| Oracle® R Enterpriseユーザーズ・ガイド リリース1.4.1 E57720-01 |
|


 前 |
 次 |
Oracle R Enterpriseの埋込みRの実行では、Oracle Databaseサーバーで稼働するRセッションでRスクリプトを起動できます。この章では、埋込みRの実行について、次の各項で説明します。
Oracle R Enterpriseの埋込みRの実行では、RスクリプトをOracle DatabaseのRスクリプト・リポジトリに格納して、このようなスクリプトを起動できます。スクリプトを起動すると、そのスクリプトは、データベース・サーバーで稼働しデータベースにより動的に起動されて管理される1つ以上のRエンジンで実行されます。Oracle R Enterpriseでは、埋込みRの実行用にRインタフェースとSQLインタフェースの両方が提供されています。同じRスクリプトから、構造化データ、RオブジェクトおよびイメージのXML表現、さらにはデータベース表のBLOB列を介してPNGイメージを取得できます。
この項の内容は次のとおりです。
埋込みRの実行には次の利点があります。
Oracle DatabaseサーバーからローカルのRセッションへデータを移動する必要がありません。
セキュリティを向上するでなく、Oracle Databaseと内部Rエンジン間のデータベース・データの転送は、別個のクライアントRエンジンよりはるかに高速です。
データベース・サーバーを使用して、サーバーで稼働するRエンジンでRスクリプトの実行を開始、管理および制御します。
Rエンジンの実行に、データベース・サーバー・マシンのメモリーおよび処理能力を活用することで、より優れたスケーラビリティおよびパフォーマンスを提供します。
Hadoopのマップ/リデュース・ジョブの特殊なケースに対応したユーザー定義のR関数をデータ・パラレルおよびタスク・パラレルに実行できます。
パラレル・シミュレーション機能が装備されています。
データベース・サーバーで稼働するRスクリプトで、オープン・ソースのCRANパッケージを使用できます。
R環境を終了することなく、分析アプリケーション用の包括的なスクリプトを1つの手順で開発および操作できるようにする機能が装備されています。
探索的分析で使用されるRスクリプトをアプリケーション・タスクに直接統合できます。また、移植を排除し、アプリケーション・コードに対する変更の即時更新を可能にすることによって、本番でRスクリプトをすばやく起動して、開発期間を大幅に減少できます。
SQLからRスクリプトを実行することで、Rスクリプトの結果をOracle Business Intelligence Enterprise Edition (OBIEE)、Oracle BI Publisherおよび構造化データ、Rオブジェクトおよびイメージ用のその他のSQL対応のツールと統合できます。
Oracle R Enterpriseには、埋込みRの実行用のRおよびSQLのアプリケーション・プログラミング・インタフェースがあります。表6-1に、埋込みRの実行関数のサマリーおよび使用可能なRスクリプトのリポジトリ関数を示します。関数fはユーザー定義のR閉包(スクリプト)を参照しますが、これはR関数オブジェクトまたはデータベースのRスクリプト・リポジトリの名前付きR関数のいずれかとして提供されています。
表6-1 埋込みRの実行用のRおよびSQLのAPI
| RのAPI | SQLのAPI | 説明 |
|---|---|---|
|
|
|
データを自動転送せずにfを実行します。 |
|
|
|
fの最初の引数として指定された入力 |
|
|
rqGroupEval この関数は、ユーザーが明示的に定義する必要があります。 |
グループ化列の値に応じてデータをパーティショニングすることでfを実行します。各データ・パーティションをfの最初の引数に |
|
|
|
指定された入力 |
|
|
該当するものはありません。 |
データの自動転送なしでfを実行しますが、1からnまで(nは関数を呼び出す回数)の呼出しの索引を提供します。データベース・サーバーで稼働するRエンジンのプールでの各f呼出しのパラレル実行をサポートします。 |
|
|
|
指定されたR関数をRスクリプト・リポジトリに指定された名前でロードします。 |
|
|
|
指定されたR関数をRスクリプト・リポジトリから削除します。 |
Rスクリプトではデータベース・サーバーへのアクセスが許可されるため、スクリプトの作成を制御する必要があります。RQADMINロールはOracle Database権限の集合で、スクリプトを作成してOracle DatabaseのRスクリプト・リポジトリに格納したり、リポジトリからスクリプトを削除するために、ユーザーが持つ必要のある権限です。
Oracle R Enterpriseをデータベース・サーバーにインストールすると、RQADMINロールが作成されます。このロールは、明示的にユーザーに付与する必要があります。RQADMINをユーザーに付与するには、SQL*Plusをsysdbaで起動し、次のようなGRANT文(ロールをユーザーRQUSERに付与します)を入力します。
GRANT RQADMIN to RQUSER
|
注意: RQADMINは、必要とするユーザーにのみ付与してください。 |
Oracle R Enterpriseの埋込みRの実行関数の一部では、データベースでのパラレル実行の使用がサポートされています。関数ore.groupApply、ore.rowApply、rq.groupEvalおよびrq.rowEvalはデータ・パラレル実行をサポートし、ore.indexApplyはタスク・パラレル実行をサポートします。このパラレル実行機能によって、Oracle Exadataデータベース・マシンなどの高パフォーマンスのコンピューティング・ハードウェアをスクリプトで利用できます。
関数ore.groupApply、ore.rowApplyおよびore.indexApplyのparallel引数には、埋込みRの実行で使用する並列度を指定します。引数の値には、次のいずれかを指定できます。
特定の並列度では、2以上の正の整数
パラレル化しない場合は、FALSEまたは1
data引数のデフォルトのパラレル化の場合はTRUE
操作に対するデータベースのデフォルトはNULL
この引数のデフォルト値は、グローバル・オプションore.parallelの値、またはore.parallelが設定されていない場合はFALSEです。
ore.doEvalまたはore.tableApplyを使用して呼び出したユーザー定義のR関数は、並行して実行されません。このような関数は1つのRエンジンで実行されます。
rq.groupEval関数およびrq.rowEval関数の場合、並列度は入力カーソル引数のPARALLELヒントによって指定します。
ore.groupApply関数およびrq.groupEval関数のデータ・パラレル実行では、1つ以上のRエンジンが同じR関数(タスク)を別のデータ・パーティションで実行します。この機能によって、たとえば何万または何十万もの予測モデルを顧客に1モデルずつ構築するなどの、多数のモデルの構築が可能です。
ore.rowApply関数およびrq.rowEval関数のデータ・パラレル実行では、1つ以上のRエンジンが同じR関数をデータの非結合チャンクで実行します。この機能によって、大規模なデータセットでのスケーラブルなモデルのスコアリングおよび予測が可能です。
ore.indexApply関数のタスク・パラレル実行では、1つ以上のRエンジンが同じまたは異なる計算(タスク)を実行します。実行の索引に関連付けられている数字が、関数に提供されます。この機能は、シミュレーションの実行などの各種の操作で重要です。
Oracle Databaseは、複合的である可能性のあるRエンジンの管理および制御をデータベース・サーバーで処理し、自動的にパーティショニングしてデータをRエンジンに渡して並行して実行します。すべてのパーティションですべてのR関数の実行が完了することが保証されますが、そうでない場合はOracle R Enterpriseの関数はエラーを返します。各ユーザー定義の埋込みR関数の実行結果は、ore.listに収集されます。このリストは、ユーザーが結果を要求するまでデータベースに保持されます。
埋込みRの実行では、Comprehensive R Archive Network (CRAN)のオープン・ソースのRパッケージまたは他のサード・パーティのRパッケージの関数を使用する可能性のあるユーザー定義のR関数のデータ・パラレル実行も可能です。ただし、サード・パーティのパッケージは、インデータベース並列性を活用しないため、Rの並列性制約の対象となります。サード・パーティのパッケージは、埋込みRの実行でサポートされているデータ・パラレル実行およびタスク・パラレル実行を利用できます。
埋込みRの実行では、Oracle Databaseサーバーで実行されるユーザー定義のR関数で、CRANまたは他のサード・パーティのパッケージを使用できます。埋込みRの実行でサード・パーティのパッケージを使用するには、そのパッケージをデータベース・サーバーにインストールする必要があります。埋込みRの実行用のRインタフェースでこのパッケージを使用する場合は、パッケージをクライアントにもインストールする必要があります。非互換性を回避するために、クライアント・マシンとサーバー・マシンの両方に同じバージョンのパッケージをインストールする必要があります。
Oracle Database管理者(DBA)は、埋込みR関数またはすべてのRユーザーが使用できるようにパッケージをデータベース・サーバーにインストールできます。DBAは、パッケージを1つまたは複数のデータベース・サーバーにインストールできます。
通常、DBAは次の手順を実行します。
CRANからパッケージをダウンロードしてインストールします。CRANからパッケージをダウンロードするには、インターネット接続が必要です。
サーバーで稼働するOracle R Enterpriseセッションで、パッケージをロードします。パッケージ内の関数を使用して、パッケージが正しくインストールされていることを確認します。
1つのデータベース・サーバーにパッケージをインストールするには、次のいずれかを実行します。
サーバーで稼働するOracle R Enterpriseセッションで、例6-1に示すようなinstall.packages関数を呼び出します。この関数によって自動的にパッケージがダウンロードされ、依存性がインストールされます。
wgetを使用してCRANからパッケージ・ソースをダウンロードします。このパッケージが、使用されているR Distribution内にないパッケージのいずれかに依存している場合は、それらのパッケージもダウンロードします。
オペレーティング・システムのコマンドラインからORE CMD INSTALLコマンドを使用して、このパッケージをOracle R Enterpriseパッケージと同じ場所($ORACLE_HOME/R/library)にインストールします。例6-2を参照してください。
パッケージおよび依存パッケージをOracle Real Application Clusters (Oracle RAC)や複数ノードのOracle Exadataデータベース・マシン環境などの複数のデータベース・サーバーにインストールする場合は、例6-3に示すように、Exadata Distributed Command Line Interface (DCLI)ユーティリティを使用します。DCLIを使用してパッケージをインストールする手順の詳細は、『Oracle R Enterpriseインストレーションおよび管理ガイド』を参照してください。
パッケージが正しくインストールされたことを確認するには、例6-4に示すように、パッケージをロードしてパッケージ内の関数を使用します。
例6-1では、install.packages関数を呼び出して、CRANからC50パッケージをダウンロードしてインストールします。C50パッケージには、C5.0ディシジョン・ツリーおよびパターン認識用のルールベース・モデルを作成するための関数が含まれています。
例6-1の出力は、例6-2のORE CMD INSTALLコマンドの出力とほぼ同じです。
例6-2では、CRANからC50パッケージをダウンロードし、LinuxコマンドラインからORE CMD INSTALLを使用してこれをインストールします。
例6-2 コマンドラインからの単一データベースへのパッケージのインストール
wget http://cran.r-project.org/src/contrib/C50_0.1.0-19.tar.gz ORE CMD INSTALL C50_0.1.0-19.tar.gz
例6-2のリスト
$ wget http://cran.r-project.org/src/contrib/C50_0.1.0-19.tar.gz
# The output of wget is not shown.
$ ORE CMD INSTALL C50_0.1.0-19.tar.gz
* installing to library '/example/dbhome_1/R/library'
* installing *source* package 'C50' ...
** package 'C50' successfully unpacked and MD5 sums checked
checking for gcc... gcc
checking whether the C compiler works... yes
checking for C compiler default output file name... a.out
checking for suffix of executables...
checking whether we are cross compiling... no
checking for suffix of object files... o
checking whether we are using the GNU C compiler... yes
checking whether gcc accepts -g... yes
checking for gcc option to accept ISO C89... none needed
configure: creating ./config.status
config.status: creating src/Makevars
** libs
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c attwinnow.c -o attwinnow.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c classify.c -o classify.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c confmat.c -o confmat.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c construct.c -o construct.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c contin.c -o contin.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c discr.c -o discr.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c formrules.c -o formrules.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c formtree.c -o formtree.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c getdata.c -o getdata.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c getnames.c -o getnames.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c global.c -o global.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c hash.c -o hash.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c hooks.c -o hooks.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c implicitatt.c -o implicitatt.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c info.c -o info.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c mcost.c -o mcost.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c modelfiles.c -o modelfiles.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c p-thresh.c -o p-thresh.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c prune.c -o prune.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c rc50.c -o rc50.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c redefine.c -o redefine.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c rsample.c -o rsample.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c rulebasedmodels.c -o rulebasedmodels.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c rules.c -o rules.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c ruletree.c -o ruletree.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c siftrules.c -o siftrules.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c sort.c -o sort.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c strbuf.c -o strbuf.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c subset.c -o subset.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c top.c -o top.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c trees.c -o trees.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c
update.c -o update.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c utility.c -o utility.o
gcc -m64 -std=gnu99 -I/usr/include/R -DNDEBUG -DNDEBUG -I/usr/local/include -ffloat-store -g -fpic -g -O2 -c xval.c -o xval.o
gcc -m64 -std=gnu99 -shared -L/usr/local/lib64 -o C50.so attwinnow.o classify.o confmat.o construct.o contin.o discr.o formrules.o formtree.o getdata.o getnames.o global.o hash.o hooks.o implicitatt.o info.o mcost.o modelfiles.o p-thresh.o prune.o rc50.o redefine.o rsample.o rulebasedmodels.o rules.o ruletree.o siftrules.o sort.o strbuf.o subset.o top.o trees.o update.o utility.o xval.o -L/usr/lib64/R/lib -lR
installing to /example/dbhome_1/R/library/C50/libs
** R
** data
** preparing package for lazy loading
** help
*** installing help indices
converting help for package 'C50'
finding HTML links ... done
C5.0 html
C5.0Control html
churn html
predict.C5.0 html
summary.C5.0 html
varImp.C5.0 html
** building package indices
** testing if installed package can be loaded
* DONE (C50)
例6-3に、C50パッケージをインストールするためのDLCIコマンドを示します。
dcli -gフラグはインストール先のノードのリストを含むファイルを指定し、-lフラグはコマンドの実行時に使用するユーザーIDを指定します。DCLIの使用方法の詳細は、『Oracle R Enterpriseインストレーションおよび管理ガイド』を参照してください。
例6-4では、Rを起動し、サーバー上のOracle R Enterpriseに接続してC50パッケージをロードし、パッケージ内の関数を使用します。この例では、LinuxコマンドラインからOREコマンドを実行してRを起動します。また、Oracle R Enterpriseに接続して、C50パッケージをロードします。demo関数を呼び出して、パッケージ内のサンプル・プログラムを検索します。このパッケージにはサンプルが含まれていないため、例6-4でC5.0関数のヘルプを取得します。このヘルプからサンプル・コードを呼び出します。
例6-4 C50パッケージ関数の使用方法
ORE
library(ORE)
ore.connect(user = "RQUSER", sid = "orcl", host = "myhost",
password = "rquserStrongPassword", port = 1521, all=TRUE)
library(C50)
demo(package = "C50")
?C5.0
data(churn)
treeModel <- C5.0(x = churnTrain[, -20], y = churnTrain$churn)
treeModel
例6-4のリスト
$ ORE
R> library(ORE)
Loading required package: OREbase
Attaching package: 'OREbase'
The following objects are masked from 'package:base':
cbind, data.frame, eval, interaction, order, paste, pmax, pmin,
rbind, table
Loading required package: OREembed
Loading required package: OREstats
Loading required package: MASS
Loading required package: OREgraphics
Loading required package: OREeda
Loading required package: OREmodels
Loading required package: OREdm
Loading required package: lattice
Loading required package: OREpredict
Loading required package: ORExml
> ore.connect(user = "RQUSER", sid = "orcl", host = "myhost",
+ password = "rquserStrongPassword", port = 1521, all=TRUE)
Loading required package: ROracle
Loading required package: DBI
R> library(C50)
R> demo(package = "C50")
no demos found
R> ?C5.0 # Output not shown.
R> data(churn)
R> treeModel <- C5.0(x = churnTrain[, -20], y = churnTrain$churn)
R> treeModel
Call:
C5.0.default(x = churnTrain[, -20], y = churnTrain$churn)
Classification Tree
Number of samples: 3333
Number of predictors: 19
Tree size: 27
Non-standard options: attempt to group attributes
|
関連項目:
|
Oracle R Enterpriseには、Oracle Databaseに埋め込まれている1つ以上のRエンジンで実行するRスクリプトを起動する関数があります。また、Rスクリプトを作成してデータベースのRスクリプト・リポジトリに格納する関数や、リポジトリからスクリプトを削除する関数もあります。この項では、次の各トピックでこれらの関数について説明します。
Oracle R Enterpriseの埋込みRの実行関数のore.doEval、ore.tableApply、ore.groupApply、ore.rowApplyおよびore.indexApplyには、これらの関数の一部またはすべてに共通の引数があります。一部の関数には、その関数に固有の引数もあります。
この項では、引数について次の各項で説明します。
|
関連項目:
|
すべての埋込みRの実行関数には、スクリプトの実行時に適用するための関数が必要です。次の相互に排他的な引数のどちらかを使用して入力関数を指定します。
FUN
FUN.NAME
FUN引数は、関数オブジェクトを直接指定された関数としてまたはR変数に割り当てられた関数として使用します。RQADMINロールを持つユーザーのみが、埋込みR関数の呼出し時にFUN引数を使用できます。
FUN.NAME引数には、Rスクリプト・リポジトリに格納されているスクリプトを指定します。格納されたスクリプトには、スクリプトの実行時に適用する関数が含まれます。すべてのOracle R Enterpriseユーザーが、埋込みR関数の呼出し時にFUN.NAME引数を使用できます。
|
注意: OREmodelsパッケージのOracle R Enterpriseの高度な分析関数であるore.glm、ore.lmおよびore.neuralは、埋込みRの実行フレームワークを内部で使用し、埋込みRの実行関数では使用できません。 |
すべての埋込みRの実行関数は、指定が可能または不可能なオプションの引数を取ります。Oracle R Enterpriseは、ユーザー定義のオプションの引数を入力関数に渡します。モデルなどの複合Rオブジェクトを含む入力関数に、任意の数のオプションの引数を渡すことができます。
ore.で始まる引数は、特殊な制御引数です。Oracle R Enterpriseはそれらを入力関数に渡しませんが、かわりに、それらを使用して入力関数の実行前または後に発生することを制御します。次の制御引数がサポートされます。
ore.connectは、埋込みRの実行関数内でOracle R Enterpriseに自動的に接続するかどうかを制御します。これは、クライアント・セッションと同じ資格証明を指定してore.connectをコールすることと同等です。デフォルト値はFALSEです。
自動接続を有効にすると、次の機能を実現できます。
埋込みRスクリプトがデータベースに接続されます。
接続は、埋込みR SQL関数を呼び出すセッションと同じ資格証明を持ちます。
このスクリプトは自律型トランザクション内で実行されます。
ROracle問合せは自動接続と連携できます。
Oracle R Enterprise透過層の機能が埋込みスクリプトで使用可能になります。
ore.dropは入力データを制御します。オプション値がTRUEの場合、1列のdata.frameがvectorに変換されます。デフォルト値はTRUEです。
ore.envAsEmptyenvは、シリアライズ中にオブジェクト内の参照される環境を空の環境で置き換えるかどうかを制御します。一部のタイプの入力パラメータおよび戻りオブジェクト(listやformulaなど)は、データベースに保存される前にシリアライズされます。制御引数の値がTRUEの場合、オブジェクト内の参照される環境は親が.GlobalEnvである空の環境で置き換えられ、参照される元の環境内のオブジェクトはシリアライズされません。これにより、シリアライズされるオブジェクトのサイズを大幅に削減できる場合があります。制御引数の値がFALSEの場合、参照される環境内のすべてのオブジェクトがシリアライズされますが、後からシリアライズ解除してリカバリすることができます。デフォルト値は、グローバル・オプションore.envAsEmptyenvによって決定されます。
ore.na.omit入力データの欠損値の処理を制御します。ore.na.omit = TRUEを指定した場合、欠損値を含む行またはベクター要素(ore.drop設定に応じて)が入力データから削除されます。チャンクのすべての行に欠損値がある場合、そのチャンクの入力データは空のdata.frameまたはvectorになります。デフォルト値はFALSEです。
ore.graphicsは、グラフィカル・ドライバを起動して画像を検索するかどうかを制御します。デフォルト値はTRUEです。
ore.png.*には、ore.graphicsがTRUEの場合に、pngグラフィック・ドライバの追加引数を指定します。これらの引数のネーミング規則では、png関数の引数にore.png.接頭辞を追加します。たとえば、ore.png.heightを指定すると、引数heightがpng関数に渡されます。設定しない場合は、png関数に標準のデフォルト値が使用されます。
|
関連項目: 制御引数の詳細は、help(ore.doEval)を呼び出すことで表示されるオンライン・ヘルプを参照してください。 |
すべての埋込みRの実行関数に適用されるもう1つの引数にFUN.VALUEがあります。FUN.VALUE引数がNULLの場合、ore.doEval関数およびore.tableApply関数はore.objectクラス・オブジェクトとしてシリアライズRオブジェクトを返し、ore.groupApply、ore.indexApplyおよびore.rowApplyの各関数はore.listオブジェクトを返します。ただし、data.frameまたはore.frameにFUN.VALUE引数を指定した場合、この関数は、指定したdata.frameオブジェクトまたはore.frameオブジェクトの構造を持つore.frameを返します。
ore.doEval関数およびore.indexApply関数は、データベースから自動的にデータを受け取りません。FUN引数またはFUN.NAME引数で指定された関数を単純に実行します。入力関数で必要なすべてのデータは、その関数内で生成されるか、Oracle Database、その他のデータベースまたはフラット・ファイルなどのデータ・ソースから明示的に取得するかのいずれかです。入力関数は、ore.pull関数またはその他の透過層関数を使用して、ファイルまたは表からデータをロードできます。
ore.tableApply、ore.groupApplyおよびore.rowApplyの各関数には、入力データとしてデータベース表が必要です。この表はore.frameで表されます。このデータに、X引数(埋込みRの実行関数の最初の引数)で指定するore.frameを指定します。埋込みRの実行関数は、ore.frameオブジェクトを最初の引数としてユーザー定義の入力関数に渡します。
|
注意: ユーザー定義のR関数に渡されたore.frameオブジェクトによって表されるデータは、Oracle Databaseからデータベース・サーバーのRエンジンにコピーされます。Rメモリーの制限が適用されます。データベース・サーバー・マシンに32GBのRAMがあり、データ表が64GBの場合、Oracle R EnterpriseはデータをRエンジンのメモリーにロードできません。 |
ore.groupApply、ore.indexApplyおよびore.rowApplyの各関数は、parallel引数を取ります。この引数には、入力関数の埋込みRの実行で使用するための並列度を指定します。「パラレル実行のサポート」を参照してください。
関数ore.groupApply、ore.indexApplyおよびore.rowApplyは、それぞれの関数に固有の引数を取ります。
ore.groupApply関数はINDEX引数を取り、これには、入力データの行が入力関数での処理のためにパーティショニングされる列の名前を指定します。
ore.indexApply関数はtimes引数を取り、これには、入力関数を実行する回数を指定します。
ore.rowApply関数はrows引数を取り、これには、入力関数の各呼出しに渡す行の数を指定します。
「実行するための入力関数」で説明しているように、埋込みRの実行関数はFUN.VALUE引数を取ることができます。その引数には、Rスクリプト・リポジトリ内のスクリプトの名前を指定します。スクリプトをリポジトリに追加するには、ore.scriptCreate関数を呼び出します。Rスクリプト・リポジトリ内のスクリプトは、埋込みRの実行用のSQL APIインタフェースで使用することもできます。
ore.scriptDrop関数は、指定したスクリプトをRスクリプト・リポジトリから削除します。
|
注意: ore.scriptCreate関数またはore.scriptDrop関数を呼び出すには、RQADMINロールが必要です。詳細は、「スクリプトのセキュリティに関する考慮事項」を参照してください。 |
ore.scriptCreate関数とore.scriptDrop関数はどちらも、成功した場合、表示されないNULL値を返します。関数がスクリプトの作成または削除に失敗した場合、エラーが返されます。
例6-5ではまず、ore.scriptDropを呼び出して、指定された名前のスクリプトがRスクリプト・リポジトリに含まれていないことを確認します。次に、ore.scriptCreate関数を呼び出して、myRandomRedDotsというユーザー定義関数を作成します。このユーザー定義関数は引数を受け入れ、2つの列を持ち100個のランダム標準値を表示するdata.frameオブジェクトを返します。ore.scriptCreateを呼び出すと、myRandomRedDotsがRスクリプト・リポジトリに格納されます。
例6-5 ore.scriptCreate関数およびore.scriptDrop関数の使用方法
ore.scriptDrop("myRandomRedDots")
ore.scriptCreate("myRandomRedDots", function(divisor = 100){
id <- 1:10
plot(1:100, rnorm(100), pch = 21, bg = "red", cex = 2 )
data.frame(id = id, val = id / divisor)
})
|
関連項目:
|
ore.doEval関数は、入力関数によって生成されたデータを使用して指定された入力関数を実行します。ore.frameオブジェクトまたはシリアライズRオブジェクトをore.objectオブジェクトとして返します。
ore.doEval関数の構文は次のとおりです。
ore.doEval(FUN, ..., FUN.VALUE = NULL, FUN.NAME = NULL)
例6-6で、RandomRedDotsが取得する関数は、引数を取り、2つの列を持ち100個のランダム標準値を表示するdata.frameオブジェクトを返します。次に、ore.doEval関数を呼び出して、RandomRedDots functionオブジェクトを渡します。イメージがクライアントに表示されますが、これはRandomRedDots関数を実行したデータベース・サーバーのRエンジンによって生成されます。
例6-6 ore.doEval関数の使用方法
RandomRedDots <- function(divisor = 100){
id<- 1:10
plot(1:100, rnorm(100), pch = 21, bg = "red", cex = 2 )
data.frame(id=id, val=id / divisor)
}
ore.doEval(RandomRedDots)
例6-6のリスト
R> RandomRedDots <- function(divisor = 100){
+ id<- 1:10
+ plot(1:100, rnorm(100), pch = 21, bg = "red", cex = 2 )
+ data.frame(id=id, val=id / divisor)
+ }
R> ore.doEval(RandomRedDots)
id val
1 1 0.01
2 2 0.02
3 3 0.03
4 4 0.04
5 5 0.05
6 6 0.06
7 7 0.07
8 8 0.08
9 9 0.09
10 10 0.10
doEval関数のオプションの引数として入力関数に引数を指定できます。例6-7では、RandomRedDots関数のdivisor引数をオーバーライドするオプションの引数を指定してdoEval関数を呼び出します。
例6-7のリスト
R> ore.doEval(RandomRedDots, divisor = 50) id val 1 1 0.02 2 2 0.04 3 3 0.06 4 4 0.08 5 5 0.10 6 6 0.12 7 7 0.14 8 8 0.16 9 9 0.18 10 10 0.20 # The graph displayed by the plot function is not shown.
入力関数がRスクリプト・リポジトリに格納されている場合は、ore.doEval関数をFUN.NAME引数を指定して呼び出せます。例6-8ではまず、ore.scriptDropを呼び出して、myRandomRedDotsという名前のスクリプトがRスクリプト・リポジトリに含まれていないことを確認します。この例では、例6-6のRandomRedDots関数をmyRandomRedDotsという名前でリポジトリに追加します。例6-8では、ore.doEval関数を呼び出し、myRandomRedDotsを指定します。結果は変数resに割り当てられます。
RandomRedDots関数の戻り値はdata.frameですが、例6-8では、ore.doEval関数はore.objectオブジェクトを返します。data.frameオブジェクトを取得するために、ore.pullを呼び出して結果をクライアントのRセッションにプルします。
例6-8 FUN.NAME引数を指定したore.doEval関数の使用方法
ore.scriptDrop("myRandomRedDots")
ore.scriptCreate("myRandomRedDots", RandomRedDots)
res <- ore.doEval(FUN.NAME = "myRandomRedDots", divisor = 50)
class(res)
res.local <- ore.pull(res)
class(res.local)
例6-8のリスト
R> ore.scriptDrop("myRandomRedDots")
R> ore.scriptCreate("myRandomRedDots", RandomRedDots)
R> res <- ore.doEval(FUN.NAME = "myRandomRedDots", divisor = 50)
R> class(res)
[1] "ore.object"
attr(,"package")
[1] "OREembed"
R> res.local <- ore.pull(res)
R> class(res.local)
[1] "data.frame"
doEval関数でore.objectではなくore.frameオブジェクトが返されるように、例6-9に示すとおり、引数FUN.VALUEを使用して結果の構造を指定します。
例6-9 FUN.VALUE引数を指定したore.doEval関数の使用方法
res.of <- ore.doEval(FUN.NAME="myRandomRedDots", divisor = 50,
FUN.VALUE= data.frame(id = 1, val = 1))
class(res.of)
例6-9のリスト
R> res.of <- ore.doEval(FUN.NAME="myRandomRedDots", divisor = 50, + FUN.VALUE= data.frame(id = 1, val = 1)) R> class(res.of) [1] "ore.frame" attr(,"package") [1] "OREbase"
例6-10では、特殊なオプション引数ore.connectを使用して埋込みR関数でデータベースに接続することにより、データストアに格納されているオブジェクトの使用を可能にします。この例では、RandomRedDots2関数オブジェクト(例6-6のRandomRedDots関数と似ているが、RandomRedDots2関数はデータストア名を指定する引数を取る)を作成します。この例では、myVar変数を作成して、datastore_1という名前のデータストアに保存します。次に、doEval関数を呼び出してデータストア名を渡し、TRUEに設定したore.connect制御引数を渡します。
例6-10 ore.connect引数を指定したdoEval関数の使用方法
RandomRedDots2 <- function(divisor = 100, datastore.name = "myDatastore"){
id <- 1:10
plot(1:100, rnorm(100), pch = 21, bg = "red", cex = 2 )
ore.load(datastore.name) # Contains the numeric variable myVar.
data.frame(id = id, val = id / divisor, num = myVar)
}
myVar <- 5
ore.save(myVar, name = "datastore_1")
ore.doEval(RandomRedDots2, datastore.name = "datastore_1", ore.connect = TRUE)
例6-10のリスト
R> RandomRedDots2 <- function(divisor = 100, datastore.name = "myDatastore"){
+ id <- 1:10
+ plot(1:100, rnorm(100), pch = 21, bg = "red", cex = 2 )
+ ore.load(datastore.name) # Contains the numeric variable myVar.
+ data.frame(id = id, val = id / divisor, num = myVar)
+ }
R> ore.doEval(RandomRedDots2, datastore.name = "datastore_1", ore.connect = TRUE)
id val num
1 1 0.01 5
2 2 0.02 5
3 3 0.03 5
4 4 0.04 5
5 5 0.05 5
6 6 0.06 5
7 7 0.07 5
8 8 0.08 5
9 9 0.09 5
10 10 0.10 5
# The graph displayed by the plot function is not shown.
ore.tableApply関数は、入力データとしてore.frameを指定してRスクリプトを起動します。ore.tableApply関数は、ore.frameを最初の引数としてユーザー定義の入力関数に渡します。ore.tableApply関数は、ore.frameオブジェクトまたはシリアライズRオブジェクトをore.objectオブジェクトとして返します。
ore.tableApply関数の構文は次のとおりです。
ore.tableApply(X, FUN, ..., FUN.VALUE = NULL, FUN.NAME = NULL)
例6-11では、ore.tableApply関数を使用してirisデータセットにNaive Bayesモデルを構築します。naiveBayes関数はe1071パッケージにあり、クライアントとデータベース・サーバー・マシンの両方のRエンジンにインストールする必要があります。ore.tableApply関数の最初の引数として、ore.push(iris)の呼出しでは一時データベース表およびその表のプロキシであるore.frameが作成されます。2番目の引数は入力関数で、これには引数datがあります。ore.tableApply関数は、ore.frame表プロキシをdat引数として入力関数に渡します。この入力関数は、ore.tableApply関数がore.objectオブジェクトとして返すモデルを作成します。
例6-11 ore.tableApply関数の使用方法
library(e1071)
nbmod <- ore.tableApply(
ore.push(iris),
function(dat) {
library(e1071)
dat$Species <- as.factor(dat$Species)
naiveBayes(Species ~ ., dat)
})
class(nbmod)
nbmod
例6-11のリスト
R> nbmod <- ore.tableApply(
+ ore.push(iris),
+ function(dat) {
+ library(e1071)
+ dat$Species <- as.factor(dat$Species)
+ naiveBayes(Species ~ ., dat)
+ })
R> class(nbmod)
[1] "ore.object"
attr(,"package")
[1] "OREembed"
R> nbmod
Naive Bayes Classifier for Discrete Predictors
Call:
naiveBayes.default(x = X, y = Y, laplace = laplace)
A-priori probabilities:
Y
setosa versicolor virginica
0.3333333 0.3333333 0.3333333
Conditional probabilities:
Sepal.Length
Y [,1] [,2]
setosa 5.006 0.3524897
versicolor 5.936 0.5161711
virginica 6.588 0.6358796
Sepal.Width
Y [,1] [,2]
setosa 3.428 0.3790644
versicolor 2.770 0.3137983
virginica 2.974 0.3224966
Petal.Length
Y [,1] [,2]
setosa 1.462 0.1736640
versicolor 4.260 0.4699110
virginica 5.552 0.5518947
Petal.Width
Y [,1] [,2]
setosa 0.246 0.1053856
versicolor 1.326 0.1977527
virginica 2.026 0.2746501
ore.groupApply関数は、入力データとしてore.frameを指定してRスクリプトを起動します。ore.groupApply関数は、ore.frameを最初の引数としてユーザー定義の入力関数に渡します。ore.groupApply関数のINDEX引数は、ore.frameの列の名前を指定しますが、これによってOracle Databaseはユーザー定義のR関数による処理のために行をパーティショニングします。ore.groupApply関数は、1つ以上のRエンジンが同じR関数(タスク)をデータの別のパーティションで実行するデータ・パラレル実行を使用できます。
ore.groupApply関数の構文は次のとおりです。
ore.groupApply(X, INDEX, FUN, ..., FUN.VALUE = NULL, FUN.NAME = NULL,
parallel = getOption("ore.parallel", NULL))
ore.groupApply関数は、ore.listオブジェクトまたはore.frameオブジェクトを返します。
ore.groupApply関数の使用例は、次の各項で説明します。
例6-12では、ディシジョン・ツリーおよびルールベース・モデルを構築する関数が含まれるC50パッケージを使用します。このパッケージには、トレーニング・データとテスト・データのセットも含まれています。例6-12では、状態ごとのデータに基づいて1つのチャーン・モデルを作成することを目的に、C50パッケージのchurnデータセットからのchurnTrainトレーニング・データセットに基づいてC5.0モデルを構築します。この例では、次の操作を実行しています。
C50パッケージをロードした後に、churnデータセットをロードします。
ore.create関数を使用して、churnTrain (data.frameオブジェクト)からCHURN_TRAINデータベース表およびそのプロキシore.frameオブジェクトを作成します。
CHURN_TRAIN (プロキシore.frameオブジェクト)をore.groupApply関数の最初の引数として指定し、state列をINDEX引数として指定します。ore.groupApply関数は、state列のデータをパーティショニングし、ユーザー定義の関数を各パーティションで呼び出します。
ore.groupApply関数によって返されるore.listオブジェクトを取得するための変数modListを作成します。ore.listオブジェクトには、データの各パーティションでユーザー定義の関数を実行した結果が含まれています。この場合は、状態ごとに1つのC5.0モデルで、各モデルはore.objectオブジェクトとして格納されています。
ユーザー定義の関数を指定します。ユーザー定義の関数の最初の引数は、データ(1つの状態に関連付けられたすべてのデータ)の1つのパーティションを受け取ります。
ユーザー定義の関数は、次のことを実行します。
データベースのRエンジンで起動したときに関数で使用できるように、C50パッケージをロードします。
state列がモデルに含まれないように、data.frameからこの列を削除します。
ore.frameはファクタを定義しますが、ユーザー定義の関数にロードされたときにファクタが文字列ベクターとして表示されるため、列をファクタに変換します。
状態のモデルを構築し、それを返します。
ore.pull関数を使用してデータベースからmod.MA変数としてモデルを取得し、そこでsummary関数を呼び出します。mod.MAのクラスはC5.0です。
例6-12 ore.groupApply関数の使用方法
library(C50)
data("churn")
ore.create(churnTrain, "CHURN_TRAIN")
modList <- ore.groupApply(
CHURN_TRAIN,
INDEX=CHURN_TRAIN$state,
function(dat) {
library(C50)
dat$state <- NULL
dat$churn <- as.factor(dat$churn)
dat$area_code <- as.factor(dat$area_code)
dat$international_plan <- as.factor(dat$international_plan)
dat$voice_mail_plan <- as.factor(dat$voice_mail_plan)
C5.0(churn ~ ., data = dat, rules = TRUE)
});
mod.MA <- ore.pull(modList$MA)
summary(mod.MA)
例6-12のリスト
R> library(C50)
R> data(churn)
R>
R> ore.create(churnTrain, "CHURN_TRAIN")
R>
R> modList <- ore.groupApply(
+ CHURN_TRAIN,
+ INDEX=CHURN_TRAIN$state,
+ function(dat) {
+ library(C50)
+ dat$state <- NULL
+ dat$churn <- as.factor(dat$churn)
+ dat$area_code <- as.factor(dat$area_code)
+ dat$international_plan <- as.factor(dat$international_plan)
+ dat$voice_mail_plan <- as.factor(dat$voice_mail_plan)
+ C5.0(churn ~ ., data = dat, rules = TRUE)
+ });
R> mod.MA <- ore.pull(modList$MA)
R> summary(mod.MA)
Call:
C5.0.formula(formula = churn ~ ., data = dat, rules = TRUE)
C5.0 [Release 2.07 GPL Edition] Thu Feb 13 15:09:10 2014
-------------------------------
Class specified by attribute `outcome'
Read 65 cases (19 attributes) from undefined.data
Rules:
Rule 1: (52/1, lift 1.2)
international_plan = no
total_day_charge <= 43.04
-> class no [0.963]
Rule 2: (5, lift 5.1)
total_day_charge > 43.04
-> class yes [0.857]
Rule 3: (6/1, lift 4.4)
area_code in {area_code_408, area_code_415}
international_plan = yes
-> class yes [0.750]
Default class: no
Evaluation on training data (65 cases):
Rules
----------------
No Errors
3 2( 3.1%) <<
(a) (b) <-classified as
---- ----
53 1 (a): class no
1 10 (b): class yes
Attribute usage:
89.23% international_plan
87.69% total_day_charge
9.23% area_code
Time: 0.0 secs
ore.groupApply関数はINDEX引数に1つの列のみを取りますが、使用する列を連結した新しい列を作成して、この新しい列をINDEX引数として指定できます。
例6-13は、CHURN_TRAINデータセットのデータを使用して、指定したデータのパーティション(voice_mail_plan列およびinternational_plan列)に対するルールを作成するrpartモデルを構築します。この例では、Rのtable関数を使用して各パーティションで予測される行の数を示します。次に、vmp_ip.g1という名前の新しい列を作成するために、必要な2列を一緒にペーストした新しい列を追加します。
この例では次に、指定された名前のスクリプトがRスクリプト・リポジトリに存在しないように、ore.scriptDrop関数を呼び出します。その後、ore.scriptCreate関数を使用してmy.rpartFunctionという名前のスクリプトを定義し、それをリポジトリに格納します。格納されたスクリプトでは、Oracle R Enterpriseのデータストア・オブジェクトの命名に使用されるデータ・ソースおよび接頭辞を使用する関数を定義します。my.rpartFunction関数を呼び出すたびに、vmp_ipで特定されるパーティションの1つからデータを取得します。ソース・パーティションの列は定数のため、この関数はそれらをNULLに設定します。文字列ベクターをファクタに変換し、流動を予測するためのモデルを構築し、そこに適切に命名されたデータストアを保存します。この関数は、特定のパーティション列値、流動値の分布およびモデル自身を返すためのリストを作成します。
次にrpartライブラリをロードし、データストアの接頭辞を設定し、派生列vmp_ipをINDEX引数の値として、my.rpartFunctionをRスクリプト・リポジトリに格納されているユーザー定義の関数を呼び出すためのFUN.NAME引数の値として使用して、ore.groupApplyを呼び出します。ore.groupApply関数は、オプションの引数を使用してdatastorePrefix変数をユーザー定義の関数に渡します。この関数は、ユーザー定義の関数の実行時に、オプションの引数ore.connectを使用してデータベースに接続します。ore.groupApply関数は、変数resとしてore.listオブジェクトを返します。
この例では、返されるリストの最初のエントリを表示します。次に、ore.load関数を呼び出して、顧客がボイス・メール・プランと国際プランの両方を持つ場合のモデルをロードします。
例6-13 複数列でデータをパーティションする場合のore.groupApplyの使用方法
library(C50)
data(churn)
ore.drop("CHURN_TRAIN")
ore.create(churnTrain, "CHURN_TRAIN")
table(CHURN_TRAIN$international_plan, CHURN_TRAIN$voice_mail_plan)
CT <- CHURN_TRAIN
CT$vmp_ip <- paste(CT$voice_mail_plan, CT$international_plan,sep = "-")
options(width = 80)
head(CT, 3)
ore.scriptDrop("my.rpartFunction")
ore.scriptCreate("my.rpartFunction",
function(dat, datastorePrefix) {
library(rpart)
vmp <- dat[1, "voice_mail_plan"]
ip <- dat[1, "international_plan"]
datastoreName <- paste(datastorePrefix, vmp, ip, sep = "_")
dat$voice_mail_plan <- NULL
dat$international_plan <- NULL
dat$state <- as.factor(dat$state)
dat$churn <- as.factor(dat$churn)
dat$area_code <- as.factor(dat$area_code)
mod <- rpart(churn ~ ., data = dat)
ore.save(mod, name = datastoreName, overwrite = TRUE)
list(voice_mail_plan = vmp,
international_plan = ip,
churn.table = table(dat$churn),
rpart.model = mod)
})
library(rpart)
datastorePrefix = "my.rpartModel"
res <- ore.groupApply(CT, INDEX = CT$vmp_ip,
FUN.NAME = "my.rpartFunction",
datastorePrefix = datastorePrefix,
ore.connect = TRUE)
res[[1]]
ore.load(name=paste(datastorePrefix, "yes", "yes", sep = "_"))
mod
例6-13のリスト
R> library(C50)
R> data(churn)
R> ore.drop("CHURN_TRAIN")
R> ore.create(churnTrain, "CHURN_TRAIN")
R>
R> table(CHURN_TRAIN$international_plan, CHURN_TRAIN$voice_mail_plan)
no yes
no 2180 830
yes 231 92
R> CT <- CHURN_TRAIN
R> CT$vmp_ip <- paste(CT$voice_mail_plan, CT$international_plan, sep = "-")
R> options(width = 80)
R> head(CT, 3)
state account_length area_code international_plan voice_mail_plan
1 KS 128 area_code_415 no yes
2 OH 107 area_code_415 no yes
3 NJ 137 area_code_415 no no
number_vmail_messages total_day_minutes total_day_calls total_day_charge
1 25 265.1 110 45.07
2 26 161.6 123 27.47
3 0 243.4 114 41.38
total_eve_minutes total_eve_calls total_eve_charge total_night_minutes
1 197.4 99 16.78 244.7
2 195.5 103 16.62 254.4
3 121.2 110 10.30 162.6
total_night_calls total_night_charge total_intl_minutes total_intl_calls
1 91 11.01 10.0 3
2 103 11.45 13.7 3
3 104 7.32 12.2 5
total_intl_charge number_customer_service_calls churn vmp_ip
1 2.70 1 no yes-no
2 3.70 1 no yes-no
3 3.29 0 no no-no
R>
R> ore.scriptDrop("my.rpartFunction")
R> ore.scriptCreate("my.rpartFunction",
+ function(dat, datastorePrefix) {
+ library(rpart)
+ vmp <- dat[1, "voice_mail_plan"]
+ ip <- dat[1, "international_plan"]
+ datastoreName <- paste(datastorePrefix, vmp, ip, sep = "_")
+ dat$voice_mail_plan <- NULL
+ dat$international_plan <- NULL
+ dat$state <- as.factor(dat$state)
+ dat$churn <- as.factor(dat$churn)
+ dat$area_code <- as.factor(dat$area_code)
+ mod <- rpart(churn ~ ., data = dat)
+ ore.save(mod, name = datastoreName, overwrite = TRUE)
+ list(voice_mail_plan = vmp,
+ international_plan = ip,
+ churn.table = table(dat$churn),
+ rpart.model = mod)
+ })
R>
R> library(rpart)
R> datastorePrefix = "my.rpartModel"
R>
R> res <- ore.groupApply(CT, INDEX = CT$vmp_ip,
+ FUN.NAME = "my.rpartFunction",
+ datastorePrefix = datastorePrefix,
+ ore.connect = TRUE)
R> res[[1]]
$voice_mail_plan
[1] "no"
$international_plan
[1] "no"
$churn.table
no yes
1878 302
$rpart.model
n= 2180
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 2180 302 no (0.86146789 0.13853211)
2) total_day_minutes< 263.55 2040 192 no (0.90588235 0.09411765)
4) number_customer_service_calls< 3.5 1876 108 no (0.94243070 0.05756930)
8) total_day_minutes< 223.25 1599 44 no (0.97248280 0.02751720) *
9) total_day_minutes>=223.25 277 64 no (0.76895307 0.23104693)
18) total_eve_minutes< 242.35 210 18 no (0.91428571 0.08571429) *
19) total_eve_minutes>=242.35 67 21 yes (0.31343284 0.68656716)
38) total_night_minutes< 174.2 17 4 no (0.76470588 0.23529412) *
39) total_night_minutes>=174.2 50 8 yes (0.16000000 0.84000000) *
5) number_customer_service_calls>=3.5 164 80 yes (0.48780488 0.51219512)
10) total_day_minutes>=160.2 95 22 no (0.76842105 0.23157895)
20) state=AL,AZ,CA,CO,DC,DE,FL,HI,KS,KY,MA,MD,ME,MI,NC,ND,NE,NH,NM,OK,OR,SC,TN,VA,VT,WY 56 2 no (0.96428571 0.03571429) *
21) state=AK,AR,CT,GA,IA,ID,MN,MO,NJ,NV,NY,OH,RI,TX,UT,WA,WV 39 19 yes (0.48717949 0.51282051)
42) total_day_minutes>=182.3 21 5 no (0.76190476 0.23809524) *
43) total_day_minutes< 182.3 18 3 yes (0.16666667 0.83333333) *
11) total_day_minutes< 160.2 69 7 yes (0.10144928 0.89855072) *
3) total_day_minutes>=263.55 140 30 yes (0.21428571 0.78571429)
6) total_eve_minutes< 167.3 29 7 no (0.75862069 0.24137931)
12) state=AK,AR,AZ,CO,CT,FL,HI,IN,KS,LA,MD,ND,NM,NY,OH,UT,WA,WV 21 0 no (1.00000000 0.00000000) *
13) state=IA,MA,MN,PA,SD,TX,WI 8 1 yes (0.12500000 0.87500000) *
7) total_eve_minutes>=167.3 111 8 yes (0.07207207 0.92792793) *
R> ore.load(name = paste(datastorePrefix, "yes", "yes", sep = "_"))
[1] "mod"
R> mod
n= 92
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 92 36 no (0.60869565 0.39130435)
2) total_intl_minutes< 13.1 71 15 no (0.78873239 0.21126761)
4) total_intl_calls>=2.5 60 4 no (0.93333333 0.06666667)
8) state=AK,AR,AZ,CO,CT,DC,DE,FL,GA,HI,ID,IL,IN,KS,MD,MI,MO,MS,MT,NC,ND,NE,NH,NJ,OH,SC,SD,UT,VA,WA,WV,WY 53 0 no (1.00000000 0.00000000) *
9) state=ME,NM,VT,WI 7 3 yes (0.42857143 0.57142857) *
5) total_intl_calls< 2.5 11 0 yes (0.00000000 1.00000000) *
3) total_intl_minutes>=13.1 21 0 yes (0.00000000 1.00000000) *
ore.rowApply関数は、入力データとしてore.frameを指定してRスクリプトを起動します。ore.rowApply関数は、ore.frameを最初の引数としてユーザー定義の入力関数に渡します。ore.rowApply関数に対するrows引数には、ユーザー定義のR関数の呼出しごとに渡す行の数を指定します。最後のチャンクまたは行は、指定した数より少なくなる可能性があります。ore.rowApply関数は、1つ以上のRエンジンが同じR関数(タスク)をデータの別のパーティションで実行するデータ・パラレル実行を使用できます。
ore.rowApply関数の構文は次のとおりです。
ore.rowApply(X, FUN, ..., FUN.VALUE = NULL, FUN.NAME = NULL, rows = 1,
parallel = getOption("ore.parallel", NULL))
ore.rowApply関数は、ore.listオブジェクトまたはore.frameオブジェクトを返します。
例6-14では、事前にCRANからダウンロードしてあるe1071パッケージを使用します。また、この例では、例6-11「ore.tableApply関数の使用方法」で作成したNaive Bayeモデルであるnbmodオブジェクトも使用します。
例6-14では、次の処理を行います。
パッケージe1071をロードします。
irisデータセットをIRIS一時表およびore.frameオブジェクトとしてデータベースにプッシュします。
IRISをIRIS_PREDとしてコピーし、予測を含めるためにPRED列をIRIS_PREDに追加します。
ore.rowApply関数を呼び出し、IRIS ore.frameをユーザー定義R関数のデータソースおよびユーザー定義R関数自体として渡します。
ユーザー定義の関数は、次のことを実行します。
パッケージe1071を、データベース内で稼働するRエンジンまたはエンジンで使用できるようにロードします。
ore.frameはファクタを定義しますが、ユーザー定義の関数にロードされたときにファクタが文字列ベクターとして表示されるため、Species列をファクタに変換します。
predictメソッドを起動し、データセットに追加された列に予測が含まれているresオブジェクトを返します。
この例では、モデルをクライアントのRセッションにプルします。
IRIS_PREDを引数FUN.VALUEとして渡しますが、この引数にore.rowApply関数が返すオブジェクトの構造を指定します。
ユーザー定義関数の呼出しごとに渡す行の数を指定します。
resのクラスを表示し、table関数を呼び出してSpecies列およびresオブジェクトのPRED列を表示します。
例6-14 ore.rowApply関数の使用方法
library(e1071)
IRIS <- ore.push(iris)
IRIS_PRED <- IRIS
IRIS_PRED$PRED <- "A"
res <- ore.rowApply(
IRIS,
function(dat, nbmod) {
library(e1071)
dat$Species <- as.factor(dat$Species)
dat$PRED <- predict(nbmod, newdata = dat)
dat
},
nbmod = ore.pull(nbmod),
FUN.VALUE = IRIS_PRED,
rows = 10)
class(res)
table(res$Species, res$PRED)
例6-14のリスト
R> library(e1071)
R> IRIS <- ore.push(iris)
R> IRIS_PRED <- IRIS
R> IRIS_PRED$PRED <- "A"
R> res <- ore.rowApply(
+ IRIS ,
+ function(dat, nbmod) {
+ library(e1071)
+ dat$Species <- as.factor(dat$Species)
+ dat$PRED <- predict(nbmod, newdata = dat)
+ dat
+ },
+ nbmod = ore.pull(nbmod),
+ FUN.VALUE = IRIS_PRED,
+ rows = 10)
R> class(res)
[1] "ore.frame"
attr(,"package")
[1] "OREbase"
R> table(res$Species, res$PRED)
setosa versicolor virginica
setosa 50 0 0
versicolor 0 47 3
virginica 0 3 47
例6-12と同様に例6-15でも、C50パッケージを使用して、C5.0モデルを使用してチャーン・データをスコアリングします(つまり、解約傾向が高い顧客を予測します)。ただし、例6-15では、列によってデータをパーティショニングするのではなく、多数の行によってデータをパーティショニングします。この例では、指定された状態からの顧客を並行してスコアリングします。データストアを使用し、関数をRスクリプト・リポジトリに保存することにより、これらの関数をOracle R Enterprise SQL API関数で使用できるようにします。
例6-15ではまず、C50パッケージおよびデータセットをロードします。この例では、名前にmyC5.0modelFLが含まれるデータストアが存在する場合、そのデータストアを削除します。ore.dropを呼び出してCHURN_TEST表(存在する場合)を削除した後、ore.createを呼び出してchurnTestデータセットからCHURN_TEST表を作成します。
次に、ファクタ列ごとにレベルのlistを返すore.getLevelsを呼び出します。この呼出しでは、最初の列(state)のレベルは必要ないため最初の列は除外されます。最初にレベルを取得しておくと、モデル構築中に、一部のレベルに対して値を持たない行があっても、すべての使用可能なレベルを確実に取得できます。ore.deleteの呼出しによって、指定された名前のデータストアが存在しないことが確認され、ore.saveの呼出しによって、xlevelsオブジェクトがmyXLevelsという名前のデータストアに保存されます。
例6-15では、C5.0モデルを生成するユーザー定義関数myC5.0FunctionForLevelsを作成します。この関数は、例6-12のようにas.factor関数をユーザー定義関数として使用してレベルを計算するのではなく、関数ore.getXlevelsにより返されたレベルのリストを使用します。レベルを使用して、列タイプを文字ベクターからファクタに変換します。関数myC5.0FunctionForLevelsは、値TRUEを返します。この例では、この関数をRスクリプト・リポジトリに保存します。
次に、指定された文字列を含む名前のデータストアのリストを取得し、これらのデータストアが存在していれば削除します。
その後、ore.groupApplyを呼び出し、それによってCHURN_TESTデータの各状態に対して関数myC5.0FunctionForLevelsが呼び出されます。myC5.0FunctionForLevelsの呼出しのたびに、ore.groupApplyは、xlevelsオブジェクトを含むデータストアと、myC5.0FunctionForLevelsにより生成されたデータストアのネーミングに使用する接頭辞を渡します。また、ore.connect制御引数を渡して埋込みR関数でデータベースに接続することにより、データストアに格納されているオブジェクトを使用できるようにします。ore.groupApplyの呼出しにより、myC5.0FunctionForLevelsのすべての呼出しの結果を含むリストが返されます。
この例では、結果をローカルなRセッションにプルし、データソース内の各状態に対してmyC5.0FunctionForLevelsがTRUEを返したことを確認します。
例6-15では次に、別のユーザー定義関数myScoringFunctionを作成して、Rスクリプト・リポジトリに格納します。この関数は、状態のレベルでC5.0モデルをスコアリングし、結果をdata.frameで返します。
次に、関数ore.rowApplyを呼び出します。マサチューセッツ州のデータのみを使用するように入力データをフィルタ処理します。呼び出す関数としてmyScoringFunctionを指定し、xlevelsオブジェクトを含むデータストアの名前と、状態に対するC5.0モデルを含むデータストアをロードする際に使用する接頭辞をそのユーザー定義関数に渡します。ore.rowApplyの呼出しにより、各パラレルRエンジンでデータセット200行に対してmyScoringFunctionを呼び出すことを指定します。ore.rowApplyがmyScoringFunctionのすべての呼出しの結果を含むore.frameを返すように、FUN.VALUE引数を使用します。変数scoresは、ore.rowApply呼出しの結果を取得します。
例6-15では最後に、scoresオブジェクトを出力した後、表関数を使用してスコアリング用の混同マトリクスを表示します。
例6-15 データストアおよびスクリプトを指定したore.rowApply関数の使用方法
library(C50)
data(churn)
ore.drop("CHURN_TEST"
ore.create(churnTest, "CHURN_TEST")
xlevels <- ore.getXlevels(~ ., CHURN_TEST[,-1])
ore.delete("myXLevels")
ore.save(xlevels, name = "myXLevels")
ore.scriptDrop("myC5.0FunctionForLevels")
ore.scriptCreate("myC5.0FunctionForLevels",
function(dat, xlevelsDatastore, datastorePrefix) {
library(C50)
state <- dat[1,"state"]
datastoreName <- paste(datastorePrefix, dat[1, "state"], sep = "_")
dat$state <- NULL
ore.load(name = xlevelsDatastore)
for (j in names(xlevels))
dat[[j]] <- factor(dat[[j]], levels = xlevels[[j]])
c5mod <- C5.0(churn ~ ., data = dat, rules = TRUE)
ore.save(c5mod, name = datastoreName)
TRUE
})
ds.v <- ore.datastore(pattern= "myC5.0modelFL")$datastore.name
for (ds in ds.v) ore.delete(name = ds)
res <- ore.groupApply(CHURN_TEST,
INDEX=CHURN_TEST$state,
FUN.NAME = "myC5.0FunctionForLevels",
xlevelsDatastore = "myXLevels",
datastorePrefix = "myC5.0modelFL",
ore.connect = TRUE)
res <- ore.pull(res)
all(as.logical(res) == TRUE)
ore.scriptDrop("myScoringFunction")
ore.scriptCreate("myScoringFunction",
function(dat, xlevelsDatastore, datastorePrefix) {
library(C50)
state <- dat[1,"state"]
datastoreName <- paste(datastorePrefix,state,sep="_")
dat$state <- NULL
ore.load(name = xlevelsDatastore)
for (j in names(xlevels))
dat[[j]] <- factor(dat[[j]], levels = xlevels[[j]])
ore.load(name = datastoreName)
res <- data.frame(pred = predict(c5mod, dat, type = "class"),
actual = dat$churn,
state = state)
res
}
)
scores <- ore.rowApply(
CHURN_TEST[CHURN_TEST$state == "MA",],
FUN.NAME = "myScoringFunction",
xlevelsDatastore = "myXLevels",
datastorePrefix = "myC5.0modelFL",
ore.connect = TRUE, parallel = TRUE,
FUN.VALUE = data.frame(pred = character(0),
actual = character(0),
state = character(0)),
rows=200)
scores
table(scores$actual, scores$pred)
例6-15のリスト
R> library(C50)
R> data(churn)
R>
R> ore.drop("CHURN_TEST"
R> ore.create(churnTest, "CHURN_TEST")
R>
R> xlevels <- ore.getXlevels(~ ., CHURN_TEST[,-1])
R> ore.delete("myXLevels")
[1] "myXLevels
R> ore.save(xlevels, name = "myXLevels")
R>
R> ore.scriptDrop("myC5.0FunctionForLevels")
R> ore.scriptCreate("myC5.0FunctionForLevels",
+ function(dat, xlevelsDatastore, datastorePrefix) {
+ library(C50)
+ state <- dat[1,"state"]
+ datastoreName <- paste(datastorePrefix, dat[1, "state"], sep = "_")
+ dat$state <- NULL
+ ore.load(name = xlevelsDatastore)
+ for (j in names(xlevels))
+ dat[[j]] <- factor(dat[[j]], levels = xlevels[[j]])
+ c5mod <- C5.0(churn ~ ., data = dat, rules = TRUE)
+ ore.save(c5mod, name = datastoreName)
+ TRUE
+ })
R>
R> ds.v <- ore.datastore(pattern="myC5.0modelFL")$datastore.name
R> for (ds in ds.v) ore.delete(name=ds)
R>
R> res <- ore.groupApply(CHURN_TEST,
+ INDEX=CHURN_TEST$state,
+ FUN.NAME="myC5.0FunctionForLevels",
+ xlevelsDatastore = "myXLevels",
+ datastorePrefix = "myC5.0modelFL",
+ ore.connect = TRUE)
R> res <- ore.pull(res)
R> all(as.logical(res) == TRUE)
[1] TRUE
R>
R> ore.scriptDrop("myScoringFunction")
R> ore.scriptCreate("myScoringFunction",
+ function(dat, xlevelsDatastore, datastorePrefix) {
+ library(C50)
+ state <- dat[1,"state"]
+ datastoreName <- paste(datastorePrefix,state,sep="_")
+ dat$state <- NULL
+ ore.load(name = xlevelsDatastore)
+ for (j in names(xlevels))
+ dat[[j]] <- factor(dat[[j]], levels = xlevels[[j]])
+ ore.load(name = datastoreName)
+ res <- data.frame(pred = predict(c5mod, dat, type="class"),
+ actual = dat$churn,
+ state = state)
+ res
+ }
+ )
R>
R> scores <- ore.rowApply(
+ CHURN_TEST[CHURN_TEST$state =="MA",],
+ FUN.NAME = "myScoringFunction",
+ xlevelsDatastore = "myXLevels",
+ datastorePrefix = "myC5.0modelFL",
+ ore.connect = TRUE, parallel = TRUE,
+ FUN.VALUE = data.frame(pred=character(0),
+ actual=character(0),
+ state=character(0)),
+ rows=200
R>
R> scores
pred actual state
1 no no MA
2 no no MA
3 no no MA
4 no no MA
5 no no MA
6 no yes MA
7 yes yes MA
8 yes yes MA
9 no no MA
10 no no MA
11 no no MA
12 no no MA
13 no no MA
14 no no MA
15 yes yes MA
16 no no MA
17 no no MA
18 no no MA
19 no no MA
20 no no MA
21 no no MA
22 no no MA
23 no no MA
24 no no MA
25 no no MA
26 no no MA
27 no no MA
28 no no MA
29 no yes MA
30 no no MA
31 no no MA
32 no no MA
33 yes yes MA
34 no no MA
35 no no MA
36 no no MA
37 no no MA
38 no no MA
Warning message:
ORE object has no unique key - using random order
R> table(scores$actual, scores$pred)
no yes
no 32 0
yes 2 4
ore.indexApply関数は、入力関数によって生成されたデータを使用して指定されたユーザー定義の入力関数を実行します。これは、1つ以上のRエンジンが同じまたは異なる計算(タスク)を実行するタスク・パラレル実行をサポートします。ore.indexApply関数に対するtimes引数には、データベース内で入力関数を実行する回数を指定します。必要なすべてのデータは、入力関数内で明示的に生成またはロードされる必要があります。
ore.indexApply関数の構文は次のとおりです。
ore.indexApply(times, FUN, ..., FUN.VALUE = NULL, FUN.NAME = NULL,
parallel = getOption("ore.parallel", NULL))
ore.indexApply関数は、ore.listオブジェクトまたはore.frameオブジェクトを返します。
ore.indexApply関数の使用例は、次の各項で説明します。
例6-16では、ore.indexApplyを呼び出し、入力関数を並行して5回実行することを指定します。結果のクラスであるore.listを表示した後に、結果を表示します。
例6-16 ore.indexApply関数の使用方法
res <- ore.indexApply(5,
function(index) {
paste("IndexApply:", index)
},
parallel = TRUE)
class(res)
res
例6-16のリスト
R> res <- ore.indexApply(5,
+ function(index) {
+ paste("IndexApply:", index)
+ },
+ parallel = TRUE)
R> class(res)
[1] "ore.list"
attr(,"package")
[1] "OREembed"
R> res
$`1`
[1] "IndexApply: 1"
$`2`
[1] "IndexApply: 2"
$`3`
[1] "IndexApply: 3"
$`4`
[1] "IndexApply: 4"
$`5`
[1] "IndexApply: 5"
例6-17では、Rのsummary関数を使用して、irisデータセットの最初の4つの数値列でサマリー統計を並行して計算します。この例では、計算を最終結果に結合します。ore.indexApply関数の最初の引数は4で、これは、並行してまとめる列の数を指定します。ユーザー定義の入力関数は1つの引数indexを取り、これは、まとめる列を指定する1から4の値です。
この例では、summary関数を指定した列で呼び出します。summaryの呼出しでは、列のサマリー統計が含まれている単一の行が返されます。この例では、summary呼出しの結果をdata.frameに変換し、そこに列名を追加します。
次に、ore.indexApply関数に対してFUN.VALUE引数を使用して、関数の結果の構造を定義します。結果はその後、その構造とともにore.frameオブジェクトとして返されます。
例6-17 ore.indexApply関数の使用方法および結果の結合
res <- NULL
res <- ore.indexApply(4,
function(index) {
ss <- summary(iris[, index])
attr.names <- attr(ss, "names")
stats <- data.frame(matrix(ss, 1, length(ss)))
names(stats) <- attr.names
stats$col <- names(iris)[index]
stats
},
FUN.VALUE=data.frame(Min. = numeric(0),
"1st Qu." = numeric(0),
Median = numeric(0),
Mean = numeric(0),
"3rd Qu." = numeric(0),
Max. = numeric(0),
Col = character(0)),
parallel = TRUE)
res
例6-17のリスト
R> res <- NULL
R> res <- ore.indexApply(4,
+ function(index) {
+ ss <- summary(iris[, index])
+ attr.names <- attr(ss, "names")
+ stats <- data.frame(matrix(ss, 1, length(ss)))
+ names(stats) <- attr.names
+ stats$col <- names(iris)[index]
+ stats
+ },
+ FUN.VALUE=data.frame(Min. = numeric(0),
+ "1st Qu." = numeric(0),
+ Median = numeric(0),
+ Mean = numeric(0),
+ "3rd Qu." = numeric(0),
+ Max. = numeric(0),
+ Col = character(0)),
+ parallel = TRUE)
R> res
Min. X1st.Qu. Median Mean X3rd.Qu. Max. Col
1 2.0 2.8 3.00 3.057 3.3 4.4 Sepal.Width
2 4.3 5.1 5.80 5.843 6.4 7.9 Sepal.Length
3 0.1 0.3 1.30 1.199 1.8 2.5 Petal.Width
4 1.0 1.6 4.35 3.758 5.1 6.9 Petal.Length
Warning message:
ORE object has no unique key - using random order
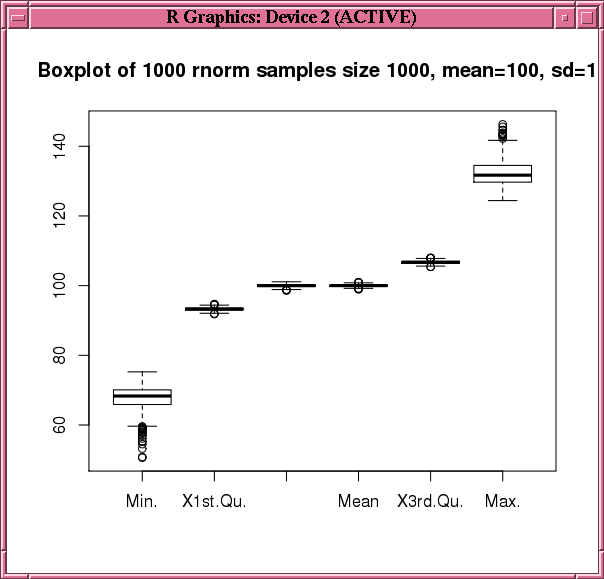
ore.indexApply関数をシミュレーションで使用しすることで、Oracle Exadataデータベース・マシンなどの高パフォーマンスのコンピューティング・ハードウェアを利用できます。例6-18は、ランダムな正規分布の複数のサンプルを使用してサマリー統計の分布を比較します。各シミュレーションは、データベースの別個のRエンジンで、データベースで許可された並列度まで並列に実行されます。
例6-18では、サンプル・サイズの変数、乱数値の平均および標準偏差および実行するシミュレーションの数を定義します。この例では、num.simulationsをore.indexApply関数の最初の引数として指定します。ore.indexApply関数は、num.simulationsをindex引数としてユーザー定義の関数に渡します。この入力関数はその後、各入力関数の呼出しで異なる乱数値のセットが生成されるように、索引に基づいて乱数シードを設定します。
次に、入力関数は、rnorm関数を使用してsample.sizeランダムな標準値を生成します。乱数のベクターでsummary関数を呼び出し、返される結果としてdata.frameを準備します。ore.indexApply関数には、シミュレーションの結合された結果を構成するore.frameを返すように、FUN.VALUE引数を指定します。res変数は、ore.indexApply関数によって返されるore.frameを取得します。
サンプルの分布を取得するために、この例では、ore.pull関数を使用した結果であるdata.frameでboxplot関数を呼び出し、resから選択した列をクライアントに渡します。
例6-18 シミュレーションでのore.indexApply関数の使用方法
res <- NULL
sample.size = 1000
mean.val = 100
std.dev.val = 10
num.simulations = 1000
res <- ore.indexApply(num.simulations,
function(index, sample.size = 1000, mean = 0, std.dev = 1) {
set.seed(index)
x <- rnorm(sample.size, mean, std.dev)
ss <- summary(x)
attr.names <- attr(ss, "names")
stats <- data.frame(matrix(ss, 1, length(ss)))
names(stats) <- attr.names
stats$index <- index
stats
},
FUN.VALUE=data.frame(Min. = numeric(0),
"1st Qu." = numeric(0),
Median = numeric(0),
Mean = numeric(0),
"3rd Qu." = numeric(0),
Max. = numeric(0),
Index = numeric(0)),
parallel = TRUE,
sample.size = sample.size,
mean = mean.val, std.dev = std.dev.val)
options("ore.warn.order" = FALSE)
head(res, 3)
tail(res, 3)
boxplot(ore.pull(res[, 1:6]),
main=sprintf("Boxplot of %d rnorm samples size %d, mean=%d, sd=%d",
num.simulations, sample.size, mean.val, std.dev.val))
例6-18のリスト
R> res <- ore.indexApply(num.simulations,
+ function(index, sample.size = 1000, mean = 0, std.dev = 1) {
+ set.seed(index)
+ x <- rnorm(sample.size, mean, std.dev)
+ ss <- summary(x)
+ attr.names <- attr(ss, "names")
+ stats <- data.frame(matrix(ss, 1, length(ss)))
+ names(stats) <- attr.names
+ stats$index <- index
+ stats
+ },
+ FUN.VALUE=data.frame(Min. = numeric(0),
+ "1st Qu." = numeric(0),
+ Median = numeric(0),
+ Mean = numeric(0),
+ "3rd Qu." = numeric(0),
+ Max. = numeric(0),
+ Index = numeric(0)),
+ parallel = TRUE,
+ sample.size = sample.size,
+ mean = mean.val, std.dev = std.dev.val)
R> options("ore.warn.order" = FALSE)
R> head(res, 3)
Min. X1st.Qu. Median Mean X3rd.Qu. Max. Index
1 67.56 93.11 99.42 99.30 105.8 128.0 847
2 67.73 94.19 99.86 100.10 106.3 130.7 258
3 65.58 93.15 99.78 99.82 106.2 134.3 264
R> tail(res, 3)
Min. X1st.Qu. Median Mean X3rd.Qu. Max. Index
1 65.02 93.44 100.2 100.20 106.9 134.0 5
2 71.60 93.34 99.6 99.66 106.4 131.7 4
3 69.44 93.15 100.3 100.10 106.8 135.2 3
R> boxplot(ore.pull(res[, 1:6]),
+ main=sprintf("Boxplot of %d rnorm samples size %d, mean=%d, sd=%d",
+ num.simulations, sample.size, mean.val, std.dev.val))
Oracle R Enterpriseの埋込みRの実行用のSQLインタフェースでは、本番データベースのアプリケーションでRスクリプトを実行できます。SQLインタフェースには、Rスクリプト・リポジトリのスクリプトの追加と削除、Rスクリプトの実行、およびOracle R Enterpriseデータストアの削除を行うための関数があります。
このSQLインタフェースについては、次のトピックで説明しています。
Oracle R Enterpriseでは、埋込みRの実行用のRインタフェース関数のほとんどに相当するSQL表関数が提供されています。SELECT FROM TABLE文を実行し、いずれかの表関数を指定すると、指定されたRスクリプトが呼び出されます。このスクリプトは、Oracle Databaseサーバー上の1つ以上のRエンジンで実行されます。
rqEval
rqGroupEval
rqRowEval
rqTableEval
表6-1に、Rインタフェース関数およびそれに相当するSQL関数を示します。
rqGroupEval関数の場合、Oracle R EnterpriseはSQLでのグループ適用機能の汎用実装を提供します。入力カーソルの後続を取得する表関数を記述する必要があります。
この項の次の各トピックで、SQL表関数の一般的な側面について説明します。
これらの関数の使用例を含む詳細は、次の項目を参照してください。
SQL表関数の中には、共通のパラメータを持つものもあれば、その関数に固有のパラメータを持つものもあります。SQL表関数のパラメータは次のとおりです。
表6-2 SQL表関数のパラメータ
| パラメータ | 説明 |
|---|---|
|
|
|
|
|
R関数に渡す引数を指定するカーソル。パラメータ・カーソルは、単一行のスカラー値で構成されます。引数には文字列または数値を指定できます。カーソル内には複数の引数を指定できます。R関数への引数では大/小文字が区別されるため、列名などの名前は二重引用符で囲む必要があります。 カーソル内には、Oracle R Enterprise制御引数やシリアライズされたRオブジェクト(Oracle R Enterpriseデータストア内にある予測モデルなど)の名前をスカラー値として指定することもできます。 R関数への引数も制御引数も渡さない場合は、このパラメータ・カーソルの値を |
|
|
出力表の定義。この引数の値は、 |
|
|
rqGroupEval関数の場合、グループ化列の名前。 |
|
|
|
|
|
Rスクリプト・リポジトリ内でR関数を識別する名前。 |
Oracle R EnterpriseのSQL表関数は、表を返します。表の構造と内容は、SQL表関数に渡されたR関数の結果と、OUT_QRYパラメータによって決定されます。R関数はdata.frameオブジェクト、他のRオブジェクトおよびグラフィックを返すことができます。R関数の結果を表す表の構造は、次のいずれかのOUT_QRY値によって指定されます。
NULL: データ・オブジェクトとイメージ・オブジェクトの両方を含む可能性のあるシリアライズ・オブジェクトを持つ表が返されます。
SELECT文で指定された表シグネチャ: 定義された構造の表が返されます。R関数の結果はdata.frameとなる必要があります。イメージは返されません。
文字列'XML': XML文字列での構造化データとグラフ・イメージの両方を含む可能性のあるCLOBを持つ表が返されます。イメージでないRオブジェクト(data.frameやmodelオブジェクトなど)が最初に提供され、次にbase 64でエンコードされたイメージのPNG表示が続きます。
文字列'PNG': PNG形式のグラフ・イメージを含むBLOBを持つ表が返されます。表には、列名name、idおよびimageが含まれます。
埋込みRの実行中にOracle Databaseサーバー上のOracle R Enterpriseへの接続を確立するには、パラメータ・カーソル内に制御引数ore.connectを指定できます。これを行うと、埋込みR関数を呼び出したユーザーの資格証明を使用して接続が確立されます。また、自動的にOREパッケージがロードされます。オブジェクトをOracle R EnterpriseのRオブジェクト・データストアに保存する場合や、データソースからオブジェクトをロードする場合は、Oracle R Enterpriseへの接続を確立する必要があります。また、これにより、Oracle R Enterpriseの透過層を明示的に使用できます。
埋込みRの実行用のSQL APIの関数では、引数として、OracleデータベースのRスクリプト・リポジトリに格納されている名前付きRスクリプトが必要です。sys.rq_scriptsビューには、使用可能なスクリプトの名前とコンテンツが含まれます。
SQL APIでは、関数sys.rqScriptCreateおよびsys.rqScriptDropはスクリプトを作成および削除します。「スクリプトのセキュリティに関する考慮事項」で説明したように、スクリプトを作成したり、Rスクリプト・リポジトリからスクリプトを削除するには、RQADMINロールが必要です。
sys.rqScriptCreate関数を使用する場合、スクリプトの名前と、1つのR関数定義を含むRスクリプトを指定する必要があります。関数sys.rqScriptCreateおよびsys.rqScriptDropのコールは、BEGIN-END PL/SQLブロックでラップする必要があります。関数はキャラクタ・ラージ・オブジェクト(CLOB)としてデータベースに格納されるため、関数定義を一重引用符で囲んで文字列として指定する必要があります。
これらの関数の構文は次のとおりです。
sys.rqScriptCreate (
V_NAME IN VARCHAR2
V_SCRIPT IN CLOB)
sys.rqScriptDrop (
V_NAME IN VARCHAR2)
表6-3に、スクリプト作成および削除の関数のパラメータを示します。
例6-19ではまず、sys.rqScriptDrop関数を実行して、指定された名前のスクリプトがRスクリプト・リポジトリに含まれていないことを確認します。次に、sys.rqScriptCreate関数を実行して、myRandomRedDots2というユーザー定義関数を作成します。このユーザー定義関数は2つの引数を受け入れ、2つの列を持ち指定の数のランダム標準値を表示するdata.frameオブジェクトを返します。sys.rqScriptCreate関数は、ユーザー定義関数をRスクリプト・リポジトリに格納します。
例6-19 SQL APIによるRスクリプトの削除および作成
BEGIN
sys.rqScriptDrop('myRandomRedDots2');
END;
/
BEGIN
sys.rqScriptCreate('myRandomRedDots2',
'function(divisor = 100, numDots = 100) {
id <- 1:10
plot(1:numDots, rnorm(numDots), pch = 21, bg = "red", cex = 2 )
data.frame(id = id, val = id / divisor)
}');
END;
/
Oracle R Enterpriseは、SQLでの基本的なデータストア管理機能を提供します。基本的なデータストア管理には、表示、検索および削除があります。次の関数およびビューを提供します。
rquser_DataStoreListは、現行ユーザー・スキーマにあるすべてのデータストアのデータストア・レベルの情報が含まれるビューです。この情報は、データストア名、オブジェクト数、サイズ、作成日および説明で構成されます。
次の例は、ビューの使用方法を示しています。
SELECT * from rquser_DataStoreList; SELECT dsname, nobj, dssize FROM rquser_datastorelist WHERE dsname = 'ds_1';
rquser_DataStoreContentsは、現行のユーザー・スキーマにあるすべてのデータストアのオブジェクト・レベルの情報が含まれるビューです。この情報は、オブジェクト名、サイズ、クラス、長さ、行および列の数で構成されます。
次の例では、データストアdatastore_1のデータストア・コンテンツをリストします。
SELECT * FROM rquser_DataStoreContents WHERE dsname = 'datastore_1';
rqDropDataStoreは、データストアおよびデータストア内のすべてのオブジェクトを削除します。
構文: rqDropDataStore('<ds_name>')。ここで、<ds_name>は削除するデータストアの名前です。
次の例では、現行ユーザー・スキーマからデータストアdatastore_1を削除します。
rqDropDataStore('datastore_1')
rqEval関数は、EXP_NAMパラメータで指定されているスクリプト内のR関数を実行します。PAR_CURパラメータを使用して、引数をR関数に渡すことができます。
rqEval関数は、データベースからのデータを自動的には受信しません。R関数は、使用するデータを生成するか、Oracle Database、他のデータベース、フラット・ファイルなどのデータソースからデータを明示的に取得します。
R関数は、データベース内にSQL表として表示されるR data.frameオブジェクトを返します。OUT_QRYパラメータを使用して、返される値の形式を定義します。
パラメータ
表6-4に、rqEval関数のパラメータを示します。
表6-4 rqEval関数のパラメータ
| パラメータ | 説明 |
|---|---|
|
|
|
|
|
次のうちの1つ。
|
|
|
Rスクリプト・リポジトリ内のスクリプトの名前。 |
例
例6-20では、例6-19で作成されてRスクリプト・リポジトリに格納された関数myRandomRedDots2を呼び出します。rqEvalの最初のパラメータの値は、関数myRandomRedDots2に引数を渡さないことを指定するNULLです。2番目のパラメータの値は、rqEvalにより返されたdata.frameの列名およびデータ型を記述するSQL文を指定する文字列です。3番目のパラメータの値は、Rスクリプト・リポジトリ内のスクリプトの名前です。
例6-20 rqEvalの使用方法
SELECT * FROM table(rqEval(NULL, 'SELECT 1 id, 1 val FROM dual', 'myRandomRedDots2'));
Oracle SQL DeveloperでのSELECT文の結果は次のようになります。
ID VAL
---------- ----------
1 .01
2 .02
3 .03
4 .04
5 .05
6 .06
7 .07
8 .08
9 .09
10 .1
10 rows selected
例6-21では、rqEvalの最初のパラメータとしてカーソルを指定することにより、R関数に引数を渡します。カーソルは、単一行のスカラー値の中に複数の引数を指定します。
例6-21 rqEvalにより呼び出されたR関数に引数を渡す
SELECT *
FROM table(rqEval(cursor(SELECT 50 "divisor", 500 "numDots" FROM dual),
'SELECT 1 id, 1 val FROM dual',
'myRandomRedDots2'));
Oracle SQL DeveloperでのSELECT文の結果は次のようになります。
ID VAL
---------- ----------
1 .02
2 .04
3 .06
4 .08
5 .1
6 .12
7 .14
8 .16
9 .18
10 .2
10 rows selected
例6-22では、PNG_Exampleというスクリプトを作成してRスクリプト・リポジトリに格納します。rqEvalを呼び出すと、'PNG'のOUT_QRY値が指定されます。
例6-22 出力表定義としてのPNGの指定
BEGIN
sys.rqScriptDrop('PNG_Example');
sys.rqScriptCreate('PNG_Example',
'function(){
dat <- data.frame(y = log(1:100), x = 1:100)
plot(lm(y ~ x, dat))
}');
END;
/
SELECT *
FROM table(rqEval(NULL,'PNG','PNG_Example'));
Oracle SQL DeveloperでのSELECT文の結果は次のようになります。
NAME ID IMAGE
------ ---- ------
1 (BLOB)
2 (BLOB)
3 (BLOB)
4 (BLOB)
rqGroupEval関数は、グループ化列を識別するユーザー定義関数です。ユーザーは、SQLでのグループ適用機能の汎用実装であるSQLオブジェクトrqGroupEvalImplを使用して、PL/SQLでrqGroupEval関数を定義します。この実装ではデータ・パラレル実行がサポートされており、1つ以上のRエンジンにより同じR関数(タスク)が異なるデータ・パーティションで実行されます。データは、グループ化列の値に従ってパーティショニングされます。
1つのグループ化列のみがサポートされています。複数の列がある場合、それらの列を1つの列に結合して、その新しい列をグループ化列として使用します。
rqGroupEval関数は、EXP_NAMパラメータで指定されているスクリプト内のR関数を実行します。INP_CURパラメータを使用して、データをR関数に渡します。PAR_CURパラメータを使用して、引数をR関数に渡すことができます。
R関数は、データベース内にSQL表として表示されるR data.frameオブジェクトを返します。OUT_QRYパラメータを使用して、返される値の形式を定義します。
rqGroupEval関数を作成するには、次の2つのPL/SQLオブジェクトを作成します。
返される結果の型を指定するPL/SQLパッケージ。
パッケージの戻り値を取り、その戻り値とPIPELINED_PARALLEL_ENABLEセットを使用してデータをパーティショニングする列を示す関数。
構文
rqGroupEval (
INP_CUR REF CURSOR IN
PAR_CUR REF CURSOR IN
OUT_QRY VARCHAR2 IN
GRP_COL VARCHAR2 IN
EXP_NAM VARCHAR2 IN)
パラメータ
表6-7に、ユーザー定義のrqGroupEval関数のパラメータを示します。
表6-5 rqGroupEval関数のパラメータ
| パラメータ | 説明 |
|---|---|
|
|
|
|
|
R関数に渡す引数値を含むカーソル。 |
|
|
次のうちの1つ。
|
|
|
データのパーティショニングに使用するグループ化列の名前。 |
|
|
Rスクリプト・リポジトリ内のスクリプトの名前。 |
例
例6-23に示すPL/SQLブロックでは、スクリプトmyC5.0FunctionがRスクリプト・リポジトリに存在しないように、このスクリプトを削除します。次に、関数を作成して、それをスクリプトmyC5.0Functionとしてリポジトリに格納します。
このR関数は、2つの引数(操作対象のデータと、データストアの作成で使用する接頭辞)を受け入れます。この関数はC50パッケージを使用して、C50からのchurnデータセットに基づいてC5.0モデルを構築します。この関数は、状態ごとのデータに基づいて1つのチャーン・モデルを構築します。
myC5.0Function関数はC50パッケージをロードして、データベース・サーバーのRエンジンで関数が実行されるときにその関数本体がC50パッケージにアクセスできるようにします。次に、データストアの接頭辞および状態の名前を使用して、データストア名を作成します。モデルから状態名を除外するために、この関数はdata.frameから列を削除します。data.frame内のファクタはユーザー定義の埋込みR関数にロードされるときに文字列ベクターに変換されるため、myC5.0Function関数は明示的に文字ベクターをRファクタに戻します。
myC5.0Function関数は、指定された列から状態のデータを取得し、その状態のモデルを作成して、モデルをデータストアに保存します。R関数は、関数の実行結果として表示可能な単純な値を持つためにTRUEを返します。
例6-23では次に、PL/SQLパッケージchurnPkgおよびユーザー定義関数churnGroupEvalを作成します。rqGroupEval関数実装を定義する場合、PARALLEL_ENABLE句はオプションですが、CLUSTER BY句は必須です。
最後に、churnGroupEval関数を呼び出すSELECT文を実行します。churnGroupEval関数のINP_CUR引数で、SELECT文は、R関数およびR関数に渡すデータセットのパラレル実行を使用するようにPARALLELヒントを指定します。churnGroupEval関数のINP_CUR引数は、Oracle R Enterpriseへの接続およびR関数に渡すデータストア接頭辞を指定します。OUT_QRY引数はXML形式の値を返すことを指定し、GRP_NAM引数は、グループ化列としてデータセットの状態列を使用することを指定し、EXP_NAM引数は、呼び出すR関数としてRスクリプト・リポジトリ内のmyC5.0Functionスクリプトを指定します。
例6-23 rqGroupEval関数の使用方法
BEGIN
sys.rqScriptDrop('myC5.0Function');
sys.rqScriptCreate('myC5.0Function',
'function(dat, datastorePrefix) {
library(C50)
datastoreName <- paste(datastorePrefix, dat[1, "state"], sep = "_")
dat$state <- NULL
dat$churn <- as.factor(dat$churn)
dat$area_code <- as.factor(dat$area_code)
dat$international_plan <- as.factor(dat$international_plan)
dat$voice_mail_plan <- as.factor(dat$voice_mail_plan)
mod <- C5.0(churn ~ ., data = dat, rules = TRUE)
ore.save(mod, name = datastoreName)
TRUE
}');
END;
/
CREATE OR REPLACE PACKAGE churnPkg AS
TYPE cur IS REF CURSOR RETURN CHURN_TRAIN%ROWTYPE;
END churnPkg;
/
CREATE OR REPLACE FUNCTION churnGroupEval(
inp_cur churnPkg.cur,
par_cur SYS_REFCURSOR,
out_qry VARCHAR2,
grp_col VARCHAR2,
exp_txt CLOB)
RETURN SYS.AnyDataSet
PIPELINED PARALLEL_ENABLE (PARTITION inp_cur BY HASH ("state"))
CLUSTER inp_cur BY ("state")
USING rqGroupEvalImpl;
/
SELECT *
FROM table(churnGroupEval(
cursor(SELECT * /*+ parallel(t,4) */ FROM CHURN_TRAIN t),
cursor(SELECT 1 AS "ore.connect",
'myC5.0model' AS "datastorePrefix" FROM dual),
'XML', 'state', 'myC5.0Function'));
50州とワシントンD.Cのそれぞれについて、SELECT文は、churnGroupEval表関数から州の名前と値TRUEを含むXML文字列を返します。
rqRowEval関数は、EXP_NAMパラメータで指定されているスクリプト内のR関数を実行します。INP_CURパラメータを使用して、データをR関数に渡します。PAR_CURパラメータを使用して、引数をR関数に渡すことができます。ROW_NUMパラメータは、R関数の各呼出しに渡す必要のある行数を指定します。最後のチャンクの行数は、指定した数より少なくなる可能性があります。
rqRowEval関数ではデータ・パラレル実行がサポートされており、1つ以上のRエンジンにより同じR関数(タスク)が個々の独立したデータ・チャンクで実行されます。Oracle Databaseは、データベース・サーバー・マシンで実行されるRエンジン(複数の場合もある)の管理および制御を処理し、自動的にデータをチャンク化して、パラレルで実行されるRエンジンに渡します。Oracle Databaseでは行のすべてのチャンクに対するR関数の実行完了が保証されており、完了しない場合はrqRowEval関数によってエラーが返されます。
R関数は、データベース内にSQL表として表示されるR data.frameオブジェクトを返します。OUT_QRYパラメータを使用して、返される値の形式を定義します。
構文
rqRowEval (
INP_CUR REF CURSOR IN
PAR_CUR REF CURSOR IN
OUT_QRY VARCHAR2 IN
ROW_NUM NUMBER IN
EXP_NAM VARCHAR2 IN)
パラメータ
表6-6に、rqRowEval関数のパラメータを示します。
表6-6 rqRowEval関数のパラメータ
| パラメータ | 説明 |
|---|---|
|
|
|
|
|
R関数に渡す引数値を含むカーソル。 |
|
|
次のうちの1つ。
|
|
|
R関数の各呼出しに含める行数。 |
|
|
Rスクリプト・リポジトリ内のスクリプトの名前。 |
例
例6-24では、C50パッケージを使用して、C5.0ディシジョン・ツリー・モデルを使用してチャーン・データをスコアリングします(つまり、解約傾向が高い顧客を予測します)。この例では、指定された状態からの顧客を並行してスコアリングします。この例では、例6-15の関数ore.rowApplyを呼び出した場合と同じ結果になります。
例6-24では、例6-23と同様にユーザー定義関数を作成し、その関数をRスクリプト・リポジトリに保存します。このユーザー定義関数は状態のC5.0モデルを作成し、そのモデルをデータストアに保存します。ただし、例6-24のユーザー定義関数myC5.0FunctionForLevelsは、例6-23の関数myC5.0Functionのようにas.factor関数を使用してレベルを計算するのではなく、例6-15で作成されたレベルのリストを使用します。関数myC5.0FunctionForLevelsは、値TRUEを返します。
例6-24では、例6-23と同様にPL/SQLパッケージchurnPkgおよび関数churnGroupEvalを作成します。例6-23では、文字列myC5.0modelFLを含むデータストアの名前を取得するためのカーソルを宣言してから、これらのデータソースを削除するPL/SQLブロックを実行します。次に、churnGroupEval関数を呼び出すSELECT文を実行します。churnGroupEval関数はmyC5.0FunctionForLevels関数を呼び出してC5.0モデルを生成し、それをデータストアに保存します。
例6-24では次に、myScoringFunction関数を作成してRスクリプト・リポジトリに格納します。この関数は、状態のレベルでC5.0モデルをスコアリングし、結果をdata.frameで返します。
例6-24では最後に、rqRowEval関数を呼び出すSELECT文を実行します。rqRowEval関数への入力カーソルはPARALLELヒントを使用して、使用する並列度レベルを指定します。カーソルはデータソースとしてCHURN_TEST表を指定し、マサチューセッツの行のみが含まれるように行をフィルタ処理します。処理される行はすべて同じ予測モデルを使用します。
パラメータ・カーソルはore.connect制御引数を指定して、データベース・サーバー上のOracle R Enterpriseに接続し、myScoringFunction関数へのdatastorePrefix引数とxlevelsDatastore引数の値を指定します。
OUT_QRYパラメータのSELECT文は、出力形式を指定します。ROW_NUMパラメータでは、各パラレルRエンジンで一度に処理する行数として200を指定します。EXP_NAMEパラメータでは、呼び出すR関数としてRスクリプト・リポジトリ内のmyScoringFunctionを指定します。
例6-24 rqRowEval関数の使用方法
BEGIN
sys.rqScriptDrop('myC5.0FunctionForLevels');
sys.rqScriptCreate('myC5.0FunctionForLevels',
'function(dat, xlevelsDatastore, datastorePrefix) {
library(C50)
state <- dat[1,"state"]
datastoreName <- paste(datastorePrefix, dat[1, "state"], sep = "_")
dat$state <- NULL
ore.load(name = xlevelsDatastore) # To get the xlevels object.
for (j in names(xlevels))
dat[[j]] <- factor(dat[[j]], levels = xlevels[[j]])
c5mod <- C5.0(churn ~ ., data = dat, rules = TRUE)
ore.save(c5mod, name = datastoreName)
TRUE
}');
END;
/
CREATE OR REPLACE PACKAGE churnPkg AS
TYPE cur IS REF CURSOR RETURN CHURN_TEST%ROWTYPE;
END churnPkg;
/
CREATE OR REPLACE FUNCTION churnGroupEval(
inp_cur churnPkg.cur,
par_cur SYS_REFCURSOR,
out_qry VARCHAR2,
grp_col VARCHAR2,
exp_txt CLOB)
RETURN SYS.AnyDataSet
PIPELINED PARALLEL_ENABLE (PARTITION inp_cur BY HASH ("state"))
CLUSTER inp_cur BY ("state")
USING rqGroupEvalImpl;
/
DECLARE
CURSOR c1
IS
SELECT dsname FROM rquser_DataStoreList WHERE dsname like 'myC5.0modelFL%';
BEGIN
FOR dsname_st IN c1
LOOP
rqDropDataStore(dsname_st.dsname);
END LOOP;
END;
SELECT *
FROM table(churnGroupEval(
cursor(SELECT * /*+ parallel(t,4) */ FROM CHURN_TEST t),
cursor(SELECT 1 AS "ore.connect",
'myXLevels' as "xlevelsDatastore",
'myC5.0modelFL' AS "datastorePrefix" FROM dual),
'XML', 'state', 'myC5.0FunctionForLevels'));
BEGIN
sys.rqScriptDrop('myScoringFunction');
sys.rqScriptCreate('myScoringFunction',
'function(dat, xlevelsDatastore, datastorePrefix) {
library(C50)
state <- dat[1, "state"]
datastoreName <- paste(datastorePrefix, state, sep = "_")
dat$state <- NULL
ore.load(name = xlevelsDatastore) # To get the xlevels object.
for (j in names(xlevels))
dat[[j]] <- factor(dat[[j]], levels = xlevels[[j]])
ore.load(name = datastoreName)
res <- data.frame(pred = predict(c5mod, dat, type = "class"),
actual= dat$churn,
state = state)
res
}');
END;
/
SELECT * FROM table(rqRowEval(
cursor(select /*+ parallel(t, 4) */ *
FROM CHURN_TEST t
WHERE "state" = 'MA'),
cursor(SELECT 1 as "ore.connect",
'myC5.0modelFL' as "datastorePrefix",
'myXLevels' as "xlevelsDatastore"
FROM dual),
'SELECT ''aaa'' "pred",''aaa'' "actual" , ''aa'' "state" FROM dual',
200, 'myScoringFunction'));
Oracle SQL Developerでの最後のSELECT文の結果は次のようになります。
pred actual state ---- ------ ----- no no MA no no MA no no MA no no MA no no MA no no MA no no MA no yes MA yes yes MA yes yes MA no no MA no no MA no no MA no no MA no no MA no no MA yes yes MA no no MA no no MA no no MA no no MA no no MA no no MA no no MA no no MA no no MA no no MA no no MA no no MA no no MA no yes MA no no MA no no MA no no MA yes yes MA no no MA no no MA no no MA 38 rows selected
rqTableEval関数は、EXP_NAMパラメータで指定されているスクリプト内のR関数を実行します。INP_CURパラメータを使用して、データをR関数に渡します。PAR_CURパラメータを使用して、引数をR関数に渡すことができます。
R関数は、データベース内にSQL表として表示されるR data.frameオブジェクトを返します。OUT_QRYパラメータを使用して、返される値の形式を定義します。
構文
rqTableEval (
INP_CUR REF CURSOR IN
PAR_CUR REF CURSOR IN
OUT_QRY VARCHAR2 IN
EXP_NAM VARCHAR2 IN)
パラメータ
表6-7に、rqTableEval関数のパラメータを示します。
表6-7 rqTableEval関数のパラメータ
| パラメータ | 説明 |
|---|---|
|
|
|
|
|
入力関数に渡す引数値を含むカーソル。 |
|
|
次のうちの1つ。
|
|
|
Rスクリプト・リポジトリ内のスクリプトの名前。 |
例
例6-25の最初にあるPL/SQLブロックでは、スクリプトmyNaiveBayesModelがRスクリプト・リポジトリに存在しないように、このスクリプトを削除します。次に、関数を作成して、それをスクリプトmyNaiveBayesModelとしてリポジトリに格納します。
このR関数は、2つの引数(操作対象のデータおよびデータストアの名前)を受け入れます。この関数は、irisデータセットに基づいてNaive Bayesモデルを構築します。Naive Bayesはe1071パッケージ内にあります。
myNaiveBayesModel関数はe1071パッケージをロードして、データベース・サーバーのRエンジンで関数が実行されるときにその関数本体がe1071パッケージにアクセスできるようにします。data.frame内のファクタはユーザー定義の埋込みR関数にロードされるときに文字列ベクターに変換されるため、myNaiveBayesModel関数は明示的に文字ベクターをRファクタに変換します。
myNaiveBayesModel関数は指定された列からデータを取得した後、モデルを作成してデータストアに保存します。R関数は、関数の実行結果として表示可能な単純な値を持つためにTRUEを返します。
例6-25では次に、rqTableEval関数を呼び出すSELECT文を実行します。churnGroupEval関数のINP_CUR引数で、SELECT文は、R関数に渡すデータセットを指定します。データは、ore.create(iris, "IRIS")の呼出しによって作成されたIRIS表から取得されます(この例には示していません)。rqTableEval関数のINP_CUR引数は、R関数に渡すデータストアの名前を指定し、ユーザー定義のR関数の埋込みRの実行中にデータベースへのOracle R Enterprise接続を確立するためのore.connect制御引数を指定します。OUT_QRY引数はXML形式の値を返すことを指定し、EXP_NAM引数は、呼び出すR関数としてRスクリプト・リポジトリ内のmyNaiveBayesModelスクリプトを指定します。
例6-25 rqTableEval関数の使用方法
BEGIN
sys.rqScriptDrop('myNaiveBayesModel');
sys.rqScriptCreate('myNaiveBayesModel',
'function(dat, datastoreName) {
library(e1071)
dat$Species <- as.factor(dat$Species)
nbmod <- naiveBayes(Species ~ ., dat)
ore.save(nbmod, name = datastoreName)
TRUE
}');
END;
/
SELECT *
FROM table(rqTableEval(
cursor(SELECT * FROM IRIS),
cursor(SELECT 'myNaiveBayesDatastore' "datastoreName",
1 as "ore.connect" FROM dual),
'XML', 'myNaiveBayesModel'));
SELECT文は、rqTableEval表関数から値TRUEを含むXML文字列を返します。
次のSELECT文に示すとおり、myNaiveBayesDatastoreデータソースが生成され、オブジェクトnbmodがこのデータソースに存在しています。
SQL> SELECT * from rquser_DataStoreContents 2 WHERE dsname = 'myNaiveBayesDatastore'; DSNAME OBJNAME CLASS OBJSIZE LENGTH NROW NCOL --------------------- ------- ---------- ------- ------ ---- ---- myNaiveBayesDatastore nbmod naiveBayes 1485 4
次のように、ローカルのRセッションでモデルをロードして表示できます。
R> ore.load("myNaiveBayesDatastore")
[1] "nbmod"
R> nbmod
$apriori
Y
setosa versicolor virginica
50 50 50
$tables
$tables$Sepal.Length
Sepal.Length
Y [,1] [,2]
setosa 5.006 0.3524897
versicolor 5.936 0.5161711
virginica 6.588 0.6358796
$tables$Sepal.Width
Sepal.Width
Y [,1] [,2]
setosa 3.428 0.3790644
versicolor 2.770 0.3137983
virginica 2.974 0.3224966
$tables$Petal.Length
Petal.Length
Y [,1] [,2]
setosa 1.462 0.1736640
versicolor 4.260 0.4699110
virginica 5.552 0.5518947
$tables$Petal.Width
Petal.Width
Y [,1] [,2]
setosa 0.246 0.1053856
versicolor 1.326 0.1977527
virginica 2.026 0.2746501
$levels
[1] "setosa" "versicolor" "virginica"
$call
naiveBayes.default(x = X, y = Y, laplace = laplace)
attr(,"class")
[1] "naiveBayes"