory.
-
Unzip mapreduce-clientconfig.zip into a permanent location on the client system.
$ unzip mapreduce-clientconfig.zip Archive: mapreduce-clientconfig.zip inflating: hadoop-conf/hadoop-env.sh inflating: hadoop-conf/core-site.xml inflating: hadoop-conf/hdfs-site.xml inflating: hadoop-conf/log4j.properties inflating: hadoop-conf/mapred-site.xmlAll files are stored in a subdirectory named hadoop-config.
-
Open hadoop-env.sh in a text editor and set
JAVA_HOMEto the correct location on your system:export JAVA_HOME=full_directory_path -
Delete the number sign (#) to uncomment the line, and then save the file.
-
Make a backup copy of the Hadoop configuration files:
# cp /full_path/hadoop-conf /full_path/hadoop-conf-bak
-
Overwrite the existing configuration files with the downloaded configuration files in Step 6.
# cd /full_path/hadoop-conf # cp * /usr/lib/hadoop/conf -
Verify that you can access HDFS on Oracle Big Data Appliance from the client, by entering a simple Hadoop file system command like the following:
$ hadoop fs -ls /user Found 4 items drwx------ - hdfs supergroup 0 2013-01-16 13:50 /user/hdfs drwxr-xr-x - hive supergroup 0 2013-01-16 12:58 /user/hive drwxr-xr-x - oozie hadoop 0 2013-01-16 13:01 /user/oozie drwxr-xr-x - oracle hadoop 0 2013-01-29 12:50 /user/oracleCheck the output for HDFS users defined on Oracle Big Data Appliance, and not on the client system. You should see the same results as you would after entering the command directly on Oracle Big Data Appliance.
-
Validate the installation by submitting a MapReduce job. You must be logged in to the host computer under the same user name as your HDFS user name on Oracle Big Data Appliance.
The following example calculates the value of pi:
$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples-2.0.0-cdh4.2.0.jar pi 10 1000000 Number of Maps = 10 Samples per Map = 1000000 Wrote input for Map #0 Wrote input for Map #1 . . . 13/04/30 08:15:50 INFO mapred.JobClient: BYTES_READ=240 Job Finished in 12.403 seconds Estimated value of Pi is 3.14158440000000000000 -
Use Cloudera Manager to verify that the job ran on Oracle Big Data Appliance instead of the local system. Select mapreduce from the Activities menu for a list of jobs.
Figure 3-1 shows the job created by the previous example.
Figure 3-1 Monitoring a MapReduce Job in Cloudera Manager
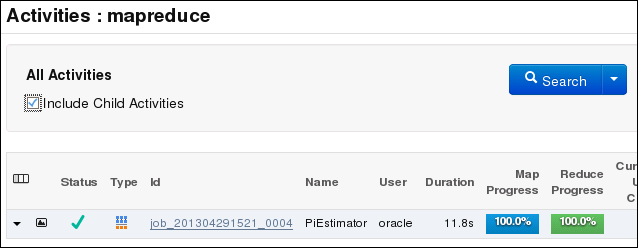
Description of "Figure 3-1 Monitoring a MapReduce Job in Cloudera Manager"
3.2 Managing User Accounts
This section describes how to create users who can access HDFS, MapReduce, and Hive. It contains the following topics:
3.2.1 Creating Hadoop Cluster Users
When creating additional user accounts, define them as follows:
-
To create and modify tables in Hive, users must be in the
hivegroup. -
To create Hue users, open Hue in a browser and click the User Admin icon. See "Using Hue to Interact With Hadoop."
To create a Hadoop cluster user:
-
Open an ssh connection as the
rootuser to a noncritical node (node04 to node18). -
Create the user's home directory:
# sudo -u hdfs hadoop fs -mkdir /user/user_nameYou use
sudobecause the HDFS super user ishdfs(notroot). -
Change the ownership of the directory:
# sudo -u hdfs hadoop fs -chown user_name:hadoop /user/user_name
-
Verify that the directory is set up correctly:
# hadoop fs -ls /user
-
Create the operating system user across all nodes in the cluster:
# dcli useradd -G hadoop,hive[,group_name...] -m user_name
In this syntax, replace group_name with an existing group and user_name with the new name.
-
Verify that the operating system user belongs to the correct groups:
# dcli id user_name -
Verify that the user's home directory was created on all nodes:
# dcli ls /home | grep user_name
Example 3-1 creates a user named jdoe with a primary group of hadoop and an addition group of hive.
Example 3-1 Creating a Hadoop User
# sudo -u hdfs hadoop fs -mkdir /user/jdoe # sudo -u hdfs hadoop fs -chown jdoe:hadoop /user/jdoe # hadoop fs -ls /user Found 5 items drwx------ - hdfs supergroup 0 2013-01-16 13:50 /user/hdfs drwxr-xr-x - hive supergroup 0 2013-01-16 12:58 /user/hive drwxr-xr-x - jdoe jdoe 0 2013-01-18 14:04 /user/jdoe drwxr-xr-x - oozie hadoop 0 2013-01-16 13:01 /user/oozie drwxr-xr-x - oracle hadoop 0 2013-01-16 13:01 /user/oracle # dcli useradd -G hadoop,hive -m jdoe # dcli id jdoe bda1node01: uid=1001(jdoe) gid=1003(jdoe) groups=1003(jdoe),127(hive),123(hadoop) bda1node02: uid=1001(jdoe) gid=1003(jdoe) groups=1003(jdoe),123(hadoop),127(hive) bda1node03: uid=1001(jdoe) gid=1003(jdoe) groups=1003(jdoe),123(hadoop),127(hive) . . . # dcli ls /home | grep jdoe bda1node01: jdoe bda1node02: jdoe bda1node03: jdoe
3.2.2 Providing User Login Privileges (Optional)
Users do not need login privileges on Oracle Big Data Appliance to run MapReduce jobs from a remote client. However, for those who want to log in to Oracle Big Data Appliance, you must set a password. You can set or reset a password the same way.
To set a user password across all Oracle Big Data Appliance servers:
-
Create a Hadoop cluster user as described in "Creating Hadoop Cluster Users.".
-
Confirm that the user does not have a password:
# dcli passwd -S user_name bda1node01.example.com: jdoe NP 2013-01-22 0 99999 7 -1 (Empty password.) bda1node02.example.com: jdoe NP 2013-01-22 0 99999 7 -1 (Empty password.) bda1node03.example.com: jdoe NP 2013-01-22 0 99999 7 -1 (Empty password.)
If the output shows either "Empty password" or "Password locked," then you must set a password.
-
Set the password:
hash=$(echo 'password' | openssl passwd -1 -stdin); dcli "usermod --pass='$hash' user_name"
-
Confirm that the password is set across all servers:
# dcli passwd -S user_name bda1node01.example.com: jdoe PS 2013-01-24 0 99999 7 -1 (Password set, MD5 crypt.) bda1node02.example.com: jdoe PS 2013-01-24 0 99999 7 -1 (Password set, MD5 crypt.) bda1node03.example.com: jdoe PS 2013-01-24 0 99999 7 -1 (Password set, MD5 crypt.)
See Also:
-
Oracle Big Data Appliance Owner's Guide for information about
dcli. -
The Linux
manpage for the full syntax of theuseraddcommand.
3.3 Recovering Deleted Files
CDH provides an optional trash facility, so that a deleted file or directory is moved to a trash directory for a set period of time instead of being deleted immediately from the system. By default, the trash facility is enabled for HDFS and all HDFS clients.
3.3.1 Restoring Files from the Trash
When the trash facility is enabled, you can easily restore files that were previously deleted.
To restore a file from the trash directory:
-
Check that the deleted file is in the trash. The following example checks for files deleted by the
oracleuser:$ hadoop fs -ls .Trash/Current/user/oracle Found 1 items -rw-r--r-- 3 oracle hadoop 242510990 2012-08-31 11:20 /user/oracle/.Trash/Current/user/oracle/ontime_s.dat -
Move or copy the file to its previous location. The following example moves ontime_s.dat from the trash to the HDFS /user/oracle directory.
$ hadoop fs -mv .Trash/Current/user/oracle/ontime_s.dat /user/oracle/ontime_s.dat
3.3.2 Changing the Trash Interval
The trash interval is the minimum number of minutes that a file remains in the trash directory before being deleted permanently from the system. The default value is 1 day (24 hours).
To change the trash interval:
-
Open Cloudera Manager. See "Managing CDH Operations Using Cloudera Manager".
-
On the All Services page under Name, click hdfs.
-
On the hdfs page, click Configuration, and then select View and Edit.
-
Search for or scroll down to the Filesystem Trash Interval property under NameNode Settings. See Figure 3-2.
-
Click the current value, and enter a new value in the pop-up form.
-
Click Save Changes.
-
Expand the Actions menu at the top of the page and choose Restart.
-
Open a connection as
rootto a node in the cluster. -
Deploy the new configuration:
dcli -C bdagetclientconfig
Figure 3-2 shows the Filesystem Trash Interval property in Cloudera Manager.
Figure 3-2 HDFS Property Settings in Cloudera Manager
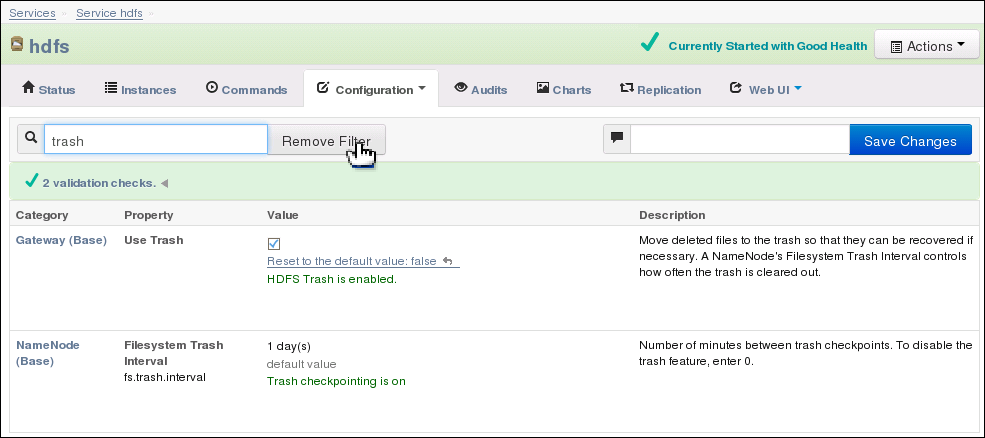
Description of "Figure 3-2 HDFS Property Settings in Cloudera Manager"
3.3.3 Disabling the Trash Facility
The trash facility on Oracle Big Data Appliance is enabled by default. You can change this configuration for a cluster. When the trash facility is disabled, deleted files and directories are not moved to the trash. They are not recoverable.
3.3.3.1 Completely Disabling the Trash Facility
The following procedure disables the trash facility for HDFS. When the trash facility is completely disabled, the client configuration is irrelevant.
To completely disable the trash facility:
-
Open Cloudera Manager. See "Managing CDH Operations Using Cloudera Manager".
-
On the All Services page under Name, click hdfs.
-
On the hdfs page, click the Configuration subtab.
-
Search for or scroll down to the Filesystem Trash Interval property under NameNode Settings. See Figure 3-2.
-
Click the current value, and enter a value of 0 (zero) in the pop-up form.
-
Click Save Changes.
-
Expand the Actions menu at the top of the page and choose Restart.
3.3.3.2 Disabling the Trash Facility for Local HDFS Clients
All HDFS clients that are installed on Oracle Big Data Appliance are configured to use the trash facility. An HDFS client is any software that connects to HDFS to perform operations such as listing HDFS files, copying files to and from HDFS, and creating directories.
You can use Cloudera Manager to change the local client configuration setting, although the trash facility is still enabled.
Note:
If you do not want any clients to use the trash, then you can completely disable the trash facility. See "Completely Disabling the Trash Facility."To disable the trash facility for local HDFS clients:
-
Open Cloudera Manager. See "Managing CDH Operations Using Cloudera Manager".
-
On the All Services page under Name, click hdfs.
-
On the hdfs page, click the Configuration subtab.
-
Search for or scroll down to the Use Trash property under Client Settings. See Figure 3-2.
-
Deselect the Use Trash check box.
-
Click Save Changes. This setting is used to configure all new HDFS clients downloaded to Oracle Big Data Appliance.
-
Open a connection as
rootto a node in the cluster. -
Deploy the new configuration:
dcli -C bdagetclientconfig
3.3.3.3 Disabling the Trash Facility for a Remote HDFS Client
Remote HDFS clients are typically configured by downloading and installing a CDH client, as described in "Providing Remote Client Access to CDH." Oracle SQL Connector for HDFS and Oracle R Connector for Hadoop are examples of remote clients.
To disable the trash facility for a remote HDFS client:
-
Open a connection to the system where the CDH client is installed.
-
Open /etc/hadoop/conf/hdfs-site.xml in a text editor.
-
Change the trash interval to zero:
<property> <name>fs.trash.interval</name> <value>0</value> </property> -
Save the file.