| Oracle® Database SQL言語リファレンス 12cリリース1 (12.1) B71278-13 |
|


 前 |
 次 |
構文
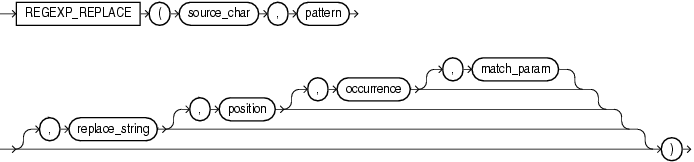
用途
REGEXP_REPLACEは、正規表現パターンで文字列を検索できるようにREPLACEの機能を拡張したものです。デフォルトでは、このファンクションは、正規表現パターンに一致するすべての文字をreplace_stringに置き換えてsource_charを戻します。source_charと同じキャラクタ・セットの文字列が戻されます。このファンクションは、1つ目の引数がLOBではない場合はVARCHAR2を戻し、1つ目の引数がLOBの場合はCLOBを戻します。
このファンクションは、POSIX正規表現規格およびUnicode Regular Expression Guidelinesに準拠しています。詳細は、付録D「Oracleの正規表現のサポート」を参照してください。
source_charは、検索値として使用される文字式です。一般的には文字の列であり、データ型はCHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOB、NCLOBのいずれかになります。
patternは正規表現です。通常はテキスト・リテラルであり、データ型はCHAR、VARCHAR2、NCHARまたはNVARCHAR2のいずれかになります。ここには、 512バイトまで入力できます。patternのデータ型がsource_charのデータ型と異なる場合、Oracleはpatternをsource_charのデータ型に変換します。patternで指定できる演算子のリストは、付録D「Oracleの正規表現のサポート」を参照してください。
replace_stringは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。replace_stringがCLOBまたはNCLOBの場合、replace_stringは32KBに切り捨てられます。replace_stringには、最大500個の部分正規表現への後方参照を\nという書式で指定できます。nは、1から9の数値です。replace_stringにバックスラッシュ(\)を含める場合、その前にエスケープ文字(これもバックスラッシュ)を付ける必要があります。たとえば、\2を置き換えるには、\\2を入力します。後方参照表現の詳細は、「Oracleの正規表現のサポート」の表D-1に示す説明を参照してください。
positionは、Oracleが検索を開始する文字source_charの位置を示す正の整数です。デフォルトは1で、source_charの最初の文字から検索が開始されます。
occurrenceは、置換操作の対象となる文字を示す、負ではない整数です。
0(ゼロ)を指定すると、一致したすべての文字が置換されます。
正の整数nを指定すると、n番目に一致した文字が置換されます。
occurrenceが1より大きい場合、1番目のpatternが検出された後に続く1文字目から、2番目(以降)の出現を検索します。この動作は、最初の出現の2番目の文字から2番目の出現を検索するINSTRファンクションとは異なります。
match_parameterは、ファンクションのデフォルトの検索動作を変更するためのテキスト・リテラルです。このパラメータの動作は、REGEXP_COUNTのこのファンクションの動作と同じです。詳細は、「REGEXP_COUNT」を参照してください。
例
次の例では、phone_numberを調べて、xxx.xxx.xxxxというパターンを検索します。その後、このパターンを(xxx) xxx-xxxxという書式に変更します。
SELECT
REGEXP_REPLACE(phone_number,
'([[:digit:]]{3})\.([[:digit:]]{3})\.([[:digit:]]{4})',
'(\1) \2-\3') "REGEXP_REPLACE"
FROM employees
ORDER BY "REGEXP_REPLACE";
REGEXP_REPLACE
--------------------------------------------------------------------------------
(515) 123-4444
(515) 123-4567
(515) 123-4568
(515) 123-4569
(515) 123-5555
. . .
次の例では、country_nameを調べます。文字列内のNULLでない各文字の後に空白を挿入します。
SELECT REGEXP_REPLACE(country_name, '(.)', '\1 ') "REGEXP_REPLACE" FROM countries; REGEXP_REPLACE -------------------------------------------------------------------------------- A r g e n t i n a A u s t r a l i a B e l g i u m B r a z i l C a n a d a . . .
次の例では、文字列を調べて、2つ以上の空白を検索します。検索された2つ以上の空白を、それぞれ1つの空白に置換します。
SELECT
REGEXP_REPLACE('500 Oracle Parkway, Redwood Shores, CA',
'( ){2,}', ' ') "REGEXP_REPLACE"
FROM DUAL;
REGEXP_REPLACE
--------------------------------------
500 Oracle Parkway, Redwood Shores, CA
