| Oracle® R Enterpriseユーザーズ・ガイド リリース1.4.1 E57720-01 |
|


 前 |
 次 |
Oracle R Enterpriseには、回帰モデル、ニューラル・ネットワーク・モデルおよびOracle Data Miningアルゴリズムに基づいたモデルを構築するための関数が用意されています。
この章では、次の項目について説明します。
Oracle R EnterpriseのパッケージOREmodelsには、ore.frameオブジェクトを使用して拡張分析データ・モデルの作成に使用できる関数(次の各項で説明します)が含まれています。
OREmodelsパッケージには、ore.frameオブジェクトを使用して拡張分析データ・モデルの構築に使用できる関数が含まれています。OREmodelsの関数を次に示します。
表4-1 OREmodelsパッケージの関数
| 関数 | 説明 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
注意: Rの用語では、「モデルを適合する」という表現は、多くの場合「モデルを構築する」と同じ意味で使用されます。このドキュメントおよびOracle R Enterpriseの関数のオンライン・ヘルプでは、この表現は同じ意味で使用されます。 |
関数ore.glm、ore.lmおよびore.stepwiseには次の利点があります。
アルゴリズムはアウトオブコアQR Factorizationを使用した正確な解決方法を提供します。QR Factorizationは、行列を直交行列と三角行列に分解します。
QRは、困難とされるランクのない適合モデルに使用されるアルゴリズムです。
メモリーに収まらないデータ、つまりアウトオブコアのデータを処理できます。QRはマトリクスを、メモリーに収めるものとディスクに保存するものの、2つに分解します。
ore.glm、ore.lmおよびore.stepwiseの各関数は、10億行を超えるデータセットを解決できます。
ore.stepwise関数によって、前方、後方およびステップワイズによるモデル選択の手法を高速に実装できます。
ニューラル・ネットワークのスケーラビリティの高い実装であり、10億行のデータセット上のモデルであってもわずか数分で構築できます。ore.neural関数は、小中規模のデータセットに対してはインメモリー、大規模入力に対しては分散(アウトオブコア)の2つのモードで実行できます。
ore.neuralでは多くの種類の活性化関数がサポートされているため、ユーザーは活性化関数をニューロン上で層ごとに指定できます。
ユーザーは、0(ゼロ)を含む任意の数の非表示層からなるニューラル・ネットワーク・トポロジを指定できます。
ほとんどの線形回帰およびore.neuralの例では、Rによって提供されるlongleyデータセットを使用します。これはマクロ経済データセットで、共線回帰の既知の例を提供し、16年にわたり毎年観察された7つの経済変数で構成されます。
例4-1では、longleyデータセットを一時データベース表にプッシュしますが、これにはプロキシore.frameオブジェクトのore.frameがあり、longley_ofの最初の6行を表示します。
例4-1のリスト
R> longley_of <- ore.push(longley)
R> dim(longley_of)[1] 16 7
R> head(longley_of)
GNP.deflator GNP Unemployed Armed.Forces Population Year Employed
1947 83.0 234.289 235.6 159.0 107.608 1947 60.323
1948 88.5 259.426 232.5 145.6 108.632 1948 61.122
1949 88.2 258.054 368.2 161.6 109.773 1949 60.171
1950 89.5 284.599 335.1 165.0 110.929 1950 61.187
1951 96.2 328.975 209.9 309.9 112.075 1951 63.221
1952 98.1 346.999 193.2 359.4 113.270 1952 63.639
ore.lm関数およびore.stepwise関数は、最小二乗回帰およびステップワイズ最小二乗回帰をそれぞれore.frameオブジェクトに表されたデータで実行します。モデル適合は、埋込みRマップ/リデュース処理を使用して生成されますが、このときマップ処理によって、評価される係数の数に応じてQR分解またはマトリクスのクロス積のいずれかが作成されます。基礎となるモデル・マトリクスは、モデルのスパーシティに応じてmodel.matrixオブジェクトまたはsparse.model.matrixオブジェクトのいずれかを使用して作成されます。モデルの係数が推定されると、データの別のパスが実行されて、モデル水準統計が推定されます。
前方、後方またはステップワイズ検索が実行されるとき、XtXおよびXtyマトリクスがサブセット化され、XtXサブセット・マトリクスのコレスキー分解を使用して生成された係数推定に基づくF検定のp値が生成されます。
モデルに共線的な項がある場合、関数ore.lmおよびore.stepwiseは一連の共線的な項に対する係数値を推定しません。ore.stepwiseでは、共線的な項セットは、手順全体から除外されます。
ore.lmおよびore.stepwiseの詳細は、help(ore.lm)を呼び出してください。
例4-2では、longleyデータセットを一時データベース表にプッシュしますが、これにはプロキシore.frameオブジェクトのlongley_ofが含まれています。この例では、ore.lmを使用して線形回帰モデルを構築します。
例4-2 ore.lmの使用方法
longley_of <- ore.push(longley) # Fit full model oreFit1 <- ore.lm(Employed ~ ., data = longley_of) class(oreFit1) summary(oreFit1)
例4-2のリスト
R> longley_of <- ore.push(longley)
R> # Fit full model
R> oreFit1 <- ore.lm(Employed ~ ., data = longley_of)
R> class(oreFit1)
[1] "ore.lm" "ore.model" "lm"
R> summary(oreFit1)
Call:
ore.lm(formula = Employed ~ ., data = longley_of)
Residuals:
Min 1Q Median 3Q Max
-0.41011 -0.15767 -0.02816 0.10155 0.45539
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.482e+03 8.904e+02 -3.911 0.003560 **
GNP.deflator 1.506e-02 8.492e-02 0.177 0.863141
GNP -3.582e-02 3.349e-02 -1.070 0.312681
Unemployed -2.020e-02 4.884e-03 -4.136 0.002535 **
Armed.Forces -1.033e-02 2.143e-03 -4.822 0.000944 ***
Population -5.110e-02 2.261e-01 -0.226 0.826212
Year 1.829e+00 4.555e-01 4.016 0.003037 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3049 on 9 degrees of freedom
Multiple R-squared: 0.9955, Adjusted R-squared: 0.9925
F-statistic: 330.3 on 6 and 9 DF, p-value: 4.984e-10
例4-3では、longleyデータセットを一時データベース表にプッシュしますが、これにはプロキシore.frameオブジェクトのlongley_ofが含まれています。この例では、ore.stepwise関数を使用して線形回帰モデルを構築します。
例4-3 ore.stepwise関数の使用方法
longley_of <- ore.push(longley)
# Two stepwise alternatives
oreStep1 <-
ore.stepwise(Employed ~ .^2, data = longley_of, add.p = 0.1, drop.p = 0.1)
oreStep2 <-
step(ore.lm(Employed ~ 1, data = longley_of),
scope = terms(Employed ~ .^2, data = longley_of))
例4-3のリスト
R> longley_of <- ore.push(longley)
R> # Two stepwise alternatives
R> oreStep1 <-
+ ore.stepwise(Employed ~ .^2, data = longley_of, add.p = 0.1, drop.p = 0.1)
R> oreStep2 <-
+ step(ore.lm(Employed ~ 1, data = longley_of),
+ scope = terms(Employed ~ .^2, data = longley_of))
Start: AIC=41.17
Employed ~ 1
Df Sum of Sq RSS AIC
+ GNP 1 178.973 6.036 -11.597
+ Year 1 174.552 10.457 -2.806
+ GNP.deflator 1 174.397 10.611 -2.571
+ Population 1 170.643 14.366 2.276
+ Unemployed 1 46.716 138.293 38.509
+ Armed.Forces 1 38.691 146.318 39.411
<none> 185.009 41.165
Step: AIC=-11.6
Employed ~ GNP
Df Sum of Sq RSS AIC
+ Unemployed 1 2.457 3.579 -17.960
+ Population 1 2.162 3.874 -16.691
+ Year 1 1.125 4.911 -12.898
<none> 6.036 -11.597
+ GNP.deflator 1 0.212 5.824 -10.169
+ Armed.Forces 1 0.077 5.959 -9.802
- GNP 1 178.973 185.009 41.165
... The rest of the output is not shown.
ore.glm関数は、ore.frameオブジェクト内のデータに対して一般化線形モデルを適合します。この関数は、Fisherスコアリングの繰返し加重最小二乗(IRLS)アルゴリズムを使用します。
適切ではない係数推定の選択を防ぐ必要がある従来の手順のかわりに、ore.glmは行検索を使用して、繰返しごとに新しい係数推定を選択し、式(1 - alpha) * old + alpha * suggestedを使用して現在の係数推定から開始し、Fisherスコアリングで提案される推定に移動します(ここでalphaは[0, 2]です)。interp制御引数がTRUEの場合、逸脱度は3次スプライン補間によって概算されます。FALSEの場合、逸脱度はフォローアップ・データ・スキャンを使用して計算されます。
各繰返しは、2つまたは3つの埋込みRマップ/リデュース操作で構成されますが、それは、IRLS操作、初期行検索操作およびinterp = FALSEの場合は、オプションのフォローアップ行検索操作です。ore.lmを使用すると、IRLSマップ操作によって、QR分解(update = "qr"の場合)、クロス積(model.matrixのupdate = "crossprod"の場合)またはsparse.model.matrix (引数sparse = TRUEの場合)が作成され、IRLSリデュース操作ブロックは、それらのQR分解またはクロス積行列を更新します。アルゴリズムが収束するか、最大繰返し数に到達したら、最後の埋込みRマップ/リデュース操作が使用され、完全なモデル水準統計が生成されます。
ore.glm関数は、ore.glmオブジェクトを返します。
ore.glm関数の引数の詳細は、help(ore.glm)を呼び出してください。
例4-4では、rpartパッケージをロードしてから、kyphosisデータセットをプロキシore.frameオブジェクトのKYPHOSISが含まれている一時データベース表にプッシュします。この例では、ore.glm関数およびglm関数を使用して一般線形モデルをそれぞれ構築し、このモデルでsummary関数を呼び出します。
例4-4 ore.glm関数の使用方法
# Load the rpart library to get the kyphosis and solder data sets. library(rpart) # Logistic regression KYPHOSIS <- ore.push(kyphosis) kyphFit1 <- ore.glm(Kyphosis ~ ., data = KYPHOSIS, family = binomial()) kyphFit2 <- glm(Kyphosis ~ ., data = kyphosis, family = binomial()) summary(kyphFit1) summary(kyphFit2)
例4-4のリスト
R> # Load the rpart library to get the kyphosis and solder data sets.
R> library(rpart)
R> # Logistic regression
R> KYPHOSIS <- ore.push(kyphosis)
R> kyphFit1 <- ore.glm(Kyphosis ~ ., data = KYPHOSIS, family = binomial())
R> kyphFit2 <- glm(Kyphosis ~ ., data = kyphosis, family = binomial())
R> summary(kyphFit1)
Call:
ore.glm(formula = Kyphosis ~ ., data = KYPHOSIS, family = binomial())
Deviance Residuals:
Min 1Q Median 3Q Max
-2.3124 -0.5484 -0.3632 -0.1659 2.1613
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.036934 1.449622 -1.405 0.15998
Age 0.010930 0.006447 1.696 0.08997 .
Number 0.410601 0.224870 1.826 0.06786 .
Start -0.206510 0.067700 -3.050 0.00229 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 83.234 on 80 degrees of freedom
Residual deviance: 61.380 on 77 degrees of freedom
AIC: 69.38
Number of Fisher Scoring iterations: 4
R> summary(kyphFit2)
Call:
glm(formula = Kyphosis ~ ., family = binomial(), data = kyphosis)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.3124 -0.5484 -0.3632 -0.1659 2.1613
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.036934 1.449575 -1.405 0.15996
Age 0.010930 0.006446 1.696 0.08996 .
Number 0.410601 0.224861 1.826 0.06785 .
Start -0.206510 0.067699 -3.050 0.00229 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 83.234 on 80 degrees of freedom
Residual deviance: 61.380 on 77 degrees of freedom
AIC: 69.38
Number of Fisher Scoring iterations: 5
# Poisson regression
R> SOLDER <- ore.push(solder)
R> solFit1 <- ore.glm(skips ~ ., data = SOLDER, family = poisson())
R> solFit2 <- glm(skips ~ ., data = solder, family = poisson())
R> summary(solFit1)
Call:
ore.glm(formula = skips ~ ., data = SOLDER, family = poisson())
Deviance Residuals:
Min 1Q Median 3Q Max
-3.4105 -1.0897 -0.4408 0.6406 3.7927
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.25506 0.10069 -12.465 < 2e-16 ***
OpeningM 0.25851 0.06656 3.884 0.000103 ***
OpeningS 1.89349 0.05363 35.305 < 2e-16 ***
SolderThin 1.09973 0.03864 28.465 < 2e-16 ***
MaskA3 0.42819 0.07547 5.674 1.40e-08 ***
MaskB3 1.20225 0.06697 17.953 < 2e-16 ***
MaskB6 1.86648 0.06310 29.580 < 2e-16 ***
PadTypeD6 -0.36865 0.07138 -5.164 2.41e-07 ***
PadTypeD7 -0.09844 0.06620 -1.487 0.137001
PadTypeL4 0.26236 0.06071 4.321 1.55e-05 ***
PadTypeL6 -0.66845 0.07841 -8.525 < 2e-16 ***
PadTypeL7 -0.49021 0.07406 -6.619 3.61e-11 ***
PadTypeL8 -0.27115 0.06939 -3.907 9.33e-05 ***
PadTypeL9 -0.63645 0.07759 -8.203 2.35e-16 ***
PadTypeW4 -0.11000 0.06640 -1.657 0.097591 .
PadTypeW9 -1.43759 0.10419 -13.798 < 2e-16 ***
Panel 0.11818 0.02056 5.749 8.97e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 6855.7 on 719 degrees of freedom
Residual deviance: 1165.4 on 703 degrees of freedom
AIC: 2781.6
Number of Fisher Scoring iterations: 4
ニューラル・ネットワーク・モデルを使用すると、入力と出力との間の複雑な非リニアの関係を取得すること、つまりデータのパターンを見つけることができます。ore.neural関数は、ore.frameのデータに対して回帰用のフィードフォワードニューラル・ネットワーク・モデルを構築します。これは、ノード数を指定可能な複数の非表示層をサポートします。各層には、複数の活性化関数のいずれかを設定できます。
出力層は、単一の数値カテゴリ・ターゲットまたはバイナリのカテゴリ・ターゲットです。出力層には、任意の活性化関数を設定できます。これには、デフォルトで線形活性化関数があります。
ore.neuralの出力は、タイプore.neuralのオブジェクトになります。
ore.neural関数を使用したモデル化は、センサー・データなどのノイズ・データおよび複合データに適しています。そのようなデータに発生する可能性のある問題は次のとおりです。
ピクセル値など、(数値)予測子が多い可能性がある
ターゲットが離散値、実数値またはそのような値のベクターである可能性がある
トレーニング・データに(ノイズに対して堅牢な)エラーが含まれている可能性がある
スコアリングが高速
モデルの透過性が不要なため、モデルの解釈が困難
ニューラル・ネットワーク・モデリングの一般的な手順は次のとおりです。
アーキテクチャの指定
データの準備
モデルの構築
停止条件(反復、許容範囲内の検証セットでのエラー)の指定
モデルの統計結果の表示
モデルの改善
ore.neural関数に対する引数の詳細は、help(ore.neural)を呼び出してください。
例4-5では、デフォルト値(hidden sizeを1など)でニューラル・ネットワークを構築します。この例では、longleyデータセットのサブセットをデータベース・メモリーのore.frameオブジェクトに、オブジェクトtrainDataとしてプッシュします。次に、longleyの別のサブセットをオブジェクトtestDataとしてデータベースにプッシュします。この例では、trainDataを使用してニューラル・ネットワーク・モデルを構築し、testDataを使用して結果を予測します。
例4-5 ニューラル・ネットワーク・モデルの構築
trainData <- ore.push(longley[1:11, ])
testData <- ore.push(longley[12:16, ])
fit <- ore.neural('Employed ~ GNP + Population + Year', data = trainData)
ans <- predict(fit, newdata = testData)
ans
例4-5のリスト
R> trainData <- ore.push(longley[1:11, ])
R> testData <- ore.push(longley[12:16, ])
R> fit <- ore.neural('Employed ~ GNP + Population + Year', data = trainData)
R> ans <- predict(fit, newdata = testData)
R> ans
pred_Employed
1 67.97452
2 69.50893
3 70.28098
4 70.86127
5 72.31066
Warning message:
ORE object has no unique key - using random order
例4-6では、irisデータセットを一時データベース表にプッシュしますが、これにはプロキシore.frameオブジェクトのIRISが含まれています。この例では、ore.neural関数を使用してニューラル・ネットワーク・モデルを構築し、層ごとに異なる活性化関数を指定します。
例4-6 ore.neuralの使用方法および活性化の指定
IRIS <- ore.push(iris)
fit <- ore.neural(Petal.Length ~ Petal.Width + Sepal.Length,
data = IRIS,
sparse = FALSE,
hiddenSizes = c(20, 5),
activations = c("bSigmoid", "tanh", "linear"))
ans <- predict(fit, newdata = IRIS,
supplemental.cols = c("Petal.Length"))
options(ore.warn.order = FALSE)
head(ans, 3)
summary(ans)
例4-6のリスト
R> IRIS <- ore.push(iris)
R> fit <- ore.neural(Petal.Length ~ Petal.Width + Sepal.Length,
+ data = IRIS,
+ sparse = FALSE,
+ hiddenSizes = c(20, 5),
+ activations = c("bSigmoid", "tanh", "linear"))
R>
R> ans <- predict(fit, newdata = IRIS,
+ supplemental.cols = c("Petal.Length"))
R> options(ore.warn.order = FALSE)
R> head(ans, 3)
Petal.Length pred_Petal.Length
1 1.4 1.416466
2 1.4 1.363385
3 1.3 1.310709
R> summary(ans)
Petal.Length pred_Petal.Length
Min. :1.000 Min. :1.080
1st Qu.:1.600 1st Qu.:1.568
Median :4.350 Median :4.346
Mean :3.758 Mean :3.742
3rd Qu.:5.100 3rd Qu.:5.224
Max. :6.900 Max. :6.300
この項では、Oracle R EnterpriseのOREdmパッケージを使用したRでのOracle Data Miningモデルの構築について説明します。この項の内容は次のとおりです。
|
関連項目: 『Oracle Data Mining概要』 |
Oracle Data Miningでは、表、ビュー、スター・スキーマ、トランザクション・データおよび非構造化データのマイニングが可能です。OREdm関数は、対応する予測分析関数およびデータ・マイニング関数に、一般的なRの使用法に適合した引数を使用するRインタフェースを提供します。
この項の内容は次のとおりです。
OREdmパッケージの関数は、Oracle Databaseのインデータベース・データ・マイニング機能へのアクセスを提供します。これらの関数を使用して、データベースにデータ・マイニング・モデルを構築します。
表4-2に、Oracle Data Miningモデル構築するOracle R Enterpriseの関数および対応するOracle Data Miningのアルゴリズムおよび関数をリストします。
表4-2 Oracle R Enterpriseのデータ・マイニング・モデルの関数
| Oracle R Enterpriseの関数 | Oracle Data Miningのアルゴリズム | Oracle Data Miningの関数 |
|---|---|---|
|
|
最小記述長 |
分類または回帰の属性評価 |
|
|
Apriori |
相関ルール |
|
|
ディシジョン・ツリー |
分類 |
|
|
一般化線形モデル |
分類および回帰 |
|
|
k-Means |
クラスタリング |
|
|
Naive Bayes |
分類 |
|
|
Non-Negative Matrix Factorization |
特徴抽出 |
|
|
直交パーティショニング・クラスタ(O-Cluster) |
クラスタリング |
|
|
サポート・ベクター・マシン |
分類および回帰 |
各OREdmのRモデル・オブジェクトで、スロットname (またはfit.name)は、OREdm関数で生成された基礎となるOracle Data Miningモデルの名前です。Rモデルが存在している場合は、Oracle Data Miningのモデル名を使用して、次のような他のインタフェースを介してOracle Data Miningモデルにアクセスできます。
Oracle Data Miner
SQLインタフェース(SQL*Plus、SQL Developerなど)
具体的には、このモデルはOracle Data MiningのSQL予測機能とともに使用できます。
Oracle Data Minerを使用して、次のことを実行できます。
利用可能なモデルのリストを表示する
モデル・ビューアを使用してモデルの詳細を調べる
変換されたデータを適切にスコアリングする
|
注意: Rの領域で実行される変換は、Oracle Data MinerまたはSQLスコアリングには引き継がれません。 |
さらに、SQLを使用して、モデルの詳細を調べるため、または変換されたデータを適切にスコアリングするためのモデルのリストも取得できます。
OREdm関数を使用して構築されたモデルは一時オブジェクトであるため、Oracle R Enterpriseデータストアに明示的に保存されないかぎり、Rセッション終了後は保持されません。一方、Data MinerまたはSQLを使用して構築されたOracle Data Miningモデルは、明示的に削除されるまで存在します。
モデル・オブジェクトは、「データベースでのRオブジェクトの保存および管理」で説明するように保存または保持できます。OREdmで生成されたモデル・オブジェクトを保存すると、このオブジェクトはRセッション全体で存在でき、対応するOracle Data Miningを所定の場所に保持できます。OREdmモデルが存在する間、これをエクスポートおよびインポートでき、その後、Oracle R Enterprise Rオブジェクトの存在から切り離して使用できます。
ore.odmAssocRules関数は、Aprioriアルゴリズムを実装することで、高頻度アイテム・セットを検索して相関モデルを生成します。これによって、マーケット・バスケット分析のような場合の大量のトランザクション・データにおいて、アイテムの同時発生が検出されます。相関ルールは、トランザクション・レコードで一連のアイテムが出現すれば、もう1つの一連のアイテムが存在するというデータのパターンを特定します。ルールの形成に使用されるアイテムのグループは、発生(ルールの支持度)する頻度および後件が前件(ルールの信頼度)に従う回数に応じて、最小しきい値を渡す必要があります。相関モデルは、ユーザー指定のしきい値よりも大きい支持度および信頼度を備えるすべてのルールを生成します。Aprioriアルゴリズムは効率的で、トランザクション数、アイテム数および生成されるアイテム・セットおよびルールの数が有効に測定されます。
formulaの仕様にはform ~ termsがあり、ここでtermsは分析に含まれる一連の列名です。複数の列名は列名の間に+を使用することで指定されます。~ .は、データのすべての列をモデル構築に使用する場合に使用します。列を除外するには、除外する各列名の前に-を使用します。関数は変換を確認するためにtermsの項目に適用できます。
ore.odmAssocRules関数は、次の形式のデータを受け入れます。
トランザクション・データ
アイテムIDおよびアイテム値を使用した複数レコードのケース・データ
リレーショナル・データ
データの形式の指定の例および関数の引数の詳細は、help(ore.odmAssocRules)を呼び出してください。
関数rulesは、クラスore.rules (一連の相関ルールを指定します)のオブジェクトを返します。ore.pullを使用して、ore.rulesオブジェクトをローカルのRセッションのメモリーにプルできます。ローカルのインメモリー・オブジェクトは、arulesパッケージで定義されているクラスrulesのものです。help(ore.rules)を参照してください。
関数itemsetsは、クラスore.itemsets (一連のアイテムセットを指定します)のオブジェクトを返します。ore.pullを使用して、ore.itemsetsオブジェクトをローカルのRセッションのメモリーにプルできます。ローカルのインメモリー・オブジェクトは、arulesパッケージで定義されているクラスitemsetsのものです。help(ore.itemsets)を参照してください。
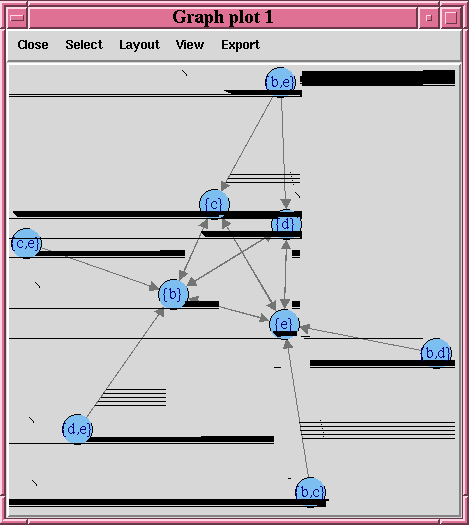
例4-7では、トランザクション・データセットに基づいて、相関モデルを構築します。パッケージarulesおよびarulesVizは、生成されるルールおよびアイテムセットをクライアントのRセッションのメモリーにプルして表示するために必要です。このルールのグラフを図4-1に示します。
例4-7 ore.odmAssocRules関数の使用方法
# Load the arules and arulesViz packages.
library(arules)
library(arulesViz)
# Create some transactional data.
id <- c(1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3)
item <- c("b", "d", "e", "a", "b", "c", "e", "b", "c", "d", "e")
# Push the data to the database as an ore.frame object.
transdata_of <- ore.push(data.frame(ID = id, ITEM = item))
# Build a model with specifications.
ar.mod1 <- ore.odmAssocRules(~., transdata_of, case.id.column = "ID",
item.id.column = "ITEM", min.support = 0.6, min.confidence = 0.6,
max.rule.length = 3)
# Generate itemsets and rules of the model.
itemsets <- itemsets(ar.mod1)
rules <- rules(ar.mod1)
# Convert the rules to the rules object in arules package.
rules.arules <- ore.pull(rules)
inspect(rules.arules)
# Convert itemsets to the itemsets object in arules package.
itemsets.arules <- ore.pull(itemsets)
inspect(itemsets.arules)
# Plot the rules graph.
plot(rules.arules, method = "graph", interactive = TRUE)
例4-7のリスト
R> # Load the arules and arulesViz packages.
R> library(arules)
R> library(arulesViz)
R> # Create some transactional data.
R> id <- c(1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3)
R> item <- c("b", "d", "e", "a", "b", "c", "e", "b", "c", "d", "e")
R> # Push the data to the database as an ore.frame object.
R> transdata_of <- ore.push(data.frame(ID = id, ITEM = item))
R> # Build a model with specifications.
R> ar.mod1 <- ore.odmAssocRules(~., transdata_of, case.id.column = "ID",
+ item.id.column = "ITEM", min.support = 0.6, min.confidence = 0.6,
+ max.rule.length = 3)
R> # Generate itemsets and rules of the model.
R> itemsets <- itemsets(ar.mod1)
R> rules <- rules(ar.mod1)
R> # Convert the rules to the rules object in arules package.
R> rules.arules <- ore.pull(rules)
R> inspect(rules.arules)
lhs rhs support confidence lift
1 {b} => {e} 1.0000000 1.0000000 1
2 {e} => {b} 1.0000000 1.0000000 1
3 {c} => {e} 0.6666667 1.0000000 1
4 {d,
e} => {b} 0.6666667 1.0000000 1
5 {c,
e} => {b} 0.6666667 1.0000000 1
6 {b,
d} => {e} 0.6666667 1.0000000 1
7 {b,
c} => {e} 0.6666667 1.0000000 1
8 {d} => {b} 0.6666667 1.0000000 1
9 {d} => {e} 0.6666667 1.0000000 1
10 {c} => {b} 0.6666667 1.0000000 1
11 {b} => {d} 0.6666667 0.6666667 1
12 {b} => {c} 0.6666667 0.6666667 1
13 {e} => {d} 0.6666667 0.6666667 1
14 {e} => {c} 0.6666667 0.6666667 1
15 {b,
e} => {d} 0.6666667 0.6666667 1
16 {b,
e} => {c} 0.6666667 0.6666667 1
R> # Convert itemsets to the itemsets object in arules package.
R> itemsets.arules <- ore.pull(itemsets)
R> inspect(itemsets.arules)
items support
1 {b} 1.0000000
2 {e} 1.0000000
3 {b,
e} 1.0000000
4 {c} 0.6666667
5 {d} 0.6666667
6 {b,
c} 0.6666667
7 {b,
d} 0.6666667
8 {c,
e} 0.6666667
9 {d,
e} 0.6666667
10 {b,
c,
e} 0.6666667
11 {b,
d,
e} 0.6666667
R> # Plot the rules graph.
R> plot(rules.arules, method = "graph", interactive = TRUE)
ore.odmAI関数は、Oracle Data Mining最小記述長アルゴリズムを使用して属性評価を計算します。属性評価では、ターゲットの予測における重要度に従って属性がランク付けされます。
最小記述長(MDL)は、情報理論モデルの選択原理の1つである。それは、情報理論(情報の定量化の研究)および学習理論(経験的データに基づく一般化の容量の研究)における重要な概念です。
MDLでは、最も単純でコンパクトな表現が、データの説明として最適かつ最も可能性が高いとみなされます。MDL原理は、Oracle Data Miningの属性評価モデルの作成に使用されます。
Oracle Data Miningを使用して構築された属性評価モデルは、新しいデータに適用できません。
ore.odmAI関数は、属性のランキングおよび属性評価の値を作成します。
|
注意: OREdm AIモデルは、モデル・オブジェクトが保持されない、Rモデル・オブジェクトが返されない、という点で、Oracle Data Mining AIモデルとは異なります。モデルによって作成された重要度ランキングのみが返されます。 |
ore.odmAI関数の引数の詳細は、help(ore.odmAI)を呼び出してください。
例4-8では、data.frameのirisをデータベースにore.frameのiris_ofとしてプッシュします。この例では次に、属性評価モデルを構築します。
例4-8のリスト
R> iris_of <- ore.push(iris)
R> ore.odmAI(Species ~ ., iris_of)
Call:
ore.odmAI(formula = Species ~ ., data = iris_of)
Importance:
importance rank
Petal.Width 1.1701851 1
Petal.Length 1.1494402 2
Sepal.Length 0.5248815 3
Sepal.Width 0.2504077 4
ore.odmDT関数は、Oracle Data Miningディシジョン・ツリー・アルゴリズムを使用しますが、これは条件付確率を基にしています。ディシジョン・ツリーはルールを生成します。ルールは、ユーザーが容易に理解でき、レコード・セットを識別するためにデータベース内で使用できる条件文です。
ディシジョン・ツリー・モデルは分類モデルです。
ディシジョン・ツリーは、一連の質問を問うことによってターゲット値を予測します。各段階で問われる質問はそれぞれ、直前の質問に対する回答によって決まります。最終的に特定のターゲット値を一意に識別できるような質問を重ねていきます。図形的には、このプロセスがツリー構造を形成します。
ディシジョン・ツリー・アルゴリズムは、トレーニング・プロセスにおいて、ケース(レコード)のセットを2つの子ノードに分割する最も効率的な方法を繰り返し見つける必要があります。ore.odmDT関数では、この分岐の計算用に2つの同種メトリック(giniおよびentropy)を使用できます。デフォルトのメトリックはginiです。
ore.odmDT関数の引数の詳細は、help(ore.odmDT)を呼び出してください。
例4-9では、入力ore.frameを作成し、モデルを構築し、予測を行い、混同マトリクスを生成します。
例4-9 ore.odmDT関数の使用方法
m <- mtcars m$gear <- as.factor(m$gear) m$cyl <- as.factor(m$cyl) m$vs <- as.factor(m$vs) m$ID <- 1:nrow(m) mtcars_of <- ore.push(m) row.names(mtcars_of) <- mtcars_of # Build the model. dt.mod <- ore.odmDT(gear ~ ., mtcars_of) summary(dt.mod) # Make predictions and generate a confusion matrix. dt.res <- predict (dt.mod, mtcars_of, "gear") with(dt.res, table(gear, PREDICTION))
例4-9のリスト
R> m <- mtcars
R> m$gear <- as.factor(m$gear)
R> m$cyl <- as.factor(m$cyl)
R> m$vs <- as.factor(m$vs)
R> m$ID <- 1:nrow(m)
R> mtcars_of <- ore.push(m)
R> row.names(mtcars_of) <- mtcars_of
R> # Build the model.
R> dt.mod <- ore.odmDT(gear ~ ., mtcars_of)
R> summary(dt.mod)
Call:
ore.odmDT(formula = gear ~ ., data = mtcars_of)
n = 32
Nodes:
parent node.id row.count prediction split
1 NA 0 32 3 <NA>
2 0 1 16 4 (disp <= 196.299999999999995)
3 0 2 16 3 (disp > 196.299999999999995)
surrogate full.splits
1 <NA> <NA>
2 (cyl in ("4" "6" )) (disp <= 196.299999999999995)
3 (cyl in ("8" )) (disp > 196.299999999999995)
Settings:
value
prep.auto on
impurity.metric impurity.gini
term.max.depth 7
term.minpct.node 0.05
term.minpct.split 0.1
term.minrec.node 10
term.minrec.split 20
R> # Make predictions and generate a confusion matrix.
R> dt.res <- predict (dt.mod, mtcars_of, "gear")
R> with(dt.res, table(gear, PREDICTION))
PREDICTION
gear 3 4
3 14 1
4 0 12
5 2 3
ore.odmGLM関数は一般化線形モデル(GLM)を構築しますが、これは線形モデル(線形回帰)のクラスを含み、このクラスを拡張したものです。一般化線形モデルは、実際には違反されることが多い線形モデルの制限を緩和したものです。たとえば、2値(yes/noまたは0/1)応答は、クラス間で同じ分散を持ちません。
Oracle Data MiningのGLMはパラメトリック・モデリング手法です。パラメトリック・モデルでは、データの分散を仮定します。仮定が満たされる場合、パラメトリック・モデルはノンパラメトリック・モデルよりも効率的になります。
このタイプのモデルの作成では、どの程度仮定が満たされるかを見極めることが課題となります。このため、良質なパラメトリック・モデルを作成するには質の診断が重要です。
古典的な、線形回帰における重み付き最小二乗推定およびロジスティック回帰における反復再重み付き最小二乗推定(いずれもコレスキー分解およびマトリクス反転を使用する解決)に加えて、Oracle Data MiningのGLMでは、マトリクス反転が不要で高次元データに最適な共役勾配法に基づく最適化アルゴリズムを提供します。アルゴリズムの選択は内部的に処理され、ユーザーに対して透過的です。
GLMを使用して、次のような分類モデルまたは回帰モデルを構築できます。
分類: 2項ロジスティック回帰は、GLM分類アルゴリズムです。このアルゴリズムでは、ロジット・リンク関数および2項分散関数を使用します。
回帰: 線形回帰は、GLM回帰アルゴリズムです。このアルゴリズムでは、ターゲット値の範囲に対する一定分散およびターゲット変換を想定していません。
ore.odmGLM関数では、2つの異なるタイプのモデルを構築できます。一部、分類モデルにのみ適用される引数、回帰モデルにのみ適用される引数があります。
ore.odmGLM関数の引数の詳細は、help(ore.odmGLM)を呼び出してください。
次の例では、GLMを使用していくつかのモデルを構築します。入力ore.frameオブジェクトは、データベースにプッシュされるRデータセットです。
例4-10では、longleyデータセットを使用して線形回帰モデルを構築します。
例4-10 線形回帰モデルの構築
longley_of <- ore.push(longley) longfit1 <- ore.odmGLM(Employed ~ ., data = longley_of) summary(longfit1)
例4-10のリスト
R> longley_of <- ore.push(longley)
R> longfit1 <- ore.odmGLM(Employed ~ ., data = longley_of)
R> summary(longfit1)
Call:
ore.odmGLM(formula = Employed ~ ., data = longely_of)
Residuals:
Min 1Q Median 3Q Max
-0.41011 -0.15767 -0.02816 0.10155 0.45539
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.482e+03 8.904e+02 -3.911 0.003560 **
GNP.deflator 1.506e-02 8.492e-02 0.177 0.863141
GNP -3.582e-02 3.349e-02 -1.070 0.312681
Unemployed -2.020e-02 4.884e-03 -4.136 0.002535 **
Armed.Forces -1.033e-02 2.143e-03 -4.822 0.000944 ***
Population -5.110e-02 2.261e-01 -0.226 0.826212
Year 1.829e+00 4.555e-01 4.016 0.003037 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3049 on 9 degrees of freedom
Multiple R-squared: 0.9955, Adjusted R-squared: 0.9925
F-statistic: 330.3 on 6 and 9 DF, p-value: 4.984e-10
例4-11では、 例4-10のlongley_ofのore.frameを使用します。例4-11では、ore.odmGLM関数を呼び出し、係数のリッジ推定を使用して指定します。
例4-11 ore.odmGLMモデルの係数に対するリッジ推定の使用方法
longfit2 <- ore.odmGLM(Employed ~ ., data = longley_of, ridge = TRUE,
ridge.vif = TRUE)
summary(longfit2)
例4-11のリスト
R> longfit2 <- ore.odmGLM(Employed ~ ., data = longley_of, ridge = TRUE,
+ ridge.vif = TRUE)
R> summary(longfit2)
Call:
ore.odmGLM(formula = Employed ~ ., data = longley_of, ridge = TRUE,
ridge.vif = TRUE)
Residuals:
Min 1Q Median 3Q Max
-0.4100 -0.1579 -0.0271 0.1017 0.4575
Coefficients:
Estimate VIF
(Intercept) -3.466e+03 0.000
GNP.deflator 1.479e-02 0.077
GNP -3.535e-02 0.012
Unemployed -2.013e-02 0.000
Armed.Forces -1.031e-02 0.000
Population -5.262e-02 0.548
Year 1.821e+00 2.212
Residual standard error: 0.3049 on 9 degrees of freedom
Multiple R-squared: 0.9955, Adjusted R-squared: 0.9925
F-statistic: 330.2 on 6 and 9 DF, p-value: 4.986e-10
例4-12では、ロジスティック回帰(分類)モデルを構築します。ここでは、infertデータセットを使用します。この例では、ore.odmGLM関数を呼び出し、logisticをtype引数(二項分布GLMを構築します)として指定します。
例4-12 ロジスティック回帰GLMの構築
infert_of <- ore.push(infert)
infit1 <- ore.odmGLM(case ~ age+parity+education+spontaneous+induced,
data = infert_of, type = "logistic")
infit1
例4-12のリスト
R> infert_of <- ore.push(infert)
R> infit1 <- ore.odmGLM(case ~ age+parity+education+spontaneous+induced,
+ data = infert_of, type = "logistic")
R> infit1
Response:
case == "1"
Call: ore.odmGLM(formula = case ~ age + parity + education + spontaneous +
induced, data = infert_of, type = "logistic")
Coefficients:
(Intercept) age parity education0-5yrs education12+ yrs spontaneous induced
-2.19348 0.03958 -0.82828 1.04424 -0.35896 2.04590 1.28876
Degrees of Freedom: 247 Total (i.e. Null); 241 Residual
Null Deviance: 316.2
Residual Deviance: 257.8 AIC: 271.8
例4-13では、ロジスティック回帰(分類)モデルを構築し、参照値を指定します。この例では、例4-12のinfert_ofのore.frameを使用します。
例4-13 ロジスティック回帰GLMの構築での参照値の指定
infit2 <- ore.odmGLM(case ~ age+parity+education+spontaneous+induced,
data = infert_of, type = "logistic", reference = 1)
infit2
例4-13のリスト
infit2 <- ore.odmGLM(case ~ age+parity+education+spontaneous+induced,
data = infert_of, type = "logistic", reference = 1)
infit2
Response:
case == "0"
Call: ore.odmGLM(formula = case ~ age + parity + education + spontaneous +
induced, data = infert_of, type = "logistic", reference = 1)
Coefficients:
(Intercept) age parity education0-5yrs education12+ yrs spontaneous induced
2.19348 -0.03958 0.82828 -1.04424 0.35896 -2.04590 -1.28876
Degrees of Freedom: 247 Total (i.e. Null); 241 Residual
Null Deviance: 316.2
Residual Deviance: 257.8 AIC: 271.8
ore.odmKM関数は、Oracle Data Miningのk-Means (KM)アルゴリズムを使用しますが、これは、指定した数のクラスタにデータを分割する、距離ベースのクラスタリング・アルゴリズムです。このアルゴリズムには、次の機能があります。
複数の距離関数(ユークリッド、コサインおよび高速コサインの各距離関数)。デフォルトはユークリッドです。
クラスタごとに、アルゴリズムによって、重心、各属性のヒストグラム、およびクラスタに割り当てられるデータの大部分を囲むハイパーボックスを記述するルールが戻されます。重心は、カテゴリ属性については最頻値を、数値属性については平均および分散をレポートします。
ore.odmKM関数の引数の詳細は、help(ore.odmKM)を呼び出してください。
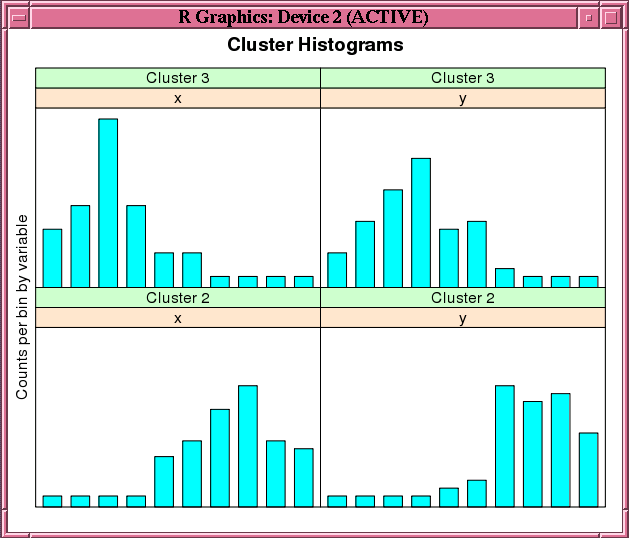
例4-14にore.odmKMeans関数の使用を示します。この例では、100行および2列を含むマトリクスを2つ作成します。行の値は無作為変量です。このマトリクスをmatrix xにバインドします。この例では、xをdata.frameに強制変換し、それをデータベースにore.frameオブジェクトであるx_ofとしてプッシュします。例では、ore.odmKMeans関数を呼び出して、KMモデルのkm.mod1を構築します。次に、summary関数およびhistogram関数をそのモデルで呼び出します。図4-2に、histogram関数で表示されるグラフを示します。
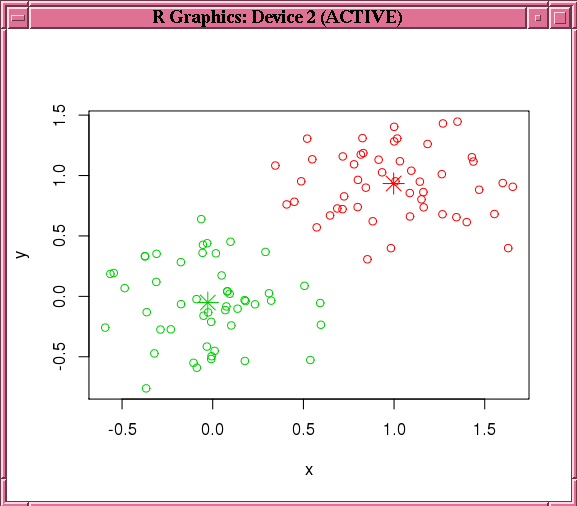
この例では次に、このモデルを使用して予測を行い、その結果をローカル・メモリーにプルします。結果が描画されます。図4-3に、この例のpoints関数で表示されるグラフを示します。
例4-14 ore.odmKM関数の使用方法
x <- rbind(matrix(rnorm(100, sd = 0.3), ncol = 2),
matrix(rnorm(100, mean = 1, sd = 0.3), ncol = 2))
colnames(x) <- c("x", "y")
x_of <- ore.push (data.frame(x))
km.mod1 <- NULL
km.mod1 <- ore.odmKMeans(~., x_of, num.centers=2)
summary(km.mod1)
histogram(km.mod1) # See Figure 4-2.
# Make a prediction.
km.res1 <- predict(km.mod1, x_of, type="class", supplemental.cols=c("x","y"))
head(km.res1, 3)
# Pull the results to the local memory and plot them.
km.res1.local <- ore.pull(km.res1)
plot(data.frame(x=km.res1.local$x, y=km.res1.local$y),
col=km.res1.local$CLUSTER_ID)
points(km.mod1$centers2, col = rownames(km.mod1$centers2), pch = 8, cex=2)
head(predict(km.mod1, x_of, type=c("class","raw"),
supplemental.cols=c("x","y")), 3)
例4-14のリスト
R> x <- rbind(matrix(rnorm(100, sd = 0.3), ncol = 2),
+ matrix(rnorm(100, mean = 1, sd = 0.3), ncol = 2))
R> colnames(x) <- c("x", "y")
R> x_of <- ore.push (data.frame(x))
R> km.mod1 <- NULL
R> km.mod1 <- ore.odmKMeans(~., x_of, num.centers=2)
R> summary(km.mod1)
Call:
ore.odmKMeans(formula = ~., data = x_of, num.centers = 2)
Settings:
value
clus.num.clusters 2
block.growth 2
conv.tolerance 0.01
distance euclidean
iterations 3
min.pct.attr.support 0.1
num.bins 10
split.criterion variance
prep.auto on
Centers:
x y
2 0.99772307 0.93368684
3 -0.02721078 -0.05099784
R> histogram(km.mod1) # See Figure 4-2.
R> # Make a prediction.
R> km.res1 <- predict(km.mod1, x_of, type="class", supplemental.cols=c("x","y"))
R> head(km.res1, 3)
x y CLUSTER_ID
1 -0.03038444 0.4395409 3
2 0.17724606 -0.5342975 3
3 -0.17565761 0.2832132 3
# Pull the results to the local memory and plot them.
R> km.res1.local <- ore.pull(km.res1)
R> plot(data.frame(x=km.res1.local$x, y=km.res1.local$y),
+ col=km.res1.local$CLUSTER_ID)
R> points(km.mod1$centers2, col = rownames(km.mod1$centers2), pch = 8, cex=2)
R> # See Figure 4-3.
R> head(predict(km.mod1, x_of, type=c("class","raw"),
supplemental.cols=c("x","y")), 3)
'2' '3' x y CLUSTER_ID
1 8.610341e-03 0.9913897 -0.03038444 0.4395409 3
2 8.017890e-06 0.9999920 0.17724606 -0.5342975 3
3 5.494263e-04 0.9994506 -0.17565761 0.2832132 3
ore.odmNB関数は、Oracle Data MiningのNaive Bayesモデルを構築します。Naive Bayesアルゴリズムは条件付き確率に基づいています。Naive Bayesは履歴データを検索し、属性値の頻度と属性値の組合せの頻度を観測することによってターゲット値の条件付き確率を計算します。
Naive Bayesでは、各予測子は他の予測子とは条件的に独立していると想定されます。(Bayesの定理では、予測子が独立している必要があります。)
ore.odmNB関数の引数の詳細は、help(ore.odmNB)を呼び出してください。
例4-9では、入力ore.frameを作成し、Naive Bayesモデルを構築し、予測を行い、混同マトリクスを生成します。
例4-15 ore.odmNB関数の使用方法
m <- mtcars m$gear <- as.factor(m$gear) m$cyl <- as.factor(m$cyl) m$vs <- as.factor(m$vs) m$ID <- 1:nrow(m) mtcars_of <- ore.push(m) row.names(mtcars_of) <- mtcars_of # Build the model. nb.mod <- ore.odmNB(gear ~ ., mtcars_of) summary(nb.mod) # Make predictions and generate a confusion matrix. nb.res <- predict (nb.mod, mtcars_of, "gear") with(nb.res, table(gear, PREDICTION))
例4-15のリスト
R> m <- mtcars
R> m$gear <- as.factor(m$gear)
R> m$cyl <- as.factor(m$cyl)
R> m$vs <- as.factor(m$vs)
R> m$ID <- 1:nrow(m)
R> mtcars_of <- ore.push(m)
R> row.names(mtcars_of) <- mtcars_of
R> # Build the model.
R> nb.mod <- ore.odmNB(gear ~ ., mtcars_of)
R> summary(nb.mod)
Call:
ore.odmNB(formula = gear ~ ., data = mtcars_of)
Settings:
value
prep.auto on
Apriori:
3 4 5
0.46875 0.37500 0.15625
Tables:
$ID
( ; 26.5), [26.5; 26.5] (26.5; )
3 1.00000000
4 0.91666667 0.08333333
5 1.00000000
$am
0 1
3 1.0000000
4 0.3333333 0.6666667
5 1.0000000
$cyl
'4', '6' '8'
3 0.2 0.8
4 1.0
5 0.6 0.4
$disp
( ; 196.299999999999995), [196.299999999999995; 196.299999999999995]
3 0.06666667
4 1.00000000
5 0.60000000
(196.299999999999995; )
3 0.93333333
4
5 0.40000000
$drat
( ; 3.385), [3.385; 3.385] (3.385; )
3 0.8666667 0.1333333
4 1.0000000
5 1.0000000
$hp
( ; 136.5), [136.5; 136.5] (136.5; )
3 0.2 0.8
4 1.0
5 0.4 0.6
$vs
0 1
3 0.8000000 0.2000000
4 0.1666667 0.8333333
5 0.8000000 0.2000000
$wt
( ; 3.2024999999999999), [3.2024999999999999; 3.2024999999999999]
3 0.06666667
4 0.83333333
5 0.80000000
(3.2024999999999999; )
3 0.93333333
4 0.16666667
5 0.20000000
Levels:
[1] "3" "4" "5"
R> # Make predictions and generate a confusion matrix.
R> nb.res <- predict (nb.mod, mtcars_of, "gear")
R> with(nb.res, table(gear, PREDICTION))
PREDICTION
gear 3 4 5
3 14 1 0
4 0 12 0
5 0 1 4
ore.odmNMF関数は、特徴抽出にOracle Data MiningのNon-Negative Matrix Factorization (NMF)モデルを構築します。NMFによって抽出される各特徴は、元の属性セットの線形結合です。各特徴には、負でない一連の係数があり、それらは特徴の各属性の重みのメジャーです。引数allow.negative.scoresがTRUEの場合、負の係数が許可されます。
ore.odmNMF関数の引数の詳細は、help(ore.odmNMF)を呼び出してください。
例4-16では、NMFモデルをトレーニング・データセットに作成し、テスト・データセットでスコアリングします。
例4-16 ore.odmNMF関数の使用方法
training.set <- ore.push(npk[1:18, c("N","P","K")])
scoring.set <- ore.push(npk[19:24, c("N","P","K")])
nmf.mod <- ore.odmNMF(~., training.set, num.features = 3)
features(nmf.mod)
summary(nmf.mod)
predict(nmf.mod, scoring.set)
例4-16のリスト
R> training.set <- ore.push(npk[1:18, c("N","P","K")])
R> scoring.set <- ore.push(npk[19:24, c("N","P","K")])
R> nmf.mod <- ore.odmNMF(~., training.set, num.features = 3)
R> features(nmf.mod)
FEATURE_ID ATTRIBUTE_NAME ATTRIBUTE_VALUE COEFFICIENT
1 1 K 0 3.723468e-01
2 1 K 1 1.761670e-01
3 1 N 0 7.469067e-01
4 1 N 1 1.085058e-02
5 1 P 0 5.730082e-01
6 1 P 1 2.797865e-02
7 2 K 0 4.107375e-01
8 2 K 1 2.193757e-01
9 2 N 0 8.065393e-03
10 2 N 1 8.569538e-01
11 2 P 0 4.005661e-01
12 2 P 1 4.124996e-02
13 3 K 0 1.918852e-01
14 3 K 1 3.311137e-01
15 3 N 0 1.547561e-01
16 3 N 1 1.283887e-01
17 3 P 0 9.791965e-06
18 3 P 1 9.113922e-01
R> summary(nmf.mod)
Call:
ore.odmNMF(formula = ~., data = training.set, num.features = 3)
Settings:
value
feat.num.features 3
nmfs.conv.tolerance .05
nmfs.nonnegative.scoring nmfs.nonneg.scoring.enable
nmfs.num.iterations 50
nmfs.random.seed -1
prep.auto on
Features:
FEATURE_ID ATTRIBUTE_NAME ATTRIBUTE_VALUE COEFFICIENT
1 1 K 0 3.723468e-01
2 1 K 1 1.761670e-01
3 1 N 0 7.469067e-01
4 1 N 1 1.085058e-02
5 1 P 0 5.730082e-01
6 1 P 1 2.797865e-02
7 2 K 0 4.107375e-01
8 2 K 1 2.193757e-01
9 2 N 0 8.065393e-03
10 2 N 1 8.569538e-01
11 2 P 0 4.005661e-01
12 2 P 1 4.124996e-02
13 3 K 0 1.918852e-01
14 3 K 1 3.311137e-01
15 3 N 0 1.547561e-01
16 3 N 1 1.283887e-01
17 3 P 0 9.791965e-06
18 3 P 1 9.113922e-01
R> predict(nmf.mod, scoring.set)
'1' '2' '3' FEATURE_ID
19 0.1972489 1.2400782 0.03280919 2
20 0.7298919 0.0000000 1.29438165 3
21 0.1972489 1.2400782 0.03280919 2
22 0.0000000 1.0231268 0.98567623 2
23 0.7298919 0.0000000 1.29438165 3
24 1.5703239 0.1523159 0.00000000 1
ore.odmOC関数は、直交パーティショニング・クラスタ(O-Cluster)アルゴリズムを使用してOracle Data Miningモデルを構築します。O-Clusterアルゴリズムは、グリッドベースの階層クラスタリング・モデルを構築しますが、つまり、軸並行な(直行の)パーティションを入力属性空間に作成します。このアルゴリズムは再帰的に作用します。生成される階層構造は、属性空間をクラスタに分割する不規則なグリッドになります。生成されるクラスタは、属性空間内の密度の高い領域を定義します。
クラスタは、属性軸沿いの間隔と、対応する重心およびヒストグラムによって記述されます。sensitivity引数は、基準となる密度レベルを定義します。最大密度がこの基準水準を上回る領域のみがクラスタとして認識されます。
k-Meansアルゴリズムの場合、自然なクラスタが存在しない可能性があっても、空間を分割します。たとえば、密度が均一な領域がある場合、k-Meansは、その領域をn個のクラスタ(nはユーザーが指定します)に分割します。O-Clusterは、低密度の領域に切断面を配置して、高密度の領域を切り離します。O-Clusterでは、複数の最頻値を持つヒストグラム(ピークと谷)を必要とします。ある領域に、密度が均一または単調に変化している投影がある場合、O-Clusterはその領域をパーティション化しません。
O-Clusterによって発見されたクラスタを使用して、ベイズ確率モデルが生成され、このモデルがpredict関数によるスコアリングの際に使用され、データ・ポイントをクラスタに割り当てます。生成される確率モデルは混合モデルで、混合要素は、量的属性の独立正規分布と質的属性の多項分布の積によって表されます。
O-Cluster用のデータをユーザー自身が準備する場合は、次の点に留意してください。
O-Clusterアルゴリズムでは、モデルを構築する際に、必ずしもすべての入力データを使用するわけではありません。O-Clusterは、データをバッチで読み込みます(デフォルトのバッチ・サイズは50,000)。統計テストに基づいて、まだ見つかっていないクラスタが存在すると考えられる場合にのみ、別のバッチを読み込みます。
O-Clusterは、すべてのデータを読み込むことなくモデルの作成を停止する場合があるので、データをランダム化しておくことをお薦めします。
2項属性は、質的属性として宣言する必要があります。O-Clusterは、質的データを数値にマップします。
ビンの必要数の概算が自動化されたOracle Data Miningの等幅ビニング変換を使用することを強くお薦めします。
外れ値が存在すると、クラスタリング・アルゴリズムに大きな影響を与える可能性があります。ビニングまたは正規化を行う前に、クリッピング変換を実行してください。等幅ビニングで外れ値が存在すると、O-Clusterでクラスタを検出できなくなる場合があります。その結果、母集団全体が1つのクラスタ内に含まれているように見えます。
formula引数の仕様には~ termsがあり、ここでtermsはモデルに含まれる列名です。複数のterms項目は列名の間に+を使用することで指定されます。~ .は、dataのすべての列をモデル構築に使用する場合に使用します。列を除外するには、除外する各列名の前に-を使用します。
ore.odmOC関数の引数の詳細は、help(ore.odmOC)を呼び出してください。
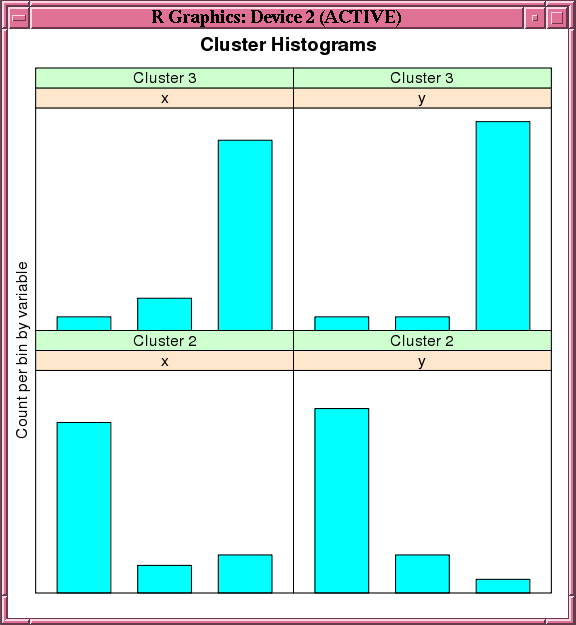
例4-17では、OCモデルを統合データセットに作成します。図4-4に、生成されるクラスタのヒストグラムを示します。
例4-17 ore.odmOC関数の使用方法
x <- rbind(matrix(rnorm(100, mean = 4, sd = 0.3), ncol = 2),
matrix(rnorm(100, mean = 2, sd = 0.3), ncol = 2))
colnames(x) <- c("x", "y")
x_of <- ore.push (data.frame(ID=1:100,x))
rownames(x_of) <- x_of$ID
oc.mod <- ore.odmOC(~., x_of, num.centers=2)
summary(oc.mod)
例4-17のリスト
R> x <- rbind(matrix(rnorm(100, mean = 4, sd = 0.3), ncol = 2),
+ matrix(rnorm(100, mean = 2, sd = 0.3), ncol = 2))
R> colnames(x) <- c("x", "y")
R> x_of <- ore.push (data.frame(ID=1:100,x))
R> rownames(x_of) <- x_of$ID
R> oc.mod <- ore.odmOC(~., x_of, num.centers=2)
R> summary(oc.mod)
Call:
ore.odmOC(formula = ~., data = x_of, num.centers = 2)
Settings:
value
clus.num.clusters 2
max.buffer 50000
sensitivity 0.5
prep.auto on
Clusters:
CLUSTER_ID ROW_CNT PARENT_CLUSTER_ID TREE_LEVEL DISPERSION IS_LEAF
1 1 100 NA 1 NA FALSE
2 2 56 1 2 NA TRUE
3 3 43 1 2 NA TRUE
Centers:
MEAN.x MEAN.y
2 1.85444 1.941195
3 4.04511 4.111740
R> histogram(oc.mod) # See Figure 4-4.
R> predict(oc.mod, x_of, type=c("class","raw"), supplemental.cols=c("x","y"))
'2' '3' x y CLUSTER_ID
1 3.616386e-08 9.999999e-01 3.825303 3.935346 3
2 3.253662e-01 6.746338e-01 3.454143 4.193395 3
3 3.616386e-08 9.999999e-01 4.049120 4.172898 3
# ... Intervening rows not shown.
98 1.000000e+00 1.275712e-12 2.011463 1.991468 2
99 1.000000e+00 1.275712e-12 1.727580 1.898839 2
100 1.000000e+00 1.275712e-12 2.092737 2.212688 2
ore.odmSVM関数は、Oracle Data Miningのサポート・ベクター・マシン(SVM)モデルを構築します。SVMは、Vapnik-Chervonenkis理論に基づいた強固な理論的基礎を持つ最新の強力なアルゴリズムです。SVMは、強力な正則化プロパティを持ちます。正則化とは、新しいデータへのモデルの一般化を指します。
SVMモデルは、一般的なデータ・マイニング手法であるニューラル・ネットワークおよび動径基底関数に似た関数形式を持ちます。
SVMは、次のような問題の解決に使用できます。
分類: SVM分類は、決定境界を定義する決定面の概念に基づいています。決定面は、異なるクラスのメンバーシップを持つオブジェクト・セット間を区別するものです。SVMは、クラスの最も広範な区切りを与えるセパレータを定義するベクター(サポート・ベクター)を検出します。
SVM分類では、2項および多クラスの両ターゲットがサポートされます。
回帰: SVMでは、回帰問題を解決するために、イプシロン非感受性損失関数が使用されます。
SVM回帰では、データ・ポイントの最大数がイプシロン幅の非感受性チューブ内に収まるような連続関数の検出が試行されます。真のターゲット値のイプシロン距離内におさまる予測は、誤差として解釈されません。
異常検出: 異常検出は、一見同質なデータ内に存在する特異なケースを識別します。異常検出は、重大な意味を持ちながら検出することが難しい、不正行為、ネットワークへの侵入などの発生頻度の低いイベントを検出するための重要なツールです。
異常検出は、1クラスSVM分類として実装されます。異常検出モデルでは、あるデータ・ポイントが特定の分布に対して典型的かどうかを予測します。
ore.odmSVM関数は、次の3つの異なるタイプのモデルを構築します。一部、分類モデルにのみ適用される引数、回帰モデルにのみ適用される引数、異常検出モデルにのみ適用される引数があります。
ore.odmSVM関数の引数の詳細は、help(ore.odmSVM)を呼び出してください。
例4-18に、SVM分類の使用を示します。この例では、Rのmtcarsデータセットからデータベースにmtcarsを作成し、分類モデルを構築し、予測を行い、最終的に、混同マトリクスを生成します。
例4-18 ore.odmSVM関数の使用方法および混同マトリクスの生成
m <- mtcars m$gear <- as.factor(m$gear) m$cyl <- as.factor(m$cyl) m$vs <- as.factor(m$vs) m$ID <- 1:nrow(m) mtcars_of <- ore.push(m) svm.mod <- ore.odmSVM(gear ~ .-ID, mtcars_of, "classification") summary(svm.mod) svm.res <- predict (svm.mod, mtcars_of,"gear") with(svm.res, table(gear, PREDICTION)) # generate confusion matrix
例4-18のリスト
R> m <- mtcars
R> m$gear <- as.factor(m$gear)
R> m$cyl <- as.factor(m$cyl)
R> m$vs <- as.factor(m$vs)
R> m$ID <- 1:nrow(m)
R> mtcars_of <- ore.push(m)
R>
R> svm.mod <- ore.odmSVM(gear ~ .-ID, mtcars_of, "classification")
R> summary(svm.mod)
Call:
ore.odmSVM(formula = gear ~ . - ID, data = mtcars_of, type = "classification")
Settings:
value
prep.auto on
active.learning al.enable
complexity.factor 0.385498
conv.tolerance 1e-04
kernel.cache.size 50000000
kernel.function gaussian
std.dev 1.072341
Coefficients:
[1] No coefficients with gaussian kernel
R> svm.res <- predict (svm.mod, mtcars_of,"gear")
R> with(svm.res, table(gear, PREDICTION)) # generate confusion matrix
PREDICTION
gear 3 4
3 12 3
4 0 12
5 2 3
例4-18に、SVM回帰を示します。この例では、データ・フレームを作成し、それを表にプッシュしてから、回帰モデルを構築します(ore.odmSVMでは、線形カーネルを指定します)。
例4-19 ore.odmSVM関数の使用方法および回帰モデルの構築
x <- seq(0.1, 5, by = 0.02) y <- log(x) + rnorm(x, sd = 0.2) dat <-ore.push(data.frame(x=x, y=y)) # Build model with linear kernel svm.mod <- ore.odmSVM(y~x,dat,"regression", kernel.function="linear") summary(svm.mod) coef(svm.mod) svm.res <- predict(svm.mod,dat, supplemental.cols="x") head(svm.res,6)
例4-18のリスト
R> x <- seq(0.1, 5, by = 0.02)
R> y <- log(x) + rnorm(x, sd = 0.2)
R> dat <-ore.push(data.frame(x=x, y=y))
R>
R> # Build model with linear kernel
R> svm.mod <- ore.odmSVM(y~x,dat,"regression", kernel.function="linear")
R> summary(svm.mod)
Call:
ore.odmSVM(formula = y ~ x, data = dat, type = "regression",
kernel.function = "linear")
Settings:
value
prep.auto on
active.learning al.enable
complexity.factor 0.620553
conv.tolerance 1e-04
epsilon 0.098558
kernel.function linear
Residuals:
Min. 1st Qu. Median Mean 3rd Qu. Max.
-0.79130 -0.28210 -0.05592 -0.01420 0.21460 1.58400
Coefficients:
variable value estimate
1 x 0.6637951
2 (Intercept) 0.3802170
R> coef(svm.mod)
variable value estimate
1 x 0.6637951
2 (Intercept) 0.3802170
R> svm.res <- predict(svm.mod,dat, supplemental.cols="x")
R> head(svm.res,6)
x PREDICTION
1 0.10 -0.7384312
2 0.12 -0.7271410
3 0.14 -0.7158507
4 0.16 -0.7045604
5 0.18 -0.6932702
6 0.20 -0.6819799
このSVN異常検出の例では、分類の例で作成されたmtcars_ofを使用し、異常検出モデルを構築します。
例4-20 ore.odmSVM関数の使用方法および異常検出モデルの構築
svm.mod <- ore.odmSVM(~ .-ID, mtcars_of, "anomaly.detection") summary(svm.mod) svm.res <- predict (svm.mod, mtcars_of, "ID") head(svm.res) table(svm.res$PREDICTION)
例4-18のリスト
R> svm.mod <- ore.odmSVM(~ .-ID, mtcars_of, "anomaly.detection")
R> summary(svm.mod)
Call:
ore.odmSVM(formula = ~. - ID, data = mtcars_of, type = "anomaly.detection")
Settings:
value
prep.auto on
active.learning al.enable
conv.tolerance 1e-04
kernel.cache.size 50000000
kernel.function gaussian
outlier.rate .1
std.dev 0.719126
Coefficients:
[1] No coefficients with gaussian kernel
R> svm.res <- predict (svm.mod, mtcars_of, "ID")
R> head(svm.res)
'0' '1' ID PREDICTION
Mazda RX4 0.4999405 0.5000595 1 1
Mazda RX4 Wag 0.4999794 0.5000206 2 1
Datsun 710 0.4999618 0.5000382 3 1
Hornet 4 Drive 0.4999819 0.5000181 4 1
Hornet Sportabout 0.4949872 0.5050128 5 1
Valiant 0.4999415 0.5000585 6 1
R> table(svm.res$PREDICTION)
0 1
5 27
予測モデルは通常、特定のデータに基づいて構築され、別に保存されているデータや未知データに基づいて検証されます。交差検定とはモデル改善手法の1つであり、使用可能なデータから繰り返しサンプリングを行って複数のモデルを構築およびテストすることにより、1回の学習/試験実験に伴う制約を回避します。その目的は、モデルが新しいデータに対して適切に一般化されるかを見極め、過剰適合の発生や、誤解を招きやすい既知データ特徴から誤った結論が導き出されるのを回避することにあります。
ore.CVユーティリティのR関数は、Oracle R Enterpriseを使用して回帰モデルと分類モデルの交差検定を実行します。関数ore.CVは、Oracle R Technologiesの次のブログ投稿からダウンロードできます。
https://blogs.oracle.com/R/entry/model_cross_validation_with_ore
関数ore.CVは、アルゴリズムおよびケースの選択セットに対して、Oracle R Enterpriseの回帰関数および分類関数によりインデータベース・データを使用して生成されたモデルに対する交差検定を実行します。
ore.CV関数は、次のOracle R Enterprise関数により生成されたモデルに使用できます。
ore.lm
ore.stepwise
ore.glm
ore.neural
ore.odmDT
ore.odmGLM
ore.odmNB
ore.odmSVM
また、ore.CVを使用すると、Oracle R Enterprise埋込みRの実行によってR回帰関数で生成されたモデルを交差検定することもできます。これらのR関数は次のとおりです。
lm
glm
svm
ore.CVの使用方法と使用例、および関数自体のダウンロード方法の詳細は、ブログ投稿を参照してください。