| Oracle® Life Sciences Data Hub Application Developer's Guide Release 2.4 E54089-01 |
|
|
PDF · Mobi · ePub |
| Oracle® Life Sciences Data Hub Application Developer's Guide Release 2.4 E54089-01 |
|
|
PDF · Mobi · ePub |
This section contains information on the following topics:
The Oracle Life Sciences Data Hub (Oracle LSH) offers the following capabilities related to execution and data handling:
You can submit a job for immediate execution or schedule it for a later date and time or set it up to run at regular intervals; see "Submitting Jobs for Execution".
You can set up and run backchain execution to ensure that you are processing the most current data available in the source data system; see "Backchaining".
If you are using Reload processing, you can choose to run in either Full or Incremental mode; use Incremental mode to quickly load and changed data; use Full mode to do the same and also to delete records that are not reloaded; see "Reload Processing".
Apply snapshot labels to the target or both source and target Table instances that a particular job reads from and writes to; see "Data Snapshots".
Maintain blinded data; see "Managing Blinded Data".
Each job submitted from the user interface is called a master job. A master job may execute a single executable object, such as a Program, Load Set, or Data Mart. When a user submits a Report Set, the master job includes the execution of all the Program instances contained in the Report Set. A Workflow execution may include the execution of other executable objects. A Program execution using backchaining is also a master job that includes multiple subjobs.
Oracle LSH uses the runtime platform of the Oracle Warehouse Builder for all internal execution. Some additional information is available in "Stopping and Starting Services and Queues" in the Oracle Life Sciences Data Hub System Administrator's Guide.
You execute each type of Oracle LSH executable objectâPrograms, Load Sets, Report Sets, Workflows, and Data Martsâin the same way.
Before you can submit any executable object, you must do the following:
Define an Execution Setup for the executable instance. See "Creating, Modifying, and Submitting Execution Setups" for instructions.
Map the executable instance's source and target Table Descriptors to Table instances; see "Mapping Table Descriptors to Table Instances".
Install the instance and all the Table instances to which it is mapped; see Chapter 12, "Using, Installing, and Cloning Work Areas".
Ensure that the source Table instances contain data.
After you have submitted a job, you can track its progress and see details about the job in the Job Execution section of your My Home screen. For information about the job information displayed, see "Tracking Job Execution" in the Oracle Life Sciences Data Hub User's Guide.
Submitting a Job from the Applications Tab While you are defining an executable object, it's easiest to submit it directly from the instance in its Work Area. You can also submit jobs from your My Home screen and from the Reports tab; see "Generating Reports and Running Other Jobs" in the Oracle Life Sciences Data Hub User's Guide.
To submit a job from the Applications tab, do the following:
In the appropriate Work Area, navigate to the installed executable instance you want to submit.
Click Run. The Submission screen opens.
Alternatively, in the Actions drop-down list, click Execution Setups, then Click the Submit icon of the Execution Setup you want to use. The Submission screen opens.
Set values for Submission Details, Submission Parameters, and Data Currency as necessary. For information on each of these, see "Creating, Modifying, and Submitting Execution Setups".
Click Submit. The system submits the job for execution and displays the job ID.
This section contains the following topics:
Oracle LSH offers four different basic types of data processing to accommodate the different technologies used for loading data into Oracle LSH and operating on data within Oracle LSH: transactional, reload, staging, and transactional high throughput. The types are described in the following sections.
The type of processing the system uses depends on the processing type specified for the target Table instance, not the Program. However, you must be careful to choose a processing type for a Table instance that is compatible with the Program that writes to it:
If the processing type is Transactional, the source code must explicitly update, insert, and delete records.
If the processing type is Reload, the source code must simply ensure that all records from the source are loaded (as Inserts) into the target Table instance.
Program instances need to be compatible only with Table instances they write to. Any Program instance can read from a Table instance of any processing type.
Although only one Program instance can write to a particular Table instance, some data processing types allow more than one execution of that Program to run at the same time.
Each processing type is described in the following sections. The following table summarizes the differences among Oracle LSH data processing types in terms of whether they require Unique or Primary Keys, are audited, and the kind of data deletion that they effect:
Table 13-1 Summary of Oracle LSH Data Processing Types
| Processing Type | UK/PK Required? | Audited? | Data Deletion |
|---|---|---|---|
|
Transactional with Audit |
Yes |
Yes |
Soft-deletes data specified by the Program with explicit DML Delete statements. |
|
Transactional without Audit |
No |
No |
Hard-deletes data specified by the Program with explicit DML Delete statements. |
|
Reload |
Yes |
Yes |
In Full mode, soft-deletes all data not reinserted. In Incremental mode, does not delete data. |
|
Staging with Audit |
No |
Yes |
Deletes all data immediately before the next Program execution; saves a copy of the data. |
|
Staging without Audit |
No |
No |
Hard-deletes all data immediately before the next Program execution. |
|
Transactional High Throughput |
No |
No |
Truncates the Table in Full mode. Hard-deletes data with explicit DML Delete statements in the Incremental mode. |
Reload and Transactional with Audit types require either a Primary Key or a Unique Key to be defined for the Table instance. Staging and Transactional without Audit types do not require a Primary or Unique Key.
Transactional, Reload, and Transactional High Throughput Table instances must be mapped to target Table Descriptors of the same type. Staging Table instances can be mapped to target Table Descriptors of any processing type.
From the point of view of the Program writing to the Table instance, a Transactional target Table Descriptor can be mapped to either a Transactional or Staging Table instance and a Reload target Table Descriptor can be mapped to either a Reload or Staging Table instance. Staging Table Descriptors must be mapped to Staging Table instances.
All types except Staging are serialized, so that only one job can write to the Table instance at a time. For staging Table instances, if more than one job writes to the Table instance at a time, the system ensures that there is at least one second's difference in the refresh timestamp.
Different processing types handle data deletion differently:
Transactional processing deletes only those records specified in Delete statements in the Program source code. If the Table instance is audited, the system only soft-deletes the data.
Incremental Reload processing never deletes data. Full Reload processing soft-deletes all records not explicitly reloaded.
Staging Without Audit processing deletes all the data written by the previous job at the beginning of the next job. Staging With Audit does not delete data.
Transactional High Throughput processing truncates the Table in the Full mode. In the Incremental mode, hard-deletes data if the Program source code specifically issues a Delete statement.
In transactional processing, the Program writing to the Table instance does the work of determining which records are inserted, updated, and deleted. The system populates the target database table using explicit DML statements (Insert, Update, or Delete) in the Program's source code. The system processes only those records that the Program specifies; records not explicitly inserted, updated, or deleted are not processed. If a record is explicitly updated but if the data remains the same, the system updates its refresh timestamp.
The Program writing to the table can "see" all current data, including changes it has made and records from previous jobs that are still current. Only one job can write to a Transactional table at a time. The system serializes them.
There are several data processing types that use transactional processing:
Transactional with Audit. The system maintains a record of all changes to all records, including deleted records, over time. Only one Program instance at a time can write to a Table instance of this type.
Transactional without Audit. The system maintains only the current set of records. Only one Program execution at a time can write to a Table instance of this type.
In Reload processing, the internal data processing algorithm does the work of determining which records to insert, update, and delete. The Program writing to the Table instance simply inserts data (and must insert all data from the source). The system compares the unique or primary key of each inserted record to the existing records to determine whether the record insertion is treated as an insert or an update: if a record already exists with the same unique or primary key, the system treats the loading of that record as an update. The way the system processes deletions depends on whether the job is run in Full or Incremental mode (see below).
If the updated record does not include any data changes, the system simply changes its refresh timestamp to the timestamp of the current job.
Reload processing requires a primary or unique key defined for the target Table instance. If both exist, you must specify which one to use for data processing. It is not necessary to have a primary or unique key defined on the source; for example, a Load Set can successfully load SAS data into an Oracle LSH Table instance even if no primary or unique key is defined for the dataset in the source SAS system.
Programs writing to reload tables can "see" only data processed in the current job.
Reload Table instances are always audited. Only one job can write to a Reload table at a time. The system serializes them.
There are two modes of reload processing: Incremental and Full. The mode used is set in the Execution Setup for the Program writing to the Reload table. It can be bound or settable at runtime by the person submitting the job.
Incremental Reload. In incremental processing, the system never deletes a record. If a record is not reloaded it remains in the system but its timestamp is not updated.
Full Reload. Full reload processing is the same as incremental processing except for one additional step: after processing all the records, the system soft-deletes all records that were not reloaded. The system keeps soft-deleted records in the database associated with an end timestamp and inserts an additional row to explicitly record the deletion.
If you are incrementally adding records to a table, or loading updated versions of different subsets of data, choose Incremental. If you are reloading a complete set of the most up-to-date records that may be missing some records due to deletions, choose Full
Incremental Reload Example Use Incremental Reload processing for the target Table instance of a Load Set that loads new lab data every week. Do not use Full Reload for loads that contain only new data, because Full Reload would delete all the data not explicitly loaded.
Full Reload Example Use Full Reload processing occasionally for cleanup with jobs that normally use Incremental Processing. For example, use Incremental Reload to load the external demography table nightly, but use Full Reload on the same table once a month before running a monthly report, to delete any records that have been deleted from the external table.
Staging Tables are compatible with any type of Program; that is, you can map a Program target Table Descriptor of any typeâStaging, Reload, or Transactionalâto a staging Table instance.
Staging processing is designed specifically to hold data only for the duration of the execution of the Program or Load Set that writes to the Table instance. If the Program to which a staging Table instance is mapped is contained in a Report Set of Workflow, the system retains the data for the duration of the master job (the whole Report Set or Workflow). However, you can choose to audit a staging Table instance, so that its data is never hard-deleted:
Staging with Audit. In staging processing with auditing, the system does not delete any data; the records remain in the table with a creation timestamp equal to the refresh timestamp of the job that inserted them. The staging processing logic allows a job to process only records whose creation timestamp is equal to its own timestamp. Records in a staging Table instance do not have an end timestamp.
There is no relationship between records with one creation timestamp and those with another, whether or not they share a unique or primary key. For example, loading the same set of records twice will result in the table containing two complete sets of the loaded records.
Staging without Audit In staging processing without auditing, immediately before the next execution of the Program, the system hard-deletes the data in the table. This setting saves space in the database.
More than one job can run on a staging table instance at a time. Each job can "see" only the records whose creation timestamp is equal to its own refresh timestamp.
Example You might want to audit data in a staging table that you use for reports on different subsets of data; for example, a Table that holds Adverse Events data that you report in groups according to patient age: one report for Patients in their 20s, another for those in their 30s, and so on.
This is an audit-less processing type, specifically designed to load large volumes of raw data as quickly as possible. It also supports DML statements.
Note:
If you convert a Transactional High Throughput data processing type Table into a Table with any of the other processing types (by modifying the Table's Process Type attribute), you are required to perform a full install of the Table when you install the Work Area next. This results in the re-creation of the Table and you lose all the existing data.This processing type supports full and incremental data loading.
You can load large volumes of data by splitting the data loading job and yet be able to view all of the data together in a single snapshot.
This processing type has the following features:
Displays All Data in a Single Snapshot. This data processing type makes all of the data available in a single snapshot even if the data is loaded through multiple jobs (when you use the Full data loading mode).
Supports Blinding. This data processing type provides full support for data Blinding. You can mark the data loaded into the target Table of this processing type as Blinded or Dummy in the same way as with the other data processing types.
Note:
If the table is blinded and data has been loaded into both partitions then performing a load using full mode will delete the data from both partitions. You will lose all Blinded data if you choose the full mode for loading data, even if you run the job with the Dummy Blind Break setting. The system warns you if a new data-loading job is about to overwrite Blinded data giving you the option to cancel the job.Supports Full and Incremental Data Loading Modes. This processing type supports both incremental and full data loads. The default mode is full. In the full mode, the system truncates the existing Table and loads fresh data into it. In this mode, you will lose all the Blinded data in the Table, even if you run the job with the Dummy Blind Break setting.
In the incremental mode, the new data is appended to the Table. The system hard-deletes data only if the Oracle LSH Program explicitly issues a Delete statement.
Note:
The default data loading mode is Full. If you do not want to lose all your existing data, change the data loading mode to Incremental.Supports Compression. If you create Oracle LSH Table instances marked with Transactional High Throughput data processing type in a tablespace that supports compression, you can compress these Tables.
Supports Serialized Data Writing and Parallel Data Reading. Only one job can write data to a Table instance at a time. However, multiple jobs can read data from a Table instance, even when another writing job is running in parallel.
Does Not Support Logical Rollback on Failure. In the event of a failure during data load, the system does not roll back the data that is already committed to the database. For example, if a job is inserting 5000 records into a Transactional High Throughput Table, and encounters an error at the 4000th record, the 3999 records already committed to the database are not rolled back.
This is different from all the other data processing types, in that, when a job fails, the system removes all the data written to the Table and committed to the database as part of that job.
Does Not Require Unique/Primary Key. You do not have to specify a unique/primary key for Table instances of this processing type. However if you specify these constraints, the Transactional High Throughput data processing type enforces them.
For Table instances that are the target of an Oracle-technology Load Set, you can specify in the Process Type drop-down list that the Table instance is a pass-through view. No processing type is required because the system does not write data to the Table instance. Instead, you use the Table instance as a view to see data in the source system.
For further information, see "About Oracle Tables and Views Load Sets".
To enable auditing of all changes to data, provide consistent views of data at a point in time, and provide consistent views across a set of tables, Oracle LSH implements table auditing, snapshots, and multi-table refresh groups.
When a table is audited, Oracle LSH never truly deletes data from the table, but records each change to each record over time, including deletion. Because the data remains in the table, with timestamps for each update, you can recreate the state of data in the table at any previous point in time in a data snapshot.
If a Table is used in such a way that an audit trail is unnecessaryâfor example, the Table is used only as a temporary staging areaâthen you can save space in the database by using a processing type without auditing.
The audit facility for Transactional and Reload processing is based on a self-journaling mechanism: record "versioning" within a table. Each record's uniqueness is defined by a primary or unique key; for example, in a patient enrollment table, the patient ID is the primary key. No other patient has the same ID.
Therefore each time a Program or Load Set writes a row to a Table instance with a patient ID that already exists in the Table instance, the stem sees the new row as an update for an existing patient. Instead of making a change in the existing row, however, the system sets the end timestamp for the existing row for the patient and inserts a new row with the current Column values and a creation timestamp equal to the end timestamp of the previous row. Each row effectively becomes a version of a patient record that is current during the period between its creation timestamp and its end timestamp. Only one version of a record is current at any point in time. The current row always has distant future end timestamp: 3 million Julian.
The timestamp used for records' creation and end timestamp is constant for a given master job; it is the refresh timestamp (REFRESH_TS) of the job.
Insertions When a new recordâa record whose primary or unique key value does not match any other in the Table instanceâis inserted, the system sets the creation timestamp to the job timestamp (REFRESH_TS) and the end timestamp to 3 million Julian.
Updates As records are updated, either through explicit updates in transactional processing or implicitly in reload processing, for each modified record the system:
sets the end timestamp to the job's refresh timestamp for the most recent row
inserts a new row with a creation timestamp equal to the job's refresh timestamp and an end timestamp of 3 million Julian
Deletions When a record is deleted, either explicitly through transactional processing or implicitly through full reload processing, the system sets the end timestamp of the current row to the job's refresh timestamp minus 1 second and also inserts an additional row to explicitly document the deletion. This deletion row has a creation timestamp set to the job's refresh timestamp minus second and an end timestamp of the job's refresh timestamp. This is called "soft-deletion;" the record remains in the database.
Auditing in Staging processing is much simpler; the system saves a copy of data written to the Table instance for each job. Each set of records has the same creation timestampâthe refresh timestamp of the job that created them. With each job, the entire current set of records is inserted. While the job that inserts the records can also perform updates or deletions of those records, there is no audit of these changes.
Snapshots allow Oracle LSH to view the data in one or more Table instances in the state it was in at the completion of any job that modified data in the Table instance(s).
The system uses the master job's refresh timestamp for the creation timestamp (and, for deleted records, end timestamp) of all records processed in a master job.
The system uses the master job's refresh timestamp for the creation timestamp (and, for deleted records, end timestamp) of all records processed in a master job, even if the job takes place over a number of hours and includes incremental commits. A master job is any job submitted explicitly for execution. Some master jobs include subjobs; for example, Workflows, Report Sets and any executable submitted using backchaining.
A snapshot comprises all the records in a Table instance that are current at a given point in time. For reload and audited transaction Table instances, a snapshot is the set of records whose end timestamp is greater than, and whose creation timestamp is less than or equal to, a given refresh timestamp. For audited staging Table instances, it is the set of records whose creation timestamp equals the refresh timestamp.
Using snapshots has the following benefits:
When Programs subsequently access the resulting data, the system bases a stable view of the data on the most recent refresh timestamp, providing a consistent view of the data even if the table is being updated at the time the Program reading the data is running.
It is possible to recreate data as it was at an earlier point in time.
Access to incompletely loaded data is prevented and rollbacks of incomplete loads are supported even if there have been incremental commits.
You can label snapshots in two ways:
When you run a job you can specify a label to be applied to the source and/or target Table instances (see instructions for "Generating Reports and Running Other Jobs" in the Oracle Life Sciences Data Hub User's Guide).
In a Work Area, you can apply a snapshot label to a data timestamp in one or more Table instances in the Work Area; see "Adding, Removing, or Moving a Snapshot Label".
The system treats any set of tables that are populated by the same master job as a refresh group. The system prevents access to any of the tables until changes to all the tables populated in the Program are complete. The Oracle LSH job tracking record for the execution of each of these applies to all of their contained tables.
For example:
The target Table instances of a Load Set or Program that populates a multiple table instances
a Workflow containing multiple Programs that write to table instances
It is possible to define a Program that processes only a subset of the data in its source tables based on subsetting Parameters. However, if the Program is defined in such a way that the data subset Parameters are modifiable, it does not make sense to use target table processing types that are intended to support incremental or time-based snapshot processing.
Use staging Table instances with or without audit for subsetting. Use staging without audit when you do not need to maintain audited results; for example, in a Workflow that reads data for a subset of patients, reorganizes the data into the temporary table, and runs a series of reports.
If you need to save the results, use staging with audit.
If you want to use Parameters to process different subsets without deleting the data from previously loaded subsets, use reload processing in incremental mode.
You can use staging tables with any Program technology type (SAS, Oracle Reports, or PL/SQL).
Using forward chaining execution you can automatically update all tables downstream in a data flow that directly or indirectly read from a table when that source table is updated. When the first Program, Load Set, or Workflow in the forward chain runs, it triggers the execution of some or all Programs or other executables that read from the tables it writes to. Those executables can in turn trigger the execution of all Programs or other executables that read from the tables they write to, and so on.
The system detects dependencies and executes the chain in the proper order so that data in all impacted tables is synchronized and all report outputs reflect the latest data. Where there are no dependencies, jobs run in parallel.
Forward chaining can include executables in many Work Areas, Application Areas, and even Domainsâunlike Workflows, which are limited to a single Work Area. All executable object typesâLoad Sets, Programs, Workflows, Report Sets, and Data Martsâcan be part of a forward chaining process. Load Sets can only be triggered manually as the first object in a chain, and Data Marts can only be the end of their data flow branch.
You can trigger a forward chain by using the Forward Chaining-enabled Execution Setup of any executable in the chain, and that will trigger the execution of downstream executables in just that downstream branchâthose that directly or indirectly read from the tables written to by the executable object you run.
To participate in a forward chain execution, a Program or other executable object instance and related objects must meet all the following conditions:
The executable must have an Execution Setup with Forward Chaining enabled.
If it is not the first object in the chain, the preceding executables in the chainâthe ones that write to the tables it reads fromâ must have an Execution Setup with Cascade enabled.
The Work Area, Application Area, and Domain(s) containing the executable must have Forward Chaining enabled.
The executable's validation status must be equal to or greater than its Work Area's Usage Intent.
The Work Area's own validation status should be equal to or greater than its Usage Intent.
Note:
If the user who submits the forward chain job does not have the privileges to execute any object included in the chain, the system does not execute that object or any objects downstream from it.If any individual object execution fails, the system does not execute any objects downstream from it. Other subjobs continue unaffected, but the master job status is Failed.
If the system detects a loop in dependencies, the job fails.
By default, all Domains, Application Areas, and Work Areas have Forward Chaining enabled. If it is disabled for a Domain, Application Area, or Work Area, no executables anywhere in the container can participate in forward chaining, even if they meet the other requirements.
The first Execution Setup created for an executable object also has Forward Chaining (and Cascade) enabled by default.
You can change the Forward Chaining and Cascade settings at any level at any time.
Report Only Mode You can run an executable that qualifies for forward chaining in Order Only mode to produce a report of all the downstream executables that would be executed as part of a forward chain. The report is part of the job's log file.
Starting a Forward Chain Process When you submit an Execution Setup that has Forward Chaining enabled, select a Data Currency of Most Current Available (Trigger Forward Chain). The system displays the following additional fields:
Report Only: Select it to run in Report Only Mode.
Desired Top Level Hierarchy: By default this is set to All and all possible objects that are part of the forward chain are included. However, you can limit the scope of the job by selecting a Work Area, Application Area, or Domain above the object being executed that you want to serve as the top level of the hierarchy; objects outside it are not included in the job.
In backchaining, the system checks upstream along a data flow where backchaining is enabled to see if more recent data is available. You create a backchain data flow by defining a backchain-enabled Execution Setup for each executable along the data flow, and submitting the Execution Setup for execution.
If the system finds more recent data anywhere in the data flow where backchaining is enabled, it runs executable objects in the data flow starting at the point with more recent data in order to feed the most recent data into the program being executed.
Oracle Clinical Data Extract Load Sets (both Oracle and SAS) allow the system to interpret data currency in the source system so that a backchain can reach as far as the source tables or data sets in Oracle Clinical. If more current data exists in the source system, the backchain process triggers the execution of the Load Set(s) to load the more recent data into Oracle LSH.
When at least one of the Programs or Load Sets that writes data to a Table instance that a Program instance reads from has a backchain Execution Setup defined and submitted, Oracle LSH displays "Most Current Available" as an allowed value for the Data Currency system parameter in the Execution Setup for the Program instance. When a user submits a job with the Data Currency parameter set to Most Current Available, the system invokes a backchain process that does the following:
The backchain process checks each Program or Load Set instance that writes to the job's source Table instances, looking for a job submission with the Submission Type system parameter set to Backchain. This is a backchain job submission. (To create a backchain job submission, create an Execution Setup with Submission Type set to Backchain and submit it for execution.)
For each Program instance with a backchain job submission, the backchain process checks each Program or Load Set instance that writes to its source Table instances to see if those Programs or Load Set instances also have a backchain job submission.
The backchain job continues to look farther and farther upstream each branch of the data flow until it reaches either the source data system or a Program or Load Set instance that does not have a backchain job submission.
On each branch, when the backchain job has gone as far upstream as it can, it compares the data currency of the source and target data of the last Program or Load Set that has a backchain job submission.
If the source data is more current than the target data, the backchain process executes the Program or Load Set instance to refresh the target data. The backchain job then executes the next Program to refresh its target data, and so on. Each job submitted by the backchain process uses the blinding and priority system parameter values set in the job submitted by the user with the data currency set to Most Current Data Available.
If the target data is already as current as the source data, the backchain job does not execute the Program or Load Set instance, but instead checks the source and target data currency of the next Program downstream, and so on. When it finds a Program whose target data is less current than its source data, the backchain job executes that Program instance and each subsequent Program instance.
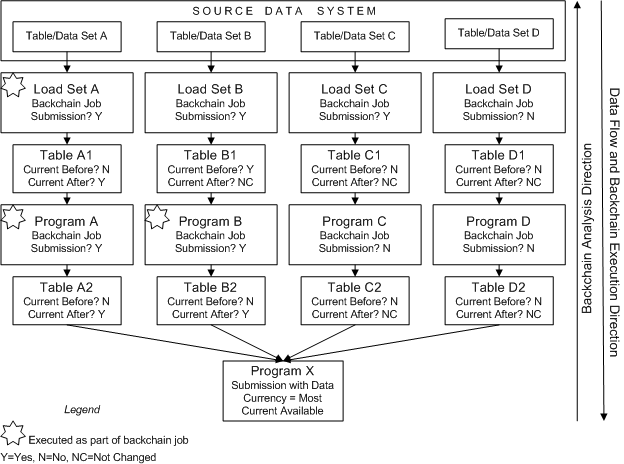
When all branches with backchaining enabled have the most current possible data, the backchain job triggers the execution of the original job submitted (with Data Currency set to Most Current Available). See Figure 13-1, "Backchain Example".
In the example shown in Figure 13-1, the user submits Program X with the Data Currency system parameter set to Most Current Available. This submission starts a backchain process that checks all the Programs that populate the Table instances that Program X reads from for a backchain job submission. In this example, the backchain process finds that Programs A and B have backchain job submissions, but Programs C and D do not. The backchain process then checks the Load Sets that populate the source Table instances of Programs A and B for a backchain job submission. Load Sets A and B both have backchain job submissions.
The backchain process then checks the data currency of the Load Sets' source and target data. Load Set A's target data is less current than its source, but Load Set B's target data is current. The backchain process checks the data currency of Table B1 compared to Table B2, and finds that B2 is less current.
The backchain process executes Load Set A, and Table A1 becomes current. The backchain process executes Program A, and Table A2 becomes current. The backchain process executes Program B, and Table B2 becomes current. The backchain process then executes Program X, which then has the most current data available. However, because Programs C and D did not have backchain jobs submitted, Program X does not have the most current data from the source system for those streams. This is true even for stream C, where Load Set C has a backchain job submission but Program C does not.
Note that even if Table A2 is current in relation to its source Table before the backchain process, it becomes noncurrent after the execution of Load Set A updates Table A1. However, Program A then runs and Table A2 becomes current again.
The system enforces the following rules:
A particular executable can have only one Execution Setup with a submission type of Backchain.
Only master jobs can have backchaining Execution Setups or run with Most Current Data Available set.
The same Load Set or other executable with a backchain job submission can be executed by backchain processes initiated by any number of executable objects downstream in a data flow submitted with data currency set to Most Current Data Available. For example, if more than one Program reads from the Tables populated by a Load Set, and if the Load Set has a backchain job submission, the Load Set can be executed as part of a backchain process when either Program is submitted with its data currency set to Most Current Data Available.
If an executable has multiple source Tables and multiple executables write to those Tables, each of these data flows is processed separately for backchaining, and backchaining can execute successfully even if some data flows go all the way back to the source system and others reach a point where backchaining is not enabled within Oracle LSH.
For example, if you have a Program that combines treatment codes with patient data, you may not want to enable backchaining on the treatment codes, because they should never be automatically loaded into Oracle LSH, but you do want to see the most recent patient data.
Backchaining is not possible in Load Sets that load files: Text and SAS.
Backchaining is not possible with Load Sets whose target Table instances are created as pass-through views. The execution of the entire backchain fails.
The security for the entire backchain is determined by the security required for the job submitted with Data Currency set to Most Current Available. In other words, if a user has the privileges required to run Program X in the example above, he or she can submit Program X and the entire backchain job can run and invoke every job required for a successful backchain, even if the user does not have the security privileges required to run any of the upstream jobs triggered by the backchain job.
Keep the following in mind:
When you define a backchain Execution Setup, you must click Submit when you are finished. This does not actually run the job, but the Execution Setup will not run during an actual backchain process unless you have submitted it once already.
If a user cancels the job created for the backchain Execution Setup, the backchain process cannot run that job or any job dependent on it (upstream, or earlier, in the data flow). To recover, do the following:
Create another Execution Setup with a submission type of Backchain.
Set the Force Duplicate Execution Parameter to Yes.
Submit the Execution Setup.
Since backchain jobs are executed automatically, you must supply default values for all required Parameters in backchaining Execution Setups. If you use subsetting Parameters, be sure to be consistent in all the Execution Setups involved in a single backchain job.
Otherwise, if you allow manually submitted executions of the same program to use different subsetting parameter values, then the tables may look up-to-date to backchaining, but only be up-to-date for a particular, different subset of the data.
The system allows you to include a Workflow in a backchaining data flow. However, if a Workflow includes an activity such as an Approval Request that requires manual intervention, the backchain will not be able to complete automatically. Therefore, do not include Workflows in a backchain data flow if they contain Approval Requests.
Because backchaining execution involves checking for more recent data upstream in the data flow, and then executing multiple objects, processing potentially large amounts of data, it is generally much slower than standard Oracle LSH execution, which operates on the most current data or a specified snapshot of data in the immediate source Table instances.
This section includes the following topics:
For additional information on data blinding, see "Security for Blinded Data" in the Oracle Life Sciences Data Hub Implementation Guide.
You may want to hide, or blind, treatment codes or other information that would reveal which patients were receiving which treatments.
Oracle LSH supports data blinding in:
the Oracle LSH Table instances you specify
all reports and other outputs generated using one or more blinded Table instances as a source
all Table instances downstream in the data flow from a blinded Table instance: If a Program instance that reads from a blinded or unblinded Table instance attempts to write data to a nonblinded target Table instance, the submission failsâunless the target Table instance is explicitly authorized to accept data from such a Program and a user with Blind Break privileges explicitly confirms that the Program can be executed.
All Table instances have a Blinding flag attribute that indicates whether or not they may contain data that is sensitive and must be blinded at some point in time.
If a Table instance's Blinding Flag is set to Yes, then Oracle LSH maintains two partitioned sets of rows for the Table instance: one set of rows of real data and one set of rows of dummy data. Programs that run on data in these Table instances operate on only one set of data at a time: either the real data or the dummy data.
Table instances also have a Blinding Status attribute. If a Table instance's Blinding flag is set to Yes, its Blinding Status can be either Blinded or Unblinded to indicate the current state of the data. If a Table instance's Blinding flag is set to No, its Blinding Status can be either Not Applicable (the default) or Authorized; see "Exception Authorization".
When you load data into Oracle LSH, you must declare the data to be either real or dummy data by setting the Blind Break system Parameter. You cannot load real data and dummy data at the same time. However, only one Program or Load Set can write data to any particular Table instance. Different technologies require different approaches to populating the real and dummy data partitions of blinded Table instances.
Note:
Oracle LSH cannot ascertain whether data in an external system requires blinding or not. You must set up your security system so that only people who understand the issues and the source data can run Load Sets that may load sensitive data.SAS and Text Load Sets Define your SAS and Text Load Sets so that the file to be loaded must be specified at runtime. Load a file containing real data in one run, and a file with the same structure but containing dummy data in another run. When you load each file, take care to set the Blind Break system Parameter correctly. The system flags each record in the blinded file as blinded and each record in the dummy file as not blinded.
Oracle Tables and Views The same strategy does not work with Oracle Load Sets because the source table is part of the Load Set definition. Instead, as shown in Figure 13-2, you can:
Figure 13-2 Populating the Blinded and Nonblinded Partitions with Oracle Source Data
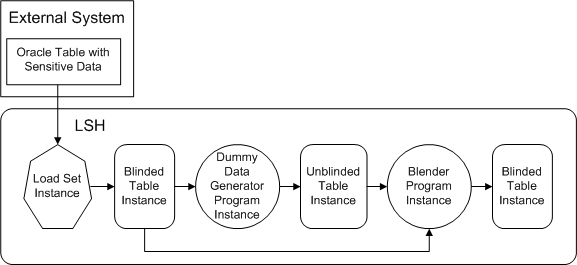
Create a Load Set to load all data from the source table, defining the target Table instance with its Blinding flag set to Yes and its Blinding Status set to Blinded.
Create a dummy data generator Program that reads from the Load Set's target Table instance and writes to a nonblinded Table instance with the same structure. The Program should retain the primary key column values but replace the data in all columns that contain sensitive data with dummy data. The target Table instance must have its Blinding flag set to No and its Blinding Status set to Authorized; see"Exception Authorization".
Create another Program that simply reads data and writes the dataâwith no changesâinto another Table instance with the same structure, but with its Blinding flag set to Yes and its Blinding Status set to Blinded. Map the Program to two source Table instances: the blinded Load Set target Table instance and the nonblinded target Table instance of the first Program. Use a Parameter to determine which Table instance the Program reads from.
To load real data into the blinded partition of the target Table instance, run this Program with its Blind Break system Parameter set to Real (Blind Break) and the Parameter you created set so that it reads from the blinded Table instance.
To load dummy data into the dummy partition of the target Table instance, run this Program with its Blind Break system Parameter set to Dummy and the Parameter you created set so that it reads from the nonblinded Table instance.
Note:
Blind Break privileges are required to run both Programs.Oracle Clinical Randomization When you load treatment codes into Oracle LSH from Oracle Clinical using a Randomization Load Set, the privileges you have in Oracle Clinical and the state of the data in Oracle Clinical determine which data you can load into Oracle LSH. Oracle LSH partitions the data appropriately; see "Oracle Clinical Randomization".
When a Load Set writes to a Table instance whose Blinding flag is set to Yes, the system changes the values available for the Blind Break system Parameter in the Execution Setup for the Load Set to Real (Blind Break) and Dummy instead of Not Applicable.
The same is true for any Program that reads data from that blinded Table instance and so on downstream in the data flow as Programs read from blinded or unblinded Table instances and write to other blinded or unblinded Table instances.
In each case, the person running the Program must set the Blind Break system Parameter in the Execution Setup. If it is set to Real (Blind Break), the system runs the Program on the data in the blinded partition of the source Table instance and writes to the blinded partition of the target Table instance. If it is set to Dummy, the system runs the Program on the data in the dummy partition of the source Table instance and writes to the dummy partition of the target Table instance.
Special privileges are required to run a Load Set or Program that has one or more source or target Table instances with its Blinding flag set to Yes. For complete information on blinding-related privileges, see the chapter on security in the Oracle Life Sciences Data Hub Implementation Guide.
Normal Usage Oracle LSH requires that downstream Table instances have the Blinding flag set to Yes, but you must set the flag manually. Oracle LSH enforces the rule at runtime. If you attempt to run a Program that writes real data from a Table instance whose Blinding flag is set to Yes (with a Blinding Status of either Blinded or Unblinded) into a nonblinded Table instance (with its Blinding flag set to No and its Blinding Status set to Not Applicable)) the submission fails.
Exception Authorization There may be cases where you need to create a Program that reads from one or more blinded or unblinded Table instances and writes to one or more nonblinded Table instances; for examples, see "Loading Real and Dummy Data" and Figure 13-3 below.
In this case you must set the nonblinded target Table instance's Blinding flag to No and its Blinding Status to Authorized. The system then allows users with special privileges on the blinded or unblinded source Table instances to run the Program after confirming that it is safe.
Figure 13-3 Reading from a Blinded Table and Writing to a Nonblinded Table
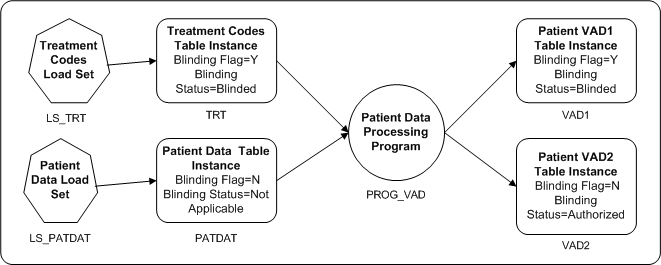
In this example, one source Table instance contains treatment codes and is blinded. The other contains patient data and is not blinded. A Program reads from both Table instances, transforms data, and writes to two Table instances. One target Table instance, VAD1, combines patient data with treatment codes and must be blinded. However, target Table instance VAD2 does not include any treatment code information and does not need to be blinded.
Only users with Blind Break privileges can run PROG_VAD on real data as long as either Table instance TRT or VAD1 has a Blinding Status of Blinded. If the Blinding Status of both of Table instances changes to Unblinded, then users with Read Unblind privileges as well as those with Blind Break privileges can run PROG_VAD.
At some point, such as the end of a clinical trial, you may want to make the real, sensitive data that has been blinded during the study, available to a larger group of people for analysis and reporting. To do this, you unblind Table instances that have been blinded, and then run Programs on the real (now unblinded) data.
Special security privileges are required to unblind and reblind a Table instance. See the security chapter in the Oracle Life Sciences Data Hub Implementation Guide for information.
To unblind a blinded Table instance:
Navigate to the Table instance in its Work Area.
Click Update.
Change the Blinding Status to Unblinded.
Note:
You can reblind an unblinded Table instance by setting the Blinding Status back to Blinded.Click Apply.
This section contains the following topics:
It is possible to trigger jobs in Oracle LSH by sending an XML message from an external system. For example, if you load patient data into Oracle LSH from Oracle Clinical, you may want to wait until batch validation completes successfully before loading the updated data into Oracle LSH.
Oracle LSH listens at its Event Queue (an Oracle Streams Advanced Queue) for incoming messages. When a message arrives, the system parses the message and triggers the execution of the job.
The message must use a specific XML schema (see Example 13-1, "Required XML Schema for Messages"). The system checks the validity of the schema structure and all its supplied values. If anything is invalid, the system does not execute the job.
The system sends an email notification to the submitting user of success, failure, warning or error, if the XML message so specifies (see "Notification Type").
A message cannot exceed a total of 4000 characters. Messages are never deleted from the Event Queue.
For information about creating an Execution Setup to be triggered upon receipt of an XML message, see "Creating, Modifying, and Submitting Execution Setups".
To set up message-triggered submission you must do the following:
Execution Setup. Create an Execution Setup for the Load Set (or other executable) that accepts the Triggered submission type (see "Creating, Modifying, and Submitting Execution Setups") as well as the Immediate and Deferred submission types.
Oracle LSH User Account. Create a user account in Oracle LSH for the external system user who will create the database link from the remote location. If you want the external system user to receive email notifications, set it up in the user account; see "Creating User Accounts" in the Oracle Life Sciences Data Hub System Administrator's Guide for information.
If the application that triggers the submission is part of the Oracle E-Business Suite, it is not necessary to create another user account.
Oracle LSH Database Account. If the external system's database is separate from Oracle LSH, create a database account in Oracle LSH for the user account; see "Creating Database Accounts" in the Oracle Life Sciences Data Hub System Administrator's Guide for information.
Grant Execute on the API Security Package cdr_pub_api_initialization to the user with the LSH database account.
Database Link. In the remote database, use the Oracle LSH database account user ID and password to create a database link to the Oracle LSH database.
XML Message. Send an XML message from the external system using the required XML schema; see Example 13-1, "Required XML Schema for Messages". In the XML message, the user ID you specify must be the same as the user ID used to create the database link.
An Oracle LSH API package called cdr_pub_exe_msg_api with the procedure Submit Message is available for use in enqueuing messages; see the Oracle Life Sciences Data Hub Application Programming Interface Guide.
For information about enqueuing messages, see the Oracle® Streams Advanced Queuing User's Guide at http://download.oracle.com/docs/cd/B19306_01/server.102/b14257.pdf.
You must use XML messages that follow a specific schema (shown in Example 13-1, "Required XML Schema for Messages").
The schema requires the following information:
The XML message must identify an existing, installed executable object instance to be executed, including its Domain(s), Application Area, and Work Area, and the Execution Setup to be used. The Execution Setup must be active and defined to accept the Triggered submission type.
Note:
If the executable object instance is contained in a Work Area and Application Area that are contained in a nested Domain, enter the names of all the Domains, starting at the top level and inserting a forward slash between Domain names. For example, if the object is contained in Study123_Domain contained in ProjectABC_Domain, enter ProjectABC_Domain/Study123_Domain.The XML message must supply valid values for all System Parameters whose value should be different from the default values defined in the Execution Setup. The System Parameters included in the schema are:
Submission Type The XML message must supply a submission type of either Immediate or Deferred. If Immediate, the system executes the job immediately after receiving and processing the message. If Deferred, the system executes the job at a date and time specified in the message using the format DD-MON-YYYY HH24:MI (for example, 31-MAY-2010 13:45). If, at submission time, the supplied scheduled time is in the past, the job will be executed immediately.
Run Mode If you are using the Reload processing type, the XML message must supply a run mode of either Full or Incremental. See "Data Processing Types".
Execution Priority The XML message must supply an execution priority of either Normal, Low, or High.
Notification Type The XML message must specify under what circumstances the system should send the user a notification. You can specify one or more of the following values:
None. The system never sends a notification to the user.
Success. The system sends a notification to the user if the job executes successfully.
Failure. The system sends a notification to the user if the job execution fails.
Warning. The system sends a notification to the user if the job ends with a warning.
Error. The system sends a notification to the user if the job end with an error.
Data Currency Type The XML message must specify the data currency type of the data, and the Execution Setup must be defined appropriately for that type.
Current. The system runs the job on data that is current in the immediate source tables at the time of execution.
Backchain. The system uses backchaining to find the most current data available. The Execution Setup must have a submission type of Immediate or Deferred and a data currency type of Most Current Available. The Execution Setups for Programs feeding data to the source tables must have a submission type of Backchain. See "Backchaining" for further information.
Note:
The system does not support using message-triggered submission on data snapshots. Do not enter Snapshot as a value.Snapshot Label If you want the job to apply a snapshot label to Oracle LSH data, enter one of the following values:
Target. If set to Target, the system applies a snapshot label to target Table instances only.
Both. If set to Both, the system applies a snapshot label to both source and target Table instances.
Label If you enter either Target or Both as the value for Snapshot Label, enter the text of the label as this Parameter value.
Blind Break Flag The XML message must indicate whether this job is being run on real, blinded data. All Oracle LSH security rules pertaining to blinding apply to message-triggered jobs. The submitting user must have the required privileges or the job does not run.
No. A value of No indicates that the job is not a blind break. This is the default value.
Yes. A value of Yes indicates the job is to be run on real, blinded data.
Force Execution Flag The XML message must indicate whether or not to execute the job even if the resulting output will be the same as for the last execution.
Yes. If set to Yes, the system always executes the job.
No. If set to No, the system compares the executable definition version, the Parameter settings, and the source data currency for the previous execution of the same executable with the current ones and does not execute the job if they are all the same. The system sends a Notification to the Home page of the user who submitted the job stating that the job was not executed.
The Oracle Applications Account ID of the user for whom the job is being submitted:
If the message is sent from a remote database, the system checks the user ID specified in the message matches a database account in Oracle LSH.
If the message is sent from within Oracle LSH, the user ID specified in the message must be the same as the logged-in Oracle LSH user who sends the message.
If the message is sent from an application in the Oracle E-Business Suite that shares the same database as Oracle LSH, the database account is APPS. The system checks that the user ID specified in the message matches the Oracle Applications Account ID with which the XML message-sending user has logged into the E-Business Suite.
The XML message must supply an identifier to be included in execution logs and messages back to the submitter.
The XML message must use the schema shown in the following example.
Example 13-1 Required XML Schema for Messages
<?xml version="1.0" encoding="iso-8859-1"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="SubmissionRequest">
<xs:annotation>
<xs:documentation>Oracle LSH submission request submitted via event queue</xs:documentation>
</xs:annotation>
<xs:complexType>
<xs:sequence>
<xs:element name="ProgramSpecification">
<xs:annotation>
<xs:documentation>Identifies the program to be executed</xs:documentation>
</xs:annotation>
<xs:complexType>
<xs:attribute name="domain" type="xs:string" use="required"/>
<xs:attribute name="applicationArea" type="xs:string" use="required"/>
<xs:attribute name="workArea" type="xs:string" use="required"/>
<xs:attribute name="program" type="xs:string" use="required"/>
<xs:attribute name="executionSetup" type="xs:string" use="required"/>
</xs:complexType>
</xs:element>
<xs:element name="SystemParameters" minOccurs="0">
<xs:annotation>
<xs:documentation>Provides values for required system parameters. Elements can be omitted; defaults will be supplied during processing.</xs:documentation>
</xs:annotation>
<xs:complexType>
<xs:sequence>
<xs:element name="SubmissionTypeRc" minOccurs="0">
<xs:annotation>
<xs:documentation>IMMEDIATE or DEFERRED. If DEFERRED, supply a datetime, in schedStartTs, at which the job is to be executed. DD-MM-YYYY HH24:MI IF time is in the past, the job will be executed immediately.</xs:documentation>
</xs:annotation>
<xs:complexType>
<xs:attribute name="value" default="IMMEDIATE">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="IMMEDIATE"/>
<xs:enumeration value="DEFERRED"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
<xs:attribute name="schedStartTs" type="xs:string"/>
</xs:complexType>
</xs:element>
<xs:element name="RunModeRc" minOccurs="0">
<xs:complexType>
<xs:attribute name="value" default="FULL">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="FULL"/>
<xs:enumeration value="INCREMENTAL"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
<xs:element name="ExecutionPriorityRc" minOccurs="0">
<xs:complexType>
<xs:attribute name="value" default="NORMAL">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="LOW"/>
<xs:enumeration value="NORMAL"/>
<xs:enumeration value="HIGH"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
<xs:element name="NotificationTypeRc" minOccurs="0">
<xs:complexType>
<xs:attribute name="value" default="FAILURE">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="SUCCESS"/>
<xs:enumeration value="WARNING"/>
<xs:enumeration value="FAILURE"/>
<xs:enumeration value="NONE"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
<xs:element name="CurrencyTypeRc" minOccurs="0">
<xs:complexType>
<xs:attribute name="value" default="CURRENT">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="CURRENT"/>
<xs:enumeration value="BACKCHAIN"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
<xs:element name="SnapshotLabel" minOccurs="0">
<xs:complexType>
<xs:attribute name="ApplySnapshotLabel" default="BOTH">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="BOTH"/>
<xs:enumeration value="TARGETS"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
<xs:attribute name="Label" type="xs:string"/>
</xs:complexType>
</xs:element>
<xs:element name="BlindBreakFlag" minOccurs="0">
<xs:complexType>
<xs:attribute name="value" default="NO">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="YES"/>
<xs:enumeration value="NO"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
<xs:element name="ForceExecutionFlag" minOccurs="0">
<xs:complexType>
<xs:attribute name="value" default="NO">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="YES"/>
<xs:enumeration value="NO"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="ProgramParameters" minOccurs="0">
<xs:annotation>
<xs:documentation>If the specified program requires parameter values, they are specified in this element.</xs:documentation>
</xs:annotation>
<xs:complexType>
<xs:sequence>
<xs:element name="ParameterSetting" minOccurs="0" maxOccurs="unbounded">
<xs:annotation>
<xs:documentation>Each supplied parameter setting must have name and a value. </xs:documentation>
</xs:annotation>
<xs:complexType>
<xs:attribute name="name" type="xs:string" use="required"/>
<xs:attribute name="value" type="xs:string" use="required"/>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="userId" type="xs:string" use="required">
<xs:annotation>
<xs:documentation>Oracle Applications account of the user for whom the job will be executed. </xs:documentation>
</xs:annotation>
</xs:attribute>
<xs:attribute name="requestId" type="xs:string" use="required">
<xs:annotation>
<xs:documentation>An identifer supplied by the application that generates the request. This ID will be included in execution logs and messages back to the submitter.</xs:documentation>
</xs:annotation>
</xs:attribute>
</xs:complexType>
</xs:element>
</xs:schema>
|
Copyright © 2006, 2014, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|