5 Data Nodes
Data nodes specify data for a mining operation, to transform data, or to save data to a table. The input for Oracle Data Mining operations is a table or view in Oracle Database or an Oracle Data Miner node that is part of a data flow.
The Data nodes are available in the Data section in the Components pane.
The following Data nodes enable you to specify data in a workflow and to create and modify tables:
5.1 Create Table or View Node
The Create Table or View node is a type of node that enables you to save the results in a table in the schema to which you are connected. For example, use a Create Table or View node to save the results of an Apply node to a table.
The Create Table node automatically uses compression when possible.
The Create Table node can run in parallel.
The benefits of Create Table or View node are:
-
Data Persistence: A Create Table or View node saves the data that flow into the node as a view or table in the database. If you create a table, then the actual data persists. If you create a view, then the SQL definition (full lineage) persists. Output from this node is the data provided by the view or table.
-
Performance Improvement: If you perform one or more complex transformations, such as Joins and Aggregations, and save the result of the transformations as a table, then the subsequent operations are faster. For example, you can perform an Aggregation and a Join, create a table that contains the results of the transformation, and then use the table as input for building the model. Therefore, you will create a table from the Join node. The Classification models are built against this table.
5.1.1 Working with the Create Table or View Node
You can perform the following tasks with a Create Table or View node:
5.1.1.1 Create a Create Table or View Node
You create a Create Table or View node to save a data flow to a table or view. You can connect a Create Table or View node to any node that create a data flow, such as an Apply node.
To create a Create Table or View node:
-
In the Components pane, go to the Workflow Editor and expand Data.
If the Components pane is not visible, then in the SQL Developer menu bar, go to View and click Components. Alternately, press Ctrl+Shift+P to dock the Components pane.
-
In the Data section, click the Create Table or View icon.
-
Drag and drop the Create Table or View node from the Components pane to the Workflow pane. This adds the Create Table or View node to the workflow.
-
Right-click the node from which to create the table, and click Connect in the context menu.
-
Draw a line from the selected node to the Create Table or View node and click again.
-
You can accept the default settings of the Create Table or View node or edit the default settings. Click Edit in the context menu.
-
To create the table, right-click the Create Table or View node and select Run from the context menu.
The table is automatically compressed, if possible.
-
After running the node, right-click the node and select View Data to view the results.
5.1.1.2 Create Table Node and Compression
Table compression does the following:
-
Saves disk space
-
Reduces memory use in the buffer cache
-
Speeds up the running of queries during reads
When Oracle Data Miner creates a table, if Oracle Data Miner determines that the data does not have nested columns DM_NESTED_*, then it uses compression to create the table. Oracle Data Miner creates tables in the Create Table node, and creates split data sets for testing in the Classification and Regression model build.
For the Create Table node, Oracle Data Miner also verifies that a primary key is not defined and no indexes are defined.
5.1.1.3 Edit Create Table or View Node
You can modify the operation of the Create Table or View node. To edit a Create Table or View node:
-
Double-click the node or right-click and select Edit. The Edit Create Table or View node dialog box opens.
-
In the Edit Create Table or View node dialog box, you can make the following changes:
-
Name: Displays the default table name. You can change the default name of the table or view to any unique and valid name.
-
Type: By default, the object type is
Table.You can change the default toViewby selecting the appropriate option. -
Auto Input Column Selection: Deselect the check box to manually select and edit input columns. You can perform the following tasks:
-
Delete columns: Select the column and click
 .
. -
Edit columns: Select the column and click
 . The Select Column dialog box opens.
. The Select Column dialog box opens.Note:
If JSON data is present, select the column and click to specify Data Guide settings in the Edit Data Guide dialog box. -
Edit the data type entry in the Target Type column for JSON data only. Click the data type in the Target column to select an option from the in-place drop-down list.
-
Specify Key, Index and Alias for each column.
Note:
If you create a table that join another object, adding an index will speed up the join.
-
-
JSON Settings: Click JSON Settings to specify node settings that determines how Data Guides are generated. This option is applicable only for JSON data.
-
-
Click OK.
See Also:
5.1.1.4 Select Columns
By default, all columns are selected. You must select at least one attribute for the Create Table or View definition to be complete. You can perform the following tasks:
-
Remove columns: Select the attribute in the Selected Attribute section and move it to the Available Attribute section. Click OK.
-
Add columns: Select the attribute in the Available Attribute section and move it to the Selected Attribute section. Click OK.
5.1.1.5 View Create Table or View Data
After the node runs successfully, right-click the node and select View Data. The data is displayed in the Data Source Node viewer.
See Also:
"Data Source Node Viewer"5.1.1.6 Create the Table or View Context Menu
To view the context menu, right-click the Create Table or View node. You can perform the following tasks:
-
Edit. See "Edit Create Table or View Node" for more information.
-
Run. See "Running a Data Source Node" for more information about how the node is run.
-
View Data. See "Data Source Node Viewer" for more information.
-
Parallel Query. See "About Parallel Processing" for more information.
5.1.1.7 Create the Table or View Node Properties
In the Properties pane, you can examine and change the characteristics or properties of a Create Table or View node. To manage the Create Table or View node from Properties pane:
-
Right-click the node and click Go to Properties.
-
The Properties pane opens in the lower right panel in the SQL Developer window. The name of the table or view identifies the Create Table or View property. The Properties pane consists of the following:
5.1.1.7.1 Table
Displays the name of the Table or View. You can perform the following tasks:
-
Change the name of the Table or View: If you change the default name of the table, name of the node changes to match the name of the table. For example, if you change the default name of the table to
PREDICTIONS,the name of the Create Table or View node also changes toPREDICTIONS. -
Change the object type from table to view: The default type is
Table.To create a view, click View.
5.1.1.7.2 Columns
Displays the columns of the table. The default setting enables automatic behavior. If you deselect Auto Input Column Selection, then you can manually select and edit the columns in the table. You can:
-
Delete columns: Select the column to delete and click
. -
Edit columns: Select the column and click
. Edit the required changes in:-
Select Column dialog box
-
Edit Data Guide dialog box for JSON data
-
5.1.1.7.3 Automatic Behavior
If Auto Input Column Selection is selected, then the possible scenarios are:
-
Scenario 1: When input is connected
All columns in the input node are selected. The node becomes valid. It assumes that at least one column is included in the specification. -
Scenario 2: When input is disconnected
All columns are automatically removed. The node becomes invalid. -
Scenario 3: When the input node is edited
The following are the possible edit scenarios:-
Add column: The column is added to the Create Table or View node, if it is compatible.
-
Remove column: The column is removed from the Create Table or View node.
-
Edit column: If a column is edited, any change in the column data type could trigger an invalid state in the node.
-
Note:
If the Auto Input Column Selection option is deselected, you must manually add and remove column specifications from the Create Table or View node.5.2 Data Source Node
A Data Source node defines source data for the workflow. For example, a Data Source node specifies the build data for a model. Any table or view accessible to the user can be selected as the source. This node does not allow any input node connections. Data Source nodes rely on database resources for their definitions. It may be necessary to refresh a node definition if the database resources change. For example, if the resources are deleted or re-created.
Data Source nodes can run in parallel.
Only certain data types are allowed in a Data Source node. Columns with other data types are excluded.
See Also:
-
"Supported Data Types for Data Source Nodes" for the list of supported data types
5.2.1 Supported Data Types for Data Source Nodes
Most of the basic Oracle data types are supported by the Data Source node. Object-based data types can be included, but each object type has to be well understood. Object data types require storage clauses to be defined at appropriate levels with the object hierarchy.
These data types are fully supported:
-
VARCHAR2 -
CHAR -
FLOAT -
NUMBER -
CLOB -
NESTED_NUMERICALS -
NESTED_CATEGORICALS
These data types are supported by Oracle Data Mining 12c Release 1 (12.1):
-
BINARY_DOUBLE -
BINARY_FLOAT -
DM_NESTED_BINARY_DOUBLES -
DM_NESTED_BINARY_DOUBLES -
BLOB, for Text only
The BINARY data types and BLOB are supported by Oracle Data Miner if you are connected to Oracle Data Mining 12c Release 1 (1.2) or later.
These data types for date and time are partially supported:
-
DATE -
TIMESTAMP -
TIMESTAMP_WITH_LOCAL_TIMEZONE -
TIMESTAMP_WITH_TIMEZONE -
TIMESTAMP_WITH_LOCAL_TIMEZONE
Oracle Database 12.1.0.2 supports JSON data in the following data types. Oracle Data Miner derives pseudo JSON data types from these data types:
-
VARCHAR2 -
CLOB -
BLOB -
RAW -
NCLOB -
NVARCHAR2
See Also:
"Support for Date and Time Data"5.2.2 Support for Date and Time Data
The Transform transformation partially supports the data and time data types DATE, TIMESTAMP, TIMESTAMP_WITH_LOCAL_TIMEZONE, and TIMESTAMP_WITH_TIMEZONE, as follows:
-
Attributes with data and time data types can be binned using Equal Width or Custom binning.
-
You can apply Statistic or Value missing values treatments to attributes with the data and time data types.
Attributes with data and time types are analyzed by the Explore Data node.
Data and time data types cannot be used for other functions in Oracle Data Miner. In particular, date and time data types cannot be the targets of model builds.
See Also:
5.2.3 Working with the Data Source Node
You can perform the following tasks with Data Source nodes:
5.2.3.1 Create a Data Source Node
You create a Data Source node after creating a workflow. To create a Data Source node and attach data to it:
-
In the Components pane, go to the Workflow Editor and expand Data.
If the Components pane is not visible, then in the SQL Developer menu bar, go to View and click Components. Alternately, press Ctrl+Shift+P to dock the Components pane.
-
In the Data section, click Data Source node icon.
-
Drag and drop the Data Source node from the Components pane to the Workflow pane. This adds the Data Source node to the workflow. The Define Data Source dialog box opens.
-
In the Define Data Source dialog box, you can select a table or view. By default, the tables in your schema are listed. You can add tables from other schemas to which you have access, in the Edit Schema List dialog box.
-
Click Next.
-
In the Define Data Source - Select Columns dialog box, add or remove attributes to the table.
-
Click Finish.
-
In the Select Table window, select the table or view to use. Click OK. The Properties pane displays information about the table or view that you selected. The node can now be run.
The default name of the node is the name of the table or view that you select. If
SH.CUSTOMERSas the table, the node is namedCUSTOMERS.
5.2.3.1.1 Edit Schema List
By default, tables and views from the schema to which you are connected are listed.
To add other schemas:
-
If this is the first time that you are adding schemas, then click Add Schemas.
-
If you have already added schemas, then click Edit Schemas.
The Edit Schema List dialog box opens. Available Schemas is a list of the schemas to which you have access. To display tables and views in one of these schemas, move the name to Selected Schemas.
For example, to display tables in the SH schema, move SH to the Selected Schemas list. Click OK.
You return to the Define Data Source wizard. Select Include Tables from Other Schemas. Tables and views in the added schemas are listed. For example, if you selected SH, you now see tables, such as SH.CUSTOMERS, in the Available Tables/Views list. You can select these tables as data sources.
5.2.3.2 Define a Data Source Node
You can use this interface to:
-
Define table and attributes for a new Data Source node.
-
Edit an existing data source node.
If you import a workflow that uses tables or views that are not available, then you can use this wizard to define a data source to replace the missing one. The wizard also detects input columns with JSON data types.
The wizard has two steps:
-
Select Table: Here, the tables and views to which you have access, are displayed. The schemas are the schemas to which you are connected, along with the schemas added using the Edit Schema List. Select the table or view types. The columns and data are displayed in the lower pane in the following tabs:
-
Columns: Lists the columns of the selected table in a grid. For each column, Data Type, Mining Type, Length, Precision, Scale, and Column ID are displayed.
-
Data: Displays the data in the table arranged according to Column ID.
-
To include all attributes in the table, click Finish.
-
To manually exclude certain attributes in the table, click Next.
-
To change the table selection for an existing node, click Edit Data Source Node.
-
-
-
Select Columns: By default, the Define Data Source wizard includes all columns in the Table or View. You can perform the following tasks:
-
Include a column by moving the attribute from Available Attribute to Selected Attributes section.
A drop-down list is available for JSON data. If there is an input table with JSON data, then the wizard detects the column as a JSON column and displays it in the Data Type column. If the wizard cannot detect JSON data, then you can manually change the data type for the column by clicking the drop-down list.
-
Specify Data Guide Settings: Applicable only for JSON data type. Select the attribute and click
to specify Data Guide settings in the Edit Data Guide dialog box. -
JSON Settings: Click JSON Settings to specify node settings that determines how Data Guides are generated. This option is applicable only for JSON data.
-
5.2.3.3 Edit Data Guide
The Edit Data Guide dialog box enables users to specify how data guide should be generated for a selected JSON type column. The dialog box has two tabs:
-
Structure: Displays the JSON data structure for the selected column
-
Data: Displays the content of the imported or generated Data Guide table
You can perform the following tasks:
-
Generate Data Guide: You can generate a new data guide table whenever the node is run or rerun. To generate a data guide, select any of the following options from the Data Guide Generation drop-down list:
-
Default: If the option Generate Data Guide if necessary in the JSON Settings dialog box is selected, then the data guide table is generated whenever the node is run or rerun. Otherwise, no data guide is generated.
-
On: Select this option to generate a new data guide table whenever the node is run or rerun.
-
Off: Select this option to not generate a new data guide table whenever the node is run or rerun.
-
Import from Workflow: Select this option to import a data guide from an existing JSON type column defined in a Data Source node or Create Table node within the same workflow or from a different workflow using the Select Data Guide dialog box.
-
Import from file: Select this option to import a data guide from a CSV file. The process validates the data guide, that is, it verifies the correctness of the column header, JSON path format, JSON types, and so on during an import operation.
-
-
Remove Data Guide: To delete the current Data Guide table, click
. -
Export Data Guide: Select this option to export the current data guide table to a CSV file. If you find the generated data guide does not fully represent the underlying JSON data, then you have the option to export the data guide and add any missing JSON paths. You can then import the data guide back to replace the generated one.
See Also:
5.2.3.3.1 Select Data Guide
The Select Data Guide dialog box enables you to import a data guide table from an existing JSON type column defined in a Data Source node or Create Table node within the same workflow or from a different workflow. Only completed nodes with generated JSON schema are displayed. To import a data guide table:
-
In the Show field, select a workflow from the drop-down list.
-
Select the nodes to import.
-
Click OK.
5.2.3.4 JSON Settings
In the JSON Parsing Settings dialog box, you can specify node settings that determine how data guides are generated. A data guide is used whenever a JSON structure is present in the UI, for example, JSON Query node. Because the data guide table generation could be time consuming, especially for large JSON data, the following settings offers some control on the table generation:
-
Generate Data Guide if necessary: By default, this option is selected. It generates a data guide for the JSON type columns. Deselect this option if JSON data is not used in the product. Therefore, no Data Guide will be generated.
-
Sampling: Defines how many JSON documents stored in a column are to be processed, to generate the data guide table. The JSON document contains the entire content of the JSON column for a given row.
-
Max number of documents:
2000(Default). Use the arrows to change this setting.
-
-
Limit Document Values to Process: Defines how many JSON values (Number, String, Boolean) are to be parsed in the document to generate the data guide table.
-
Max number per document:
10,000(Default). Use the arrows to change this setting.
-
5.2.3.5 Edit a Data Source Node
To edit an existing Data Source node:
-
Double-click or right-click the node and select Edit. The Edit Data Source Node opens.
-
In the Edit Data Source Node dialog box, you can change the attributes selected in the current Data Source. You can perform the following tasks:
-
Change attribute selection: To change the attribute selection, move the attributes from the Available Attributes pane to the Selected Attributes pane by using the arrows. For example, to remove ATTRIBUTE1 from the data source, move ATTRIBUTE1 from the Selected Attributes list to the Available Attributes list. After you are done, click OK.
-
Select a different table: To select a different table or view, click Edit. The Define Data Source dialog box opens.
-
See Also:
"Define a Data Source Node"5.2.3.6 Running a Data Source Node
To run a valid Data Source node, right-click the node and select Run.
The Oracle Data Miner server generates a sample of the selected table or view. The size of the table and type of sampling used is determined by the sample settings of the node.
If the node is complete but is required to provide data to a child node that is being run, then the node is run for validation to ensure that the columns and table still exist. If there are any errors, then the node state is set to Error and affected attributes are set to Invalid.
5.2.3.7 Data Source Node Context Menu
To see the context menu, right-click a Data Source node. These selections are available in the context-menu:
-
Edit: Opens the Edit a Data Source Node dialog box.
-
Attributes: Opens the Select Attributes dialog box.
-
Run: Runs the node, as described in Running a Data Source Node.
-
View Data: Opens the Data Source Node Viewer dialog box.
-
Parallel Query: See "About Parallel Processing" for more information.
-
Show Runtime Errors. Displayed only if there is an error.
-
Show Validation Errors. Displayed only if there are validation errors.
5.2.3.7.1 Select Attributes
The Select Attributes dialog box enables you to move attributes between the Available Attributes list and the Selected Attributes list. To deselect an attribute, move it to the Available Attributes list.
You can search the Available Attributes list for attributes.
Use the shuttle controls to move attributes between the lists.
When you have finished selecting attributes, click OK.
5.2.4 Data Source Node Viewer
To view data, right-click the node and select View Data from the context menu. The Data Viewer opens.
Note:
You can view data only when the Data Source node is in theValid state.The data viewer has these tabs:
5.2.4.1 Data
The Data tab displays a sample of the data. The Data Viewer provides a grid display of the rows of data either from the sampling defined in Cache, or pulled through the lineage of nodes back to the source tables.
The Data tab for MINING_DATA_BUILD_V: 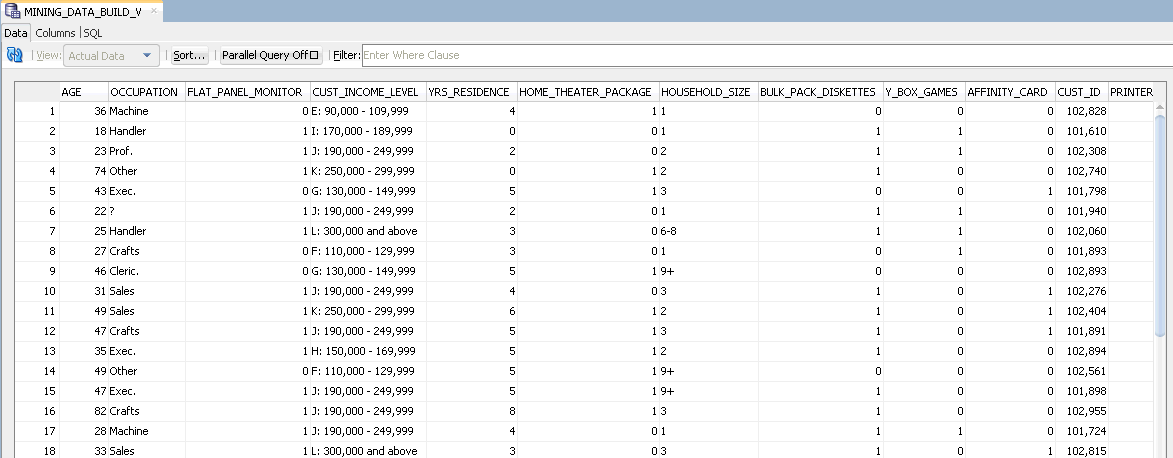
Description of the illustration viewdata.gif
You can perform the following tasks:
-
Refresh: Click
 to refresh the data.
to refresh the data. -
View: Click View and select either Actual Data or Cached Data.
Cached data is available only if you cache data in the Cache section of the Properties pane. -
Sort: Click Sort to sort data according to applicable criteria. Displays the Select Column to Sort By dialog box.
-
Filter: In the Filter field, enter a
WHEREclause to select data.
See Also:
5.2.4.1.1 Select Column to Sort By
This dialog box enables you to:
-
Select multiple columns to sort
-
Determine the column ordering
-
Determine ascending or descending order by column
-
Specify
Nulls Firstso that null values appear before real data values
The sort order is preserved until you clear it.
Column headers are also sort-enabled to provide a temporary override to the sort settings.
5.2.4.2 Graph
This tab enables you to create graphs of numeric data.
See Also:
"Graph Node" for more information.5.2.4.3 Columns
The Column tab is a list of all the columns that are output from the node. For each column, the Name, Data Type, Mining Type, Length, Precision and Scale (for floating point), and Column ID are displayed.
-
If the node has not run, the table or view structure provided by the database is displayed.
-
If the node has run successfully, then the structure of the sample table is displayed, based on the sampling defined when the node was specified.
There are several filtering options that limit the columns displayed. The filter settings with the (or)/(and) suffixes allow you to enter multiple strings separated by spaces. For example, if the Name/Data Type/Mining Type(or) is selected, then the filter string A B produces all columns where the name or the data type or the mining type starts with the letter A or B.
5.2.4.4 SQL
The SQL tab provides the SQL Details text area. The text area displays the SQL code that generates the data provided by the actual view shown in the Data tab.
The SQL can be a stacked expression that includes SQL from parent nodes, depending on what lineage is required to access the actual data.
You can copy the SQL and run it in a suitable SQL interface. Select All (Ctrl+A) and Copy (Ctrl+C) are enabled.
The Search control is a standard search control that highlights matching text and searches forward and backward.
5.2.5 Data Source Node Properties
Data Source node properties enables you to examine and change characteristics of a Data Source node. To open the Properties pane, right-click the node and select Go to Properties from the context menu. The Properties pane for a Data Source node has these sections:
See Also:
"Properties"5.2.5.1 Data
The Data section consists of the following:
-
Source Table: Displays the name of the source table or view for the Data Source node. If no source table is associated with the node, click … to the right of Source Table. A list of tables and views that are accessible from the data mining account is displayed. You can select the table or view. You can also use this process to change the table or view.
-
Data: Displays the attributes in a grid. For each attribute, the name, the alias, and the data type are displayed. You can perform the following tasks:
-
Create an alias for an attributed by entering the alias in the appropriate cell.
-
Filter attributes.
-
Delete attributes. Select the attribute and click
. -
Edit attributes. Select the attribute and click
. -
Select Attributes to include in the Data Source.
-
Refresh the node. Click
.
-
See Also:
5.2.5.2 Cache
The Cache section provides the option to generate a cache for output data. You can change this default using the transform preference.
You can perform the following tasks:
-
Generate Cache of Output Data to Optimize Viewing of Results: Select this option to generate a cache.
The default setting is to not generate a cache.-
Sampling Size: You can select caching or override the default settings.
Default sampling size isNumber of Rows
Default Value=2000
-
See Also:
"Transforms"5.2.5.3 Details
The Details section displays the name of the node and any comments about it. You can change the name and comments in the fields here:
-
Node Name
-
Node Comments
5.3 Explore Data Node
The Explore Data node provides the profile of any input data source. Explore Data Statistics can either be based on all data or on a sample of the data. The Explore Data node enables you to do the following:
-
View common statistics and a histogram for each column. Optionally, you can select a Group By attribute and have multivariate view of histograms generated.
-
Generate an output flow containing the results of all the statistical analysis. You can connect any source of data input to an Explore Data node. For example, you can attach an Explore Data node to an Apply node.
-
Analyze attributes with all supported data types and the following data types for date and time:
-
DATE -
TIMESTAMP -
TIMESTAMP_WITH_TIMEZONE -
TIMESTAMP_WITH_LOCAL_TIMEZONE
-
-
Run Explore Data node in parallel.
-
Create graphs.
-
Export the statistic generated by the Explore Data node using SQL Developer.
5.3.1 Working with the Explore Data Node
You can perform the following tasks with the Explore Data node:
5.3.1.1 Create an Explore Data Node
You create an Explore Data node and connect it to a data source to analyze the data in the data source. You can connect an Explore Data node to any data source.
To create an Explore Data node:
-
In the Components pane, go to the Workflow Editor and expand Data.
If the Components pane is not visible, then in the SQL Developer menu bar, go to View and click Components. Alternately, press Ctrl+Shift+P to dock the Components pane. -
In the Data section, click Explore Data.
-
Drag and drop the Explore Data node from the Components pane to the workflow pane. This adds the Explore Data node to the workflow.
-
Right-click the node in the workflow that you want to analyze and click Connect in the context menu.
-
Draw a line from the node to analyze to the Explore Data node and click again.
-
To generate statistics and analyze data, right-click the Explore Data node, and click Run.
-
After running the node, right-click the node and click View Data. The data is displayed in the Explore Data Node Data Viewer.
By default, all attributes in the data source are analyzed. You can specify specific attributes to analyze.
5.3.1.2 Edit the Explore Data Node
You can edit the Explore Data node by either double-clicking the node or by right-clicking the node and selecting Edit.
The Edit Explore Data Node editor has these tabs:
5.3.1.2.1 Input (Explore)
Click the Input tab to specify the attributes to analyze. By default all attributes in the data source are analyzed.
The default is to select no Group By attribute. Group By displays a sorted list of attributes that are limited to data types that can be binned by Explore Data. Selecting a Group By attribute enables you to analyze data based on the selected attribute. For example, suppose that the data contains AGE and GENDER as attributes. If you select AGE as the Group By attribute, then the histograms for GENDER show the age composition of each value of GENDER.
Change the list of attributes to analyze in either of these ways
-
Right-click the Explore Data node and select Edit. The Select Attributes dialog box opens.
-
Select the Explore Data node. The Explore tab in the Explore Data node Properties pane enables you to change the list of attributes.
5.3.1.2.2 Select Attributes
By default, all attributes of the data source are selected. If you do not want to view statistics for an attribute, move it from the Selected Attributes list to the Available Attributes list.
You can sort the lists by Name or by Data Type.
When you have finished, click OK.
5.3.1.2.3 Statistics (Explore)
Click the Statistics tab to specify the statistics to calculate. You can also change statistics in the Statistics section of Explore node Properties pane.
The statistics tab contains a list of statistics available. For each statistic, there is a brief definition and an indication of the cost to calculate that statistic.
If you change any of the default selections, click Restore Defaults to change all selections to the default selections.
You can search for an individual statistic by name.
By default, Oracle Data Miner calculates these statistics:
-
Average
-
Distinct percent
-
Maximum
-
Median
-
Minimum
-
Mode sampled
-
Percent NULLs
-
Standard deviation
-
Variance
The default statistics have a low or medium cost to calculate.
Skewness and kurtosis have a high cost to calculate. They are not selected by default. You can select them if necessary.
Calculating mode using a sample is a low cost operation. Calculating the mode using all available data is a very high cost operation. To calculate mode using sample data or all available data, click Mode (Sampled) in the Edit Explore Data Node dialog box.
See Also:
-
"Export Explore Node Calculations" for information about exporting statistics to a spreadsheet.
5.3.1.2.4 Mode (Sampled)
The default is to calculate mode using a sample of 2000 records. You can calculate the mode using all available data. This calculation has a very high cost.
To use all available data, click the Available Data option and click OK.
5.3.1.3 Perform Tasks from the Explore Data Node Context Menu
The context menu for an Explore Data node has these selections:
-
Edit: Opens the Select Attributes dialog box.
-
View Data: Opens the Data Source Node Viewer.
-
Parallel Query: See "About Parallel Processing" for more information.
-
Show Runtime Errors. Displayed only if there is an error.
-
Show Validation Errors. Displayed only if there are validation errors.
5.3.1.4 Export Explore Node Calculations
You can export the statistics calculated by an Explore node to a Microsoft Excel spreadsheet. To export:
-
When an Explore node runs, it writes the statistics that it calculates to a database table. The name of the table is in the Output section of the Explore Data node Properties pane. Suppose that the name of the table is
OUTPUT_8_3.
If the Properties pane of the node is not visible, then right-click the Explore node and select Go to Properties. -
In SQL Developer, go to the Connections tab. Expand the connection that you used for data mining.
-
Expand Tables. Find
OUTPUT_8_3and right-clickOUTPUT_8_3. -
Select Export in the context menu. The Export Wizard opens.
-
In the Export Wizard:
-
Deselect Export DDL.
-
In the Export Data section, select the version of Microsoft Excel to which you want to export from the Format drop-down list.
-
Specify a file name. Alternately, you can accept the default.
-
Click Next.
-
-
Click Finish. SQL Developer exports the table to the spreadsheet.
The spreadsheet contains the statistics. It contains the names of the histograms generated by the Explore Data node.
To export an individual histogram, right-click the histogram and save the graphic.
5.3.2 Explore Data Node Data Viewer
After the node runs successfully, you can view the data. To view the data, right-click the node and select View Data. The viewer opens in a new tab.
The viewer enables you to see the statistics and other analyses performed by the Explore Data node.
The viewer displays the information in the following tabs:
5.3.2.1 Statistics
The Statistics tab show the statistics calculated by the Explore Data node.
Attributes are listed the Statistics grid. For each attribute, the name, data type, histogram, and summary of the statistics are displayed.
To view a large version of the histogram for an attribute, select the attribute. The histogram is displayed below the grid. If the attribute has null values, then the histogram has a separate bin labeled Null bin. The histogram may also contain an Others bin consisting of values that are not NULL but are not in any other bin.
For more information about the histogram, go to the large histogram and right-click the attribute name. These choices are available:
-
Copy to Clipboard: Copies the histogram to the Microsoft Windows clipboard. You can paste this histogram in to any rich editor, such as a word processor or image editor.
-
Save Image As: Exports the image to a PNG file that can be stored in the file system.
-
View Data: Displays the data used to create the histogram in a pop up window. You can search for attribute name, attribute value, or attribute percent. Click Close when you have finished.
Histograms created by Oracle Data Miner use a sample of the data and can be slightly different each time they are displayed.
For all data types, a histogram is created. The number of distinct values, the percentage of NULL values, and the number of distinct values are displayed.
Additional statistics calculated depend on the data type of the attribute:
-
For character attributes
VARCHAR2,the Mode is calculated. -
For numeric attributes
NUMBERorFLOAT,the following are calculated:-
Average
-
Minimum value
-
Maximum value
-
Standard deviation
-
Skewness (a measure of the asymmetry of the distribution)
-
Kurtosis (a measure of flatness or peakedness of the curve describing a frequency distribution in the region about its mode)
-
5.3.3 Explore Data Node Properties
To open the Properties pane, right-click the node and select Go to Properties from the context menu.
The Explore Data node Properties pane has these sections:
5.3.3.1 Input (Properties)
The Input section lists the attributes that are analyzed.
Attributes are listed in a grid. For each attribute, the name and the data type are displayed. To sort the list of attributes by name or data type, click the heading in the grid.
You can specify a Group By attribute. Select an attribute from the list.
You can either choose the default settings or select columns:
-
To select columns, deselect Auto Input Columns Selection.
-
To delete an attribute, select it and click
. -
To edit an attribute, click
.
The Select Attributes dialog box opens.
See Also:
-
"Edit the Explore Data Node" for more information about the Group By attribute.
5.3.3.2 Statistics (Properties)
The Statistics section lists the calculated statistics.
See Also:
"Statistics (Explore)"5.3.3.3 Output
The Output section lists the columns in the data source. The names and data type of each column is listed in a grid. You can search the grid by name (the default) or by data type.
To clear the search, click ![]() .
.
5.3.3.4 Histogram
You can use bins to create histograms. This tab lists the default number of bins for the following types of bins:
-
Numerical Bins
-
Categorical Bins
-
Date Bins
-
Null Values
-
Other Values
The default number of bins for all of these bin types is 10. The default specifies a maximum number of bins.
5.3.3.5 Sample
The data is sampled to support data analysis. The default is to use a sample. The Sample tab has the following selections:
-
Use All Data: By default, Use All Data is deselected.
-
Sampling Size: The default is
Number of Rowswith a value of 2000. You can change sampling size toPercent.
The default is 60 percent.
5.4 Graph Node
A Graph node creates a two-dimensional graph of numeric data. A Graph node is not a data provider, which means that it cannot be connected to another node.
Note:
You cannot generate code from a Graph node.You can perform the following tasks:
-
Create and edit one or more graphs of different types such as line, scatter, bar, histogram, and box.
-
Create graphs with actual data and sample data.
-
Run a Graph node in parallel.
See Also:
"About Parallel Processing"5.4.1 Types of Graphs
The Graph node enables you to create two-dimensional graphs of numeric data in several ways. You can create the following types of graphs:
-
Line plot: Uses a line to connect the data points. Line plots are useful for identifying if two variable are correlated. Oracle Data Miner supports two-dimensional line plots.
-
Bar plot: Compares values. The height of the bar represents the measured value or frequency.
-
Histogram: Shows frequencies, as adjacent rectangles, erected over discrete intervals (bins), with an area equal to the frequency of the observations in the interval.
-
Scatter plot: Display values in two discrete sets. One variable determines the position on the horizontal axis and the other variable determines the position on the vertical axis.
-
Box plot or Box graph: Graphically depicts groups of numeric data using the quantiles of the data.
Graph nodes require you to specify one or more axes. Axes must consists of numeric data.
5.4.1.1 Box Plot or Box Graph
A box plot graphically depicts groups of numeric data using the quantiles of the data. The bottom and top of the box are the first and third quartiles, and the band inside the box is the second quartile (the median). In the type of box plot created by Data Miner, the whiskers show the minimum and maximum values of all the data.
5.4.2 Supported Data Types for Graph Nodes
A Graph node supports the following data types:
-
NUMBER -
FLOAT
Date and Time data types are also supported:
-
DATE -
TIMESTAMP -
TIMESTAMP_WITH_TIMEZONE -
TIMESTAMP_WITH_LOCAL_TIMEZONE
5.4.3 Working with Graph Nodes
You can create a Graph node and perform additional tasks through the context menu.
5.4.3.1 Create a Graph Node
You can create a Graph node to visualize numeric data and relationships between numeric variables.
To create a Graph node:
-
In the Components pane, go to Workflow Editor.
If the Components pane is not visible, then go to View and click Components. -
In the Workflow Editor, expand Data and click Graph.
-
Drag and drop the Graph node from the Components pane to the Workflow pane. The Graph node is added to the workflow.
-
Right-click the node that contains the data for which you want to create the graph. Select Connect from the context menu.
-
Draw a line to the Graph node and click again.
-
To create a graph using sample data, then right-click the graph node and click Run.
-
Double-click the Graph node or right-click the node and select Edit from the context menu.
-
If no graphs are defined, then the New Graph dialog box opens. You can define a graph here.
-
If a graph is defined, then in the Graph Node Editor, you can add new graphs or edit existing graphs.
-
-
After running of the graph node is complete, the graph is automatically displayed in the Graph Node Editor. You can edit the graph. You can also define new graphs, modify settings and attributes of graphs, and delete graphs.
See Also:
5.4.3.2 Graph Node Context Menu
To view the context menu, right-click a Graph node. The context menu provides the following options:
-
Edit. Opens the Edit a Data Source Node dialog box.
-
Run. See "Running Graph Node" for more information.
-
Save SQL: This option is disabled. It indicates that you cannot generate SQL query for this node.
-
Parallel Query. See "About Parallel Processing" for more information.
-
Show Validation Errors. Displayed only if there is an error.
-
Show Validation Errors. Displayed if there are validation errors.
5.4.3.2.1 Running Graph Node
To run the Graph node, right-click the Graph node and click Run. Run the Graph node to generate sample data. If you do not generate sample data, graphs are created using the data provided to the node.
Note:
If you import workflow that contains Graph nodes, you must run the Graph node to view the graphs.5.4.3.2.2 Show Graph
The Show Graph option opens the Graph Node Editor. All graphs are displayed in the Graph Node Editor.
5.4.4 New Graph
The New Graph dialog box defines a graph with a default name. You can change the name of the graph here.
Select the type of graph to create and follow the steps to define that type of graph:
The graph that you defined is displayed in a container. After you have created a graph, you can edit the definition. You can also add graphs, delete graphs, view the data used to construct a graph, and save the graph as a graphic.
5.4.4.1 Line or Scatter
To create a Line or Scatter:
-
Click Line to create a Line graph. The Line graph is the default type.
To create scatter graph, click Scatter. -
For a line graph or a scatter graph, enter the following details:
-
Title: This is the title of the graph. You can use the default name or you can provide a different name.
-
Comment: Type a description of the graph. This is an optional field.
-
For line graph settings, specify the following information:
-
X-Axis: Select an attribute for the x-axis of the graph.
-
Y-Axis: Select an attribute for the y-axis of the graph.
-
Group By: Click this option to select an optional Group By attribute. Use this option to create a series based on the Group By attribute values.
Select an attribute for Group By. To specify how the grouping is performed, click Settings.
-
-
-
Click OK.
5.4.4.2 Bar
A bar graph plots the values of a selected attribute (x-axis) against frequency counts (y-Axis). To specify a bar graph:
-
Click Bar.
-
Specify the following information for Bar Graph settings:
-
Title: This is the name of the graph. You can use the default name or you can enter a different name.
-
Comment: Provide a description for the bar graph. This is an optional field.
-
Specify the following Bar Graph settings:
-
X-Axis: Select one attribute to be plotted along the x-axis of the graph. This attribute is handled using either Top N, or Binned (the default).
To specify handling, click Settings. -
Y-Axis: Select one attribute to be plotted along the y-axis of the graph. Specify the value for frequency count as statistic. For example, Average, Min, Max Median, Count. The statistic that you choose summarizes the values in the bin.
-
Group By: Click this option to select an optional Group By attribute. This attribute groups the values in the bin (stack the bar).
Select an attribute for Group By. To specify how the grouping is performed, click Settings.
-
-
-
Click OK.
See Also:
"Settings (Graph Node)"5.4.4.3 Histogram
A histogram plots the values of a selected attribute along the x-axis against frequency counts along the y-axis. To create a histogram:
-
Click Histogram.
-
Enter the following information for the histogram:
-
Title: This is the name of the histogram. You can use the default name or you can enter a different name.
-
Comment: Enter a description of the histogram. This is an optional field.
-
Specify the following settings for the Histogram:
-
X-Axis: Select an attribute to plot along the x-axis of the graph. This attribute is handled using either Top N, or Binned (the default). To specify handling, click Settings.
-
Group By: Click Group By to select an optional Group By attribute. This attribute groups values in the bin (stack the bar).
To specify how Group By is performed, click Settings.
By default, a histogram with a Group By attribute is displayed as a Stacked Bar Graph.
Click , the Stacked Bar Graph icon, and select
, the Stacked Bar Graph icon, and select  the Dual Y Bar Graph icon.
the Dual Y Bar Graph icon.
If you specify an invalid value, a message appears explaining the problem.
-
-
-
Click OK.
See Also:
"Settings (Graph Node)"5.4.4.4 Box
A box plot summarizes binned data of a selected attribute (X axis).
-
To specify a box plot or box graph, click Box.
-
Enter the following details of the Box Graph:
-
Title: This is the name of the Box Graph. You can use the default name or you can enter a different name.
-
Comment: Enter a description of the Box Graph. This is an optional field.
-
Specify the following settings for the box graph:
-
X-Axis: Select an attribute to be plotted along the x-axis of the graph. This attribute is binned using either Top N, or Binned (the default).
To specify handling, click Settings. -
Group By: Click Group By to select an optional group by attribute. This attribute provides values on the y-axis.
To specify how the grouping is performed, click Settings.
If you specify an invalid value, a message appears explaining the problem.
-
-
-
Click OK.
5.4.4.5 Settings (Graph Node)
Depending on the data type of the attribute selected, one of these dialog boxes is displayed when you click Settings:
5.4.4.5.1 Select Values to Display
If you specify a categorical attribute for an axis or the Group By attribute, click Settings to display the Select Values to Display dialog box.
The values of the attribute are listed in the Values column. Select values in one of the following:
-
All
-
None
-
Default
By default, the most frequent values using Top N is selected.
-
Select specific values by clicking the check box for the values.
You can search for values using the search box.
When you have finished, click OK to return to the definition of the graph.
5.4.4.5.2 Axis Treatment
If you specify a numeric attribute for an axis or Group By attribute, click Settings to display the Axis Treatment Settings dialog box.
The options are:
-
Raw Values (as is)
-
Binned automatically: Use Equal width binning for the axis values. The default number of bins is 10. You can change this value.
The default is to not show null values. To show null values, click the check box.
Click OK to return to the definition of the graph.
5.4.5 Graph Node Editor
If at least one graph is defined for a Graph node, double-click the Graph node to open the Graph Node Editor.
If no graphs are defined, then the New Graph dialog box opens.
The editor displays all defined graphs. Each graph is in a container. The graph containers are laid out in a grid.
You can modify an existing graph or add graphs to the node. You can also zoom in to view details of a graph.
These icons are applicable to all graphs in the node:
-
To add a new graph, click
 to open the New Graph dialog box.
to open the New Graph dialog box. -
To refresh the display, click
. -
To select data used to create the graph, click View. The options are:
-
Actual Data: Displays the default unless you have run the Graph node. In this case, the node creates the graph using whatever data is provided.
-
Sample Data: Available only if you have run the Graph node to generate sample data.
-
The name of the new or existing graph is displayed at the top of the container for the graph, along with these controls:
-
To adjust the size of the graph (zoom in and out), click
 .
. -
To edit the current graph, click
. When you edit or add a graph, the results are automatically displayed in the editor. -
To delete the current graph, click
. -
To examine specific values of the graph, zoom the graph.
See Also:
5.4.5.1 Zoom Graph
To examine details of a graph, zoom in on the selected values. For example, to see more detail for selected x-axis values, draw a selection box with the mouse that encloses the values. The display shows values in the selection box in more detail and the axis expands. You can zoom in multiple times. When you have finished viewing the selected values, click the graph once for each time that you zoomed in to return to the original graph.
5.4.5.2 Viewing Data used to Create Graph
To view the data used to create the graph or to save the graph as a graphic:
-
Right-click the graph and select an one of the following options:
-
Select any one of the following options:
-
Copy to Clipboard: Copies the graph to the Microsoft Windows clipboard
-
Save Image As: Saves the graph in a PNG file format
-
View Data: Displays the data used to create the graph
-
5.4.6 Edit Graph
When you edit a graph, you can do the following:
-
Change the attributes of the existing graph type. For example, if you edit a line graph, you can change the x-axis and y-axis or add a Group By attribute. You can change the axis treatment or values to display if the graph uses these items.
-
Specify a different graph type. You can change the type of graph. For example, you can change a line graph to a histogram. To change the type of the graph, click the button at the top of the window and specify the required information:
5.4.7 Graph Node Properties
Graph node properties is identified by the node name that you are viewing. In the Properties pane, you can examine and change characteristics of a Graph node.
To open Properties pane, right-click the node and select Go to Properties.
The Properties pane of a Graph node consists of these sections:
-
Data: Indicates the Cache Settings to use.
See Also:
"Properties"5.4.7.1 Cache (Graph Node)
After you generate sample data, the option Generate Cache of Output Data to Optimize Viewing Results is selected.
The default value is 2000 records. You can change this value.
5.5 SQL Query Node
A simple use case for SQL Query node is to write a SQL query that performs special data preparation. Use the SQL Query node to provide input for a model build. A SQL Query node enables you to do the following:
-
Manually enter a SQL query with the least amount of constraints possible.
-
Incorporate a broader array of methodologies as part of an Oracle Data Miner workflow. You can insert any SQL query as a source of data or as a transformation by using existing data.
-
Run Oracle R Enterprise scripts that are registered for the database.
-
Run parallel processes or parallel queries.
See Also:
5.5.1 Input for SQL Query Node
A SQL Query node requires the following input:
-
Zero to many data provider nodes, such as Data Source nodes and Transform nodes.
-
Zero to many input model provider nodes, such as Model Build nodes and Model nodes.
Data provider nodes are used as follows:
-
If there are no data provider nodes, then you define an originating Data Source node using an
SQL SELECTstatement that is not constrained by any input sources that must be defined within Oracle Data Miner. The statement can contain its own internal table references, such as:Select * from a, b where a.id = b.id
When there are no data provider nodes, the source tables or views are hidden from Data Miner. Code generation cannot parameterize such tables in the generated SQL script.
-
If there are one or more data provider nodes, then you can reference each data flow within the expression builder interface. You can continue to expose all data sources within the Oracle Data Miner workflow.
When a model provider node is connected as input, it enables you to see the list of model names contained in the node. This is useful in creating SQL that requires a model name.
Oracle Data Miner includes snippets that help you write SQL queries.
See Also:
"Snippets in Oracle Data Miner"5.5.2 SQL Query Restriction
SQL is limited to a query that returns a flow of data. A SQL Query node can provide data to any node that requires data, such as a node that builds a model.
5.5.3 Oracle R Enterprise Script Support
Oracle R Enterprise, a component of the Oracle Advanced Analytics option, makes the open source R statistical programming language and environment ready for the enterprise and big data. Oracle R Enterprise integrates R with Oracle Database. It is designed for problems that involve large amounts of data.
R users can develop, refine, and deploy R scripts that leverage the parallelism and scalability of the database to perform predictive analytics and data analysis.
The SQL Query node in Oracle Data Miner 4.1 provides a simplified interface for integrating R scripts that have been registered with the database. This enables R developers to provide useful scripts for analyzing data.
Note:
Oracle R Enterprise must be installed with the server in the same database to which Oracle Data Miner connects to. See Oracle R Enterprise Installation and Administration Guide for more information.You can run embedded R scripts that use theses interfaces:
-
rqEval -
rqTableEval -
rqRowEval -
rqGroupEval
5.5.3.1 Oracle R Enterprise Database Roles
The Oracle R Enterprise database roles are added to the OMDRUSER role. The OMDRUSER role includes both these two roles:
-
RQUSER -
RQADMIN
If the RQUSER and RQAMIN roles are not available in the database configuration at the time of Oracle Data Miner repository installation, then the roles must be added by the DBA manually to the ODMRUSER role after Oracle R Enterprise is installed.
You must register R scripts before you can use them. You can register scripts using SQL*Plus or SQL Worksheet, using the SYS connection.
Registered R Scripts are listed on the R Scripts tab of the SQL Query node. There are also R code snippets, which are code fragments that help you write scripts. Some snippets are just syntax, and others are examples. You can insert and edit snippets when you are using SQL Worksheet or creating or editing R code using SQL Query node.
5.5.4 Working with SQL Query Node
You can create a SQL Query node and also perform related tasks through the context menu and the SQL Query Node editor:
5.5.4.1 Create a SQL Query Node
You create a SQL Query node to write a SQL query. To create a SQL Query node:
-
In the Components pane, go to Workflow Editor.
If the Components pane is not visible, then go to View and click Components. -
Create zero or more data provider nodes, such as Data Source nodes or Transform nodes.
-
Create zero or more model provider nodes, such as Model Build nodes or Model nodes.
-
In the Workflow Editor, expand Data, and click Create SQL Query.
-
Drag and drop the SQL Query node in the workflow pane. The SQL Query node is added to the workflow.
-
Right-click the data provider and or model provider nodes. For each node, select Connect from the context menu.
-
Draw a line to the SQL Query node and click again. Ensure that you connect all the required nodes.
-
Open SQL Query Node Editor by double-clicking the SQL Query node or by selecting Edit from the context node.
-
Write the SQL query, and validate or preview it.
-
Click OK.
See Also:
"SQL Query Node Editor"5.5.4.2 SQL Query Node Editor
The SQL Query node Editor enables you to define and validate a SQL query.
The editor provides specifications that can be dragged and dropped or double-clicked into the query build text area.
The tabs on the left of the window provide help in writing a query:
-
Source is a list of input nodes that includes both Data Provider nodes and Model Provider nodes. When you select an item in the Source list, information appears in the Message box.
-
Snippets are standard SQL Developer Snippets (SQL code fragments) arranged by the type of calculation.
The snippet category Predictive Query helps write queries using the
DBMS_PREDICTIVE_ANALYTICS PL/SQLpackage.For information about snippets, see ”Using Snippets to Insert Code Fragments” in SQL Developer Concepts and Usage.
For a brief description of snippet functionality, move the cursor over the name. The information is displayed in a tool tip.
-
PL/SQL Functions is a list of PL/SQL functions by user schema.
-
R Scripts is a list of registered R Scripts; this tab is displayed if Oracle R Enterprise is installed.
Write SQL in the text area.
Below the text area are:
-
Columns—List the columns and data types.
-
Preview—Displays a small number of the rows returned by the query.
When you click OK or Validate, the following are verified:
-
The query generates at least one column of output.
-
All data types are data types that Oracle Data Miner supports. Most scalar data types are supported. The most common data types that are not supported are user custom object types.
If unsupported data types are found, then a table is created and an error message is displayed above the column panel. All unacceptable data types in the column list are marked with an invalid icon next to the column name.
-
If no validation errors occur during the parsing of the query, then the Columns tab shows data types of the columns and the Data tab shows a small sample of results.
If a validation error occurs, then the validation panel is displayed for the Column and Data tabs.
5.5.4.3 SQL Query Node Context Menu
To see the context menu, right-click a Data Source node. The following options are available in the context menu:
-
Edit. Opens the SQL Query Node Editor.
-
Parallel Query. See "About Parallel Processing" for more information.
-
Show Runtime Errors. Displayed only if there is an error.
-
Show Validation Errors. Displayed if there are validation errors.
5.6 Update Table Node
An Update Table node updates an existing table with selected columns from the data input to the node. Input columns are mapped to the existing table columns.
Update Table node can run in parallel.
Update Table nodes rely on database resources for their definitions. It may be necessary to refresh a node definition if the database resources change. For example, if the resources are deleted or re-created.
See Also:
5.6.1 Input and Output for Update Table Node
The input for an Update Table node is any node that produces a data flow. You can connect only one node to an Update Table node.
The output of an Update Table node is a data flow. You can use the data flow as a data source. To save the output as a table or view, use a Create Table or View node.
See Also:
"Create Table or View Node"5.6.2 Data Types for Update Table Node
Update Table node supports certain data types. You can also support other types, such as B, and also supports these additional types with manual mapping.
You can manually map columns that do not have exact data type matches but the column data types have reasonable, safe implicit conversion default. For example, you can map BINARY_DOUBLE to NUMBER, or NVARCHAR2 to VARCHAR2. There could be some loss of data for such mappings:
-
Mapping
BINARY_DOUBLEorBINARY_FLOATtoNUMBERcould result in the loss of precision -
Mapping
NVARCHAR2andNCHARtoVARCHAR2can result in the loss of data becauseNVARCHAR2andNCHARare based on a potentially different character set thanVARCHAR2.For mappings to work, your database must be set up so thatNVARCHAR2andNCHARare based on the same character set asVARCHAR2.
5.6.3 Working with Update Table Node
You can create an Update Table node and perform related tasks through the context menu and the editor, as listed in the following topics:
5.6.3.1 Create Update Table Node
You create an Update Table node to update an existing table with data from selected columns in the table. You can connect an Update Table node to any node that creates a data flow, such as an Apply node.
To create an Update Table node:
-
In the Components pane, go to Workflow Editor. If the Components pane is not visible, then go to View and click Components.
-
In Workflow Editor, expand Data, and click Update Table.
-
Drag and drop the Update Table node in the workflow pane. This adds the Update Table node to the workflow.
-
Move the mouse to the node in the workflow that produces the data flow to update. Right-click the node, and select Connect from the context menu.
-
Draw a line to the Update Table node and click again.
-
The Edit Update Table Node dialog box opens. You can define the characteristics of the Update Table node.
-
You can do either of the following:
-
Accept the default settings for the Table Update node.
-
Edit the default settings in Edit Update Table node.
-
-
To update the table, right-click the Update Table node, and select Run.
-
After running of the Update Table node is complete, you can view the results. Right-click the node and select View Data.
5.6.3.1.1 Update Table Node Automatic Behavior
If the Auto Input Column Selection option is selected, then the behavior under the following scenarios are:
-
When input is connected—If the Update Table node has a selected table to update, then any column that matches the existing columns in the table are mapped to that column automatically. The node becomes valid, if at least one column was included in the specification.
-
When input is disconnected—All columns are automatically removed. The node becomes invalid.
-
When the input node is edited:
-
If a column is added to the input node, the column is added to the update node, if there is a matching column in the existing table.
-
If a column is removed, then the column is removed from the node.
-
If a column is edited, then there are two possibilities:
-
If the edited column no longer matches an existing column, then it is removed.
-
If the edited column matches an existing column, then it is added.
-
-
If Auto Input Column Selection is not selected, then you must manually add and remove column specifications from the Update Table node.
5.6.3.2 Edit Update Table Node
The Edit Update Table dialog box provides the specification for the Update Table node. To edit the Update Table node:
-
Name: Displays the name of the table. You can select an existing table by clicking Browse Table and select an existing table. Or you can create a new table by clicking New. S
-
Auto Input Columns Selection: This option is selected by default. To select other columns, deselect this option.
If you deselect this option, then click to select an input column. Use the arrows to move attributes from Available Attributes to Selected Attributes. -
Drop Existing Rows: If this option is selected, then existing rows in the table are dropped before the table is updated. By default, the option is not selected.
-
Columns are listed in the Data grid.
See Also:
5.6.3.2.1 Create Table (Update Table)
You can either accept the name for the new table or select a different name. All of the attributes of the attached table are listed.
-
To delete an attribute, click
. -
To edit an attribute, click
.
The Select Attributes (Update Table) dialog box opens.
5.6.3.2.2 Select Attributes (Update Table)
By default, all columns are selected. If you do not want to include a column in the data, then move the attribute from Selected Attributes to Available Attributes.
Click OK.
5.6.3.2.3 Edit Columns (Update Table)
This tab displays the columns of the table to be updated. For each column, the Input Name, Target Name and Target (data) type are displayed.
By default, the option Auto Input Columns Selection is selected. If you deselect Auto Input Columns Selection, then you must manually select input columns by clicking ![]() .
.
Use the arrows to move the attributes from Available Attributes to Selected Attributes.
See Also:
"Update Table Node Automatic Behavior"5.6.3.3 Update Table Node Context Menu
To see the context menu, right-click a Data Source node. The following options are available in the context menu:
-
Edit. Opens the Edit Update Table Node dialog box.
-
View Data. Opens the Update Table Node Data Viewer dialog box.
-
Parallel Query. See "About Parallel Processing" for more information.
-
Show Runtime Errors. Displayed only if there is an error.
-
Show Validation Errors. Displayed only if there are validation errors.
5.6.4 Update Table Node Data Viewer
After the node runs successfully, you can view the data. To view the data, right-click the node and select View Data. The data viewer is the same as Data Source Node Viewer.
5.6.5 Update Table Node Properties
To view the Properties pane, right-click the node and select Go to Properties from the context menu.
Update Table Properties consists of these sections:
5.6.5.1 Table (Update Table)
This tab displays the name of the table to update. The default is to not drop existing rows. To drop existing rows, select Drop Existing Rows.
5.6.5.2 Columns (Update Table)
This tab displays the columns of the table that are to be updated. For each column, Input Name, Target Name and Target (data) type are displayed.
By default, the Auto Input Columns Selection is selected.
If you deselect the Auto Input Columns Selection, then you must manually select input columns by clicking ![]() . Use the arrows to move the attributes from Available Attributes list to Selected Attributes list.
. Use the arrows to move the attributes from Available Attributes list to Selected Attributes list.
If data on the server changes, then it may be necessary to refresh the nodes. To refresh, click ![]() .
.