| Oracle® Big Data Applianceオーナーズ・ガイド リリース2 (2.5) E53258-01 |
|


 前 |
 次 |
この章では、Oracle Big Data Applianceを監視および管理する方法について説明します。一部の手順では、dcliユーティリティを使用してすべてのサーバーでパラレルにコマンドを実行します。
この章の内容は次のとおりです。
環境温度の状態をサーバーの設計仕様の範囲内に維持することは、最大限の効率性および目的のコンポーネント・サービスの存続期間を実現するために役立ちます。摂氏21から23度(華氏70から74度)の気温範囲を逸脱する温度は、Oracle Big Data Appliance内のすべてのコンポーネントに影響し、パフォーマンス上の問題の原因となり、サービスの存続期間が短縮される可能性があります。
周辺温度を監視するには、次の手順を実行します。
Oracle Big Data Applianceサーバーにrootとして接続します。
「パスワードなしSSHの設定」の説明に従ってsetup-root-sshコマンドを入力し、rootのパスワードなしSSHを設定します。
現在の温度を確認します。
dcli 'ipmitool sunoem cli "show /SYS/T_AMB" | grep value'
示されている温度が稼働範囲を逸脱している場合、調査して問題を修正します。表2-11を参照してください。
次に、コマンド出力の例を示します。
bda1node01-adm.example.com: value = 22.000 degree C
bda1node02-adm.example.com: value = 22.000 degree C
bda1node03-adm.example.com: value = 22.000 degree C
bda1node04-adm.example.com: value = 23.000 degree C
.
.
.
この項で説明する項目は、次のとおりです。
この項には、規則的な方法でOracle Big Data Applianceのコンポーネントの電源を投入および切断する手順が含まれます。
|
関連項目: ソフトウェアをインストールして実行するときに正常に電源を投入および切断する方法については、『Oracle Big Data Applianceソフトウェア・ユーザーズ・ガイド』を参照してください。 |
Oracle Big Data Applianceの電源を投入するには、次の手順を実行します。
2つのPDUの12のブレーカすべてをオンにします。
Oracle ILOMおよびLinuxオペレーティング・システムが自動的に起動します。
Oracle Big Data Applianceの電源を切断するには、次の手順を実行します。
サーバーの電源を切断します。
2つのPDUの12のブレーカすべてをオフにします。
Linuxのshutdownコマンドを使用して、サーバーの電源を切断するか、再起動します。rootとして次のコマンドを入力し、サーバーを即座に停止します。
# shutdown -hP now
次のコマンドでは、サーバーを即座に再起動します。
# shutdown -r now
|
関連項目: 詳細は、LinuxのSHUTDOWNのマニュアル・ページを参照してください。 |
dcliユーティリティを使用して、同時に複数のサーバーでshutdownコマンドを実行します。停止するサーバーからdcliユーティリティを実行しないでください。「パスワードなしSSHの設定」の説明に従って、rootのパスワードなしSSHを設定します。
次のコマンドで、コマンドの構文を示します。
# dcli -l root -g group_name shutdown -hP now
このコマンドで、group_nameは、サーバーのリストを含むファイルです。
次の例では、server_groupファイルにリストされているすべてのOracle Big Data Applianceサーバーを停止します。
# dcli -l root -g server_group shutdown -hP now
ネットワーク・スイッチには電源スイッチがありません。データ・センターのPDUまたはブレーカをオフにして電源を解除すると、電源が切断されます。
緊急時には、Oracle Big Data Applianceへの電源供給を即座に停止してください。次の緊急時には、状況に応じてOracle Big Data Applianceの電源を切断する必要があります。
地震、洪水、台風、竜巻、つむじ風などの自然災害
システムから発する異常な雑音、臭気または煙
人体の安全に対する脅威
Oracle Big Data Applianceには次の注意および警告が適用されます。
|
警告: 高圧電力を使用するこの製品の部品に触れないでください。それらに触れると、重傷を負う可能性があります。 |
|
注意:
|
メモリーは、クラスタ内のすべてのノードに追加するか、追加メモリーを必要とするNameNodeなどの特定のノードに追加できます。
Oracle Big Data Appliance X4-2およびX3-2の各サーバーには、工場出荷時に64GBのメモリーが搭載されています。16枚実装のDIMMスロットの8つに、8GBのDIMMが挿入されています。
これらのアプライアンスは、8 GB、16 GB、32 GBのDIMMをサポートしています。1つのサーバーのメモリー量は、最大512GB (16 x 32GB)に拡張できます。
DIMMのサイズは混在できますが、サイズの大きいものから小さいものの順に取り付ける必要があります。対称性を保つことによって、最もよいパフォーマンスを得られます。たとえば、同じサイズのDIMMを4枚(メモリー・チャネルごとに1枚)各プロセッサに追加し、両方のプロセッサで同じサイズのDIMMが同じ順序で取り付けられていることを確認します。
Sun Server X4-2LまたはSun Server X3-2Lにメモリーを追加するには、次の手順を実行します。
DIMMのサイズを混在させる場合、次の場所にあるSun Server X3-2Lサービス・マニュアルのDIMMの配置規則の項を参照してください。
http://docs.oracle.com/cd/E23393_01/html/E27229/ceiehcdb.html#scrolltoc
サーバーの電源を切断します。
新しいDIMMを取り付けます。16GBまたは32GBのDIMMを取り付ける場合、まず既存の8GB DIMMと交換し、次にプラスチック・フィラーと交換します。サイズが最も大きいDIMMから順に取り付けます。元の8GB DIMMは最後に再取り付けできます。
次の場所にあるSun Server X3-2Lサービス・マニュアルを参照してください。
http://docs.oracle.com/cd/E23393_01/html/E27229/ceicjagi.html#scrolltoc
サーバーの電源を投入します。
Oracle Big Data Applianceの各サーバーには、工場出荷時に48GBのメモリーが搭載されています。18枚実装のDIMMスロットの6つに、8GBのDIMMが挿入されています。空のスロットに8GBのDIMMを挿入して、合計メモリーを96GB (12 x 8GB)または144GB (18 x 8GB)にすることが可能です。144GBにアップグレードすると、メモリー帯域幅が縮小するために多少パフォーマンスが低下する可能性があります(メモリーの動作周波数は1333MHzから800MHzに落ちます)。
Sun Fire X4270 M2サーバーにメモリーを追加するには、次の手順を実行します。
サーバーの電源を切断します。
プラスチック・フィラーをDIMMに交換します。次の場所にあるSun Fire X4270 M2サーバー・サービス・マニュアルを参照してください。
http://docs.oracle.com/cd/E19245-01/E21671/motherboard.html#50503715_71311
サーバーの電源を投入します。
物理ディスクの修理では、Oracle Big Data Applianceを停止する必要はありません。ただし、個々のサーバーは一時的にクラスタの外部に取り出すことがあり、停止時間が必要です。
各Oracle Big Data Applianceサーバーの12のディスク・ドライブは、LSI MegaRAID SAS 92610-8iディスク・コントローラによって制御されます。パフォーマンス低下の可能性や機能停止を避けるため、RAIDデバイスのステータスを確認することをお薦めします。RAIDデバイスを検証することによるサーバーに対する影響は、ごくわずかです。修正作業はサーバーの操作に影響する可能性があり、その範囲は、検出された特定の問題に応じて単純な再構成から機能停止にまで及びます。
ディスク・コントローラ構成を確認するには、次のコマンドを入力します。
# MegaCli64 -AdpAllInfo -a0 | grep "Device Present" -A 8
次に、コマンドからの出力例を示します。通常は、12の仮想ドライブがあり、縮退ドライブやオフライン・ドライブはなく、14の物理デバイスがあります。14のデバイスは、コントローラと12のディスク・ドライブです。
Device Present
================
Virtual Drives : 12
Degraded : 0
Offline : 0
Physical Devices : 14
Disks : 12
Critical Disks : 0
Failed Disks : 0
出力が異なる場合、調査して問題を修正してください。
# MegaCli64 -LDInfo -lAll -a0
次に、仮想ドライブ0に関する出力例を示します。StateがOptimalであることを確認してください。
Adapter 0 -- Virtual Drive Information: Virtual Drive: 0 (Target Id: 0) Name : RAID Level : Primary-0, Secondary-0, RAID Level Qualifier-0 Size : 1.817 TB Parity Size : 0 State : Optimal Strip Size : 64 KB Number Of Drives : 1 Span Depth : 1 Default Cache Policy: WriteBack, ReadAheadNone, Cached, No Write Cache if Bad BBU Current Cache Policy: WriteBack, ReadAheadNone, Cached, No Write Cache if Bad BBU Access Policy : Read/Write Disk Cache Policy : Disk's Default Encryption Type : None
# MegaCli64 -PDList -a0 | grep Firmware
次に、コマンドからの出力例を示します。通常、12のドライブに、Online, Spun Upが表示されます。出力が異なる場合、調査して問題を修正してください。
Firmware state: Online, Spun Up
Device Firmware Level: 061A
Firmware state: Online, Spun Up
Device Firmware Level: 061A
Firmware state: Online, Spun Up
Device Firmware Level: 061A
.
.
.
ディスクの障害がOracle Big Data Applianceにとって致命的になることはありません。ユーザー・データは何も失われません。HDFSまたはOracle NoSQL Databaseに格納されているデータは、自動的にレプリケートされます。
この項で説明する項目は、次のとおりです。
|
関連項目: My Oracle SupportドキュメントID 1581331.1 |
次に、サーバー・ディスク・ドライブを交換するための基本手順を示します。
障害ディスク・ドライブを交換します。
新しいディスクの基本構成手順を実行します。
障害ディスクの固有の機能がオペレーティング・システム・ディスク、HDFSディスクまたはOracle NoSQL Databaseディスクのいずれであるかを識別します。
ディスクをその固有の機能用に構成します。
構成が正しいことを確認します。
Oracle Big Data Applianceソフトウェアをインストールします。
|
関連項目: 次の場所にあるSun Server X3-2Lサービス・マニュアルのストレージ・ドライブおよびリア・ドライブの修理に関する項
次の場所にあるSun Fire X4270 M2 Serverサービス・マニュアルのストレージ・ドライブおよびブート・ドライブの修理に関する項を参照してください。
|
Oracle Big Data Applianceサーバーには、ホスト・バス・アダプタ(HBA)によって制御されるディスク・エンクロージャ・ケージが含まれます。エンクロージャには、スロット番号0から11で識別される12のディスク・ドライブがあります。ドライブは、表11-1に示すような固有の機能専用にすることができます。
Oracle Big Data Applianceでは、ディスクのスロット番号を識別するために、/dev/disk/by_hba_slotで定義されるシンボリック・リンクを使用します。リンクの形式は、snpmであり、nはスロット番号、mはパーティション番号です。たとえば、/dev/disk/by_hba_slot/s0p1は初期状態で/dev/sda1に対応します。
ディスクがホット・スワップされる場合、オペレーティング・システムでは、カーネル・デバイス名を再利用できません。かわりに、新しいデバイス名が割り当てられます。たとえば、/dev/sdaをホット・スワップすると、/dev/disk/by-hba-slot/s0に対応するディスクは、/dev/sdaのかわりに/dev/sdnにリンクされます。したがって、/dev/disk/by-hba-slot/のリンクは、デバイスの追加または削除時に自動的に更新されます。
コマンド出力では、デバイス名がシンボリック・リンク名ではなくカーネル・デバイス名でリストされます。つまり、/dev/disk/by-hba-slot/s0は、コマンド出力では/dev/sdaとして識別される場合があります。
表11-1に、RAID論理ドライブとオペレーティング・システム識別子との間の通常の初期マッピングを示します。ただし、システムに存在するマッピング(ここにリストしたものとは異なる可能性があります)を使用する必要があります。表には、Oracle Big Data Applianceサーバーの各ドライブの専用機能も示します。障害ドライブのあるサーバーは、CDHクラスタ(HDFS)またはOracle NoSQL Databaseクラスタの一部です。
表11-1 ディスク・ドライブ識別子
| 物理スロットに対するシンボリック・リンク | 一般的な初期カーネル・デバイス名 | 固有の機能 |
|---|---|---|
|
/dev/disk/by-hba-slot/s0 |
/dev/sda |
オペレーティング・システム |
|
/dev/disk/by-hba-slot/s1 |
/dev/sdb |
オペレーティング・システム |
|
/dev/disk/by-hba-slot/s2 |
/dev/sdc |
HDFSまたはOracle NoSQL Database |
|
/dev/disk/by-hba-slot/s3 |
/dev/sdd |
HDFSまたはOracle NoSQL Database |
|
/dev/disk/by-hba-slot/s4 |
/dev/sde |
HDFSまたはOracle NoSQL Database |
|
/dev/disk/by-hba-slot/s5 |
/dev/sdf |
HDFSまたはOracle NoSQL Database |
|
/dev/disk/by-hba-slot/s6 |
/dev/sdg |
HDFSまたはOracle NoSQL Database |
|
/dev/disk/by-hba-slot/s7 |
/dev/sdh |
HDFSまたはOracle NoSQL Database |
|
/dev/disk/by-hba-slot/s8 |
/dev/sdi |
HDFSまたはOracle NoSQL Database |
|
/dev/disk/by-hba-slot/s9 |
/dev/sdj |
HDFSまたはOracle NoSQL Database |
|
/dev/disk/by-hba-slot/s10 |
/dev/sdk |
HDFSまたはOracle NoSQL Database |
|
/dev/disk/by-hba-slot/s11 |
/dev/sdl |
HDFSまたはOracle NoSQL Database |
表11-2に、HDFSパーティションとマウント・ポイントとの間のマッピングを示します。
表11-2 マウント・ポイント
| 物理スロットおよびパーティションに対するシンボリック・リンク | HDFSパーティション | マウント・ポイント |
|---|---|---|
|
/dev/disk/by-hba-slot/s0p4 |
/dev/sda4 |
/u01 |
|
/dev/disk/by-hba-slot/s1p4 |
/dev/sdb4 |
/u02 |
|
/dev/disk/by-hba-slot/s2p1 |
/dev/sdc1 |
/u03 |
|
/dev/disk/by-hba-slot/s3p1 |
/dev/sdd1 |
/u04 |
|
/dev/disk/by-hba-slot/s4p1 |
/dev/sde1 |
/u05 |
|
/dev/disk/by-hba-slot/s5p1 |
/dev/sdf1 |
/u06 |
|
/dev/disk/by-hba-slot/s6p1 |
/dev/sdg1 |
/u07 |
|
/dev/disk/by-hba-slot/s7p1 |
/dev/sdh1 |
/u08 |
|
/dev/disk/by-hba-slot/s8p1 |
/dev/sdi1 |
/u09 |
|
/dev/disk/by-hba-slot/s9p1 |
/dev/sdj1 |
/u10 |
|
/dev/disk/by-hba-slot/s10p1 |
/dev/sdk1 |
/u11 |
|
/dev/disk/by-hba-slot/s11p1 |
/dev/sdl1 |
/u12 |
次のMegaCli64コマンドを使用して、仮想ドライブ番号と物理スロット番号のマッピングを確認します。「ディスク・ドライブの交換」を参照してください。
# MegaCli64 LdPdInfo a0 | more
作業または障害HDFSディスクまたはオペレーティング・システム・ディスクを交換する予定の場合、最初にHDFSパーティションをディスマウントする必要があります。オペレーティング・システム・ディスクを交換する前には、スワッピングを無効にする必要もあります。
|
注意: HDFSパーティションのみをディスマウントしてください。オペレーティング・システム・ディスクの場合、オペレーティング・システム・パーティションをディスマウントしないでください。HDFSには、オペレーティング・システム・ディスクのパーティション4 (sda4またはsdb4)のみを使用します。 |
HDFSパーティションをディスマウントするには、次の手順を実行します。
障害ドライブのあるサーバーにログインします。
障害ドライブがオペレーティング・システムをサポートしている場合、スワッピングを無効にします。
# bdaswapoff
アクティブなスワッピングが存在するディスクを削除すると、カーネルがクラッシュします。
マウントされているHDFSパーティションをリストします。
# mount -l
/dev/md2 on / type ext3 (rw,noatime)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
/dev/md0 on /boot type ext3 (rw)
tmpfs on /dev/shm type tmpfs (rw)
/dev/sda4 on /u01 type ext4 (rw,nodev,noatime) [/u01]
/dev/sdb4 on /u02 type ext4 (rw,nodev,noatime) [/u02]
/dev/sdc1 on /u03 type ext4 (rw,nodev,noatime) [/u03]
/dev/sdd1 on /u04 type ext4 (rw,nodev,noatime) [/u04]
.
.
.
障害ディスクでマウントされているパーティションのリストを確認します。ディスクのパーティションがリストされていない場合、「ディスク・ドライブの交換」に進みます。そうではない場合、次の手順に進みます。
|
注意: オペレーティング・システム・ディスクの場合、パーティション4 (sda4またはsdb4)を見つけます。オペレーティング・システム・パーティションはディスマウントしないでください。 |
障害ディスクのHDFSマウント・ポイントをディスマウントします。
# umount mountpoint
たとえば、umount /u11によって、パーティション/dev/sdk1のマウント・ポイントが削除されます。
umountコマンドに成功した場合、「ディスク・ドライブの交換」に進みます。デバイスがビジーであるというメッセージとともにumountコマンドに失敗した場合、パーティションはまだ使用中です。次の手順に進みます。
Cloudera Managerのブラウザ・ウィンドウを開きます。次に例を示します。
http://bda1node03.example.com:7180
Cloudera Managerで次の手順を実行します。
adminとしてログインします。
「Services」ページで、「hdfs」をクリックします。
「Instances」サブタブをクリックします。
「Host」列で、障害ディスクのあるサーバーを特定します。次に、「Name」列のサービス(datanodeなど)をクリックしてそのページを開きます。
「Configuration」サブタブをクリックします。
「Directory」フィールドからマウント・ポイントを削除します。
「Save Changes」をクリックします。
「Actions」リストから、「Restart this DataNode」を選択します。
|
注意: Cloudera Managerでマウント・ポイントを削除した場合、他のすべての構成手順が終了した後に、Cloudera Managerでマウント・ポイントをリストアする必要があります。 |
障害ドライブのあるサーバーのセッションに戻ります。
umountコマンドを再発行します。
# umount mountpoint
ディスクをオフラインにします。
# MegaCli64 PDoffline "physdrv[enclosure:slot]" a0
たとえば、"physdrv[20:10]"はディスクs11を示します。これは、エンクロージャ20のスロット10にあります。
コントローラ構成表からディスクを削除します。
MegaCli64 CfgLDDel Lslot a0
たとえば、L10はスロット10を示します。
「ディスク・ドライブの交換」の手順を完了します。
サーバーは、ディスク交換手順の最中に、ユーザーがrebootコマンドを発行したため、またはMegaCli64コマンドでエラーが発生したために再起動することがあります。ほとんどの場合、サーバーは正常に再起動し、作業を継続できます。ただし、それ以外の場合、エラーが発生するためにSSHを使用して再接続できなくなります。この場合、Oracle ILOMを使用して再起動を完了する必要があります。
Oracle ILOMを使用してサーバーを再起動するには、次の手順を実行します。
ブラウザで、Oracle ILOMを使用してサーバーに対する接続を開きます。次に例を示します。
http://bda1node12-c.example.com
|
注意: ブラウザには、JDKプラグインがインストールされている必要があります。ログイン・ページにJavaのコーヒー・カップが表示されない場合、作業を続行する前にプラグインをインストールする必要があります。 |
Oracle ILOM資格証明を使用してログインします。
「Remote Control」タブを選択します。
「Launch Remote Console」ボタンをクリックします。
[Ctrl]を押しながら[D]を押し、再起動を続行します。
再起動に失敗した場合、プロンプトでサーバーのrootパスワードを入力し、問題の修正を試みます。
サーバーが正常に再起動したら、「Redirection」メニューを開いて「Quit」を選択し、コンソール・ウィンドウを閉じます。
作業ディスクまたは障害ディスクを交換する前に、「作業ディスクまたは障害ディスクを交換するための前提条件」を参照してください。
障害ディスク・ドライブを交換します。
「Oracle Big Data Applianceサーバーの部品」を参照してください。
障害ディスクを交換するためにサーバーの電源を切断した場合、電源を投入します。
KVMまたはラップトップとのSSL接続を使用して、rootとしてサーバーに接続します。
ファイルに物理ドライブの情報を保存します。
# MegaCli64 pdlist a0 > pdinfo.tmp
注意: このコマンドによって、出力がファイルにリダイレクトされるため、テキスト・エディタを使用して複数の検索を実行できます。必要に応じて、moreまたはgrepコマンドを通じて出力をパイプ処理できます。
ユーティリティによって、スロットごとに次の情報が返されます。次の例は、Firmware StateがUnconfigured(good), Spun Upであることを示しています。
Enclosure Device ID: 20 Slot Number: 8 Drive's postion: DiskGroup: 8, Span: 0, Arm: 0 Enclosure position: 0 Device Id: 11 WWN: 5000C5003487075C Sequence Number: 2 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Last Predictive Failure Event Seq Number: 0 PD Type: SAS Raw Size: 1.819 TB [0xe8e088b0 Sectors] Non Coerced Size: 1.818 TB [0xe8d088b0 Sectors] Coerced Size: 1.817 TB [0xe8b6d000 Sectors] Firmware state: Unconfigured(good), Spun Up Is Commissioned Spare : NO Device Firmware Level: 061A Shield Counter: 0 Successful diagnostics completion on : N/A SAS Address(0): 0x5000c5003487075d SAS Address(1): 0x0 Connected Port Number: 0(path0) Inquiry Data: SEAGATE ST32000SSSUN2.0T061A1126L6M3WX FDE Enable: Disable Secured: Unsecured Locked: Unlocked Needs EKM Attention: No Foreign State: None Device Speed: 6.0Gb/s Link Speed: 6.0Gb/s Media Type: Hard Disk Device . . .
手順5で作成したファイルをテキスト・エディタで開き、次の項目を検索します。
Foreign StateがForeignのディスクでは、そのステータスを消去します。
# MegaCli64 CfgForeign clear a0
外部ディスクは、コントローラが以前認識していたディスクです(再挿入されたディスクなど)。
Firmware StateがUnconfigured (Bad)のディスクでは、次の手順を実行します。
エンクロージャ・デバイスのID番号とスロット番号を書き留めます。
次の書式でコマンドを入力します。
# MegaCli64 pdmakegood physdrv[enclosure:slot] a0
たとえば、[20:10]では、スロット10のエンクロージャ20によって識別されるディスクが修復されます。
もう一度Foreign Stateの現在のステータスを確認します。
# MegaCli64 pdlist a0 | grep foreign
Foreign StateがまだForeignの場合は、clearコマンドを繰り返します。
# MegaCli64 CfgForeign clear a0
Firmware StateがUnconfigured (Good)のディスクでは、次のコマンドを使用します。複数のディスクが未構成の場合、最小のスロット番号から最大のスロット番号へと向かう順序でそれらを構成します。
# MegaCli64 CfgLdAdd r0[enclosure:slot] a0 Adapter 0: Created VD 1 Adapter 0: Configured the Adapter!! Exit Code: 0x00
たとえば、[20:5]では、スロット5のエンクロージャ20によって識別されるディスクが修復されます。
手順9のCfgLdAddコマンドがキャッシュされたデータにより失敗した場合は、キャッシュを消去します。
# MegaCli64 discardpreservedcache l1 a0
ディスクがオペレーティング・システムによって認識されることを確認します。
# lsscsi
ディスクは、その元のデバイス名(/dev/sdcなど)で表示されるか、新しいデバイス名(/dev/sdnなど)で表示されます。オペレーティング・システムでディスクが認識されない場合、そのディスクはlsscsiコマンドによって生成されるリストに含まれません。
lssci出力が正しい順序で表示されない場合もありますが、構成は続行できます。同じ物理ディスクから論理ディスクへのマッピングが必要な場合には、カーネルに対して同じディスクからデバイスへのマッピングは不要です。ディスク構成は、/dev/disks/by-hba-slotのデバイス名に基づいて行われます。
次の出力例は、新しいデバイス名の2つのディスクを示しています(スロット5の/dev/sdnおよびスロット10の/dev/sdo)。
[0:0:20:0] enclosu ORACLE CONCORD14 0960 - [0:2:0:0] disk LSI MR9261-8i 2.12 /dev/sda [0:2:1:0] disk LSI MR9261-8i 2.12 /dev/sdb [0:2:2:0] disk LSI MR9261-8i 2.12 /dev/sdc [0:2:3:0] disk LSI MR9261-8i 2.12 /dev/sdd [0:2:4:0] disk LSI MR9261-8i 2.12 /dev/sde [0:2:5:0] disk LSI MR9261-8i 2.12 /dev/sdn [0:2:6:0] disk LSI MR9261-8i 2.12 /dev/sdg [0:2:7:0] disk LSI MR9261-8i 2.12 /dev/sdh [0:2:8:0] disk LSI MR9261-8i 2.12 /dev/sdi [0:2:9:0] disk LSI MR9261-8i 2.12 /dev/sdj [0:2:10:0] disk LSI MR9261-8i 2.12 /dev/sdo [0:2:11:0] disk LSI MR9261-8i 2.12 /dev/sdl [7:0:0:0] disk ORACLE UNIGEN-UFD PMAP /dev/sdm [
サーバーのハードウェア・プロファイルを確認し、エラーがあれば修正します。
# bdacheckhw
サーバーのソフトウェア・プロファイルを確認し、エラーがあれば修正します。
# bdachecksw
「Wrong mounted partitions」エラーが表示され、デバイスがリストにない場合は、エラーを無視して続行できます。ただし、「Duplicate mount points」エラーが表示されるか、またはスロット番号が切り替わった場合は、「マウントされているパーティションのエラーの修正」を参照してください。
ドライブを適切に構成できるように、その機能を識別します。「ディスク・ドライブの機能の識別」を参照してください。
bdacheckswユーティリティで見つかる問題は通常、マウントされているパーティションに関係しています。
古いマウント・ポイントがmountコマンドの出力として表示される場合があるため、たとえば/u03など、同じマウント・ポイントが2回表示されることもあります。
重複しているマウント・ポイントを修正するには、次の手順を実行します。
umountコマンドを2回使用して、両方のマウント・ポイントをディスマウントします。この例では、重複している2つの/u03をディスマウントしています。
# umount /u03 # umount /u03
マウント・ポイントを再マウントします。この例では、/u03を再マウントしています。
# mount /u03
ディスクが誤ったスロット(つまり、仮想ドライブ番号)にある場合には、2つのドライブを切り替えることができます。
スロットを切り替えるには、次の手順を実行します。
両方のドライブのマッピングを削除します。この例では、スロット4および10からドライブを削除しています。
# MegaCli64 cfgLdDel L4 a0 # MegaCli64 cfgLdDel L10 a0
表示しようとする順序でドライブを追加します。最初のコマンドで、使用可能な最初のスロット番号が取得されます。
# MegaCli64 cfgLdAdd [20:4] a0 # MegaCli64 cfgLdAdd [20:5] a0
スロット番号が正しい場合であってもマウント・エラーが続く場合には、サーバーを再起動してください。
障害ディスクのあるサーバーはHDFSまたはOracle NoSQL Databaseをサポートするように構成され、ほとんどのディスクはその目的のみに使用されます。ただし、2つのディスクはオペレーティング・システム専用です。新しいディスクを構成する前に、障害ディスクがどのように構成されたかを確認します。
Oracle Big Data Applianceは、最初の2つのディスク上にオペレーティング・システムが構成されます。
障害ディスクでオペレーティング・システムがサポートされていたことを確認するには、次の手順を実行します。
交換ディスクが/dev/sdaまたは/dev/sdb (オペレーティング・システム・ディスク)に対応しているかどうかを確認します。
# lsscsi
「ディスク・ドライブの交換」の手順11での出力を参照してください。
/dev/sdaおよび/dev/sdbがオペレーティング・システムのミラー化パーティション・ディスクであることを確認します。
# mdadm -Q –-detail /dev/md2
/dev/md2:
Version : 0.90
Creation Time : Mon Jul 22 22:56:19 2013
Raid Level : raid1
.
.
.
Number Major Minor RaidDevice State
0 8 2 0 active sync /dev/sda2
1 8 18 1 active sync /dev/sdb2
前の手順で障害ディスクがオペレーティング・システム・ディスクであることがわかった場合、「オペレーティング・システム・ディスクの構成」に進みます。
最初の2つのディスクによって、Linuxオペレーティング・システムがサポートされます。これらのディスクには、ミラー化されたオペレーティング・システムのコピー、スワップ・パーティション、ミラー化されたブート・パーティションおよびHDFSデータ・パーティションが格納されます。
オペレーティング・システム・ディスクを構成するには、稼働を続けているディスクからパーティション表をコピーし、HDFSパーティション(ext4ファイル・システム)を作成して、オペレーティング・システムのソフトウェアRAIDパーティションとブート・パーティションを追加する必要があります。
スロット0またはスロット1のディスクを交換した後、次の手順を実行します。
|
注意: 次のコマンドの/dev/disk/by-hba-slot/snは、適切なシンボリック・リンク(/dev/disk/by-hba-slot/s0または/dev/disk/by-hba-slot/s1)に置き換えてください。 |
論理ドライブをパーティション化するには、次の手順を実行します。
「ディスク・ドライブの交換」の手順を完了します。
新しいディスクにパーティション表が存在しないことを確認します。
# parted /dev/disk/by-hba-slot/sn -s print
通常は、欠落しているパーティション表に関するメッセージが表示されます。
partedコマンドでパーティション表が表示された場合、それを消去します。
# dd if=/dev/zero of=/dev/disk/by-hba-slot/sn bs=1M count=100
|
ヒント: 間違った場合、このコマンドを使用してオペレーティング・システム・ディスクの構成を再開できます。 |
パーティション表を作成します。
# parted /dev/disk/by-hba-slot/sn -s mklabel gpt print
稼働を続けているディスクのCylinder Head Sector (CHS)パーティション情報をリストします。つまり、/dev/disk/by-hba-slot/s0をパーティション化する場合、次のコマンドの/dev/disk/by-hba-slot/smとして/dev/disk/by-hba-slot/s1を入力します。
# parted /dev/disk/by-hba-slot/sm -s unit chs print Model: LSI MR9261-8i (scsi) Disk /dev/sda: 243031,30,6 Sector size (logical/physical): 512B/512B BIOS cylinder,head,sector geometry: 243031,255,63. Each cylinder is 8225kB. Partition Table: gpt Number Start End File system Name Flags 1 0,0,34 25,127,7 ext3 raid 2 25,127,8 21697,116,20 ext3 raid 3 21697,116,21 23227,61,35 linux-swap 4 23227,61,36 243031,29,36 ext3 primary
稼働を続けているディスクのパーティションを複製して、新しいドライブにパーティション1から3を作成します。次の書式で3つのコマンドを発行します。
# parted /dev/disk/by-hba-slot/sn -s mkpart file_system start end
次の例に示されているアドレスのかわりに、手順5で取得した開始アドレスと終了アドレスを使用してください。
# parted /dev/disk/by-hba-slot/sn -s mkpart ext3 0,0,34 25,127,7 # parted /dev/disk/by-hba-slot/sn -s mkpart ext3 25,127,8 21697,116,20 # parted /dev/disk/by-hba-slot/sn -s mkpart linux-swap 21697,116,21 23227,61,35
手順5で取得した開始アドレスと100%の終了アドレスを使用して、プライマリ・パーティション4を作成します。
# parted /dev/disk/by-hba-slot/sn -s mkpart primary ext3 23227,61,36 100%
パーティション4にはHDFSデータが格納され、この構文によってパーティションが可能なかぎり大きくなります。
RAIDフラグを設定します。
# parted -s /dev/disk/by-hba-slot/sn set 1 raid # parted -s /dev/disk/by-hba-slot/sn set 2 raid
対話モードでpartedを使用して名前を消去します。
# parted /dev/disk/by-hba-slot/sn GNU Parted 1.8.1 Using /dev/sdn Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) name 1 " " (parted) name 2 " " (parted) name 3 " " (parted) quit
「RAIDアレイの修理」の手順を完了します。
ディスクをパーティション化した後、2つの論理RAIDアレイを修理できます。
/dev/md0には、/dev/disk/by-hba-slot/s0p1および/dev/disk/by-hba-slot/s1p1が含まれます。/bootとしてマウントされます。
/dev/md2には、/dev/disk/by-hba-slot/s0p2および/dev/disk/by-hba-slot/s1p2が含まれます。/ (root)としてマウントされます。
|
注意: システムが停止する操作になるため、/dev/mdデバイスはディスマウントしないでください。 |
RAIDアレイを修理するには、次の手順を実行します。
RAIDアレイからパーティションを削除します。
# mdadm /dev/md0 -r detached # mdadm /dev/md2 -r detached
RAIDアレイが縮退していることを確認します。
# mdadm -Q –-detail /dev/md0 # mdadm -Q –-detail /dev/md2
各アレイの縮退ファイルが1に設定されていることを確認します。
# cat /sys/block/md0/md/degraded 1 # cat /sys/block/md2/md/degraded 1
RAIDアレイにパーティションをリストアします。
# mdadm –-add /dev/md0 /dev/disk/by-hba-slot/snp1 # mdadm –-add /dev/md2 /dev/disk/by-hba-slot/snp2
/dev/md2がリカバリ状態になり、アイドル状態でなくなるように、再同期が開始されていることを確認します。
# cat /sys/block/md2/md/sync_action
repair
再同期の進行を確認するには、mdstatファイルを監視します。カウンタによって、完了した割合が示されます。
# cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb1[1] sda1[0]
204736 blocks [2/2] [UU]
md2 : active raid1 sdb2[2] sda2[0]
174079936 blocks [2/1] [U_]
[============>........] recovery = 61.6% (107273216/174079936) finish=18.4min speed=60200K/sec
次の出力は、同期が完了したことを示しています。
Personalities : [raid1]
md0 : active raid1 sdb1[1] sda1[0]
204736 blocks [2/2] [UU]
md2 : active raid1 sdb2[1] sda2[0]
174079936 blocks [2/2] [UU]
unused devices: <none>
/etc/mdadm.confのコンテンツを表示します。
# cat /etc/mdadm.conf
# mdadm.conf written out by anaconda
DEVICE partitions
MAILADDR root
ARRAY /dev/md0 level=raid1 num-devices=2 UUID=df1bd885:c1f0f9c2:25d6...
ARRAY /dev/md2 level=raid1 num-devices=2 UUID=6c949a1a:1d45b778:a6da...
次のコマンドの出力をステップ7の/etc/mdadm.confの内容と比較します。
# mdadm --examine --brief --scan --config=partitions
ファイル内のUUIDがmdadmコマンドの出力内のUUIDと異なる場合は、次の手順を実行します。
テキスト・エディタで/etc/mdadm.confを開きます。
ARRAYからファイルの末尾までを選択し、選択した行を削除します。
ファイルの行を削除した部分に、コマンドの出力をコピーします。
変更したファイルを保存して終了します。
「オペレーティング・システム・ディスクのHDFSパーティションのフォーマット」の手順を完了します。
オペレーティング・システム・ディスクのパーティション4 (sda4)は、HDFSに使用されます。パーティションをフォーマットして適切なラベルを設定すると、ディスク領域が必要な場合にパーティションを使用するようにHDFSによってジョブの負荷がリバランスされます。
HDFSパーティションをフォーマットするには、次の手順を実行します。
ext4ファイル・システムとしてHDFSパーティションをフォーマットします。
# mke4fs -t ext4 /dev/disk/by-hba-slot/snp4 mke4fs 1.41.12 (17-May-2010) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 110354432 inodes, 441393655 blocks 22069682 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=4294967296 13471 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968, 102400000, 214990848 Writing inode tables:
|
注意: デバイスがマウントされているためにこのコマンドが失敗する場合、ここでドライブをディスマウントし、手順3を省略してください。ディスマウントの手順は、「作業ディスクまたは障害ディスクを交換するための前提条件」を参照してください。 |
パーティション・ラベル(s0p4に対する/u01など)が存在しないことを確認します。
# ls -l /dev/disk/by-label
適切なHDFSパーティション(/dev/sdaの場合は/u01、/dev/sdbの場合は/u02)をディスマウントします。
# umount /u0n
パーティション・ラベルを再設定します。
# tune4fs -c -1 -i 0 -m 0.2 -L /u0n /dev/disk/by-hba-slot/snp4
HDFSパーティションをマウントします。
# mount /u0n
「スワップ・パーティションのリストア」の手順を完了します。
HDFSパーティションをフォーマットした後、スワップ・パーティションをリストアできます。
スワップ・パーティションをリストアするには、次の手順を実行します。
スワップ・ラベルを設定します。
# mkswap -L SWAP-sdn3 /dev/disk/by-hba-slot/snp3 Setting up swapspace version 1, size = 12582907 kB LABEL=SWAP-sdn3, no uuid
スワップ・パーティションがリストアされたことを確認します。
# bdaswapon; bdaswapoff
Filename Type Size Used Priority
/dev/sda3 partition 12287992 0 1
/dev/sdb3 partition 12287992 0 1
交換したディスクがオペレーティング・システムによって認識されることを確認します。
$ ls -l /dev/disk/by-label
total 0
lrwxrwxrwx 1 root root 10 Aug 3 01:22 BDAUSB -> ../../sdn1
lrwxrwxrwx 1 root root 10 Aug 3 01:22 BDAUSBBOOT -> ../../sdm1
lrwxrwxrwx 1 root root 10 Aug 3 01:22 SWAP-sda3 -> ../../sda3
lrwxrwxrwx 1 root root 10 Aug 3 01:22 SWAP-sdb3 -> ../../sdb3
lrwxrwxrwx 1 root root 10 Aug 3 01:22 u01 -> ../../sda4
lrwxrwxrwx 1 root root 10 Aug 3 01:22 u02 -> ../../sdb4
lrwxrwxrwx 1 root root 10 Aug 3 01:22 u03 -> ../../sdc1
lrwxrwxrwx 1 root root 10 Aug 3 01:22 u04 -> ../../sdd1
.
.
.
出力に交換したディスクがリストされない場合:
Linux 5で、udevtriggerを実行します。
Linux 6で、udevadm triggerを実行します。
その後、手順3を繰り返します。lsscsiコマンドも、ディスクの正しい順序をレポートする必要があります。
「GRUBマスター・ブート・レコードおよびHBAブート順序のリストア」の手順を完了します。
スワップ・パーティションをリストアした後、Grand Unified Bootloader (GRUB)のマスター・ブート・レコードをリストアできます。
GRUBのブート・レコードをリストアするには、次の手順を実行します。
GRUBを開きます。
# grub --device-map=/boot/grub/device.map
GNU GRUB version 0.97 (640K lower / 3072K upper memory)
[ Minimal BASH-like line editing is supported. For the first word, TAB
lists possible command completions. Anywhere else TAB lists the possible
completions of a device/filename.
]
device.mapファイルによって、オペレーティング・システム・デバイスにBIOSドライブがマップされます。次に、デバイス・マップ・ファイルの例を示します。
# this device map was generated by anaconda (hd0) /dev/sda (hd1) /dev/sdb
/dev/sdaの場合はhd0、/dev/sdbの場合はhd1を入力して、ルート・デバイスを設定します。
grub> root (hdn,0) root (hdn,0) Filesystem type is ext2fs, partition type 0x83
/dev/sdaの場合はhd0、/dev/sdbの場合はhd1を入力して、GRUBをインストールします。
grub> setup (hdn) setup (hdn) Checking if "/boot/grub/stage1" exists... no Checking if "/grub/stage1" exists... yes Checking if "/grub/stage2" exists... yes Checking if "/grub/e2fs_stage1_5" exists... yes Running "embed /grub/e2fs_stage1_5 (hdn)"... failed (this is not fatal) Running "embed /grub/e2fs_stage1_5 (hdn,0)"... failed (this is not fatal) Running "install /grub/stage1 (hdn) /grub/stage2 p /grub/grub.conf "... succeeded Done.
GRUBコマンドライン・インタフェースを終了します。
grub> quit
論理ドライブL0 (L +ゼロ)がHBAのブート・ドライブとして設定されていることを確認します。
# MegaCli64 -AdpBootDrive -get a0
Adapter 0: Boot Virtual Drive - #0 (target id - 0).
前のコマンドでL0 (仮想ドライブ0、ターゲット0)がレポートされなかった場合は、次のように入力します。
# MegaCli64 AdpBootDrive set L0 a0
自動選択ブート・ドライブ機能が有効であることを確認します。
# MegaCli64 adpBIOS EnblAutoSelectBootLd a0
Auto select Boot is already Enabled on Adapter 0.
構成を確認します。「ディスク構成の確認」を参照してください。
オペレーティング・システムで使用されていないすべてのディスクで、次の手順を実行します。「ディスク・ドライブの機能の識別」を参照してください。
ディスクを構成するには、それをパーティション化してフォーマットする必要があります。
|
注意: 次のコマンドのsnp1は、s4p1などの適切なシンボリック名に置き換えてください。 |
HDFSまたはOracle NoSQL Databaseで使用するためにディスクをフォーマットするには、次の手順を実行します。
「ディスク・ドライブの交換」の手順をまだ完了していない場合は完了します。
ドライブをパーティション化します。
# parted /dev/disk/by-hba-slot/sn -s mklabel gpt mkpart primary ext3 0% 100%
ext4ファイル・システムのパーティションをフォーマットします。
# mke4fs -t ext4 /dev/disk/by-hba-slot/snp1 mke4fs 1.41.12 (17-May-2010) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 122011648 inodes, 488036855 blocks 24401842 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=4294967296 14894 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968, 102400000, 214990848 Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done This filesystem will be automatically checked every 23 mounts or 180 days, whichever comes first. Use tune4fs -c or -i to override.
存在しないデバイスに適切なパーティション・ラベルを再設定します。表11-2を参照してください。
# tune4fs -c -1 -i 0 -m 0.2 -L /unn /dev/disk/by-hba-slot/snp1
たとえば、次のコマンドでは、/u03に対して/dev/disk/by-hba-slot/s2p1というラベルを再設定します。
# tune4fs -c -1 -i 0 -m 0.2 -L /u03 /dev/disk/by-hba-slot/s2p1 Setting maximal mount count to -1 Setting interval between checks to 0 seconds Setting reserved blocks percentage to 0.2% (976073 blocks)
交換したディスクがオペレーティング・システムによって認識されることを確認します。
$ ls -l /dev/disk/by-label
total 0
lrwxrwxrwx 1 root root 10 Aug 3 01:22 BDAUSB -> ../../sdn1
lrwxrwxrwx 1 root root 10 Aug 3 01:22 BDAUSBBOOT -> ../../sdm1
lrwxrwxrwx 1 root root 10 Aug 3 01:22 SWAP-sda3 -> ../../sda3
lrwxrwxrwx 1 root root 10 Aug 3 01:22 SWAP-sdb3 -> ../../sdb3
lrwxrwxrwx 1 root root 10 Aug 3 01:22 u01 -> ../../sda4
lrwxrwxrwx 1 root root 10 Aug 3 01:22 u02 -> ../../sdb4
lrwxrwxrwx 1 root root 10 Aug 3 01:22 u03 -> ../../sdc1
lrwxrwxrwx 1 root root 10 Aug 3 01:22 u04 -> ../../sdd1
.
.
.
出力に交換したディスクがリストされない場合:
Linux 5で、udevtriggerを実行します。
Linux 6で、udevadm triggerを実行します。
その後、手順5を繰り返します。lsscsiコマンドも、ディスクの正しい順序をレポートする必要があります。
適切なマウント・ポイントを入力してHDFSパーティションをマウントします。
# mount /unn
たとえば、mount /u03とします。
複数のドライブを構成する場合、前述の手順を繰り返します。
Cloudera ManagerでHDFSドライブのマウント・ポイントを削除していた場合、リストにリストアします。
Cloudera Managerのブラウザ・ウィンドウを開きます。次に例を示します。
http://bda1node03.example.com:7180
Cloudera Managerを開き、adminとしてログインします。
「Services」ページで、「hdfs」をクリックします。
「Instances」サブタブをクリックします。
「Host」列で、交換ディスクのあるサーバーを特定します。次に、「Name」列のサービス(datanodeなど)をクリックしてそのページを開きます。
「Configuration」サブタブをクリックします。
「Directory」フィールドにマウント・ポイントがない場合、リストに追加します。
「Save Changes」をクリックします。
「Actions」リストから、「Restart」を選択します。
構成を確認します。「ディスク構成の確認」を参照してください。
Oracle Big Data Applianceソフトウェアをサーバーに再インストールする前に、新しいディスク・ドライブの構成が適切であることを確認する必要があります。
ディスク構成を確認するには、次の手順を実行します。
ソフトウェア構成を確認します。
# bdachecksw
エラーが存在する場合、必要に応じて構成手順を再実行して問題を修正します。
/rootディレクトリでBDA_REBOOT_SUCCEEDEDというファイルを確認します。
BDA_REBOOT_FAILEDという名前のファイルが見つかった場合には、そのファイルを読んで新しい問題を特定し、修正します。
次のスクリプトを使用して、BDA_REBOOT_SUCCEEDEDファイルを生成します。
# /opt/oracle/bda/lib/bdastartup.sh
BDA_REBOOT_SUCCEEDEDが存在することを確認します。まだBDA_REBOOT_FAILEDファイルが見つかる場合には、前の手順を繰り返します。
インフィニバンド・ネットワークは、bondib0インタフェースを通じてサーバーをラックのインフィニバンド・スイッチに接続します。この項では、インフィニバンド・スイッチのメンテナンスを実行する方法について説明します。
この項で説明する項目は、次のとおりです。
Oracle ILOMでは、Oracle Big Data Applianceサーバーのリモート管理がサポートされます。この項では、Mammothユーティリティによって設定されるOracle ILOM構成設定をバックアップおよびリストアする方法について説明します。
|
関連項目:
|
Sun Server X4-2LまたはX3-2Lサーバー上のOracle ILOM構成設定をバックアップするには、次の手順を実行します。
Oracle Big Data Applianceと同じネットワーク上にある任意のシステムでブラウザを開き、Oracle ILOMサービス・プロセッサに移動します。この例では、node08という名前のサーバーのOracle ILOMアドレスを使用します。
http://bda1node08-ilom.example.com
インフィニバンド・スイッチのOracle ILOMをバックアップするには、スイッチ・アドレス(bda1sw-ib1など)を入力します。
rootユーザーとしてログインします。初期パスワードはwelcome1です。
「Backup/Restore」ページに移動します。
Oracle ILOM 3.1の場合は、「Maintenance」タブを選択した後、「Backup/Restore」サブタブを選択します。
Oracle ILOM 3.0の場合は、ナビゲーション・ツリーで「ILOM Administration」フォルダを展開し、「Configuration Management」を選択します。
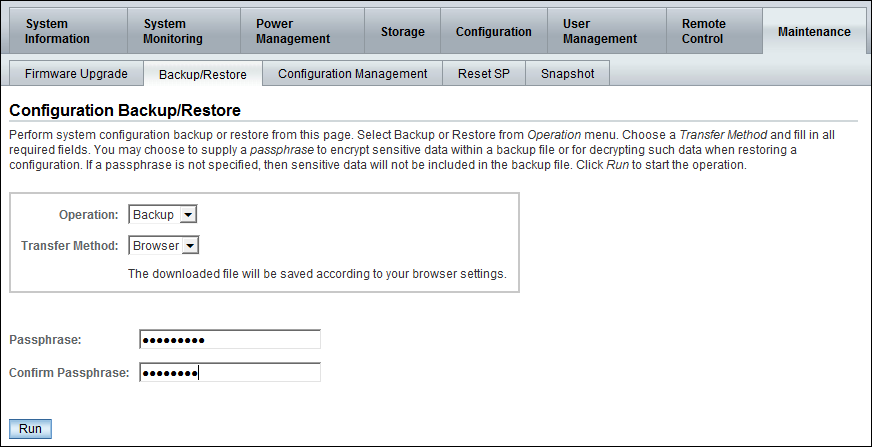
図11-1に示すとおり、バックアップ操作とブラウザ転送方式を選択します。
パスフレーズを入力します。このフレーズを使用して、バックアップ・ファイルのパスワードなどの機密情報を暗号化します。
「Run」をクリックしてバックアップ操作を開始します。結果は、ローカル・システムにダウンロードされ、config_backup.xmlというXMLファイルに格納されます。
セキュアな場所にファイルを保存します。
「Log Out」ボタンをクリックします。
Oracle ILOM構成設定をリストアするには、次の手順を実行します。
Oracle Big Data Applianceと同じネットワーク上にある任意のシステムでブラウザを開き、Oracle ILOMサービス・プロセッサに移動します。次の例では、node08のOracle ILOMを使用します。
http://bda1node08-ilom.us.example.com
ilom_adminユーザーとしてログインします。デフォルト・パスワードはwelcome1です。
「Maintenance」タブを選択した後、「Backup/Restore」サブタブを選択します。
リストア操作とブラウザ転送方式を選択します。
「Choose File」をクリックし、バックアップ操作で前に保存したconfig_backup.xmlファイルを選択します。
バックアップ操作中に設定したパスフレーズを入力します。
「Run」をクリックして構成をリストアします。
次の手順を実行して、Sun Network QDR Infiniband Gateway SwitchまたはSun Datacenter InfiniBand Switch 36を交換します。
|
関連項目:
|
障害のあるインフィニバンド・スイッチを交換するには、次の手順を実行します。
スイッチからケーブルを外します。すべてのインフィニバンド・ケーブルには、両端にその場所を示すラベルがあります。どのケーブルにもラベルがない場合、ラベルを付けてください。
電源プラグを取り外して、スイッチの両方の電源を切断します。
ラックからスイッチを取り外します。
ラックに新しいスイッチを設置します。
「Oracle ILOM設定のバックアップおよびリストア」の説明に従って、バックアップ・ファイルを使用してスイッチ設定をリストアします。
ilom_adminとしてスイッチに接続し、ファブリック管理シェルを開きます。
-> show /SYS/Fabric_Mgmt
プロンプトが->からFabMan@hostname->に変更されます。
サブネット・マネージャを無効にします。
FabMan@bda1sw-02-> disablesm
適切なポートに各ケーブルを慎重に接続して、新しいスイッチにケーブルを接続します。
ファブリックのどのリンクにもエラーがないことを確認します。
FabMan@bda1sw-02-> ibdiagnet -c 1000 -r
サブネット・マネージャを有効にします。
FabMan@bda1sw-02-> enablesm
|
注意: 交換したスイッチがSun Datacenter InfiniBand Switch 36スパイン・スイッチである場合、スパイン・スイッチがマスターになるまで、他のスイッチのサブネット・マネージャを無効にして、マスター・サブネット・マネージャをスイッチに手動でフェイルバックします。次に、他のすべてのスイッチでサブネット・マネージャを再有効化します。 |
インフィニバンド・ネットワークのコンポーネントにメンテナンスが必要な場合(サーバーのインフィニバンド・ホスト・チャネル・アダプタ(HCA)、インフィニバンド・スイッチまたはインフィニバンド・ケーブルの交換など)、またはインフィニバンド・ネットワークの操作が十分に機能していないと疑われる場合、インフィニバンド・ネットワークが適切に動作していることを確認してください。次の手順では、ネットワーク操作を確認する方法について説明します。
|
注意: インフィニバンド・ネットワークのパフォーマンスが想定を下回る場合、常に次の手順を使用します。 |
インフィニバンド・ネットワーク操作を確認するには、次の手順を実行します。
ibdiagnetコマンドを入力して、インフィニバンド・ネットワーク品質を確認します。
# ibdiagnet -c 1000
このコマンドでレポートされるすべてのエラーを調査します。これによって多少のネットワーク・トラフィックが生成されますが、通常のワークロード中に実行できます。
|
関連項目: Sun Network QDR InfiniBand Gateway Switchコマンド・リファレンス
|
スイッチ・ポート・エラー・カウンタとポート構成情報をレポートします。LinkDowned、RcvSwRelayErrors、XmtDiscardsおよびXmtWaitエラーは、このコマンドでは無視されます。
# ibqueryerrors.pl -rR -s LinkDowned,RcvSwRelayErrors,XmtDiscards,XmtWait
|
関連項目: ibqueryerrorsのLinux manページ |
ハードウェアのステータスを確認します。
# bdacheckhw
次に、出力の例を示します。
[SUCCESS: Correct system model : SUN FIRE X4270 M2 SERVER
[SUCCESS: Correct processor info : Intel(R) Xeon(R) CPU X5675 @ 3.07GHz
[SUCCESS: Correct number of types of CPU : 1
[SUCCESS: Correct number of CPU cores : 24
[SUCCESS: Sufficient GB of memory (>=48): 48
[SUCCESS: Correct GB of swap space : 24
[SUCCESS: Correct BIOS vendor : American Megatrends Inc.
[SUCCESS: Sufficient BIOS version (>=08080102): 08080102
[SUCCESS: Recent enough BIOS release date (>=05/23/2011) : 05/23/2011
[SUCCESS: Correct ILOM version : 3.0.16.10.a r68533
[SUCCESS: Correct number of fans : 6
[SUCCESS: Correct fan 0 status : ok
[SUCCESS: Correct fan 1 status : ok
[SUCCESS: Correct fan 2 status : ok
[SUCCESS: Correct fan 3 status : ok
[SUCCESS: Correct fan 4 status : ok
[SUCCESS: Correct fan 5 status : ok
[SUCCESS: Correct number of power supplies : 2
[1m[34mINFO: Detected Santa Clara Factory, skipping power supply checks
[SUCCESS: Correct disk controller model : LSI MegaRAID SAS 9261-8i
[SUCCESS: Correct disk controller firmware version : 12.12.0-0048
[SUCCESS: Correct disk controller PCI address : 13:00.0
[SUCCESS: Correct disk controller PCI info : 0104: 1000:0079
[SUCCESS: Correct disk controller PCIe slot width : x8
[SUCCESS: Correct disk controller battery type : iBBU08
[SUCCESS: Correct disk controller battery state : Operational
[SUCCESS: Correct number of disks : 12
[SUCCESS: Correct disk 0 model : SEAGATE ST32000SSSUN2.0
[SUCCESS: Sufficient disk 0 firmware (>=61A): 61A
[SUCCESS: Correct disk 1 model : SEAGATE ST32000SSSUN2.0
[SUCCESS: Sufficient disk 1 firmware (>=61A): 61A
.
.
.
[SUCCESS: Correct disk 10 status : Online, Spun Up No alert
[SUCCESS: Correct disk 11 status : Online, Spun Up No alert
[SUCCESS: Correct Host Channel Adapter model : Mellanox Technologies MT26428 ConnectX VPI PCIe 2.0
[SUCCESS: Correct Host Channel Adapter firmware version : 2.9.1000
[SUCCESS: Correct Host Channel Adapter PCI address : 0d:00.0
[SUCCESS: Correct Host Channel Adapter PCI info : 0c06: 15b3:673c
[SUCCESS: Correct Host Channel Adapter PCIe slot width : x8
[SUCCESS: Big Data Appliance hardware validation checks succeeded
ソフトウェアのステータスを確認します。
# bdachecksw
[SUCCESS: Correct OS disk sda partition info : 1 ext3 raid 2 ext3 raid 3 linux-swap 4 ext3 primary [SUCCESS: Correct OS disk sdb partition info : 1 ext3 raid 2 ext3 raid 3 linux-swap 4 ext3 primary [SUCCESS: Correct data disk sdc partition info : 1 ext3 primary [SUCCESS: Correct data disk sdd partition info : 1 ext3 primary [SUCCESS: Correct data disk sde partition info : 1 ext3 primary [SUCCESS: Correct data disk sdf partition info : 1 ext3 primary [SUCCESS: Correct data disk sdg partition info : 1 ext3 primary [SUCCESS: Correct data disk sdh partition info : 1 ext3 primary [SUCCESS: Correct data disk sdi partition info : 1 ext3 primary [SUCCESS: Correct data disk sdj partition info : 1 ext3 primary [SUCCESS: Correct data disk sdk partition info : 1 ext3 primary [SUCCESS: Correct data disk sdl partition info : 1 ext3 primary [SUCCESS: Correct software RAID info : /dev/md2 level=raid1 num-devices=2 /dev/md0 level=raid1 num-devices=2 [SUCCESS: Correct mounted partitions : /dev/md0 /boot ext3 /dev/md2 / ext3 /dev/sda4 /u01 ext4 /dev/sdb4 /u02 ext4 /dev/sdc1 /u03 ext4 /dev/sdd1 /u04 ext4 /dev/sde1 /u05 ext4 /dev/sdf1 /u06 ext4 /dev/sdg1 /u07 ext4 /dev/sdh1 /u08 ext4 /dev/sdi1 /u09 ext4 /dev/sdj1 /u10 ext4 /dev/sdk1 /u11 ext4 /dev/sdl1 /u12 ext4 [SUCCESS: Correct swap partitions : /dev/sdb3 partition /dev/sda3 partition [SUCCESS: Correct Linux kernel version : Linux 2.6.32-200.21.1.el5uek [SUCCESS: Correct Java Virtual Machine version : HotSpot(TM) 64-Bit Server 1.6.0_29 [SUCCESS: Correct puppet version : 2.6.11 [SUCCESS: Correct MySQL version : 5.5.17 [SUCCESS: All required programs are accessible in $PATH [SUCCESS: All required RPMs are installed and valid [SUCCESS: Big Data Appliance software validation checks succeeded
サブネット・マネージャでは、次のような機能を含むインフィニバンド・ネットワークのすべての動作特性を管理します。
インフィニバンド・ネットワークには、複数のサブネット・マネージャを含めることができますが、同時にアクティブにできるサブネット・マネージャは、1つのみです。アクティブなサブネット・マネージャは、マスター・サブネット・マネージャです。他のサブネット・マネージャは、スタンバイ・サブネット・マネージャです。マスター・サブネット・マネージャが停止するか、障害が発生すると、スタンバイ・サブネット・マネージャが自動的にマスター・サブネット・マネージャになります。
各サブネット・マネージャには、構成可能な優先度があります。複数のサブネット・マネージャがインフィニバンド・ネットワーク上に存在する場合、最高の優先度を持つサブネット・マネージャがマスター・サブネット・マネージャになります。Oracle Big Data Applianceでは、リーフ・スイッチのサブネット・マネージャが優先度5に構成され、スパイン・スイッチのサブネット・マネージャが優先度8に構成されます。
次のガイドラインによって、サブネット・マネージャがOracle Big Data Applianceで実行される場所が決定されます。
サブネット・マネージャは、Oracle Big Data Applianceのスイッチでのみ実行されます。他のデバイスでサブネット・マネージャを実行することは、サポートされません。
ケーブルで接続された1つ、2つまたは3つのラックでインフィニバンド・ネットワークが構成される場合、すべてのスイッチでサブネット・マネージャを実行する必要があります。マスター・サブネット・マネージャは、スパイン・スイッチで実行されます。
ケーブルで接続された4つ以上のラックでインフィニバンド・ネットワークが構成される場合、サブネット・マネージャはスパイン・スイッチでのみ実行されます。リーフ・スイッチでは、サブネット・マネージャを無効にする必要があります。
|
関連項目:
|
Sun Network QDR Infiniband Gateway Switchに対する10GbE接続の数を変更する場合、bdaredoclientnetユーティリティを実行する必要があります。「bdaredoclientnet」を参照してください。
ラックのVNICを再作成するには、次の手順を実行します。
/opt/oracle/bda/BdaDeploy.jsonがすべてのサーバーに存在し、カスタム・ネットワーク設定を正しく記述していることを確認します。次のコマンドによって、欠落しているファイルや、異なる日付スタンプを持つファイルを識別します。
dcli ls -l /opt/oracle/bda/BdaDeploy.json
管理ネットワークを使用してnode01 (ラックの一番下)に接続します。bdaredoclientnetユーティリティによってクライアント・ネットワークが停止されるため、この手順でそれを使用することはできません。
パスワードなしSSHを削除します。
/opt/oracle/bda/bin/remove-root-ssh
このコマンドの詳細は、「パスワードなしSSHの設定」を参照してください。
ディレクトリを変更します。
cd /opt/oracle/bda/network
ユーティリティを実行します。
bdaredoclientnet
出力は、例7-2に示されている内容とほぼ同じです。
パスワードなしSSHをリストアします(オプション)。
/opt/oracle/bda/bin/setup-root-ssh
ネットワーク・タイム・プロトコル(NTP)・サーバーの構成情報は、初期設定後に変更できます。次の手順では、インフィニバンド・スイッチ、CiscoスイッチおよびSunサーバーのNTP構成情報を変更する方法について説明します。各サーバーを個別に変更することをお薦めします。
Oracle Big Data Applianceサーバーを更新するには、次の手順を実行します。
インフィニバンド・スイッチを更新するには、次の手順を実行します。
ilom-adminユーザーとしてスイッチにログインします。
「インフィニバンド・スイッチでのタイムゾーンおよびクロックの設定」の指示に従います。
Ciscoイーサネット・スイッチを更新するには、次の手順を実行します。
Telnetを使用してCiscoイーサネット・スイッチに接続します。
現在の設定を削除します。
# configure terminal Enter configuration commands, one per line. End with CNTL/Z. (config)# no ntp server current_IPaddress
新しいIPアドレスを入力します。
# configure terminal Enter configuration commands, one per line. End with CNTL/Z. (config)# ntp server new_IPaddress
現在の構成を保存します。
# copy running-config startup-config
セッションを終了します。
# exit
サーバーおよびスイッチの変更後にOracle Big Data Applianceを再起動します。
PDUの電流は直接監視できます。しきい値設定を構成してPDUを監視します。各メータリング・ユニット・モジュールおよび相の構成可能なしきい値は、Info low、Pre WarningおよびAlarmです。
|
関連項目: PDUの構成および監視の詳細は、次の場所にあるSun Rack II配電ユニット・ユーザーズ・ガイドを参照してください。 |
表11-3に、単相低電圧PDUを使用するOracle Big Data Applianceラックのしきい値を示します。
表11-3 単相低電圧PDUのしきい値
| PDU | モジュール/相 | Info Lowしきい値 | Pre Warningしきい値 | Alarmしきい値 |
|---|---|---|---|---|
|
A |
モジュール1、相1 |
0 |
18 |
23 |
|
A |
モジュール1、相2 |
0 |
22 |
24 |
|
A |
モジュール1、相3 |
0 |
18 |
23 |
|
B |
モジュール1、相1 |
0 |
18 |
23 |
|
B |
モジュール1、相2 |
0 |
22 |
24 |
|
B |
モジュール1、相3 |
0 |
18 |
23 |
表11-4に、3相低電圧PDUを使用するOracle Big Data Applianceラックのしきい値を示します。
表11-4 3相低電圧PDUのしきい値
| PDU | モジュール/相 | Info Lowしきい値 | Pre Warningしきい値 | Alarmしきい値 |
|---|---|---|---|---|
|
AおよびB |
モジュール1、相1 |
0 |
32 |
40 |
|
AおよびB |
モジュール1、相2 |
0 |
34 |
43 |
|
AおよびB |
モジュール1、相3 |
0 |
33 |
42 |
表11-5に、単相高電圧PDUを使用するOracle Big Data Applianceラックのしきい値を示します。
表11-5 単相高電圧PDUのしきい値
| PDU | モジュール/相 | Info Lowしきい値 | Pre Warningしきい値 | Alarmしきい値 |
|---|---|---|---|---|
|
A |
モジュール1、相1 |
0 |
16 |
20 |
|
A |
モジュール1、相2 |
0 |
20 |
21 |
|
A |
モジュール1、相3 |
0 |
16 |
20 |
|
B |
モジュール1、相1 |
0 |
16 |
20 |
|
B |
モジュール1、相2 |
0 |
20 |
21 |
|
B |
モジュール1、相3 |
0 |
16 |
20 |
表11-6に、3相高電圧PDUを使用するOracle Big Data Applianceラックのしきい値を示します。