| Oracle® Streams概要および管理 12cリリース1 (12.1) B71329-02 |
|


 前 |
 次 |
Oracle Streamsでの情報の取得とは、情報を含むメッセージを作成し、そのメッセージをキューにエンキューすることです。取得される情報は、データベースの変更に関する説明の場合もあれば、その他の情報である場合もあります。
次の各項では、Oracle Streamsによる情報の取得の概念について説明します。
単一データベースで複数の取得プロセスを実行する場合は、各インスタンスのシステム・グローバル領域(SGA)のサイズを増やしてください。SGAサイズを増やすには、SGA_MAX_SIZE初期化パラメータを使用します。また、Oracle Streamsプールのサイズがデータベースで自動管理されていない場合は、取得プロセスの並列性ごとにOracle Streamsプールを 10MB増やす必要があります。たとえば、2つの取得プロセスがデータベースで実行されており、parallelismパラメータが一方の取得プロセスでは4、もう一方の取得プロセスでは1に設定されている場合、Oracle Streamsプールを50MB(並列性は4+1=5)増やします。
また、取得プロセス、伝播または取得プロセスで使用される各ANYDATAキューには、特定のソース・データベースの最大1つの取得プロセスからの取得LCRを格納することをお薦めします。したがって、特定のソース・データベースで行われた変更を取得する各取得プロセスで個別のキューを使用し、各キューに独自のキュー表があることを確認します。また、同じソース・データベースの2つ以上の取得プロセスからのメッセージが同じキューに伝播されないようにしてください。
|
注意: MEMORY_TARGET、MEMORY_MAX_TARGETまたはSGA_TARGET初期化パラメータが0(ゼロ)以外の値に設定されている場合、Oracle Streamsプールのサイズは自動的に管理されます。 |
|
関連項目:
|
チェックポイントは、取得プロセスの現在の状態に関する情報です。この情報は、取得プロセスを実行しているデータベースのデータ・ディクショナリに永続的に格納されます。取得プロセスでは、チェックポイント間隔と呼ばれる定期的な間隔でチェックポイントの記録が試行されます。
取得プロセスでREDOデータが必要となる最小のチェックポイントに対応するシステム変更番号(SCN)は、必須チェックポイントSCNと呼ばれます。必須チェックポイントSCNが含まれているREDOログ・ファイルおよび後続のすべてのREDOログ・ファイルが、取得プロセスで使用可能である必要があります。取得プロセスを停止して再起動すると、REDOログのスキャンは、必須チェックポイントSCNに対応するSCNから開始されます。必須チェックポイントSCNは、データベースが予期せず停止した場合のリカバリで重要となります。また、取得プロセス用に先頭SCNをリセットする場合は、取得プロセスの必須チェックポイントSCN以下の値に設定する必要があります。取得プロセスの必須チェックポイントSCNを確認するには、DBA_CAPTUREデータ・ディクショナリ・ビューのREQUIRED_CHECKPOINT_SCN列を問い合せます。
取得プロセスによって記録された最後のチェックポイントに対応するSCNは、最大チェックポイントSCNと呼ばれます。ソース・データベースから変更を取得する取得プロセスを作成し、同じソース・データベースから変更を取得する別の取得プロセスが存在している場合は、既存の取得プロセスの最大チェックポイントSCNを使用して、新しい取得プロセスでLogMinerデータ・ディクショナリを作成するか、既存のLogMinerデータ・ディクショナリのいずれかを共有するかを決定できます。取得プロセスの最大チェックポイントSCNを確認するには、DBA_CAPTUREデータ・ディクショナリ・ビューのMAX_CHECKPOINT_SCN列を問い合せます。
チェックポイント保存時間とは、チェックポイントが自動的に消去されるまで取得プロセスによって保持される時間(日数)のことです。取得プロセスでは、取得プロセスの必須チェックポイントSCNが含まれているアーカイブREDOログ・ファイルのFIRST_TIMEから、チェックポイントに対応するアーカイブREDOログ・ファイルのNEXT_TIMEを差し引くことによって、チェックポイントの経過時間が定期的に計算されます。計算された値がチェックポイント保存時間より大きい場合、先頭SCN値を進めることによってチェックポイントが自動的に消去されます。計算された値がチェックポイント保存時間より小さい場合、チェックポイントは保持されます。DBA_REGISTERED_ARCHIVED_LOGビューにはアーカイブREDOログ・ファイルのFIRST_TIMEおよびNEXT_TIMEが表示され、DBA_CAPTUREビューのREQUIRED_CHECKPOINT_SCN列には取得プロセスの必須チェックポイントSCNが表示されます。
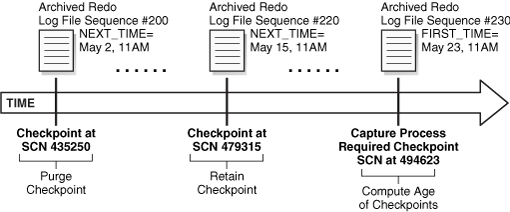
図7-1に、チェックポイント保存期間が20日に設定されている場合のチェックポイントの消去の例を示します。
図7-1では、チェックポイント保存時間が20日に設定されています。経過時間が21日のSCN 435250のチェックポイントは消去され、経過時間が8日のSCN 479315のチェックポイントは保持されています。
取得プロセスの先頭SCNがリセットされるたびに、取得プロセスによって、新しい先頭SCNより前のアーカイブREDOログ・ファイルに関する情報がLogMinerデータ・ディクショナリから消去されます。この情報が消去された後、アーカイブREDOログ・ファイルはハード・ディスクに残りますが、これらのファイルは取得プロセスでは不要となります。不要となったアーカイブREDOログ・ファイルに対して、DBA_REGISTERED_ARCHIVED_LOGビューのPURGEABLE列にYESが表示されます。これらのファイルをディスクから削除したり、別の場所に移動しても、取得プロセスに影響はありません。
DBMS_CAPTURE_ADMパッケージのCREATE_CAPTUREプロシージャを使用して取得プロセスを作成する場合、checkpoint_retention_timeパラメータを使用して、チェックポイント保存時間(日数)を指定できます。CREATE_CAPTUREプロシージャにcheckpoint_retention_timeパラメータを指定しなかった場合、またはDBMS_STREAMS_ADMパッケージを使用して取得プロセスを作成する場合、デフォルトのチェックポイント保存時間の60日が使用されます。DBA_CAPTUREビューのCHECKPOINT_RETENTION_TIME列に、取得プロセスの現在のチェックポイント保存時間が表示されます。
取得プロセスのチェックポイント保存時間を変更するには、DBMS_CAPTURE_ADMパッケージのALTER_CAPTUREプロシージャで新しい期間を指定します。取得プロセスのチェックポイントが自動的に消去されないようにするには、CREATE_CAPTUREまたはALTER_CAPTUREのcheckpoint_retention_timeパラメータにDBMS_CAPTURE_ADM.INFINITEを指定します。
|
注意: 取得プロセスのチェックポイント保存時間を指定するには、取得プロセスが実行されているデータベースの互換性レベルが10.2.0以上である必要があります。データベースの互換性レベルが10.2.0未満の場合は、データベースで実行されているすべての取得プロセスのチェックポイント保存時間が無期限になります。 |
|
関連項目:
|
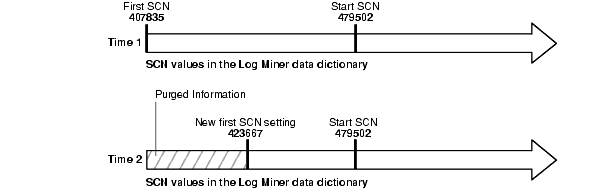
既存の取得プロセスに対する先頭SCN値をリセットする場合、またはチェックポイントの消去時に先頭SCNが自動的にリセットされる場合は、新しい先頭SCNの設定前にLogMinerデータ・ディクショナリ情報が自動的に消去されます。取得プロセスの開始SCNが、消去されたREDO情報に対応している場合は、開始SCNが先頭SCNと同じ値に自動的にリセットされます。ただし、開始SCNが新しい先頭SCNの設定より大きい場合、開始SCNは変更されません。
図7-2に、新しい先頭SCNの設定前にLogMinerデータ・ディクショナリ情報が自動的に消去される仕組み、および開始SCNが新しい先頭SCNの設定値より大きい場合に開始SCNが変更されない仕組みを示します。
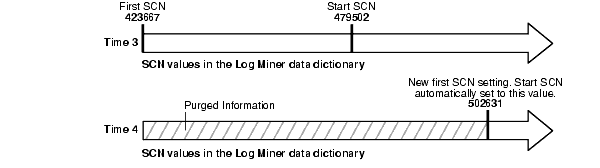
この例に示されているように、先頭SCNが取得プロセスの開始SCNより大きい値に再度リセットされた場合、開始SCNはLogMinerデータ・ディクショナリ内の既存の情報に対応しなくなります。図7-3に、開始SCNが新しい先頭SCNの設定より小さい場合、開始SCNが自動的にリセットされる仕組みを示します。
この図に示されているように、取得プロセスの先頭SCNおよび開始SCNは、時間の経過に伴い大きくなる場合があります。先頭SCNは、大きくなることによって、DBMS_CAPTURE_ADM.BUILDプロシージャで設定したSCNに対応しなくなる可能性があります。
|
関連項目:
|
次に、異なるタイプの取得プロセスによるREDOデータの読取り方法について説明します。
ローカル取得プロセスでは、可能な場合、REDOログ・バッファを読み取ります。ログ・バッファを読み取ることができない場合は、オンラインREDOログを読み取ります。ログ・バッファまたはオンラインREDOログを読み取ることができない場合は、アーカイブREDOログ・ファイルを読み取ります。このため、ローカル取得プロセスが変更を取得するように構成されている場合は、ソース・データベースをARCHIVELOGモードで実行している必要があります。
リアルタイム・ダウンストリーム取得プロセスでは、可能な場合、ソース・データベースのオンラインREDOデータを読み取ります。これが可能ではない場合は、ソース・データベースからREDOデータが含まれているアーカイブREDOログ・ファイルを読み取ります。この場合、ソース・データベースからのREDOデータはダウンストリーム・データベースのスタンバイREDOログに格納され、スタンバイREDOログのREDOデータはダウンストリーム・データベースのアーカイバによって格納されます。このため、リアルタイム・ダウンストリーム取得プロセスが変更を取得するように構成されている場合は、ソース・データベースとダウンストリーム・データベースの両方をARCHIVELOGモードで実行している必要があります。
アーカイブ・ログ・ダウンストリーム取得プロセスでは、常にソース・データベースからアーカイブREDOログ・ファイルを読み取ります。このため、アーカイブ・ログ・ダウンストリーム取得プロセスが変更を取得するように構成されている場合は、ソース・データベースをARCHIVELOGモードで実行している必要があります。
取得プロセスの必須チェックポイントSCNを判別するには、DBA_CAPTUREデータ・ディクショナリ・ビューのREQUIRED_CHECKPOINT_SCN列を問い合せます。取得プロセスを再起動すると、必須チェックポイントSCN以降のREDOログがスキャンされます。このため、必須チェックポイントSCNが含まれているREDOログ・ファイルおよび後続のすべてのREDOログ・ファイルが取得プロセスに対して使用可能になっている必要があります。
アーカイブREDOログ・ファイルは、アーカイブREDOログ・ファイルを必要とする取得プロセスが存在しなくなるまで使用可能にしておく必要があります。取得プロセスの先頭SCNは、大きい値にリセットすることはできますが、小さい値にリセットすることはできません。このため、取得プロセスでは、先頭SCNより前の情報が含まれているREDOログ・ファイルは必要ありません。いずれの取得プロセスでも必要とされないアーカイブREDOログ・ファイルを判別するには、DBA_LOGMNR_PURGED_LOGデータ・ディクショナリ・ビューを問い合せます。
ローカル取得プロセスで遅延が発生すると、オンラインREDOログの読取りからアーカイブREDOログの読取りへとシームレスに推移し、ローカル取得プロセスで遅延が取り戻されると、アーカイブREDOログの読取りからオンラインREDOログの読取りへとシームレスに推移します。同様に、リアルタイム・ダウンストリーム取得プロセスで遅延が発生すると、スタンバイREDOログの読取りからアーカイブREDOログの読取りへとシームレスに推移し、リアルタイム・ダウンストリーム取得プロセスで遅延が取り戻されると、アーカイブREDOログの読取りからスタンバイREDOログの読取りへとシームレスに推移します。
|
注意: ダウンストリーム取得プロセス構成のダウンストリーム・データベースでは、リモート・ソース・データベースのログ・ファイルを、ローカル・データベースとは別に格納する必要があります。また、ダウンストリーム・データベースに複数のソース・データベースからのログ・ファイルが含まれている場合は、各ソース・データベースからのログ・ファイルを個別に格納する必要があります。 |
|
関連項目:
|
取得プロセスは、DBMS_STREAMS_ADMパッケージまたはDBMS_CAPTURE_ADMパッケージのプロシージャを使用して作成できます。DBMS_STREAMS_ADMパッケージのプロシージャを使用すると、いくつかの構成オプションにデフォルトが自動的に使用されるため、取得プロセスをより簡単に作成できます。また、DBMS_STREAMS_ADMパッケージのプロシージャを使用すると、取得プロセスに対してルール・セットが作成され、このルール・セットに自動的にルールを追加することができます。ルール・セットは、そのプロシージャでinclusion_ruleパラメータがTRUEに設定されている場合(デフォルト)はポジティブ・ルール・セット、inclusion_ruleパラメータがFALSEに設定されている場合はネガティブ・ルール・セットになります。
DBMS_CAPTURE_ADMパッケージのCREATE_CAPTUREプロシージャを使用すると、より柔軟に取得プロセスを作成できます。取得プロセスの作成前または作成後に1つ以上のルール・セットおよびルールを作成します。DBMS_STREAMS_ADMパッケージまたはDBMS_RULE_ADMパッケージのプロシージャを使用すると、取得プロセスのルール・セットにルールを追加できます。ダウンストリーム・データベースで取得プロセスを作成するには、 DBMS_CAPTURE_ADMパッケージを使用する必要があります。
DBMS_STREAMS_ADMパッケージのプロシージャを使用して取得プロセスを作成し、この取得プロセスのポジティブ・ルール・セットに1つ以上のルールを生成すると、変更を取得されるオブジェクトがインスタンス化のために自動的に準備されます。ただし、この取得プロセスがダウンストリーム取得プロセスで、ダウンストリーム・データベースからソース・データベースへのデータベース・リンクが存在しない場合は除きます。
DBMS_CAPTURE_ADMパッケージのCREATE_CAPTUREプロシージャを使用して取得プロセスを作成する場合は、変更を取得するすべてのオブジェクトのインスタンス化を準備する必要があります。取得プロセスの作成後、できるだけ早く、これらのオブジェクトのインスタンス化を準備してください。オブジェクトのインスタンス化を準備するには、DBMS_CAPTURE_ADMパッケージの次のいずれかのプロシージャを使用します。
PREPARE_TABLE_INSTANTIATION: 単一表をインスタンス化のために準備します。
PREPARE_SCHEMA_INSTANTIATION: スキーマ内のすべてのオブジェクトおよび将来そのスキーマに追加されるすべてのオブジェクトをインスタンス化のために準備します。
PREPARE_GLOBAL_INSTANTIATION: データベース内のすべてのオブジェクトおよび将来そのデータベースに追加されるすべてのオブジェクトをインスタンス化のために準備します。
これらのプロシージャを使用して、インスタンス化のために準備された表のキー列またはすべてのキー列のサプリメンタル・ロギングを有効にすることもできます。
|
関連項目:
|
取得プロセスには、ソース・データベースのプライマリ・データ・ディクショナリとは別個のデータ・ディクショナリが必要です。この別個のデータ・ディクショナリは、LogMinerデータ・ディクショナリと呼ばれます。特定のソース・データベースに対して、複数のLogMinerデータ・ディクショナリが存在する場合があります。ソース・データベースから変更を取得する複数の取得プロセスが存在する場合は、複数の取得プロセスで1つのLogMinerデータ・ディクショナリを共有するか、または取得プロセスごとに独自のLogMinerデータ・ディクショナリを所有できます。取得プロセスに必要なLogMinerデータ・ディクショナリが存在しない場合は、取得プロセスの最初の起動時にREDOログの情報を使用してLogMinerデータ・ディクショナリが移入されます。
データ・ディクショナリ情報は、DBMS_CAPTURE_ADM.BUILDプロシージャによってREDOログに抽出されます。このプロシージャは、ソース・データベースで発生した変更を取得するように構成された任意の取得プロセスが起動される前に、ソース・データベース上で1回以上実行する必要があります。REDOログに抽出されたデータ・ディクショナリ情報には、DBMS_CAPTURE_ADM.BUILDプロシージャの実行時のプライマリ・データ・ディクショナリとの一貫性があります。また、このプロシージャでは、取得プロセスの作成に使用できる有効な先頭SCN値の識別も行われます。
REDOログでのデータ・ディクショナリ情報のビルドは複数回実行できますが、特定のビルドが取得プロセスによるLogMinerデータ・ディクショナリの作成に使用されない場合もあります。BUILDプロシージャの実行時にREDOログに抽出される情報の量は、データベース内のオブジェクトの数によって異なります。通常、BUILDプロシージャでは大量のREDOデータが生成されます。これらのデータは後で取得プロセスでスキャンする必要があります。このため、BUILDプロシージャは、必要な場合にのみ実行する必要があります。
ほとんどの場合、DBMS_STREAMS_ADMまたはDBMS_CAPTURE_ADMパッケージのプロシージャを使用して取得プロセスを作成する際にビルドが必要な場合は、このプロシージャによって自動的にBUILDプロシージャが実行されます。ただし、次の場合は、取得プロセスの作成時にBUILDプロシージャは自動的には実行されません。
CREATE_CAPTUREを使用し、first_scnパラメータにNULL以外の値を指定した場合。この場合、指定した先頭SCNが以前のビルドに対応している必要があります。
データベース・リンクを使用しないダウンストリーム取得プロセスを作成した場合。この場合、ダウンストリーム・データベースのコマンドで、ソース・データベースと通信してBUILDプロシージャを自動的に実行することはできません。このため、ソース・データベースでBUILDプロシージャを手動で実行し、取得プロセス作成時のビルドに対応する先頭SCNを指定する必要があります。
プライマリ・データ・ディクショナリの情報はREDOログから取得される変更に適用できない場合があるため、取得プロセスにはLogMinerデータ・ディクショナリが必要です。このような変更は、取得プロセスによって取得される数分前、数時間前または数日前に発生した可能性があります。たとえば、次の使用例について考えてみます。
取得プロセスは、表に対する変更を取得するように構成されています。
データベース管理者が取得プロセスを停止します。取得プロセスを停止すると、その時点で取得中だった変更のSCNが取得プロセスによって記録されます。
ユーザー・アプリケーションは、取得プロセスの停止中も引き続き表に対する変更を行います。
停止してから3時間後に取得プロセスが再起動されます。
この場合、取得プロセスでは、データ整合性を確保するために、停止された時点からREDOログの変更の取得を開始する必要があります。取得プロセスでは、停止時に記録したSCNから変更の取得が開始されます。
REDOログにはRAWデータが含まれています。これには、データベース・オブジェクト名および表の列名は含まれていません。かわりに、データベース・オブジェクトおよび列にそれぞれオブジェクト番号および内部列番号が使用されます。したがって、取得プロセスでは、変更を取得する場合、データ・ディクショナリを参照して変更の詳細を確認する必要があります。
取得プロセスの最初の起動時にLogMinerデータ・ディクショナリが移入される場合があるため、変更の取得の開始に時間がかかることがあります。所要時間は、データベース内のデータベース・オブジェクトの数によって異なります。取得プロセスによるデータ・ディクショナリ・ビルドの処理の進捗を監視するには、V$STREAMS_CAPTURE動的パフォーマンス・ビューのSTATE列を問い合せます。
|
関連項目:
|
取得プロセスが、表t1に対する変更を取得するように構成されている場合について考えてみます。この表には列aおよびbがあり、この表に対して3つの異なる時点で次の変更が行われるとします。
時刻1: 値a=7およびb=15の挿入
時刻2: 列cの追加
時刻3: 列bの削除
なんらかの理由で取得プロセスがこれ以前の時点から変更を取得している場合は、プライマリ・データ・ディクショナリとLogMinerデータ・ディクショナリ内の関連バージョンに異なる情報が含まれていることになります。表7-1に、現在の時刻が変更取得時刻とは異なる場合の、LogMinerデータ・ディクショナリ内の情報の使用方法を示します。
表7-1 プライマリ・データ・ディクショナリ内とLogMinerデータ・ディクショナリ内の表t1に関する情報
| 現在の時刻 | 変更取得時刻 | プライマリ・データ・ディクショナリ | LogMinerデータ・ディクショナリ |
|---|---|---|---|
|
1 |
1 |
表 |
表 |
|
2 |
1 |
表 |
表 |
|
3 |
1 |
表 |
表 |
取得プロセスで、実際の時刻が3のときに、時間1に行われた挿入による変更を取得するとします。取得プロセスでプライマリ・データ・ディクショナリが使用されていた場合、列aに値7、列cに値15が挿入されたとみなされる可能性があります。これらの列がプライマリ・データ・ディクショナリ内の時刻3における表t1の列であるためです。ただし、実際には、値15は、列cではなく列bに挿入されています。
取得プロセスではLogMinerデータ・ディクショナリが使用されるため、このエラーは回避されます。LogMinerデータ・ディクショナリは取得プロセスと同期化され、時刻1の時点で表t1に列aおよびbが存在することを引き続き記録します。このため、取得された変更は、列bに値15が挿入されたことを示します。
1つ以上の取得プロセスでソース・データベースに対する変更を取得しているときに、同じソース・データベースに対する変更を取得する取得プロセスを作成する場合、新しい取得プロセスでは、LogMinerデータ・ディクショナリを作成するか、または他の1つ以上の取得プロセスと既存のLogMinerデータ・ディクショナリの1つを共有することができます。
新しい取得プロセスに対して新しいLogMinerデータ・ディクショナリが作成されるかどうかは、CREATE_CAPTUREを実行して取得プロセスを作成したときのfirst_scnパラメータの設定によって異なります。
複数のLogMinerデータ・ディクショナリが存在し、かつ取得プロセスの作成時にfirst_scnパラメータにNULLを指定した場合、新しい取得プロセスでは、1つ以上のチェックポイントを取得済の既存のいずれかの取得プロセスのLogMinerデータ・ディクショナリの共有が自動的に試行されます。DBA_CAPTUREデータ・ディクショナリ・ビューのMAX_CHECKPOINT_SCN列を問い合せると、すべての既存の取得プロセスに対する最大チェックポイントSCNを表示できます。取得プロセスの作成時に、first_scnパラメータがNULL、start_scnパラメータがNULL以外で、start_scnパラメータ設定がすべての既存の取得プロセスに対するすべての先頭SCN値より小さい場合、エラーが発生します。
複数のLogMinerデータ・ディクショナリが存在し、かつ取得プロセスの作成時にfirst_scnパラメータでNULL以外の値を指定した場合、新しい取得プロセスの最初の起動時に新しいLogMinerデータ・ディクショナリが作成されます。この場合、新しい取得プロセスを作成する前に、データベースでDBMS_CAPTURE_ADMパッケージのBUILDプロシージャを実行する必要があります。BUILDプロシージャによって、対応する有効な先頭SCN値が生成されます。この値は、新しい取得プロセスの作成時に指定できます。
BUILDプロシージャによって生成される先頭SCNを検索するには、次の問合せを実行します。
COLUMN FIRST_CHANGE# HEADING 'First SCN' FORMAT 999999999 COLUMN NAME HEADING 'Log File Name' FORMAT A50 SELECT DISTINCT FIRST_CHANGE#, NAME FROM V$ARCHIVED_LOG WHERE DICTIONARY_BEGIN = 'YES';
BUILDプロシージャを複数回実行すると、この問合せによって複数の行が返される場合があります。
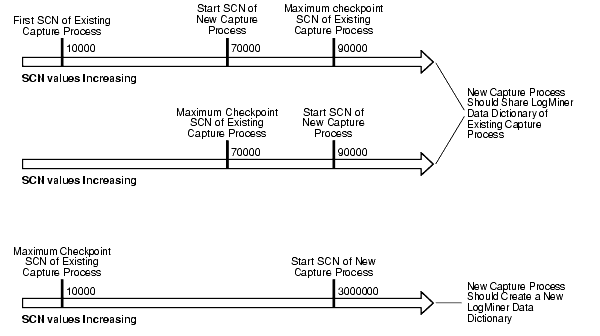
新しい取得プロセスで既存のLogMinerデータ・ディクショナリを共有するか、またはLogMinerデータ・ディクショナリを作成するかを決定する際に考慮する最も重要な要素は、既存の取得プロセスの最大チェックポイントSCN値と新しい取得プロセスの開始SCN値の差です。新しい取得プロセスでは、LogMinerデータ・ディクショナリを共有する場合、先頭SCNより前の変更を取得できないにもかかわらず、共有するLogMinerデータ・ディクショナリの最大チェックポイントSCN以降のREDOログをスキャンする必要があります。新しい取得プロセスの開始SCNが既存の取得プロセスの最大チェックポイントSCNより大幅に大きい場合は、開始SCNに達する前に大量のREDOデータをスキャンする必要があります。
取得プロセスの作成時にfirst_scnパラメータにNULL以外の値を指定した場合、取得プロセスでは、新しいLogMinerデータ・ディクショナリが作成されます。新しい取得プロセスで既存のLogMinerデータ・ディクショナリを共有するか、LogMinerデータ・ディクショナリを作成するかを決定する場合は、次のガイドラインに従ってください。
1つ以上の最大チェックポイントSCN値が、指定する開始SCN値より大きい場合、およびこの開始SCNが1つ以上の既存の取得プロセスの先頭SCNより大きい場合は、既存の取得プロセスのLogMinerデータ・ディクショナリを共有することをお薦めします。この場合、開始SCNより小さいチェックポイントSCNが存在すること、およびこのチェックポイントSCNと開始SCNの差が小さいことを想定できます。新しい取得プロセスは、このチェックポイントSCN以降のREDOログのスキャンを開始し、開始SCNに迅速に到達します。
開始SCN値より大きい最大チェックポイントSCNがない場合、および最大チェックポイントSCNと開始SCNの差が小さい場合は、既存の取得プロセスのLogMinerデータ・ディクショナリを共有することをお薦めします。新しい取得プロセスは、最大チェックポイントSCN以降のREDOログのスキャンを開始しますが、開始SCNに迅速に到達します。
開始SCN値より大きい最大チェックポイントSCNがない場合、および最大チェックポイントSCNと開始SCNの差が大きい場合は、取得プロセスが開始SCNに到達するまでに長い時間かかる可能性があります。この場合は、新しい取得プロセスでLogMinerデータ・ディクショナリを作成することをお薦めします。取得プロセスの最初の起動時には新しいLogMinerデータ・ディクショナリの作成に時間がかかりますが、先頭SCNと開始SCNに同じ値を指定すると、大量のREDOデータをスキャンする必要がなくなります。
図7-4に、これらのガイドラインを示します。
|
注意:
|
|
関連項目:
|
伝播および適用プロセスでは、Oracle Streamsデータ・ディクショナリを使用して、特定のソース・データベースのデータベース・オブジェクトが追跡されます。Oracle Streamsデータ・ディクショナリは、ソース・データベースで1つ以上のデータベース・オブジェクトをインスタンス化のために準備するたびに移入されます。具体的には、データベース・オブジェクトをインスタンス化のために準備すると、そのデータベース・オブジェクトがREDOログに記録されます。取得プロセスでは、REDOログのスキャン時に、この情報を使用して、ソース・データベースのローカルのOracle Streamsデータ・ディクショナリが移入されます。ローカル取得の場合、このOracle Streamsデータ・ディクショナリはソース・データベースに存在します。ダウンストリーム取得の場合、このOracle Streamsデータ・ディクショナリはダウンストリーム・データベースに存在します。
データベース・オブジェクトをインスタンス化のために準備すると、伝播(データベース・オブジェクトに対する変更の伝播)および適用プロセス(データベース・オブジェクトに対する変更の適用)で、データベース・オブジェクトに関する情報が必要であることがOracle Streamsに通知されます。これらの変更を伝播または適用するデータベースでは、変更が発生したソース・データベースのOracle Streamsデータ・ディクショナリが必要となります。
オブジェクトをインスタンス化のために準備した後、取得プロセスによってオブジェクトに対するDDL文が処理される際に、ローカルのOracle Streamsデータ・ディクショナリが更新されます。また、このDDL文に関する情報が含まれている内部メッセージが取得され、取得プロセスのキューに配置されます。その後、伝播によって、これらの内部メッセージをデータベースの宛先キューに伝播できます。
Oracle Streamsデータ・ディクショナリはマルチバージョンです。データベースに複数の伝播および適用プロセスが含まれている場合は、これらすべての伝播および適用プロセスで特定のソース・データベースに対して同じOracle Streamsデータ・ディクショナリが使用されます。データベースには、特定のソース・データベースに対するOracle Streamsデータ・ディクショナリを1つのみ含めることができます。ただし、複数のソース・データベースからの変更を伝播または適用する場合は、複数のOracle Streamsデータ・ディクショナリを含めることができます。
|
関連項目:
|
取得プロセスは、ポジティブ・ルール・セットおよびネガティブ・ルール・セットに対してREDOログ内で検出した変更を評価します。取得プロセスは、まずネガティブ・ルール・セットに対して変更を評価します。ネガティブ・ルール・セットの1つ以上のルールが変更に対してTRUEと評価されると、この変更は廃棄されます。一方、変更に対してTRUEと評価されるルールがネガティブ・ルール・セットに含まれていない場合、この変更はネガティブ・ルール・セットを満たしています。変更が取得プロセスのネガティブ・ルール・セットを満たす場合、取得プロセスは、ポジティブ・ルール・セットに対して変更を評価します。ポジティブ・ルール・セットの1つ以上のルールが変更に対してTRUEと評価される場合、この変更はポジティブ・ルール・セットを満たしています。一方、変更に対してTRUEと評価されるルールがポジティブ・ルール・セットに含まれていない場合、この変更は廃棄されます。取得プロセスにルール・セットが1つのみ含まれている場合は、この1つのルール・セットに対してのみ変更が評価されます。
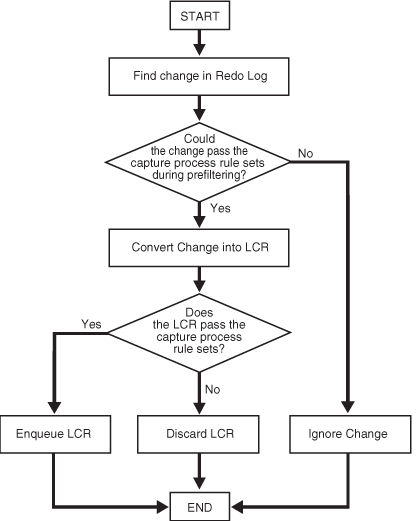
実行中の取得プロセスは、次の一連のアクションを実行して変更を取得します。
REDOログ内で変更を検索します。
REDOログ内の変更の事前フィルタ処理を実行します。この手順で、取得プロセスは、基本レベルでルール・セット内のルールを評価し、REDOログ内で検出された変更を2つのカテゴリに分類します。一方のカテゴリはLCRに変換する変更で、もう一方はLCRに変換しない変更です。事前フィルタ処理は、2つのフェーズで実行されます。1つ目のフェーズでは、事前フィルタ処理で評価可能な情報に、スキーマ名、オブジェクト名、コマンド・タイプなどが含まれます。変更をLCRに変換する必要があるかどうかの判断に追加の情報が必要な場合、事前フィルタ処理の2つ目のフェーズで評価可能な情報に、可能な場合にタグの値および列値が含まれます。
事前フィルタ処理は、不完全な情報を使用して実行される安全な最適化です。この手順では、これ以後に処理対象となる関連する変更が次のように識別されます。
変更が取得プロセスのルール・セットを満たす場合、取得プロセスは変更をLCRに変換します。この場合、手順3に進みます。
変更が取得プロセスのルール・セットを満たさない場合、取得プロセスは変更をLCRに変換しません。
MAYBE評価の場合、ルール評価は次のとおり行われます。
取得プロセスのポジティブ・ルール・セットおよびネガティブ・ルール・セットの両方に対して変更がMAYBEと評価された場合、この変更が両方のルール・セットを確実に満たすかどうかを判別するための十分な情報が取得プロセスに含まれていない可能性があります。この場合、追加の評価が必要です。手順3に進みます。
取得プロセスのネガティブ・ルール・セットに対して変更がFALSEと評価され、ポジティブ・ルール・セットに対してMAYBEと評価された場合、この変更が両方のルール・セットを確実に満たすかどうかを判別するための十分な情報が取得プロセスに含まれていない可能性があります。この場合、追加の評価が必要です。手順3に進みます。
取得プロセスのネガティブ・ルール・セットに対して変更がMAYBEと評価され、ポジティブ・ルール・セットに対してTRUEと評価された場合、この変更が両方のルール・セットを確実に満たすかどうかを判別するための十分な情報が取得プロセスに含まれていない可能性があります。この場合、追加の評価が必要です。手順3に進みます。
取得プロセスのネガティブ・ルール・セットに対して変更がTRUEと評価され、ポジティブ・ルール・セットに対してMAYBEと評価された場合、取得プロセスはこの変更を廃棄します。
取得プロセスのネガティブ・ルール・セットに対して変更がMAYBEと評価され、ポジティブ・ルール・セットに対してFALSEと評価された場合、取得プロセスはこの変更を廃棄します。
事前フィルタ処理に基づいて、取得プロセスのルール・セットを満たすか、または満たす可能性がある変更をLCRに変換します。
LCRのフィルタ処理を実行します。この手順で、取得プロセスは各LCR内の情報に関するルールを評価して、LCRを2つのカテゴリに分けます。一方のカテゴリはエンキューする必要があるLCRで、もう一方は廃棄する必要があるLCRです。
取得プロセスのルール・セットを満たさなかったためエンキューしないLCRを廃棄します。
たとえば、取得プロセスのポジティブ・ルール・セットに対して、department_idが50であるhr.employees表に対する変更を取得するというルールが定義されているとします。この取得プロセスに他のルールは定義されておらず、そのparallelismパラメータは1に設定されています。
このルールが定義されている場合に、hr.employees表に対するUPDATE文によって表の50行が変更されるとします。この取得プロセスは、行の変更ごとに次の一連のアクションを実行します。
REDOログ内でUPDATE文によって発生する次の変更を検索します。
hr.employees表に対するUPDATE文によって変更が発生しており、取得する必要があると判断します。変更が異なる表に対するものの場合、取得プロセスはその変更を無視します。
変更を取得してLCRに変換します。
LCRをフィルタ処理し、department_idが50である行が関係しているかどうかを判断します。
LCRに含まれている行のdepartment_idが50の場合は、取得プロセスに関連付けられているキューにLCRをエンキューします。または、LCRに含まれている行のdepartment_idが50でないか、またはdepartment_idが含まれていない場合は、LCRを廃棄します。
図7-5に、取得プロセス・ルールの評価をフロー・チャート形式で示します。