1 Introduction à la récupération après sinistre
Les pratiques recommandées en matière de récupération après sinistre d'ELS consistent généralement à concevoir et implémenter des systèmes matériels et logiciels résistants aux pannes qui peuvent perdurer après un sinistre ("continuité de l'activité") et reprendre un fonctionnement normal ("reprise de l'activité"), avec une intervention minimale de l'utilisateur et, idéalement, sans perte de données. La mise en place d'environnements résistants aux pannes pour répondre aux objectifs de reprise après sinistre d'ELS et les contraintes budgétaires du monde réel nécessitant du temps et de l'argent, l'entreprise doit être totalement impliquée dans ce projet.
La récupération après sinistre est généralement prévue pour répondre à un ou plusieurs des types de sinistres suivants :
-
dommages importants ou étendus subis par les installations informatiques, qui ont été provoqués par une catastrophe naturelle (tremblement de terre, tempête, inondation, etc.) ou d'autres causes (incendie, vandalisme, vol, etc.) ;
-
perte importante de services essentiels pour l'installation informatique (coupure de courant, refroidissement ou accès réseau, par exemple) ;
-
perte de personnel clé.
Le processus de planification de récupération après sinistre (DR) commence par identifier et déterminer les types de sinistres auxquels une entreprise doit faire face, ainsi que les opérations de reprise qu'elle doit mettre en place. Le processus de planification identifie les conditions de haut niveau requises en matière de continuité et de reprise de l'activité, notamment le degré nécessaire de tolérance aux pannes. Le produit de planification de la reprise après sinistre est une architecture de récupération et de reprise qui permet à des applications, des données et des systèmes tolérants aux pannes de prendre en charge ces conditions requises selon les contraintes en vigueur. La récupération après sinistre doit généralement prendre en compte les contraintes suivantes : objectif de délai de récupération (RTO), objectif du point de récupération (RPO) et budget disponible. L'architecture DR associée aux contraintes de l'activité génère des procédures de récupération après sinistre qui intègrent tous les éléments du système dans un véritable schéma "de bout en bout", afin de garantir des résultats prévisibles pour le processus global de récupération après sinistre.
Les systèmes tolérants aux pannes font généralement preuve de robustesse et de résilience grâce à la redondance. Souvent très coûteux, un système totalement redondant ne dispose pas d'un point de panne unique au sein de son architecture et peut continuer et reprendre son fonctionnement après le pire des sinistres dans la limite de ses moyens. Les systèmes de contrôle de vol et de navette spatiale constituent d'excellents exemples de systèmes totalement redondants. Les applications informatiques moins critiques utilisent généralement des systèmes moins robustes avec une redondance inférieure. Ces systèmes sont moins chers à mettre en place et impliquent nécessairement une interruption de service après des sinistres, au cours de laquelle l'entreprise s'efforce de rétablir ses applications, données et systèmes récupérables.
Finalement, la nature d'une entreprise, les exigences de ses clients et le budget disponible pour la récupération après sinistre constituent des facteurs clés à prendre en compte lors de la formulation des conditions requises pour la récupération après sinistre. Une solution de récupération après sinistre complète peut coûter cher...mais il est essentiel qu'elle repose sur une architecture. L'argent, le matériel et les logiciels ne suffisent pas pour venir à bout d'un éventuel sinistre, tout en espérant que votre activité pourra reprendre et perdurer. Cependant, même si vous planifiez et mettez en place une architecture de façon intelligente, vous risquez de devoir faire face à des coupures plus longues et/ou une détérioration du service tant que l'ensemble des services ne sera pas rétabli, mais vous pourrez toujours disposer d'une solution de reprise après sinistre limitée fiable.
Toutefois, vous devez savoir que probablement aucune planification ne peut anticiper tous les scénarios de récupération après sinistre possibles et y répondre. Par exemple, ce qui semble être de prime abord un problème banal sur un système peut dégénérer au fil du temps et affecter d'autres systèmes de diverses manières, pour finir en catastrophe pour laquelle il n'existe aucun scénario de récupération. De même, la capacité d'une entreprise à honorer ses contrats de service peut se trouver affectée si des hypothèses clés ne sont pas vérifiées. Par exemple, si des composants ou des services essentiels ne sont pas disponibles, ou si le fournisseur de la solution de récupération après sinistre ne peut pas livrer le service aussi efficacement qu'il le prétendait. Toutefois, si un sinistre se révèle plus grave que le pire scénario que vous aviez prévu, la récupération risque de ne pas être possible.
Définition de l'objectif de délai de récupération (RTO, Recovery Time Objective)
Le RTO est un objectif de niveau de service du temps mis pour atteindre une fonction opérationnelle donnée après un sinistre. Par exemple, les exigences de l'entreprise peuvent mettre en place le RTO stipulant que tous les systèmes de production fonctionneront à 80 % des capacités antérieures au sinistre dans les 30 minutes suivant une coupure non planifiée qui durerait plus d'une heure (en cas d'absence de fonction de récupération après sinistre). Le temps de traitement du RPO, la disponibilité de personnel informatique qualifié et la complexité des processus informatiques manuels requis après un sinistre constituent des exemples de contraintes pouvant influer sur la détermination du RTO. Le RTO ne s'applique pas aux systèmes entièrement tolérants aux pannes, car ces derniers effectuent une reprise implicite pendant et après un sinistre, sans interruption de service.
Les planificateurs de DR peuvent déterminer des RTO différents pour tout ou partie des exigences de continuité de l'activité (BC) définies. Les divers types d'activités peuvent nécessiter des RTO différents, par exemple pour les systèmes en ligne et les fenêtres de traitement par lot. En outre, des RTO différents peuvent s'appliquer aux phases d'un plan de DR, dans lequel un RTO est défini pour chaque phase. Enfin, une application récupérable peut disposer de RTO différents pour chacun de ses niveaux de service.
Les exigences en matière de disponibilité des données de continuité de l'activité sont extrêmement importantes pour la planification d'un RTO. Lorsque les données qui doivent être saisies dans le processus de DR ne se trouvent pas sur le site de récupération après sinistre, le temps mis pour extraire les données sur site entraînera un retard du RTO. Par exemple, la durée d'extraction des données situées dans des archivages de stockage hors site sera longue. La récupération peut s'effectuer rapidement si les données d'entrée à jour sont dupliquées sur le site de récupération avant le début des opérations de récupération après sinistre.
Définition de l'objectif du point de récupération (RPO)
Le RPO est un objectif de continuité de l'activité qui détermine l'état de l'activité, ou niveau de l'activité, obtenu après le rétablissement des systèmes récupérables par le processus de récupération après sinistre. Conceptuellement, un RPO est un état cible de synchronisation ou de "restauration" connu antérieur au sinistre. Le RPO est donc le point de récupération après sinistre à partir duquel le traitement des applications récupérables interrompues peut reprendre. Toutes les transactions qui ont lieu dans l'intervalle situé entre le RPO et le moment du sinistre sont irrécupérables. Le RPO ne s'applique pas aux systèmes entièrement tolérants aux pannes, car le sinistre n'affecte pas la continuité de l'activité de ces derniers.
La Figure 1-1 illustre les concepts de RPO en suggérant divers points de récupération qui doivent être pris en compte par les planificateurs de DR. La planification doit s'assurer que le RPO souhaité est réalisable en fonction du RTO choisi et inversement. En général, les plans de récupération après sinistre qui exigent des RPO plus proches du moment du sinistre nécessitent davantage de tolérance aux pannes et sont plus chers à implémenter que les RPO plus éloignés. Comme pour les RTO, les planificateurs de DR peuvent définir différents RPO en fonction des exigences de continuité de l'activité, des phases du plan de récupération après sinistre ou des niveaux de service de l'application.
Figure 1-1 Objectifs de point de récupération
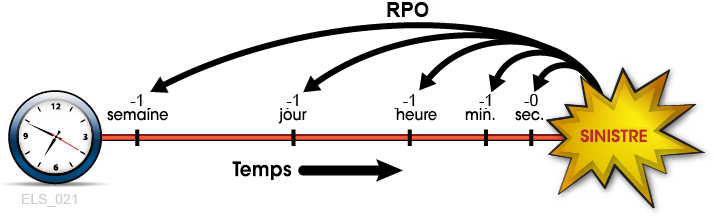
Description de Figure 1-1 Objectifs de point de récupération
Plus généralement, la planification de RPO doit identifier tous les éléments associés qui doivent être présents pour rétablir chaque système récupérable, notamment les données, les métadonnées, les plates-formes, les installations et le personnel. La planification doit garantir que ces éléments sont disponibles au niveau de l'activité voulu pour la récupération. Les exigences en matière de mise à jour des données de continuité de l'activité sont particulièrement importantes pour la planification du RPO. Par exemple, si les exigences de continuité de l'activité exigent un RPO d'une heure, les données ou métadonnées qui alimentent le processus de récupération doivent être au niveau du RPO, sous peine de ne pouvoir l'atteindre. Les processus de récupération après sinistre de l'organisation spécifient les procédures permettant d'atteindre tous les RPO définis au sein des RTO établis.
Les métadonnées système requises pour la récupération de RPO incluent des structures de catalogue de système d'exploitation et des informations système de gestion des bandes. Ces éléments doivent être mis à jour lors du processus de récupération après sinistre pour activer tous les RPO choisis. Par exemple, pour assurer la cohérence entre les diverses entrées de métadonnées dans le processus de DR, les jeux de données existants qui seront recréés sur le RPO ne doivent pas être catalogués, les jeux de données mis à jour entre le RPO et le moment du sinistre doivent être restaurés à la version antérieure ou simultanée au RPO et les modifications du catalogue relatives aux bandes doivent être synchronisées avec le système de gestion des bandes.
Traitement des pannes temporaires
La récupération après sinistre fournit une solution pour les pannes très longues qui risqueraient de rendre un site de production inutilisable pendant une longue période. Alors que le reste de cette introduction concerne les pratiques relatives à la récupération après sinistre, il est également important de mettre en place des procédures permettant de réduire les pannes relativement brèves qui peuvent affecter négativement la production si elles ne sont pas résolues. Prenons l'exemple d'une interruption de service au cours de laquelle certaines installations matérielles ou réseau sont indisponibles pendant une heure ou deux, mais durant laquelle la production peut continuer en "mode dégradé” avec quelques rapides ajustements temporaires. Une procédure applicable à une panne temporaire doit indiquer comment isoler le problème, les modifications à apporter, les personnes à avertir et comment rétablir l'environnement d'exploitation normal après la restauration du service.
Concept clé : récupération du point de synchronisation
Le redémarrage des applications de production sur des RPO définis est une activité clé qui est effectuée lors d'une réelle récupération après sinistre et des tests DR. Les environnements DR les plus résistants veilleront à s'assurer que chaque application récupérable, qu'elle provienne d'un fournisseur extérieur ou soit développée en interne, applique une exigence essentielle en matière de récupération après sinistre, à savoir que l'application soit conçue pour redémarrer à partir d'un point planifié, appelé point de synchronisation, pour atténuer les effets d'une interruption non programmée lors de son exécution. Lorsqu'une application interrompue est redémarrée à un point de synchronisation, ses résultats sont identiques à ceux d'une application non interrompue.
La procédure de redémarrage pour une application récupérable dépend de la nature de l'application et de ses entrées. La procédure de redémarrage d'une application pour une réelle récupération après sinistre ou des tests DR est assez souvent identique à celle utilisée pour le redémarrage de l'application en cas d'échec lors d'une exécution de production normale. Lorsque cela est possible, la réutilisation des procédures de redémarrage de la production pour la réelle récupération après sinistre ou les tests DR simplifie la création et la maintenance des procédures DR et exploite ces procédures éprouvées. Dans le cas le plus simple, une application récupérable est une étape de travail unique avec un seul point de synchronisation, qui constitue le début du programme appelé par cette étape. Dans ce cas, la procédure de récupération peut simplement consister à soumettre à nouveau le travail interrompu. Une procédure de redémarrage légèrement plus complexe peut impliquer le non-catalogage de l'ensemble des jeux de données de sortie générés par l'application lors de sa dernière exécution, puis le redémarrage de l'application.
Les procédures de redémarrage pour les applications ayant le choix entre plusieurs points de synchronisation internes risquent de ne pas être aussi simples. Les applications qui utilisent des techniques de point de reprise/redémarrage pour implémenter ces points de synchronisation enregistrent périodiquement leur progression et peuvent par exemple utiliser les informations de point de reprise enregistrées pour redémarrer au dernier point de synchronisation interne enregistré avant une interruption. Les procédures de redémarrage se conformeront aux exigences de chaque point de synchronisation. Lorsque des points de reprise sont utilisés, les jeux de données qui leur sont associés ne doivent pas avoir expiré, être retirés du catalogue ou supprimés alors que le point de reprise reste valide pour la récupération d'application. Une façon simple de définir un point de synchronisation pour une étape de travail qui modifie ses jeux de données d'entrée existants consiste à réaliser une copie de sauvegarde de chaque jeu de données modifiable avant d'exécuter l'étape. Ces jeux de données d'entrée modifiables peuvent être facilement identifiés en recherchant l'attribut JCL DISP=MOD dans des instructions DD ou dans des demandes d'allocation dynamique. En cas d'échec ou d'interruption d'une étape de travail, effacez simplement les jeux de données d'entrée modifiés, restaurez-les à partir des copies de sauvegarde et redémarrez l'étape à partir des copies restaurées. Ces copies de sauvegarde sont également utiles pour redémarrer une étape de travail défaillante ou interrompue qui a expiré, a été retirée du catalogue ou dont les originaux ont été supprimés.
Mise en relation d'un RPO avec la récupération du point de synchronisation
Lorsque le RPO s'aligne sur un point de synchronisation, l'exécution de la procédure de redémarrage d'une application qui a été développée pour ce point de synchronisation fera redémarrer l'application au début si aucune interruption n'a eu lieu (Figure 1-2). Toutes les transactions traitées entre ce RPO et le sinistre sont censées être irrécupérables.
Figure 1-2 RPO au point de synchronisation
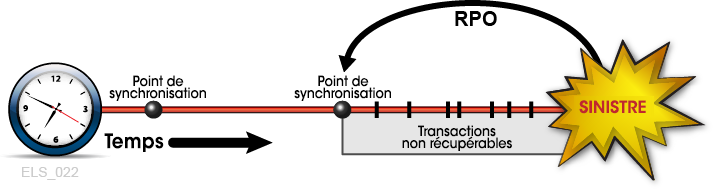
Description de Figure 1-2 RPO au point de synchronisation
Les exigences de continuité de l'activité peuvent parfois justifier de placer le RPO entre des points de synchronisation. Dans ces cas, la récupération entre points de synchronisation se fonde sur des données complémentaires qui décrivent les modifications critiques apportées à l'état de l'application ou les événements qui se sont produits après la définition du point de synchronisation le plus récent. Examinons par exemple le RPO situé une minute avant le sinistre. Supposons qu'une application récupérable soit conçue pour utiliser des points de reprise afin d'enregistrer sa progression, mais que le temps système mis pour définir ces points de reprise à des intervalles d'une minute soit intolérable. Une solution consiste à définir des points de reprise moins fréquents et à consigner toute les transactions validées entre ces points de reprise. Ce journal des transactions constitue ensuite des données d'entrée complémentaires, qui sont utilisées par le processus de récupération du point de reprise pour redémarrer à partir d'un RPO situé au delà du point de synchronisation le plus récent. Dans cet exemple, la procédure de redémarrage de l'application accède aux données du point de reprise le plus récent et utilise le journal des transactions complémentaire pour rétablir toutes les transactions validées qui ont été traitées après le point de reprise et avant le RPO (Figure 1-3). Ainsi, la récupération du point de reprise peut obtenir un RPO cible en utilisant les données d'entrée de plusieurs sources. Toutes les transactions traitées entre le RPO et le sinistre sont censées être irrécupérables.
Figure 1-3 RPO entre des points de synchronisation
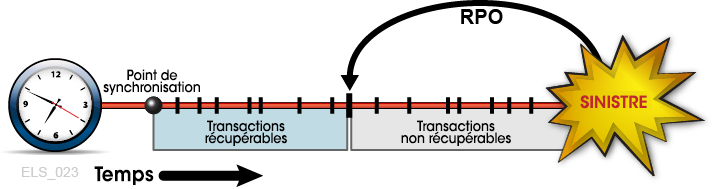
Description de Figure 1-3 RPO entre des points de synchronisation
Planification de la haute disponibilité des données (D-HA)
Les données constituent souvent l'une des ressources les plus précieuses que détient une entreprise. La plupart des sociétés veillent particulièrement à protéger leurs données essentielles contre une éventuelle perte et réalisent pour ce faire des investissements supplémentaires. De même, elles tiennent à s'assurer que les données sont utilisées à bon escient et au moment opportun. Les conséquences risquent d'être désastreuses pour une entreprise qui ne peut pas se prémunir contre une perte de données critiques. La méthode la plus répandue pour se protéger contre la perte de données consiste peut-être à stocker des copies des données critiques sur différents sous-systèmes ou médias de stockage et à conserver certaines de ces copies dans divers emplacements physiques. Les copies conservées sur des médias de stockage amovibles, notamment des bandes à cartouche magnétique, des CD-ROM et des DVD, sont généralement archivées dans des emplacements de stockage hors site. De même, les copies supplémentaires sont généralement stockées sur site dans des installations informatiques où des applications peuvent traiter ces données. La création et le stockage de copies de données critiques augmentent la redondance des données et améliorent leur tolérance aux pannes. Pour les médias amovibles, en particulier pour les bandes à cartouche magnétique, l'augmentation de la redondance des données seule ne suffit généralement pas à garantir la haute disponibilité des données pour les applications qui les utiliseront. Par exemple, le système VSM d'Oracle pour les bandes virtuelles mainframe stocke les données sur des volumes de bande physiques appelés MVC. VSM peut réaliser automatiquement des copies MVC pour améliorer la redondance des données et réduire les risques liés à un incident sur le média ou au mauvais positionnement d'une cartouche de bande. Un système VSM de production utilise de nombreux composants matériels spécialisés pour extraire les données stockées sur une cartouche MVC, notamment un lecteur tampon VTSS, une bandothèque automatisée et des lecteurs de bande connectés à une bandothèque, appelés RTD, qui sont également reliés au lecteur tampon VTSS. Les applications hôtes dépendent de tous ces composants VSM qui interagissent pour extraire les données des MVC. Bien que la plupart des gens ne considèrent pas la panne d'un seul composant comme un sinistre comparable à la perte de la totalité d'un centre de données dans un tremblement de terre, il deviendra quasiment impossible d'extraire des données MVC si un seul composant VSM critique tombe en panne sans sauvegarde, quel que soit le nombre de copies MVC redondantes existantes. Par conséquent, alors que la création de copies MVC constitue l'une des pratiques recommandées éprouvées pour réduire la vulnérabilité et les risques, cette opération ne suffit pas toujours à garantir la haute disponibilité des données (D-HA) en cas de pannes. Les exigences en matière de D-HA sont fondamentales pour la continuité de l'activité lors de la planification de la récupération après sinistre. La D-HA est généralement obtenue en augmentant les redondances pour éliminer les points de panne uniques qui empêcheraient les applications d'accéder aux données en cas de pannes du système de stockage. Un système VSM incluant des composants redondants améliore par exemple sa tolérance aux pannes. L'installation de plusieurs périphériques VTSS, HandBots SL8500 redondants et RTD vise à éliminer les points de panne VSM uniques sur le chemin de données entre l'application et les données critiques stockées sur une MVC. L'architecture VSM est conçue pour prendre en charge l'ajout de composants redondants afin d'augmenter la tolérance aux pannes et de promouvoir la D-HA.
Bande physique hautement disponible
Les solutions d'automatisation de bande mainframe d'Oracle activent la D-HA pour les applications de bande physique en stockant des copies de données redondantes dans différents ACS au sein d'un tapeplex, à savoir dans un complexe de bandes mappé par un seul CDS. Par exemple, les applications exécutées sur une installation informatique avec un seul tapeplex peuvent facilement stocker des copies de jeux de données de bandes en double dans un ou plusieurs ACS au sein de ce tapeplex. Cette technique améliore la D-HA en ajoutant des médias redondants, des transports de bandes et des bandothèques automatisées. Dans un scénario simple, une application stocke des copies redondantes d'un jeu de données critique sur deux bandes de cartouche différentes dans une seule bibliothèque SL8500 avec Redundant Electronics, deux HandBots sur chaque rail et au moins deux transports de bandes connectés à la bibliothèque sur chaque rail, qui sont compatibles avec le média de jeu de données. Pour supprimer la bibliothèque SL8500 comme possible point de panne unique, une deuxième bibliothèque SL8500 est ajoutée à l'ACS pour stocker davantage de copies redondantes du jeu de données critique. Pour éliminer l'installation informatique elle-même comme point de panne unique, les copies redondantes du jeu de données peuvent être archivées hors site ou créées sur un ACS distant par transport de bande, via une extension de canal (Figure 1-4).
Figure 1-4 Configuration de bandes physiques FD-HA
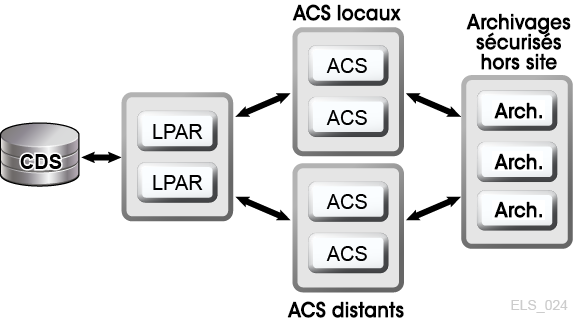
Description de Figure 1-4 Configuration de bandes physiques FD-HA
Vous pouvez également réaliser plusieurs copies de bandes physiques dans divers emplacements physiques lorsque chacun d'eux dispose de son propre CDS indépendant, à savoir lorsque le matériel présent dans chaque emplacement représente un tapeplex distinct. Grâce à l'utilisation de la fonctionnalité client/serveur de SMC et à la définition de stratégies qui dirigent les copies du jeu de données vers un tapeplex distant, les travaux peuvent créer des copies de bandes dans un ACS figurant sur un autre tapeplex sans apporter de modifications au JCL.
Bande virtuelle hautement disponible
VSM fournit des technologies de clustering et de multiplexage MVC pour activer la D-HA pour les bandes virtuelles mainframe. Le multiplexage VSM implique la création de plusieurs copies MVC (par exemple, duplex, quadruplex) dans un ou plusieurs ACS afin d'optimiser la redondance (Figure 1-5). Les ACS qui reçoivent des copies multiplexées peuvent être des bibliothèques locales ou des ACS distants par transport de bande, via une extension de canal. Les stratégies de migration VSM contrôlent le mouvement des VTV situés sur le tampon VTSS vers des MVC locales ou distantes, qui peuvent être archivées hors site.
Figure 1-5 Configuration du multiplexage VSM de la D-HA
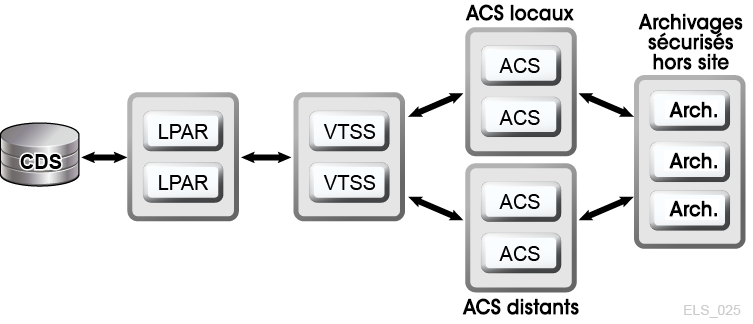
Description de Figure 1-5 Configuration du multiplexage VSM de la D-HA
Un cluster VSM contient plusieurs périphériques VTSS (nœuds) qui sont mis en réseau pour permettre l'échange de données via un lien de communications (CLINK.) Les CLINK sont des canaux unidirectionnels ou bidirectionnels. La configuration de cluster VSM la plus élémentaire se compose de deux nœuds VTSS reliés à un CLINK unidirectionnel dans le même tapeplex, mais des CLINK bidirectionnels sont fréquemment déployés (Figure 1-6). Chaque nœud de cluster peut se trouver sur un site différent. Les stratégies de stockage unidirectionnel VSM contrôlent la réplication automatique des volumes de bande virtuelle (VTV) entre VTSS A et VTSS B via un CLINK unidirectionnel. Les stratégies de stockage bidirectionnel et les CLINK bidirectionnels permettent au VTSS A d'effectuer une réplication sur le VTSS B et inversement.
Figure 1-6 Configuration de cluster VSM de la D-HA
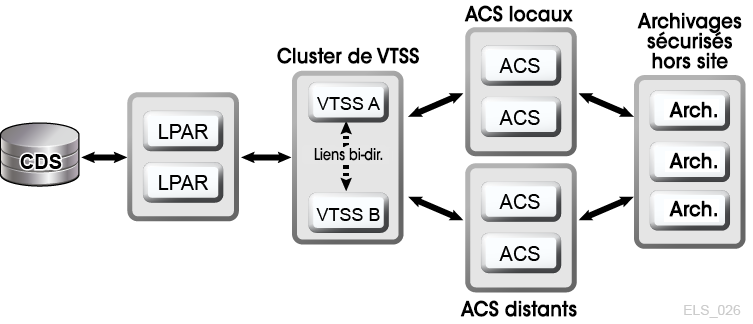
Description de Figure 1-6 Configuration de cluster VSM de la D-HA
Le clustering étendu VSM permet une connectivité de plusieurs à plusieurs entre trois périphériques VTSS au minimum au sein d'un tapeplex, afin d'optimiser la disponibilité des données (Figure 1-7). L'installation de périphériques de cluster VTSS sur plusieurs sites au sein d'un tapeplex comme dans l'illustration permet d'augmenter la redondance en éliminant chaque site en tant que point de panne unique.
Figure 1-7 Configuration de cluster étendue de la D-HA (archivages hors site non indiqués)
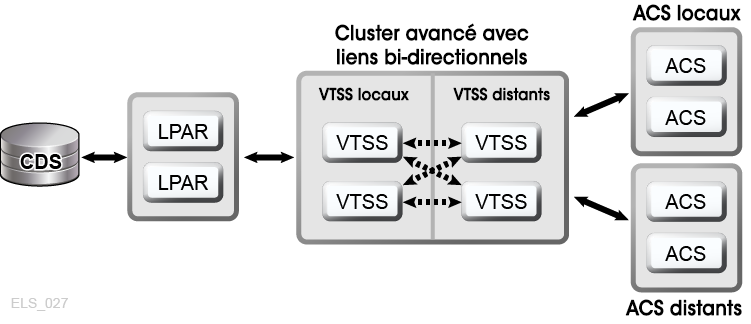
Description de Figure 1-7 Configuration de cluster étendue de la D-HA (archivages hors site non indiqués)
Le produit LCM d'Oracle rationalise les processus d'archivage sécurisé hors site pour les volumes MVC en gérant le processus de recyclage entre les archivages et les bibliothèques de production. La fonction d'archivage sécurisé de LCM planifie le renvoi des volumes MVC archivés lorsque la quantité de données ayant expiré dépasse un seuil défini.
Un cluster CTR (Cross-Tapeplex Replication) VSM permet à des périphériques de cluster VTSS de figurer dans différents tapeplex et de répliquer des VTV entre un tapeplex et un ou plusieurs autres tapeplex, en activant des modèles de réplication de cluster de plusieurs à plusieurs via des CLINK unidirectionnels ou bidirectionnels (Figure 1-8). L'envoi et la réception de tapeplex peut avoir lieu sur des sites différents. Les VTV répliqués sont entrés dans le CDS du tapeplex récepteur sous forme de volumes en lecture seule. Cela garantit ainsi une excellente protection des données contre leur modification par les applications exécutées dans le tapeplex récepteur. Le CDS du tapeplex récepteur indique également que les copies VTV répliquées via CTR appartiennent au tapeplex émetteur. Ainsi, pour renforcer la protection, CTR s'assure qu'un tapeplex ne peut pas modifier un VTV dont il n'est pas propriétaire.
Figure 1-8 Configuration de la réplication entre Tapeplex (CTR) VSM de la D-HA
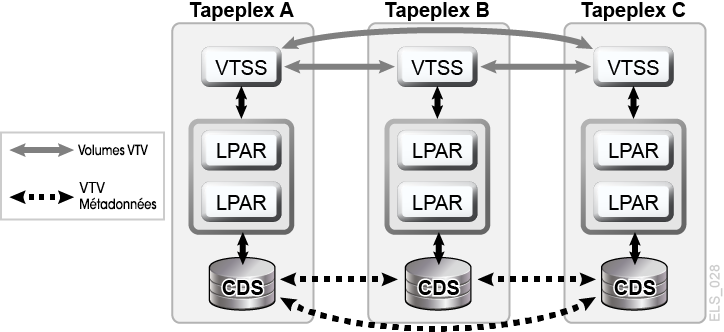
Description de Figure 1-8 Configuration de la réplication entre Tapeplex (CTR) VSM de la D-HA
D-HA et récupération du point de synchronisation
La création de plusieurs copies de volumes physiques (MVC ou non) améliore la redondance de données, mais ces copies posent des conditions particulières pour la récupération du point de synchronisation. L'aspect le plus important de la récupération du point de synchronisation consiste à s'assurer que les données créées au point de synchronisation restent à l'état de lecture seule tout en restant valides à des fins de récupération après sinistre. Cela signifie que les copies de volume de bande physique qui peuvent être utilisées pour la récupération après sinistre doivent rester à l'état de lecture seule. Une méthode pour effectuer cette opération consiste à envoyer ces copies vers un emplacement d'archivage hors site sur lequel il n'existe aucune fonction de traitement de bande. Sachez que les copies non protégées qui subissent une modification deviennent inutilisables pour la récupération du point de synchronisation, car le contenu mis à jour ne reflète plus le point de synchronisation associé. Les environnements de bande virtuelle ajoutent une dimension supplémentaire à la gestion de plusieurs de copies de volume pour la récupération du point de synchronisation. Des copies VTV peuvent cohabiter simultanément dans plusieurs tampons VSM et sur plusieurs MVC. Même lorsque toutes les MVC d'un VTV donné sont archivées hors site, il est possible de modifier les copies VTV qui demeurent sur site dans les tampons VSM. Une copie VTV mise à jour dans un tampon ne doit pas être utilisée pour la récupération du point de synchronisation, sauf si cet VTV appartient à un nouveau point de synchronisation qui invalide les copies hors site archivées à des fins de récupération après sinistre.
Exécution d'une réelle récupération après sinistre
Le succès d'une opération de réelle récupération après sinistre repose sur le fait de disposer d'un site DR adéquat, de personnel formé, d'une procédure DR qui a fait ses preuves, d'une charge globale de production récupérable avec des points de synchronisation pour répondre aux RPO définis, ainsi que de l'ensemble des données d'entrée et des métadonnées système nécessaires à la réalisation de ces objectifs. Les données d'entrée et les métadonnées système doivent être accessibles sur le site DR si nécessaire et disponibles aux niveaux requis de mise à jour. Avec une planification minutieuse, une préparation approfondie et une exécution bien rôdée, les opérations de réelle récupération après sinistre peuvent se dérouler sans problème selon le plan établi pour atteindre les RPO et les RTO définis. Les données de production générées sur le site DR doivent être protégées de façon adéquate alors que le site DR fonctionne comme un site de production. Supposons par exemple que l'architecture D-HA nécessite que la charge globale de production réplique les copies de données redondantes sur trois sites distants et que le site DR soit l'un de ces sites de réplication distants avant le sinistre. Lorsque le site de production subit un sinistre et que sa charge globale est transférée vers le site DR, ce dernier ne peut plus servir de site de réplication distant pour la charge globale de production actuellement exécutée en local sur le site. Pour répondre à l'exigence de D-HA des trois sites de réplication distants, un troisième nouveau site de réplication distant doit être mis en ligne tant que la production reste sur le site DR. Cet exemple illustre la façon dont une analyse minutieuse des exigences de D-HA permet aux planificateurs de DR de répondre à toutes les exigences de D-HA critiques qui doivent être satisfaites lorsque la production est transférée vers un site DR. Un plan de récupération après sinistre complet n'englobe pas seulement les activités permettant de rétablir la production sur le site DR, mais également le processus de suppression du site DR lorsque le site de production est réparé et prêt à l'emploi, en supposant que le site DR ne soit qu'un substitut temporaire au site de production. Par exemple, lorsque le site de production est prêt à reprendre son fonctionnement, les données de production doivent être rétablies sur ce site. Les méthodes proposées incluent le clustering bidirectionnel entre le site DR et le site de production, accordant ainsi suffisamment de temps au travail de production exécuté sur le site DR pour réalimenter l'ancien site de production via la réplication de données. Il peut toutefois être nécessaire, voire plus opportun ou efficace, de simplement retransférer les MVC physiques vers le site de production rétabli. Les méthodes choisies dépendront des exigences de récupération après sinistre.
Planification de tests DR
La préparation de la réelle récupération après sinistre est évaluée en testant l'efficacité et le rendement des systèmes et procédures de DR lors du rétablissement d'une charge globale de production sur un site de test DR donné. L'environnement de test DR peut être une plate-forme de test DR dédiée, mais il est généralement plus économique de partager des ressources entre les systèmes de production et de test DR. Les tests DR effectués en parallèle à la production et l'utilisation de ressources partagées avec la production constituent ce que l'on appelle les tests DR simultanés. Si une application doit s'exécuter en parallèle aux systèmes de production et de test DR, les planificateurs de la récupération après sinistre doivent s'assurer que ces deux instances de l'application ne se gêneront pas lorsqu'elles s'exécuteront simultanément. Le fait d'isoler les systèmes de production et de test DR sur des partitions LPAR distinctes et de limiter l'accès aux données de production à partir du système de test DR suffit généralement. Les tests DR sont souvent effectués petit à petit pour permettre des tests ciblés des diverses applications à différents moments, au lieu de tester la récupération de l'ensemble de l'environnement de production en une seule fois. Un test ciblé est essentiel pour réduire la quantité de matériel dédié requis pour le système de test DR. Par exemple, si les tests DR d'une application récupérable ne requièrent qu'un petit sous-ensemble de ressources VSM, ces ressources peuvent être partagées entre les systèmes de production et de test DR, et réaffectées au système de test DR pour le cycle de test DR. Cette approche réduit les dépenses matérielles liées au système de test DR mais peut avoir une influence négative sur les performances du système de production lors de l'exécution du test DR. Toutefois, un cycle de test DR ne dédie généralement qu'un faible pourcentage des ressources partagées au système de test DR et les tests DR parallèles n'ont pas de réel impact sur l'environnement de production diminué. Néanmoins, certaines organisations ont mis en place des stratégies pour lutter contre l'altération ou la détérioration de la production afin de faciliter les tests DR. Vos auditeurs peuvent exiger une correspondance exacte entre les résultats des tests DR et les résultats de production pour certifier le processus de récupération après sinistre. Pour répondre à cette exigence, vous pouvez définir un point de synchronisation juste avant un cycle de production planifié, enregistrer une copie des résultats de production, reprendre le cycle de production à ce point de synchronisation sur le site de test DR et comparer la sortie avec les résultats de production enregistrés. Toute différence entre les résultats met en évidence un écart qui doit être analysé. L'impossibilité de résoudre à temps les écarts détectés peut mettre en péril la capacité de réelle récupération après sinistre d'une organisation. Qu'un test DR soit conçu pour récupérer une charge globale complexe ou une seule application, le processus doit suivre les mêmes procédures que celles en vigueur pour la réelle récupération après sinistre. Il s'agit de la seule méthode fiable pour s'assurer que le test DR a réussi.
Déplacement de données pour les tests DR
Il existe deux méthodes pour transférer les données d'application pour les tests DR sur un site de test DR : le déplacement de données physiques et le déplacement de données électroniques. Le déplacement de données physiques implique le transport de cartouches de bande physiques vers le site de test DR au cours d'un processus décrit ci-dessous et appelé exportation/importation physique. Le déplacement de données électroniques utilise des lecteurs de bande distants, des RTD distants ou des techniques de cluster VSM pour créer des copies des données d'application sur un site de test DR. Ces deux méthodes de déplacement de données permettent d'effectuer des tests DR, mais le déplacement de données électroniques évite le transfert de données physiques et les éventuels problèmes liés à la perte de bandes, etc. Le transfert électronique améliore également le temps d'accès aux données en les plaçant à l'endroit approprié pour la réelle récupération après sinistre, ou en transférant les données vers un tampon VSM en amont d'un cycle de test DR. Le déplacement de données électroniques pour les volumes virtuels s'effectue au sein d'un seul tapeplex à l'aide du clustering étendu VSM, ou entre deux tapeplex à l'aide de la fonction CTR (Cross-Tapeplex Replication). Pour les données situées sur un seul tapeplex, le logiciel CDRT (Concurrent Disaster Recovery Test) d'Oracle rationalise les tests DR.
Tests DR avec exportation/importation physique
Supposons que vous vouliez effectuer des tests DR pour une application de production utilisant des bandes virtuelles et physiques. Vous souhaitez tester cette application sur le site de test DR en répétant un cycle de production récent et en vérifiant que la sortie du test correspond à la sortie de production récente. Pour préparer l'opération, vous devez enregistrer des copies des jeux de données d'entrée utilisés par le cycle de production et une copie de la sortie de production afin de les comparer. Supposons que le site de test DR soit isolé et ne partage aucun équipement avec la production. Vous pouvez effectuer le test DR à l'aide de ce processus d'exportation/importation physique.
Site de production :
-
Effectuez une copie des VTV et volumes physiques requis.
-
Exportez ces copies VTV.
-
Ejectez les copies MVC et les copies de volume physique associées à partir de l'ACS de production.
-
Transférez les MVC et les volumes physiques éjectés vers le site de test DR.
Site de test DR :
-
Entrez les volumes transférés dans l'ACS de récupération après sinistre.
-
Synchronisez les catalogues du système d'exploitation et le système de gestion des bandes avec les volumes entrés.
-
Importez les données VTV/MVC.
-
Exécutez l'application.
-
Comparez les résultats.
-
Ejectez tous les volumes entrés pour ce test.
-
Transférez à nouveau les volumes éjectés vers le site de production.
Site de production :
-
Entrez à nouveau les volumes transférés dans l'ACS de production.
Ce processus permet d'exécuter des tests DR en toute sécurité parallèlement à la production, car le système de test DR est isolé du système de production. Le système de test DR possède son propre CDS et le processus de test DR entre des informations de volume dans le CDS de test DR pour préparer le test DR, comme illustré ci-dessus. L'application récupérée peut alors effectuer le test avec les mêmes volumes et noms de jeux de données que ceux qu'elle utilise en production. Pour les jeux de données de bande virtuels, la fonction d'archivage sécurisé du logiciel LCM d'Oracle simplifie le placement des VTV sur les MVC et rationalise les étapes d'aller-retour ci-dessus pour exporter et éjecter des volumes sur le site de production, importer ces volumes sur le site de test DR et éjecter ces volumes pour qu'ils soient à nouveau transférés vers le site de production. L'exportation/importation physique induit des dépenses sur le site pour le traitement des bandes physiques, ainsi que des dépenses de coursier pour le transport des cartouches de bande entre les sites de production et de test DR. Les données sensibles transportées par coursier doivent figurer sur des cartouches de bande chiffrées. La rapidité d'exécution des tests DR est affectée par le temps de transport et de traitement des cartouches de bande lors de leur déplacement entre les sites.
Tests DR avec CDRT
Grâce à une planification et à un matériel suffisant sur les sites de production et de récupération après sinistre, CDRT, lorsqu'il est combiné au déplacement de données électroniques, permet d'éviter le transport de cartouches de bande physiques vers le site DR et d'effectuer des tests DR simultanés pour un coût inférieur à celui induit par le maintien d'un site de test DR dédié isolé. CDRT permet d'effectuer des tests DR sur presque toutes les charges globales de production, configurations, ou tous les RPO ou RTO imaginables. La procédure de test DR inclura quelques étapes supplémentaires pour démarrer CDRT et effectuer un nettoyage après un test DR. Avant d'exécuter un test DR avec CDRT, vous devez déplacer électroniquement toutes les données d'application et métadonnées système (informations du catalogue du système d'exploitation et du système de gestion de bandes) nécessaires au test vers le site de test DR. Vous pouvez déplacer électroniquement des données d'application par le biais du clustering VSM ou de la migration de copies VTV vers des MVC sur le site DR. Utilisez ensuite CDRT pour créer un CDS spécial pour le système de test DR, qui met en miroir le CDS de production. Les systèmes de production et de test DR sont des environnements distincts. L'environnement de test DR utilisera le CDS de test DR spécial au lieu du CDS de production. Etant donné que CDRT crée le CDS de test DR à partir des informations figurant dans le CDS de production, il contient des métadonnées pour l'ensemble des volumes qui ont été déplacés électroniquement vers le site de test DR avant le test DR. Cela permet aux applications de test DR d'utiliser les mêmes numéros de série de volume et noms de jeux de données de bande qu'en production. CDRT impose des restrictions opérationnelles au système de test DR pour empêcher l'environnement de récupération après sinistre d'interférer avec l'environnement de production. Vous pouvez renforcer ces protections en utilisant les fonctions VOLPARM/POOLPARM d'ELS pour définir des plages volser distinctes pour les MVC et les VTV provisoires qui seront exclusivement utilisées par CDRT. CDRT permet au système de test DR de lire les MVC de production et d'écrire dans son propre pool de MVC dédié, qui est effacé logiquement après chaque cycle de test DR. Pour les applications de bandes virtuelles, CDRT requiert au moins un périphérique VTSS dédié pendant la durée du cycle de test DR. Ces VTSS dédiés peuvent être temporairement réaffectés à partir de la production pour faciliter l'exécution d'un test DR et le système VSM de test DR peut accéder aux ACS de production parallèlement à la charge globale de production. La Figure 1-9 et la Figure 1-10 illustrent la scission d'un cluster VSM de production pour prêter un périphérique de cluster au système de test DR du CDRT (ici VTSS2 sur le site de test DR). Lorsque ce cluster est scindé, vous devez modifier les stratégies de production pour remplacer la migration par la réplication, afin que VTSS1 crée des copies VTV redondantes sur le site DR dans ACS01. Ainsi, la capacité de VTSS1 ne sera pas saturée si le cluster est scindé. VTSS2 est mis hors ligne en production et en ligne sur la partition LPAR de test DR. Dans la Figure 1-9, CDRT a créé le CDS de test DR à partir d'une copie distante du CDS de production. Seul le système de production peut accéder aux volumes de VTSS1 et ACS00 au cours du cycle de test DR. De même, seul le système de test DR peut accéder à VTSS2. Les systèmes de production et de test DR partagent un accès simultané aux volumes dans ACS01. Dans la Figure 1-9 et la Figure 1-10, une copie distante du CDS de production sur le site de test DR, par exemple par le biais de la mise en miroir distante, est conservée pour s'assurer qu'un CDS de production à jour est disponible sur le site DR en vue de son utilisation pour la réelle récupération après sinistre. Notez toutefois que le CDS de test DR créé par CDRT à partir de la copie CDS distante est une version de test DR spéciale du CDS de production, utilisable uniquement par CDRT. Avant de reconstituer le cluster de production à la fin du cycle de test DR, le VTSS de la récupération après sinistre doit être purgé pour éviter la perte des données de production, comme cela serait le cas si VTSS2 contenait une version plus récente d'un VTV qui était également présent dans VTSS1. Vous devez également modifier les stratégies de production pour passer de la migration à la réplication lorsque le cluster est reconstitué. S'il n'est pas possible de scinder un cluster de production comme indiqué ici, vous pouvez conserver un VTSS distinct sur le site DR exclusivement pour les tests DR. Dans ce cas, les VTV nécessaires au test seront rappelés à partir des copies MVC.
Figure 1-9 Cluster de production avec le nœud de cluster distant VTSS2 sur le site de test DR
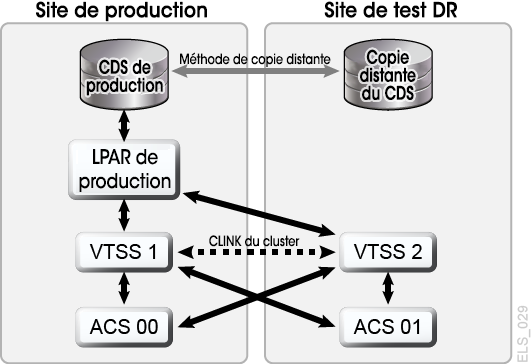
Description de Figure 1-9 Cluster de production avec le nœud de cluster distant VTSS2 sur le site de test DR
Figure 1-10 Configuration de production avec VTSS2 prêté pour les tests de récupération après sinistre CDRT
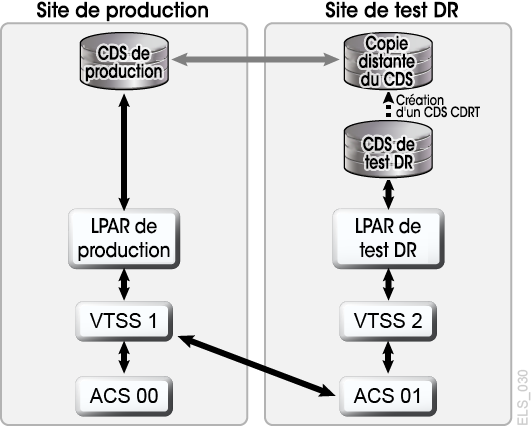
Description de Figure 1-10 Configuration de production avec VTSS2 prêté pour les tests de récupération après sinistre CDRT
Tests DR avec fonction CTR (Cross-Tapeplex Replication) de VSM
La fonction CTR (Cross-Tapeplex Replication) de VSM active des architectures tapeplex de production, symétriques, en cluster, qui facilitent l'exécution de tests DR sans utiliser CDRT, sans avoir besoin de matériel VTSS dédié uniquement aux tests DR et sans modifier l'environnement de production pour les tests DR. Par exemple, la fonction CTR permet à chaque tapeplex de production de répliquer des données sur les autres tapeplex de production dans le même cluster CTR. Les clusters entre homologues de la fonction CTR de production peuvent éviter l'emploi d'un site de test DR dédié. La fonction CTR active de nombreux types d'architectures tapeplex en cluster différentes et facilite les tests DR d'une configuration ou d'une charge globale de production, avec des RPO ou RTO réalisables. Dans un exemple simple, un cluster CTR bidirectionnel relie symétriquement deux tapeplex de production et chaque tapeplex réplique des données sur l'autre TapePlex (Figure 1-11). Un tapeplex récepteur entre un VTV répliqué dans son CDS à l'état de lecture seule et le marque comme appartenant au tapeplex émetteur. Dans cet exemple, les tests DR d'une application sur le tapeplex A impliquent la réplication des données d'application sur le tapeplex B et la récupération de l'application sur le tapeplex B.
Figure 1-11 Cluster CTR de production symétrique pour les tests DR
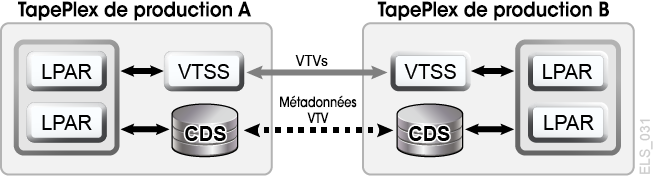
Description de Figure 1-11 Cluster CTR de production symétrique pour les tests DR
La symétrie de cette architecture de cluster CTR homologue signifie que l'application récupérée qui est testée sur le site homologue s'exécute de la même façon pendant un test DR qu'en production. Le CDS homologue contient toutes les informations de volume répliquées nécessaires aux tests DR, qui s'exécutent en parallèle à la production, tandis que le même matériel VTSS permet une utilisation simultanée par les charges globales de production et de test DR. Les clusters VTSS de production peuvent se trouver au sein de chaque TapePlex et n'ont pas besoin d'être scindés pour partager du matériel entre tapeplex pour les tests DR. Le tapeplex de production sur lequel sont exécutés les tests DR de l'application ne pouvant pas modifier les VTV répliqués par la fonction CTR, toutes les données de production répliquées sont totalement protégées lors du cycle de test DR. En outre, les tests DR basés sur la fonction CTR garantissent qu'une procédure de test DR validée produira des résultats identiques lors d'une réelle récupération après sinistre. Le logiciel hôte SMC enverra un message en cas de tentative de mise à jour d'un VTV répliqué à l'aide de la fonction CTR, qui sert à identifier l'application comme l'une de celles modifiant un jeu de données d'entrée existant. En suivant les pratiques recommandées ci-dessus pour la gestion des points de synchronisation, vous devez vérifier que l'environnement de production enregistre une copie de ce jeu de données avant qu'il ne soit modifié par l'application, au cas où une copie de sauvegarde serait nécessaire pour la récupération du point de synchronisation.