Bootstrapping is a simple technique that estimates the reliability or accuracy of forecast statistics or other sample data. Classical methods rely on mathematical formulas to describe the accuracy of sample statistics. When a statistic’s sampling distribution is not normally distributed or easily found, these classical methods are difficult to use or are invalid.
Bootstrapping analyzes sample statistics by repeatedly sampling the data and creating distributions of the different statistics from each sampling. The term bootstrap comes from the saying, “to pull oneself up by one’s own bootstraps”, since this method uses the distribution of statistics itself to analyze the statistics’ accuracy.
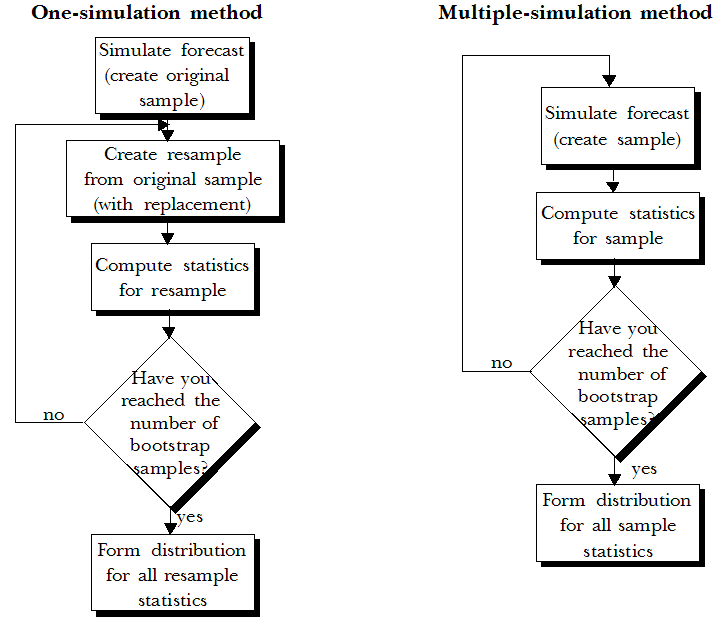
Two bootstrap methods are available with this tool:
One-simulation method — Simulates the model data once (creating the original sample) and then repeatedly resamples those simulation trials (the original sample values). Resampling creates a new sample from the original sample with replacement. That is, it returns the selected value to the sample before selecting another value, letting the selector possibly reselect the same value. It then creates a distribution of the statistics calculated from each resample. This method assumes only that the original simulation data accurately portrays the true forecast distribution, which is likely if the sample is large enough. This method isn’t as accurate as the multiple-simulation method, but it takes significantly less time to run.
Multiple-simulation method — Repeatedly simulates the model, and then creates a distribution of the statistics from each simulation. This method is more accurate than the one-simulation method, but it may take a prohibitive amount of time.
When you use the multiple-simulation method, the tool temporarily turns off the Use Same Sequence Of Random Numbers option. In statistics literature, the one-simulation method is also called the non-parametric bootstrap, and the multisimulation method is also called the parametric bootstrap. |
Since the bootstrap technique does not assume that the sampling distribution is normally distributed, you can use it to estimate the sampling distribution of any statistic, even an unconventional one such as the minimum or maximum value of a forecast. You can also easily estimate complex statistics, such as the correlation coefficient of two data sets, or combinations of statistics, such as the ratio of a mean to a variance.
To estimate the accuracy of Latin Hypercube statistics, you must use the multiple-simulation method.