| Oracle® Life Sciences Data Hub Application Developer's Guide Release 2.4 E54089-01 |
|
|
PDF · Mobi · ePub |
| Oracle® Life Sciences Data Hub Application Developer's Guide Release 2.4 E54089-01 |
|
|
PDF · Mobi · ePub |
This section contains information on the following topics, which are tasks common to the definition of different types of Oracle LSH objects:
See also Chapter 2, "Introduction to Application Development in the Oracle Life Sciences Data Hub".
This section contains the following topics:
See also Naming Objects.
For information on creating new definitions, see the section for each object:
Creating a New Table Definition and Instance; includes instructions for creating an Oracle LSH Table from a SAS data set
You can look for an appropriate definition to use in several ways:
If you know the location of the definition you need to use, click Create an Instance of an Existing Definition and use the Search utility there; see "Using the Search and Select Window".
To search with other criteria, including classifications and validation status, go to any screen with the Advanced Search utility, search, and make a note of the results. See "Advanced Search" in the Oracle Life Sciences Data Hub User's Guide for instructions.
In the main Applications screen, navigate to a Domain or Application Area where you think you might find an appropriate definition, and click Maintain Definitions to see all the definitions in that Domain or Application Area library. See "Navigating in the Applications Tab".
There are several ways you can reuse an existing definition:
Create an instance of an existing definition and use the definition as it is. This is the easiest and fastest way to reuse a definition, requiring no revalidation of the definition. Use this method if the definition you need is validated and appropriate for your needs (see "Creating an Instance of an Existing Definition").
Create an instance of an existing definition and then copy the definition to the current Application Area. After you create an instance of an existing definition, check in the definition through the instance if it is not already checked in. Then check it out, selecting the option to create a copy of the definition in the current Application Area (see "Checking Out an Object Definition through an Instance") and modify it as necessary.
This method leaves the original definition unchanged and readily available for reuse elsewhere. You must validate the copied definition when you have finished modifying it.
The system enforces unique object names within a container; see "Naming Objects".
Create an instance of an existing definition and modify it as necessary. If you have the necessary privileges, you can modify the definition through the new instance. The system creates a new version of the definition, which you must revalidate. You can label the new version to distinguish it from other versions; see "Version Labels".
Whenever possible, choose this option. It saves work by reducing the time required to define and validate objects and by promoting consistency across the application. See "Finding an Appropriate Definition".
Figure 3-1 shows the process of creating an instance of an existing Program definition. The process is similar for all object types. When you create a new instance of an existing Program definition, you do not need to create Table Descriptors, Source Code, Parameters, or Planned Outputs because they are included in the Program definition. You do need to map the Table Descriptors to Table instances and define at least one Execution Setup. You then install the Program instance and the Table instances to which it is mapped, run and test the Program instance, validate it and assign user groups to it according to your company's policies.
Figure 3-1 Creating a New Program Instance from an Existing Program Definition

To create an Instance of an existing Definition:
Select Create an Instance of an Existing Definition and click Apply.
The system displays the Definition Source field with a Search icon as shown here:
If you know the name of the object definition you want, enter it in the Definition Source field.
If not, click the Search icon. The Search and Select pop-up window appears. See "Using the Search and Select Window" below.
Select a subtype and classifications for the new object instance, if necessary.
Click Apply. The system creates a new instance of the definition you specified in the current Work Area.
For all object types except Tables, you must map the Table Descriptors; see "Mapping Table Descriptors to Table Instances" for information.
For all executable objects, you must create at least one Execution Setup; see "Creating, Modifying, and Submitting Execution Setups".
The Search and Select window is called from many screens in Oracle LSH. It receives its context from the calling screen. For example, if you click the Search icon in the Create Program screen, the Search and Select function finds only Program definitions.
Enter values in the following fields:
Domain. From the drop-down list, select the name of the Domain that contains the definition you need.
If the Domain you specified contains one or more child Domains, you can see the child domain in the Domain drop-down list with the name of all parent domains preceding it and separated by a right angle bracket (>). For example:
Domain 1 > Child Domain 1 > Child Domain 2 > Child Domain 3
The system populates the Application Area drop-down list with the names of Application Areas contained in that Domain.
Application Area. If the definition is contained directly in a Domain library, do not select an Application Area.
If the definition is contained in an Application Area, select the Application Area from the drop-down list.
Search By. If you know the name or version label of the object, select either Name or Version Label from the Search By drop-down list and enter either the name or version label in the field to the right. You can use special characters such as the % wildcard. For example, if you enter Study_12345% as a name, the system retrieves all objects whose name begins with Study_12345.
Note:
For some object types this field is case-sensitive. If an object's name begins with STUDY_12345 and you enterStudy_12345% the system does not retrieve the object because its name is not in uppercase.Display All Versions If checked, the system returns all versions of the object with the name you specified in the Search By field. If unchecked, the system returns only the latest version. (If you specified Version Label in the Search By field, the system returns only the version with that label.)
Display Not Null Version Labels If checked, the system returns only object versions with a version label. This checkbox is relevant only if Name is selected in the Search By field above.
Click Go. The system displays the results of the search, including, for each definition retrieved, its name, version number, version label (if any), validation status, the username of the person who created the definition, and the date on which it was created. The system retrieves object definitions only if they are currently checked in.
Select the definition you want by clicking the icon in the Quick Select column, or by clicking its radio button and then clicking the Select button. The system returns you to the screen you came from, displaying the name of the object you selected.
If no object definition exists that suits your needs, or that you can modify to suit your needs, you must create a new one.
When you create a new definition and instance at the same time, the system simultaneously creates the definition in the current Application Area and an instance of it in the current Work Area. As you save your work, the system applies your changes to the appropriate objectâdefinition or instance. The system applies the name and description you enter to both the definition and instance unless there is a conflict with either one; see "Naming Objects".
Figure 3-2 shows the process of creating a new Program definition and instance. The process is similar for all object types. You first create the object as a whole, classify both the definition and the instance, then define component objects: in the case of Programs these include Table Descriptors, Source Code, Parameters, and Planned Outputs. All executable instances require mapping Table Descriptors to Table instances and defining at least one Execution Setup. You must install all object instances in their Work Area, assign user groups for object security and validate the definition and the instance according to your company's policies.
Figure 3-2 Creating a New Program Definition and Instance

Specific instructions for each object type are included in the section on each type:
Creating a New Table Definition and Instance; includes instructions for creating an Oracle LSH Table from a SAS data set
There are also instructions for creating the following component objects:
This section contains the following topics:
Make an object name as descriptive as possible to help other users understand its purpose. Your company may develop naming conventions; see "Customizable Naming Validation Package".
To avoid problems, do not use special characters such as ( & @ * $ | % ~ -) in object names, except for underscore (_). Also do not use Oracle SQL or PL/SQL reserved words in object names, especially the Oracle name. For lists of reserved words, see:
Oracle® DatabaseSQL Language Reference at http://download.oracle.com/docs/cd/E11882_01/server.112/e17118.pdf
Oracle® Database PL/SQL Language Reference at http://download.oracle.com/docs/cd/E11882_01/appdev.112/e17126.pdf
For the latest information, you can generate a list of all keywords and reserved words with the V$RESERVED_WORDS view, described in the Oracle® Database Reference at http://download.oracle.com/docs/cd/E11882_01/server.112/e17110.pdf.
Oracle LSH enforces unique naming for each object type in the same container, whether the container is an organizational objectâDomain, Application Area or Work Areaâor a Report Set or Workflow. (Report Sets contain Programs. Workflows may contain Programs, Load Sets, Report Sets, and/or Data Marts.) The system enforces unique names only within the immediate container; for example, you cannot have two Program instances named Program_A in the same Workflow, but you can have a Program_A in a Workflow and another Program_A directly in the Application Area that contains the Workflow.
If you try to create a second object of the same type and name in the same container, the system creates the object but automatically appends an underscore and number 1 (_1) to the name. If you add a third object of the same type and name, the system increments the number (_2). For example, if you create a Program called Merge in Application Area 12345, and then create another Program called Merge in the same Application Area, the system names the new Program Merge_1. If you create a third Program called Merge in the same Application Area, the system names the new Program Merge_2.
Names can contain up to 200 characters. However, the system populates the values for Oracle Name and SAS Name with the value you enter for Name stored in uppercase, truncating the Oracle Name to 30 characters and the SAS Name to 32 characters. You can change the Oracle and SAS Names.
When you create a new object by uploading a table, view, data set, or column, the system truncates the Oracle Name and also replaces the last two characters with the number 01 or, if an object of the same type with the same name already exists in the same container, the next highest number (in this case, 02).
Although names can contain up to 200 characters, the maximum length of a file path is 256 characters in Windows. When you open an integrated development environment (IDE) such as SAS or run a SAS Program on your personal computer, Oracle LSH uses the actual full file path for Source Code definitions, Table instances, and the SAS runtime script. If the full file path exceeds this length you get an error and cannot open the IDE or run the Program. You can use a package to limit object name size or display an error when an object's file path is too long; see "Customizable Naming Validation Package".
The full file path begins with the Oracle LSH username of the person who opens the IDE followed by the directory name cdrwork. It also includes all Subdomains in the path, if any. (The maximum number of Subdomains is 9. This number is configurable.)
Source Code definitions. The path for Source Code definitions is: username>cdrwork>Domain_name>Subdomain_name(s) (0-9)>Application_ Area_name>Program_definition_name>Source_Code_definition_nameversion_number>fileref>source_code_filename
Table instances. The path for Table instances is: username>cdrwork>Domain_name>Subdomain_name(s) (0-9)>Application_ Area_name>Work_Area_name>program instance name>program version>Table_Descriptor_libname> Table_Descriptor_SAS_name>
SAS runtime script. The path for x is: username>cdrwork>Domain_name>Subdomain_name(s) (0-9)>Application_ Area_name>Work_Area_name>Program_instance_name>version_number>setup
This section contains the following topics:
If you plan to export a Domain to another Oracle LSH instance, you may want to avoid using spaces in its name. Domain names with spaces must be entered with escape characters surrounding it in the Import Export Utility; for example: \" domain name\".
There are important requirements for Source Code names:
Source Code names must not include reserved words or special characters.
Source Code names must include a file extension; for example, .sas for SAS, .rpt for Oracle Reports, or .sql for PL/SQL source code definitions. The system uses the name you enter to name the actual file that contains the source code.
A Source Code's Oracle name must not be the same as the Oracle name of either a Table Descriptor or another Source Code in the same PL/SQL Program definition.
Do not use spaces in the name of any Parameter you create for use in a Report Set. This will cause an error during Report Set postprocessing because the Parameter name becomes an HTML tag, and spaces are not allowed.
Oracle LSH object creation and modification code includes a call to a predefined validation package from every object name field. By default, this package performs no validation and returns a value of TRUE, allowing users to enter any name in the field. However, you can customize the package to enforce your own naming conventions, full path length, or other object attribute standards. See "Customizing Object Validation Requirements" in the Oracle Life Sciences Data Hub System Administrator's Guide.
The process of viewing and modifying object instances and definitions is similar for all object types. This section includes the following topics:
When you view an object instance (such as a Program or Table instance) in a Work Area, you see all the metadata details that apply to the object instance, including the properties that belong to the instance and the properties that belong to the definition.
The fields and settings in the upper portion of the screen (labeled "Instance Properties") belong to the object instance. The fields and settings in the lower portion of the screen (labeled "Definition Properties"), including the information under the subtabs in the middle of the screen, belong to the definition. The exceptionâfor all objects that contain Table Descriptorsâis Table Descriptor mappings, which belong to the instance but are displayed with the Table Descriptors, which belong to the definition.
Use the Actions drop-down list to see other characteristics of the instance, including its classifications, security user group assignments, validation supporting information, metadata reports, and Execution Setups.
You can view object definitions two ways:
To see an object definition where it is located, do the following:
In the main Applications screen, click the Domain or Application Area where the object you want to see is located.
Expand the relevant object type (such as Report Set or Program).
Click the link for the definition you want to see.
You can see old versions of object definitions in the Version History screen from the Actions drop-down list (see "Version History").
You can also use Advanced Search to find old versions of objects or retired objects. See "Advanced Search" in the Oracle Life Sciences Data Hub User's Guide.
When you look at an object instance in a Work Area, you see many details of its source definition as well. The fields and settings in the lower portion of the screen (labeled "Definition Properties"), including the information under the subtabs in the middle of the screen, belong to the definition. The exceptionâfor all objects that contain Table Descriptorsâis Table Descriptor mappings, which belong to the instance but are displayed with the Table Descriptors, which belong to the definition.
In an object instance in a Work Area, you cannot see the source definition's classifications and user group assignments. To see these, you must go to the definition in its Domain or Application Area. You can do this directly from the Work Area as follows:
Click the Definition link in the Instance Properties section of the screen. The system opens the Properties screen of the definition in its Domain or Application Area.
Select the appropriate itemâApply Security or Assign Classificationâfrom the Actions drop-down list and click Go. The system opens the appropriate screen.
To return to the object instance you came from, click the second last link in the breadcrumb at the top of the screen (see "Navigating Using Breadcrumbs") or click Return to go back to the Definition page and click the last breadcrumb link from there.
This section includes the following topics:
Oracle LSH keeps all object definitions and instances under version control, maintaining a record of the user who created each new version, the date and time the version was created, and, for definitions explicitly checked out, an optional comment entered by the person who checked it out.
The system creates a new version of an object when it is checked out, either explicitly or implicitly, and applies all changes to the new version until it is checked in. To make further changes you must check it out and modify the new version.
The system creates new object versions with the same user group assignments (security) and classifications as the previous version, but always gives new object versions a validation status of Development, no matter what validation status the previous version had.
When you create a new version of an object definition, instances of the previous version continue to point to the previous version. You can upgrade one or more instances to the new definition if you want to; see "Upgrading One or More Instances from the Definition".
Report Sets' versioning is different from other objects'; see Chapter 9, "Defining Report Sets" for information on Report Sets. Domains and Application Areas are not versioned; their version number is always 1.
Using Old Object Definition Versions You can use old versions of object definitions as follows:
Do not upgrade instances. Instances continue to point to the definition version selected when they were created until they are explicitly upgraded.
When you create a new instance of an existing object definition, you can select any version of the definition after selecting "Display all Versions;" see "Creating an Instance of an Existing Definition".
You can copy an old version of an object definition at any time from its Version History screen; see "Copying an Old Version of an Object Definition".
If an object definition is not already checked out, you can check out an old version of it either from its Version History screen or through an instance that points to the old version.
Note:
If the definition is already checked out, you have the option to copy the version to the current Application Area.Note:
When you check out an old version of an object, the system behaves the same way as when you check out the latest version. It creates a new version with the characteristics of the one you checked out and gives it a version number equal to the latest version number plus one.The system does not display the fact that the new version is based on an older version. If you want to make that clear, enter a checkout comment or create a version label with the information.
This section contains the following topics:
When you check out an object, either explicitly or implicitly, Oracle LSH creates a new version of it:
When you click Update to work on properties of an object definition or instance, Oracle LSH checks the object out.
When you explicitly check out an object definition, Oracle LSH checks it out.
When you explicitly check out an object definition through an instance of it, Oracle LSH implicitly checks out the instance and points it to the new version of the definition.
When you create a new object definition or instance, Oracle LSH creates it as checked out by you, including when you choose to copy the definition and check it out (see "Checking Out an Object Definition through an Instance".
While an object is checked out, only the person who initiated the checkout, either explicit or implicit, can modify the object , check it in, or uncheck it. That person can save changes multiple times. The exception is Report Sets, which allow multiple people to work on different sections at the same time.
Note:
If another user has already checked out an object definition, you cannot check out the object. However, you can copy the definition and modify the copy.When you check out an object definition through an instance of it, you have the option to modify the definition in its current Domain or Application Area (if you have the required privileges) or to create a copy of the definition in the current Application Area, where you can modify it as necessary.
The system points the instance to the new version of the definition whether you choose to modify it in its current location or copy the definition to the current Application Area.
To check out an object definition through an instance of it, do the following:
Navigate to the object instance.
Select one of the following:
Check out existing definition. This option allows you to modify the definition in its current location if you have the required privileges.
If the definition is already checked out by another user, you get an error message when you select this option.
Copy definition to the local Application Area and check out. This option is useful if:
you do not have the privileges required to modify the original definition in its location
the current version of the definition should remain easily available for reuse
the definition is checked out by another user
Note:
The system gives you this option even if the definition is already located in the current Application Area.Click Apply.
To explicitly check out an object definition directly in its Domain or Application Area, do the following:
Navigate to the object definition.
Click Check Out. The Check Out screen appears.
Type the reason for checking out the object in the Comments field.
Click Apply.
From the object definition's Version History page:
Navigate to the object definition in its Domain or Application Area, either in the Applications screen or by clicking the link to the definition in an instance of it.
From the Actions drop-down list, select View Version History. The Version History screen opens; see "Version History".
Select the version you want to check out and click Check Out. The system creates a new version of the object based on the one you checked out, with a version number that is equal to the latest version's number plus one. All the changes you make apply to the new version.
Oracle LSH finalizes an object version when it checks in the version, either explicitly or implicitly, as follows:
When you install or clone an object instance, Oracle LSH checks in the instance. It also checks in the underlying definition if it is not already checked in.
After you explicitly check out an object definition, you can explicitly check it in.
When you change the validation status of an object definition or instance, Oracle LSH checks it in if it is not already checked in.
To check in an object:
Navigate to the object's screen.
Type the reason for checking in the object in the Comments field.
Click Apply.
Note:
You can check in only those objects that you have checked out, unless you have the Checkin Administrator privileges.If someone else has checked out the definition and you do not have Checkin Administrator privileges, you cannot check it in. If you are working in an object instance, the username of the person who has checked out the object definition is displayed. If you are working directly on an object definition in an Application Area or Domain, you can find out who has checked out the object by running the All Instances report under Reports in the Actions drop-down list.
After you explicitly check out an object definition, you can explicitly uncheck it. Oracle LSH discards the new version.
To undo a checkout for an object:
When you have checked out an object definition, the system displays a Check In button and an Uncheck button.
Click Uncheck. A confirmation for undoing the checkout appears.
Click Yes.
Note:
You can undo a check out for only those objects which you check in, even if you have the Checkin Administrator privileges.You can use version labels to identify important versions of objects. These labels are visible when you search for an object and when you upgrade object instances, and you can filter search results to return only object versions with labels.
To label an object version, follow these steps:
Navigate to the object version you want to label. To label an object definition, you must go to the definition in its Domain or Application Area.
From the Actions drop-down list, select Version Label. Click Go.
Do one of the following:
Enter text for the label In the Version Label field.
Click the Search icon. The system displays all labels that have been created for objects in the same location. Select one of them.
If you enter or select a label that has already been applied to a previous version of the same object, you receive a warning. If you apply the label to the current version, the system removes it from the previous version.
Click Apply. The system applies the label.
You can see the version history of object definitions (not instances) by selecting View Version History from the Actions drop-down list.
You can select any version of the object and click Copy or Check Out to copy it or check it out.
For each version you see the following information:
Name. The object version name is also a hyperlink to the object version definition.
Description of object version description.
Version number.
Status: Installable or Noninstallable.
Validation Status: Development, Quality Control, Production or Retired.
Last Modified By. Username of the person who created the version by modifying the object definition.
Last Modified. The timestamp of the creation of the version.
If you click the + node you can see the following information:
Copied From. If the object version was created by modifying the previous version of the object, that object version is displayed. If it was created by copying and pasting an object from another location, or by cloning a Work Area and all its objects, that information is displayed.
Version Label. If a label was applied to the version, the system displays the label.
Check In Comments. If the person who checked in the object version entered a comment, the system displays it here.
Check Out Comments. If the person who created the object version by checking out the previous version entered a comment, the system displays it here.
Oracle LSH implicitly increments and tracks the version number of components of object definitions such as Source Code, Planned Outputs, Table Descriptors, and Columns that are not contained directly in a Domain or Application Area but only in other defined objects such as Programs or Tables.
To modify these objects you must check out their containing object. The system automatically increments their version number behind the scenes when you modify them within the containing object. When you check in the containing object, the system applies a new version number to the modified component object as well as the containing object. If you uncheck the container, you effectively uncheck the component object as well and the system does not save the new version of either object.
The system increments the component's version number only if you modify it, so the version number of the component object may not match the version number of the containing object definition. Oracle LSH uses the information it stores about component versions to reconstruct past versions of the definition as a whole.
Component object definitions that are contained directly in a Domain or Application Area (Variables, Parameters, Parameter Sets, Notifications, and Overlay Templates) can have version labels (see "Version Labels"). They can also have classifications and user group assignments.
This section contains the following topics:
If an object instance references a definition that has been updated since the instance was created, you may want to update the instance so that it references the new version of the definition. You can upgrade object instances to a newer version of their source definition through the Actions drop-down list either from the definition or from the instance.
For upgrading Source Code instances, see "Upgrading Source Code And Undoing Source Code Upgrades".
To upgrade one or more instances of a definition to a newer version of the definition, do the following:
Navigate to the definition in the Applications tab.
Check in the definition if it is not already checked in.
From the Actions drop-down list, select Upgrade All Instances and click Go. The system opens the Upgrade Instances screen with all instances of the definition displayed.
Note:
If you don't see the Upgrade All Instances option in the Actions drop-down list, then you are not in the latest version of the definition. You can upgrade instances only from the latest definition version.The exception to the above is if you are upgrading Source Code instances. See "Upgrading Multiple Source Code Instances".
For each instance, the system displays the following information:
Object Name. The name of the object instance that points to any version of the definition.
Object Type. The type of the object.
Object Version. The version number of the instance.
Version Label. The version label of the instance.
Installed Version. The most recent version of the instance that was successfully installed.
Validation Status. The instance's validation status.
Checked Out By. The name of the person who has checked out the instance. If a person other than you has the instance checked out, then you cannot upgrade it: the check box next to it is grayed out.
Definition Version. The version number of the definition to which the instance currently points.
Definition Validation Status. The validation status of the definition.
Parent Name. The name of the Parent object.
Parent Object Type. The type of object that contains the instance.
Parent Validation Status. The parent's validation status.
Container. The container hierarchy for the instance.
Select one or more instances you want to upgrade. You can use the Select All and Select None functions and/or select or deselect instances individually by checking or unchecking their Select checkbox. Instances that already point to the current version of the definition cannot be selected.
Click Upgrade. The system changes the source definition of the selected instances to the new version of the definition.
Note:
If you find the Upgrade button not enabled, then the definition you want to upgrade to, is not checked in.To make an object instance point to a different version of its source definition, do the following:
If the version of the definition to which you want to upgrade is not already checked in, navigate to it in its Domain or Application Area and check it in.
Navigate to the object instance in a Work Area.
From the Actions drop-down list, select Upgrade Instance.
Click Go. The system displays the available versions of the object definition in the lower portion of the screen.
For each version of the definition, the system displays the following information:
Version. The version number of the definition version.
Name. The name of the definition version.
Description. The description entered for the definition version.
Status. The definition version's installation status.
Validation Status. The definition version's validation status.
Version Label. The label associated with the definition version, if any.
Checked Out By. If the definition version is checked out, the system displays the username of the person who checked it out. You cannot upgrade to a version that is checked out, and only the person who checked it out can check it in.
Click the icon in the Upgrade column for the version to which you want to point the instance. The icon of the version to which the instance is currently pointing is grayed out.
Note:
You can select an older version than the one to which the instance is currently pointing. This is useful if you want to undo an earlier upgrade.If you are working on an object instance that is not using the most current version of its source definition, the following buttons appear in the Definition Properties portion of the instance's screen:
View Latest. Click to view the latest version of the definition.
Upgrade to Latest. Click to upgrade to the latest version of the definition.
Note:
This option is available only if the definition is checked in, even if you are the person who has checked it out.This section contains the following topics:
This section contains the following topics:
You can copy object definitions or instances from one location and paste them into another. You can copy a whole Work Area, Application Area, or Domain, with all its contents.
When you copy a very large objectâa Work Area, Application Area, Domain, Report Set, or Workflowâeither by itself or as one of multiple selected objects, the system launches the copy operation as a batch job and displays a message with the Job ID.
When you copy an object instance or definition, the system copies only the current version (unless you explicitly select an older version in the View Version History screen; see "Copying an Old Version of an Object Definition"). When you paste the object into its new location, the system gives it a version number of one (1).
For additional information on the Copy operation, see "Comparison of Copying and Cloning Individual Objects".
From the main Applications screen you can copy a single object instance, Domain, Application Area, or Work Area.
All links between objects that are included in the container object you copy are also copied. For example, if you copy a whole Application Area, and it includes an object instance in a Work Area that points to an object definition in the Application Area, the system copies the link, so that the copied instance in its new location points to the copied definition in its new location. If you copy a Work Area where Table instances are mapped to executable instances, the system copies the mappings so that the copied Table instances are mapped to the copied executable instances.
Click the Applications tab. The main Applications screen opens.
Select one object and click Copy. The system opens the Copy Objects screen and displays the objects you selected in the section labeled SourceâSource objects to be copied.
Follow instructions for "Pasting Objects".
You can copy multiple objects at once if they are all in the same location to begin with and you paste them all into the same location. If you copy a Program instance and Table instance that are mapped to each other, the system automatically remaps them in the new location.
To copy and paste multiple object definitions or instances at the same time, do the following:
In the Applications tab, go to the Properties screen of the Domain, Application Area, or Work Area that contains the objects you want to copy or, for Domains and Application Areas, the Manage Definitions screen.
Select one or more objects and click Copy. The system opens the Copy Objects screen and displays the objects you selected in the section labeled SourceâSource objects to be copied.
Follow instructions for "Pasting Objects".
To copy an old version of an object definition, do the following:
Navigate to the object definition in its Domain or Application Area, either in the Applications screen or by clicking the link to the definition in an instance of it.
From the Actions drop-down list, select View Version History. The Version History screen opens; see "Version History".
Select the version you want to check out and click Copy. The system opens the Copy Objects screen and displays the objects you selected in the section labeled SourceâSource objects to be copied.
Follow instructions for "Pasting Objects".
Cloning an object differs from copying an object as follows:
Instances and Definitions. You can copy object definitions as well as object instances. You can clone only object instances.
Allowed Targets. You can copy an object definition or instance into the same containerâDomain, Application Area, or Work Areaâthat contains the source object. In that case, the Copy operation creates a copy of the object with the name Copy_of_source_object_name. You can clone an object instance only to a different Work Area; not the same Work Area that contains the source object instance.
Replacement. If an object of the same type with the same name exists in the target Work Area, the Copy operation creates a new object in the target Work Area with a different name (_1 appended or final number incremented by 1). The Clone operation upgrades the target object with a duplicate of the source object (including the same name with nothing appended) unless the target is already identical to the source, in which case the Clone operation takes no action on the target object. Neither operation (Copy or Clone) compares the version number of the source and target objects (see "Version Number" below).
If an object of the same type with the same name does not exist in the target Work Area, the Clone and Copy operations both create a duplicate of the source object, with the same name, in the target Work Area.
Implicit Cloning of Mappings and Table instances. If you clone a Program, Load Set, Data Mart, Business Area, Report Set, or Workflow that is mapped to one or more Table instances in the same Work Area, the Clone operation automatically clones each Table instance and the mapping as well. If a source Table instance is in a different Work Area, the system copies the mapping to the same Table instance. The Copy operation does not copy any objects except those that are explicitly selected.
If a Table instance with the same name already exists in the target Work Area of a Clone operation with implicit cloning of a Table instance, the system checks to see if the Table instance in the target Work Area was already cloned from the same source Table instance or not. If it was, the clone proceeds without warning and replaces the Table instance. If the target Table instance was originally defined in the target Work Area, or if it was cloned or copied from a different Table instance, you receive an error and cannot proceed with the cloning operation.
Note:
Cloning upgrades Table instances and all other instances; it does not delete data in Table instances unless the source Table instance has been modified in a destructive way, such as removing a Column. In that case, you get a warning when you make the destructive change that the change may prevent upgrading during the next installation. However, you do not receive a warning during the Clone operation.Changing a table's Blinding flag to Y from N is not considered a destructive change. Changing the Blinding flag from N to Y is allowed if there is no dummy data loaded.
Validation Status. When you copy an object, the new object's validation status is always set to Development, no matter what the validation status of the source object was. When you clone an object, the new object has the same validation status as the source object.
Note:
When you copy or clone an object, none of its validation supporting information links are maintained. They are maintained when you move an object.Version Number. When you copy an object, the new object's version number is always set to 1, no matter what the version number of the source object was. When you clone an object, the Clone operation increments the version number of the target object by 1.
Security. The same privileges are required to copy and to clone objects: Read privileges for the object type in the source location and Create or Modify privileges for the object type in the target location.
For information about cloning an entire Work Area, see "Cloning Work Areas for Testing and Production".
This section contains the following topics:
You can select one object instance to clone from either the Application Development screen or from the main Work Area screen. In the Work Area screen you can also select multiple objects and clone them at the same time to the same target Work Area.
See "Comparison of Copying and Cloning Individual Objects" for additional information about cloning object instances.
Note:
When you select a Program instance that is mapped to one or more Table instances in the same Work Area, Oracle LSH automatically clones the Table instance(s) and the mapping(s) as well as the Program instance.Cloning object instances is different from cloning a whole Work Area in the following ways:
Implicit Cloning of Mapped Table Instances. If you clone an individual executable objectâProgram, Load Set, Data Mart, Business Area, Report Set, or Workflowâthat is mapped to one or more Table instances in the same Work Area, the Clone operation automatically clones the Table instance and the mapping as well.
If you clone a whole Work Area, the system replaces any Table instances in the target Work Area that have been modified in the source Work Area since the last clone.
Checks. When you clone a whole Work Area, the system duplicates the source Work Area, resulting in an identical target Work Area. Any object instances present in the target Work Area before the clone are either dropped or replaced, and objects that were not previously present are created.
When you clone an object instance, the system does the following before performing the clone:
Checks Table instance origin during implicit clone. When you clone an individual Table instance implicitly by cloning an executable to which it is mapped, and a Table instance with the same name already exists in the target Work Area, the system checks to see if the Table instance in the target Work Area was already cloned from the same source Table instance or not. If it was, the clone proceeds without warning and replaces the Table instance. If the target Table instance was originally defined in the target Work Area, or if it was cloned or copied from a different Table instance, you receive a warning and cannot proceed with the Clone operation.
Note:
The system performs this check only when you clone a Table instance implicitly. If you explicitly select a Table instance for cloning, the system does not make this check: if a Table instance already exists in the target Work Area with the same name, the new Table instance replaces it, regardless of the target Table instance's origin.After you have cloned a Table instance from two different source Table instances, the system allows you to clone the Table instance implicitly as well as explicitly from either source.
Prevents multiple executables from writing to the same Table instance. When you clone an individual Table instance, either explicitly or implicitly when you clone a Program or Load Set instance to which it is mapped, the system does not allow the Clone operation to succeed if the result would be that two executables (Programs or Load Sets) wrote to the same target Table instance.
When you clone a whole Work Area, this is not an issue because the system has already prevented multiple executables from writing to the same Table instance in the source Work Area.
When you clone a whole Work Area, you must apply a label to the source and target Work Areas. However, when you clone an object, you cannot apply a clone label to the source and target objects.
When you clone a whole Work Area you can update the Usage Intent of the target Work Area as part of the Clone operation.
When you clone an individual object instance the source Work Area is not checked in as part of the cloning operation as it is when you clone a whole Work Area.
When you clone an individual object instance you cannot create a new target Work Area as part of the cloning operation, as you can when you clone a whole Work Area and specify an Application Area as the target.
For more information on Work Area cloning, see Chapter 12, "Using, Installing, and Cloning Work Areas".
To clone an object from the Application Development screen, do the following:
Click the Applications tab to open the Application Development screen.
Expand the Application Area and Work Area that contain the object you want to clone.
Click the icon in the Clone column on the same row as the object you want to clone. The Clone Instances screen opens with the selected object displayed in the Instance Objects to Be Cloned section.
In the Clone Destination section, select the Work Area in which you want to create a clone of the object.
If you want to clone the object into a Work Area in a different Domain, click the Search icon and follow instructions at "Select a Domain on the Applications Screen". The system displays the Application Areas contained in the Domain.
Expand the node (+) of the Application Area that contains the target Work Area.
Select the target Work Area.
Click Apply.
To clone one or more objects from the Work Area screen, do the following:
In the Application Development screen, click the hyperlink in the Name column of the Work Area that contains the object or objects you want to clone. The Work Area Properties screen opens.
Select each object you want to copy and click Clone. The Clone Instances screen opens with the selected object(s) displayed in the Instance Objects to Be Cloned section.
In the Clone Destination section, select the Work Area in which you want to create a clone of the object.
If you want to clone the object into a Work Area in a different Domain, click the Search icon and follow instructions at "Select a Domain on the Applications Screen". The system displays the Application Areas contained in the Domain.
Expand the node (+) of the Application Area that contains the target Work Area.
Select the target Work Area.
Click Apply.
Moving an object removes it from its original location and puts it into a new location without breaking any references; that is, instances of a definition being moved continue to point to the definition in its new location. The system moves all versions of the object together. The Move operation is available inside Domains, Application Areas, and Report Sets for object definitions and Report Set Entries, respectively. It is not available in Work Areas for object instances.
You can move multiple objects at once if they are all in the same location to begin with and you paste them all into the same new location.
You can move an object to a different location if you have Create privileges for that object type in that location and Modify privileges on its parent object (Domain, Application Area, or Report Set definition).
Use the Move operation to do the following:
Move object definitions from Application Areas to Domains when they have been thoroughly tested and approved for reuse.
Move an Application Area or child Domain, with all its contents, to a different Domain.
Move object definitions from one Application Area or Domain to another.
To move one or more objects, do the following:
Navigate to one of the following locations:
To move one or more object definitions: In the Applications tab, click Manage Definitions for the Domain or Application Area from which you want to move objects. In the Maintain Library screen that opens, select the object you want to move and click Move.
To move one ore more Application Areas and/or child Domains: In the Applications tab, click the Domain's hyperlink in the Name column. In the Domain properties screen that opens, select one or more Application Areas and child Domains and click Move.
To move a child Domain or Application Area, one at a time: In the Applications tab, Application Development screen, click the icon in the object's Move column.
If you are moving objects (not Application Areas or Domains) a confirmation message appears, listing the objects you have selected to move that are currently checked out, if any, and telling you that they will be checked in as part of the Move operation.
Click Yes to continue with the operation. The Move Objects screen opens.
Select the new location: follow instructions for "Pasting Objects".
Pasting is the second part of a copy, move, or clone operation. The objects you have selected appear in the upper portion of the screen.
In the section labeled DestinationâTarget for objects when paste applied, select the Domain into which you want to paste the object(s).
The current Domain is displayed by default. You can enter the name of another Domain or click the Search icon and select another Domain; see "Using the Search and Select Window".
The system displays the Domain you selected and any child Domains and Application Areas it contains. You can click the + nodes to see Work Areas and objects within the Work Areas.
Click the Select radio button for the Domain, Application Area, Work Area, Report Set or Workflow into which you want to paste the object or objects.
The system activates the radio button only for valid locations for the object type(s) you have selected.
Click Apply. The system creates version one (1) of each object in the new location.
Note:
If the target location already contains an object of the same type and with the same name, the system appends _1 to the name of the object you copy into the target location. If the object with the same name already ends in a number, the system renames the copied object with the number incremented by one (1).If you have the necessary privileges, you can remove an object instance from a Work Area or an object definition from an Application Area or Domain. After you remove an object, the system prepends its name with a tilde (~). You can then use the original name again within the same container.
Object metadata is never completely removed. The system gives the definition or instance an end date but stores a record of it as it existed during the time it existed. However, when a Table instance is removed, all its data is deleted.
You cannot remove an object instance that has been installed and executed.
You cannot remove an object definition that is used as a source definition by one or more instances. You must remove the instance(s) first. If you try to remove an object definition with an instance, you receive an error message with the name of the instance object. To proactively check if a definition has instances, select Upgrade Instances from the Actions drop-down. The system displays all instances with their locations, validation statuses, and other information.
You cannot remove an object that contains objects that have not been deleted. This applies to Domains, Application Areas, Work Areas, Report Sets, and Workflows.
To remove objects:
In the Applications tab, go to the location of the object you need to remove.
Select one or more objects to remove.
Click Remove. The system gives you a message asking you to confirm that you want to remove the selected object(s).
Click Yes. The system removes the object or objects and returns you to the Application Development screen.
Oracle LSH enforces the following rules for object removal:
You cannot remove an object if other objects are dependent on it. For example, you cannot remove an object definition if there are one or more instances of it. (You can set the object definition's status to Retired, however, and then no additional instances of it can be created.)
You cannot remove Table instances with a validation status of Production. This is to protect production data.
In some cases the removed object is still displayed in the user interface. The system then renames the object by prepending a tilde (~) to its name.
Using a tilde to rename the object signifies that the object has been removed and allows you to create a new object of the same type in the same container with the same name.
Examples:
If an executable object has been executed and then removed, it appears in the Job Details page for the job preceded by a tilde (~).
You can remove a component object (such as a Parameter) from the object that contains it (such as a Program) or an executable object (such as a Program) from either a Report Set or a Workflow. In these cases Oracle LSH continues to display the removed object in the Version History screen for its container but renames the removed object by prepending one or more tildes (~) to its name in previous versions of the container object. You can then create a new object of the same type with the same name in the latest version of the same container. The old versions of the container continue to function as before.
This section contains the following topics:
Classifications are logically related labels defined by your company that help people find the objects you define and outputs they generate:
Oracle LSH displays outputs and submission forms (Execution Setups) by their classifications in the Reports tab.
The Advanced Search feature allows people to search for object definitions, instances, and outputs by their classifications.
When you create a new object, you must select a subtype for it according to your company's policies. The subtype determines which classification hierarchy levels you can or must use to classify your object.
There may be default or inherited classification values assigned to your object. You can accept these or override them with values you select, according to your company's policies.
Example Your company has set up a classification hierarchy with three levels, Project, Study, and Site. The Project level values include all the therapeutic areas with current trials. The Study level values include all the current trials, each linked to its therapeutic area. The Site level values include all the sites participating in each trial, each linked to its trial or trials. A given subtype may require classification only at the Study level.
When you classify a Program instance, for example, that will be used in all sites for Trial X, you classify it at the Study level to Trial X. If the whole Application Area where the Program is located is devoted to Trial X, your company may have set up its classification system so that all objects within the Application Area automatically inherit the classification value Trial X from the Application Area. This may be true for Work Areas within the Application Area and the object instances in the Work Areas as well.
Reclassification You can reclassify an object definition or instance at any time.
To view or modify the classification of the definition, you must view it in its locationâApplication Area or Domain. You cannot see the definition's classifications from an instance of it in a Work Area.
Object Versions and Classifications Classifications apply to all versions of an object. When you reclassify an object, either explicitly or through inheritance, the new classifications apply to all versions of the object.
To classify an object instance or definition:
When you first create an object, a classification interface appears automatically. If you are creating a new object definition and instance at the same time, a classification interface appears for both the definition and the instance.
If you want to change or view the classifications afterward, go to the object and select Assign Classification from the Actions drop-down list. To change the classifications, click Update.
Select a Subtype from the drop-down list, according to your company's policy, and click Go.
The system displays the classification hierarchies and levels defined for that subtype. Under each hierarchy name, the system displays the levels of that hierarchy for which objects of the subtype you specified must have a value. For example, in the Project/Study/Site hierarchy, an object subtype may require classification at the Study level, while classification at the Site level is optional. If classification at the Project level is not predefined for the object subtype, the Project level is not displayed.
For each level you see the following information:
Classification. The system displays the name of the level inside its hierarchy.
Type. The system displays whether the row shows a Subtype, a Hierarchy, a Level, or a Term. For terms, this field does not say "Term" but displays Inherited or Explicit, as the case may be.
Assignment Type. If the classification type is Inherited, the object is automatically classified to the same value for this level as its container object. For example, an object definition inherits the value from its Application Area or Domain, and an object instance inherits the value from its Work Area.
If the classification type is Explicit, you can enter one or more values. There may be a default value; if so, you can override it.
You can change the type. Normally it is best to leave inherited classifications alone, but there may be times when a particular object should not inherit the classification value of its parent.
Search and Add Value. If the assignment type is Explicit, you can search for values and assign them to the object.
Mandatory. If Yes, objects of this subtype must have a value assigned for this level, either explicitly or inherited. If No, you can assign a value from this level to the object, but it is not required.
For Explicit-type assignments, you can search and add values, as follows. If classification to the level is mandatory, you must do so.
Click the + icon in the Search and Add Value column. The system opens the Select Classification Hierarchy Terms/Values screen with a field displayed for each level in the hierarchy.
You can click Go to see all the possible classifications at once, or you can narrow the search by specifying a value in one or more of the fields. For example, in the Project/Study/Site hierarchy, if you enter Project A in the Project field and then click Go, the system returns only studies and sites related to Project A.
Select one or more values in the Results section and click Select and Continue. The system returns to the Assign Classification screen with the value or values you select displayed under their classification level.
Repeat for each level for which you want to assign classification values.
Click Apply. The system saves all the classification assignments you have made for the object.
This section contains the following topics:
Classifying outputs is different from classifying other objects because you must classify them before they are created. You can reclassify them after they are created if you have the necessary privileges.
Report Sets have a single set of classifications for the Report Set as a whole. If Programs contained in a Report Set have classifications, they have no effect.
Workflows do not have a Planned Output for the Workflow as a whole. Outputs generated by Programs and other executables in a Workflow are classified according to the Planned Output definition in the Program or other executable.
Planned Outputs An output is generated by running an executable object instance âProgram, Report Set, Load Set, or Data Martâthat has a Planned Output defined as as a placeholder for the actual output. You classify the output by classifying the Planned Output. The process for classifying a Planned Output is the same as classifying any other object, except that you have an additional option: the Program itself can create the classification at runtime; see "Classification by Parameter Value".
If you assign more than one classification value to a particular Planned Output, the actual output appears in multiple places in the Reports screen.
Execution Setups If you set the Planned Outputs's assignment type for a particular classification level to Inherited, the actual output inherits the value for that level from the Execution Setup.
Since the Execution Setup belongs to the Program, Load Set, Data Mart, or Report Set instance (unlike a Planned Output, which belongs to the definition), this approach allows you to classify the outputs of different instances of the same definition in different ways.
Classification by Parameter Value You can arrange for an output to be classified at runtime by specifying a classification type of Parameter and specifying the Parameter whose value is used as the classification assignment.
The Parameter can be an Input/Output Parameter visible, settable, and required in the Execution Setup, so that the person submitting the Program or Report Set must enter a value.
Alternatively, in the case of a Program, it can be an Output type Parameter and the Program logic must populate its value with a valid classification term.
You can define a list of values for Parameters based on classification levels; see "Defining Allowed Values" for further information.
The process is the same as for classifying object definitions and instances, except that an additional option is available for outputs.
Go to the objectâProgram, Data Mart, Load Set, or Report Setâthat will generate the output you want to classify.
Click the link of the Planned Output you want to classify. The Planned Output Properties screen opens.
Select Assign Classification from the Actions drop-down list and click Go. The Classification screen opens.
Classify the Planned Output. Follow instructions at "Classifying Objects and Outputs". However, in Programs and Report Sets you have one additional option: an assignment type of Parameter; see "Classification by Parameter Value".
If you select Parameter as the Assignment Type, the system adds another column called Parameter instance and populates a drop-down list in that column for the row with the names of all the Parameter instances in the Program or Report Set instance. Select a Parameter that will return a valid value for that classification level.
After you have run a Program, Report Set, Load Set, or Data Mart and created an output, you can change its classifications if you have the necessary privileges.
Navigate to the output in Oracle LSH. There are several ways to do this:
My Home. In the Job Execution section at the bottom of the My Home page, click the Job ID of the job that produced the output. The Job Execution Details screen opens. Click the hyperlink that is the output's name.
You can see outputs through the My Home page only if you submitted them yourself.
Reports. In the Reports tab, navigate to the output using its current classifications, then click on the icon in the Action column.
Administration. In the Job Execution subtab of the Administration tab, query for the job that produced the output. See "Querying for Jobs" in the Oracle Life Sciences Data Hub System Administrator's Guide. The system returns the search results. Click the Job ID of the job that produced the output, then click the hyperlink that is the output's name.
If you have access to the Administration tab, you can see all users' jobs.
Note:
You can use the Advanced Search feature from most screens to find outputs.To reclassify the output, do the following:
In the Output Properties screen, select Assign Classification from the Actions drop-down list. The Assign Classification screen opens.
Change the classifications as necessary; see "Classifying Objects".
This section contains the following topics:
In order to view or perform any other operation on an object, a user must belong to a user group assigned to the object. Objects automatically inherit the user group assignments of their immediate container. Therefore, by default, any object you create has the same user group assignments as its immediate container (Work Area, Application Area, Domain, Report Set or Workflow).
If you have the necessary privileges you can accept these default assignments or explicitly de-assign any of the user groups assigned to your object. You can also add other user group assignments. The changes you make will be inherited by objects contained by your object, if any.
To view user group assignments for an object:
Go to the Properties screen for the object.
From the Actions drop-down, select Apply Security. The Manage Security screen opens.
Each user group currently assigned to the object is displayed with its assignment status, which reflects the way it was assigned to the object:
Assigned. The user group was explicitly assigned to the object.
Inherited. The object inherited the user group assignment from its containing object.
Click Return to return to the object's Properties screen.
To assign a new user group:
Go to the Properties screen for the object.
From the Actions drop-down, select Apply Security. The Manage Security screen opens.
Click Assign Group. The Search User Group screen appears.
In the Group Name field, enter the name of the user group you want to add, if you know it. If you do not know it, you can click Search to retrieve all user groups, or enter part of the name plus % and click Search.
The system displays the search results.
Select one or more groups by checking the Select checkbox and clicking the Apply button.
The system returns you to the Manage Security screen with the newly assigned user group(s) displayed.
To remove a user group assignment:
Go to the Properties screen for the object.
From the Actions drop-down, select Apply Security. The Manage Security screen opens.
Click the icon in the Un-Assign column if the group's status is Assigned.
Click the icon in the Revoke column if the group's status is Inherited.
Click Yes when asked to confirm your action of unassigning or revoking the selected user group from the selected object.
Click Return to return to the object's Properties screen.
To re-assign a user group whose inherited assignment was revoked, do the following. This operation restores the assignment as inherited; if the user group is revoked from the parent object, it is automatically revoked from the current object as well.
Go to the Properties screen for the object.
From the Actions drop-down, select Apply Security. The Manage Security screen opens.
Click the icon in the Un-Revoke column.
This section includes the following topics:
Your organization must develop standards for testing Oracle LSH defined objects to demonstrate that they are valid; that is, that they handle data as they are designed to do, without introducing any corruption. As you create object definitions and instances you must follow your organization's policy for validating them in compliance with industry regulations.
All Oracle LSH objects that are contained directly in a Domain, Application Area, or Work Areaâincluding definitions and instances of Tables, Programs, Load Sets, Data Marts, Report Sets, Workflows, and Business Areas, as well as Variables, Parameters, and Notificationsâhave an attribute called Validation Status with possible values Development, Quality Control, Production, and Retired.
To support object validation, Oracle LSH provides the following tools:
Validation Status. When an object definition or instance meets the standards set by your organization for a higher validation status, you can change its status. See "Validation Statuses" for further information.
Validation Supporting Information. You can link an object with outputs and documents. See "Adding Supporting Information" for further information.
Report Coversheets. You can generate a coversheet for every report output that displays all the defined objects that interacted with the data in the report from when it was loaded into Oracle LSH to when it was reported out of Oracle LSH, including the validation status of each object. See "Generating a Coversheet with Validation and Data Currency Information" in the Oracle Life Sciences Data Hub User's Guide for further information.
Work Area Usage Intent and Cloning. Work Areas have an attribute called Usage Intent with the same list of values (except Retired) as the Validation Status attribute: Development, Quality Control, Production. Oracle LSH enforces Validation Rules based on the interaction of Work Area usage intent and object validation statuses. Work Areas also have a special operation called cloning that enables you to create clean, distinct environments for testing objects and for production; see "Cloning Work Areas for Testing and Production".
Special rules apply to the validation of Report Set Entries, which you can validate independently from other Report Set Entries and the Report Set as a whole. See "Validating Report Set Definitions and Outputs" for further information.
By default, outputs inherit the validation status of their Execution Setup. The Execution Setup inherits its validation status from its executable instance. An instance cannot have a higher validation status than its source definition. Therefore, by default an output cannot have a validation status of Production unless the Program (or other) definition used to produce it has a validation status of Production.
You can manually change the validation status of an output after it is generated; see "Changing Objects' Validation Status".
For Programs only, you can set a flag in the definition to force the system to set the validation status of an output to Development regardless of the validation status of the Program definition, instance, or Execution Setup. You can then upgrade the output's validation status manually according to your company's policies. For information about using this approach in Report Sets see "Validating Report Set Definitions and Outputs".
There are four validation statuses in Oracle LSH: Development, Quality Control, Production, and Retired. Your organization must develop a policy on the use of validation statuses. Oracle LSH enforces some behavior based on validation statuses; see Validation Rules.
Development The Development status is intended for objects that are being developed and unit tested. All new objects have a validation status of Development when they are created.
Quality Control The Quality Control status is intended for objects that are ready for or undergoing formal testing.
Production The Production status is intended of objects that are ready for or are being used in a production environment.
Retired The Retired status is for objects you no longer wish to use. See "Rules for Retired Objects" for further information.
Object definitions and instances both have a validation status. You must work directly in the definition or instance to change its validation status.
Note:
One security privilege is required to upgrade an object's validation status to Quality Control, and a different privilege is required to upgrade an object's status to Production. If you have either of these privileges, you can set an object's status to Retired.When an object meets the standards set by your organization for the next validation status, change the status as follows:
Navigate to the object definition or instance.
From the Actions drop-down list, select Support Validation Info. The Validation Status screen appears.
From the Select Validation Status drop-down list, select the correct status.
Click Update. The system tries to change the validation status and returns a message of success or failure.
Validation Cascade. The system tries to upgrade related objects at the same time in accordance with the Validation Rules. If you are promoting an object instance to a higher validation status than its underlying definition, the system tries to promote the definition as well. If someone else has the definition checked out, the operation fails.
If the definition contains secondary objectsâsuch as Parametersâ whose definitions are at a lower status, the system tries to promote them as well, and the operation fails if another user has checked them out.
Automatic Checkin. In most cases the system checks in the object and related objects as part of the validation process and applies the new status to the checked-in versions. However, you must manually check in an Execution Setup before you can change its validation status.
Click Return. The system returns you to the Properties screen for the object.
To change an output's validation status, do the following:
Navigate to the output in one of these ways:
If you submitted the job, you can click the Job ID on the My Home page to reach the Job Details screen, and then click the Output to reach the Output screen.
In the Reports tab, navigate to the output according to its classifications and click its icon in the Action column.
From the Actions drop-down list, select Support Validation Info and click Go.
From the Select Validation Status drop-down list, select the correct status.
Click Update. The system changes the validation status of the output.
Click Return. The system returns you to the Properties screen for the output.
This section contains two topics:
Before you promote an object to the next validation status, your organization may require that you provide documentation about the object: either a link to an output generated by the object, such as a report or log file, or a document such as a functional requirements document for the object.
Outputs. You can use a log file to demonstrate that a Program or other executable ran successfully. You can use a report to demonstrate that an executable object has produced an appropriate report.
Documents. You can upload any document as supporting information; for example, a requirements document or a set of test cases.
Note:
To add supporting information for an object definition, you must navigate to the definition in its Domain or Application Area. When you are in a Work Area you can add supporting information only for object instances.To link an object to a document as supporting validation information, do the following:
Navigate to the object.
From the Actions drop-down list, select Support Validation Info. The Validation Status screen appears.
Under Supporting Documents, click Add. The Manage Supporting Documents screen opens.
Enter a Name for the document.
Enter a Description for the document.
Click Browse. The system opens a standard Browse pop-up window.
Select any document on a local or shared drive and click Open.
Click Apply.
The system returns to the Supporting Information screen with the new supporting output listed. The new supporting document's status is set to Active.
Version History. If you upload a different document in the future, the system creates a new version of the supporting document. Click Version History to see who changed the document when, with the reason for change, which is required. You can also view the document uploaded for each previous version.
Click Return to go back to the object's Properties screen.
To link an object to an output as supporting validation information, do the following:
Navigate to the object.
From the Actions drop-down list, select Support Validation Info. The Validation Status screen appears.
Under Supporting Outputs, click Add. The Manage Supporting Outputs screen opens.
Enter a Description for the output (required).
Click the Search icon to find the output you need. The Search and Select screen opens.
For Search Using, select either Hierarchy or Job ID.
If you select Hierarchy, select the hierarchy name and the level to which the output is classified and enter the value in the Search field.
Or enter a high-level value only and check Include hierarchy based child in the search to search all values in levels below the value you specify.
If you select Job ID, enter the job ID in the Search field.
Click Go. The system displays the results of the search.
Click the icon in the Quick Select column for the output you want.
The system returns to the Supporting Output Properties screen with the new output listed.
Click Apply. The system returns to the Managing Supporting Outputs screen with the new supporting output listed.
Click Return. The system returns to the Validation Status screen.
Click Return. The system returns to the object's Properties screen.
The system enforces the following rules based on objects' validation status:
You can change an object's validation status only when it is checked in. If the object is not checked in, the system tries to check it in. If another user has checked it out, you cannot change the validation status.
Changing the validation status of a checked-in object does not change the version number of the object.
You cannot promote an object instance to a validation status higher than its underlying object definition. However, the system tries to promote the underlying definition when you promote the instance. If the definition is checked out by another user, the operation fails.
For example, if you create an instance of a Program definition whose validation status is Quality Control, you can promote the instance to a validation status of Quality Control, but you cannot promote it to Production until the definition has been promoted to Production. However, the system attempts to promote the definition to Production when you promote the instance, and if you have the necessary privileges on the definition, and if the definition is not checked out by a different user, the promotion succeeds.
Validation status is version-specific. Each time you create a new version of an object by checking it out (including checking out a definition through an instance) the system automatically gives the new version a validation status of Development. The system does not change the validation status of any existing versions.
When you copy an object, the validation status of the copy is set to Development no matter what the validation status of the original is.
You cannot run an Execution Setup whose validation status is less than the validation status of its owning object instance unless you have the IQ Submit security privilege on the Execution Setup.
To be installed in a Work Area, object instances must have a validation status equal to or greater than the Usage Intent of the Work Area.
The Work Area cannot be promoted to a validation status higher than the validation status of any of its object instances. However, if you try to promote a Work Area to a status above that of any of its objects, you have the opportunity to promote all the object instances and their underlying definition versions to the same status in a cascade operation.
The cascade validation fails if a different user has checked out any of the object definitions in need of promotion.
No executables can be run in a Work Area until the Work Area's validation status is equal to or greater than its Usage Intent value, except by users with the special Install Qualify Submit privilege on the Work Area. This is to allow testing of the Work Area before making it generally available for use.
Full installation and the Replace operation on Table instances in partial installation are not allowed in Work Areas with a usage intent of Production. This is to protect production data from deletion.
You cannot remove a Table instance whose validation status is Production from a Work Area of any usage intent.
Rules for Retired Objects The following rules apply to Retired objects:
If an executable object instance is set to Retired, it cannot be submitted for execution, regardless of the validation status of it Execution Setups.
If a Work Area is set to Retired, no executable objects within it can be submitted for execution.
If you clone a Retired Work Area, the clone's status is also set to Retired. In the Work Area clone, the object instances retain the validation status they had in the original Work Area. Retired objects are included in the cloning process.
You can use the Reorder function to change the order of some objects and the Renumber function to create sequential numbering for some objects.
To reorder and/or renumber objects:
Select the object you want to move and click the Up and Down arrows to move it in relation to the other objects.
Starting Entry Number (Report Sets only). By default, the object displayed at the top is assigned the number one (1). You can enter a different starting number in the Starting Entry Number field.
If you want to change the object's numbers to reflect the new order and/or the new starting number, leave the Renumber flag set to Yes. If you change the setting to No, the system keeps the original numbers (except the changed starting number, if any) but displays the objects in the order you specify.
Click Apply. The new order and/or numbers are displayed in the original screens.
This section contains the following topics:
Table Descriptors are a required subcomponent of Programs, Load Sets, Data Marts, and Business Areas whose purpose is to promote the reuse of these types of object definitions by serving as an interfaceâan extra definitional layerâbetween the object in which they are contained and the Tables the object reads from and/or writes to. You define Table Descriptors as part of the object definition and, in the object instance, map each one to a Table instance. A Table Descriptor is a view contained in a Program or other object definition.
In a Program definition's source code you refer to source and target Tables and Columns by the names of the Table Descriptors and their Columns, not the actual Table instances. In each instance of the Program you map the Table Descriptors to the Table instances they must read from or write to. You can have multiple instances of the same Program mapped to different source and target Table instances, and the Table instances may have different names or a different (but compatible) structure (see "Mapping Columns of Different Data Types and Lengths").
For example, if Study 1 and Study 2 use demography tables with the same structure but called Demog in Study 1 and Demo in Study 2, you can create a single Program definition that reads from the demography table and creates several reports. You can create one instance of the Program that reads from the Study 1 Demog Table and another instance of the Program that reads from the Study 2 Demo Table.
Table Descriptors do not have constraints or data processing types. Different rules apply to source and target Table Descriptors.
Source Table Descriptor A source Table Descriptor must be mapped to a Table instance that contains data to be used as input. You can map a source Table Descriptor to a Table instance located in any Work Area to which you have security access; in other words, your Program (or Data Mart or Business Area) can operate or report on data located anywhere in Oracle LSH where you have View privileges to Table instances.
For example, if you have a different Application Area for each clinical trial, you can pull data from each trial and combine data for a whole project by mapping the source Table Descriptors of the Program that combines the data to Table instances in the Work Area for each of the clinical trials.
The same Table instance can serve as a source for multiple Programs, Business Areas, and Data Marts.
Target Table Descriptor A target Table Descriptor must be mapped to a Table instance that receives data output from a Program or Load Set. Target Table Descriptors must be mapped to a Table instance located in the same Work Area as the Program or Load Set instance.
Mapping Rules The system enforces the following mapping rules:
Only one Program can write to a Table instance; therefore only one target Table Descriptor can be mapped to a particular Table instance.
A Table instance can be mapped to only one Table Descriptor in a Program instance.
For additional rules, see "Using Format Conversions" and "Mapping Columns of Different Data Types and Lengths".
There are several ways to create a Table Descriptor:
Adding a Target Table Descriptor from an Existing Table Definition
Creating Table Descriptors from Table Instances and Simultaneously Mapping Them
See also:
This option is available for objects that have source Table Descriptors: Programs, Business Areas, and Data Marts. To use this option, the Table instance you want to read from must already be defined in Oracle LSH and you must have Read privileges on it. You can create multiple Table Descriptors at a time from Table instances located in a single Work Area.
The system bases the Table Descriptor on the same Table definition the Table instance is based on, and automatically maps the new Table Descriptor to the Table instance.
Note:
This functionality is also available in the Actions drop-down as the Table Descriptors from Existing Table Instances item.Note:
You can also create a source Table Descriptor by creating a target Table Descriptor and changing its Is Target attribute value to No.In the Table Descriptors subtab in the Properties screen of a Program, Business Area, or Data Mart instance, click Add Source.
The Create Table Descriptors from Table Instances screen opens.
Select the location of a Table instance for which you want to create a Table Descriptor:
Select the Table instance's Domain from the Domain drop-down list.
Select the Table instance's Application Area from the Application Area drop-down list. The choices are limited to Application Areas contained in the Domain you selected.
Select the Table instance's Work Area from the Work Area drop-down list. The choices are limited to Work Areas contained in the Application Area you selected.
Click Go. The system displays all the Table instances in the Work Area you selected.
Select one or more Table instances by clicking the Select checkbox.
Click Create Table Descriptor. The system returns you to the Create Table Descriptors from Table Instances screen. To return to the Program's Properties screen, click Return. Check that the mappings are complete.
This option is available for Oracle technology Programs and Load Sets.
The system searches for Variables in the same Application Area with the same name, data type, and length as each of the variables in the data set. If a matching Variable exists, the system bases a Column of the Table definition on it. If a Table definition with the same name already exists in the Application Area, the system appends _1 to it, or _x if the Table name already has a number appended, where x is the next larger integer.
After defining the Remote Location and any other required attributes, go to the Table Descriptors subtab of the Load Set's Properties screen and click Add Target from Remote Location. The system opens the Upload Table Descriptors screen with tables from the specified remote location displayed.
Select the tables from which you want to create Table Descriptors and click Apply.
For each selected table, the system creates a target Table Descriptor and Table definition in the current Application Area. The system returns to the Load Set's Properties screen.
You can update the Table Descriptor as necessary; click the Table Descriptor name. See "Setting Table Descriptor Attributes" and "Adding or Uploading Columns".
Click the Mapping icon for the Table Descriptor and map it to a Table instance. See "Mapping Table Descriptors to Table Instances".
This option is available for objects that have target Table Descriptors and support this option: Programs and some Load Sets. If you specify a single data set file, the system creates a single Table Descriptor. If you specify a SAS transport file that contains more than one data set, the system creates one Table Descriptor for each data set in the file.
The system searches for Variables in the same Application Area with the same name, data type, and length as each of the variables in the data set. If a matching Variable exists, the system bases a Column of the Table definition on it. If a Table definition with the same name already exists in the Application Area, the system appends _1 to it, or _x if the Table name already has a number appended, where x is the next larger integer.
Note:
Oracle LSH gives SAS variables of SAS format BEST8 a length of 8 and Precision set to null.In the Table Descriptors subtab of the Load Set or Program's Properties screen, click Add Target from SAS File. The system opens the Create Table Descriptors screen. with Create a New Table Definition and Descriptor from SAS file selected.
Click Browse. The system opens a standard browse screen.
Navigate to the location of the SAS file.
Highlight the file and click OK, then click Apply
The system creates a target Table Descriptor and Table definition in the current Work Area. The system returns to the Program or Load Set's Properties screen.
Click the Table Descriptor name to see the Table Descriptor screen. You can update the Table Descriptor here as necessary; see "Setting Table Descriptor Attributes" and "Adding or Uploading Columns".
Click the Mapping icon for the Table Descriptor and map it to a Table instance. See "Mapping Table Descriptors to Table Instances".
This option is available for objects that have target Table Descriptors: Programs and Load Sets.
In the Table Descriptors subtab of the Program or Load Set's Properties screen, click Add Target from Library. The system opens the Create Table Descriptors screen with Create a Descriptor of an Existing Table Definition selected.
Click the Search icon. The system opens the Search and Select screen.
Select the location of a Table definition from which you want to create a Table Descriptor:
Select the Table definition's Domain from the Domain drop-down list.
Select the Table definition's Application Area from the Application Area drop-down list. The choices are limited to Application Areas contained in the Domain you selected. Leave this field blank to search for definitions contained in the Domain library.
If you know the exact name or version label of the definition you want, select either Name or Version Label from the Search By drop-down list and enter the name or version label in the blank field.
(Optional) Select Display All Versions and/or Display Not Null Version Labels.
Click Go. The system displays the Table definitions in the Application Area or Domain Library you selected.
Click the Quick Select icon for the Table definition from which you want to create the Table Descriptor. The system populates the Definition Source field with the definition you selected.
Click Apply. The system opens the screen for the new Table Descriptor.
You can update the Table Descriptor here as necessary; see "Setting Table Descriptor Attributes" and "Adding or Uploading Columns".
Click the Mapping icon for the Table Descriptor and map it to a Table instance. See "Mapping Table Descriptors to Table Instances".
You can create aTable Descriptors by uploading a metadata (.mdd) file with a required format, or create multiple Table Descriptors at once by uploading a zipped file containing multiple metadata files.
Depending on the type of object for which you are creating the Table Descriptor, the name of the button in the Table Descriptor tab varies: either Add, or Add Target, or File.
If the file has an .mdd extension, the system expects a set of Column attribute values, optionally preceded by a row identifying the delimiter and a row defining Table attribute values, each of which must begin with a key word. A row beginning with dashes is treated as a comment. For example:
--This is a comment.
Example 3-1 Sample Set Metadata File
lsh_delimiter = ,
--This section is for the Table attributes
lsh_table= DM,DEMOG Table,EMP,EMP,EMP,Staging with Audit,Yes,Yes,Blinded,target,yes,yes
--The following are columnsComment Line 2
INITS,VARCHAR2,100,,inits,inits,2.,,inits,no,1
AGE,NUMBER,10,,2,age,age,2.,,age,yes,1
DOB,DATE,,,3,dob,dob,datetime.,,dob,yes,1,MM/DD/YY HH24:MI:SS
Delimiter The first row defines the delimiter used in the file. If not specified, Oracle LSH treats it as a comma delimited file. The delimiter row must begin with lsh_delimiter=
Table and Table Descriptor Attributes The second row lists the table attributes required in the file. The Table attribute row must begin with lsh_table=
If the second row is not present or contains null values, the system assumes that the filename (without extension) is the Table Name and follows the normal Oracle LSH default behavior for the attribute values. The attributes and their required order in the file are: Name, Description, Oracle Name, SAS Name, SAS Label, Process Type, Allow Snapshot?, Blinding Flag?, Blinding Status, SAS Library Name, Is Target?, Target as Dataset?
Some attributes have associated reference codelists and allow either the actual values for the associated reference codelist (RC) columns or the decode values defined in the "Meaning" attribute of the _RC lookup. For example, "select meaning from cdr_lookups where lookup_code='< RC>' so that YES or Yes or $YESNO$YES are acceptable values.
The following table outlines the applicable values for each Oracle LSH Table attribute that has an associated reference codelist.
Note:
Processing types that require audit keys are not supported.Table 3-1 Table Attributes with Reference Codelist Values
| Table Attribute | Applicable Reference Codelist Values |
|---|---|
|
Processing Type |
Staging with Audit, Staging without Audit, Transactional High Throughput, Transactional without Audit |
|
Allow Snapshot |
Yes, No |
|
Blinding Flag |
Yes, No |
|
Blinding Status |
Blinded, Unblinded |
|
Is Target |
Yes, No |
|
Target as dataset |
Yes, No |
|
Data Type |
Date, Number, Varchar2 |
|
Nullable |
Nullable , Yes, No |
Columns Subsequent rows must contain the column and variable attributes with each represented by a new row in the text file with attributes. The position is determined by the order in which the column /variable rows are processed. For example, in a comma delimited file: Name, Data Type, Length, Precision, Oracle Name, SAS Name, SAS Format, Description, SAS Label, Nullable, Default Value, Date Format
Normal Oracle LSH validation rules apply to the Column or variable attributes. The operation uses Oracle LSH default values if invalid values are provided for any of the attributes.
This option is available for objects that have target Table Descriptors: Programs and Load Sets. If your Program will write to (or read from) a table that does not yet exist, you can manually create the Table definition and Table Descriptor at the same time:
In the Table Descriptors subtab of the Program's Properties screen, click Add Target from New. The system opens the Create Table Descriptors screen with Create a New Table Definition and Descriptor selected.
Enter values in the following fields:
Name. See "Naming Objects".
Description. See "Creating and Using Object Descriptions".
Oracle Name (up to 30 characters, uppercase, no spaces). Enter text or accept the default value. The system automatically creates the default from the text you entered in the Name field, converting it to uppercase, with underscores (_) substituted for spaces, truncated to 30 characters if necessary.
Note:
Each Table Descriptor within a particular executable object must have a unique Oracle Name.SAS Name (up to 32 characters, uppercase, no spaces). Enter text or accept the default value. The system automatically creates the default from the text you entered in the Name field, converting it to uppercase, with underscores (_) substituted for spaces.
Enter a SAS Label (optional, up to 256 characters). Enter text or accept the default value. The system automatically creates the default from the text you entered in the Name field.
Enter a SAS Library Name (optional, up to 8 characters).
Note:
If you plan to use this Table Descriptor with an Oracle Business Intelligence (OBIEE) Business Area, you can set the SAS Library Name to$REPINIT. See "Defining Table Descriptors" for more information.Set Is Target and other Table Descriptor attributes; see "Setting Table Descriptor Attributes".
In the Classification section, select the following for the definition:
Subtype. Select a subtype according to your company's policies.
Classification Values. See "Classifying Objects and Outputs" for instructions.
Click Apply. The system opens the screen for the new Table Descriptor.
You can update it as necessary:
Click Update to modify attribute settings. See "Setting Table Descriptor Attributes".
Check out the Table definition to be able to add Columns. See "Adding or Uploading Columns".
If you make any changes, click Apply to save them. The system opens the Table Descriptor Properties screen. Click Return. The system opens the Program's Properties screen.
Click the Mapping icon for the Table Descriptor and map it to a Table instance. See "Mapping Table Descriptors to Table Instances".
Table Descriptors may have the following attributes:
Is Target Select Yes to create a target Table Descriptor. Select No to create a source Table Descriptor.
Target As Dataset (Available only in SAS Programs, and only when Is Target is set to Yes.) Select Yes if you are using a legacy SAS program that uses data statements to write to data sets. Because Program source code must write to Table Descriptors, and Table Descriptors are views, you should use Proc SQL statements to write data to tables in Oracle LSH. However, if you set this attribute to Yes, Oracle LSH adds a processing step to enable SAS data statements to write to Oracle LSH Table Descriptors. This extra processing step results in slower performance but allows you to use existing programs.
Select No if the Program's source code uses Proc SQL statements to write to Table Descriptors. This results in optimal performance.
Reveal Audit (Available only for source Table Descriptors; when Is Target is set to No.) By default Reveal Audit is set to No and the Program, Data Mart, or Load Set can read data from the Table instance mapped to this Table Descriptor that is or was current at a particular point in time. By default it sees only current data, but it is possible to specify a data snapshot at a past point in time in the Execution Setup of the Program, Data Mart, or Load Set.
Each time a data record is changed in Oracle LSH, the system creates a new row with the updated information. The system sets the end timestamp of the old record so that it is no longer current. When a record is deleted, the system sets its end timestamp and also adds a row explicitly recording the deletion. The set of rows for a single data record constitutes its audit trail.
If you set Reveal Audit to Yes the system exposes all data in the Table instance at all points in time to the Program, Data Mart, or Load Set reading from the Table instance, and exposes the predefined audit columns CDR$CREATION_TS (creation timestamp), CDR$CREATED_BY (creator username), CDR$MODIFICATION_TS (modification timestamp), and CDR$MODIFIED_BY (modifier username).
Note:
Because SAS does not support the $ special character, the SAS Name of each of these internal column names has an underscore (_) instead of a dollar sign ($) as follows: CDR_CREATION_TS, CDR_CREATED_BY, CDR_MODIFICATION_TS, CDR_MODIFIED_BY.You can use this functionality as follows:
Data Marts. If you set Reveal Audit to Yes for all the Table Descriptors in a Data Mart, the resulting Data Mart output contains the complete audit trail of every record that the mapped Table instances ever contained.
Programs. If you set Reveal Audit to Yes for all the Table Descriptors in a Program, you can write source code that reads data from all points in time and that references the audit columns.
Load Sets. Because the source Table Descriptors of most types of Load Sets point to data files or tables outside of Oracle LSH that do not contain audit information, it does not make sense to use the Reveal Audit feature with SAS, text, or most Oracle Load Sets. However, Oracle Clinical uses a similar system for maintaining an audit trail so you may want to use Reveal Audit with some Oracle Clinical tables.
Oracle Clinical inserts a row each time a record is modified and sets the end timestamp of the previous row for the same record. However, when a record is deleted Oracle Clinical sets its end timestamp but does not add a row explicitly recording the deletion.
Note:
The Execution Setup user interface cannot detect if a Table instance is mapped to a Table Descriptor whose Reveal Audit flag is set to Yes, so it is possible for a user to specify a snapshot for such a Table instance at execution time. However, during execution the system ignores any snapshots set for Table instances mapped to a source Table Descriptor whose Reveal Audit flag is set to Yes.You can upload Columns based on SAS data set variables:
Check out the Table Definition if it is not already checked out.
Click Upload Column. The system displays the Upload Column screen.
Click Browse. The system opens a standard Browse pop-up window.
Navigate to the data set from which you want to upload Columns and click Open, then Apply. The system uploads all the variables from the data set as Columns in the Table Descriptor and its source Table definition.
You can remove any Columns you do not need. To remove one or more Columns, click the checkbox in the Select column and click Remove.
This section includes the following topics:
Creating Table Descriptors from Table Instances and Simultaneously Mapping Them
Creating Table Instances from Table Descriptors and Simultaneously Mapping Them
The Effects of Modifying the Table Descriptor or Table Instance on a Mapping
A Program or other executable object instance can read data only when its source Table Descriptors are mapped to the Table instances that contain the source data, and can write data to Table instances only when target Table Descriptors are mapped to the Table instances. In addition, both the executable instance and the Table instance must be installed in the database. Table Descriptors must be mapped to Table instances at both the Table and Column level.
Mapping Columns When you map a Table Descriptor to a Table instance, the system may or may not be able to map Columns automatically. If not, you can map them manually; see "Mapping Table Descriptors Manually".
However, if a Target Table Descriptor in a Load Set or Program is updated or new columns added, installation automatically upgrades the Table instance and completes the mapping. Note that the Table instance is upgraded only if the changes to the Table Descriptor are non-destructive, such as the addition of a column.
You can supply default values for any Columns that are still unmapped; see "Mapping Columns to Constants". In some cases, you can map columns of different data types and lengths; see "Mapping Columns of Different Data Types and Lengths").
For source Table Descriptors you do not need to map Table instance Columns that are not used by the Program.
Data Processing Compatibility Be sure to map target Table Descriptors to Table instances whose data processing type is compatible with your source code:
If you have insert, update, and delete statements in your source code, you must map your target Table Descriptors to Table instances with a data processing type of either Transactional or Staging.
If you have insert statements only, you must map your target Table Descriptors to Table instances with a data processing type of either Reload or Staging.
The Automatic Mapping by Name job can run on multiple Table Descriptors in a Program or other executable object. By default, it looks for a Table instance with the same name in the same Work Area as the executable instance. If you are mapping source Table Descriptors only, you can specify a different Work Area.
You can also use this feature for remapping Table Descriptors.
To run automatic mapping:
On the executable instance's Properties screen, select Automatic Mapping By Name from the Actions drop-down list and click Go. (In a Report Set instance, you can reach this screen from the Report Set structure screen by selecting the Report Set instance or a Report Set Entry, then selecting Map from the drop-down list and clicking Go.)
The system displays the Automatic Mapping by Name screen and, by default, unmapped Table Descriptors only. The current Work Area is selected by default, and if it contains a Table instance with the same name as an unmapped Table Descriptor, the Table instance is displayed on the same row as the Table Descriptor.
In the View drop-down list, specify which Table Descriptors to display:
Unmapped. The system displays only unmapped Table Descriptors (the default).
Mapped. The system displays only mapped Table Descriptors, so that you can remap them to different Table instances.
Both Mapped and Unmapped. The system displays all Table Descriptors and you can map and remap them as necessary.
Select the location of a Table instance you want to map to. Accept the current Work Area or, only if you are mapping a source Table Descriptor, specify a different one by doing the following:
Select the Table instance's Domain from the Domain drop-down list.
Select the Table instance's Application Area from the Application Area drop-down list. The choices are limited to Application Areas contained in the Domain you selected.
Select the Table instance's Work Area from the Work Area drop-down list.
Click Go. The system searches the selected Work Area for Table instances with a name that matches the name of any of the displayed Table Descriptors and displays them in the same row as the matching Table Descriptor if found.
Select one or more Table Descriptors with a matching Table instance in the specified location and click Map. The system creates the Table-level mapping and attempts to map Columns by name.
Map another Table Descriptor or click Return to display the executable's main page.
Check the mapping status of the Table Descriptors you have mapped.
If the system was able to map all their Columns, their mapping status is Complete.
If the system could not map all the required Columns, their mapping status is Incomplete and you must map them manually. See "Mapping Columns".
If you want to map a Table Descriptor to a Table instance that has a different name, you must map it manually. You can also use this method to remap a Table Descriptor that is already mapped.
To map a Table Descriptor to a Table instance manually, go to the main Program screen, Table Descriptors subtab, and do the following:
Click the icon in the Table Descriptor's Mapping column. The system opens the Mapping screen with the Table Descriptor's name already entered in either the From or To column, depending on whether it is a target or a source Table Descriptor, respectively.
Click Update. Several fields become modifiable.
Click the Search icon next to the Map to Table Instance field. The system opens the Search screen.
Select the Domain, Application Area, and Work Area of the Table instance to which you want to map.
Select the Table instance's Domain from the Domain drop-down list.
Select the Table instance's Application Area from the Application Area drop-down list. The choices are limited to Application Areas contained in the Domain you selected.
If you know the exact name or version label of the Table instance you want, select either Name or Version Label from the Search By drop-down list and enter the name or version label in the blank field.
Click Go. The system displays all the Table instances that meet the criteria, and for which you have View privileges.
You cannot map to a Table instance while its source Table definition is checked out. The system displays Table instances whose source Table definition is currently checked out as grayed out. You can look at the Table definition to see who has it checked out.
Click the Quick Select icon for the Table instance you want to map.
The system enters the name of the Table instance you selected and automatically tries to map it to the Table Descriptor. The system displays any Columns it finds that match a Column in the Table Descriptor across from the matching Column.
If the system does not find a match, it populates a drop-down list for each Table instance Column that contains the names of all the Table instance Columns.
For each Column of the Table instance, choose the Column from the drop-down list that you want to map to the Table Descriptor Column displayed on the same row.
Alternatively, you can map to a constant (see Mapping Columns to Constants) or convert to a different data type (see "Mapping Columns of Different Data Types and Lengths") you can enter that information in the Default Value or Format String field, respectively.
Click Apply. The system saves the mapping and returns you to the Program screen.
You can remap a mapped Table Descriptor to a different Table instance in two ways:
If the Table Descriptor has the same name as the Table instance, use automatic mapping by name; see "Automatic Mapping by Name".
If the Table Descriptor has a different name from the Table instance, use manual mapping; see "Mapping Table Descriptors Manually".
A mapping is specific to a particular version of both the Table Descriptor and the Table instance. When you check out either one:
The system upgrades the mapping to the new version of the Table Descriptor or Table instance if possible. There are two conditions where it is not possible: You modify a Table Descriptor from a source to a target and either:
The Table instance is not in the same Work Area as the executable object that owns the Table Descriptor.
The Table instance is already mapped to another target Table Descriptor.
The system reevaluates the mapping and resets its status to either Complete or Incomplete.
For a Mapping to be complete, all Columns must be mapped to Columns in the Table instance or to constants, and all other mapping rules must be followed.
When you check out either a mapped Table Descriptor or a mapped Table instance, there is no effect on the other object, only on the mapping.
This section includes the following topics:
When you map a Table Descriptor to a Table instance using any method, the system tries to map the Columns at the same time, by name. If the system cannot map the Columns, the mapping status of the Table Descriptor is set to Incomplete. You must map the Columns manually before you can install the Program instance.
In most cases you map each Column of the Table Descriptor to a Column in the Table instance to which it is mapped. However, you can also map Columns to constants.
If you have mapped a Table Descriptor to a Table instance, but have not mapped the columns, then the system can map columns automatically. Do the following:
In the Program instance's Properties screen, Table Descriptors subtab, click the icon in the Mapping column for the Table Descriptor whose Columns you want to map.
Click the Reset to Default Mapping button. For each Table Descriptor, the system checks the Table instance for a column with a matching name or a matching variable reference. If it finds one, it maps the Table Descriptor column with the Table instance column.
Nothing happens if you click this button when the Table Descriptor and Table instance mapping is already complete.
If the system cannot find matching column names or variable reference names between the Table Descriptor and the Table instance, then you cannot automatically map in this way. You need to map columns manually as described in the next section.
To map Table Descriptor Columns to Table instance Columns, do the following:
In the Program instance's Properties screen, Table Descriptors subtab, click the icon in the Mapping column for the Table Descriptor whose Columns you want to map.
The Mapping screen opens. It has a row for each Column divided into a set of columns labeled From and another set labeled To. The system populates the From and To sections as appropriate for the flow of data: if the Table Descriptor is a source Table Descriptor, it is displayed in the To section because data appears to flow from the Table instance to the Program through the Table Descriptor; if it is a target Table Descriptor, it is displayed in the From portion because data appears to flow through it to the target Table instance. (Table Descriptors never actually contain data.)
Click Update. The system makes several fields enterable.
Select a Table instance. If a Table instance is not already specified in the upper portion of the screen, or if you want to map the Table Descriptor to a different Table instance, click the Search icon by the Map to Table Instance field.
The Search and Select screen opens with the current Work Area's Table instances displayed by default.
If the Table Descriptor is a target Table Descriptor, you cannot select a different Work Area. If the Table Descriptor is a source Table Descriptor, you can select a Table instance in any Work Area:
Select the Table instance's Domain from the Domain drop-down list.
Select the Table instance's Application Area from the Application Area drop-down list. The choices are limited to Application Areas contained in the Domain you selected.
If you know the exact name or version label of the Table instance you want, select either Name or Version Label from the Search By drop-down list and enter the name or version label in the blank field.
Click the Quick Select icon for the Table instance you want to map to. the system returns you to the Mapping screen with the Table instance information displayed.
Map Columns. Map each Table Descriptor Column to a Table instance Column or a default value. You can also enter a conversion string if either the Table instance Column or the constant is in a different format from the Table Descriptor Column:
Select a Table instance Column from the drop-down list to which to map the Table Descriptor Column.
Enter a value in the Default Value field to populate the Column to a constant; see "Mapping Columns to Constants".
If you are mapping Columns of different data types, enter a format string for the system to use in the conversion, if necessary. See "Using Format Conversions".
Click Apply. The system validates the mappings you specified and returns you to the Program instance's Properties screen.
If you specified an invalid mapping, the system displays an error message.
If you map to a Table instance Column or a constant with a different data type or format than the Table Descriptor's Column, you can enter a format conversion string for Oracle LSH to convert the value that is upstream in the data flow to the correct format for the downstream value.
For example, if a source Table instance contains a number value that needs to be converted to a dollar amount for the Program to analyze, enter a format conversion such as: format=$99,999.00. If a source Column has a data value of 10000, Oracle LSH converts that value to $10,000.00.
For format models, see the Oracle 9i SQL Reference Guide.
If the data types and/or lengths of the Table instance and Table Descriptor Columns do not match, mapping may still be allowed. The rules are different for source and target Table Descriptors. See Figure 3-3 for an illustration of the data flow.
The principles are:
Only Number data types can feed into Number data types and only Date data types can feed into Date data types.
Shorter lengths can feed into longer lengths, but longer lengths cannot feed into shorter lengths.
For Number data types, lesser precision can feed into greater precision, but greater precision cannot feed into lesser precision.
On the source side, Table instance Columns of Number and Date data types can feed into Table Descriptor Column Varchar2 data types.
On the target side, Table Descriptor Column Number data types can feed into Table instance Column Varchar2 data types, but Date data types cannot.
There may be cases where a Table instance or Table Descriptor upstream in the data flow does not contain a Column needed for mapping by a Table Descriptor or Table instance Column downstream in the data flow:
a source Table instance does not contain a Column that is needed for mapping by a source Table Descriptor
a target Table Descriptor does not have a Column needed for mapping by the target Table instance
In these cases, you can map the existing Column of the source Table Descriptor or target Table instance to a constant by supplying a default value for the Column. Figure 3-3 shows how to supply constants for Columns in relation to the data flow direction.
If you are supplying a constant as a value to a Column whose data type is not Varchar2, you must provide conversion information. For example, to convert the text you enter as the constant to the Date data type, enter the value 04-JAN-2005 in the Default Value column, and enter DD-MON-YYYY in the Format String column. The system reads the constant as a date.
For any data type, the value after conversion cannot exceed the length defined for the Column.
NULL is a valid constant value (if allowed by the receiving Column).
When you pass a constant to a Column downstream from it in the data flow (either to a source Table Descriptor Column or a target Table instance Column (see Figure 3-3), the specific requirements differ according to the data type of the receiving Column, as follows:
Varchar2 If you pass a constant to a Column with a data type of Varchar2, the length of the constant must be less than or equal to the length of the Column.
Number If you pass a constant to a Column with a data type of Number, the following rules apply:
You must provide a number format (with a default) and the constant must be valid when passed to a to_number with the supplied number format.
The length of number produced by to_number (constant, number format) must be <= the length of the Column.
The precision of number produced by to_number (constant, number format) must be <= the precision of the Column.
Date You must provide a date format and the constant must be valid when passed to a to_date with the supplied number format.
Null Allowed EXCEPT if mapping from a target Table Descriptor to a Table instance Column that is not nullable.
Figure 3-3 Data Flow from Table Instances to Program Instance to Table Instances
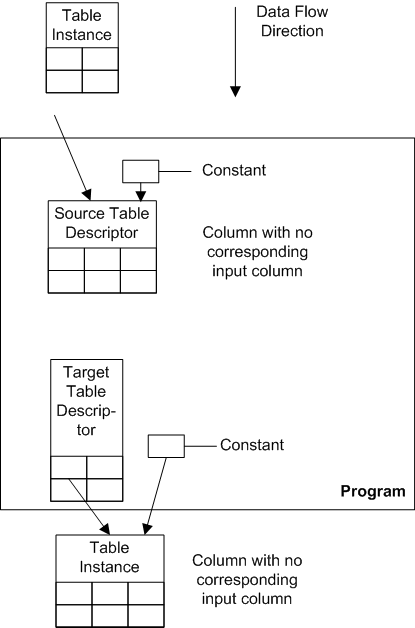
This section contains information on the following topics:
Creating and Mapping Table Instances during Single Instance Installation
Creating Table Descriptors from Table Instances and Simultaneously Mapping Them
Creating Table Instances from Table Descriptors and Simultaneously Mapping Them
You can install an object from its Properties screen or Work Area even if its installation status is Non Installable. For objects that have target Table Descriptors, such as Programs and Load Sets, the system attempts to correct issues that are preventing the object from being installed:
The system runs Automatic Mapping by Name to map any unmapped target Table Descriptors to Table instances with the same name in the current Work Area, if any.
If any target Table Descriptors remain unmapped, the system automatically creates new Table instances in the current Work Area and maps them.
Both these tasks are performed by a batch job. If the system cannot resolve all issues automatically, the job fails. You can view the job log in your My Home screen.
If the Table instance you need to read from or write to already exists in Oracle LSH, you can create a Table Descriptor from the Table instance. The system bases the Table Descriptor on the same Table definition the Table instance is based on, and automatically maps the new Table Descriptor to the Table instance.
You can use this method to create multiple Table Descriptors at the same time from Table instances located in a single Work Area.
This is the only method where the system creates a source Table Descriptor by default. You can change the setting to Is Target if necessary.
Note:
You can create target Table Descriptors only from Table instances in the same Work Area as the Program.To create a Table Descriptor from an existing Oracle LSH Table instance, do the following:
In the Program's Properties screen, select Table Descriptors from Existing Table Instances from the Actions drop-down list and click Go.
The Create Table Descriptors from Table Instances screen opens.
Select the location of a Table instance for which you want to create a Table Descriptor:
Select the Table instance's Domain from the Domain drop-down list.
Select the Table instance's Application Area from the Application Area drop-down list. The choices are limited to Application Areas contained in the Domain you selected.
Select the Table instance's Work Area from the Work Area drop-down list. The choices are limited to Work Areas contained in the Application Area you selected.
Click Go. The system displays all the Table instances in the Work Area you selected.
Note:
A Table instance can be mapped to only one Table Descriptor in a Program instance. In addition, only one Program instance can write to a particular Table instance. You get an error if you select a Table instance whose selection would violate either of those rules.Select one or more Table instances by clicking the Select checkbox.
Click Create Table Descriptor. The system returns you to the Create Table Descriptors from Table Instances screen. To return to the Program's Properties screen, click Return. Check that the mappings are complete.
You can create a Table instance in the current Work Area corresponding to each Table Descriptor and map each pair. The system bases the Table instance on the same Table definition the Table Descriptor is based on, and automatically maps the Table Descriptor to the new Table instance.
You can use this method to create multiple Table instances at the same time from Table Descriptors located in a single Load Set, Program, Data Mart, Business Area, Report Set or Workflow. In Report Sets and Workflows this option is available only at the Report Set and Workflow level, not from individual Program instances in the Report Set or Workflow.
Note:
Table instances are created with the default settings for all attributes, including Process Type (which is Staging with Audit). You can go to the Table instances and update them as necessary.To create a Table instance from one or more existing Table Descriptors in a single Load Set, Program, Data Mart, or Business Area, do the following:
In the object's Properties screen, select Table Instances from Existing Table Descriptors from the Actions drop-down list and click Go.
The Create Table Instances from Table Descriptors screen opens, displaying all the unmapped Table Descriptors.
Note:
If you have created the object inside a Workflow, then use the Actions drop-down list job Table Instances from Existing Tables Descriptors from the Workflow's Properties screen. This job is not available in the object's Properties screen.Select the Table Descriptors for which you want to create a Table instance by clicking the box in the Select column.
Click Create Table Instance. The system displays a message asking if you want to create the Table instance.
Click Yes.
The system returns you to the Create Table Instances from Table Descriptors screen. To return to the Program's Properties screen, click Return. Check that the mappings are complete.
If a Table Descriptor is mapped to one Table instance and you need to map it to a different Table instance, you must unmap it first.
To unmap a Table Descriptor, do the following:
In an executable object instance, click the Table Descriptor you want to unmap.
Click the icon in the Mapping column. The Mapping page opens.
Click Update. The screen becomes editable and the Unmap button appears.
Click Unmap. The system unmaps the Table Descriptor.
You can then click the Reset to Default Mapping button to automatically map columns according to column names, or remap the Table Descriptor using any of the methods described in this section; see "Mapping Table Descriptors to Table Instances".
To modify a Table Descriptor, you must also modify its source Table definition. You must check out both the Program, Load Set, Data Mart, or Business Area that contains the Table Descriptor and also check out the source Table definition. You can check out the Table definition from the Table Descriptor.
Any Table instances and Table Descriptors that are based on the original version of the source Table definition continue to reference the same version unless you choose to upgrade them to the new version; see "Upgrading Object Instances to a New Definition Version".
You can also remove a Table Descriptor and add a different one.
This section contains the following topics:
See Chapter 13, "Execution and Data Handling" for information on using Execution Setups in backchain execution and message-triggered submission.
In order to run an Oracle LSH executable objectâProgram, Load Set, Report Set, Workflow, or Data Martâyou must create at least one Execution Setup for it.
Execution Setups become the submission form for the executable object. They can be displayed in the Reports tab so that users with the appropriate privileges can submit the associated Program, Load Set, Report Set, Workflow, or Data Mart for execution.
You can also create Execution Setups to submit a job at a single future point in time, on a regularly scheduled basis, or when triggered by the receipt of an XML message from an external system. These Execution Setups are not displayed in the Reports page, but run automatically.
Execution Setups include a predefined set of system Parameters; see "System Parameters". They also include all the user-defined input and input/output Parameters defined as visible in the executable object. These Parameters are copies of the Parameters in the object and belong only to the Execution Setup. You can modify them without affecting the executable object itself. You determine whether these Parameters are visible to and settable by the person submitting the job.
More than one person can work on an Execution Setup at the same time, if they work on different Parameter Sets. For example, one person can work on a Program's Parameter settings and another person can work on system Parameters in the same Execution Setup at the same time.
You can define multiple Execution Setups for the same executable object instance. For example, you could define one Execution Setup for immediate execution, to be used to test the Program, and another Execution Setup to run at regular intervals, for use on production data. You could also define multiple Execution Setups with their Parameters bound to different values.
Copying Execution Setups You can create a copy of one or more Execution Setups for use with the same instance and then modify them as necessary.
Execution Templates If you create an Execution Setup that you think would be useful to other instances of the same executable definition, you can make it available for use as an Execution Template.
When you create an Execution Setup, you have the option of creating it from an Execution Template. If you choose this option, the system displays a list of all the Execution Setups that have been designated as Execution Templates in all instances of the same object definition version, if any. You can select one and modify it as necessary.
Forward Chaining Forward chaining is a special type of processing that executes the programs automatically that directly or indirectly uses the data in a table, whenever that table is updated. A single jobâfor example, the execution of a Load Set to load data into Oracle LSHâtriggers jobs that read from the tables the original job writes to, and then triggers the jobs that read from tables the second set of programs writes to, and so on. To be included in a forward chain, one Execution Setup for the executable must be marked as Forward Chain Enabled and, if it should trigger additional downstream forward chaining, as Cascade Enabled. In addition, the executable's Work Area, Application Area, and Domain(s) must have forward chaining enabled. See "Forward Chaining" for more information.
Backchaining Backchaining is a special type of processing in Oracle LSH where the system checks the data sources of a given executable to see if more current data exists in Oracle LSH or even in a source data system, and if so, executes all the Load Sets and Programs necessary to bring the most current data to the executable being submitted. You can define a Submission Type of Backchain for an Execution Setup so that a Program that operates on data generated by the current Program (for which you are defining the Execution Setup) can trigger the execution of the current Program as part of a backchain process. See "Backchaining" for further information.
Execution Setup Classifications An Execution Setup has its own classifications. Its classifications determine where Oracle LSH displays the submission form in the Reports tab.
In addition, if a classification level value of any of the executable's Planned Outputs is set to Inherited, the system classifies the corresponding actual output using the classification value(s) of the Execution Setup for that level. The submission form and the actual output are then located in the same folder on the Reports tab.
An Execution Setup's classification values, if inherited, are inherited from its object (Program, Load Set, Data Mart, Report Set, or Workflow) instance. The object instance's inherited classification values are inherited from the Work Area.
See "Classifying Objects and Outputs" for instructions on classifying defined objects, including Execution Setups.
Execution Setup and Output Security Execution Setups have their own user group assignments, inherited from their executable instance, which inherits its assignments from the Work Area. You can change the user group assignments if necessary; see "Applying Security to Objects and Outputs".
Execution Setup user group assignments determine two things:
The user groups' members can submit the Execution Setup to run the Program or other executable, if they have the necessary privileges within the user group.
The user groups' members can view the output of the Program or other executable, if they have the necessary privileges within the user group.
You can change an output's user group assignments after the output is generated. To do so, navigate to the output in the Reports tab or from the job ID on your Home Page and select Apply Security from the Actions drop-down.
If an output contains blinded or unblinded data, users needs special privileges to view it; see "Managing Blinded Data".)
Execution Setup Versions When you explicitly check out an Execution Setup, the system creates a new version of the Execution Setup. In addition, when you modify an Execution Setup, the system implicitly checks out the Execution Setup and gives it a new version number.
When an active Execution Setup is submitted, the system implicitly checks it in, if it is not already checked in; see "Activating a Version of an Execution Setup".
Note:
Only the user who first created or modified the Execution Setup, and thereby checked it out, can undo the checkout. You can see that person's username in the Checked Out By field.Execution Setup Upgrade An Execution Setup must be synchronized with the definition of its executable object's Parameters. You can synchronize it at any time by selecting Upgrade Execution Setup from the Actions drop-down list in the Execution Setup screen. When you submit the Execution Setup and when you install its associated executable object, the system checks if an upgrade is required and performs it. If the Execution Setup is checked in, the system implicitly checks it out, upgrades it, and checks it in.
Note:
If the executable instance is modified to point to a different object definition, the system cannot automatically upgrade the Execution Setup. You must create a new Execution Setup.The system creates an Execution Setup automatically if you click Submit directly in the Properties screen of an executable object instance and no Execution Setup currently exists. It is called Standard Execution Setup and is automatically set to be the default Execution Setup. In addition, you can create any number of Execution Setups manually as follows:
In the executable object instance for which you want to create an Execution Setup, select Execution Setup from the Actions drop-down list.
The system opens the Execution Setup screen and displays any Execution Setups that have already been defined for this executable object.
Click Create Execution Setup. The Create Execution Setup screen opens.
Select one of the following options:
When you choose to create a new Execution Setup without an Execution Template, additional fields appear.
Enter values for the following fields:
Name. Give the Execution Setup a meaningful name, including an indication of the Program or other executable it is for.
Note:
The Execution Setup's name is very important because users submitting the executable from the Reports tab see only the Execution Setup name and description and executable object type (and its version number, validation status, and creation time). The Reports tab does not display information about the executable object to be run except for the object's type. Therefore the name/description combination must be informative enough to allow users to understand what they will get when they run the Execution Setup.If you plan to make this Execution Setup available as an Execution Template, remember that definers creating new Execution Setups based on this one will see only its name, its owning executable instance, and its validation and Runnable statuses.
If there are or will be other Execution Setups for the same object, indicate what is unique about this one.
Description. Describe the Execution Setup, especially if there are multiple Execution Setups for the same executable object.
Allow Use as Execution Template. Set to Yes if you want to make this Execution Setup available as a template to other instances of the same executable definition. Set to No if you do not want the Execution Setup to be available as a template. You can change this setting only when the Execution Setup is checked in.
Select a subtype and change classifications if necessary. The output resulting from the submission of this Execution Setup may inherit its classifications from the Execution Setup; see "Classifying Outputs".
Click Apply. The system generates a default Execution Setup using the current Parameter settings and returns you to the Execution Setup screen with the Execution Setup name displayed in the Execution Setup List.
The current settings for Forward Chain Enabled and Cascade Enabled are displayed. You can change these settings by selecting the Execution Setup and clicking the appropriate button:
Forward Chain Enabled. If Yes, the Program or other executable can be triggered during a forward chain process or begin the forward chain process. Only one Execution Setup for the object can be set to Yes.
Cascade Enabled. If Yes, the Program or other executable can trigger the execution of executables that read from the tables it writes to as part of the forward chain process. Only one Execution Setup for the object can be set to Yes, and it must also have Forward Chaining Enabled set to Yes.
Notes:
Object types that do not write to tables, such as Data Marts, cannot have Cascade enabled.Even if these attributes are set to Yes, if forward chaining is not enabled for the Work Area, this object cannot be executed as part of a forward chaining process; see "Forward Chaining" for more information.
Click the Execution Setup's name in the Execution Setup column.
The system opens the Execution Setup Properties screen.
Modify as necessary. See "Modifying an Execution Setup and Setting Parameters".
Set the Execution Setup version to Active; see "Activating a Version of an Execution Setup".
When you choose to use an Execution Template, a search field appears.
Click the Search icon. The system displays all the Execution Setups available as Execution Templates that have been created for instances of the same execution object definition. For each Execution Template the system displays its Program instance name, validation status, and runnable status.
Click the icon in the Quick Select column for the Execution Template you want to use. The system returns you to the Create Execution Setup screen.
Click Apply. The system creates a new Execution Setup that is a copy of the Execution Template you selected and returns you to the Execution Setup screen with the Execution Setup name displayed in the lower portion of the screen.
Click the Execution Setup's name in the Execution Setup column.
The system opens the Execution Setup Properties screen.
Modify as necessary. See "Modifying an Execution Setup and Setting Parameters".
Set the Execution Setup version to Active; see "Activating a Version of an Execution Setup".
This section includes the following topics:
See also:
After you have generated a default Execution Setup you can modify the system Parameters and the default values of the runtime Parameters. The Parameters in the Execution Setup are copies of those in the executable object definition. Modifying them has no effect on the object definition.
To appear in the Reports tab where it is available for general use, an Execution Setup must be checked in and set to Active (see "Activating a Version of an Execution Setup"). However, from the Execution Setup definition it is possible to submit the Execution Setup even if it is checked out.
Click Update to modify the Execution Setup's Name and Description.
Note:
The Execution Setup name is very important because it is what users see in the Reports tab. The name must be descriptive enough to allow users to understand what they will get when they run the Execution Setup.Set to Yes to make this Execution Setup available for use as a template to other instances of this Program.
Set to No to make the Execution Setup unavailable as a template. This has no effect on any existing Execution Setups based on this one.
The same set of system Parameters are included in all Execution Setups. You can modify the Execution Setup to change the choices available to the person who uses the submission screen to submit a job. Each system Parameter is described below.
The standard system Parameters are described below:
To modify system Parameters, do the following:
Click the System Parameters subtab in the Execution Setup screen. The System Parameters screen opens.
Click the Update button in the System Parameters subtab.
You can modify the settings for any system Parameter as follows:
Select one of the following:
Visible. The Parameter is visible and its value is modifiable in the submission screen. This is the default value.
Read Only. The Parameter is visible but not modifiable in the submission screen.
Hidden. The Parameter is not visible or modifiable in the submission screen.
Allow. Each system Parameter has a defined list of values. Select the checkbox for each value you want to make available to the user.
Default (Optional). Set one of the allowed values as the default by clicking the radio button in the Default column next to the value. This value appears as the default value in the Submission screen.
Submission Type This system Parameter determines which submission methods this Execution Setup accepts:
Deferred. A deferred submission runs once at a future scheduled time. Either you, working in the Execution Setup definition, or a user working in the Reports tab, can schedule the job to run one time in the future.
Immediate. An immediate submission runs as soon as possible. Either you, working in the Execution Setup definition, or a user working in the Reports tab, can submit the job for immediate execution.
Scheduled. A scheduled submission runs repeatedly on a regular schedule. Either you, working in the Execution Setup definition, or a user working in the Reports tab, can schedule the job to run on a regular basis in the future.
Backchain. Backchain Execution Setups are called by another jobâone that operates on data that has been loaded or generated directly or indirectly by this Program or Load Setâthat has been submitted with the Data Currency Parameter set to Most Current Data Available. Users cannot submit a job for a backchain execution. They can, however, submit an immediate, deferred, or scheduled job that starts the backchain process. See "Backchaining" for further information.
Triggered. The Execution Setup accepts an XML message sent from an external system as the trigger for submission. For example, when Oracle Clinical batch validation has completed successfully, Oracle Clinical could send a message to trigger loading fresh data into Oracle LSH. Users cannot submit a job for a triggered execution. See "Using Message-Triggered Submission from External Systems" for further information.
Tip:
When you define an Execution Setup to accept the Triggered submission type, allow Immediate and Deferred submission as well. The XML message must specify whether the job should be executed immediately upon receipt of the message or at a scheduled time in the future.Notify on Completion This setting determines when the person who submits a job using this Execution Setup receives a notification upon completion of the job:
Job Failure. The submitter receives a Notification only if the job fails.
Never. The submitter does not receive any Notification about the status of the job.
Job Success. The submitter receives a Notification only if the job succeeds.
Job Warning. The submitter receives a Notification only if the job ends with a status of Warning.
Data Currency This system Parameter has the following allowed values:
Current Immediate Source. This is the standard setting. The system processes the most current data contained in the source Table instances (or, in the case of a Load Set, the source data system).
Most Current Available (Triggers Backchain). This setting invokes a backchaining job that reexecutes all Program and Load Set instances that directly or indirectly feed data into the source Table instances of the current executable, if they meet the following criteria:
They have a submitted Execution Setup with a Submission Type of Backchain.
Each executable instance between them and the current executable also has an Execution Setup with a Submission Type of Backchain.
Their source data is more current than their target data.
See "Backchaining" for further information.
Specify Snapshot. This setting enables the user to specify a particular labeled or timestamped snapshot of source data at a previous point in time to run the Program against. If you select Specify Snapshot, you may also want to set the following:
Default Snapshot Label. From the drop-down list, select a snapshot label. This label will appear as the default value in the submission form. The drop-down list displays all snapshot labels shared by all source Table instances.
Lock Default Snapshot Label. If set to Yes, the person submitting the Execution Setup cannot change data currency; the Data Currency subtab is Read Only. If set to No, the submitter can change data currency in the Data Currency subtab.
Execution Priority Set this value to determine the priority the system gives to the execution of this job, compared to other jobs of the same technology type. The choices are High, Normal, and Low.
Submission Mode When the target Table instances require Reload or Transactional High Throughput processing, you must specify Full or Incremental Processing. The default value is Full.
Note:
The system does not display the Incremental options for jobs that do not have Reload or Transactional High Throughput Table instances as targets.Incremental mode for Reload processing. The system processes all records, compares the primary or unique key of each record to the current records in the table, and updates or inserts records as appropriate. Incremental mode never deletes records and therefore takes less time to complete.
Full mode for Reload processing. The system does the same processing as in incremental mode and then performs the additional step of soft-deleting all records that were not reloaded. Full processing takes more time to complete but accurately reflects the state of the data in the source.
Incremental mode for Transactional High Throughput processing. The system appends data to the Table after the last record. The system hard-deletes data if the Oracle LSH Program explicitly issues a Delete statement.
Full mode for Transactional High Throughput processing. The system truncates the existing Table and loads fresh data into it. In this mode, you will lose all the Blinded data in the Table, even if you run the job with the Dummy setting for Blind Break.
You may decide to use incremental mode on jobs that are run frequently, but use full mode at regular intervals on the same jobs when you need the most accurate data.
Note:
The submission screen contains additional system Parameters that allow the user to apply a snapshot label to target Table instances or to target and source Table instances at runtime. The user must also supply the text of the label at runtime. See "Setting Submission Details and Data Currency" in the Oracle Life Sciences Data Hub User's Guide for further information.Blind Break This Parameter is relevant only when one or more source Table instances either currently or formerly contained blinded data. Special privileges are required to run a job on real, blinded, data and to see the resulting output. The values available to the Definer in the Execution Setup depend on the current Blinding Status of the source Table instances:
If none of the source Table instances has a Blinding Status, the only value available is Not Applicable. You may want to hide the Parameter (set it to Hidden) to avoid confusion.
If one or more of the source Table instances has a Blinding Status of Blinded, the values available include Real (Blind Break) and Dummy. You can make the Parameter Visible, allow both values, and make Dummy the default. Only users with Blind Break privileges on all blinded source Table instances will be able to select Real (Blind Break).
If one or more of the source Table instances has a Blinding Status of Unblinded, and none of the source Table instances has a Blinding Status of Blinded, the values available include Real (Unblinded) and Dummy. You can make the Parameter Visible, allow both values, and make Dummy the default. Only users with Unblind or Blind Break privileges on all unblinded source Table instances will be able to select Real (Unblinded).
Note:
If you set the default value to Not Applicable or Dummy, the System Parameters subtab displays the default value as No. If you set the default to Real (Blind Break) or Real (Unblinded) the System Parameters subtab displays it as Yes.For further information, see "Managing Blinded Data".
Force Execution If set to No, before running a job based on this Execution Setup, the system compares the following for the current job and for the previous time the same instance was executed and does not reexecute the job if all of the following are true:
The Program (or other executable) definition version is the same.
The Parameter values are the same.
The Source Job ID for the source Table instances is the same.
If all of the above are the same, then the same results should occur from running the job again. The system does not run the job and instead gives the user a message that it is a duplicate job. If any one of the above is different, the current job is not considered a duplicate of a past job and the system executes it.
If set to Yes, the system runs the job even if the data has not been refreshed, the Parameter settings are the same, and the Program version is the same.
Note:
In the case of a Report Set Execution Setup, the Report Set itself always executes, whether Force Execution is set to Yes or not. However, if Force Execution is set to No, the Programs in the Report Set do not run if the conditions outlined above are true. In addition, the Force Execution setting affects only Programs assigned to Report Set Entries that are selected for inclusion in the job.Timeout Value You can set a default timeout valueâthe length of time the system should continue to try to run the job after it has been submittedâby entering a number in the Default Value field and selecting a default unit of time (Minutes, Hours, Days, Weeks, Months). For example, if a report is scheduled to run once a day, a timeout period of 24 hours would prevent generating two reports for the same day. Alternatively, you can specify the allowed and default units of time without specifying a default value, and let the user set the value.
Apply Snapshot Label The available values are:
None. Users cannot apply a snapshot label to any Table instances at runtime.
Both. Users can apply a snapshot label to both source and target Table instances at runtime.
Target. Users can apply a snapshot label only to target Table instances at runtime.
Select one of these values to be the default. You can also specify a default label.
The system generates the runtime Parameters in an Execution Setup from the input and input/output Parameters, their default values and other settings, defined in the executable object instance.
In the Runtime Parameters subtab the system displays each Parameter's default value (if any) and its Required flag setting. You can change the default setting that will appear in the submission screen by entering a value in the Parameter Value column.
If you want to view or change other settings, including Visible, Read Only, Required, and the validation method, click the Parameter's hyperlink. See Chapter 6, "Defining Variables and Parameters" for further information.
Note:
If you add, remove, or modify Parameters in the executable object, when you install the object the system automatically upgrades its Execution Setups to reflect the change.Predefined Runtime Parameters Some object types have predefined runtime Parameters. In general, you should not change these Parameters in any way.
In particular, do not set values for the following Parameters in the Execution Setup:
In Oracle Load Sets, do not enter a remote location. This is a security risk. The user submitting the Load Set for execution must have his or her own remote location/connection, which requires a username and password on the external Oracle system, or proper security access to a shared connection.
In SAS and Text Load Sets, do not specify the file to be uploaded. The person submitting the Load Set for execution must enter a file name in the Server OS Filename parameter or the Data File Name parameter depending on whether Load From Server OS is Yes or No. The system uploads the file at the time that you specify it. If you specify it during Load Set or Execution Setup definition, the data in the file may be out of date by the time the user runs the Load Set.
Details about each predefined Parameter are included in the chapter about each object type: "Setting Load Set Parameters" and "Setting Data Mart Parameter Values". Also see "Setting Oracle BI Publisher Program Parameters".
This section contains the following topics:
For information on submitting a Report Set or Workflow for execution, see "Running a Job from Reports, My Home, or Applications" in the Oracle Life Sciences Data Hub User's Guide.
Report Sets and Workflows have complex structures and contain other executable objects, so their Execution Setups are more complex than other objects'.
Concurrent Editing Many people can work on a Report Set or Workflow Execution Setup at the same time. However, only one person can work on a particular object or Parameter Set at a time.
Upgrading Execution Setup Structure and Parameters The structure and Parameters of the Report Set or Workflow definition and the Execution Setup must remain synchronized. The system performs an automatic upgrade of the whole Execution Setupâsynchronizing it with both the structure and the Parameters of the Report Set or Workflowâwhen the Report Set or Workflow is installed. In addition, when a Program instance in a Report Set or Workflow is installed, the system upgrades the Report Set or Workflow's Execution Setup to synchronize with the Program's Parameters.
You can trigger synchronization manually at any time by selecting Upgrade Execution Setup from the Actions drop-down list in the Execution Setup screen.
Note:
You must install a Program instance in a Report Set for the system to reflect changes to the Program's Parameters in the Report Set's Execution Setup.Execution Setup Versioning When a Report Set or Workflow is installed or submitted, the system implicitly checks in any of its Execution Setups that are not already checked in. When any user modifies any section of the Execution Setup, the system implicitly checks out the Execution Setup and gives it a new version number.
The system also checks in the Report Set or Workflow and all its Execution Setups when the Report Set or Workflow is copied.
Whenever the system performs an implicit checkin, if other people are working on any part of the Execution Setup, the system immediately checks it out again so that they can continue their work.
This section contains information on the following sections of the screen:
Execution Setup Properties You can click Update and modify the following properties that belong to the Report Set Execution Setup as a whole:
Name of the Execution Setup.
Description of the Execution Setup.
Allow Use as Execution Template. Set to Yes to make this Execution Setup available as a template for other Execution Setups in the Report Set definition.
Instances This tab displays information a little differently for Report Set and Workflows:
Report Sets. For Report Sets, you see the Report Set structure, with Report Set Entries displayed inside their parent Report Set Entries. You can Expand All, expand a particular node, or select a Focus icon to expand a particular node and hide the rest.
Click any Report Set Entry's hyperlink to set the runtime Parameters for that Report Set Entry or its assigned Program instance.
Note:
When you submit a Report Set for execution, you can specify which Report Set Entries to execute by using the checkboxes in the Include column.Workflows. For Workflows, you see all executable objects contained in the Workflow. Click any object's hyperlink to set its runtime Parameters.
The Instances subtab displays the following information:
Full Title. For Report Sets, this column displays each Report Set Entry's concatenated full title that includes its Entry Number Prefix, Parent Number, Delimiter, Entry Number, Entry Number Suffix, and Title.
For Workflows, this column displays the name of each executable object contained in the Workflow.
Ready. If a checkmark in a green circle (the Ready icon) is displayed, all required Parameters associated with the object on that line have a value. For Parameters with a static list of values, the system checks if the value is valid. In Report Sets, the system checks all Report Set Entries that are children of the Report Set instance or Report Set Entry for which the icon is displayed; if any child Report Set Entry is not ready, the Not Ready icon is displayed for the parent as well.
If an X in a red circle (the Not Ready icon) is displayed, at least one Parameter does not have a value, or has an invalid value.
In the submission screen you can use the Refresh button to recalculate the status of all the Ready? flags at the same time, to verify that all interdependent values are valid.
Validation Status of the object on that line.
Volume Name. (Applies only to Report Sets) If the Report Set Entry begins a new volume of the Report Set, the system displays the volume name.
Program Name. (Applies only to Report Sets) If a Program instance is assigned to the Report Set Entry, the system displays its name.
Program Checked Out By. (Applies only to Report Sets) If the assigned Program instance is checked out, the system displays the username of the person who checked it out.
Planned Output Name. (Applies only to Report Sets) If a Planned Output of the assigned Program instance is assigned to the Report Set Entry, the system displays its name.
Filename Reference. (Applies only to Report Sets) If there is a Planned Output assigned, the system displays its filename.
Parameters See "Creating Parameters for Sharing Values within the Report Set".
Overlay Template Parameters (Applies only to Report Sets) See "Setting Overlay Template Parameter Values" for information about each Parameter.
Note:
Overlay Template Parameters are displayed in the Execution Setup but not in the submission form.Post-Processing Parameters (Applies only to Report Sets) See "Setting Post-Processing Parameter Values" for information about each Parameter.
System Parameters The system displays the current values for the Execution Setup's System Parameters; see "System Parameters" for information about each Parameter.
You can remove an Execution Setup if you have delete privileges on Execution Setups of the relevant subtype and also Modify privileges on the parent object's subtype.
To remove an Execution Setup, do the following:
In the Applications tab, go to the object instance that contains the Execution Setup you want to remove.
Check out the object instance.
Select Execution Setup from the Actions drop-down list.
Click Go. The system opens the Execution Setup screen.
Select the Execution Setup you want to remove.
Click Remove. The system removes the Execution Setup.
Only one version of an Execution Setup can appear in the Reports tab for submission at any one time. Typically, it is the most recent version. However, you can select a different version if you want to. Whichever version you want to use, you must explicitly activate it or it does not appear in the Reports tab.
In the Applications tab, go to the object instance that contains the Execution Setup you want to activate.
Select Execution Setup from the Actions drop-down list.
Click Go. The system opens the Execution Setup screen.
Click the link to the Execution Setup. The system opens the Execution Setup's Properties screen.
From the Actions drop-down list, select View Version History.
Click Go. The system opens the Execution Setup Version History screen with the status of each version of the Execution Setup displayed in the Status column.
Select the version you want to be available for execution in the Reports tab and click Set As Active. The system changes the status of that version to Runnable Active. See "Execution Setup Statuses".
Note:
You must also check in the Execution Setup on its Properties screen or it does not appear in the Reports tab.Execution Setup Statuses To see an Execution Setup's status, select View Version History from the Actions drop-down list. Execution Setups can have the following statuses:
Not Runnable. An Execution Setup can be Not Runnable for the following reasons:
Its containing executable object instance has never been installed. To make the Execution Setup runnable, install the object instance.
Since the executable object instance was installed, one or more Parameters have been modified. To make the Execution Setup runnable, select Upgrade Execution Setup from the Actions drop-down list in the Execution Setup screen.
Changes have been made to the executable object instance (or its source definition) that are incompatible with the Execution Setup and that the system cannot automatically upgrade; for example, the executable instance now points to a different object definition. In this case, you cannot make the Execution Setup runnable. You must create a new Execution Setup.
Installable. The containing executable object instance has been installed, then modified and checked in but not yet reinstalled. To make the Execution Setup runnable, install the instance. The system automatically upgrades the Execution Setup and changes its status to Runnable (unless the system cannot upgrade it, in which case its status changes to Not Runnable).
Runnable. The Execution Setup is in synch with its containing executable object instance but has not been set to Active. To make the Execution Setup runnable, set it to Active.
Runnable Active. The Execution Setup is in synch with its containing executable object instance and has been set to Active. It appears in the Reports tab. (Only one version of an Execution Setup can be set to Active.)
When you have created an Execution Setup, you can submit it to execute the Program, Load Set, Report Set, Workflow, or Data Mart, by clicking Submit in the Execution Setups screen or in the Reports tab.
You can then set any Parameters defined as Visible and not Read Only and schedule the job if the Execution Setup definition allows it. Instructions are included in "Generating Reports and Running Other Jobs" in the Oracle Life Sciences Data Hub User's Guide.
You can see the job's progress and details in the Jobs subtab of the object's Properties screen or the Job Execution section of your My Home screen. Click the Job ID to open the Job Details screen. Instructions for using the My Home screen are included in "Viewing Reports and Other Outputs" in the Oracle Life Sciences Data Hub User's Guide. You can also resubmit the Execution Setup from here.
If the job results in an output, you can see the output from the Job Details screen. If the output is classified, you can also see it in the Reports tab. Instructions for browsing and searching in the Reports tab are in "Viewing Reports and Other Outputs" in the Oracle Life Sciences Data Hub User's Guide.
This section contains the following topics:
This section contains the following topics:
You can view a Table instance's data only if:
The latest version of the Table instance is installed.
You have Read Data privileges for the Table instance.
For a blinded Table instance, you have blinding-related security privileges.
Note:
In a Work Area you can see whether or not a Table instance contains data. If the value in the Has Data column for the Table instance is Yes, it contains data; if it is No, it does not contain data.You can also see the latest and the installed Table instance version numbers in the Work Area's Properties screen.
Navigation You can access the Browse Data feature in the following ways:
Work Area's Properties screen. Click the icon in the Browse Data column. The icon is enabled only for Table instances whose latest version is installed.
Table instance's Properties screen. Select Browse Data from the Actions drop-down list.
Data Currency By default you see the current data.
You can select a timestamp from the Data Currency drop-down list to view data which is not current. The Data Currency drop-down list contains timestamps only if you have loaded data into the Table instance multiple times. You can see the Table instance's snapshot labels, if any, in parentheses next to the timestamp in the Data Currency drop-down list.
For blinded Table instances, the Data Currency drop-down list contains different sets of timestamps for dummy and real data. You can see the real data timestamps if you select Real from the Blind Break option in the Customize screen. See "Customizing Data Browsing". You need the necessary privileges to use this feature.
Blinding For Table instances that support blinding, the following rules apply:
If the table contains blinded data, the system displays dummy data by default.
If the table contains unblinded data and you have the required privileges, the system displays real data by default. If you do not have the privileges required to see unblinded data, the system displays dummy data.
If the table does not support blinding, the system always displays real data.
If you do not want to see all the Table Columns, or if you have the required privileges and want to see blinded data, then click the Customize button on the Browse Data screen.
You can customize the display through the following options:
Columns. When you click the Customize button for the first time, you can see the Table's Column names in an area titled Included Columns. Another area titled Available Columns contains no Column names. This is because by default, all Columns are selected for viewing.
You can remove one or more Columns from view and also reorder them. After reordering, the Column on the top in the Included Columns area in the Customize Data Browse screen appears on the left in the Browse Data screen, and so on.
Do the following:
To remove Columns from view. Select the Column or Columns you want to remove from view and move them into the Available Columns area of the shuttle. You can use Shift+Click or Ctrl+Click to select multiple Columns. You can double-click to move them or use the arrows.
To reorder columns. Use the Up and Down arrows to reorder the Columns in the Included Columns area.
Click Apply.
You can now see the Columns you selected, in the order you selected.
Where Clause. You can use the Filter Table instance where feature to restrict the data you see. To set up a Where filter,
Select either of the conditions to associate with a Table instance Column.
Show results when ALL results are met
Show results when ANY results are met
Select a Column from the drop-down list in the Column field. All available Columns are listed according to their position.
Select a filter condition from the drop-down list. The available conditions depend on the type of data in the particular Column.
Enter a value to filter by and select Apply. If the data type is VARCHAR 2, you can select the Match Case checkbox to filter values by case.
You can add different filter conditions to the same Column or view a combination of different Columns and conditions.
To include more Columns, select a Column from the drop-down list in the Add Another section and select Add. You can then apply filter conditions to the second Column. Similarly, use the Remove button to remove a Column and its filter conditions.
For example, for a Demography table with Columns Age, Sex and Race, you can set up the following Where filters:
To retrieve data about patients who are over 50 years old, select:
ColumnâAge, ConditionâGreater than, Valueâ50
To see data about female patients who are older than 50 years, select:
ColumnâAge, ConditionâGreater than, Valueâ50. Add another Column and select:
ColumnâSex, ConditionâIs, ValueâFemale
To see records for patients of all races except white, select:
ColumnâRace, ConditionâIs not, ValueâWhite
Order By Clause. You can organize the data retrieved in any order using the Order Table Instance by feature. You can specify an ascending or descending order for the Column's values. By default, the system displays records by sorting the values from the Column with an order number of 1 in ascending alphabetical or numerical order, depending on the Column's data type.
To order a Table instance:
Select a Column from the drop-down list in the Column field. Columns are listed according to their position in ascending order. Once selected, a Column does not appear in the list.
Select either Ascending or Descending from the drop-down condition list. Data is sorted in ascending order by default.
Select Apply.
You can add more Columns to order and view by using the choice list in the Add Another section, and selecting the Add button.
Use the Remove button to remove a column from the Table instance display.
For example, for a Demography table with Columns Age, Race, and Sex:
To sort data by Age, select:
ColumnâAge
To sort data by Race, select:
ColumnâRace
To sort data in descending order of Age, and then ascending order of Sex, select:
ColumnâAge, ConditionâDescending. Add another column and select:
Column âSex
Tip:
You can find more information on SQL in these books:Oracle® DatabaseSQL Language Reference at http://download.oracle.com/docs/cd/E11882_01/server.112/e17118.pdf
Oracle® Database PL/SQL Language Reference at http://download.oracle.com/docs/cd/E11882_01/appdev.112/e17126.pdf
Oracle® Database Reference at http://download.oracle.com/docs/cd/E11882_01/server.112/e17110.pdf
Blind Break The options you see in the Blind Break drop-down list depend on the state of the Table instance and on your privileges:
Currently Blinded Table Instance. If the table contains blinded data, you may see the following options:
Dummy. The system displays dummy data, not the real, sensitive data. This is the default behavior.
Real (Blind Break). The system breaks the blind to show you the real, sensitive data. This option is available only if you have the necessary blinding-related privileges. The Table instance remains blinded.
Unblinded Table Instance. If the table has been unblinded, you may see the following options:
Real (Unblinded). The system displays the real, sensitive data that has been unblinded (made available to everyone with Read Unblind privileges). This option is available only if you have the necessary privileges. This is the default behavior for people with those privileges.
Dummy. The system displays dummy data, not the real, sensitive data. This is the default behavior for people who do not have Read Unblind privileges.
Table Instance without Blinding. If the table does not support blinding (its Blinding Flag is set to No), the system always displays real data; the Table instance does not contain dummy data. The only option in the Blind Break drop-down list is Not Applicable.
After you have defined Business Areas (see Chapter 11, "Defining Business Areas for Visualizations") you can create instantaneous on-screen visualizations of the data specified in the Business Area.
You can define a Program to display data in a report and run it at any time to see current data. See Chapter 5, "Defining Programs" and "Creating, Modifying, and Submitting Execution Setups".
After you have installed a Work Area and loaded data into it (or, in the case of Oracle data, created a view of data stored in an external system) you can use one of the integrated development environments (IDEs) to view data in Oracle LSH. To do this, you must set up a Program for this purpose:
Create a Program, including:
Source Table Descriptors mapped to the Table instances whose data you want to view.
A Source Code object. You do not need to upload any actual source code files.
Check in and install both the Program and the Table instances.
Check out the Program definition.
In the Program instance, launch the IDE.
Query the data as necessary.
For further information, see Chapter 5, "Defining Programs".
You can see a record of each submission of an executable object instance from the Jobs subtab on its Properties screen. The Jobs subtab shows jobs submitted by all users for all versions of the object instance.
You can set the Show filter to:
All. Displays all submissions of the object instance.
Deferred. Displays all submissions generated by Execution Setups with a single deferred execution.
Scheduled. Displays all submissions generated by Execution Setups with an execution schedule.
Today's. Displays all jobs with a Start TS of sysdate (the system ignores the time).
For each job, the system displays the following information. You can sort on any column by clicking the column header.
Job ID. Click the hyperlink to see Job Execution Details. (Job execution details are explained in the My Home section of the Oracle Life Sciences Data Hub User's Guide chapter on tracking job execution.)
Submission Type. The way the job was submitted for execution:
Immediate. The job was run as soon as it was submitted.
Deferred. The job was set up to run once at a later point in time from when it was submitted.
Scheduled. The job was one of series of regularly sch
eduled executions of the same executable object.
Backchain. The job was run as part of a backchain process ensuring that another job ran on the most current data available. For further information see "Backchaining".
Job Status. The highest job status the job has achieved. If the job is in progress, the status displayed is the current status. If the job has ended in failure or been aborted, the system displays the execution status the job had at the time it ended. For an explanation of job statuses, see the Oracle Life Sciences Data Hub User's Guide chapter on job execution.
Note:
To update the job status as the system processes the job, click Refresh.User Name. The name of the user who submitted the job.
Instance Version. The version number of the object instance at the time of submission.
Execution Setup Name. The name of the Execution Setup used for submission.
Submit TS. The submission timestamp.
Start TS. The timestamp of the time the job started.
End TS. The timestamp of the time the job ended.
You can view all existing outputs of executable objects several ways:
You can see all outputs of a particular executable object instance from its Work Area; see "View All Outputs" for information.
You can also see outputs from the My Home and Reports tabs by clicking the Job ID. For further information, see "Viewing Reports and Other Outputs" in the Oracle Life Sciences Data Hub User's Guide.
In addition to the preceding options, you can view all outputs of a Program or Report Set as follows:
To view existing outputs for a Program, do the following:
Navigate to a Program definition or instance.
In the Planned Output subtab, click the name of the Planned Output whose actually outputs you want to see. The selected Planned Output's Properties screen opens.
From the Actions drop-down list, select View Existing Output. The View Existing Outputs screen opens, listing all existing outputs.
Note:
The system displays existing outputs for all instances of the Program definition, even if you are in the Program instance's Properties screen. You can click on the Program Instance Name column heading to sort by Program instance.Click the icon in the View column to open the actual output file.
To view existing outputs for a Report Set, do the following:
Navigate to a Report Set or Report Set instance Structure view screen.
Select the Report Set top level or the Report Set Entry whose outputs you want to see.
From the Select Object and: drop-down, select View All Outputs and click Go. The View Existing Outputs screen opens, listing all existing outputs.
Click the icon in the View column to open the actual output file.
For each Program, Report Set, or Report Set Entry output, the View Existing Outputs screen displays the following information:
File Name. Click the hyperlink to see the output's properties.
Output Validation Status
Creation TS (timestamp)
Creation User (the username of the person who ran the Program instance that generated the output)
Job ID. Click the hyperlink to see the job execution details.
Program Instance Name
Program Instance Version
Path to Executable Instance (the location of the Program or Report Set instance)
Title
You can use the Actions drop-down list to modify an object's classifications, security user group assignments, validation status, and more.
Actions apply only to the object definition or the instance, not both. If you are in a Work Area, you are working on an object instance and the action applies only to the instance. To apply them to the definition, you must work in the definition directly in its Domain or Application Area.
Not all actions are available for both object definitions and instances. Also, not all actions change the object definition or instance; some actions only display specific information about the object definition or instance.
You do not need to click either Update or Check Out.
The following choices are available. Unless otherwise noted, they are available for both the definition (in its Domain or Application Area only) and the instance (in its Work Area) if you have the necessary privileges.
Assign Classification. You can change the classification values assigned to the object. Classification values help users find the object using Advanced Search and in the case of instances, may affect the classification of the object's outputs. See "Classifying Objects and Outputs" for further information.
Apply Security. Objects automatically inherit the user group assignments of their parent. You can remove those assignments and add others as necessary. See "Applying Security to Objects and Outputs" for further information.
Automatic Mapping by Name (executable instances only). Map Table Descriptors to Table instances with the same name. See "Automatic Mapping by Name" for further information.
Execution Setups (executable instances only). See "Creating, Modifying, and Submitting Execution Setups" for further information.
Reports. You can generate reports that provide information about Table definitions and instances; see Chapter 14, "System Reports" for further information.
Support Validation Info. You can change the instance's validation status and add outputs and documents as supporting information. See "Validating Objects and Outputs" for further information.
Table Descriptors from Existing Table Instances (executable instances only). Create Table Descriptors from existing Table instances and map them at the same time. See "Creating Table Descriptors from Table Instances and Simultaneously Mapping Them" for further information.
Table Instances from Existing Table Descriptors (executable instances only). Create Table instances from existing Table Descriptors and map them at the same time. See "Creating Table Instances from Table Descriptors and Simultaneously Mapping Them" for further information.
Upgrade All Instances From the definition, you can upgrade any or all instances of the definition to the latest version of the definition. See "Upgrading One or More Instances from the Definition" for further information.
Upgrade Instance (instances only). See "Upgrading Object Instances to a New Definition Version" for further information.
Version Label. You can apply a label to the current version of the object definition or instance. See "Version Labels" for further information.
View All Outputs. (Program definitions and instances only) Use this option to see all outputs generated by a particular Program definition or instance; see "Viewing All Outputs of a Program or Report Set" for further information.
View Version History Use this option to see all previous versions of the definition. See "Version History" for further information.
|
Copyright © 2006, 2014, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|