| Siebel CRM Performance Tuning Guide Siebel Innovation Pack 2015, Rev. A E54321_01 |
|


 Previous |
 Next |
View PDF |
| Siebel CRM Performance Tuning Guide Siebel Innovation Pack 2015, Rev. A E54321_01 |
|
Previous |
Next |
View PDF |
This chapter describes recommended guidelines for improving the performance of Siebel EIM. It contains the following topics:
Siebel Enterprise Integration Manager (Siebel EIM) is a server component in the Siebel EAI component group that transfers data between the Siebel database and other corporate data sources. This exchange of information is accomplished through intermediary tables called EIM tables. (In earlier releases, EIM tables were known as interface tables.) The EIM tables act as a staging area between the Siebel application database and other data sources.
Siebel EIM is your primary method of loading mass quantities of data into the Siebel database. Use Siebel EIM to perform bulk imports, updates, merges, and deletes of data. For more information about Siebel EIM, see Siebel Enterprise Integration Manager Administration Guide.
In the Siebel database, there are application tables (known as base tables), which Siebel Business Applications use. For data to come from other corporate data sources (external databases) into Siebel application tables, the data must go through EIM tables. So, the data exchanges between the Siebel database and external databases occurs in two phases:
Load data into EIM tables.
Run Siebel EIM to import the data from the EIM tables into the Siebel base tables.
|
Note: While the first phase of this data-exchange process involves the intermediary tables that are called EIM tables, only the second phase involves the functionality of Siebel EIM. |
When data is entered through the Siebel user interface, the application references properties that are set at the business component object type. However, when data is entered into Siebel base tables through Siebel EIM, EIM references properties that are set at the table object type.
|
Note: You must use Siebel EIM to perform bulk imports, exports, merges, and deletes, because it is not supported to use native SQL to load data directly into Siebel base tables (the tables targeted to receive the data). Additionally, be aware that Siebel EIM translates empty strings into NULL. |
You must consider the size and complexity of the implementation before executing any single item with the Siebel application. Aspects that have a direct impact on how the production application will perform might not be your highest priority when you begin your Siebel implementation. However, the decisions made during the initial phases of an implementation have a far reaching impact, not only on performance and scalability but also on the overall maintenance of the Siebel application.
It is strongly recommended to have a Siebel certified principal consultant or architecture specialist from Oracle Advanced Customer Services involved in designing the most effective logical and physical architecture for your organization. This includes capacity planning and system sizing, physical database layout, and other key architecture items. Contact your Oracle sales representative to request assistance from Oracle Advanced Customer Services.
For more information, see the following:
This topic is part of "Siebel EIM Architecture Planning Requirements".
One of the most important factors to determine about the database is its overall size. During the planning phase, you need to allocate space for system storage, rollback segments and containers, temporary storage space, log files, and other system files required by the relational database management system (RDBMS), as well as space for the Siebel application data and indexes. If you allocate too little space for the system, then performance will be affected and, in extreme cases, the system itself can be halted.
The space needed by the database depends on the total number and types of supported users. It is recommended that you consult your vendor RDBMS technical documentation for more information about these requirements.
The space required for Siebel data and indexes depends on the functionality being implemented and the amount and nature of data supporting this functionality.
The process for making accurate database size calculations is a complex one involving many variables. Use the following guidelines:
Determine the total number, and types, of users of Siebel Business Applications (for example, 500 sales representatives and 75 sales managers).
Determine the functionality that you will implement and the entities required to support them. Typically, the largest entities are as follows:
Accounts
Activities
Contacts
Forecasts
Opportunities
Service Requests
Estimate the average number of entities per user (for example, 100 accounts per sales representative) and calculate an estimated total number of records per entity for the total user base.
Using standard sizing procedures for the specific database, and Siebel Data Model Reference on My Oracle Support (Article ID 1572379.1), calculate the average record size per entity and multiply by the total number of records. Typically, these entities span multiple physical tables, all of which must be included in the row size calculation. This determines the estimated data sizes for the largest entities.
You must add additional space for the storage of other Siebel application data. A rough guideline for this additional amount would be one-half the storage required for these key entities.
Indexes typically require approximately the same amount of space as data.
Be sure to allow for a margin of error in the total size calculation.
Be sure to factor growth rates into the total size calculation.
This topic is part of "Siebel EIM Architecture Planning Requirements".
The overall performance of Siebel Business Applications largely depends on the input/output (I/O) performance of the database server. To achieve optimal I/O performance, it is critical that the tables and indexes in the database be arranged across available disk devices in a manner that evenly distributes the I/O load.
The mechanism for distributing database objects varies by RDBMS, depending on the manner in which storage space is allocated. Most databases have the ability to assign a given object to be created on a specific disk. These objects, and guidelines for some of them, are provided in the following list.
A redundant array of independent disks, or RAID, can provide large amounts of I/O throughput and capacity, while appearing to the operating system and RDBMS as a single large disk (or multiple disks, as desired, for manageability). The use of RAID can greatly simplify the database layout process by providing an abstraction layer above the physical disks while ensuring high performance.
Regardless of the implemented RDBMS and the chosen disk arrangement, be sure that you properly distribute the following types of database objects:
Database log or archive files.
Temporary workspace used by the database.
Tables and Indexes: In most implementations, the tables and corresponding indexes in the following list tend to be some of the more heavily used and must be separated across devices. In general, the indexes listed in Table 10-1 must be placed on different physical devices from the tables on which they are created.
Table 10-1 Indexes Recommended to Be Placed on Different Physical Devices
| Table Name | Table Name |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Note: If you plan on making extensive use of Siebel EIM, then put the key EIM tables (based on the unique business requirements) and their corresponding indexes on different devices from the Siebel base tables and indexes, because all of them are accessed simultaneously during Siebel EIM operations. |
This topic provides several general guidelines for effective and efficient implementations of Siebel EIM, regardless of the size of the overall Siebel implementation. You must take a strategic perspective when implementing Siebel EIM to make sure that your deployment is successful.
For more information, see the following:
This topic is part of "Siebel EIM Usage Planning".
Based on customer experience, it is recommended that a team of individuals be assigned to manage and maintain the Siebel EIM processes required for your organization. Consider using individuals with the following skill sets:
For small to medium-sized Siebel Business Applications implementations:
A database administrator with a detailed understanding of not only the RDBMS used by your organization, but also the Siebel Data Model. This individual would be responsible for identifying the actual data to be loaded into the EIM tables and making sure that the physical layout of the database provides optimal performance. This person would also be responsible for the task of mapping the data into the Siebel base tables. For more information about performing this task, see Siebel Enterprise Integration Manager Administration Guide.
A system administrator with a strong background in the systems used by your organization. This individual would be responsible for developing scripts unique to your organization to automate the loading of data into the EIM tables, and to execute Siebel EIM in order to process the data into the Siebel base tables.
|
Note: Your organization might have one individual with both these skill sets and so you might rather dedicate only a single individual to these tasks. If this is the case, then consider having a backup person, so that when this primary individual is unavailable, the backup person is capable of performing what needs to be done to keep the Siebel implementation operational. |
For larger to very large-sized Siebel implementations:
A database administrator with a detailed understanding of not only the RDBMS used by your organization, but also the Siebel Data Model. This individual would be responsible for identifying the actual data to be loaded into the EIM tables and for making sure that the physical layout of the database provides optimal performance. This team member would also be responsible for the crucial task of mapping the data into the Siebel base tables. For more information about performing this task, see Siebel Enterprise Integration Manager Administration Guide.
A system administrator with a strong background in the systems (both the database server and application server) used by your organization. This individual would be responsible for developing scripts unique to your organization to automate the loading of data into the EIM tables, and to execute Siebel EIM in order to process the data into the Siebel base tables.
A business analyst with a strong understanding of the Siebel Data Model and its intended usage in the Siebel implementation. This individual would act as a liaison between the business and technical members of the Siebel EIM team.
This topic is part of "Siebel EIM Usage Planning".
Siebel EIM uses EIM table mappings to map columns from EIM tables to Siebel base tables. Predefined Siebel EIM mappings are fixed and cannot be remapped.
|
Note: Siebel EIM uses only EIM table mappings to determine table relationships. Siebel EIM does not use configuration logic in the Siebel repository to determine table relationships. |
Using Siebel Tools, you can view:
Mappings of EIM tables to Siebel base tables
Mappings of EIM table columns to Siebel base table columns
Mappings of Siebel base tables to EIM tables
Mappings of Siebel base table columns to EIM table columns
Some base tables might not be mapped to a corresponding EIM table. In such cases, use Siebel Visual Basic (VB) to load data into these base tables and inform Global Customer Support regarding the missing mapping. For information about using Siebel VB, see Siebel VB Language Reference.
If you have licensed Database Extensibility and created extensions, you can use the Column Mapping screen to specify mappings to the new fields. Database Extensibility and Siebel EIM support mappings between columns in extension tables and in EIM tables only if these columns share the same base table. To map EIM table extensions to base table extensions, you must specify which column the extended field will point to in the base table. For more information about Database Extensibility, see Configuring Siebel Business Applications.
|
Caution: Manually mapping new extension columns to columns in EIM tables presents risks of errors during Siebel EIM execution. Whether or not you have licensed Database Extensibility, it is strongly recommended for you to request an EIM Data Mapping and Design review or other assistance from Oracle Advanced Customer Services to help you perform the necessary tasks. This review can be used to make sure that the EIM mappings are correct and will accomplish intended goals. Contact your Oracle sales representative to request assistance from Oracle Advanced Customer Services. |
To map data into a Siebel application
Determine which Siebel base table columns need to be populated for the Siebel implementation, along with the external data that will be loaded into these base tables.
Determine which EIM table and columns will be used to import from the source to the destination.
Analyze this external data to determine which attributes need to be stored and the relationship this data has to other entities.
This topic is part of "Siebel EIM Usage Planning".
Fully and completely testing Siebel EIM processes must not be overlooked. Testing is more than simply mapping the data and then running a Siebel EIM process using the default Siebel EIM configuration file. Complete testing requires you to run a large number of identical Siebel EIM jobs with similar data. Testing in this way allows you to not only find areas that you might have overlooked, but also provides some insight into optimal sizing of the Siebel EIM batches and exposure to scenarios that can occur in a production environment.
Before using Siebel EIM, a database administrator must populate the EIM tables with data to be processed by Siebel EIM. Then, you can invoke Siebel EIM to process this data, with Siebel EIM making multiple passes through the tables to complete the specified process.
Siebel EIM reads a special configuration file that specifies the Siebel EIM process to perform (import, merge, delete, or export) and the appropriate parameters. The Siebel EIM configuration file (the default file is default.ifb) is an ASCII text file of extension type .IFB that resides in the admin subdirectory under the Siebel Server directory. Before running a Siebel EIM process, you must edit the contents of the Siebel EIM configuration file to define the processes that Siebel EIM will perform.
The Siebel EIM log file can contain information at different levels of detail, depending on the values of three flags: the Error flag, the SQL flag, and the Trace flag. For more information about these flags, see Siebel Enterprise Integration Manager Administration Guide. Some of the recommended settings are described in the following list:
As a starting point, it is recommended to set the Error flag = 1, the SQL flag = 1, and the Trace flag = 1. These settings will show errors and unused foreign keys. Setting the Trace flag = 1 will provide a summary (after each batch) of the elapsed time after Siebel EIM updates primary child relationships in the Siebel database tables as necessary and runs optional miscellaneous SQL statements.
Set the Error flag = 1, the SQL flag = 8, and the Trace flag = 3. These settings will produce a log file with SQL statements that include how long each statement took, which is useful for optimizing SQL performance.
Set the Error flag = 0, the SQL flag = 0, and the Trace flag = 1. These settings will produce a log file showing how long each Siebel EIM step took, which is useful when figuring out the optimal batch size, as well as useful for monitoring any performance deterioration in a particular step.
The following guidelines are recommended for improving Siebel EIM performance:
Verify that all indexes exist for the tables involved. Keep in mind, however, that for large loads you must drop most of the indexes from the target tables to increase the speed of the process, rebuilding those indexes afterward when the process is finished.
In some cases, custom indexes might be necessary on EIM tables or base tables, to expedite processing and reduce elapsed time.
Limit tables and columns to be processed using ONLY BASE TABLES/COLUMNS configuration parameters to minimize Siebel EIM processing.
Set the system preference that enables transaction logging during the initial database load. This setting (in the Administration - Siebel Remote screen, and Remote System Preferences view) is a check box labeled Enable Transaction Logging. This setting reduces transaction activity to the Siebel docking tables, which are used for synchronizing mobile clients
Consider disabling transaction logging during the Siebel EIM run. Turning off transaction logging improves performance; however, this benefit must be balanced with the need for mobile users to reextract afterward.
Altering batch sizes to find the optimal batch size for a given business component typically helps resolve performance issues. The batch size is dependent upon the quantity of data and which type of Siebel EIM process that you are running.
|
Note: Although the limit of rows that you can process is directly related to the capabilities of your database server, executing batches greater than 100,000 rows is strongly discouraged. |
For Siebel EIM delete processes that use the DELETE EXACT parameter, use a batch size of 20,000 rows or less.
Try using batch ranges (BATCH = X-Y). This allows you to run with smaller batch sizes and avoid the startup overhead on each batch. The maximum number of batches that you can run in a Siebel EIM process is 1,000.
Perform regular table maintenance on EIM tables. Frequent insert or delete operations on EIM tables can cause fragmentation. Consult your database administrator to detect and correct fragmentation in the EIM tables.
Delete batches from EIM tables on completion. Leaving old batches in the EIM table wastes space and could adversely affect performance.
Run independent Siebel EIM jobs in parallel.
Set the USING SYNONYMS parameter to FALSE in the .IFB file to indicate that account synonyms do not need to be checked.
If no other strategy appears to be successful, then use the SQLPROFILE parameter to identify slow-running steps and queries. For more information, see "Using the SQLPROFILE Parameter".
The following sequence is recommended for implementing Siebel EIM processes:
Customize and test the .IFB file to meet the business requirements.
Tune the .IFB file parameters.
Separate the Siebel EIM processes.
Set the database parameters, making sure that the basic requirements are met, including the hardware, the settings, and no or minimal fragmentation.
Before you start optimizing Siebel EIM processes, make sure there are no network problems or server performance problems that can affect the results. Oracle Advanced Customer Services recommends using at least 100 MB network segments and network-interface cards (NICs) to connect the Siebel Server and the Siebel database, and also recommends using a network switch or similar technology, rather than a hub, to maximize throughput. Contact your Oracle sales representative to request assistance from Oracle Advanced Customer Services.
This topic contains the following information:
This topic is part of "Recommended Sequence for Implementing Siebel EIM Processes".
When you have finished coding and testing the .IFB file to meet your business requirements, the next step is to optimize the .IFB file. The selected parameters in each section of the .IFB file determine the focus of each Siebel EIM task. The following recommendations are provided for each section of the .IFB file:
ONLY BASE TABLES or IGNORE BASE TABLES. These parameters specify and restrict the selected base tables for the Siebel EIM process. A single EIM table (sometimes referred to as an interface table) is mapped to multiple user or base tables. For example, the table EIM_ACCOUNT is mapped to S_PARTY, S_ORG_EXT, and S_ADDR_ORG, as well as other tables. The default configuration is to process all base tables for each EIM table.
|
Note: Oracle Advanced Customer Services strongly recommends that you always include these parameters in every section of the .IFB file, and list only those tables and columns that are relevant for a particular Siebel EIM task. Contact your Oracle sales representative to request assistance from Oracle Advanced Customer Services. |
ONLY BASE COLUMNS or IGNORE BASE COLUMNS. These parameters specify and restrict the selected base columns for the Siebel EIM process. The default is to process all base columns for each base table. It is likely that you are not using every column in a base table, and these parameters will make sure that Siebel EIM is only processing the desired columns in the table.
You will see an additional performance increase if you exclude those columns that are defined as foreign keys (FKs) and are not used by the Siebel configuration, because Siebel EIM does not need to perform the interim processing (using SQL statements) to resolve the values for these FKs. Set the Siebel EIM task parameter Error Flags to a value of 1 to see which FKs are failing to be resolved by Siebel EIM (you might have missed excluding that FK with this parameter).
|
Note: Do not use theIGNORE BASE COLUMNS parameter for merge processes or export processes. Use this parameter only for import processes and delete processes. |
This topic is part of "Recommended Sequence for Implementing Siebel EIM Processes".
One method to find out whether the .IFB file is optimized is to check the status of the records being processed in the EIM tables. This indicates if there are tables or columns that are being processed unnecessarily. The following query can be used to check the status of records in an EIM table:
select count(*), IF_ROW_STAT from EIM Table
where IF_ROW_BATCH_NUM = ?
group by IF_ROW_STAT;
If many rows have a status of PARTIALLY IMPORTED, then it is likely that further tuning can be done by excluding base tables and columns that are not necessary. For example, two tests were run to import 5000 accounts from EIM_ACCOUNT table. The first test included all of the base tables while the second test only focused on the four necessary tables by including the following line in the .IFB file:
ONLY BASE TABLES = S_ORG_EXT, S_ADDR_ORG, S_ACCNT_POSTN, S_ORG_TYPE
The first test took 89 minutes to import (excluding the Updating Primaries step), while the second test only took 2 minutes to import (excluding the Updating Primaries step).
This topic is part of "Recommended Sequence for Implementing Siebel EIM Processes".
Wherever possible, divide the Siebel EIM batches into insert-only transactions and update-only transactions. For example, assume that you are loading 50,000 records into an EIM table as part of a weekly process. 10,000 records represent new data and 40,000 records represent updates to existing data.
By default, Siebel EIM can determine which records are to be added and which records are to be updated in the base tables, however, Siebel EIM will need to perform additional processing (through SQL statements) to make these determinations. If you were able to divide the 50,000 records into different batch numbers based on the type of transaction, then you could avoid this additional processing.
In addition, the columns being processed as part of the update activity might be fewer than those for the insert activity (resulting in an additional performance increase). To illustrate this, the .IFBs in the preceding example can be coded with the following sections:
.IFB for mixed transactions:
[Weekly Accounts] TYPE = IMPORT BATCH = 1-10 TABLE = EIM_ACCOUNT ONLY BASE TABLES = S_ORG_EXT IGNORE BASE COLUMNS = S_ORG_EXT.?
.IFB for separate insert or update transactions:
[Weekly Accounts – New] TYPE = IMPORT BATCH = 1-2 TABLE = EIM_ACCOUNT ONLY BASE TABLES = S_ORG_EXT IGNORE BASE COLUMNS = S_ORG_EXT.? INSERT ROWS = TRUE UPDATE ROWS = FALSE [Weekly Accounts – Existing] TYPE = IMPORT BATCH = 3-10 TABLE = EIM_ACCOUNT ONLY BASE TABLES = S_ORG_EXT ONLY BASE COLUMNS = S_ORG_EXT.NAME, S_ORG_EXT.LOC, S_ORG_EXT.? INSERT ROWS = FALSE UPDATE ROWS = TRUE
Before troubleshooting performance issues that are specific to Siebel EIM, verify that there are no performance bottlenecks on the Siebel Server computer or on the network. This topic contains the following information:
"Using the USE INDEX HINTS and USE ESSENTIAL INDEX HINTS Parameters"
"Using USE INDEX HINTS and USE ESSENTIAL INDEX HINTS: Example"
"Using USE INDEX HINTS and USE ESSENTIAL INDEX HINTS: Criteria for Passing Indexes to the Database"
"Using the NUM_IFTABLE_LOAD_CUTOFF Extended Parameter with Siebel EIM"
This topic is part of "Troubleshooting Siebel EIM Performance".
During this process, you need to be able to run several similar batches. If you do not have enough data with which to experiment, then you might need to back up and restore the database between runs, so that you can continue processing the same batch.
First, run a Siebel EIM job with the following flag settings: Error flag = 1, SQL flag = 8, and Trace flag = 3. This will produce a log file that contains SQL statements and shows how long each statement took. Identify SQL statements that are taking too long (on a run of 5000 rows in a batch, look for statements that took longer than one minute). These are the statements that you want to concentrate on, and it is recommended that you consult an experienced database administrator at this point. The process of optimizing the SQL for Siebel EIM involves the following:
Use the respective database vendor's utility or a third-party utility to analyze the long-running SQL statements.
Based on the review of the data access paths, review the SQL statements for proper index usage. There might be cases where an index is not used at all or the most efficient index is not being chosen. This can require a thorough analysis.
Based on this analysis, use a systematic approach to tuning these long-running statements. Perform one change at a time and measure the results of each change by comparing them to the initial benchmarks. For example, you might find that dropping a particular index to improve the performance of one long-running statement might negatively impact the performance of other SQL statements.
Base the decision of whether to drop the index on the impact to the overall process, as opposed to the individual long-running SQL statement. For this reason, it is important that one change be implemented at a time in order to measure the impact of the change.
After repetitively going through and optimizing each long-running SQL statement, the focus can be shifted to other tuning measures, such as increasing the number of records processed in the EIM table at a time and the running of parallel Siebel EIM tasks.
This topic is part of "Troubleshooting Siebel EIM Performance".
Perform testing with the .IFB file parameters USE INDEX HINTS and USE ESSENTIAL INDEX HINTS, trying both settings (TRUE and FALSE). The default value for USE INDEX HINTS is FALSE. The default value for USE ESSENTIAL INDEX HINTS is TRUE.
|
Note: If your configuration file has more than one process section, then you must specifyUSE INDEX HINTS within each one. |
If these parameters are set to FALSE, then Siebel EIM does not generate hints during processing. By setting the value to FALSE, you can realize performance gains if the TRUE setting means that hints are being generated that direct the database optimizer to use less than optimal indexes. Siebel EIM processing must be tested with both the TRUE and FALSE settings to determine which one provides better performance for each of the respective Siebel EIM jobs.
|
Note: TheUSE INDEX HINTS parameter is applicable only for Oracle Database. The USE ESSENTIAL INDEX HINTS parameter is applicable only for Oracle Database and Microsoft SQL Server. |
These two parameters work for different queries, so you have to enable both to get all of the index hints on Oracle Database.
Further information is provided as follows:
This topic is part of "Troubleshooting Siebel EIM Performance".
See also:
"Using the USE INDEX HINTS and USE ESSENTIAL INDEX HINTS Parameters"
"Using USE INDEX HINTS and USE ESSENTIAL INDEX HINTS: Criteria for Passing Indexes to the Database"
The example in Table 10-2 illustrates the results achieved for an SQL statement with index hints and without index hints. This example was performed on the Microsoft SQL Server platform.
Table 10-2 Example Results for SQL Statement With and Without Index Hints
| SQL User Name | CPU | Reads | Writes | Duration | Connection ID | SPID |
|---|---|---|---|---|---|---|
|
|
549625 |
38844200 |
141321 |
626235 |
516980 |
9 |
UPDATE dbo.S_ASSET5_FN_IF SET T_APPLDCVRG__RID = (SELECT MIN(BT.ROW_ID) FROM dbo.S_APPLD_CVRG BT (INDEX = S_APPLD_CVRG_U2) WHERE (BT.COVERAGE_CD = IT.CVRG_COVERAGE_CD AND BT.TYPE = IT.CVRG_TYPE AND BT.ASSET_ID = IT.T_APPLDCVRG_ASSETI AND (BT.ASSET_CON_ID = IT.T_APPLDCVRG_ASSETC OR (BT.ASSET_CON_ID IS NULL AND IT.T_APPLDCVRG_ASSETC IS NULL)) AND (BT.INSITEM_ID = IT.T_APPLDCVRG_INSITE OR (BT.INSITEM_ID IS NULL AND IT.T_APPLDCVRG_INSITE IS NULL)))) FROM dbo.S_ASSET5_FN_IF IT WHERE (CVRG_COVERAGE_CD IS NOT NULL AND CVRG_TYPE IS NOT NULL AND T_APPLDCVRG_ASSETI IS NOT NULL AND IF_ROW_BATCH_NUM = 10710001 AND IF_ROW_STAT_NUM = 0 AND T_APPLDCVRG__STA = 0) SET STATISTICS PROFILE ON GO SET STATISTICS IO ON GO select (SELECT MIN(BT.ROW_ID) FROM dbo.S_APPLD_CVRG BT (INDEX = S_APPLD_CVRG_U2) WHERE (BT.COVERAGE_CD = IT.CVRG_COVERAGE_CD AND BT.TYPE = IT.CVRG_TYPE AND BT.ASSET_ID = IT.T_APPLDCVRG_ASSETI AND (BT.ASSET_CON_ID = IT.T_APPLDCVRG_ASSETC OR (BT.ASSET_CON_ID IS NULL AND IT.T_APPLDCVRG_ASSETC IS NULL)) AND (BT.INSITEM_ID = IT.T_APPLDCVRG_INSITE OR (BT.INSITEM_ID IS NULL AND IT.T_APPLDCVRG_INSITE IS NULL)))) FROM dbo.S_ASSET5_FN_IF IT WHERE (CVRG_COVERAGE_CD IS NOT NULL AND CVRG_TYPE IS NOT NULL AND T_APPLDCVRG_ASSETI IS NOT NULL AND IF_ROW_BATCH_NUM = 10710001 AND IF_ROW_STAT_NUM = 0 AND T_APPLDCVRG__STA = 0)
This topic is part of "Troubleshooting Siebel EIM Performance". It explains how Siebel EIM determines which indexes to include on the hint clause passed to the database when using the USE INDEX HINTS and USE ESSENTIAL INDEX HINTS parameters.
See also:
"Using the USE INDEX HINTS and USE ESSENTIAL INDEX HINTS Parameters"
"Using USE INDEX HINTS and USE ESSENTIAL INDEX HINTS: Example"
When determining which indexes to pass on to the database as index hints, Siebel EIM takes the following steps:
Before generating a query, Siebel EIM makes a list of columns for which it has determined that an index is needed.
Siebel EIM then checks all of the indexes in the repository to find the index with the most matching columns.
Siebel EIM uses the following selection criteria in choosing indexes:
Unique indexes have priority over nonunique indexes.
Required columns have priority over nonrequired columns.
If a new index is created and it is declared in the repository, then there is a chance that Siebel EIM will choose it and pass it to the database on a hint.
This topic is part of "Troubleshooting Siebel EIM Performance".
The inclusion of the SQLPROFILE parameter greatly simplifies the task of identifying the most time-intensive SQL statements. By inserting the following statement in the header section of the .IFB file, the most time-intensive SQL statements will be placed in the file:
SQLPROFILE = c:\temp\eimsql.sql
Below is an example of the file eimsql.sql.
Start of the file: list of most time-intensive queries:
EIM: Integration Manager v8.2.2.3 [23021] LANG_INDEPENDENT SQL profile dump (pid 9096).*******************************************************************************Top 100 SQL statements (of 24564) by total time:Batch Step Pass Total Rows Per Row What-------- -------- -------- -------- -------- -------- ------------------------1000 4 106 124.07 0 virtual NULL key1003 4 706 101.68 0 virtual NULL key1002 4 506 93.15 0 virtual NULL key1000 2 101 89.36 10000 0.01 default/fixed column
…list of queries continuesStatistics by step and by pass:
*******************************************************************************Statements per step by total time:Step Stmts Total Min Max Avg %-------- -------- -------- -------- -------- -------- --------9 3405 14727.44 0.00 75.80 4.33 58.104 12011 2854.16 0.01 124.07 0.24 11.262 454 2165.35 0.50 89.36 4.77 8.54
...list of statistics continues...
************************************************************************* batch 1000, step 4, pass 106: "virtual NULL key":(total time 2:04m (124s), no rows affected)UPDATE SIEBEL.EIM_CONTACTSET T_CONTACT_BU_ID = ?WHERE (CON_BI IS NULL ANDT_CONTACT_BU_ID IS NULL ANDIF_ROW_BATCH_NUM = ? ANDIF_ROW_STAT_NUM = 0 ANDT_CONTACT__STA = 0)
...list of SQL statements continues...
This topic is part of "Troubleshooting Siebel EIM Performance".
An examination of the data access path will assist you in determining whether additional indexes are necessary to improve the performance of the long-running SQL. In particular, look for table scans and large index range scans. In the following example, after evaluating the inner loop of the nested select, it was recommended to add an index on all T2 columns.
Inner loop:
(SELECT MIN(ROW_ID) FROM siebel.EIM_ACCOUNT T2 WHERE (T2.T_ADDR_ORG__EXS = 'Y' AND T2.T_ADDR_ORG__RID = T1.T_ADDR_ORG__RID AND T2.IF_ROW_BATCH_NUM = 105 AND T2.IF_ROW_STAT_NUM = 0 AND T2.T_ADDR_ORG__STA = 0))
The index was created to consist of T2 columns used in the WHERE clause with ROW_ID at the end of the index. This influenced the database optimizer to choose this index for index-only access. Since the query wants the minimum (ROW_ID), the very first qualifying page in the index will also contain the lowest value.
|
Caution: All EIM indexes must start withIF_ROW_BATCH_NUM, or else serious performance and contention issues are unavoidable. |
The S_ORG_EXT table has indexes on many columns, but not all columns. If you have a large number of records (such as several million accounts) in S_ORG_EXT, then you might get a performance improvement in deleting and merging by adding an index to one or more of the following columns:
PR_BL_OU_IDPR_PAY_OU_IDPR_PRTNR_TYPE_IDPR_SHIP_OU_ID
You can make subqueries to base tables that access only indexes. Performance is enhanced because all related records are physically collocated, and because index leaf pages contain many more records per page than wider base table pages. Before implementing any additional indexes, first discuss this with qualified support personnel.
This topic is part of "Troubleshooting Siebel EIM Performance".
On IBM DB2, you can use the .IFB file parameter UPDATE STATISTICS to control whether Siebel EIM dynamically updates the statistics of EIM tables. The default setting is TRUE. This parameter can be used to create a set of statistics on the EIM tables that you can save and then reapply to subsequent runs. After you have determined this optimal set of statistics, you can turn off the UPDATE STATISTICS parameter in the .IFB file (UPDATE STATISTICS = FALSE), thereby saving time during the Siebel EIM runs.
|
Note: It is recommended to manage statistics manually. Also note that usingUPDATE STATISTICS in IFB executes RUNSTATS in SHRLEVEL REFERENCE mode, which causes exclusive locks and can prevent parallel EIM execution. |
To determine the optimal set of statistics, you need to run several test batches and RUNSTATS commands with different options to see what produces the best results.
Before and after each test, execute the db2look utility in mimic mode to save the statistics from the database system catalogs. For example, if you are testing Siebel EIM runs using EIM_CONTACT1 in database SIEBELDB, then the following command generates UPDATE STATISTICS commands in the file EIM_CONTACT1_mim.sql:
db2look -m -a -d SIEBELDB -t EIM_CONTACT1 -o EIM_CONTACT1_mim.sql
The file EIM_CONTACT1_mim.sql contains SQL UPDATE statements to update database system catalog tables with the saved statistics. You can experiment with running test Siebel EIM batches after inserting the RUNSTATS commands provided in "IBM DB2 Options". After you find the set of statistics that works best, you can apply that particular mim.sql file to the database. Between runs, save statistics with db2look.
|
Note: Thedb2look utility runs on IBM DB2 for Linux, Unix, and Windows (most of the IBM DB2 references in this guide are to this product). On IBM DB2 for z/OS, you can use the Optimization Service Center (OSC) utility instead. For more information about using Siebel EIM with IBM DB2 for z/OS, see "IBM DB2 for z/OS and Siebel EIM". |
The syntax for IBM DB2 commands provides more options, as follows:
shrlevel change
allow write access
allow read access
The clauses allow read access and shrlevel change provide the greatest concurrency.
This topic is part of "Troubleshooting Siebel EIM Performance".
Typically, the Siebel EIM initial load is a very database-intensive process. Each row that is inserted into the base tables requires modifications on the data page and the index pages of all of the affected indexes. However, most of these indexes are never used during a Siebel EIM run. Index maintenance is very time-consuming for most database managers and must be avoided as much as possible.
Therefore, the goal is to identify any indexes that are unnecessary for Siebel EIM and that can be dropped for the durations of the Siebel EIM run. You can create these indexes later in batch mode by using parallel execution strategies available for the respective database platform. Using this approach can save a significant amount of time.
|
Note: Under normal operations, using parallel execution strategies is not recommended. |
Target Table Indexing Strategy. For a target base table (such as S_ORG_EXT), you only need to use the Primary Index (Px, for example P1) and the Unique Indexes (Ux, for example U1), and then drop the remaining indexes for the duration of the Siebel EIM import. Past experience has determined that the Fx and Mx indexes can be dropped after an extensive SQL analysis of sample Siebel EIM runs.
Nontarget Table Indexing Strategy. For child tables (such as S_ADDR_ORG), you only need to use the Primary Index (Px), the Unique Indexes (Ux), and the Foreign Key Indexes (needed for setting primary foreign keys in the parent table). Past experience has determined that the Fx and Mx indexes can be dropped after an extensive SQL analysis of sample Siebel EIM runs.
|
Note: Always perform testing when dropping indexes (or adding indexes) to make sure that the expected results are achieved. |
This topic is part of "Troubleshooting Siebel EIM Performance".
After tuning the long-running SQL statements, further tests can be run to determine the optimal batch size for each entity to be processed. The correct batch size varies and is influenced by the amount of buffer cache available. Optimal batch ranges have been observed to range anywhere between 500 and 15,000 rows. Run several tests with different batch sizes to determine the size that provides the best rate of Siebel EIM transactions per second. Using the setting Trace Flag = 1 while running Siebel EIM helps in this task because you are then able to see how long each step takes and how many rows were processed by the Siebel EIM process.
|
Note: Also monitor this throughput rate when determining degradation in parallel runs of Siebel EIM. |
For an initial load, you can use 30,000 rows for a large batch. For ongoing loads, you can use 20,000 rows for a large batch. Do not exceed 100,000 rows in a large batch.
Furthermore, for Microsoft SQL Server and Oracle Database environments, limit the number of records in the EIM tables to those that are being processed. For example, if you have determined that the optimal batch size for your implementation is 19,000 rows per batch and you are going to be running eight parallel Siebel EIM processes, then you must have 152,000 rows in the EIM table. Under no circumstances can you have more than 250,000 rows in any single EIM table because this reduces performance. The restrictions mentioned in the preceding example do not apply to IBM DB2 environments. As long as an index is being used to access the EIM tables, the numbers of rows in the EIM tables does not matter in DB2 environments.
|
Caution: For all supported RDBMS platforms, if indexes are added to EIM tables with any column other thanIF_ROW_BATCH_NUM in the first position, then parallel Siebel EIM operations performed on that table will likely fail with index contention issues. |
|
Note: The number of rows that you can load in a single batch can vary depending on your physical computer setup and on which table is being loaded. To reduce demands on resources and improve performance, generally try to vary batch sizes to determine the optimal size for each entity to be processed. In some cases, a smaller batch size can improve performance. But for simpler tables such asS_ASSET, you might find that loads perform better at higher batch sizes than for more complex tables such as S_CONTACT. |
This topic is part of "Troubleshooting Siebel EIM Performance".
Determine the number of records that can reside at one time in an EIM table while still maintaining an acceptable throughput rate during Siebel EIM processing. One observed effect of increasing the number of records in an EIM table is reduced performance of Siebel EIM jobs. This is often caused by object fragmentation or full table scans and large index range scans.
|
Note: In an IBM DB2 environment, EIM table size is not an important factor that impacts performance, because it is relatively easy to correct table scans and nonmatching index scans. So, a large number of records in an EIM table is not likely to reduce performance in a DB2 environment. |
After addressing any object fragmentation and after the long-running SQL statements have been tuned, it is likely that you can increase the number of records that can reside in the EIM tables during Siebel EIM processing. When loading millions of records, this can result in a significant time savings because it reduces the number of times that the EIM table needs to be staged with a new data set.
When performing large data loads (millions of records) it is recommended that you perform initial load tests with fewer records in the EIM table. For example, while identifying and tuning the long-running SQL, you might start with approximately 50,000 records. After tuning efforts are complete, run additional tests, while gradually increasing the number of records. For example, you can incrementally increase the number of records to 100,000, then 200,000, and so on, until you have determined the optimal number of records to load.
This topic is part of "Troubleshooting Siebel EIM Performance".
The USING SYNONYMS parameter controls the queries of account synonyms during import processing. This parameter is also related to the S_ORG_SYN table. When set to FALSE, this parameter saves processing time because queries that look up synonyms are not used. The default setting is TRUE. Set this parameter to FALSE only when account synonyms are not needed.
This topic is part of "Troubleshooting Siebel EIM Performance".
Setting the NUM_IFTABLE_LOAD_CUTOFF extended parameter to a positive value will reduce the amount of time taken by Siebel EIM to load repository information. This is because when you set this parameter to a positive value, only information for the required EIM tables is loaded. For more information about this parameter, see Siebel Enterprise Integration Manager Administration Guide.
|
Note: While this parameter is especially important for merge processes, it can also be used for any of the other types of processes. |
Here is an example of using this parameter while running on Microsoft Windows from the server command line mode:
run task for comp eim server siebserver with config=account2.ifb, ExtendedParams="NUM_IFTABLE_LOAD_CUTOFF=1", traceflags=1
This topic is part of "Troubleshooting Siebel EIM Performance".
Typically, you set the system preference that disables transaction logging only for the initial data load. This setting (in the Administration - Siebel Remote screen, and Remote System Preferences view) is a check box labeled Enable Transaction Logging. This setting specifies whether or not the Siebel application logs transactions for the purpose of routing data to Siebel Mobile Web Clients.
By default, transaction logging is enabled. If there are no Siebel Mobile Web Clients, then you can disable this system preference. If you have Siebel Mobile Web Clients, then you must enable this system preference in order to route transactions to the Siebel Mobile Web Clients. However, during initial data loads, you can disable this system preference to reduce transaction activity to the Siebel docking tables. After the initial loads are complete, enable transaction logging again.
|
Note: For incremental data loads, transaction logging must be enabled if there are mobile clients. If this setting is changed for incremental data loads, then you will need to perform a reextract of all of the mobile clients. |
This topic is part of "Troubleshooting Siebel EIM Performance".
Disabling database triggers, by removing them through the Administration - Server screens, can also help improve the throughput rate. This can be done by running the Generate Triggers server task with both the REMOVE and EXEC parameters set to TRUE. Be aware that components such as Workflow Policies and Assignment Manager will not function for the new or updated data. Also, remember to reapply the triggers after completing the Siebel EIM load.
This topic is part of "Troubleshooting Siebel EIM Performance".
Running Siebel EIM tasks in parallel is the last strategy that you might want to adopt in order to increase the Siebel EIM throughput rate. In other words, do not try this until all long-running SQL statements have been tuned, the optimal batch size has been determined, the optimal number of records to be processed at a time in the EIM table has been determined, and the database has been appropriately tuned. Before running tasks in parallel, check the value of the Maximum Tasks parameter. This parameter specifies the maximum number of running tasks that can be run at a time for a service. For more information about this parameter, see Siebel System Administration Guide.
|
Note: UPDATE STATISTICS must be set to FALSE in the .IFB file when running parallel Siebel EIM tasks on IBM DB2 for z/OS. Failure to do so can cause Siebel EIM tasks and executing RUNSTATS to take a longer time to complete. Also, when running parallel Siebel EIM tasks, deadlock and timeout will occur if UPDATE STATISTICS is set to TRUE in the .IFB file. |
This topic describes Siebel EIM tuning tips for the database platforms supported by Siebel Business Applications. It contains the following information:
This topic is part of "Database Guidelines for Optimizing Siebel EIM".
The information that follows describes Siebel EIM tuning tips for Microsoft SQL Server.
Table and index fragmentation occurs on tables that have many insert, update, and delete activities. Because the table is being modified, pages begin to fill, causing page splits on clustered indexes. As pages split, the new pages might use disk space that is not contiguous, hurting performance because contiguous pages are a form of sequential input/output (I/O), which is faster than nonsequential I/O.
Before running Siebel EIM, it is important to defragment the tables by executing the DBCC DBREINDEX command on the table's clustered index. This applies especially to those indexes that will be used during Siebel EIM processing, which packs each data page with the fill factor amount of data (configured using the FILLFACTOR option) and reorders the information on contiguous data pages. You can also drop and recreate the index (without using the SORTED_DATA option). However, using the DBCC DBREINDEX command is recommended because it is faster than dropping and recreating the index, as shown in the following example:
DBCC SHOWCONTIG scanning '**S_GROUPIF' table... Table: '**S_GROUPIF' (731969784); index ID: 1, database ID: 7 TABLE level scan performed. Pages Scanned................................: 739 Extents Scanned..............................: 93 Extent Switches..............................: 92 Avg. Pages per Extent........................: 7.9 Scan Density [Best Count:Actual Count].......: 100.00% [93:93] Logical Scan Fragmentation ..................: 0.00% Extent Scan Fragmentation ...................: 1.08% Avg. Bytes Free per Page.....................: 74.8 Avg. Page Density (full).....................: 99.08% DBCC execution completed. If DBCC printed error messages, contact the system administrator.
To determine whether you need to rebuild the index because of excessive index page splits, look at the Scan Density value displayed by DBCC SHOWCONTIG. The Scan Density value must be at or near 100%. If it is significantly below 100%, then rebuild the index.
When purging data from the EIM table, use the TRUNCATE TABLE statement. This is a fast, nonlogged method of deleting all rows in a table. DELETE physically removes one row at a time and records each deleted row in the transaction log. TRUNCATE TABLE only logs the deallocation of whole data pages and immediately frees all of the space occupied by that table's data and indexes. The distribution pages for all indexes are also freed.
Microsoft SQL Server allows data to be bulk copied into a single EIM table from multiple clients in parallel, using the bcp utility or BULK INSERT statement. Use the bcp utility or BULK INSERT statement when the following conditions are true:
SQL Server is running on a computer with more than one processor.
The data to be bulk copied into the EIM table can be partitioned into separate data files.
These recommendations can improve the performance of data load operations. Perform the following tasks, in the order in which they are presented, to bulk copy data into SQL Server in parallel:
Set the database option truncate log on checkpoint to TRUE using sp_dboption.
Set the database option select into/bulkcopy to TRUE using sp_dboption.
In a logged bulk copy all row insertions are logged, which can generate many log records in a large bulk copy operation. These log records can be used to both roll forward and roll back the logged bulk copy operation.
In a nonlogged bulk copy, only the allocations of new pages to hold the bulk copied rows are logged. This significantly reduces the amount of logging that is needed and speeds the bulk copy operation. Once you do a nonlogged operation, immediately back up so that transaction logging can be restarted.
Make sure that the table does not have any indexes, or, if the table has an index, make sure that it is empty when the bulk copy starts.
Make sure that you are not replicating the target table.
Make sure that the TABLOCK hint is specified using bcp_control with eOption set to BCPHINTS.
|
Note: Using ordered data and theORDER hint will not affect performance because the clustered index is not present in the EIM table during the data load. |
After data has been bulk copied into a single EIM table from multiple clients, any clustered index on the table must be recreated using DBCC DBREINDEX.
This is the database that Microsoft SQL Server uses for temporary space needed during execution of various queries. Set the initial size of the TEMPDB to a minimum of 100 MB, and configure it for auto-growth, which allows SQL Server to expand the temporary database as needed to accommodate user activity.
Additional parameters have a direct impact on SQL Server performance and must be set according to the following guidelines:
SPIN COUNTER. This parameter specifies the maximum number of attempts that Microsoft SQL Server will make to obtain a given resource. The default settings are adequate in most configurations.
MAX ASYNC I/O. This parameter configures the number of asynchronous inputs/outputs (I/Os) that can be issued. The default is 32, which allows a maximum of 32 outstanding reads and 32 outstanding writes per file. Servers with nonspecialized disk subsystems do not benefit from increasing this value. Servers with high-performance disk subsystems, such as intelligent disk controllers with RAM caching and RAID disk sets, can gain some performance benefit by increasing this value because they have the ability to accept multiple asynchronous I/O requests.
MAX DEGREE OF PARALLELISM. This option is used to configure Microsoft SQL Server's use of parallel query plan generation. Set this option to 1 to disable parallel query plan generation. This setting is mandatory to avoid generating an unpredictable query plan.
LOCKS. This option is used to specify the number of locks that Microsoft SQL Server allocates for use throughout the server. Locks are used to manage access to database resources such as tables and rows. Set this option to 0 to allow Microsoft SQL Server to dynamically manage lock allocation based on system requirements.
AUTO CREATE STATISTICS. This option allows SQL Server to create new statistics for database columns as needed to improve query optimization. Make sure that this option is enabled.
AUTO UPDATE STATISTICS. This allows Microsoft SQL Server to automatically manage database statistics and update them as necessary to achieve proper query optimization. Make sure that this option is enabled.
This topic is part of "Database Guidelines for Optimizing Siebel EIM".
The subtopics that follow provide Siebel EIM tuning tips for Oracle Database.
Before running Siebel EIM, consult an experienced DBA in order to evaluate the amount of space necessary to store the data to be inserted in the EIM tables and the Siebel base tables. Also, for example with Oracle Database, you can make sure that the extent sizes of those tables and indexes are defined accordingly.
Avoiding excessive extensions and keeping a small number of extents for tables and indexes is important because extent allocation and deallocation activities (such as truncate or drop commands) can be demanding on CPU resources.
To check whether segment extension is occurring in Oracle Database
Use the SQL statement that follows to identify objects with greater than 10 extents.
|
Note: Ten extents is not a target number for segment extensions. |
SELECT segment_name,segment_type,tablespace_name,extents FROM dba_segments WHERE owner = (Siebel table_owner) and extents > 10;
To reduce fragmentation, the objects can be rebuilt with appropriate storage parameters. Always be careful when rebuilding objects because of issues such as defaults or triggers on the objects.
When purging data from an EIM table, use the TRUNCATE command as opposed to the DELETE command. The TRUNCATE command releases the data blocks and resets the high water mark while the DELETE command does not, which causes additional blocks to be read during processing. Also, be sure to drop and recreate the indexes on the EIM table to release the empty blocks.
It is recommended that Archive Logging be disabled during initial data loads. You can enable this feature to provide for point-in-time recovery after completing the data loads.
Multiple Siebel EIM processes can be executed against an EIM table provided that they all use different batches or batch ranges. The concern is that you might experience contention for locks on common objects. To run multiple jobs in parallel against the same EIM table, make sure that the FREELIST parameter is set appropriately for the tables and indexes used in the Siebel EIM processing.
|
Note: If you are using Auto Segment Space Mgmt (ASSM) as part of defining tablespaces, then thePCTUSED and FREELIST parameters (and FREELIST groups) are ignored. |
Applicable database objects include EIM tables and indexes, as well as base tables and indexes. The value of the FREELIST parameter specifies the number of block IDs that will be stored in memory which are available for record insertion. Generally, you set the value to at least half of the intended number of parallel jobs to be run against the same EIM table (for example, a FREELIST setting of 10 permits up to 20 parallel jobs against the same EIM table).
This parameter is set at the time of object creation and the default for this parameter is 1. To check the value of this parameter for a particular object, the following query can be used:
SELECT SEGMENT_NAME, SEGMENT_TYPE, FREELISTS
FROM DBA_SEGMENTS
WHERE SEGMENT_NAME='OBJECT NAME TO BE CHECKED';
To change this parameter, the object must be rebuilt. Again, be careful when rebuilding objects because of issues such as defaults or triggers on the objects.
To rebuild an object
Export the data from the table with the grants.
Drop the table.
Recreate the table with the desired FREELIST parameter.
Import the data back into the table.
Rebuild the indexes with the desired FREELIST parameter.
Another method to improve performance is to put small tables that are frequently accessed in cache. The value of BUFFER_POOL_KEEP determines the portion of the buffer cache that will not be flushed by the LRU algorithm. This allows you to put certain tables in memory, which improves performance when accessing those tables. This also makes sure that, after accessing a table for the first time, it will always be kept in the memory. Otherwise, it is possible that the table will get pushed out of memory and will require disk access the next time it is used.
Be aware that the amount of memory allocated to the keep area is subtracted from the overall buffer cache memory (defined by DB_BLOCK_BUFFERS). A good candidate for this type of operation is the S_LST_OF_VAL table. The syntax for keeping a table in the cache is as follows:
ALTER TABLE S_LST_OF_VAL CACHE;
This topic is part of "Database Guidelines for Optimizing Siebel EIM". It describes Siebel EIM tuning tips for the IBM DB2 database platform.
Review the following list of tuning tips for Siebel EIM:
Use the IBM DB2 load replace option when loading EIM tables.
|
Note: You can also use the IBM DB2 load option to purge EIM tables. To do this, run the load option with an empty (null) input file inLOAD REPLACE mode. This purges the specified EIM table(s) instantly. |
Use separate tablespaces for EIM tables and the base tables.
For large Siebel EIM loads or where many Siebel EIM tasks execute in parallel, place individual EIM tables in separate tablespaces.
Use large page sizes for EIM tables and for the larger base tables. Previous experience has determined that a page size of 16 KB or 32 KB provides good performance. The larger page sizes allow more data to be fitted on a single page and also reduces the number of levels in the index B-tree structures.
Similarly, use large extent sizes for both EIM tables and the large base tables.
Make sure that the tablespace containers are equitably distributed across the logical and physical disks and across the input/output (I/O) controllers of the database server.
Use separate bufferpools for EIM tables and the target base tables. Since initial Siebel EIM loads are quite large and there are usually no online users, it is recommended to allocate a significant amount of memory to the EIM table and base table bufferpools.
After you load new data, reorganize the tables if the data on a disk is out of cluster. If the results of executing the RUNSTATS command indicate that clustering has deteriorated (clustering index is less than 80% clustered) and that a reorganization of tables is required, then check the system catalog to see if tables need to be reorganized. See also 477378.1 (Article ID) on My Oracle Support. This article contains sample SQL that you can use to determine which tables are out of cluster and need reorganization.
|
Note: Allocate time to conversion schedules to allow for the reorganization of tables and the gathering of statistics prior to allowing end users access to a system containing new data. |
Use IBM DB2 snapshot monitors to make sure that performance is optimal and to detect and resolve any performance bottlenecks.
You can turn off logretain during the initial load. However, you must turn it back on before moving into a production environment.
|
Note: When logretain is enabled, you must make a full cold backup of the database. |
For the EIM tables and the base tables involved, alter the tables to set them to VOLATILE. This makes sure that indexes are preferred over table scans.
Executing Siebel EIM processes in parallel will cause deadlock and timeout on IBM DB2 databases if multiple Siebel EIM processes attempt to update the same catalog table simultaneously. To avoid this, set the UPDATE STATISTICS parameter to FALSE in the Siebel EIM configuration file (.IFB file).
Executing UPDATE STATISTICS in each Siebel EIM process consumes significant database server resources. It is recommended that the database administrator updates statistics outside of the Siebel EIM process using the RUNSTATS command.
Consider the settings for IBM DB2 registry values in Table 10-3:
Table 10-3 IBM DB2 Registry Settings
| Registry Value | Setting |
|---|---|
|
DB2_CORRELATED_PREDICATES = |
YES |
|
DB2_HASH_JOIN = |
NO |
|
DB2_PARALLEL_IO = |
"*" |
|
DB2_STRIPPED_CONTAINERS = |
When using RAID devices for tablespace containers |
Consider the settings for the IBM DB2 database manager configuration parameters in Table 10-4:
Table 10-4 IBM DB2 Database Manager Configuration Parameter Settings
| Registry Value | Setting |
|---|---|
|
INTRA_PARALLEL = |
NO (can be used during large index creation) |
|
MAX_QUERYDEGREE = |
1 (can be increased during large index creation) |
|
SHEAPTHRES = |
100,000 (depends upon available memory, SORTHEAP setting, and other factors) |
Consider the settings for the IBM DB2 database parameters in Table 10-5:
Table 10-5 IBM DB2 Database Parameter Settings
| Registry Value | Setting |
|---|---|
|
CATALOGCACHE_SZ = |
6400 |
|
DFT_QUERYOPT = |
3 |
|
LOCKLIST = |
5000 |
|
LOCKTIMEOUT = |
120 (between 30 and 120) |
|
LOGBUFSZ = |
512 |
|
LOGFILESZ = |
8000 or higher |
|
LOGPRIMARY = |
20 or higher |
|
MAXLOCKS = |
30 |
|
MINCOMMIT = |
1 |
|
NUM_IOCLEANERS = |
Number of CPUs in the database server |
|
NUM_IOSERVERS = |
Number of disks containing DB2 containers |
|
SORTHEAP = |
10240 (This setting is only for initial Siebel EIM loads. During production, set it to between 64 and 256.) The value you specify for SORTHEAP impacts the result of changing the value for SHEAPTHRES. For example, if SORTHEAP = 10000, then you can execute no more than nine Siebel EIM batches if you set SHEAPTHRES = 100000. If executing concurrent Siebel EIM batches, then make sure to allocate sufficient physical memory so that memory swapping or memory paging do not occur. |
|
STAT_HEAP_SZ = |
8000 |
This topic is part of "Database Guidelines for Optimizing Siebel EIM".
For IBM DB2 for z/OS configuration settings, you can find a listing (from the JCL) of the Database Manager Configuration Parameters (DSNZPARM) in Implementing Siebel Business Applications on DB2 for z/OS.
More IBM DB2 for z/OS information is provided in the following topics:
This topic is part of "Database Guidelines for Optimizing Siebel EIM".
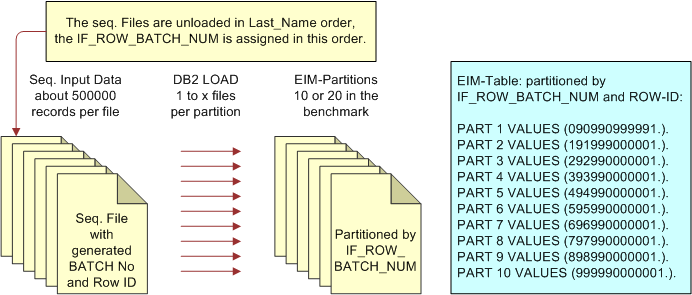
Figure 10-1 illustrates the load process for IBM DB2 for z/OS. For more information, see Siebel Enterprise Integration Manager Administration Guide.
This topic is part of "Database Guidelines for Optimizing Siebel EIM".
The following general recommendations apply when performing the IBM DB2 for z/OS loading process for Siebel EIM:
Use the ONLY BASE TABLES and IGNORE BASE TABLES parameters or ONLY BASE COLUMNS and IGNORE BASE COLUMNS parameters in the .IFB files to reduce the amount of processing performed by Siebel EIM. By using the IGNORE BASE COLUMNS option, you allow foreign keys to be excluded, which reduces both processing requirements and error log entries for keys which cannot be resolved. Remember that the key words ONLY and IGNORE are mutually exclusive. For example, the following settings exclude the options IGNORE BASE TABLES and ONLY BASE COLUMNS:
ONLY BASE TABLES = S_CONTACT IGNORE BASE COLUMNS = S_CONTACT.PR_MKT_SEG_ID
Import parents and children separately. Wherever possible, load data such as accounts, addresses, and teams at the same time, using the same EIM table.
Use batch sizes that allow all of the EIM table data in the batch to be stored in the database cache (approximately 5,000 records for IBM DB2 for z/OS). Siebel EIM can be configured through the use of an extended parameter to use a range of batches. Remember to put the variable name into the .IFB file.
Multiple Siebel EIM processes can be executed against an EIM table, provided they all use different batches or batch ranges. However, the main limit to Siebel EIM performance is not the application server but the database. Contention for locks on common objects can occur if multiple Siebel EIM streams are executed simultaneously for the same base table. Multiple Siebel EIM job streams can run concurrently for different base tables, for example, S_ORG_EXT and S_ASSET.
Run Siebel EIM during periods of minimum user activity, outside of business hours, if possible. This reduces the load for connected users and makes sure that the maximum processing capacity is available for the Siebel EIM processes.
Set the system preference that disables transaction logging during the initial database load. This setting (in the Administration - Siebel Remote screen, and Remote System Preferences view) is a check box labeled Enable Transaction Logging. Unchecking this preference reduces transaction activity to the Siebel docking tables, which are used for synchronizing mobile clients.
Disable the database triggers by removing them through the Server Administration screens. Doing this can also help to improve the throughput rate. Remember to reapply the triggers after the Siebel EIM load has completed, because the lack of triggers will mean that components, such as Workflow Policies and Assignment Manager, will not function for the new or updated data.
Make sure that the required columns ROW_ID, IF_ROW_STAT, and IF_ROW_BATCH_NUM are correctly populated in the EIM table to be processed. The most efficient time to do this is when populating the EIM table from the data source or staging area, after cleansing the data.
Unless there are specific processing requirements, make sure that the EIM table is empty before loading data into it for Siebel EIM processing. Always make sure that suitable batch numbers are being used to avoid conflicts within the EIM table. If you are using an automated routine, then truncating the EIM table between loads from the data source helps to preserve performance.
When running Siebel Business Applications on an IBM DB2 for z/OS database, Siebel EIM can sometimes stop responding when updating the S_LST_OF_VAL base table. This is due to a data issue. The BU_ID column in the S_LST_OF_VAL base table might have only one or very few distinct values. That makes the DB2 optimizer perform a table scan through all rows in the S_LST_OF_VAL table when most or all rows have the same BU_ID column value.
To avoid this problem and speed up the query, modify the statistics data by running the following SQL statements:
update sysibm.sysindexes set firstkeycard=1000 where name='S_LST_OF_VAL_M2'; update sysibm.syscolumns set colcard = 1000 where tbname='S_LST_OF_VAL' and name='BU_ID';
|
Note: Depending on the data with which you are working, you might need to run other SQL statements beforehand. |
The following recommendations apply when performing the Siebel EIM loading process:
The Siebel EIM mapping chart shows that many of the EIM table columns derive their values not from legacy database fields but from unvarying literal strings. Avoid filling up the EIM tables with this type of information, because it slows down the movement of real legacy data from the EIM tables to the base tables.
Siebel EIM offers an alternative method for populating base table columns with unvarying literal strings, namely by using the DEFAULT COLUMN statement. This approach allows you to specify default literals that must be imported into the base tables without having to retrieve them from the EIM tables.
For example, the Siebel EIM mapping chart shows Default Organization as the constant value for CON_BU in EIM_CONTACT, which in turn will move into BU_ID in S_CONTACT.
The same result can be achieved with the setting DEFAULT COLUMN = CON_BU, Default Value in the .IFB file. There are many other opportunities for moving literal strings from the EIM tables to the .IFB file.
The following recommendations are for setting run parameters when performing the Siebel EIM loading process:
Set UPDATE STATISTICS to FALSE and manually manage the statistics. The provided version of RUNSTATS that UPDATE STATISTICS calls uses SHRLEVEL REFERENCE, which will cause locking contention and other issues.
Do not set TRIM SPACES to FALSE. Using the TRIM SPACES parameter causes trailing spaces to be stored in the Siebel base table. This can lead to inefficient use of disk space since Siebel Business Applications use VarChar on virtually all text columns longer than a single character. Setting TRIM SPACES to FALSE can also waste valuable bufferpool space for the tablespace data.
Use either the IGNORE BASE TABLES parameter or the ONLY BASE TABLES parameter to limit the number of tables being inserted into or updated. The ONLY BASE TABLES parameter is preferable because the list is usually shorter and it is self-documenting. Using these parameters improves performance because it limits the number of tables that Siebel EIM attempts to load and they also save space for tables that will not be used by the user interface.
Use either the IGNORE BASE COLUMNS parameter or the ONLY BASE COLUMNS parameter to limit the number of columns being inserted into or updated. The ONLY BASE COLUMNS parameter is preferable because the list is usually shorter and it is self-documenting. Using these parameters improves performance because they limit the number of foreign keys that Siebel EIM attempts to resolve.
Set the USING SYNONYMS parameter to FALSE in the .IFB file. This logical operator indicates to Siebel EIM that account synonyms do not require processing during import, which reduces the amount of processing. Do not set the USING SYNONYMS parameter to FALSE if you plan to use multiple addresses for accounts. Otherwise, Siebel EIM will not attach addresses to the appropriate accounts.
Suppress inserts when the base table is already fully loaded and the table is the primary table for an EIM table used to load and update other tables. The command format is INSERT ROWS = table name, FALSE.
Suppress updates when the base table is already fully loaded and does not require updates such as foreign key additions, but the table is the primary table for an EIM table used to load and update other tables. The command format is UPDATE ROWS = table name, FALSE.
When you are monitoring the Siebel Server, the assumption is that you have allocated sufficient processor and memory resources for running the Siebel EIM task on the Siebel Servers and Siebel database servers.
If you are using Microsoft Windows Server as the operating system for the Siebel Server, then you can use the Microsoft Windows Performance Monitor to verify the amount of processor and memory resources being used by the hardware.
If you are using a supported UNIX or Linux operating system for the Siebel Server, then you can use vmstat and iostat to verify the amount of processor and memory resources being used by the hardware.