| Oracle® R Enterpriseユーザーズ・ガイド リリース1.4.1 E57720-01 |
|


 前 |
 次 |
この章では、分析用のデータを準備するためおよびデータの探索的分析を実行するためのOracle R Enterpriseオブジェクトの使用方法について説明します。これらの関数はすべて、モデリングのための非常に大規模なエンタープライズのデータベース常駐データの準備を容易にします。この章の内容は次のとおりです。
Oracle R Enterpriseを使用して、次の各項の説明に従って、データベースで分析用のデータを準備できます。
Oracle R Enterpriseには、Rを使用して分析用のデータベース・データを準備できる関数が用意されています。これらの関数を使用して、ore.frameおよびその他のOracle R Enterpriseオブジェクトでの一般的なデータ準備タスクを実行できます。データ準備操作は、データベースにある大量のデータに対して実行でき、Comprehensive R Archive Network (CRAN)で入手可能なパッケージの関数を使用して分析用のローカルのRセッションに結果をプルできます。
データに対して次のような操作を実行できます。
選択
ビニング
サンプリング
ソートおよび順序付け
集計
変換
日時データに対するデータ準備操作の実行
これらの操作の実行については、この章の他の項で説明します。
分析用のデータの準備の一般的な手順は、大規模なデータセットから対象の値を選択またはフィルタ処理することです。この項の例には、ore.frameオブジェクトから列、行および値でのデータの選択を示します。次の各トピックで例を示します。
例3-1では、ore.frameオブジェクトから列を選択します。まず、iris data.frameオブジェクトから、一時データベース表および対応するプロキシore.frameオブジェクトiris_ofを作成します。iris_ofの最初の3行を表示します。iris_ofから2行を選択し、それを使用してore.frameオブジェクトiris_projectedを作成します。その後、iris_projectedの最初の3行を表示します。
例3-1 列によるデータの選択
iris_of <- ore.push(iris)
head(iris_of, 3)
iris_projected = iris_of[, c("Petal.Length", "Species")]
head (iris_projected, 3)
例3-1のリスト
iris_of <- ore.push(iris)
head(iris_of, 3)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
R> iris_projected = iris_of[, c("Petal.Length", "Species")]
R> head (iris_projected, 3)
Petal.Length Species
1 1.4 setosa
2 1.4 setosa
3 1.3 setosa
例3-2では、順序付けられているore.frameオブジェクトから行を選択します。この例では最初に、順序付けられたore.frameオブジェクトの作成に使用するために、irisのdata.frameオブジェクトに列を追加します。データベース表IRIS_TABLEが存在する場合は、ore.drop関数を呼び出して削除します。次に、irisのdata.frameから、対応するプロキシore.frameオブジェクトのIRIS_TABLEとともに、データベース表を作成します。例では、ore.exec関数を呼び出して、RID列をデータベース表の主キーにするためのSQL文を実行します。次にore.sync関数を呼び出して、IRIS_TABLEのore.frameオブジェクトをこの表と同期化させ、プロキシore.frameオブジェクトの最初の3行を表示します。
例3-2では次に、IRIS_TABLEから行番号で51行を選択し、それを使用して順序付けられたore.frameオブジェクトのiris_selrowsを作成します。この例では、iris_selrowsの最初の6行を表示します。その後、行名で3行を選択して結果を表示します。
例3-2 行によるデータの選択
# Add a column to the iris data set to use as row identifiers.
iris$RID <- as.integer(1:nrow(iris) + 100)
ore.drop(table = 'IRIS_TABLE')
ore.create(iris, table = 'IRIS_TABLE')
ore.exec("alter table IRIS_TABLE add constraint IRIS_TABLE
primary key (\"RID\")")
ore.sync(table = "IRIS_TABLE")
head(IRIS_TABLE, 3)
# Select rows by row number.
iris_selrows <- IRIS_TABLE[50:100,]
head(iris_selrows)
# Select rows by row name.
IRIS_TABLE[c("101", "151", "201"),]
例3-2のリスト
R> # Add a column to the iris data set to use as row identifiers.
R> iris$RID <- as.integer(1:nrow(iris) + 100)
R> ore.drop(table = 'IRIS_TABLE')
R> ore.create(iris, table = 'IRIS_TABLE')
R> ore.exec("alter table IRIS_TABLE add constraint IRIS_TABLE
+ primary key (\"RID\")")
R> ore.sync(table = "IRIS_TABLE")
R> head(IRIS_TABLE, 3)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species RID
101 5.1 3.5 1.4 0.2 setosa 101
102 4.9 3.0 1.4 0.2 setosa 102
103 4.7 3.2 1.3 0.2 setosa 103
R> # Select rows by row number.
R> iris_selrows <- IRIS_TABLE[50:100,]
R> head(iris_selrows)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species RID
150 5.0 3.3 1.4 0.2 setosa 150
151 7.0 3.2 4.7 1.4 versicolor 151
152 6.4 3.2 4.5 1.5 versicolor 152
153 6.9 3.1 4.9 1.5 versicolor 153
154 5.5 2.3 4.0 1.3 versicolor 154
155 6.5 2.8 4.6 1.5 versicolor 155
R> # Select rows by row name.
R> IRIS_TABLE[c("101", "151", "201"),]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species RID
101 5.1 3.5 1.4 0.2 setosa 101
151 7.0 3.2 4.7 1.4 versicolor 151
201 6.3 3.3 6.0 2.5 virginica 201
例3-3に示すとおり、データセットの一部を選択できます。この例では、irisデータセットをデータベースにプッシュし、ore.frameオブジェクトのiris_ofを取得します。データをフィルタ処理してiris_of_filteredを生成しますが、これには、花弁の長さが1.5より短いもので、Sepal.Length列およびSpecies列にあるiris_ofの行の値が含まれています。この例ではさらに、条件を使用してデータをフィルタ処理して、setosa種または虹色の種で、花弁の幅が2.0より短いiris_ofの値がiris_of_filteredに含まれるようにします。
例3-3 値によるデータの選択
iris_of <- ore.push(iris)
# Select sepal length and species where petal length is less than 1.5.
iris_of_filtered <- iris_of[iris_of$Petal.Length < 1.5,
c("Sepal.Length", "Species")]
names(iris_of_filtered)
nrow(iris_of_filtered)
head(iris_of_filtered, 3)
# Alternate syntax filtering.
iris_of_filtered <- subset(iris_of, Petal.Length < 1.5)
nrow(iris_of_filtered)
head(iris_of_filtered, 3)
# Using the AND and OR conditions in filtering.
# Select all rows with in which the species is setosa or versicolor.
# and the petal width is less than 2.0.
iris_of_filtered <- iris_of[(iris_of$Species == "setosa" |
iris_of$Species == "versicolor") &
iris_of$Petal.Width < 2.0,]
nrow(iris_of_filtered)
head(iris_of, 3)
例3-3のリスト
R> iris_of <- ore.push(iris)
R> # Select sepal length and species where petal length is less than 1.5.
R> iris_of_filtered <- iris_of[iris_of$Petal.Length < 1.5,
+ c("Sepal.Length", "Species")]
R> names(iris_of_filtered)
[1] "Sepal.Length" "Species"
R> nrow(iris_of_filtered)
[1] 24
R> head(iris_of_filtered, 3)
Sepal.Length Species
1 5.1 setosa
2 4.9 setosa
3 4.7 setosa
R> # Alternate syntax filtering.
R> iris_of_filtered <- subset(iris_of, Petal.Length < 1.5)
R> nrow(iris_of_filtered)[1] 24
R> head(iris_of_filtered, 3)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
R> # Using the AND and OR conditions in filtering.
R> # Select all rows with in which the species is setosa or versicolor.
R> # and the petal width is less than 2.0.
R> iris_of_filtered <- iris_of[(iris_of$Species == "setosa" |
+ iris_of$Species == "versicolor") &
+ iris_of$Petal.Width < 2.0,]
R> nrow(iris_of_filtered)[1] 100
R> head(iris_of, 3)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
整数ベクターまたは文字列ベクターを使用して、順序付けられたore.frameオブジェクトに索引付けできます。「データのサンプリング」および「データのパーティショニング」で説明する、サンプリングおよびパーティショニングを実行するために索引付けを使用できます。
Oracle R EnterpriseはRの索引付けに類似した機能をサポートしますが、次の違いがあります。
ore.vectorオブジェクトでは整数索引の作成はサポートされません。
負の整数の索引はサポートされません。
行の順序は保持されません。
例3-4に、文字の索引付けおよび整数の索引付けを示します。この例では、例2-9のore.frameオブジェクトの順序付けられたSPAM_PKおよび順序付けられていないSPAM_NOPKを使用します。この例は、行に名前でアクセスできること、文字の行名のベクターを指定することで行のセットにアクセスできることも示します。次に、実際の整数値を指定できることを示します。例では、USERID値が1ではなく1001で始まるため、結果は様々な行のセットになります。
例3-4 ore.frameオブジェクトの索引付け
# Index to a specifically named row. SPAM_PK["2060", 1:4] # Index to a range of rows by row names. SPAM_PK[as.character(2060:2064), 1:4] # Index to a range of rows by integer index. SPAM_PK[2060:2063, 1:4]
例3-4のリスト
R> # Index to a specifically named row.
R> SPAM_PK["2060", 1:4]
TS USERID make address
2060 2060 380 0 0
R> # Index to a range of rows by row names.
R> SPAM_PK[as.character(2060:2064), 1:4]
TS USERID make address
2060 2060 380 0 0
2061 2061 381 0 0
2062 2062 381 0 0
2063 2063 382 0 0
2064 2064 382 0 0
R> # Index to a range of rows by integer index.
R> SPAM_PK[2060:2063, 1:4]
TS USERID make address
3060 3060 380 0.00 0.00
3061 3061 381 0.00 1.32
3062 3062 381 0.00 2.07
3063 3063 382 0.34 0.00
例3-5に示すとおり、merge関数を使用して、データベース表を表すore.frameオブジェクトのデータを結合できます。この例では、2つのdata.frameオブジェクトを作成してそれをマージします。次に、ore.create関数を呼び出して、それぞれのdata.frameオブジェクトにデータベース表を作成します。ore.create関数は、ore.frameオブジェクトを表のプロキシ・オブジェクトとして自動的に生成します。ore.frameオブジェクトには表と同じ名前が付けられます。この例では、ore.frameオブジェクトをマージします。2つのmerge操作の結果の順序は、ore.frameオブジェクトが順序付けられていないために同じでないことに注意してください。
例3-5 2つの表のデータの結合
# Create data.frame objects. df1 <- data.frame(x1=1:5, y1=letters[1:5]) df2 <- data.frame(x2=5:1, y2=letters[11:15]) # Combine the data.frame objects. merge (df1, df2, by.x="x1", by.y="x2") # Create database tables and ore.frame proxy objects to correspond to # the local R objects df1 and df2. ore.create(df1, table="DF1_TABLE") ore.create(df2, table="DF2_TABLE") # Combine the ore.frame objects. merge (DF1_TABLE, DF2_TABLE, by.x="x1", by.y="x2")
例3-5のリスト
R> # Create data.frame objects. R> df1 <- data.frame(x1=1:5, y1=letters[1:5]) R> df2 <- data.frame(x2=5:1, y2=letters[11:15]) R> # Combine the data.frame objects. R> merge (df1, df2, by.x="x1", by.y="x2") x1 y1 y2 1 1 a o 2 2 b n 3 3 c m 4 4 d l 5 5 e k R> # Create database tables and ore.frame proxy objects to correspond to R> # the local R objects df1 and df2. R> ore.create(df1, table="DF1_TABLE") R> ore.create(df2, table="DF2_TABLE") R> # Combine the ore.frame objects. R> merge (DF1_TABLE, DF2_TABLE, by.x="x1", by.y="x2") x1 y1 y2 1 5 e k 2 4 d l 3 3 c m 4 2 b n 5 1 a o Warning message: ORE object has no unique key - using random order
例3-6に示すとおり、aggregate関数を使用してデータを集計できます。この例では、irisデータセットをデータベース・メモリーにore.frameオブジェクトのiris_ofとしてプッシュします。length関数を使用して、iris_ofの値をSpecies列で集計します。その後、結果の最初の3行を表示します。
例3-6 データの集計
# Create a temporary database table from the iris data set and get an ore.frame.
iris_of <- ore.push(iris)
aggdata <- aggregate(iris_of$Sepal.Length,
by = list(species = iris_of$Species),
FUN = length)
head(aggdata, 3)
例3-6のリスト
# Create a temporary database table from the iris data set and get an ore.frame.
R> iris_of <- ore.push(iris)
R> aggdata <- aggregate(iris_of$Sepal.Length,
+ by = list(species = iris_of$Species),
+ FUN = length)
R> head(aggdata, 3)
species x
setosa setosa 50
versicolor versicolor 50
virginica virginica 50
|
関連項目: aggregate.Rのスクリプト例 |
分析用のデータの準備での一般的な手順は、データを再フォーマットするか新しい列を導出してデータセットに追加することによってデータを変換することです。この項の例では、データのフォーマットおよび列の導出のための2つの方法を示します。例3-7では、列のデータをフォーマットするための関数を作成し、例3-8では、transform関数を使用して同じことを行います。例3-9では、transform関数を使用して、列をデータセットに追加します。
例3-7 データのフォーマット
# Create a function for formatting data.
petalCategory_fmt <- function(x) {
ifelse(x > 5, 'LONG',
ifelse(x > 2, 'MEDIUM', 'SMALL'))
}
# Create an ore.frame in database memory with the iris data set.
iris_of <- ore.push(iris)
# Select some rows from iris_of.
iris_of[c(10, 20, 60, 80, 110, 140),]
# Format the data in Petal.Length column.
iris_of$Petal.Length <- petalCategory_fmt(iris_of$Petal.Length)
# Select the same rows from iris_of.
例3-7のリスト
# Create a function for formatting data.
R> petalCategory_fmt <- function(x) {
+ ifelse(x > 5, 'LONG',
+ ifelse(x > 2, 'MEDIUM', 'SMALL'))
+ }
# Create an ore.frame in database memory with the iris data set.
R> iris_of <- ore.push(iris)
# Select some rows from iris_of.
R> iris_of[c(10, 20, 60, 80, 110, 140),]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
10 4.9 3.1 1.5 0.1 setosa
20 5.1 3.8 1.5 0.3 setosa
60 5.2 2.7 3.9 1.4 versicolor
80 5.7 2.6 3.5 1.0 versicolor
110 7.2 3.6 6.1 2.5 virginica
140 6.9 3.1 5.4 2.1 virginica
# Format the data in Petal.Length column.
R> iris_of$Petal.Length <- petalCategory_fmt(iris_of$Petal.Length)
# Select the same rows from iris_of.
R> iris_of[c(10, 20, 60, 80, 110, 140),]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
10 4.9 3.1 SMALL 0.1 setosa
20 5.1 3.8 SMALL 0.3 setosa
60 5.2 2.7 MEDIUM 1.4 versicolor
80 5.7 2.6 MEDIUM 1.0 versicolor
110 7.2 3.6 LONG 2.5 virginica
140 6.9 3.1 LONG 2.1 virginica
例3-8では、データセットの列にあるデータを再フォーマットするためにtransform関数を使用することを除いて、例3-7と同じことを行います。
例3-8 transform関数の使用方法
# Create an ore.frame in database memory with the iris data set.
iris_of2 <- ore.push(iris)
# Select some rows from iris_of.
iris_of2[c(10, 20, 60, 80, 110, 140),]
iris_of2 <- transform(iris_of2,
Petal.Length = ifelse(Petal.Length > 5, 'LONG',
ifelse(Petal.Length > 2, 'MEDIUM', 'SMALL')))
iris_of2[c(10, 20, 60, 80, 110, 140),]
例3-8のリスト
# Create an ore.frame in database memory with the iris data set.
R> iris_of2 <- ore.push(iris)
# Select some rows from iris_of.
R> iris_of2[c(10, 20, 60, 80, 110, 140),]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
10 4.9 3.1 1.5 0.1 setosa
20 5.1 3.8 1.5 0.3 setosa
60 5.2 2.7 3.9 1.4 versicolor
80 5.7 2.6 3.5 1.0 versicolor
110 7.2 3.6 6.1 2.5 virginica
140 6.9 3.1 5.4 2.1 virginica
R> iris_of2 <- transform(iris_of2,
+ Petal.Length = ifelse(Petal.Length > 5, 'LONG',
+ ifelse(Petal.Length > 2, 'MEDIUM', 'SMALL')))
R> iris_of2[c(10, 20, 60, 80, 110, 140),]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
10 4.9 3.1 SMALL 0.1 setosa
20 5.1 3.8 SMALL 0.3 setosa
60 5.2 2.7 MEDIUM 1.4 versicolor
80 5.7 2.6 MEDIUM 1.0 versicolor
110 7.2 3.6 LONG 2.5 virginica
140 6.9 3.1 LONG 2.1 virginica
例3-9では、transform関数を使用して派生列をデータセットに追加した後に、追加の列を追加します。
例3-9 派生列の追加
# Set the page width.
options(width = 80)
# Create an ore.frame in database memory with the iris data set.
iris_of <- ore.push(iris)
names(iris_of)
# Add one column derived from another
iris_of <- transform(iris_of, LOG_PL = log(Petal.Length))
names(iris_of)
head(iris_of, 3)
# Add more columns.
iris_of <- transform(iris_of,
SEPALBINS = ifelse(Sepal.Length < 6.0, "A", "B"),
PRODUCTCOLUMN = Petal.Length * Petal.Width,
CONSTANTCOLUMN = 10)
names(iris_of)
# Select some rows of iris_of.
iris_of[c(10, 20, 60, 80, 110, 140),]
例3-9のリスト
R> # Set the page width.
R> options(width = 80)
# Create an ore.frame in database memory with the iris data set.
R> iris_of <- ore.push(iris)
R> names(iris_of)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
R> # Add one column derived from another
R> iris_of <- transform(iris_of, LOG_PL = log(Petal.Length))
R> names(iris_of)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
[6] "LOG_PL"
R> head(iris_of, 3)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species LOG_PL
1 5.1 3.5 1.4 0.2 setosa 0.3364722
2 4.9 3.0 1.4 0.2 setosa 0.3364722
3 4.7 3.2 1.3 0.2 setosa 0.2623643
R> # Add more columns.
R> iris_of <- transform(iris_of,
SEPALBINS = ifelse(Sepal.Length < 6.0, "A", "B"),
PRODUCTCOLUMN = Petal.Length * Petal.Width,
CONSTANTCOLUMN = 10)
R> names(iris_of)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width"
[5] "Species" "LOG_PL" "CONSTANTCOLUMN" "SEPALBINS"
[9] "PRODUCTCOLUMN"
R> # Select some rows of iris_of.
R> iris_of[c(10, 20, 60, 80, 110, 140),]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species LOG_PL
10 4.9 3.1 1.5 0.1 setosa 0.4054651
20 5.1 3.8 1.5 0.3 setosa 0.4054651
60 5.2 2.7 3.9 1.4 versicolor 1.3609766
80 5.7 2.6 3.5 1.0 versicolor 1.2527630
110 7.2 3.6 6.1 2.5 virginica 1.8082888
140 6.9 3.1 5.4 2.1 virginica 1.6863990
CONSTANTCOLUMN SEPALBINS PRODUCTCOLUMN
10 10 A 0.15
20 10 A 0.45
60 10 A 5.46
80 10 A 3.50
110 10 B 15.25
140 10 B 11.34
|
関連項目: derived.Rのスクリプト例 |
サンプリングは統計分析の重要な機能です。通常、データのサイズを減らし、意味のある作業を実行するためにデータをサンプリングします。Rでは、通常、サンプリングするには、データをメモリーにロードする必要があります。ただし、データが非常に大きい場合、それは不可能です。
Oracle R Enterpriseでは、データベースからデータをプルしてサンプリングするかわりに、データベースで直接サンプリングしてそのサンプル部分であるレコードのみをプルできます。データベースでサンプリングすることで、データの移動を最小化するため、より大きなデータセットで作業できます。これは、この機能を可能にする透過層での順序付けフレームワークの整数行の索引付けであることに注意してください。
この項の例に、いくつかのサンプリング手法を示します。同様の例は、sampling.Rのスクリプト例にあります。
例3-10に、行をランダムに簡単に選択する方法を示します。この例では、小規模なdata.frameオブジェクトを作成し、それをデータベースにプッシュしてore.frameオブジェクトであるMYDATAを作成します。20行のうちの5行をサンプリングします。Rのsample関数を使用して、MYDATAからサンプルを取得するために使用する索引のランダムなセットを生成します。このサンプル(simpleRandomSample)はore.frameオブジェクトです。
例3-10 簡単なランダム・サンプリング
set.seed(1) N <- 20 myData <- data.frame(a=1:N,b=letters[1:N]) MYDATA <- ore.push(myData) head(MYDATA) sampleSize <- 5 simpleRandomSample <- MYDATA[sample(nrow(MYDATA), sampleSize), , drop=FALSE] class(simpleRandomSample) simpleRandomSample
例3-10のリスト
R> set.seed(1)
R> N <- 20
R> myData <- data.frame(a=1:N,b=letters[1:N])
R> MYDATA <- ore.push(myData)
R> head(MYDATA)
a b
1 1 a
2 2 b
3 3 c
4 4 d
5 5 e
6 6 f
R> sampleSize <- 5
R> simpleRandomSample <- MYDATA[sample(nrow(MYDATA), sampleSize), , drop=FALSE]
R> class(simpleRandomSample)
[1] "ore.frame"
attr(,"package")
[1] "OREbase"
R> simpleRandomSample
a b
2 2 b
7 7 g
10 10 j
12 12 l
19 19 s
例3-11に、トレーニング・セットおよびテスト・セットへのデータのランダムなパーティショニングを示します。このデータの分割は通常、新しいデータに対するモデルの効果を評価するために、分類および回帰で行われます。この例では、例3-10で作成したMYDATAオブジェクトを使用します。
例3-11では、テスト・データセットとして使用するための索引のサンプル・セットを生成します。次に、論理ベクターgroupを作成します(索引がサンプルにある場合はTRUE、そうでない場合はFALSE)。次に、行の索引付けを使用して、トレーニング・セット(groupがFALSE)およびテスト・セット(groupがTRUE)を生成します。sample関数の呼出し時に指定したとおり、トレーニング・セットの行数は15でテスト・セットの行数は5であることに注意してください。
例3-11 分割データ・サンプリング
set.seed(1) sampleSize <- 5 ind <- sample(1:nrow(MYDATA), sampleSize) group <- as.integer(1:nrow(MYDATA) %in% ind) MYDATA.train <- MYDATA[group==FALSE,] dim(MYDATA.train) MYDATA.test <- MYDATA[group==TRUE,] dim(MYDATA.test)
例3-11のリスト
R> set.seed(1) R> sampleSize <- 5 R> ind <- sample(1:nrow(MYDATA), sampleSize) R> group <- as.integer(1:nrow(MYDATA) %in% ind) R> MYDATA.train <- MYDATA[group==FALSE,] dim(MYDATA.train) [1] 15 2 R> MYDATA.test <- MYDATA[group==TRUE,] R> dim(MYDATA.test) [1] 5 2
例3-12に、定期的に行が選択される系統的サンプリングを示します。この例では、seq関数を使用して、2から始まり3ずつ増加する一連の値を作成します。この順序の値の数はMYDATAの行数と同じです。MYDATAオブジェクトは例3-10で作成しています。
例3-12 系統的サンプリング
set.seed(1) N <- 20 myData <- data.frame(a=1:20,b=letters[1:N]) MYDATA <- ore.push(myData) head(MYDATA) start <- 2 by <- 3 systematicSample <- MYDATA[seq(start, nrow(MYDATA), by = by), , drop = FALSE] systematicSample
例3-12のリスト
R> set.seed(1)
R> N <- 20
R> myData <- data.frame(a=1:20,b=letters[1:N])
R> MYDATA <- ore.push(myData)
R> head(MYDATA)
a b
1 1 a
2 2 b
3 3 c
4 4 d
5 5 e
6 6 f
R> start <- 2
R> by <- 3
R> systematicSample <- MYDATA[seq(start, nrow(MYDATA), by = by), , drop = FALSE]
systematicSample
a b
2 2 b
5 5 e
8 8 h
11 11 k
14 14 n
17 17 q
20 20 t
例3-13に、層別サンプリングを示しますが、ここでは、行は各グループ(特定の列の値によって定義されます)内で選択されます。この例では、各行がグループに割り当てられているデータセットを作成します。関数rnormはランダムの正規値を生成します。引数4は分布の目標平均です。グループに応じてデータを分割し、各パーティションに比例してサンプリングします。最後に、サブセットore.frameオブジェクトのリストを1つのore.frameオブジェクトに行バインドし、結果の値stratifiedSampleを表示します。
例3-13 層別サンプリング
set.seed(1)
N <- 200
myData <- data.frame(a=1:N,b=round(rnorm(N),2),
group=round(rnorm(N,4),0))
MYDATA <- ore.push(myData)
head(MYDATA)
sampleSize <- 10
stratifiedSample <- do.call(rbind,
lapply(split(MYDATA, MYDATA$group),
function(y) {
ny <- nrow(y)
y[sample(ny, sampleSize*ny/N), , drop = FALSE]
}))
stratifiedSample
例3-13のリスト
R> set.seed(1)
R> N <- 200
R> myData <- data.frame(a=1:N,b=round(rnorm(N),2),
+ group=round(rnorm(N,4),0))
R> MYDATA <- ore.push(myData)
R> head(MYDATA)
a b group
1 1 -0.63 4
2 2 0.18 6
3 3 -0.84 6
4 4 1.60 4
5 5 0.33 2
6 6 -0.82 6
R> sampleSize <- 10
R> stratifiedSample <- do.call(rbind,
+ lapply(split(MYDATA, MYDATA$group),
+ function(y) {
+ ny <- nrow(y)
+ y[sample(ny, sampleSize*ny/N), , drop = FALSE]
+ }))
R> stratifiedSample
a b group
173|173 173 0.46 3
9|9 9 0.58 4
53|53 53 0.34 4
139|139 139 -0.65 4
188|188 188 -0.77 4
78|78 78 0.00 5
137|137 137 -0.30 5
例3-14に、グループ全体がランダムに選択されるクラスタ・サンプリングを示します。この例では、グループに応じてデータを分割してから、グループ内でサンプリングし、1つのore.frameオブジェクトに行バインドします。生成されるサンプルには、6および7の2つのクラスタのデータが含まれます。
例3-14 クラスタ・サンプリング
set.seed(1)
N <- 200
myData <- data.frame(a=1:N,b=round(runif(N),2),
group=round(rnorm(N,4),0))
MYDATA <- ore.push(myData)
head(MYDATA)
sampleSize <- 5
clusterSample <- do.call(rbind,
sample(split(MYDATA, MYDATA$group), 2))
unique(clusterSample$group)
例3-14のリスト
R> set.seed(1) R> N <- 200 R> myData <- data.frame(a=1:N,b=round(runif(N),2), + group=round(rnorm(N,4),0)) R> MYDATA <- ore.push(myData) R> head(MYDATA) a b group 1 1 0.27 3 2 2 0.37 4 3 3 0.57 3 4 4 0.91 4 5 5 0.20 3 6 6 0.90 6 R> sampleSize <- 5 R> clusterSample <- do.call(rbind, + sample(split(MYDATA, MYDATA$group), 2)) R> unique(clusterSample$group) [1] 6 7
例3-15に、サンプルとして連続したレコード番号が選択される割当てサンプリングを示します。この例では、head関数を使用してサンプルを選択します。tail関数も使用できます。
例3-15 割当てサンプリング
set.seed(1) N <- 200 myData <- data.frame(a=1:N,b=round(runif(N),2)) MYDATA <- ore.push(myData) sampleSize <- 10 quotaSample1 <- head(MYDATA, sampleSize) quotaSample1
例3-15のリスト
R> set.seed(1)
R> N <- 200
R> myData <- data.frame(a=1:N,b=round(runif(N),2))
R> MYDATA <- ore.push(myData)
R> sampleSize <- 10
R> quotaSample1 <- head(MYDATA, sampleSize)
R> quotaSample1
a b
1 1 0.15
2 2 0.75
3 3 0.98
4 4 0.97
5 5 0.35
6 6 0.39
7 7 0.95
8 8 0.11
9 9 0.93
10 10 0.35
大規模なデータセットの分析での通常の操作は、データセットをランダムにサブセットにパーティショニングすることです。例3-16に示すとおり、Oracle R Enterpriseの埋込みRの実行を使用することでパーティションを分析できます。この例では、data.frameオブジェクトを記号myDataを付けてローカルのRセッションに作成し、ランダムに生成された値のセットを含むそのオブジェクトに列を追加します。このデータセットをオブジェクトMYDATAとしてデータベース・メモリーにプッシュします。この例では、埋込みRの実行関数ore.groupApplyを呼び出し、パーティション列に基づいてデータをパーティショニングした後に、各パーティションにlm関数を適用します。
例3-16 データのランダムなパーティショニング
N <- 200
k <- 5
myData <- data.frame(a=1:N,b=round(runif(N),2))
myData$partition <- sample(rep(1:k, each = N/k,
length.out = N), replace = TRUE)
MYDATA <- ore.push(myData)
head(MYDATA)
results <- ore.groupApply(MYDATA, MYDATA$partition,
function(y) {lm(b~a,y)}, parallel = TRUE)
length(results)
results[[1]]
例3-16のリスト
R> N <- 200
R> k <- 5
R> myData <- data.frame(a=1:N,b=round(runif(N),2))
R> myData$partition <- sample(rep(1:k, each = N/k,
+ length.out = N), replace = TRUE)
R> MYDATA <- ore.push(myData)
R> head(MYDATA)
a b partition
1 1 0.89 2
2 2 0.31 4
3 3 0.39 5
4 4 0.66 3
5 5 0.01 1
6 6 0.12 4
R> results <- ore.groupApply(MYDATA, MYDATA$partition,
+ function(y) {lm(b~a,y)}, parallel = TRUE)
R> length(results)
[1] 5
R> results[[1]]
Call:
lm(formula = b ~ a, data = y)
Coefficients:
(Intercept) a
0.388795 0.001015
Oracle R Enterpriseでは、時系列データに対して、データのフィルタ処理、順序付け、変換などの多数のデータの準備操作を実行できます。Oracle R Enterpriseは、表1-1に示すようにRデータ型をSQLデータ型にマップすることで、Oracle R Enterpriseオブジェクトを作成し、データ準備操作をデータベース・メモリーで実行できます。
次の例では、時系列データに対する操作の一部を示します。
例3-17に、統計の集計関数の一部を示します。最初に、データセットに対して、2001年全体に均等に分散された一連の日付をローカル・クライアントに500個生成します。次に、ランダムのdifftimeおよびランダムの正規値のベクターを使用します。その後、ore.push関数を使用してデータのインデータベース版であるMYDATAを作成します。この例では、MYDATAがore.frameオブジェクトであること、およびdatetime列がクラスore.datetimeであることを示すためにclass関数を呼び出します。この例では、生成されたデータの最初の3行を表示します。次に、min、max、range、medianおよびquantileの統計の集計操作をMYDATAのdatetime列で使用します。
例3-17 日時データの集計
N <- 500
mydata <- data.frame(datetime =
seq(as.POSIXct("2001/01/01"),
as.POSIXct("2001/12/31"),
length.out = N),
difftime = as.difftime(runif(N),
units = "mins"),
x = rnorm(N))
MYDATA <- ore.push(mydata)
class(MYDATA)
class(MYDATA$datetime)
head(MYDATA,3)
# statistical aggregations
min(MYDATA$datetime)
max(MYDATA$datetime)
range(MYDATA$datetime)
quantile(MYDATA$datetime,
probs = c(0, 0.05, 0.10))
例3-17のリスト
R> N <- 500
R> mydata <- data.frame(datetime =
+ seq(as.POSIXct("2001/01/01"),
+ as.POSIXct("2001/12/31"),
+ length.out = N),
+ difftime = as.difftime(runif(N),
+ units = "mins"),
+ x = rnorm(N))
R> MYDATA <- ore.push(mydata)
R> class(MYDATA)
[1] "ore.frame"
attr(,"package")
[1] "OREbase"
R> class(MYDATA$datetime)
[1] "ore.datetime"
attr(,"package")
[1] "OREbase"
R> head(MYDATA,3)
datetime difftime x
1 2001-01-01 00:00:00 16.436782 secs 0.68439244
2 2001-01-01 17:30:25 8.711562 secs 1.38481435
3 2001-01-02 11:00:50 1.366927 secs -0.00927078
R> # statistical aggregations
R> min(MYDATA$datetime)
[1] "2001-01-01 CST"
R> max(MYDATA$datetime)
[1] "2001-12-31 CST"
R> range(MYDATA$datetime)
[1] "2001-01-01 CST" "2001-12-31 CST"
R> quantile(MYDATA$datetime,
+ probs = c(0, 0.05, 0.10))
0% 5% 10%
"2001-01-01 00:00:00 CST" "2001-01-19 04:48:00 CST" "2001-02-06 09:36:00 CST"
例3-18では、例3-17で作成したMYDATAのore.frameのdatetime列を使用して、1日分のdifftimeを追加することで、1日分のずれを作成します。結果はday1Shiftで、この例の表示ではore.datetimeクラスです。この例では、MYDATAのdatetime列およびday1Shiftの最初の3要素を表示します。day1Shiftの最初の要素は2001年1月2日です。
例3-18ではさらに、オーバーロードされたdiff関数を使用して遅れの差を計算します。MYDATAの500日は2001年全体で均等に分散されているため、日付間の差はすべて同じです。
例3-18 日付および時間の計算の使用方法
day1Shift <- MYDATA$datetime + as.difftime(1, units = "days") class(day1Shift) head(MYDATA$datetime,3) head(day1Shift,3) lag1Diff <- diff(MYDATA$datetime) class(lag1Diff) head(lag1Diff,3)
例3-18のリスト
R> day1Shift <- MYDATA$datetime + as.difftime(1, units = "days") R> class(day1Shift) [1] "ore.datetime" attr(,"package") [1] "OREbase" R> head(MYDATA$datetime,3) [1] "2001-01-01 00:00:00 CST" "2001-01-01 17:30:25 CST" "2001-01-02 11:00:50 CST" R> head(day1Shift,3) [1] "2001-01-02 00:00:00 CST" "2001-01-02 17:30:25 CST" "2001-01-03 11:00:50 CST" R> lag1Diff <- diff(MYDATA$datetime) R> class(lag1Diff) [1] "ore.difftime" attr(,"package") [1] "OREbase" R> head(lag1Diff,3) Time differences in secs [1] 63025.25 63025.25 63025.25
例3-19に、日付および時間の比較を示します。この例では、例3-17で作成したMYDATAのore.frameオブジェクトのdatetime列を使用します。例3-19では、2001年4月1日より前の日付を含むMYDATAの要素を選択します。生成されるisQ1はクラスore.logicalで、最初の3エントリの結果はTRUEです。この例では、isQ1に一致する日付が3月に何日あるかを検出します。次に、論理ベクターを集計して結果(3月には43行)を表示します。この例では次に、その年の12月27日以降の最後の日付に基づいて行をフィルタします。この結果はeoySubsetで、これはore.frameオブジェクトです。この例では、eoySubsetで返された最初の3行を表示します。
例3-19 日付および時間の比較
isQ1 <- MYDATA$datetime < as.Date("2001/04/01")
class(isQ1)
head(isQ1,3)
isMarch <- isQ1 & MYDATA$datetime > as.Date("2001/03/01")
class(isMarch)
head(isMarch,3)
sum(isMarch)
eoySubset <- MYDATA[MYDATA$datetime > as.Date("2001/12/27"), ]
class(eoySubset)
head(eoySubset,3)
例3-19のリスト
R> isQ1 <- MYDATA$datetime < as.Date("2001/04/01")
R> class(isQ1)
[1] "ore.logical"
attr(,"package")
[1] "OREbase"
R> head(isQ1,3)
[1] TRUE TRUE TRUE
R> isMarch <- isQ1 & MYDATA$datetime > as.Date("2001/03/01")
R> class(isMarch)
[1] "ore.logical"
attr(,"package")
[1] "OREbase"
R> head(isMarch,3)
[1] FALSE FALSE FALSE
R> sum(isMarch)
[1] 43
R> eoySubset <- MYDATA[MYDATA$datetime > as.Date("2001/12/27"), ]
R> class(eoySubset)
[1] "ore.frame"
attr(,"package")
[1] "OREbase"
R> head(eoySubset,3)
datetime difftime x
495 2001-12-27 08:27:53 55.76474 secs -0.2740492
496 2001-12-28 01:58:18 15.42946 secs -1.4547270
497 2001-12-28 19:28:44 28.62195 secs 0.2929171
Oracle R Enterpriseには、datetimeオブジェクトから年、月、月の日付、時間、分、秒などの様々なコンポーネントの抽出に使用できるアクセッサ関数があります。例3-20に、これらの関数の使用を示します。この例では、例3-17で作成したMYDATAのore.frameオブジェクトのdatetime列を使用します。
例3-20では、datetime列の年要素を取得します。yearに対してunique関数を呼び出すと、列内の唯一の年の値である2001が表示されます。ただし、値の範囲を持つore.mdayなどのオブジェクトの場合は、range関数は月の日付を返します。この結果には、1から31の間の値を持つベクターが含まれています。他のアクセッサ関数で示すように、range関数を呼び出すと、値の範囲が簡潔にレポートされます。
例3-20 日付および時間のアクセッサの使用方法
year <- ore.year(MYDATA$datetime) unique(year) month <- ore.month(MYDATA$datetime) range(month) dayOfMonth <- ore.mday(MYDATA$datetime) range(dayOfMonth) hour <- ore.hour(MYDATA$datetime) range(hour) minute <- ore.minute(MYDATA$datetime) range(minute) second <- ore.second(MYDATA$datetime) range(second)
例3-20のリスト
R> year <- ore.year(MYDATA$datetime) R> unique(year) [1] 2001 R> month <- ore.month(MYDATA$datetime) R> range(month) [1] 1 12 R> dayOfMonth <- ore.mday(MYDATA$datetime) R> range(dayOfMonth) [1] 1 31 R> hour <- ore.hour(MYDATA$datetime) R> range(hour) [1] 0 23 R> minute <- ore.minute(MYDATA$datetime) R> range(minute) [1] 0 59 R> second <- ore.second(MYDATA$datetime) R> range(second) [1] 0.00000 59.87976
例3-21では、as.oreサブクラスのオブジェクトを使用して、ore.datetimeデータ型を他のデータ型に強制変換します。この例では、例3-17で作成したMYDATAのore.frameオブジェクトのdatetime列を使用します。この列にはore.datetime値が含まれています。例3-21では、最初にMYDATA$datetime列から日付を抽出します。生成されるdateOnlyオブジェクトには、年、月および日のみを含み時間を含まないore.date値が含まれます。この例では次に、ore.datetime値を、日の名前、年の日数および年の四半期を表すore.character値およびore.integer値を持つオブジェクトに強制変換します。
例3-21 日付および時間のデータ型の強制変換
dateOnly <- as.ore.date(MYDATA$datetime) class(dateOnly) head(sort(unique(dateOnly)),3) nameOfDay <- as.ore.character(MYDATA$datetime, format = "DAY") class(nameOfDay) sort(unique(nameOfDay)) dayOfYear <- as.integer(as.character(MYDATA$datetime, format = "DDD")) class(dayOfYear) range(dayOfYear) quarter <- as.integer(as.character(MYDATA$datetime, format = "Q")) class(quarter) sort(unique(quarter))
例3-21のリスト
R> dateOnly <- as.ore.date(MYDATA$datetime) R> class(dateOnly)[1] "ore.date" attr(,"package")[1] "OREbase" R> head(sort(unique(dateOnly)),3) [1] "2001-01-01" "2001-01-02" "2001-01-03" R> nameOfDay <- as.ore.character(MYDATA$datetime, format = "DAY") R> class(nameOfDay) [1] "ore.character" attr(,"package") [1] "OREbase" R> sort(unique(nameOfDay)) [1] "FRIDAY " "MONDAY " "SATURDAY " "SUNDAY " "THURSDAY " "TUESDAY " "WEDNESDAY" R> dayOfYear <- as.integer(as.character(MYDATA$datetime, format = "DDD")) R> class(dayOfYear) [1] "ore.integer" attr(,"package") [1] "OREbase" R> range(dayOfYear) [1] 1 365 R> quarter <- as.integer(as.character(MYDATA$datetime, format = "Q")) R> class(quarter) [1] "ore.integer" attr(,"package") [1] "OREbase" R> sort(unique(quarter)) [1] 1 2 3 4
例3-22では、ウィンドウ関数のore.rollmeanおよびore.rollsdを使用して、ローリング平均およびローリング標準偏差を計算します。この例では、例3-17で作成したMYDATAのore.frameオブジェクトを使用します。この例では、datetime列の値をMYDATAの行名として割り当てることで、MYDATAが順序付けられたore.frameであることを確認します。この例では、5期間のローリング平均およびローリング標準偏差を計算します。次に、statsパッケージでRの時系列機能を使用するために、クライアントにデータをプルします。クライアントにプルするデータを制限するために、例3-19のベクターis.Marchを使用して3月をポイントするデータのみを選択します。この例では、ts関数を使用して時系列オブジェクトを作成し、Arimaモデルを構築し、3点を予測します。
例3-22 ウィンドウ関数の使用方法
row.names(MYDATA) <- MYDATA$datetime MYDATA$rollmean5 <- ore.rollmean(MYDATA$x, k = 5) MYDATA$rollsd5 <- ore.rollsd (MYDATA$x, k = 5) head(MYDATA) marchData <- ore.pull(MYDATA[isMarch,]) tseries.x <- ts(marchData$x) arima110.x <- arima(tseries.x, c(1,1,0)) predict(arima110.x, 3) tseries.rm5 <- ts(marchData$rollmean5) arima110.rm5 <- arima(tseries.rm5, c(1,1,0)) predict(arima110.rm5, 3)
例3-22のリスト
R> row.names(MYDATA) <- MYDATA$datetime
R> MYDATA$rollmean5 <- ore.rollmean(MYDATA$x, k = 5)
R> MYDATA$rollsd5 <- ore.rollsd (MYDATA$x, k = 5)
R> head(MYDATA)
datetime difftime
2001-01-01 00:00:00 2001-01-01 00:00:00 39.998460 secs
x rollmean5 rollsd5
-0.3450421 -0.46650761 0.8057575
datetime difftime
2001-01-01 17:30:25 2001-01-01 17:30:25 37.75568 secs
x rollmean5 rollsd5
-1.3261019 0.02877517 1.1891384
datetime difftime
2001-01-02 11:00:50 2001-01-02 11:00:50 18.44243 secs
x rollmean5 rollsd5
0.2716211 -0.13224503 1.0909515
datetime difftime
2001-01-03 04:31:15 2001-01-03 04:31:15 38.594384 secs
x rollmean5 rollsd5
1.5146235 0.36307913 1.4674456
datetime difftime
2001-01-03 22:01:41 2001-01-03 22:01:41 2.520976 secs
x rollmean5 rollsd5
-0.7763258 0.80073340 1.1237925
datetime difftime
2001-01-04 15:32:06 2001-01-04 15:32:06 56.333281 secs
x rollmean5 rollsd5
2.1315787 0.90287282 1.0862614
R> marchData <- ore.pull(MYDATA[isMarch,])
R> tseries.x <- ts(marchData$x)
R> arima110.x <- arima(tseries.x, c(1,1,0))
R> predict(arima110.x, 3)
$pred
Time Series:
Start = 44
End = 46
Frequency = 1
[1] 1.4556614 0.6156379 1.1387587
$se
Time Series:
Start = 44
End = 46
Frequency = 1
[1] 1.408117 1.504988 1.850830
R> tseries.rm5 <- ts(marchData$rollmean5)
R> arima110.rm5 <- arima(tseries.rm5, c(1,1,0))
R> predict(arima110.rm5, 3)
$pred
Time Series:
Start = 44
End = 46
Frequency = 1
[1] 0.3240135 0.3240966 0.3240922
$se
Time Series:
Start = 44
End = 46
Frequency = 1
[1] 0.3254551 0.4482886 0.5445763
Oracle R Enterpriseには、探索的データ分析を実行できる関数があります。これらの関数を使用して、一般的な統計操作を実行できます。
関数およびその使用について、次の各項で説明します。
探索的データ分析用のOracle R Enterpriseの関数は、OREedaパッケージにあります。表3-1に、このパッケージにある関数をリストします。
表3-1 OREedaパッケージの関数
| 関数 | 説明 |
|---|---|
|
|
|
|
|
オプションの集計、重み付けおよび順序付けオプションで複数の列をサポートすることで、 |
|
|
順序付けられた |
|
|
|
|
|
|
|
|
|
|
|
柔軟な行集約内の |
|
|
|
探索的データ分析関数の多くの例で、NARROWデータセットを使用します。NARROWは、例3-23に示すとおり、9列および1500行のore.frameです。一部の列は数値で、それ以外の列もあります。
例3-23のリスト
R> class(NARROW) [1] "ore.frame" attr(,"package") [1] "OREbase" R> dim(NARROW)[1] 1500 9 R> names(NARROW) [1] "ID" "GENDER" "AGE" "MARITAL_STATUS" [5] "COUNTRY" "EDUCATION" "OCCUPATION" "YRS_RESIDENCE" [9] "CLASS"
ore.corr関数を使用して相関分析を実行できます。ore.corrを使用すると、次のことを実行できます。
ore.frameによる数値列のピアソン、スピアマンまたはケンドール相関分析を実行します。
制御列を指定することによる部分相関を実行します。
相関の前に一部のデータを集計します。
結果を後処理して、Rコード・フローに統合します。
ore.corr関数の出力をRのcor関数の出力に適合させることができ、これにより、任意のR関数を使用して出力を後処理したり、出力をグラフィック関数の入力として使用できます。
この関数の引数の詳細は、help(ore.corr)を呼び出してください。
次の例にこれらの操作を示します。ほとんどの例でNARROWデータセットを使用しますが、詳細は、「探索的データ分析関数について」を参照してください。
例3-24に、別の種類の相関統計の指定方法を示します。
例3-24 基本的な相関計算の実行
# Before performing correlations, project out all non-numeric values # by specifying only the columns that have numeric values. names(NARROW) NARROW_NUMS <- NARROW[,c(3,8,9)] names(NARROW_NUMS) # Calculate the correlation using the default correlation statistic, Pearson. x <- ore.corr(NARROW_NUMS,var='AGE,YRS_RESIDENCE,CLASS') head(x, 3) # Calculate using Spearman. x <- ore.corr(NARROW_NUMS,var='AGE,YRS_RESIDENCE,CLASS', stats='spearman') head(x, 3) # Calculate using Kendall x <- ore.corr(NARROW_NUMS,var='AGE,YRS_RESIDENCE,CLASS', stats='kendall') head(x, 3)
例3-24のリスト
R> # Before performing correlations, project out all non-numeric values
R> # by specifying only the columns that have numeric values.
R> names(NARROW)
[1] "ID" "GENDER" "AGE" "MARITAL_STATUS" "COUNTRY" "EDUCATION" "OCCUPATION"
[8] "YRS_RESIDENCE" "CLASS" "AGEBINS"
R> NARROW_NUMS <- NARROW[,c(3,8,9)]
R> names(NARROW_NUMS)
[1] "AGE" "YRS_RESIDENCE" "CLASS"
R> # Calculate the correlation using the default correlation statistic, Pearson.
R> x <- ore.corr(NARROW_NUMS,var='AGE,YRS_RESIDENCE,CLASS')
R> head(x, 3)
ROW COL PEARSON_T PEARSON_P PEARSON_DF
1 AGE CLASS 0.2200960 1e-15 1298
2 AGE YRS_RESIDENCE 0.6568534 0e+00 1098
3 YRS_RESIDENCE CLASS 0.3561869 0e+00 1298
R> # Calculate using Spearman.
R> x <- ore.corr(NARROW_NUMS,var='AGE,YRS_RESIDENCE,CLASS', stats='spearman')
R> head(x, 3)
ROW COL SPEARMAN_T SPEARMAN_P SPEARMAN_DF
1 AGE CLASS 0.2601221 1e-15 1298
2 AGE YRS_RESIDENCE 0.7462684 0e+00 1098
3 YRS_RESIDENCE CLASS 0.3835252 0e+00 1298
R> # Calculate using Kendall
R> x <- ore.corr(NARROW_NUMS,var='AGE,YRS_RESIDENCE,CLASS', stats='kendall')
R> head(x, 3)
ROW COL KENDALL_T KENDALL_P KENDALL_DF
1 AGE CLASS 0.2147107 4.285594e-31 <NA>
2 AGE YRS_RESIDENCE 0.6332196 0.000000e+00 <NA>
3 YRS_RESIDENCE CLASS 0.3362078 1.094478e-73 <NA>
例3-25では、irisデータセットをデータベースの一時表にプッシュしますが、これにはプロキシore.frameオブジェクトのiris_ofがあります。種ごとにグループ化された相関マトリクスを作成します。
例3-25 相関マトリクスの作成
iris_of <- ore.push(iris)
x <- ore.corr(iris_of, var = "Sepal.Length, Sepal.Width, Petal.Length",
partial = "Petal.Width", group.by = "Species")
class(x)
head(x)
例3-25のリスト
R> iris_of <- ore.push(iris)
R> x <- ore.corr(iris_of, var = "Sepal.Length, Sepal.Width, Petal.Length",
+ partial = "Petal.Width", group.by = "Species")
R> class(x)
[1] "list"
R> head(x)
$setosa
ROW COL PART_PEARSON_T PART_PEARSON_P PART_PEARSON_DF
1 Sepal.Length Petal.Length 0.1930601 9.191136e-02 47
2 Sepal.Length Sepal.Width 0.7255823 1.840300e-09 47
3 Sepal.Width Petal.Length 0.1095503 2.268336e-01 47
$versicolor
ROW COL PART_PEARSON_T PART_PEARSON_P PART_PEARSON_DF
1 Sepal.Length Petal.Length 0.62696041 7.180100e-07 47
2 Sepal.Length Sepal.Width 0.26039166 3.538109e-02 47
3 Sepal.Width Petal.Length 0.08269662 2.860704e-01 47
$virginica
ROW COL PART_PEARSON_T PART_PEARSON_P PART_PEARSON_DF
1 Sepal.Length Petal.Length 0.8515725 4.000000e-15 47
2 Sepal.Length Sepal.Width 0.3782728 3.681795e-03 47
3 Sepal.Width Petal.Length 0.2854459 2.339940e-02 47
|
関連項目: cor.Rのスクリプト例 |
クロス集計は、値からなる2つの表の間の相互依存関係を見つける統計手法です。ore.crosstab関数は、ore.frameのクロス列分析を可能にします。この関数は、Rのtable関数の高性能なバリアントです。
ore.freqを使用して頻度分析を実行する前にore.crosstab関数を使用する必要があります。
ore.crosstab関数呼出しの結果が単一のクロス集計の場合、この関数によってore.frameオブジェクトが返されます。結果が複数のクロス集計の場合は、この関数はore.frameオブジェクトのリストを返します。
この関数の引数の詳細は、help(ore.crosstab)を呼び出してください。
ore.corrの例ではNARROWデータセットを使用しますが、詳細は、「サンプルのNARROWデータセットについて」を参照してください。
最も基本的な使用例は、例3-26に示すとおり、単一列頻度表を作成することです。この例では、GENDERによってグループ化されたNARROW ore.frameをフィルタします。
例3-26のリスト
R> ct <- ore.crosstab(~AGE, data=NARROW) R> head(ct) AGE ORE$FREQ ORE$STRATA ORE$GROUP 17 17 14 1 1 18 18 16 1 1 19 19 30 1 1 20 20 23 1 1 21 21 22 1 1 22 22 39 1 1
例3-27では、GENDERによってAGEを、CLASSによってAGEを分析します。
例3-27のリスト
R> ct <- ore.crosstab(AGE~GENDER+CLASS, data=NARROW)
R> head(ct)
$`AGE~GENDER`
AGE GENDER ORE$FREQ ORE$STRATA ORE$GROUP
17|F 17 F 5 1 1
17|M 17 M 9 1 1
18|F 18 F 6 1 1
18|M 18 M 7 1 1
19|F 19 F 15 1 1
19|M 19 M 13 1 1
# The remaining output is not shown.
行を重み付けするには、例3-28に示すとおり、別の列に基づいたカウントを含めます。この例では、YRS_RESIDENCEの値を使用してAGEおよびGENDERの値に重み付けします。
クロス集計表の行の順序付けには、次に示すようないくつかの方法があります。
分析対象の列によるデフォルトまたはNAMEの順序付け
頻度カウントによるFREQの順序付け
-NAMEまたは-FREQは、順序を逆転します
INTERNALは、順序付けをバイパスします
例3-28のリスト
R> ct <- ore.crosstab(AGE~GENDER*YRS_RESIDENCE, data=NARROW)
R> head(ct)
AGE GENDER ORE$FREQ ORE$STRATA ORE$GROUP
17|F 17 F 1 1 1
17|M 17 M 8 1 1
18|F 18 F 4 1 1
18|M 18 M 10 1 1
19|F 19 F 15 1 1
19|M 19 M 17 1 1
例3-29では、頻度カウントによって順序付けした後に、頻度カウントで順序を逆にします。
例3-29 クロス集計データの順序付け
ct <- ore.crosstab(AGE~GENDER|FREQ, data=NARROW) head(ct) ct <- ore.crosstab(AGE~GENDER|-FREQ, data=NARROW) head(ct)
例3-29のリスト
R> ct <- ore.crosstab(AGE~GENDER|FREQ, data=NARROW)
R> head(ct)
AGE GENDER ORE$FREQ ORE$STRATA ORE$GROUP66|F 66 F 1 1 170|F 70 F 1 1 173|M 73 M 1 1 174|M 74 M 1 1 176|F 76 F 1 1 177|F 77 F 1 1 1
R> ct <- ore.crosstab(AGE~GENDER|-FREQ, data=NARROW)
R> head(ct)
AGE GENDER ORE$FREQ ORE$STRATA ORE$GROUP
27|M 27 M 33 1 1
35|M 35 M 28 1 1
41|M 41 M 27 1 1
34|M 34 M 26 1 1
37|M 37 M 26 1 1
28|M 28 M 25 1 1
例3-30に、3つ以上の列の分析を示します。結果は、SQLのGROUPING SETS句の実行に似ています。
例3-30のリスト
R> ct <- ore.crosstab(AGE+COUNTRY~GENDER, NARROW)
R> head(ct)
$`AGE~GENDER`
AGE GENDER ORE$FREQ ORE$STRATA ORE$GROUP
17|F 17 F 5 1 1
17|M 17 M 9 1 1
18|F 18 F 6 1 1
18|M 18 M 7 1 1
19|F 19 F 15 1 1
19|M 19 M 13 1 1
# The rest of the output is not shown.
$`COUNTRY~GENDER`
COUNTRY GENDER ORE$FREQ ORE$STRATA ORE$GROUP
Argentina|F Argentina F 14 1 1
Argentina|M Argentina M 28 1 1
Australia|M Australia M 1 1 1
# The rest of the output is not shown.
例3-31に示すように、すべての列の名前を入力するかわりに、列の範囲を指定できます。
例3-31 列の範囲の指定
names(NARROW) # Because AGE, MARITAL_STATUS and COUNTRY are successive columns, # you can simply do the following: ct <- ore.crosstab(AGE-COUNTRY~GENDER, NARROW) # An equivalent invocation is the following: ct <- ore.crosstab(AGE+MARITAL_STATUS+COUNTRY~GENDER, NARROW)
例3-31のリスト
R> names(NARROW) R> names(NARROW) [1] "ID" "GENDER" "AGE" "MARITAL_STATUS" [5] "COUNTRY" "EDUCATION" "OCCUPATION" "YRS_RESIDENCE" [9] "CLASS" R> # Because AGE, MARITAL_STATUS and COUNTRY are successive columns, R> # you can simply do the following: R> ct <- ore.crosstab(AGE-COUNTRY~GENDER, NARROW) R> # An equivalent invocation is the following: R> ct <- ore.crosstab(AGE+MARITAL_STATUS+COUNTRY~GENDER, NARROW)
例3-32では、別の列COUNTRYの一意の値ごとに1つのクロス集計表(AGE、GENDER)を作成します。
例3-32のリスト
R> ct <- ore.crosstab(~AGE/COUNTRY, data=NARROW)
R> head(ct)
AGE ORE$FREQ ORE$STRATA ORE$GROUP
Argentina|17 17 1 1 1
Brazil|17 17 1 1 3
United States of America|17 17 12 1 19
United States of America|18 18 16 1 19
United States of America|19 19 30 1 19
United States of America|20 20 23 1 19
例3-33に示すとおり、これを複数の列に拡張できます。この例では、(COUNTRY、GENDER)の一意の組合せごとに1つの(AGE、EDUCATION)表を作成します。
例3-33 2つの列の値のセットごとに1つのクロス集計表の作成
ct <- ore.crosstab(AGE~EDUCATION/COUNTRY+GENDER, data=NARROW) head(ct)
例3-33のリスト
R> ct <- ore.crosstab(AGE~EDUCATION/COUNTRY+GENDER, data=NARROW)
R> head(ct)
AGE EDUCATION ORE$FREQ ORE$STRATA ORE$GROUP
United States of America|F|17|10th 17 10th 3 1 33
United States of America|M|17|10th 17 10th 5 1 34
United States of America|M|17|11th 17 11th 1 1 34
Argentina|M|17|HS-grad 17 HS-grad 1 1 2
United States of America|M|18|10th 18 10th 1 1 34
United States of America|F|18|11th 18 11th 2 1 33
前述のクロス集計表はすべて、例3-34に示すとおり、階層化で拡張できます。
例3-34 階層化によるクロス集計の拡張
ct <- ore.crosstab(AGE~GENDER^CLASS, data=NARROW) head(ct) R> head(ct) # The previous function invocation is the same as the following: ct <- ore.crosstab(AGE~GENDER, NARROW, strata="CLASS")
例3-34のリスト
R> ct <- ore.crosstab(AGE~GENDER^CLASS, data=NARROW)
R> head(ct)
R> head(ct)
AGE GENDER ORE$FREQ ORE$STRATA ORE$GROUP
0|17|F 17 F 5 1 1
0|17|M 17 M 9 1 1
0|18|F 18 F 6 1 1
0|18|M 18 M 7 1 1
0|19|F 19 F 15 1 1
0|19|M 19 M 13 1 1
# The previous function invocation is the same as the following:
ct <- ore.crosstab(AGE~GENDER, NARROW, strata="CLASS")
例3-35では、AGEによってカスタム・ビニングを実行してからGENDERおよびビンのクロス集計を計算します。
例3-35 ビニングおよびその後のクロス集計
NARROW$AGEBINS <- ifelse(NARROW$AGE<20, 1, ifelse(NARROW$AGE<30,2,
ifelse(NARROW$AGE<40,3,4)))
ore.crosstab(GENDER~AGEBINS, NARROW)
例3-35のリスト
R> NARROW$AGEBINS <- ifelse(NARROW$AGE<20, 1, ifelse(NARROW$AGE<30,2,
+ ifelse(NARROW$AGE<40,3,4)))
R> ore.crosstab(GENDER~AGEBINS, NARROW)
GENDER AGEBINS ORE$FREQ ORE$STRATA ORE$GROUP
F|1 F 1 26 1 1
F|2 F 2 108 1 1
F|3 F 3 86 1 1
F|4 F 4 164 1 1
M|1 M 1 29 1 1
M|2 M 2 177 1 1
M|3 M 3 230 1 1
M|4 M 4 381 1 1
ore.freq関数は、ore.crosstab関数の出力を分析し、ore.crosstabの結果に関連する手法を自動的に判別します。この手法は、次に示すようなクロス集計表の種類に応じて異なります。
2方向のクロス集計表
クロス集計における列の間の関係を記述する様々な統計
カイ二乗検定、Cochran-Mantel-Haenzsel統計、属性相関、関連の強固性、リスクの相違、オッズ比および2x2表の相対リスク、トレンドの検定
N方向のクロス集計表
N 2方向のクロス集計表
階層内または階層にわたる統計
ore.freq関数は、使用可能な場合はOracle DatabaseのSQL関数を使用します。
ore.freq関数は、すべての場合にore.frameを返します。
ore.freqを使用する前に、例3-36に従ってクロス集計を計算する必要があります。
この関数の引数の詳細は、ore.freqを呼び出してください。
例3-36では、irisデータセットをデータベースにプッシュし、ore.frameオブジェクトのiris_ofを取得します。この例ではクロス集計を取得し、そこでore.freq関数を呼び出します。
例3-36 ore.freq関数の使用方法
IRIS <- ore.push(iris) ct <- ore.crosstab(Species ~ Petal.Length + Sepal.Length, data = IRIS) ore.freq(ct)
例3-36のリスト
R> IRIS <- ore.push(iris) R> ct <- ore.crosstab(Species ~ Petal.Length + Sepal.Length, data = IRIS) R> ore.freq(ct) $`Species~Petal.Length` METHOD FREQ DF PVALUE DESCR GROUP 1 PCHISQ 181.4667 84 3.921603e-09 Pearson Chi-Square 1 $`Species~Sepal.Length` METHOD FREQ DF PVALUE DESCR GROUP 1 PCHISQ 102.6 68 0.004270601 Pearson Chi-Square 1
ore.esm関数は、順序付けられたore.vectorオブジェクトで、インデータベース時系列観測のための単純または二重の指数平滑化モデルを構築します。この関数は、時系列データ(観測が固定された均等な間隔)、またはトランザクション・データ(観測が均等な間隔ではない)で動作します。この関数は、トランザクション・データを指定された時間間隔で集計でき、モデル化フェーズに移る前に指定された方法で欠損値を処理することもできます。
ore.esm関数は、データベース・サーバーで動作している1つ以上のRエンジンのデータを処理します。この関数は、クラスore.esmのオブジェクトを返します。
predictメソッドを使用して、ore.esmによって構築される指数平滑法モデルの時系列を予測します。forecastパッケージをロード済の場合は、forecastメソッドをore.esmオブジェクトで使用できます。適合メソッドを使用して、トレーニングの時系列データセットの適合値を生成できます。
ore.esm関数の引数の詳細は、help(ore.esm)を呼び出してください。
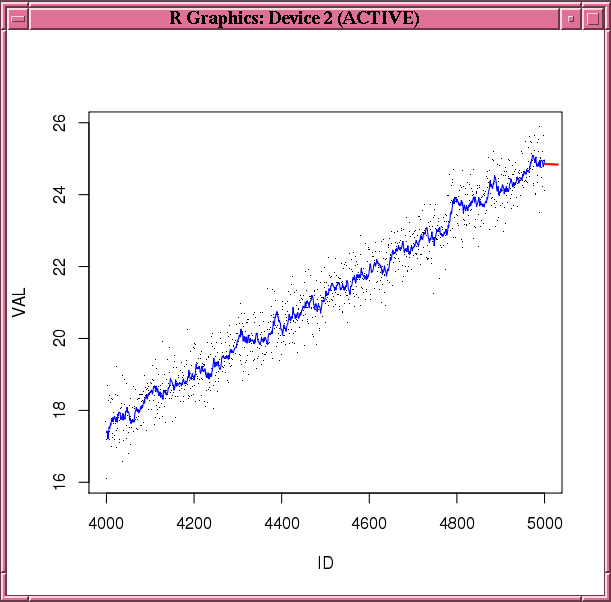
例3-37では、統合時系列データセットに二重指数平滑法モデルを構築します。予測および適合値を生成するために、predict関数およびfitted関数がそれぞれ呼び出されます。図3-1に、観測、適合値および予測を示します。
例3-37 二重指数平滑法モデルの構築
N <- 5000
ts0 <- ore.push(data.frame(ID=1:N,
VAL=seq(1,5,length.out=N)^2+rnorm(N,sd=0.5)))
rownames(ts0) <- ts0$ID
x <- ts0$VAL
esm.mod <- ore.esm(x, model = "double")
esm.predict <- predict(esm.mod, 30)
esm.fitted <- fitted(esm.mod, start=4000, end=5000)
plot(ts0[4000:5000,], pch='.')
lines(ts0[4000:5000, 1], esm.fitted, col="blue")
lines(esm.predict, col="red", lwd=2)
例3-38では、トランザクション・データセットに基づいて、単純平滑法モデルを構築します。事前処理として、平均を取ることで値を日レベルで集計し、欠損値に以前の集計値を設定して埋めます。このモデルは次に、集計された日次時系列に構築されます。関数predictは、日毎に予測値を生成するために呼び出されます。
例3-38 トランザクション・データを使用した時系列モデルの構築
ts01 <- data.frame(ID=seq(as.POSIXct("2008/6/13"), as.POSIXct("2011/6/16"),
length.out=4000), VAL=rnorm(4000, 10))
ts02 <- data.frame(ID=seq(as.POSIXct("2011/7/19"), as.POSIXct("2012/11/20"),
length.out=1500), VAL=rnorm(1500, 10))
ts03 <- data.frame(ID=seq(as.POSIXct("2012/12/09"), as.POSIXct("2013/9/25"),
length.out=1000), VAL=rnorm(1000, 10))
ts1 = ore.push(rbind(ts01, ts02, ts03))
rownames(ts1) <- ts1$ID
x <- ts1$VAL
esm.mod <- ore.esm(x, "DAY", accumulate = "AVG", model="simple",
setmissing="PREV")
esm.predict <- predict(esm.mod)
esm.predict
例3-38のリスト
R> ts01 <- data.frame(ID=seq(as.POSIXct("2008/6/13"), as.POSIXct("2011/6/16"),
+ length.out=4000), VAL=rnorm(4000, 10))
R> ts02 <- data.frame(ID=seq(as.POSIXct("2011/7/19"), as.POSIXct("2012/11/20"),
+ length.out=1500), VAL=rnorm(1500, 10))
R> ts03 <- data.frame(ID=seq(as.POSIXct("2012/12/09"), as.POSIXct("2013/9/25"),
+ length.out=1000), VAL=rnorm(1000, 10))
R> ts1 = ore.push(rbind(ts01, ts02, ts03))
R> rownames(ts1) <- ts1$ID
R> x <- ts1$VAL
R> esm.mod <- ore.esm(x, "DAY", accumulate = "AVG", model="simple",
+ setmissing="PREV")
R> esm.predict <- predict(esm.mod)
R> esm.predict
ID VAL
1 2013-09-26 9.962478
2 2013-09-27 9.962478
3 2013-09-28 9.962478
4 2013-09-29 9.962478
5 2013-09-30 9.962478
6 2013-10-01 9.962478
7 2013-10-02 9.962478
8 2013-10-03 9.962478
9 2013-10-04 9.962478
10 2013-10-05 9.962478
11 2013-10-06 9.962478
12 2013-10-07 9.962478
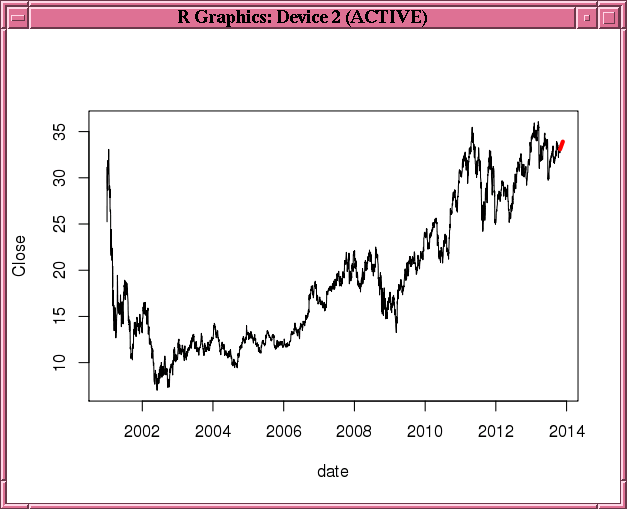
図3-1では、TTRパッケージの株のデータを使用します。これは、日ごとの株の終値に基づいて二重指数平滑法モデルを構築します。30日間の予測株価および元の観測を図3-2に示します。
例3-39 間隔を指定した二重指数平滑法モデルの構築
library(TTR)
stock <- "orcl"
xts.data <- getYahooData(stock, 20010101, 20131024)
df.data <- data.frame(xts.data)
df.data$date <- index(xts.data)
of.data <- ore.push(df.data[, c("date", "Close")])
rownames(of.data) <- of.data$date
esm.mod <- ore.esm(of.data$Close, "DAY", model = "double")
esm.predict <- predict(esm.mod, 30)
plot(of.data,type="l")
lines(esm.predict,col="red",lwd=4)
ore.rank関数は、ore.frameの数値列の値の分布を分析します。
ore.rank関数では、次のような便利な機能がサポートされています。
グループ内のランキング
ランク・タイルに基づいた、グループへの行のパーティショニング
累積パーセンテージおよびパーセンタイルの計算
同順位の処理
ランクからの標準スコアの計算
ore.rank関数の構文は、対応するSQL問合せより単純です。
ore.rank関数は、すべてのインスタンスでore.frameを返します。
次のRスコアリング・メソッドをore.rankとともに使用できます。
ランクから指数スコアを計算するには、savageを使用します。
正規スコアを計算するには、blom、tukeyまたはvw (ファン・デル・ヴェルデン)のいずれかを使用します。
この関数の引数の詳細は、help(ore.rank)を呼び出してください。
次の例では、ore.rankの使用方法を示します。この例では、NARROWデータセットを使用します。
例3-40では、2つの列AGEおよびCLASSをランキングし、派生列としてその結果をレポートしますが、値は、デフォルトの順序(昇順)でランキングされます。
例3-41では、2つの列AGEおよびCLASSをランキングします。同順位がある場合、同順位のすべての値に最小値が割り当てられます。
例3-42では、2つの列AGEとおよびCLASSをランキングし、COUNTRYに従って生成される値をランキングします。
例3-42 グループ内のランキング
x <- ore.rank(data=NARROW, var='AGE=RankOfAge, CLASS=RankOfClass', group.by='COUNTRY')
例3-43では、2つの列AGEおよびCLASSをランキングし、その列を十分位数(10パーティション)にパーティショニングします。
列を異なる数のパーティションにパーティショニングするには、groupsの値を変更します。たとえば、groups=4では、四分位数にパーティショニングされます。
例3-44では、2つの列AGEおよびCLASSをランキングし、両方の列の累積分布関数を見積ります。
例3-45では、2つの列AGEおよびCLASSをランキングし、2つの異なる方法でそのランクをスコアリングします。最初のコマンドは、列を百分位数(100グループ)にパーティショニングします。savageスコアリング・メソッドが指数スコアを計算し、blomスコアリングが正規スコアを計算します。
ore.sort関数は、by引数で指定した1つ以上の列によるデータ・フレームの柔軟なソートを可能にします。
ore.sort関数は、他のデータ事前処理関数とともに使用できます。ソートの結果を、Rの視覚化への入力に使用できます。
ore.sort関数のソートはOracle Databaseで実行されます。ore.sort関数は、データベースのnls.sortオプションをサポートします。
ore.sort関数は、ore.frameを返します。
この関数の引数の詳細は、help(ore.sort)を呼び出してください。
次のほとんどの例では、NARROWデータセットを使用します。ONTIME_Sデータセットを使用する例もあります。
例3-46では、列AGEおよびGENDERを降順でソートします。
例3-47では、AGEを降順で、GENDERを昇順でソートします。
例3-48では、AGEを基準にソートし、AGEの一意の値ごとに1行を保持します。
例3-49では、AGEを基準にソートし、重複する行を削除します。
例3-50では、AGEを基準にソートし、重複行を削除し、AGEの一意の値ごとに1行を返します。
例3-50 重複列の削除および一意の値ごとに1列を返す
x <- ore.sort(data=NARROW, by='AGE', unique.data=TRUE, unique.key = TRUE)
例3-51では、ソートされた出力で相対順序を維持します。
次の例では、ONTIME_Sエアラインのデータセットを使用します。例3-52では、ONTIME_Sをエアライン名を基準に降順で、出発の遅延を昇順でソートします。
例3-53では、ONTIME_Sをエアライン名および出発の遅延を基準にソートし、各組合せの1つを選択します(つまり、一意のキーを返します)。
ore.summary関数は、記述統計を計算し、柔軟な行の集計とともに、ore.frame内の列の広範な分析をサポートします。
ore.summary関数では、次の統計がサポートされています。
平均、最小、最大、モード、欠損値の数、合計、加重和
二乗の補正および未補正合計、値の範囲、stddev、stderr、variance
母平均が0であるという仮定をテストするためのt検定
尖度、歪度、変動係数
分位: p1、p5、p10、p25、p50、p75、p90、p95、p99、qrange
平均の片側および両側信頼限界: clm、rclm、lclm
極値のタグ付け
ore.summary関数は、同じ結果を生成するSQL問合せと比べて比較的単純な構文を提供します。
ore.summary関数は、group.by引数が使用されている場合を除くすべての場合にore.frameを返します。group.by引数が使用されている場合、ore.summaryは、階層ごとにore.frameを1つずつore.frameオブジェクトのリストを返します。
この関数の引数の詳細は、help(ore.summary)を呼び出してください。
例3-54では、列AGEおよびCLASSの平均値、最小値および最大値を計算し、GENDER列をロールアップ(集計)します。
例3-55では、AGEの歪度を列Aとして、CLASSのスチューデントのt分布の可能性を列Bとして計算します。
例3-55 歪度およびt-検定の可能性の計算
ore.summary(NARROW, class='GENDER', var='AGE,CLASS', stats='skew(AGE)=A, probt(CLASS)=B')
例3-56では、YRS_RESIDENCEを重みとしてGENDERによって集計されたAGEの重み付けされた合計を計算します(つまりsum(var*weight)を計算します)。
例3-56 重み付け合計の計算
ore.summary(NARROW, class='GENDER', var='AGE', stats='sum=X', weight='YRS_RESIDENCE')
例3-57では、GENDERおよびMARITAL_STATUSでCLASSをグループ化します。
例3-58では、GENDERおよびMARITAL_STATUSによってすべての適用可能な方法でCLASSをグループ化します。
ore.univariate関数は、ore.frameの数値変数の分布分析を提供します。
ore.univariate関数では、次の統計が提供されています。
summary関数によってレポートされるすべての統計
符号順位検定、スチューデントのt-検定
極値のレポート
ore.univariate関数は、すべての場合に出力としてore.frameを返します。
この関数の引数の詳細は、help(ore.univariate)を呼び出してください。
例3-59では、AGE、YRS_RESIDENCEおよびCLASSのデフォルトの単変量統計を計算します。
例3-60では、YRS_RESIDENCEの位置統計を計算します。
例3-61では、AGEおよびYRS_RESIDENCEの完全な分位統計を計算します。
Oracle R Enterpriseでは、Comprehensive R Archive Network (CRAN)のオープン・ソースのRパッケージまたは他のサード・パーティのRパッケージの関数を使用する場合、通常は、埋込みRの実行のコンテキストで行います。埋込みRの実行を使用すると、データベース・サーバー上の多量である可能性の高いRAMを利用できます。
ただし、Oracle Database表のデータに対してローカルのRセッションでサード・パーティのパッケージを使用する場合は、ore.pull関数を使用して、データをore.frameオブジェクトからローカル・セッションにdata.frameオブジェクトとして取得する必要があります。これは、DBAの協力なしにデータベースからデータを抽出できることを除いて、オープン・ソースRを使用する場合と同様です。
データベース表からローカルのdata.frameにデータをプルする場合、ローカル・マシンのメモリーに適合するデータ量に使用が制限されます。ローカル・マシンでは、埋込みRの実行で提供される利点を利用できません。
サード・パーティのパッケージを使用するには、システムにインストールして、Rセッションでロードする必要があります。例3-62に、CRANパッケージkernlabのダウンロード、インストールおよびロードの例を示します。kernlabパッケージには、カーネル・ベースの機械学習手法が含まれています。この例では、install.packages関数を呼び出してこのパッケージをダウンロードしてインストールします。次に、library関数を呼び出してパッケージをロードします。
例3-62のリスト
R> install.packages("kernlab")
trying URL 'http://cran.rstudio.com/bin/windows/contrib/3.0/kernlab_0.9-19.zip'
Content type 'application/zip' length 2029405 bytes (1.9 Mb)
opened URL
downloaded 1.9 Mb
package 'kernlab' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\rquser\AppData\Local\Temp\RtmpSKVZql\downloaded_packages
R> library("kernlab")
例3-63では、demo関数を呼び出して、kernlabパッケージ内のサンプル・プログラムを検索します。このパッケージにはサンプルが含まれていないため、例3-63でksvm関数のヘルプを取得します。このヘルプからサンプル・コードを呼び出します。
例3-63 kernlabパッケージ関数の使用方法
demo(package = "kernlab") help(package = "kernlab", ksvm) data(spam) index <- sample(1:dim(spam)[1]) spamtrain <- spam[index[1:floor(dim(spam)[1]/2)], ] spamtest <- spam[index[((ceiling(dim(spam)[1]/2)) + 1):dim(spam)[1]], ] filter <- ksvm(type~.,data=spamtrain,kernel="rbfdot", + kpar=list(sigma=0.05),C=5,cross=3) filter table(mailtype,spamtest[,58])
例3-63のリスト
> demo(package = "kernlab")
no demos found
> help(package = "kernlab", ksvm) # Output not shown.
> data(spam)
> index <- sample(1:dim(spam)[1])
> spamtrain <- spam[index[1:floor(dim(spam)[1]/2)], ]
> spamtest <- spam[index[((ceiling(dim(spam)[1]/2)) + 1):dim(spam)[1]], ]
> filter <- ksvm(type~.,data=spamtrain,kernel="rbfdot",
+ kpar=list(sigma=0.05),C=5,cross=3)
> filter
Support Vector Machine object of class "ksvm"
SV type: C-svc (classification)
parameter : cost C = 5
Gaussian Radial Basis kernel function.
Hyperparameter : sigma = 0.05
Number of Support Vectors : 970
Objective Function Value : -1058.218
Training error : 0.018261
Cross validation error : 0.08696
> mailtype <- predict(filter,spamtest[,-58])
> table(mailtype,spamtest[,58])
mailtype nonspam spam
nonspam 1347 136
spam 45 772
kernlabパッケージの使用例については、例2-9「キーを使用した順序付け」を参照してください。
|
関連項目:
|