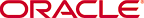| Oracle® Retail Insights Cloud Service Suite Operations Guide Release 18.0.001 F17010-01 |
|

 Previous |
 Next |
| Oracle® Retail Insights Cloud Service Suite Operations Guide Release 18.0.001 F17010-01 |
|
Previous |
Next |
This chapter describes the following fact data concepts in Retail Insights:
An overview of Retail Insights fact processing
Fact functional areas
Types of fact tables
Fact temp table usage
General fact processing
Detailed fact load processing
Fact aggregation processing
The following description and Overview of Fact, Extraction, Load, and Aggregations diagram offers an overview of the Retail Insights fact process.
For additional details on the extract, load, and aggregation process processing details such as types, program types, error handling, logging, and reject handling, see Chapter 5, "Retail Insights Program Overview". This chapter has the details of data flows for different fact load and fact aggregation programs.
SDE programs are executed to extract the data from source systems and load the data to staging tables and SIL programs look up the dimension tables for appropriate surrogate keys, perform reject handling, and load the base fact data. PLP programs roll up the already loaded base fact data and insert/update aggregate tables.
Fact data represent transaction values extracted from a source system such as the Oracle Retail Merchandising System (RMS). The Retail Insights fact functional areas are as follows:
Net Cost
Base Cost
Inventory Position
Inventory Receipts
Net Profit
Pack Sales
Planning (Original and Current)
Pricing
Sales Forecasts
Retail Markdowns
Sales Transactions
Stock Ledger
Sales Promotion
Supplier Compliance
Supplier Invoice Cost
Wholesale/Franchise Sales and Wholesale/Franchise Sales Markdowns
Inventory Transfer
Inventory Adjustment
Return To Vendor
Customer Order Facts
Store Traffic
Sales Discount
Sales Trx Tender
Gift Card Sales
Competitor Price
Unavailable Inventory
Item Season Phase
Stock Count
The Retail Insights data model contains two types of fact tables: base and aggregate.
A base fact table holds fact data for a given functional area at the lowest level of granularity. The process of populating a base fact table begins with the extraction of the data from the source system and populating the staging tables in Retail Insights schema.
Once data is loaded into staging tables, dimension data is looked up for getting the surrogate keys for the fact associated dimension records and also for identifying error records. The fact records that do not have valid associated dimension records are identified as error records and are inserted into error tables. Error record processing occurs during fact data processing and is not carried out for dimension loading programs. ODI programs are used for extracting and loading data into the Retail Insights schema.
Base fact tables in the Retail Insights schema are of two types, one which holds data for standard facts and one that holds data for positional facts. Below is a brief explanation of how this data is stored:
Standard Facts: These are fact tables holding data that can be further rolled up across associated dimensions such as Sales transaction and Retail Markdown.
Positional Facts: These are fact tables holding data that cannot be rolled up across associated dimensions by simple summation of the measures and require more complex logic such as taking averages or end of the week measure values while rolling up the data.
For performance reasons the data is stored in these tables with date ranges to reflect the effective start and end dates about the state of data. For example, to hold the inventory of a particular item in the base fact table W_RTL_INV_IT_LC_DY_F, FROM_DT_WID is used to store the date the inventory of a particular item on a particular day for a location was introduced and TO_DT_WID is used to store the date the inventory of the same item on same location was changed. This inventory change introduces a new row in this table with FROM_DT_WID as that day's business date and TO_DT_WID as a future business date (which can be very far off in future).
After facts are loaded into the base data mart tables, the process of aggregation begins. Aggregation refers to the process of taking data at a particular level of granularity, that is the item level, and summing it up to a higher level, such as the subclass level, in order to improve report query performance.
The following are the types of aggregation in Retail Insights:
Positional fact aggregation Standard fact aggregation (As Was and Corporate Aggs, Season Level Aggregates)As Is Aggregates
Some fact tables in Retail Insights contain information about an entity's position or status at a given point in time. Such data does not sum up in the same way that transactional data does. See "Standard Fact Aggregations" for additional information. For instance, the pricing data mart contains unit retail values for a given item at a given location. Even though new records are written to the table only when a price changes, a user must be able to query for any day and have the system return the correct value. However, storing positions for every item at every location for every day quickly becomes prohibitive from a data storage and load performance standpoint. In order to strike a balance between storage and performance, Retail Insights makes use of a technique called compression to store and report on positional facts. See the Compression and Partitioning chapter of the Oracle Retail Insights Implementation Guide for more information about how compression works and where Retail Insights uses it.
Because data on positional fact tables reports on the state of an entity at a certain point in time, rather than the total activity of an entity, these facts cannot be simply summed over time. For instance, the question: "What was my total unit retail for this week?" is nonsensical. For this reason, aggregations of positional facts along the axis of time take end-of-period snapshots that answer the question: "What was my unit retail at the end of this week?"
With all aggregations along the time axis, aggregation programs run daily. For aggregations of positional facts within a period, this results in a period-to-date position, rather than an end-of-period position. Once the period is complete, the last run of that period results in the desired end-of-period position.
The compression of positional facts is complex. In order to simplify maintenance and to maximize performance, it is sometimes better to leave base-level facts in their raw compressed state and to store higher-level aggregates (with less fine levels of granularity) in a decompressed state, in which positions for all entities are written everyday. Building these decompressed aggregates can be a significant task in itself because it involves finding the current positions for every entity at the lower level for the current point in time-even for those entities that may have last had a record some time ago. Fortunately, this task can be simplified by the use of a current position table (such as W_RTL_INV_IT_LC_G). A current position table is used, that is, when facts are aggregated from item-location-day to subclass-item-location-day. Less frequently, loads may also make use of a temporary table, which only contains today's changes to facilitate bulk processing of the data. That is, when facts are aggregated from item-location-day to item-location-week, the aggregation does not include the entire week's data, only today's changes.
Base fact tables are loaded using the temp tables created using corresponding staging table and dimension tables. The temp table is created for several reasons:
Temp table gets the flattened hierarchy from corresponding dimension tables and can be used as source for loading data into base fact and higher level aggregate tables. This improves the load program performance as the dimension tables are not required to be joined separately for each aggregate program.
The temp table acts as a driver for flexible aggregates. For example, one subject area has one base fact and it is decided during implementation to implement only two aggregate tables rolled up against product dimension (for example: W_RTL_SLS_TRX_IT_LC_DY_F, W_RTL_SLS_IT_LC_DY_A, W_RTL_SLS_CL_LC_DY_A ). The same temp table (W_RTL_SLS_SC_LC_DY_TMP) will be used for rolling up data to these tables and allows to skip levels as the rolling up of data in next immediate aggregate table is not mandatory. For more information on choosing the appropriate aggregate tables, see the Oracle Retail Insights Implementation Guide.
These temp tables are truncated every time before re-inserting new data in every execution.
As mentioned earlier in this chapter, these aggregates are simple aggregation or summation of measure across associated dimensions and are not very complex in processing when compared to positional facts.
As Was Aggregates: These aggregates are aggregates across product, Organization or Calendar dimension using the hierarchy that exists at the time of rollup.
For example, base fact data from standard base fact table is to be rolled up from Item, Location, Day level for Sales transactions to SubClass, Location, Day level. The Product hierarchy that existed on the day of rollup will be used to reflect the Subclasses for the respective Items.
Corporate Aggregates: These high level aggregates are used for serve reporting purposes for top level executives where reports are required to be viewed at the entire company level (Organization top level). These aggregates do not show Organization level information and assume that there is only one company.
Season Level Aggregates: These are special set of aggregate tables that are build for reporting the based on particular seasons and are created to improve the performance of reports. Since Retail Insights base facts do not have season information and is derived from the corresponding items attached to these seasons, pre-processing this information helps in improving the performance of reports requiring reporting by season.
These aggregates are built to support the As Is functionality in Retail Insights reports. Please refer to the Oracle Retail Insights User Guide for more details on As Is reporting.
Since Retail Insights supports As Is reporting in the same instance, a separate set of tables is build to support this functionality. These aggregates require re-building every time reclassification is performed in the product dimension otherwise, during the regular batch, new facts are rolled up and added to the current data set.
As Is aggregate ODI programs have two components, one component that is used for rolling up the latest transactions and second one is the reclassification component.
In addition, the reclassification ETL should be scheduled to be executed on the day following the reclassification occurs. If reclassification occurs on Business day DAY10 as an example; then the new hierarchy is available from Business day, DAY11. In order to reflect the exact hierarchy the current or as-is aggregate interface for reclassification will be scheduled to be executed right before the business date is being moved to next day (DAY11) in this case. Refer to "Extract, Transform, Load Dependencies" for more details on batch scheduling for As Is aggregates.
This section provides details of fact data flow diagram for standard aggregates: As Was Aggregate, As Is Aggregate, Season Aggregates, and Corporate Aggregates. This is general flow description and for complete list of aggregate programs by subject area, refer to Chapter 7, "Program Reference Lists". The flow diagram shows the flow for all types of aggregates, but depending on the subject area all types of aggregates may not be pre-packaged with ODI code.
For setting up proper dependencies between the programs, refer to Extract, Transform, Load Dependencies.
This step shows the data being extracted from the source system. All the required source system tables are joined together, data is transformed, and loaded to the Retail Insights staging table over the DBLink.
A view is created in the source system and DBLink is created from the target (data warehouse) to the source system for moving the data in the view from source to target database.
The fact staging table is always truncated before loading the new data. This diagram also lists the ODI knowledge modules used in this extraction step.
For example, the temporary table in this case can be a table which has Sales measures along with surrogate keys for item, subclass, class, department, group, division, and company in the merchandise hierarchy, surrogate keys for location, area, and chain in the location hierarchy, and surrogate keys for day and week in the calendar hierarchy.
Next step creates a temporary table with all the fact data extracted from the source system joined with associated dimension tables from the data warehouse schema. With this step the temporary table gets all the surrogate keys for the associated hierarchical dimensions (such as product or organization or calendar) and stores the data in a de-normalized format. This way data can be used for rolling up several levels and it is not required to always roll up the data from base fact table and improves the overall aggregation performance.
Any transaction records that do not have valid dimension data are inserted into the ODI error tables.
The temp table created in step 2 is merged into the base fact table.
The flattened temp table (created in step 2) is then used for creating temporary tables for Corporate, As Is, and Season level aggregate tables.
In this step the data is taken from lowest level which is available in the temporary table created in step 2 and rolled up to corporate level and stored in the corporate level temp table.
This temporary table can be used for rolling up data across Product or Calendar dimensions. For example, the temp table in this case will be a table with Sales measures along with surrogate keys for Product and Calendar dimensions (Organization dimension will not exist as it is corporate level aggregate). This data can be used for rolling up data from Sales at Item, Day level to Sales as Subclass, Day level or Item, and Week level.
In this step the data from temp table created in step 2 is joined with Season, Item dimension table to create season level temp table. This temp table can be used for rolling up the data across Product, Organization, and Calendar dimensions along with the season dimension.
For example, the temp table in this case will be a table with Sales measures along with surrogate keys for Product, Organization, Season and Calendar dimensions. This data can be used for rolling up data from Sales at Item, Location, Season, Day level to Sales as Subclass, Location, Season, Day level or Item, Location, Season, and Week level.
In this step the data from temp table created in step 2 is joined with flattened temp table for Product dimension (W_RTL_PRODUCT_D_TMP table) to create As Is data level temp table. This temp table can be used for rolling up the data across Product, Organization, Calendar dimensions.
Note that this step rolls up the regular transaction data for As Is aggregation. There is a separate step for recalculating the As Is aggregated data when the reclassification in Product hierarchy occurs and is explained later in this section.
For example, the temp table in this case will be a table with Sales measures along with surrogate keys for current business day's Product, Organization, Season, and Calendar dimensions. This data can be used for rolling up data from Sales at Item, Location, Season, Day level to Sales as Subclass, Location, Season, Day level or Item, Location, Season, and Week level.
In this step, the data from temp table created in step 2 is rolled up against either of Product, Organization or Calendar dimension and merges the data into As Was aggregate table.
The temp table created in step 4 is rolled up as required and the data is merged into the Corporate level aggregate table.
The temp table created in step 4 is rolled up as required and the data is merged into the Season level aggregate table.
The temp table created in step 4 is rolled up as required and the data is merged into the As Is level aggregate table.
In this step, the temp table for recalculating the As Is aggregates on the day the reclassification is created.
In this step As Was level aggregate table is joined with associated dimensions along with the temp table that contains reclassification records (W_RTL_PROD_RECLASS_TMP) and the fact data for the reclassified entities is inserted into another temp table. This step recalculates the facts for reclassified records and is ready to be merged into the As Is aggregate table.
Temp table created in step 11 is rolled up as required and the data is merged into the As Is aggregate table.