2 Example Deployments Using the Directory Server
This chapter provides sample configurations for a replicated topology including multiple instances of the Oracle Unified Directory directory server.
This section covers the following topics:
For a complete understanding of how replication works in Oracle Unified Directory, see Chapter 7, "Understanding the Oracle Unified Directory Replication Model."
2.1 Small Replicated Topology
By replicating directory data across servers, you can reduce the access load on a single server, improving server response time and providing horizontal read scalability. In addition, you can use replication to ensure availability of data if a system failure occurs.
Note:
You cannot use replication to scale write operations because a write operation to one directory server results in a write operation to every other server in the topology. The only way to scale write operations horizontally is to split the directory data among multiple databases and place those databases on different servers.The centralized replication model in Oracle Unified Directory separates user data from replication metadata. In this model, the server that stores the user data is called the directory server. The server that stores the replication metadata is called the replication server. This approach simplifies the management of replication topologies and can improve performance.
For small deployments, you can set up replication by putting the replication servers and directory servers on the same system. You can further simplify administration by running the replication server and the directory server on each system in a single process.
The following figure shows how you can use replication to ensure availability and to provide read scalability in a small topology.
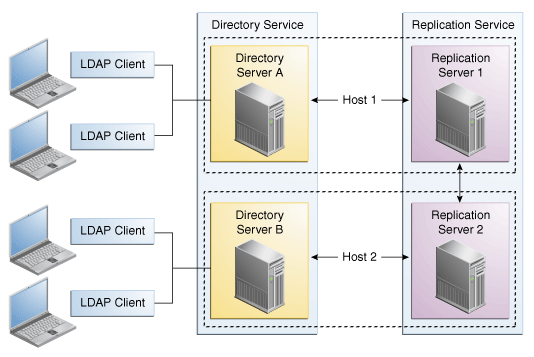
2.1.1 The Role of Directory Servers in a Topology
Directory servers are responsible for the following tasks:
-
Persistence of data and serving client requests
-
Forwarding changes to specific replication servers
When a change is made on a directory server, that server forwards the change to a selected replication server. The replication server then replays the change to other replication servers in the topology, which in turn replay the change to all other directory servers in the topology.
Each directory server contains the following items:
-
A list of the suffix DNs to be synchronized
-
A list of the replication servers to which each suffix DN can connect
Applications should typically perform reads and writes on the same directory server instance, which prevents those applications from experiencing consistency problems due to loose consistency.
2.1.2 The Role of Replication Servers in a Topology
Replication servers are responsible for the following tasks:
-
Managing connections from directory servers
-
Connecting to other replication servers
-
Listening for connections from other replication servers
-
Receiving changes from directory servers
-
Forwarding changes to directory servers and to other replication servers
-
Saving changes to stable storage, which includes trimming older operations
Each replication server contains a list of all the other replication servers in the replication topology. Replication servers are also responsible for providing other servers with information about the replication topology. Even the smallest deployment must include two replication server instances, to ensure availability in case one of the replication server instances fails. There is usually no need for additional replication server instances unless the directory service must be able to survive more than one failure at a time, or unless the number of directory server instances must be very large.
Note:
In a replication architecture, each replication server is connected to every other replication server in the topology.Although replication servers do not store directory data, they are always LDAP servers or JMX servers. Like directory servers, you can configure, monitor, back up, and restore replication servers.
2.2 Multiple Data Center Topology
Replication enables geographic distribution of the directory service by providing identical copies of directory data on multiple servers across more than one data center. The basic principles of a replication deployment outlined in the small topology also apply to multiple data center deployments.
The Oracle Unified Directory directory server uses a custom replication protocol that is efficient over a wide area network (WAN). In the following scenario, an enterprise has two major data centers, one in London and the other in New York, separated by a WAN.
This deployment includes two replication server instances for availability in each data center, in case one of the replication server instances fails. The directory servers connect first to local replication servers. Directory servers only access replication servers in another data center if all local replication servers have failed. Client applications always connect to local directory server instances, and perform reads and writes on the same directory server instance.
The Oracle Unified Directory directory server supports an unlimited number of read/write directory servers in a replication topology. The number of directory servers can be scaled according to the read requirements of the organization.
Note:
Increasing the number of directory servers does not scale the number of writes that can be processed because ultimately all servers in the topology must process all the writes. Unless it is acceptable to have a topology that does not converge, the write throughput of the topology is limited to the write throughput of the slowest server.Figure 2-2 Multiple Data Center Topology
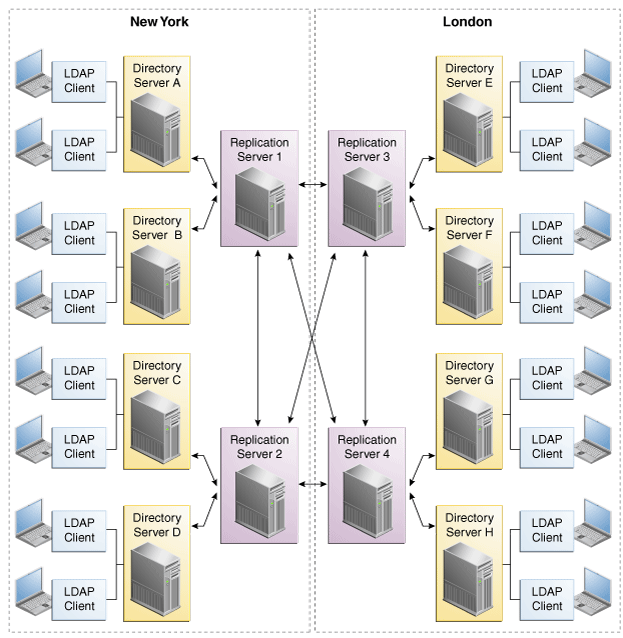
Description of ''Figure 2-2 Multiple Data Center Topology''
2.2.1 Multiple Data Centers and Replication Groups
Replication groups enable you to organize a replicated topology according to specific criteria, such as data center location. A replication group is identified by a unique ID that is applied to the replication servers and the directory servers in that group. Group IDs determine how a directory server domain connects to an available replication server. From the list of configured replication servers, a directory server first tries to connect to a replication server that has the same group ID as that of the directory server.
This sample deployment shows the use of replication groups across multiple data centers. The deployment assumes two data centers, connected by a wide area network (WAN), with the following configuration:
-
Each replication server and directory server within a single data center has the same group ID.
-
The entire data center has a unique group ID (one group ID per data center).
Figure 2-3 shows a disaster recovery deployment that includes two data centers with different group IDs.
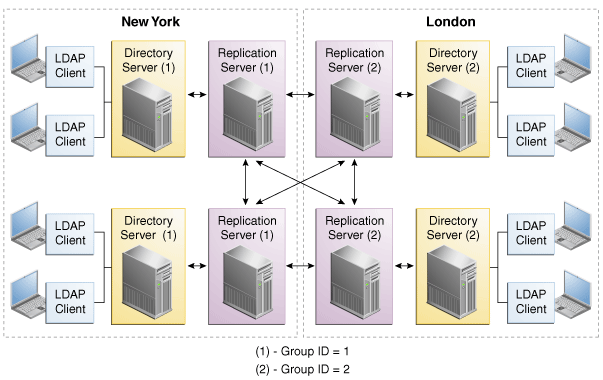
In this deployment, each directory server will attempt to connect to a replication server in its own data center, avoiding the latency associated with connection over a WAN. If all the replication servers in a data center fail, the directory server will connect to a remote replication server. This ensures that the replication service is maintained, albeit in a degraded manner (if the connection between data centers is slow). When one or more local replication servers is back online, the directory servers will automatically reconnect to a local replication server.
2.2.2 Multiple Data Centers and the Window Mechanism
The Oracle Unified Directory directory server provides a window mechanism which specifies that a certain number of update requests are sent without one server having to wait for an acknowledgment from the recipient server before continuing.
The window size represents the maximum number of update messages that can be sent without immediate acknowledgment from the recipient server. If the topology spans multiple data centers connected by a network with large latency, it might be worth increasing the window size beyond its default value of 100. To assess whether the window size is the limiting factor in replication throughput, monitor the current-send-window and current-rcv-window attributes below cn=monitor.
If a server publishes a current-send-window to another server that is consistently zero or close to zero and the corresponding server publishes a current-rcv-window that is higher, it means that all the data are currently in the network. In this case, increasing the window size on the recipient server should increase replication speed and reduce replication delay. These improvements will result in the consumption of more resources on the recipient server.